
Google CloudのIceberg「BigLake tables for Apache Iceberg in BigQuery」を試しつつ気になるトピックを調べてみた
はじめに
こんにちは、データ事業本部の渡部です。
今回はGoogle CloudでIcebergを扱う場合の選択肢の一つ、「BigLake tables for Apache Iceberg in BigQuery」を触ってみます。
弊社ブログでkobayashiさんも以前書かれているのですが、公式ドキュメントを読んでいて気になった箇所が何個かあったので、試してみようと思います。
本ブログで書くこと & 結論
- BigLake tables for Apache Iceberg in BigQueryの作成手順
- メタデータのリフレッシュが必要のような記載があるが本当かの確認
- →本当です。自動的にGCS上のmetadataフォルダ配下は更新されないため、リフレッシュ操作が必要
- 公式ドキュメントに記載のある制限事項が本当か1つピックアップして確認
- →本当です。公式ドキュメントに記載の制限事項は正しそうです
- タイムトラベルを使用した履歴データアクセス
- →BigQueryの標準機能のタイムトラベルで実現
Google CloudのIceberg対応
私が公式ドキュメントやブログ記事を漁っている限り、Google CloudでIcebergを扱う場合は以下2種類があるようです。
日本語にすると、「BigQueryのIceberg BigLakeテーブル」と「Icebergの読み取り専用外部テーブル」でしょうか。
前者はBigQueryからGCSに作成するIcebergテーブルで、小さいファイル問題の解決・自動クラスタリング・不要ファイルのガベージコレクション・メタデータファイルの最適化をはじめとした自動ストレージ最適化機能をマネージドで持ち合わせています。
AWSでいうところのS3 Tablesというイメージを私はしています。
後者のApache Iceberg read-only external tablesはSparkなどで作成したIcebergテーブルをBigQueryから外部テーブルとして読み込むテーブルです。こちらはカスタム性はありますが、上記のようなマネージドな最適化機能は持ち合わせていないテーブルとなります。
