
クラスメソッドメンバーズ提供の CUR を利用した Athena でのコスト分析環境の作り方
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
クラスメソッドでは、弊社サービスのクラスメソッドメンバーズに対応した AWS Cost and Usage Reports(CUR) を提供しています。今回 Parquet 版メンバーズ CUR を利用した Athena でのコスト分析環境を準備していきます。
CSV 形式での分析環境の作り方は、こちらの記事をご確認ください。
前提
下記2つのパターンで環境構築していきます。
- 単一の CUR を利用するパターン
- 複数の CUR を集約するパターン
また下記で紹介されている Athena サンプルクエリが実行できる環境の作成をゴールにします。
- AWS Well-Architected Cost Optimization Workshop - Cost and Usage analysis
- AWS Well-Architected Cost & Usage Report Library
単一の CUR を利用するパターン
このパターンでは、自分のデータのみが含まれる単一の CUR を自身のアカウントに出力して利用することも想定されますが、メンバーズでは AWS 組織(Organizations)レベルの CUR(AWS Organization 内のアカウントのデータを一つに集約した CUR)にも対応しています。今回はせっかくなので、AWS 組織での CUR を利用して環境を構築します。
注:AWS Organizations が利用できるプランでの契約が必要です
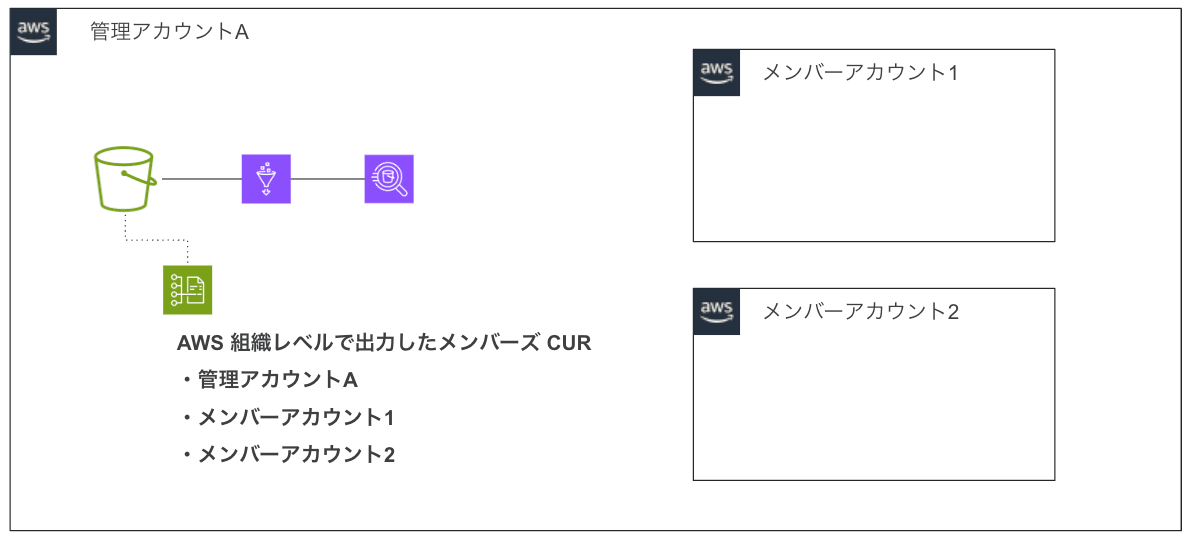
※ 便宜上、管理アカウントで構築していますが、本来は管理アカウントに必要上のリソースを作成することは推奨されていません。
[パターン1] STEP1. メンバーズ CUR 準備
メンバーズユーザーガイドに沿って Parquet 版メンバーズ CUR を出力します。この環境では4ヶ月分のデータが出力されています。
s3://cm-cur-012345678901/
cur/012345678901/
cid-cur/
20241001-20241101/
cid-cur-Manifest.json
20241101-20241201/
cid-cur-Manifest.json
20241201-20250101/
