
DynamicFrameでJDBCソースからデータを取得するGlue Jobの作成とPredicate pushdownオプションを確認する
データ事業本部の鈴木です。
Glue JobでJDBCソースのデータを取得したい場合はよくあると思います。
最近だと対応するデータベースならZero-ETLでAmazon Redshiftに連携したり、Amazon Athenaのフェデレーテットクエリを使ってクエリしたりもできますが、テーブル数が少ないならGlue JobでSparkジョブを実行して取得する方法は分かりやすいですし、採用もしやすいです。
最近ではAWS Glue StudioでUIを使ってSparkジョブを作成できるようになりました。
このときジョブの実装で使用される実装がGlue独自のDynamicFrameで、SparkがネイティブでサポートしているDataFrameと類似した仕組みですが、各レコードに合わせてより柔軟にスキーマが扱えます。
今回はJDBCソースに対するPredicate pushdown向けのオプションについて、どのようなクエリがデータベース側で実行されるのか自分で動かして確認したかったため、試したことと参考にした資料をまとめました。
0. 前準備
紹介するオプションを実行するため、必要なリソースを作成しておきました。
i. Auroraデータベースのクラスター作成
コンソールからAurora Serverless v2でPostgreSQLベースのDBクラスターを作成しました。
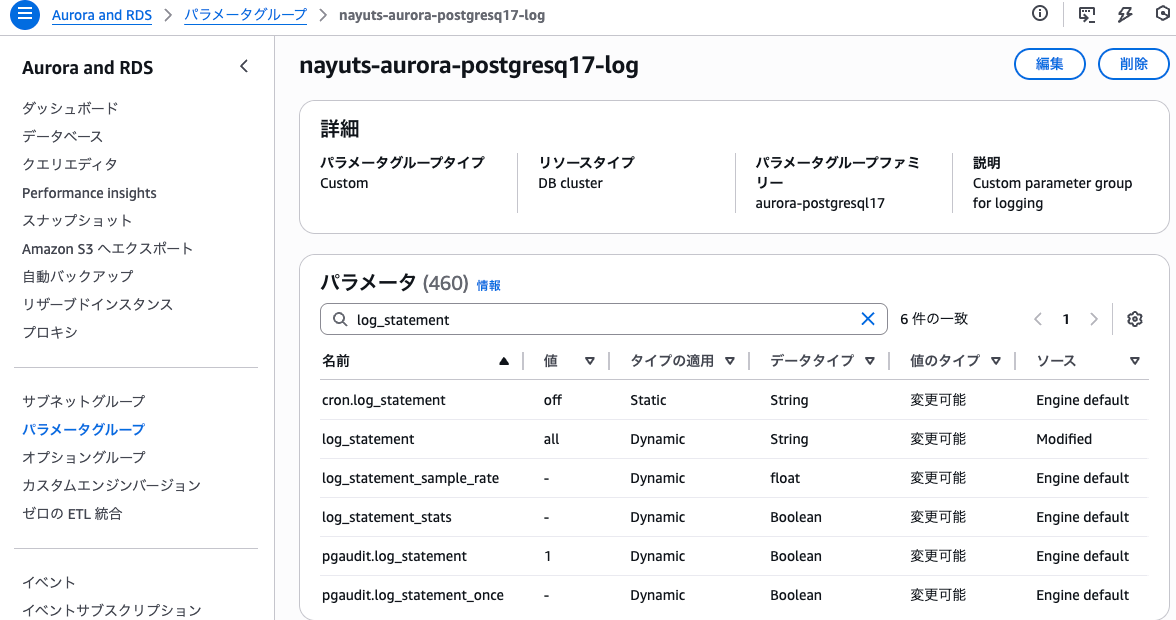
Glue Jobから実行したクエリがCloudWatch Logsから確認できるように、log_statementをallにしておきました。
これには、aurora-postgresql17のパラメータグループファミリーのパラメータグループで、log_statementをallにしたものを作成し、DBクラスターに設定しました。