AWSでいうところの汎用S3バケットにおいたIcebergテーブルに該当するかなと思います。
それぞれ詳しくは上記リンクの公式ドキュメントをご覧ください。
BigLake tables for Apache Iceberg in BigQueryの作成
以下手順で作成していきます。
- Icebergテーブルを保存するGCSバケットを作成
- クラウドリソース接続を作成
- サービスアカウントに権限を付与
- BigLake tables for Apache Iceberg in BigQueryを作成
GCSバケットをGoogle Cloud CLIで作成します。
Cloud Shellから、権限はプロジェクトレベルのオーナー権限で実行しました。
# 変数を設定
export PROJECT_ID="<プロジェクトID>"
export BUCKET_NAME="watanabe-koki-iceberg-bucket-01" # バケット名は全世界で一意にする必要があります
export LOCATION="us-central1"
# GCSバケットを作成
gcloud storage buckets create gs://${BUCKET_NAME} --project=${PROJECT_ID} --location=${LOCATION}
--uniform-bucket-level-access \
--public-access-prevention
BigQueryでGCSにアクセスするためのクラウドリソース接続を作成します。
# 変数を設定
export REGION="us-central1"
export CONNECTION_ID="iceberg-gcs-connection"
# bqコマンドで接続を作成
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connection_type=CLOUD_RESOURCE ${CONNECTION_ID}