cid-cur-Manifest.json
20250101-20250201/
cid-cur-Manifest.json
cid-cur/
year=2024/
month=10/
cid-cur-1.snappy.parquet
month=11/
cid-cur-1.snappy.parquet
month=12/
cid-cur-1.snappy.parquet
year=2025/
month=01/
cid-cur-1.snappy.parquet
[パターン1] STEP2. AWS Glue Crawler の実行
AWS Glue Crawler を利用して S3 にあるデータを Athena で分析するために必要なリソースを作成していきます。
参考手順:
Crawler 設定
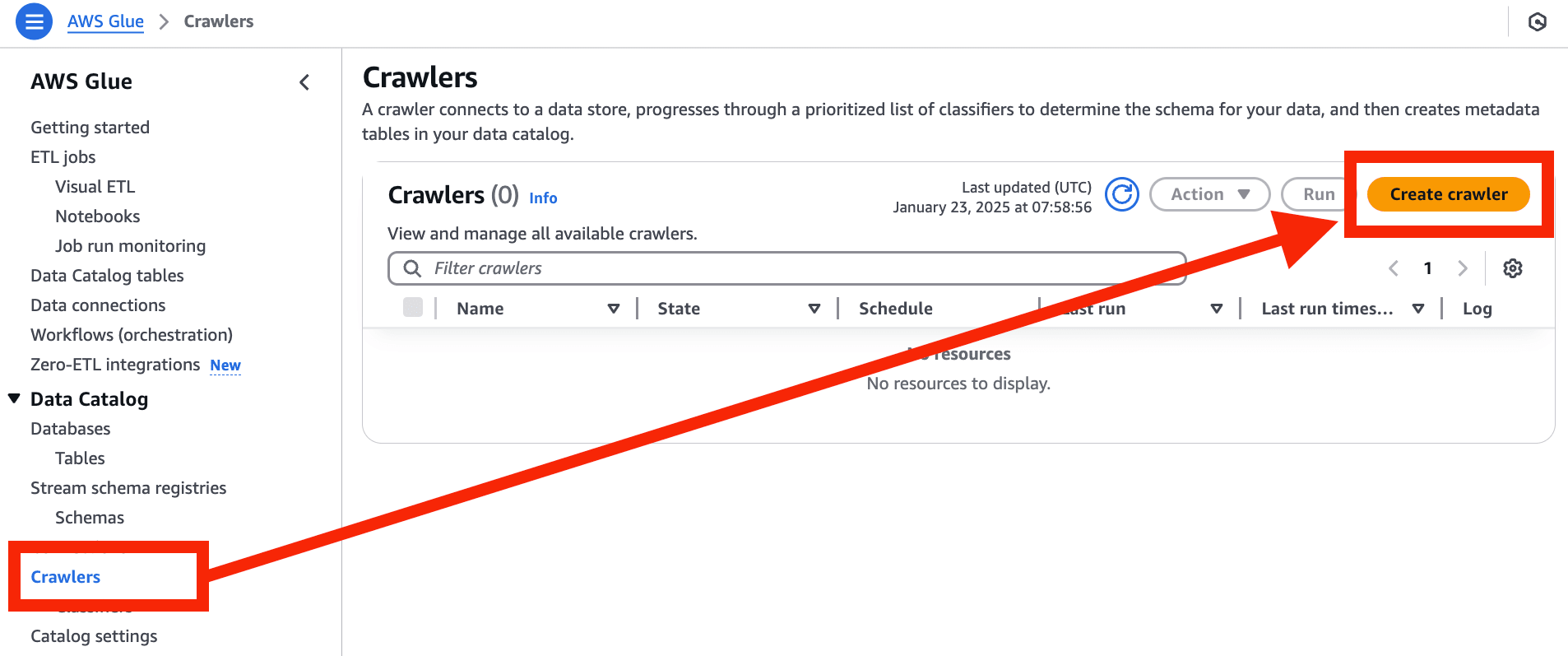
- マネジメントコンソール > AWS Glue > Crawlers > Create crawler を選択
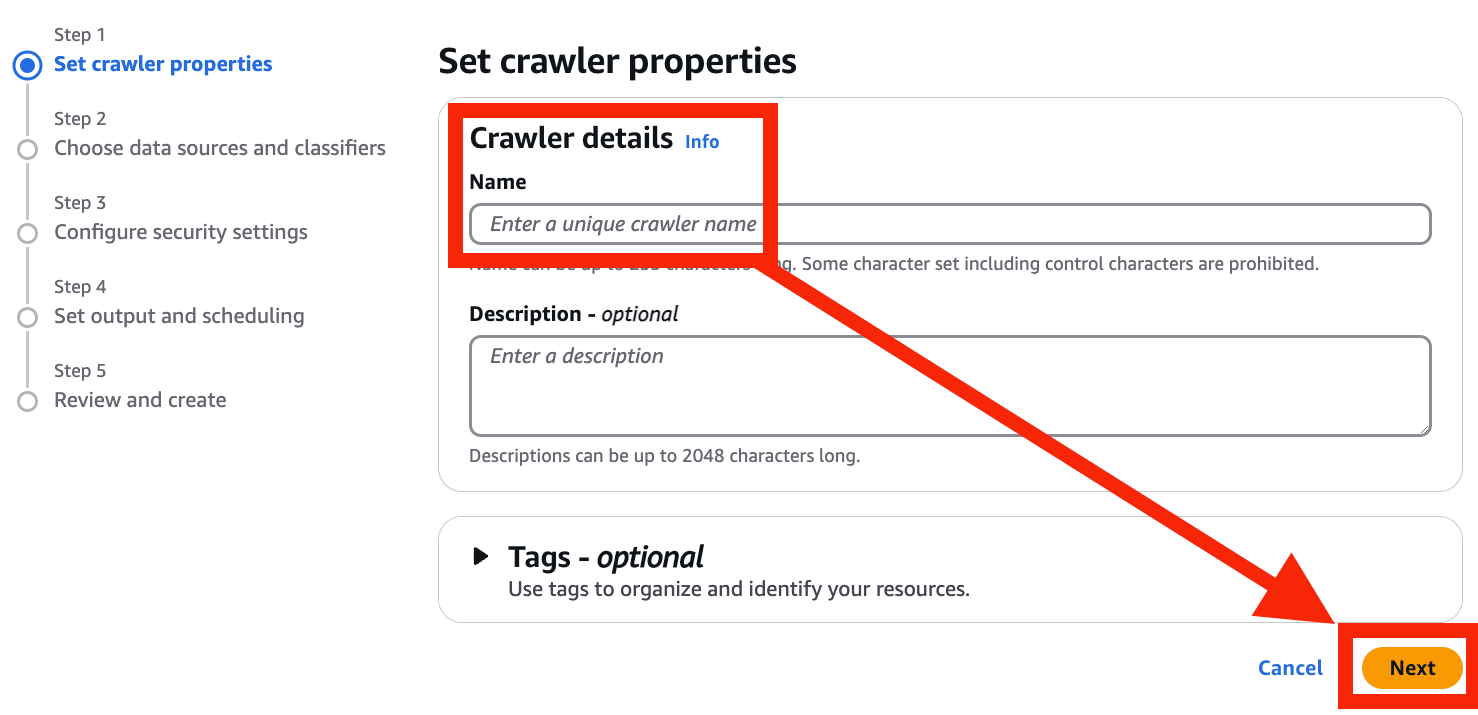
- Name を入力 > Next を選択
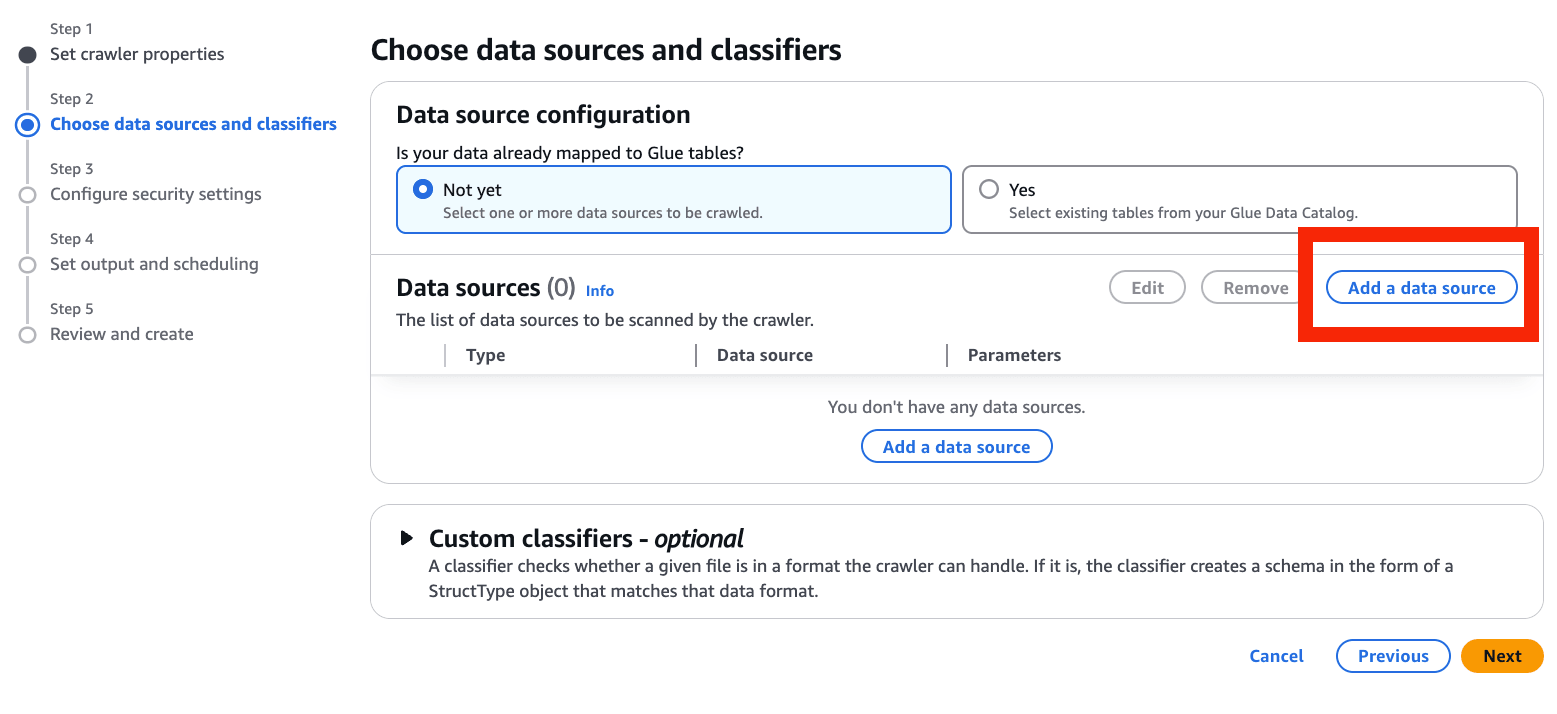
- Add a data source を選択
- Browse S3 を選択
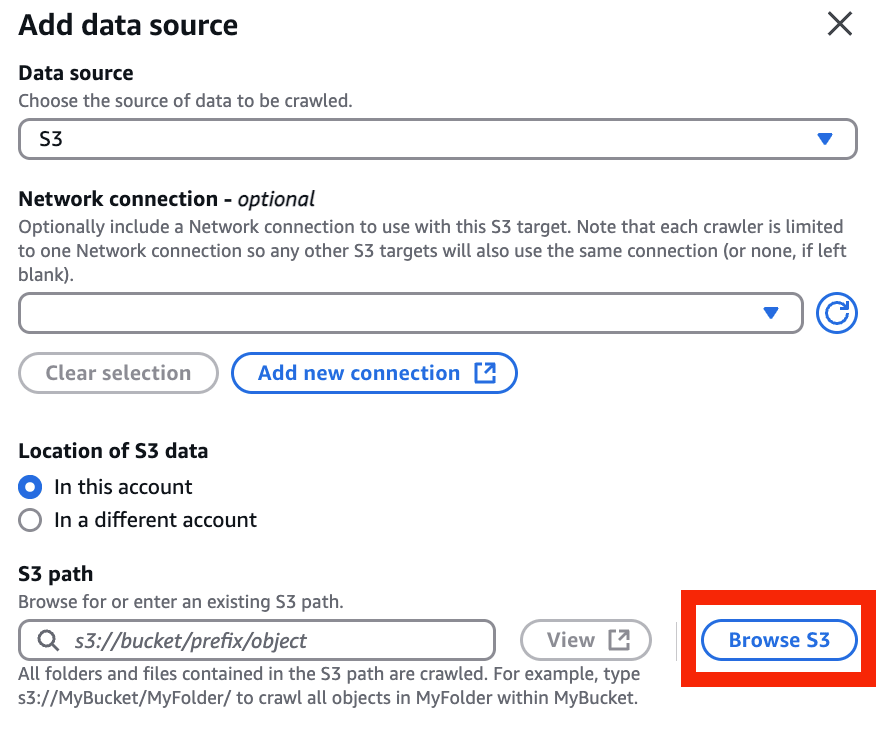
- メンバーズ CUR を出力したバケットの下記パス(上記例だと
s3://cm-cur-012345678901/cur/)を選択 > Choose を選択