ii. DBのセットアップ
app_dbというデータベースを作成し、app_userからSELECTが可能なuserテーブルを作成しました。
-- テーブルを作成
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(100),
email VARCHAR(100),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
userテーブルには以下のようなデータを格納しておきました。
id | name | email | created_at
----+------+------------------------+----------------------------
1 | 太郎 | taro@example.com | 2025-12-01 01:29:39.906726
2 | 花子 | hanako@example.com | 2025-12-01 01:29:39.906726
3 | 田中 | tanaka1@example.com | 2025-12-01 01:31:17.662297
4 | 田中 | tanaka2@example.com | 2025-12-01 01:31:17.662297
5 | 田中 | tanaka3@example.com | 2025-12-01 01:31:17.662297
6 | 田中 | tanaka4@example.com | 2025-12-01 01:31:17.662297
7 | 田中 | tanaka5@example.com | 2025-12-01 01:31:17.662297
8 | 佐藤 | sato1@example.com | 2025-12-01 01:31:17.662297
9 | 佐藤 | sato2@example.com | 2025-12-01 01:31:17.662297
10 | 佐藤 | sato3@example.com | 2025-12-01 01:31:17.662297
11 | 佐藤 | sato4@example.com | 2025-12-01 01:31:17.662297
12 | 佐藤 | sato5@example.com | 2025-12-01 01:31:17.662297
(省略)
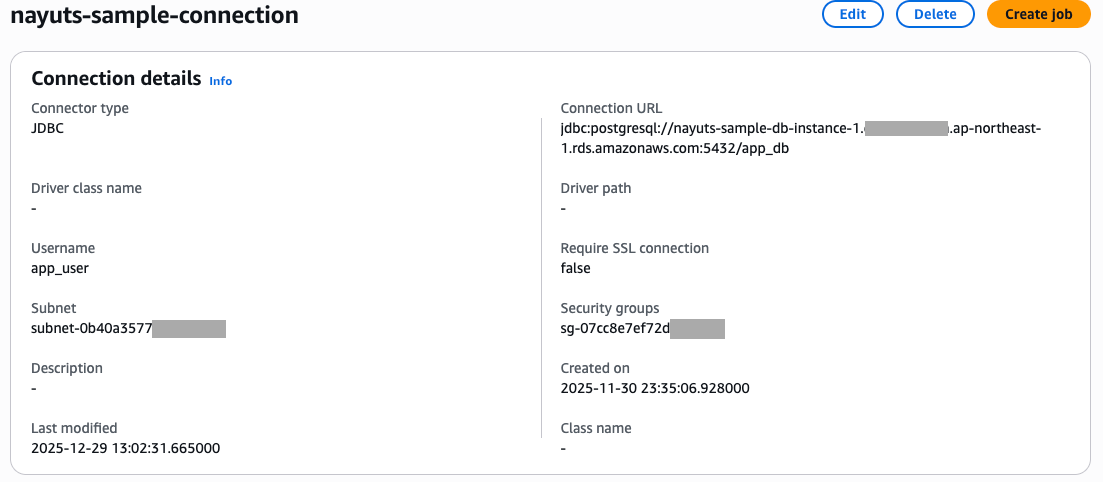
iii. Glue Connectionの作成
検証用に先のAurora向けのGlue接続を作成しておきました。この接続を設定すれば、Glue JobはデータベースあるサブネットにIPを確保して、データベースのエンドポイントにアクセスできるようになっています。
1. AWS Glue Studioで作成される実装を確認する
前準備ができたので、Glue Jobを作成していきます。
Glueのコンソールから利用できるGlue Studioでは、UIを使ってPySparkおよびScalaの実装を作成することができます。
DynamicFrameに精通している場合は手動で実装でも問題ないのですが、Glueが想定している実装を確認したい場合や、Glue Jobのほかの機能(Glue Jobが使うライブラリの仕様が記載されたドキュメントがあまり公開されていない、データ品質や機密データに関する変換機能など)を合わせて使うような場合には、まずはGlue Studioで作成した方がやりやすいです。
今回はAuroraのPostgreSQLからデータを取得したかったため、PostgreSQLのソースを追加しました。
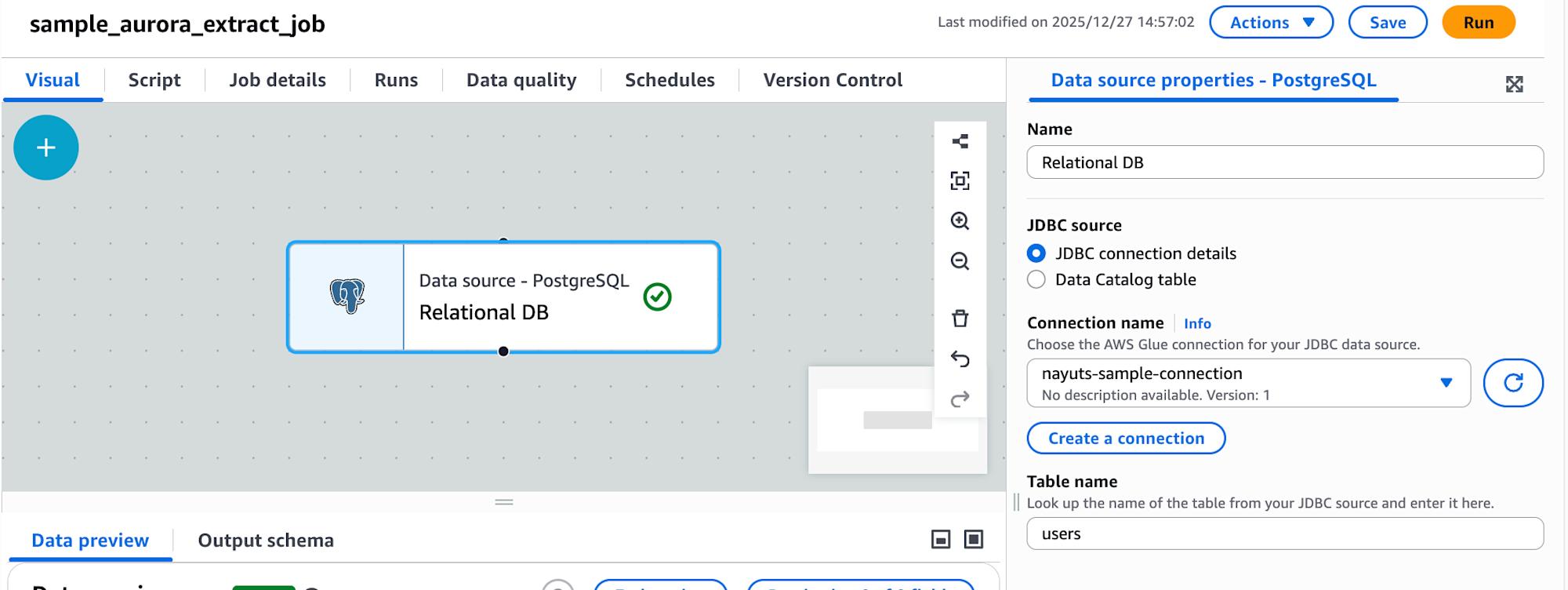
nayuts-sample-connection・usersは0で作成しておいたGlue接続名とテーブル名です。
すろと以下のようなスクリプトが作成されます。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
# Script generated for node Relational DB
RelationalDB_node1766814391107 = glueContext.create_dynamic_frame.from_options(
connection_type = "postgresql",
connection_options = {
"useConnectionProperties": "true",
"dbtable": "users",
"connectionName": "nayuts-sample-connection",
},
transformation_ctx = "RelationalDB_node1766814391107"
)
job.commit()
1766814391107はミリ秒単位のUnixタイムスタンプです。以降では適宜省略したコードを紹介します。
今回はJobのワーカー数は2にしました。
なお、この実装だと、dbtableで指定したテーブルの全件がクエリされます。
データベース側で実行されたクエリを確認するため、クエリが実行されるよう、以下のようにS3バケットにデータを書き出す実装も追加しました。(読み込みだけだとSparkエンジンは実際のデータの取得をしませんでした)
バケット名・プレフィクスは自身のものに変えてください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
RelationalDB_node = glueContext.create_dynamic_frame.from_options(
connection_type = "postgresql",
connection_options = {
"useConnectionProperties": "true",
"dbtable": "users",
"connectionName": "nayuts-sample-connection",
}
)
df = RelationalDB_node.toDF()
df.write.mode("overwrite") \
.option("header", "true") \
.csv("s3://バケット名/プレフィクス/")
job.commit()
ジョブを実行した際のAuroraデータベースのログは以下です。

