
【AWS Glue】データ品質の評価観点と、Data Qualityで利用可能なルールの対応を考えてみた
データ事業本部の川中子(かわなご)です。
今回は前ブログに引き続き、Glue Data Qualityを取り上げます。
また前々回のブログで紹介しているこちらの書籍では、
データマネジメントにおけるデータ品質の領域についても解説されています。
本ブログでは、上記の書籍で紹介されているデータ品質の観点に沿って、
Glue Data Qualityのルール定義方法について整理してみようと思います。
データ品質評価の観点
上で紹介した「データマネジメント 仕組みづくりの教科書」では、
データ品質における評価観点として以下が説明されていました。
| 評価軸 | 説明 | 計算式(例) |
|---|---|---|
| 完全性 | 必要なデータがすべて存在すること | (値が入力されているレコード数) ÷ (全レコード数) |
| 有効性 | データが決められた形式や範囲に収まっていること | (有効な形式・範囲のレコード数) ÷ (全レコード数) |
| 一貫性 | 異なる場所にある同じ意味のデータが、矛盾なく一致していること | (値が一致しているレコード数) ÷ (比較対象の全レコード数) |
| 一意性 | 一意であるべきデータが、重複なく登録されていること | (重複レコード数) ÷ (全レコード数) |
| 整合性 | 関連するデータ間の関係性が保たれていること | (参照先が存在するレコード数) ÷ (全レコード数) |
| 正確性 | データが現実世界の事実と一致していること | (事実と一致するレコード数) ÷ (全レコード数) |
| 妥当性 | データが常識的、あるいは文脈的にみて妥当な値であること | 外れ値の件数や割合を算出 |
| 適時性 | 必要なタイミングでデータが利用可能であること | (データ基盤登録日) - (連携システム登録日) |
| 最新性 | データが現実世界の最新の状態を反映していること | (データ変更日) - (現実世界での変更発生日) |
よくあるデータ品質の課題である 「テーブルによってデータの意味が異なる」 や
「特定カラムの欠損値が多い」 などが9つの項目に整理されています。
これらの観点に沿ってデータの評価を実施しようと考えた時に、
Glue Data Qualityでどのようにルールを定義できるのか気になりました。
データ品質定義言語(DQDL)の仕様
Glue Data Qualityでルール定義に使用する DQDLについては、
以下の公式ドキュメントに分かりやすく情報がまとめられています。
その中でいくつか重要な仕様について先に触れておきます。
複合ルール
DQDLでは以下のように2つ以上のルールを組み合わせたルールを、
1つのルールとして定義して評価することが可能です。
入れ子構造も可能で、ルール定義の柔軟性がとても高いですね。
Rules = [
(IsComplete "colA") and (IsUnique "colA"),
(RowCount "colB" > 100) or (IsPrimaryKey "colB"),
(RowCount > 0) or ((IsComplete "colC") and (IsUnique "colC"))
]
デフォルトの仕様ではテーブルに対して各ルールを用いて評価を行い、
その結果を組み合わせる形で最終的な評価結果が出力されます。
# テーブル
+------+------+
|myCol1|myCol2|
+------+------+
| 2| 1|
| 0| 3|
+------+------+
# 評価結果
+----------------------------------------------------------+-------+
|Rule |Outcome|
+----------------------------------------------------------+-------+
|(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed |
+----------------------------------------------------------+-------+
より詳細なデータ品質評価を実行したい場合には、