サービスに使用されるアカウントである「サービスアカウント」に対して権限を付与するために、Roleをアタッチします。
今回はroles/storage.objectAdminを設定します。
# bq showの結果をJSON形式で受け取り、jqでサービスアカウントIDのみを抽出する
export SERVICE_ACCOUNT_ID=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${CONNECTION_ID} | jq -r '.cloudResource.serviceAccountId')
# 抽出したSERVICE_ACCOUNT_IDを使って権限を付与する
gcloud storage buckets add-iam-policy-binding gs://${BUCKET_NAME} \
--member="serviceAccount:${SERVICE_ACCOUNT_ID}" \
--role="roles/storage.objectAdmin"
BigLake tables for Apache Iceberg in BigQueryを作成します。
BigQueryのコンソールからSQL実行しました。
WITH CONNECTIONでクラウドリソース接続を設定しています。
-- Icebergテーブルを作成
CREATE TABLE `<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table` (
id INT64,
name STRING,
email STRING,
created_at TIMESTAMP,
age INT64,
is_active BOOL
)
CLUSTER BY id
WITH CONNECTION `<プロジェクトID>.us-central1.iceberg-gcs-connection`
OPTIONS (
file_format = 'PARQUET',
table_format = 'ICEBERG',
storage_uri = 'gs://watanabe-koki-iceberg-bucket-01/iceberg-tables/sample_table/'