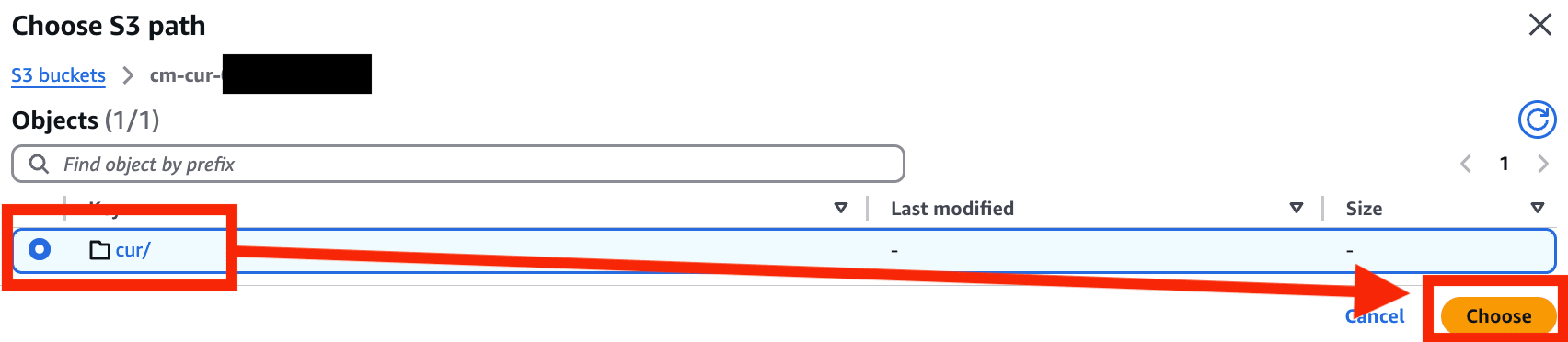
- Crawl new sub-folders only を選択
(今回のケースでは毎回全てをクロールする必要がないため変更)
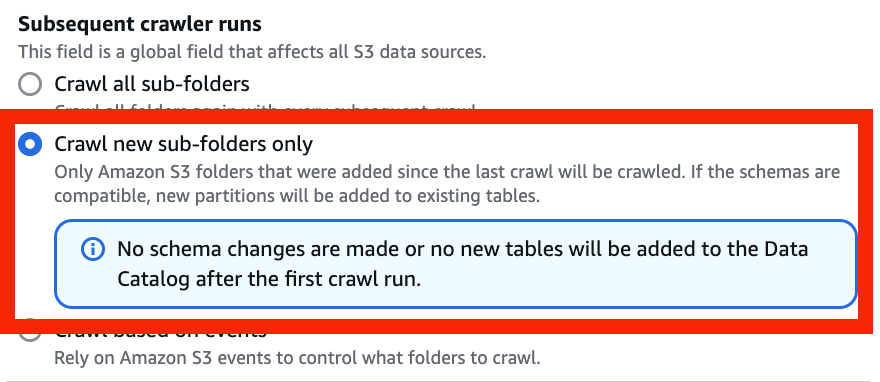
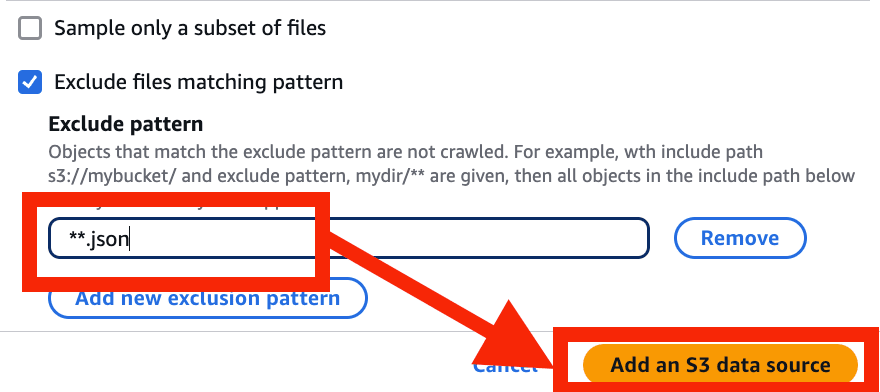
- Exclude files matching pattern にチェック > Add new exclusion pattern を選択
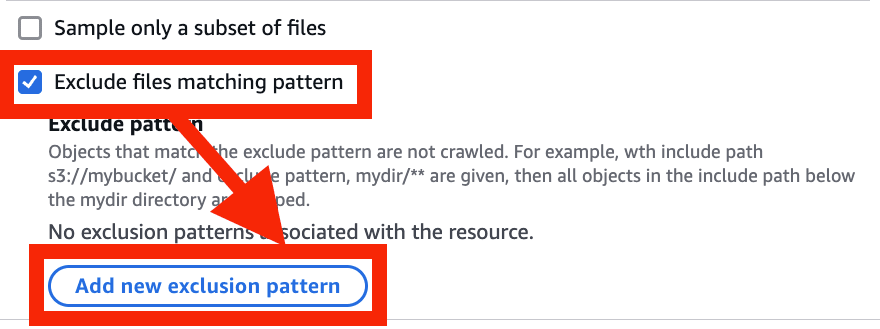
**.jsonと入力 > Add an S3 data source を選択
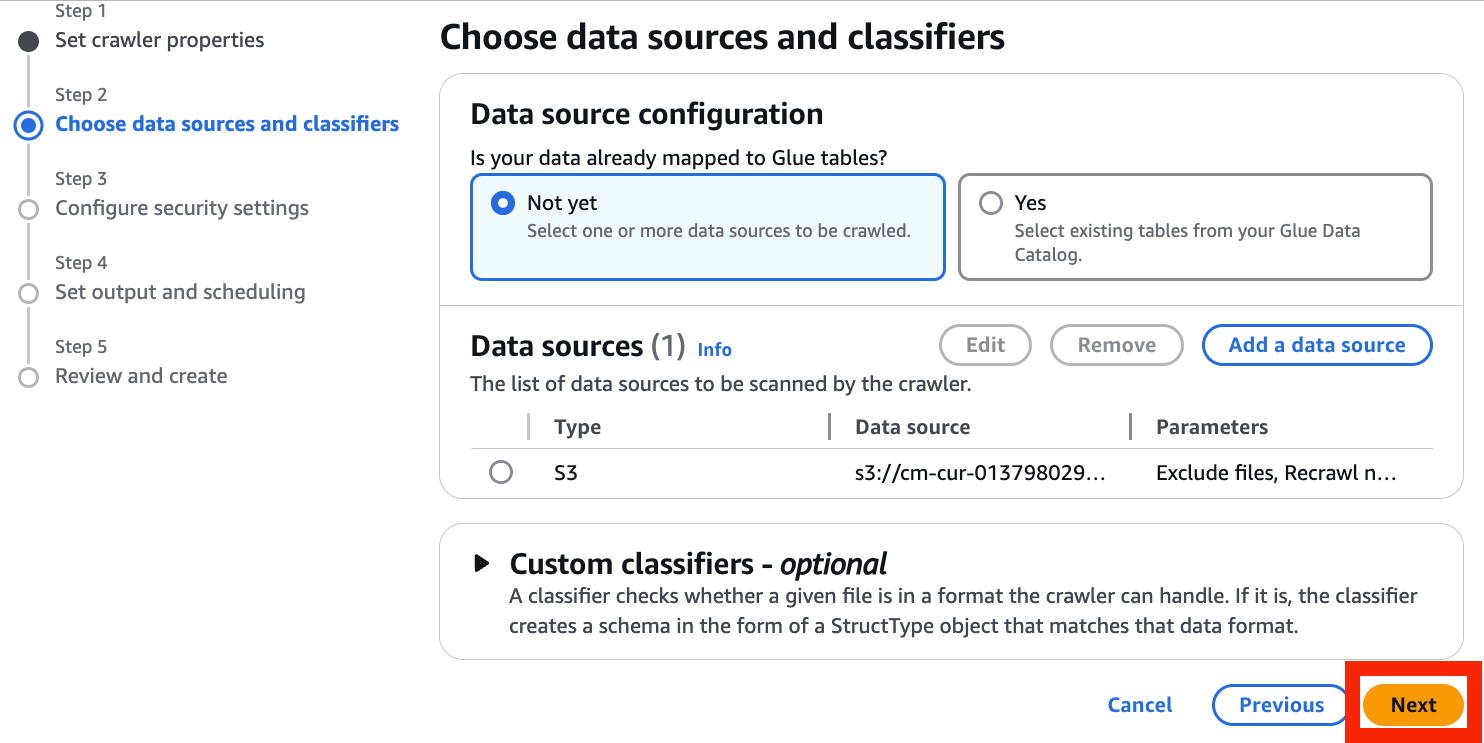