以下オプションを設定することで行単位での評価が可能です。
eval_dq = EvaluateDataQuality().process_rows(
frame=dyf,
ruleset=DQ_RULESET,
additional_options={
"compositeRuleEvaluation.method":"ROW"
},
)
上記のように行単位の実行を指定した場合、
先ほどの例のテーブルでは以下のような実行結果に変わります。
+------+------+------------------------------------------------------------+---------------------------+
|myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult|
+------+------+------------------------------------------------------------+---------------------------+
|2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
|0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed |
+------+------+------------------------------------------------------------+---------------------------+
行レベル評価における制限
詳細な条件を設定する時に便利な複合ルールですが、
一部のルールでは使用が制限されているので注意が必要です。
使用が制限されているのは以下のような、
カラムやテーブル全体に対して評価を実行するルールが対象となります。
- 比率に依存するルール
- Completeness
- DatasetMatch
- ReferentialIntegrity
- Uniqueness
- しきい値に依存するルール(
with thresholdと併用する場合)- ColumnDataType
- ColumnValues
- CustomSQL
つまり完全性と有効性を行レベルで同時に評価したい場合に、
以下のように定義してしまうとエラーが発生します。
# Completenessは列全体を評価するため行レベルには非対応
Rules = [
(Completeness "colA" > 0.95) and (ColumnValues "colA" matches "[a-zA-Z]*")
]
# 出力
IllegalArgumentException: Composite rule evaluation at row level is not supported for the following rules:
(Completeness "colA" > 0.95) and (ColumnValues "colA" matches "[a-zA-Z]*")
もし同様の内容で行レベルの評価を実行したい場合は、
以下のように行レベルの評価に対応したルールを使用する必要があります。
Rules = [
(IsComplete "colA") and (ColumnValues "colA" matches "[a-zA-Z]*")
# または
(ColumnValues "colA" != NULL) and (ColumnValues "colA" matches "[a-zA-Z]*")
]
動的ルールとアナライザー
「明確な正常値の範囲はないが、直近の値から異常値を検出したい」
このようなケースに有効なのが動的ルールとアナライザーです。
動的ルールは last(n)や集計関数を使用して定義が可能です。
Rules = [
# colAとcolBの相関係数が直近10回平均±0.1の範囲に収まっているか
ColumnCorrelation "colA" "colB" between avg(last(10))-0.1 and avg(last(10))+0.1
]
対応している集計関数は以下の通りです。
| 集計関数 | 説明 |
|---|---|
avg |
平均値 |
median |
中央値 |
max |