);
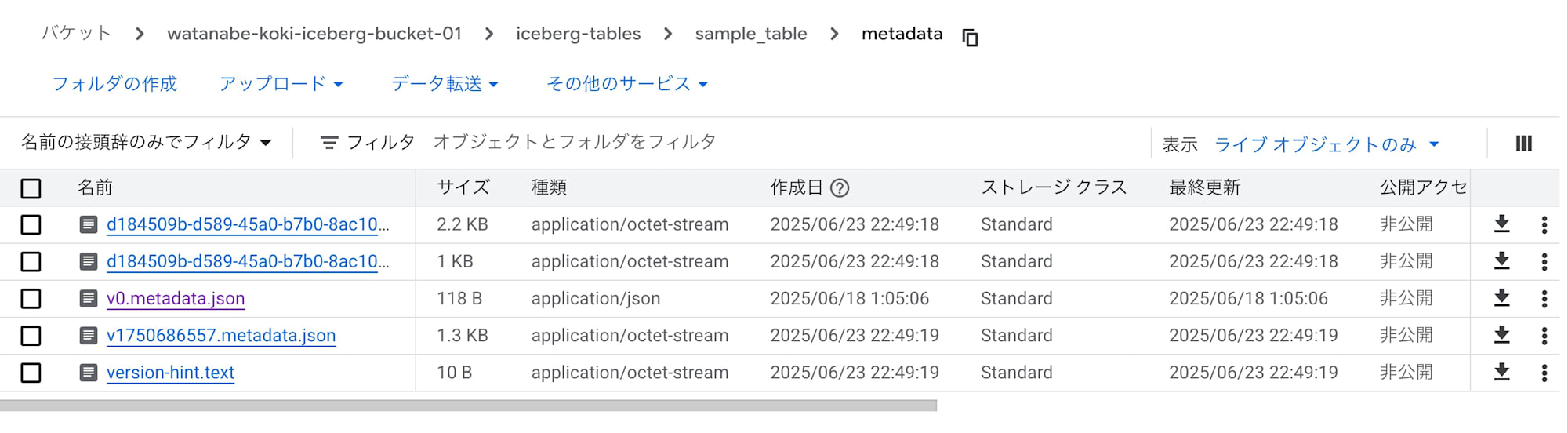
作成後のGCSバケットはこんな感じになっています。

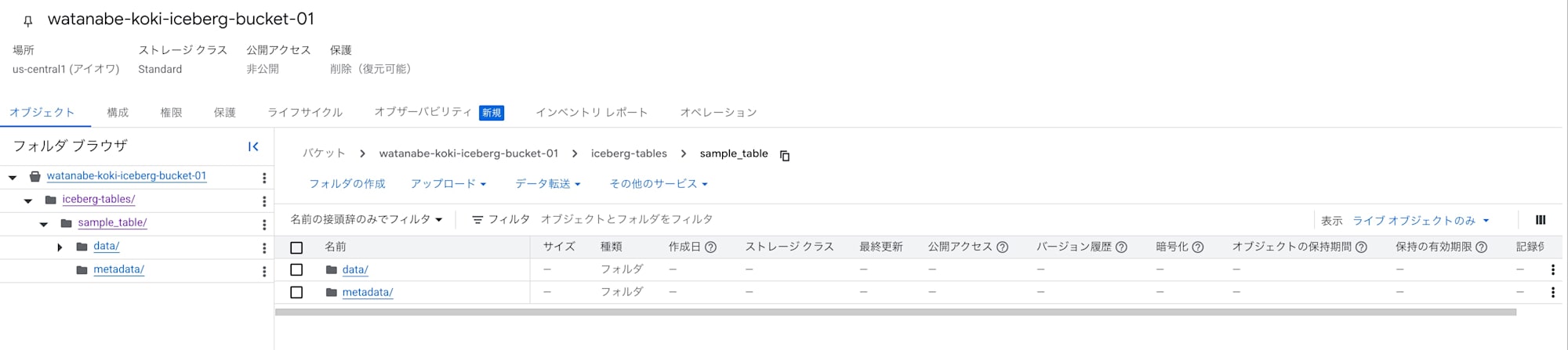
メタデータファイル./metadata/v0.metadata.jsonは以下のような内容です。
値が-1なのでまだ初期状態ということです。
{"properties":{"bigquery-table-id":"<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table"},"current-snapshot-id":-1}
サンプルデータを書き込みます。
-- サンプルデータを挿入
INSERT INTO `<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table`
VALUES
(1, 'John Doe', 'john@example.com', CURRENT_TIMESTAMP(), 30, TRUE),
(2, 'Jane Smith', 'jane@example.com', CURRENT_TIMESTAMP(), 25, TRUE),
(3, 'Bob Johnson', 'bob@example.com', CURRENT_TIMESTAMP(), 35, FALSE);
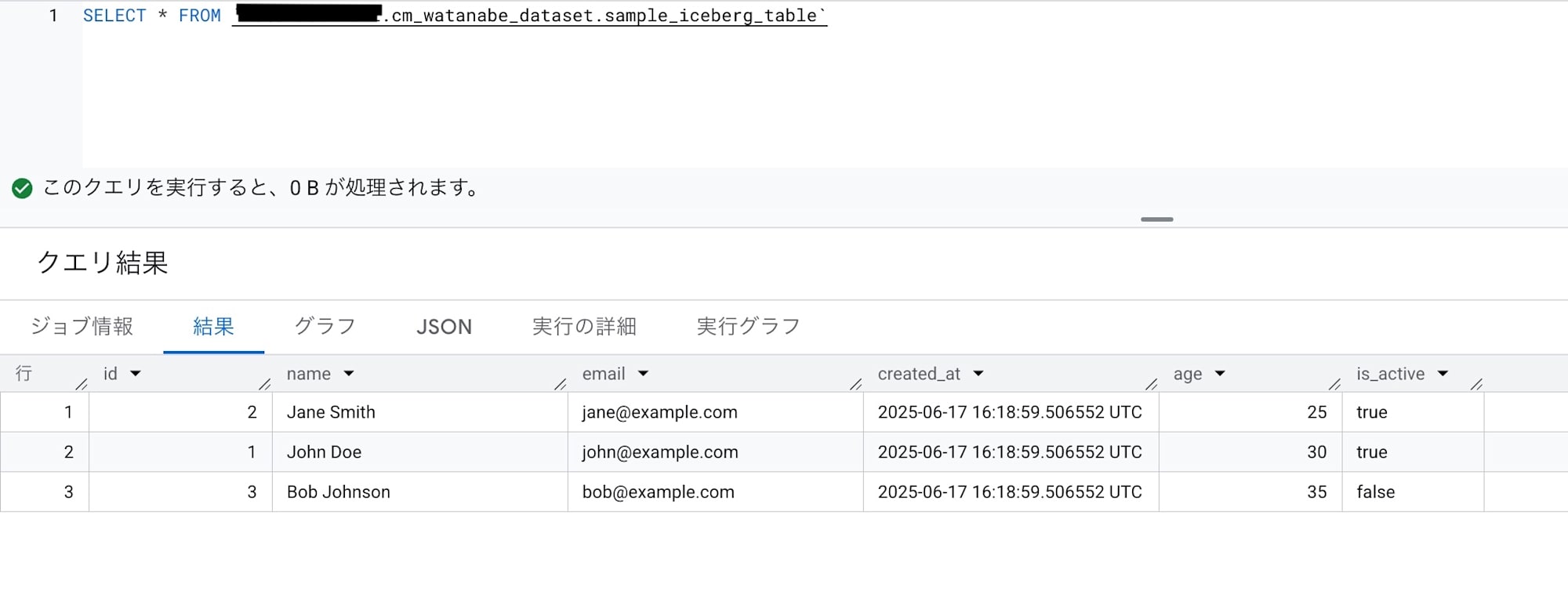
データが出力されました。
SELECT * FROM `<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table`
気になるトピックの確認
メタデータのリフレッシュが必要か
さてここからがBigLake tables for Apache Iceberg in BigQueryの調べ物です。
以下の公式ドキュメントを見る限り、GCSのメタデータはデフォルトでは更新されないような記述です。
1.SQL ステートメントを使用してメタデータを Iceberg V2 形式にエクスポートします EXPORT TABLE METADATA 。