- Next を選択
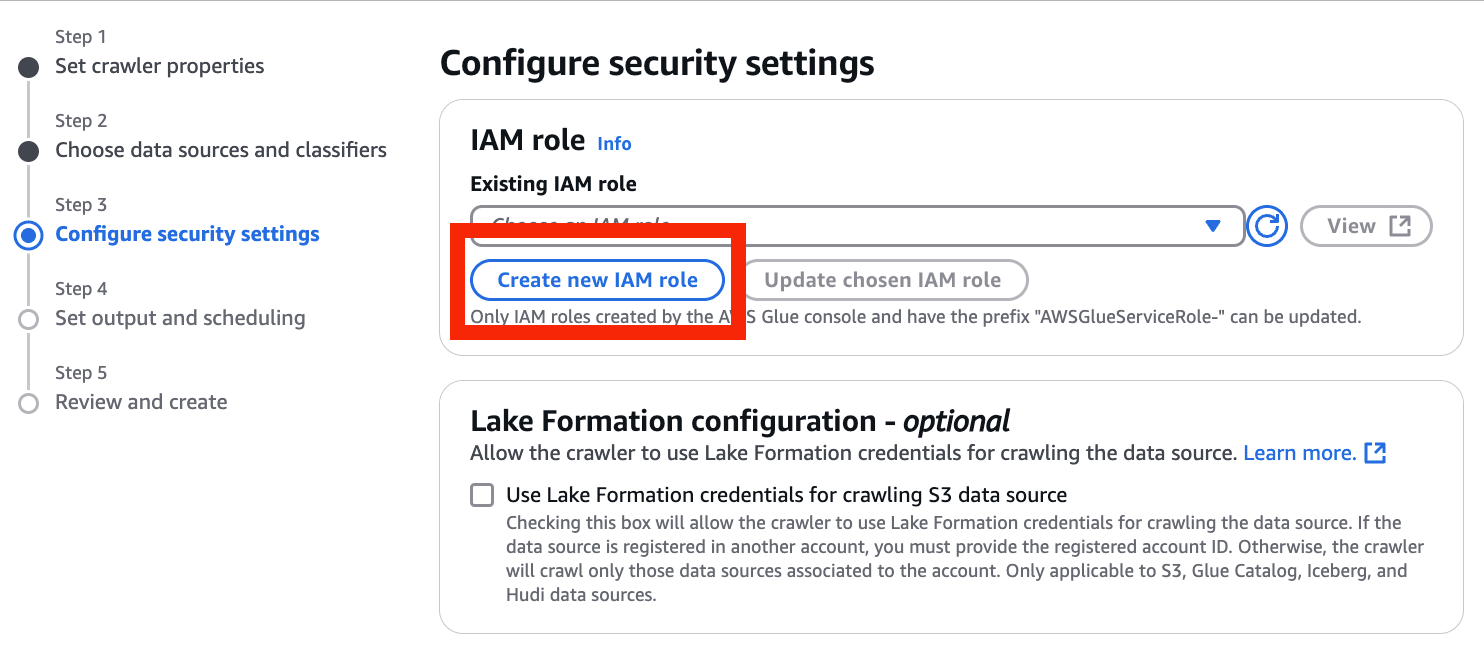
- Create new IAM role を選択
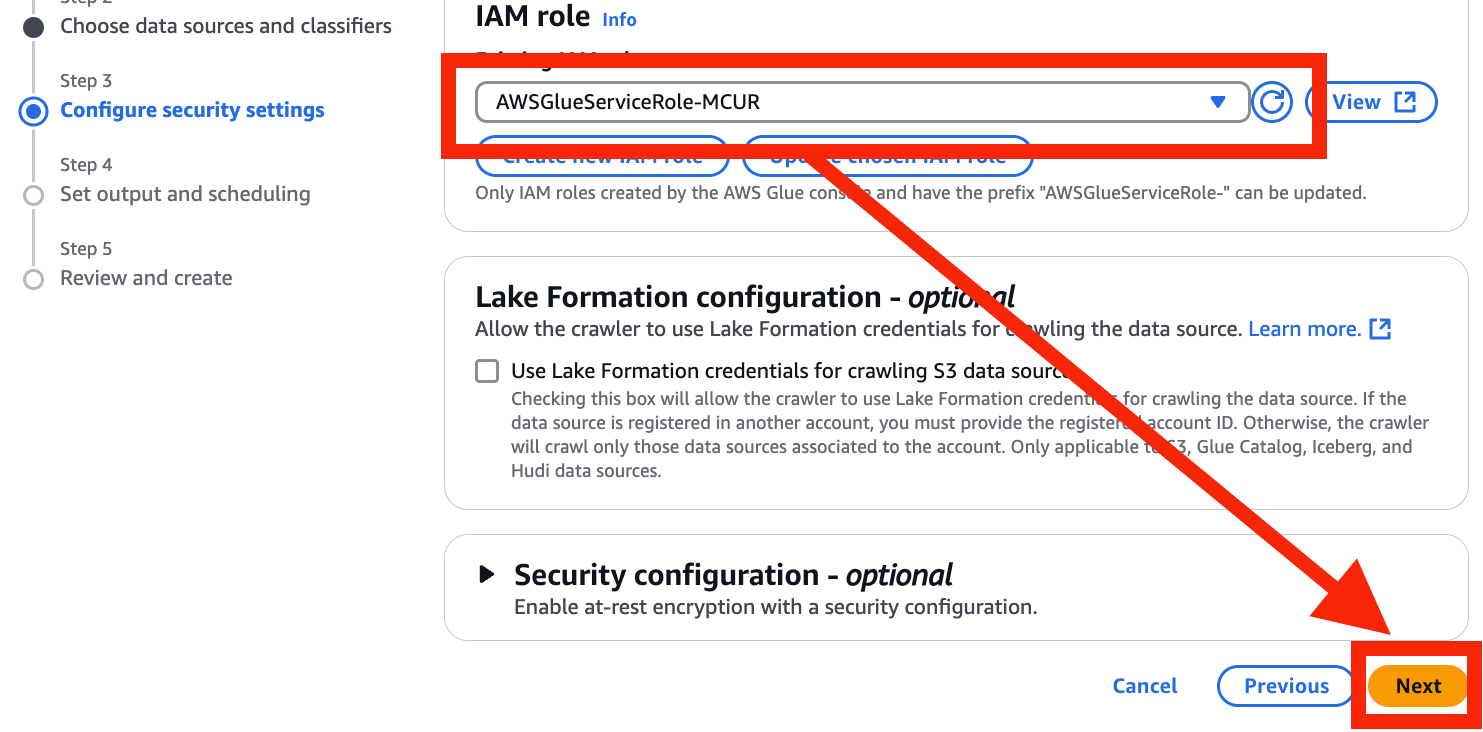
- Enter new IAM role を入力 > Create を選択

- Existing IAM role を更新 > 作成した IAM role を選択 > Next を選択
- Add database を選択
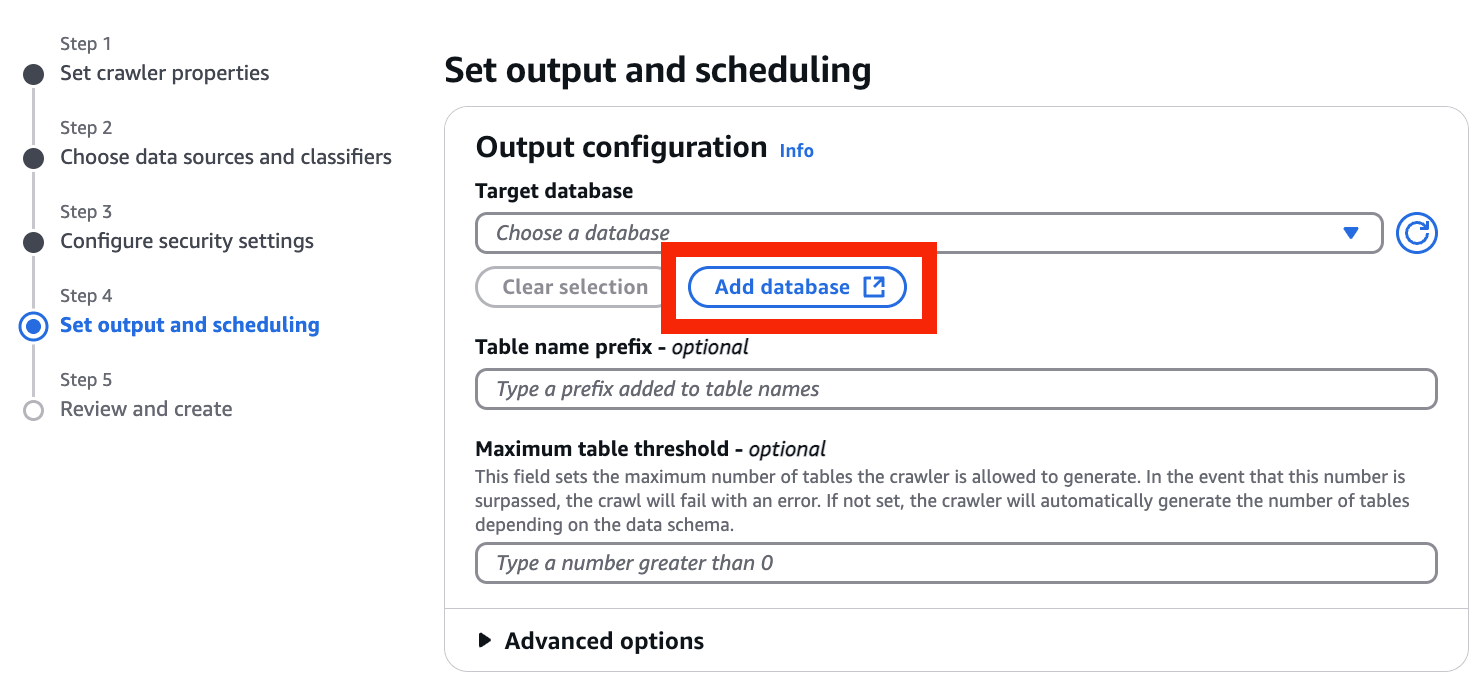
- Name を入力 > Create database を選択
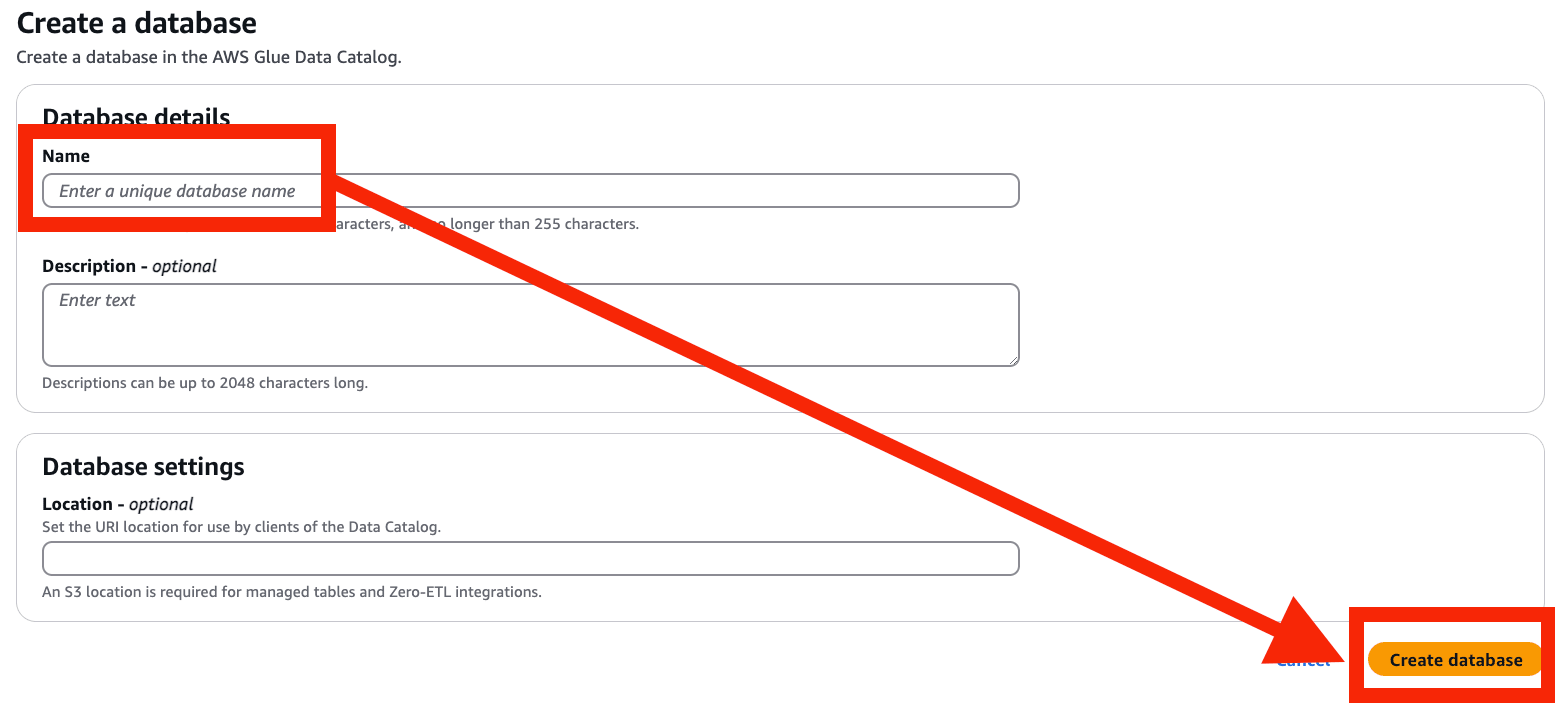
- database が作成できました!