最大値 |
min |
最小値 |
sum |
合計値 |
std |
標準偏差 |
abs |
絶対値 |
index(last(k), i) |
直近のkからi番目に新しい値 |
stdや absなどの集計関数にも対応しているため、
簡単な統計的検証などもルールとして定義できるのは便利ですね。
そして異常検知のための統計値を取得するための設定がアナライザーです。
継続的にルールに基づいた値を追跡し、異常値を検出することが可能になります。
アナライザー定義は以下のように非常にシンプルな構文になります。
Analyzers = [
DistinctValuesCount "colA",
ColumnLength "colA"
]
アナライザーに対応しているルールは以下の通りです。
| ルール | 説明 |
|---|---|
RowCount |
データセットの行数を計算する |
Completeness |
列の完全性の割合を計算する |
Uniqueness |
列の一意性の割合を計算する |
Mean |
数値列の平均を計算する |
Sum |
数値列の合計を計算する |
StandardDeviation |
数値列の標準偏差を計算する |
Entropy |
数値列のエントロピーを計算する |
DistinctValuesCount |
列内の個別値の数を計算する |
UniqueValueRatio |
列内の一意の値の比率を計算する |
ColumnCount |
データセット内の列数を計算する |
ColumnLength |
列の長さを計算する |
ColumnValues |
数値列:最小値と最大値を計算する 数値列以外:ColumnLengthの最小値と最大値を計算する |
ColumnCorrelation |
特定の列の列相関を計算する |
CustomSql |
カスタムSQLによって返される統計を計算する |
AllStatistics |
次の統計を計算します ・RowCount / ColumnCount ・すべての列:Completeness / Uniqueness ・数値:Min / Max / Entropy / Mean/ Standard Dev / Sum ・文字列:MinLength / MaxLength |
ETLで設定したアナライザーのメトリクスはグラフで確認できます。
メトリクスグラフの詳細については公式ドキュメントをご参照ください。
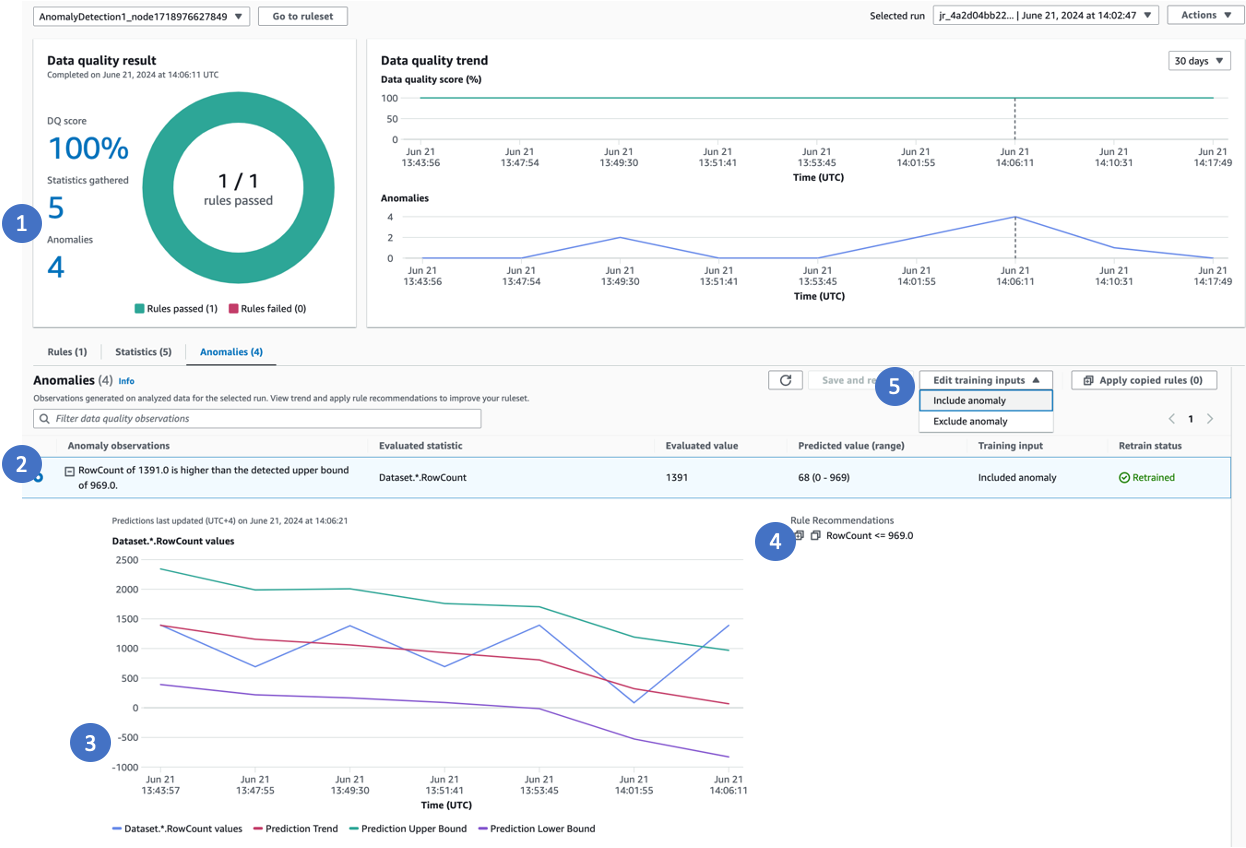
データ品質の評価観点との対応
Glue Data Qualityの仕様について前置きが長くなりましたが、
ここからはデータ品質における評価観点とルールを照らし合わせてみます。
完全性
評価観点:必要なデータがすべて存在すること
評価指標:(値が入力されているレコード数) ÷ (全レコード数)
列全体を評価する場合にはIsCompleteやCompletenessが有効です。
Rules = [
# 欠損値がないか
IsComplete "colA",
# 欠損値の割合が5%未満に収まるか
Completeness "colB" > 0.95
]
複合ルールで完全性評価を含めたい場合にはIsCompleteまたは、
ColumnValues "col" != NULLを使用することで実現可能です。
Rules = [
# IsCompleteは複合ルールの評価でも有効
(IsComplete "colA") and (ColumnValues "colA" matches "[a-zA-Z]*")
# ColumnValuesで代用することも可能
(ColumnValues "colA" != NULL) and (ColumnValues "colA" matches "[a-zA-Z]*")
]
なお文字列のカラムに対しては、欠損キーワードの使い分けが可能です。
| キーワード | 対象 |
|---|---|
| NULL | 一般的なNULL |
| EMPTY | "" (空文字) |
| WHITESPACES_ONLY | " " (スペース文字) |
有効性
評価観点:データが決められた形式や範囲に収まっていること
評価指標:(有効な形式・範囲のレコード数) ÷ (全レコード数)
有効性の検証にはColumnValuesが有効です。