2.オプション:Icebergメタデータスナップショットの更新をスケジュールします。設定した時間間隔に基づいてIcebergメタデータスナップショットを更新するには、スケジュールされたクエリを使用します。
3.オプション:プロジェクトのメタデータの自動更新を有効にすると、テーブルが変更されるたびにIcebergテーブルのメタデータのスナップショットが自動的に更新されます。メタデータの自動更新を有効にするには、 bigquery- tables-for-apache-iceberg-help@google.com までお問い合わせください。 更新操作ごとにEXPORT METADATAコストが発生します。
上記のTable作成後、1週間後に追加データを書き込みました。
-- 追加のテストデータを挿入
INSERT INTO `<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table`
VALUES
(4, 'Alice Wilson', 'alice@example.com', CURRENT_TIMESTAMP(), 28, TRUE),
(5, 'Charlie Brown', 'charlie@example.com', CURRENT_TIMESTAMP(), 42, FALSE);
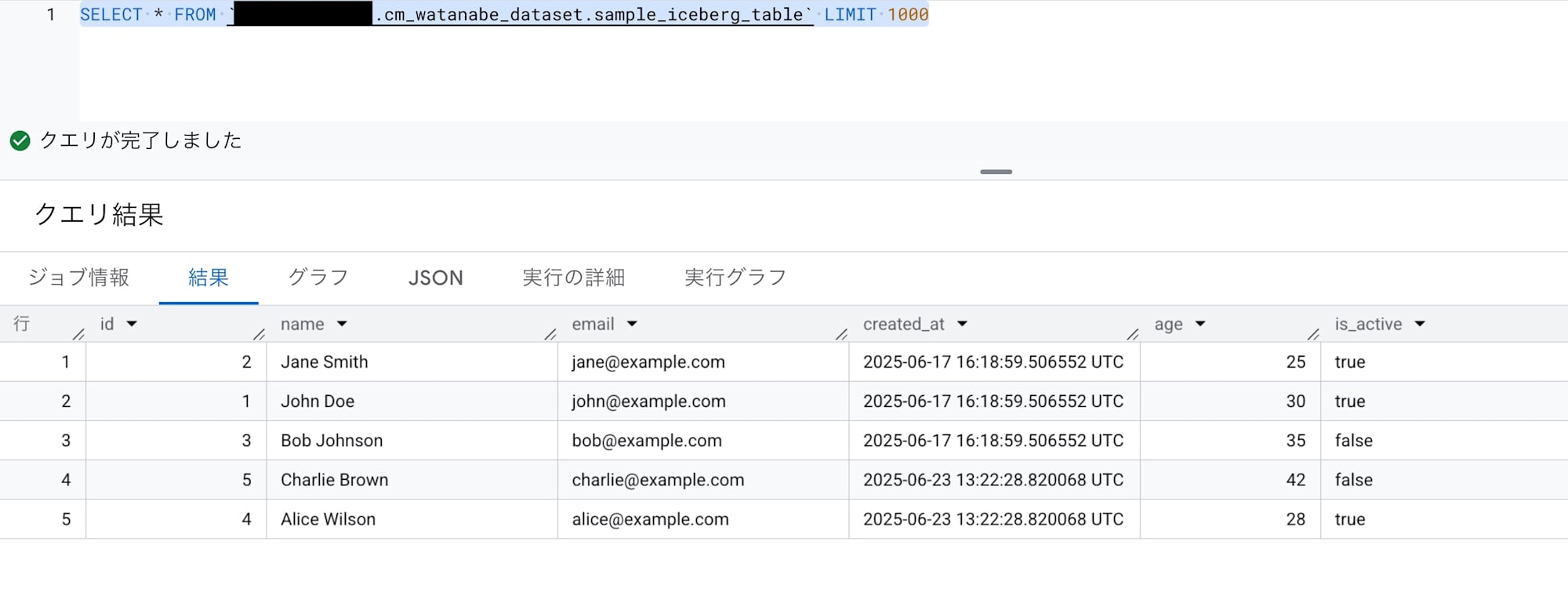
GCSを確認してみると、dataは更新されていますが、

metadataは更新されておりません。
やはり自動ではメタデータは更新されないようです。

そこでEXPORT TABLE METADATAを実行します。
公式ドキュメント曰く、Iceberg テーブルからテーブルメタデータをエクスポートするSQLのようです。
EXPORT TABLE METADATA FROM `<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table`;
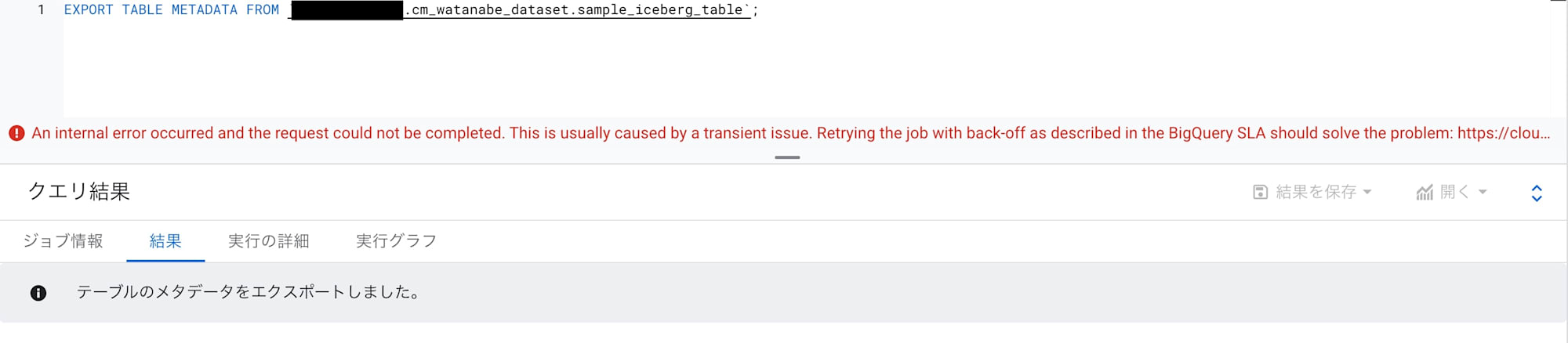
すると!