SELECT * FROM users
一部レコードに限定して取得したい場合は、以下に紹介するようにsampleQueryで指定する必要があります。
2. Predicate pushdownを使ってデータスキャン量を削減する
データベースのデータソースに対してPredicate pushdownを使うと、データ処理のフィルタ条件(WHERE句など)をデータソースのエンジンで実行することができます。
ざっくりとメリットは以下があります。
- Glue Jobに転送されるデータ量の削減
- データベース側で実行するデータスキャン量の削減
Glue Jobに転送されるデータ量が削減されれば、ジョブが早く終了することにつながります。その場合、コスト面も安くなります。読み込みのデータ量が多いためにワーカー数が増えているような場合は、ノード数を減らすことで料金の削減になる場合もあり得ます。
データベース側で実行するデータスキャン量の削減という観点では、データベース側でインデックスを作成しており、Predicate pushdownで指定した条件がインデックスにあったものであればデータベースエンジン側の負荷も減らすことにつながります。
Glue Jobでは、sampleQueryを使うことでJDBCソースに対してPredicate pushdownが可能です。
以下のような実装です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
sample_query = "select id from users where name = '田中'"
RelationalDB_node = glueContext.create_dynamic_frame.from_options(
connection_type = "postgresql",
connection_options = {
"useConnectionProperties": "true",
"dbtable": "users",
"connectionName": "nayuts-sample-connection",
"sampleQuery": sample_query,
},
)
df = RelationalDB_node.toDF()
df.write.mode("overwrite") \
.option("header", "true") \
.csv("s3://バケット名/プレフィクス/")
job.commit()
ジョブを実行した際のAuroraデータベースのログは以下です。