比較演算子などを使うことで自由度の高いルール設定が可能です。
Rules = [
# 値がリストの中に含まれるか
ColumnValues "colA" in ["Gold", "Silver", "Bronze"],
# 値が範囲内に含まれているか
ColumnValues "colB" between 0 and 120,
# 特定の形式に対応しているか
ColumnValues "colC" matches "^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\\.[a-zA-Z]{2,}$",
]
データ型の検証にはColumnDataType、
データの文字列長の検証にはColumnLengthを使用します。
Rules = [
# データ型がDateになっているか
ColumnDataType "colD" = "Date",
# 文字列長が5から10の間に含まれるか
ColumnLength "colE" between 5 and 10,
]
他にも有効値検証に有効なルールが複数用意されています。
Rules = [
# カラム同士の相関係数が0.8より大きいか
ColumnCorrelation "colF" "colG" > 0.8,
# カラム数が指定の値範囲に含まれるか
ColumnCount between 10 and 20
# 対象の列が存在するか
ColumnExists "colH"
# 全列の名前が所定の正規表現と一致するか
ColumnNamesMatchPattern "aws_.*"
# 標準偏差が1.5以下であるか
StandardDeviation "colI" < 1.5
]
なお評価観点の1つである正確性についても、
実際は上記のようなルールを使用して定義する形になると思います。
一貫性
評価観点:異なる場所にある同じ意味のデータが、矛盾なく一致していること
評価指標:(値が一致しているレコード数) ÷ (比較対象の全レコード数)
データセット間でデータが一致しているかどうかを確認する場合には、
DatasetMatchで結合キーを指定して使用します。
Rules = [
# referenceテーブルとcolA列で結合したときのデータ一致率が9割以上
DatasetMatch "reference" "colA" >= 0.9
]
特定の列について、データが参照データセットに含まれるかを確認するには、
ReferentialIntegrityでカラムを指定して使用します。
Rules = [
# colB列の値がreferenceテーブルのcolB列に9割以上含まれる
ReferentialIntegrity "colB" "reference.coB" >= 0.9
]
一意性
評価観点:一意であるべきデータが、重複なく登録されていること
評価指標:(重複レコード数) ÷ (全レコード数)
カラムの一意性評価には、UniquenessやUniqueValueRatio、
DistinctValuesCountまたはIsUniqueを使用します。
Rules = [
# 重複値がないか
IsUnique "colA",
# 重複値の割合が5%未満に収まるか
Uniqueness "colB" > 0.95
UniqueValueRatio "colC" > 0.95
# ユニーク値数が10~50種類の範囲に含まれる
DistinctValuesCount "colD" between 10 and 50
]
また上記のルールとは少し毛色が異なりますが、
プライマリキーの検証としてIsPrimaryKeyというルールもあります。
Rules = [
# 対象のカラムがプライマリキーになっているか
IsPrimaryKey "colE",
# 複合キーにも対応
IsPrimaryKey "colF" "colG"
]
整合性
評価観点:関連するデータ間の関係性が保たれていること
評価指標:(参照先が存在するレコード数) ÷ (全レコード数)
こちらは評価観点としては一貫性の項目と近しいところがあるので、
利用するルールについては重なってくるイメージを持っています。
もしテーブル間でカラムの一致を確認するケースがあれば、
SchemaMatchの使用も含まれてくると思います。
Rules = [