metadataフォルダ配下にファイルが作成されています。やはりこちらのSQLがリフレッシュには必要のようです。
以下のようなDELETE文を実行してもdataフォルダは更新されますが、metadataは更新されませんでした。
-- id=5のレコードを削除
DELETE FROM `<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table`
WHERE id = 5;
EXPORT TABLE METADATAはその時点のメタデータファイルをエクスポートする動きのようで、連続で実行すると別バージョンのメタデータが作成されました。
BigQueryを経由したアクセスであれば、いつでもメタデータが更新された状態でアクセスできる のですが、GCSのIcebergテーブルに直接読み込みをしたいというケースがある場合は、ETLの前処理・後処理でメタデータのリフレッシュをしたり、定期的なリフレッシュをする必要 がありそうです。
Icebergテーブルのファイルのメンテナンスは実行されると公式ドキュメントに記載されていますが、EXPORT METADATAをしたときに反映されるのか?など、今後要検証です。
またBigQueryのノートブックを使用したSparkからGCSバケットに直接アクセスしてデータ確認しようと試みたのですが、うまくいかなかったのでこちらも今後の要検討です。
制限事項が本当か確認
BigLake tables for Apache Iceberg in BigQueryについて、公式ドキュメントに記載されているBigQueryと比較したときの制限事項がなかなかに多かったので、「実はドキュメントが更新されてないだけじゃないか」という疑念を持ちました。
そのため、そこに記載されていたうちの一つ、ALTER TABLE RENAME TOが使用不可能か確認してみます。
SQLは至って簡単な以下です。
ALTER TABLE `<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table`
RENAME TO sample_iceberg_table2;
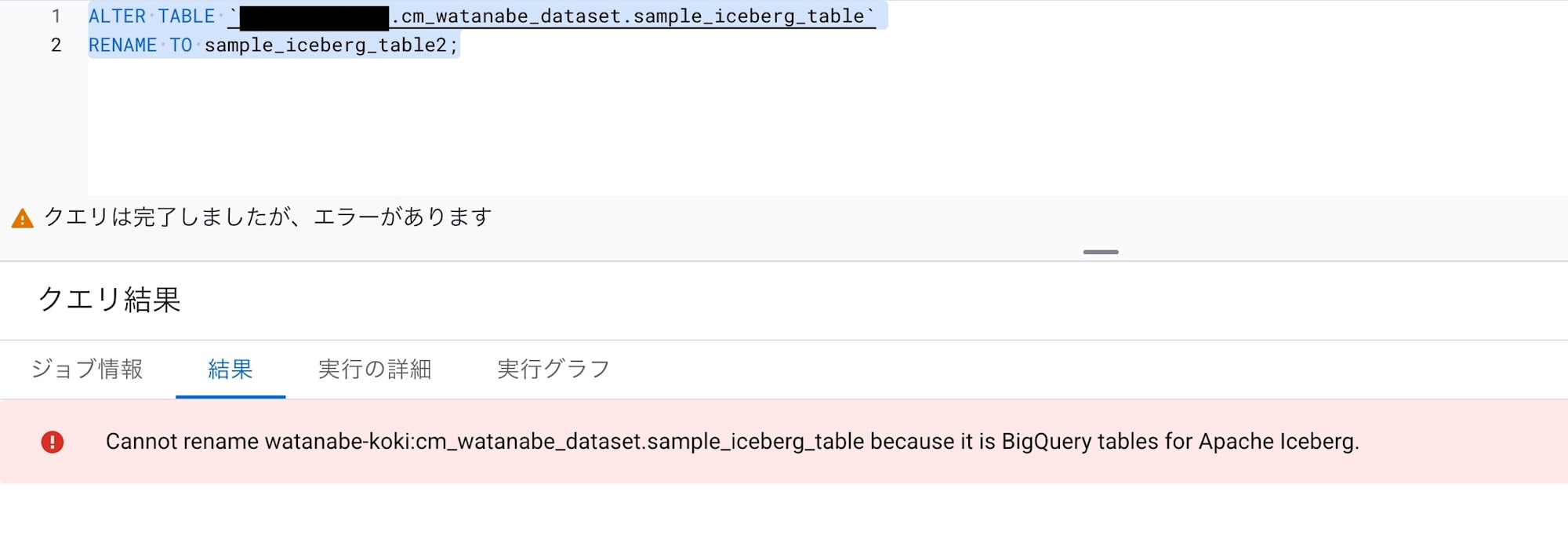
結果は・・・失敗でした。
公式ドキュメントはしっかり整備されていそうです。
タイムトラベル
BigQueryは元から機能としてタイムトラベルでの履歴データへのアクセスが可能です。
BigLake tables for Apache Iceberg in BigQueryは、このタイムトラベルを使用した履歴データアクセスをすることになります。