SELECT * FROM (select id from users where name = '田中') as users
sampleQueryのみの場合、並列では読み取りされないため、enablePartitioningForSampleQueryなどの設定と合わせて行う必要があります。
なお、次に記載する並列読み取りの場合はクエリの最後にANDをつける必要がありますが、並列読み取りでない場合はつけるとエラーになりました。
sample_query = "select id from users where name = '田中' AND"

以下のログが発行されていました。

SELECT * FROM (select id from users where name = '田中' AND) as users WHERE 1=0
3. Predicate pushdownを使ってデータスキャン量を削減する(並列読み取り)
基本的な実装は並列でない時と同じですが、enablePartitioningForSampleQueryの有効化と、どのような条件でワーカーごとに並列でデータを読み取るかの方法の指定が必要でした。
まずはenablePartitioningForSampleQueryとhashpartitionsとhashfieldを指定した例です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
sample_query = "select * from users where name IN ('田中', '鈴木') AND"
RelationalDB_node = glueContext.create_dynamic_frame.from_options(
connection_type = "postgresql",
connection_options = {
"useConnectionProperties": "true",
"dbtable": "users",
"connectionName": "nayuts-sample-connection",
"sampleQuery":sample_query,
"hashpartitions": "2",
"hashfield": "name",
"enablePartitioningForSampleQuery": True,
},
)
df = RelationalDB_node.toDF()
df.write.mode("overwrite") \
.option("header", "true") \
.csv("s3://バケット名/プレフィクス/")
job.commit()
ジョブを実行した際のAuroraデータベースのログは以下です。

SELECT * FROM (select * from users where name IN ('田中', '鈴木') AND ('x'||SUBSTR(MD5("name"::TEXT), 25, 8))::BIT(31)::INT % 2 = 1) as users
SELECT * FROM (select * from users where name IN ('田中', '鈴木') AND ('x'||SUBSTR(MD5("name"::TEXT), 25, 8))::BIT(31)::INT % 2 = 0) as users
hashfieldで指定したカラムを一度MD5によりハッシュ値にしてからhashpartitionsで割ることでワーカーそれぞれが担当するクエリを作成していました。
次にenablePartitioningForSampleQueryとhashpartitionsとhashexpressionを指定した例です。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
sample_query = "select * from users where name IN ('田中', '鈴木') AND"
RelationalDB_node = glueContext.create_dynamic_frame.from_options(
connection_type = "postgresql",
connection_options = {
"useConnectionProperties": "true",
"dbtable": "users",
"connectionName": "nayuts-sample-connection",
"sampleQuery":sample_query,
"hashpartitions": "2",
"hashexpression": "id",
"enablePartitioningForSampleQuery": True,
},
)
df = RelationalDB_node.toDF()
df.write.mode("overwrite") \
.option("header", "true") \
.csv("s3://バケット名/プレフィクス/")
job.commit()
ジョブを実行した際のAuroraデータベースのログは以下です。


SELECT * FROM (select * from users where name IN ('田中', '鈴木') AND id % 2 = 0) as users
SELECT * FROM (select * from users where name IN ('田中', '鈴木') AND id % 2 = 1) as users
こちらはより直接的にhashexpressionで指定した数値カラムの値をhashpartitionsで割ることでワーカーそれぞれが担当するクエリを作成していました。
なお、並列で読み取る場合はsampleQueryで指定するクエリの最後にANDをつけないとエラーになりました。

そのた関連する資料
今回紹介した内容はよく調べるとAWSのガイドにも記載がありますが、関係するワードの一般性が高いからか、まとまって収集しづらいように思いました。
ここまでで紹介したものが意外で、私が見つけた資料をまとめておきます。
以下のガイドにsampleQueryオプションを使った読み取りを含めたJDBC接続に関するオプションの説明があります。
Predicate pushdownを含めたパフォーマンス最適化については、AWS規範的ガイダンスにも記載がありました。
glueContext.create_dynamic_frame.from_optionsによるJDBCソースに対する読み込みは以下が参考になります。ただし、記載のqueryオプションは私の試したGlueバージョンだと動かなかったため、現在はsampleQueryを使い、もっと古いバージョンではqueryオプションを使うのかもしれません。
最後に
sampleQueryオプションを指定することで、JDBCソースに対してPredicate pushdownができました。また、enablePartitioningForSampleQueryを有効にすることで、ワーカーごとに並列に読み取りを行う様子もデータベースのログから確認できました。
実行するクエリの指定方法は並列実行の有効・無効で少しコツがあったので、上手く実行できない際には思い出して頂けると幸いです。