# referenceテーブルと全カラムの名前とデータ型が一致しているか
# 順序は考慮しない
SchemaMatch "reference" = 1.0
]
妥当性
評価観点:データが常識的、あるいは文脈的にみて妥当な値であること
評価指標:外れ値の件数や割合を算出
データの範囲が明確な場合は、事前に紹介したColumnValuesや、
Mean、StandardDeviation、Sumなどの統計値が有効です。
またカラム同士の相関係数ではColumnCorrelationを使用します。
Rules = [
# 平均値
Mean "colA" between 1000 and 50000,
# 標準偏差
StandardDeviation "colB" < 100,
# 合計値
Sum "colC" > 1000000
# カラム間の相関係数
ColumnCorrelation "colD" "colE" between -0.8 and -0.4
]
またより高度な異常検知としてDetectAnomaliesが使用できます。
その名前の通り、対象のカラムの異常値を検出できるようになります。
Rules = [
# データセット全体の行数の異常値を検知
DetectAnomalies "RowCount",
# 特定のカラムの文字列数の異常値を検知
DetectAnomalies "ColumnLength" "colF"
]
DetectAnomaliesに対応しているルール一覧は以下をご参照ください。
適時性/最新性
適時性
評価観点:必要なタイミングでデータが利用可能であること
評価指標:(データ基盤登録日) - (連携システム登録日)
最新性
評価観点:データが現実世界の最新の状態を反映していること
評価指標:(データ変更日) - (現実世界での変更発生日)
これらに評価観点については概念が近いのでまとめてご紹介します。
まず適時性についてですが、評価指標の式から分かるように、
日時を表すカラム同士の差分を取ってデータの鮮度を判断します。
しかしDQDLではカラム同士の演算が直接できないため、
カラム同士の差分を表すカラムを追加するなどの処理が別途必要です。
データ品質の検証実行の日時との差分で比較する方法であれば、
DataFreshnessやnow()関数などの使用によって実現が可能です。
Rules = [
# データが3日以内、1時間以内に更新されている
DataFreshness "colA" <= 3 days,
DataFreshness "colB" <= 1 hours,
# now()関数を使う場合
ColumnValues "colC" > (now() - 3 days)
]
対象がファイル単位であれば、FileFreshnessが有効です。
Rules = [
# S3上のファイルが24時間以内に更新されている
FileFreshness "s3://bucket/path/data.parquet" > (now() - 24 hours)
# フォルダ単位でも指定可能
FileFreshness "s3://bucket/path/" <= 24 hours,
# 日付や日時での指定も可能
FileFreshness "s3://bucket/path/" > "2020-01-01",
FileFreshness "s3://bucket/path/" between "9:30 AM" and "9:30 PM"
]
FileFreshnessの詳細な使用についてはこちらをご参照ください。
さいごに
今回はデータマネジメントにおけるデータ品質の観点から、
Glue Data Qualityの仕様やルールを調べてみました。
複合ルール、動的ルール、アナライザーなどの高度な機能により、
DQDLを使ってきめ細かな品質ルールを定義できることが分かりました。
紹介したような各種ルールをうまく設計できれば、
多くの観点に基づいて機械的に判断し、品質のスコア化ができそうです。
今回はツールの視点からデータ品質を説明してみましたが、
実際の運用では ビジネスへの影響度や優先順位などを考慮して、
あくまでデータ活用を目的としたルール設計を行うことが非常に重要 です。
ツールの利用自体が目的にならないように、気をつけたいですね。
本記事の内容が少しでも参考になれば幸いです。
最後まで記事を閲覧いただき、ありがとうございました。