以下のSQLで2時間前のデータを取得することが可能です。
SELECT *
FROM `<プロジェクトID>.cm_watanabe_dataset.sample_iceberg_table`
FOR SYSTEM_TIME AS OF TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 2 HOUR);
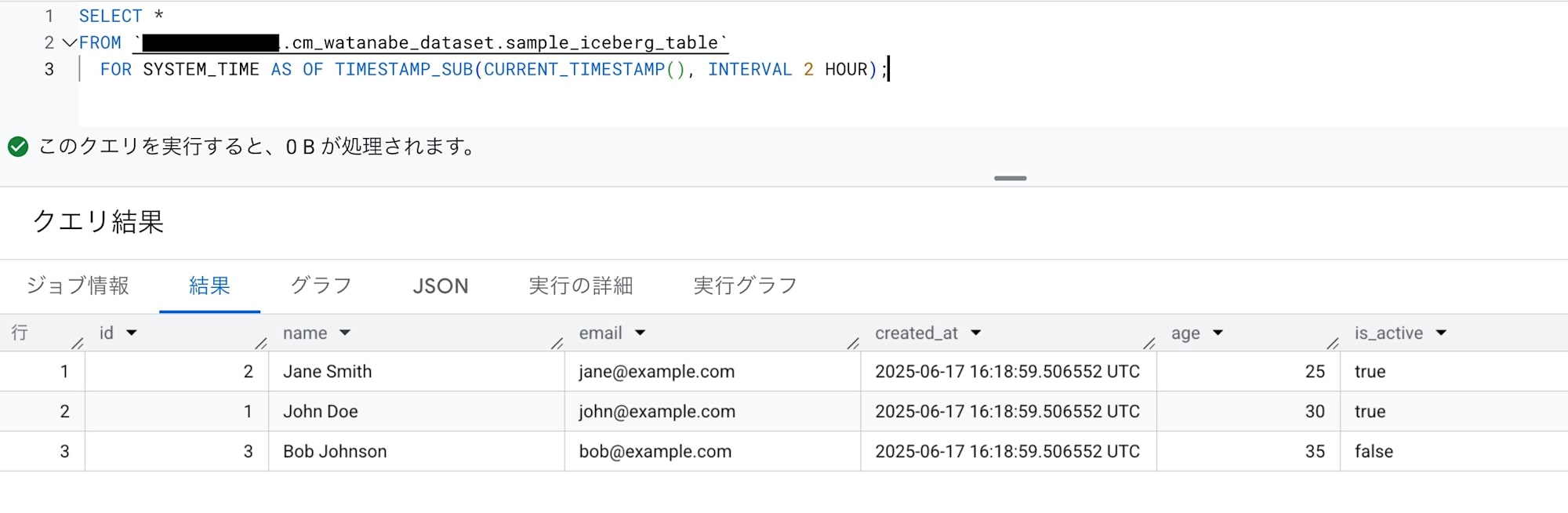
なおSQLとしてはこのくらいで、スナップショットのバージョンを指定したクエリなどは試してみましたができませんでした。
スキーマ進化 もBigQuery標準テーブルが対応しており、公式ドキュメントにBigLake tables for Apache Iceberg in BigQueryも対応しているとの記載があるので、問題なく可能です。
まとめ
いかがでしたでしょうか。
Google CloudでIcebergを検討する場合は、メンテナンス対応が盛り込まれているBigLake tables for Apache Iceberg in BigQueryが第一の選択肢になると思います。
とはいえBigQueryの機能がリッチなので、Google Cloudでデータ管理をする際にIcebergを選択するメリットが薄いような気もしてきますね。
現時点の私の知識だと、BigQuery標準テーブルとIceberg(BigLake tables for Apache Iceberg in BigQuery)の主だった違いは以下となります。
- データ形式
- BigQueryは内部的に隠蔽されたデータの保持するのに対し、Icebergはストレージ上にファイルとして出力される
- データアクセス
- BigQueryはBigQueryを経由してアクセスするのに対し、Icebergは複数のエンジンから直接データにアクセス可能
- (とはいえBigLake tables for Apache Iceberg in BigQueryはBQ経由での書き込み以外は非推奨としているため、完全なIcebergではない)
- アクセスコスト構造
- BigQueryはBigQueryのコスト体系に準じるが、Icebergはそれぞれのエンジンのコスト体系に準じる
- 機能
- BigQueryは全BigQuery機能を使用できるが、Icebergは制限がある
基本的にはBigQuery標準テーブルの使用がいいと感じますが、
自分たちが何を目的としているのかで、どのデータ保存形式をとるか検討していければと思います。
参考資料