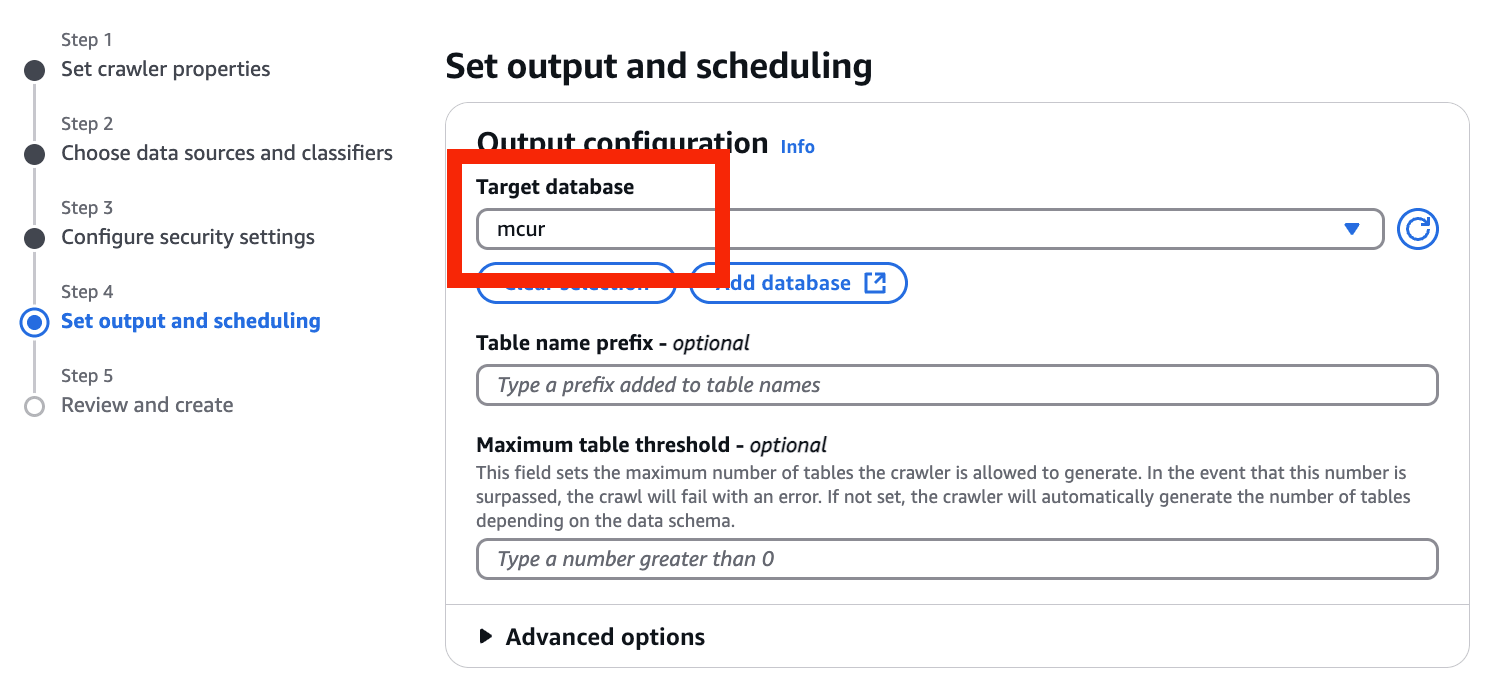
- Target database を更新 > 作成した database を選択
- Frequency を Daily、Start time を 00:00 > Next を選択
(一時的な利用であれば On Demand のままでも OK)
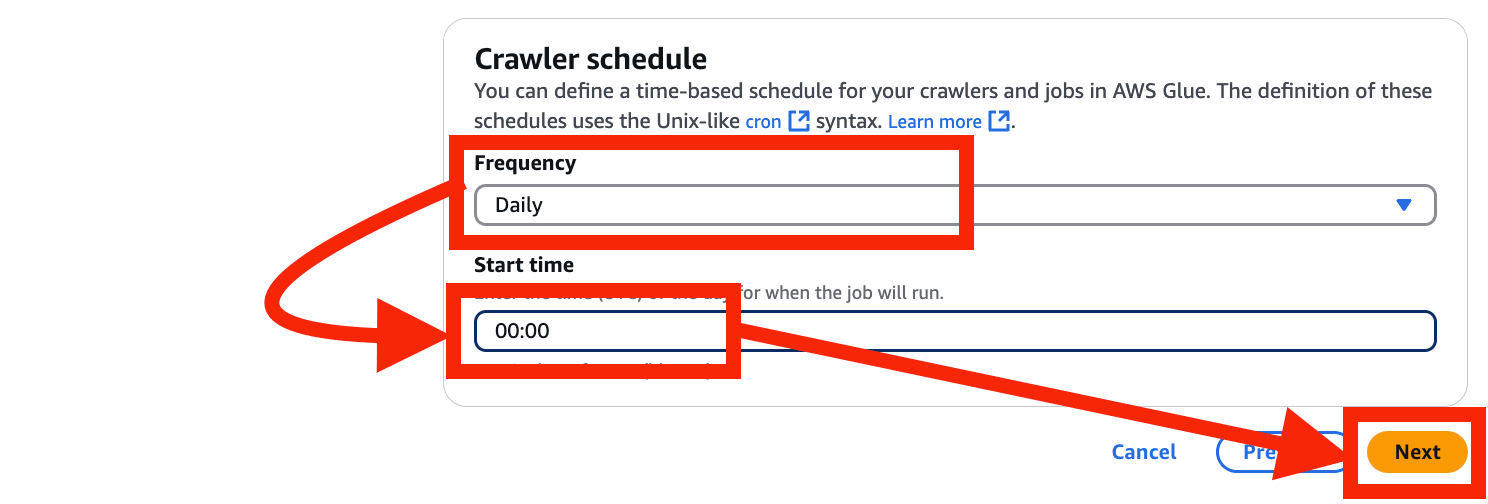
- Create crawler を選択
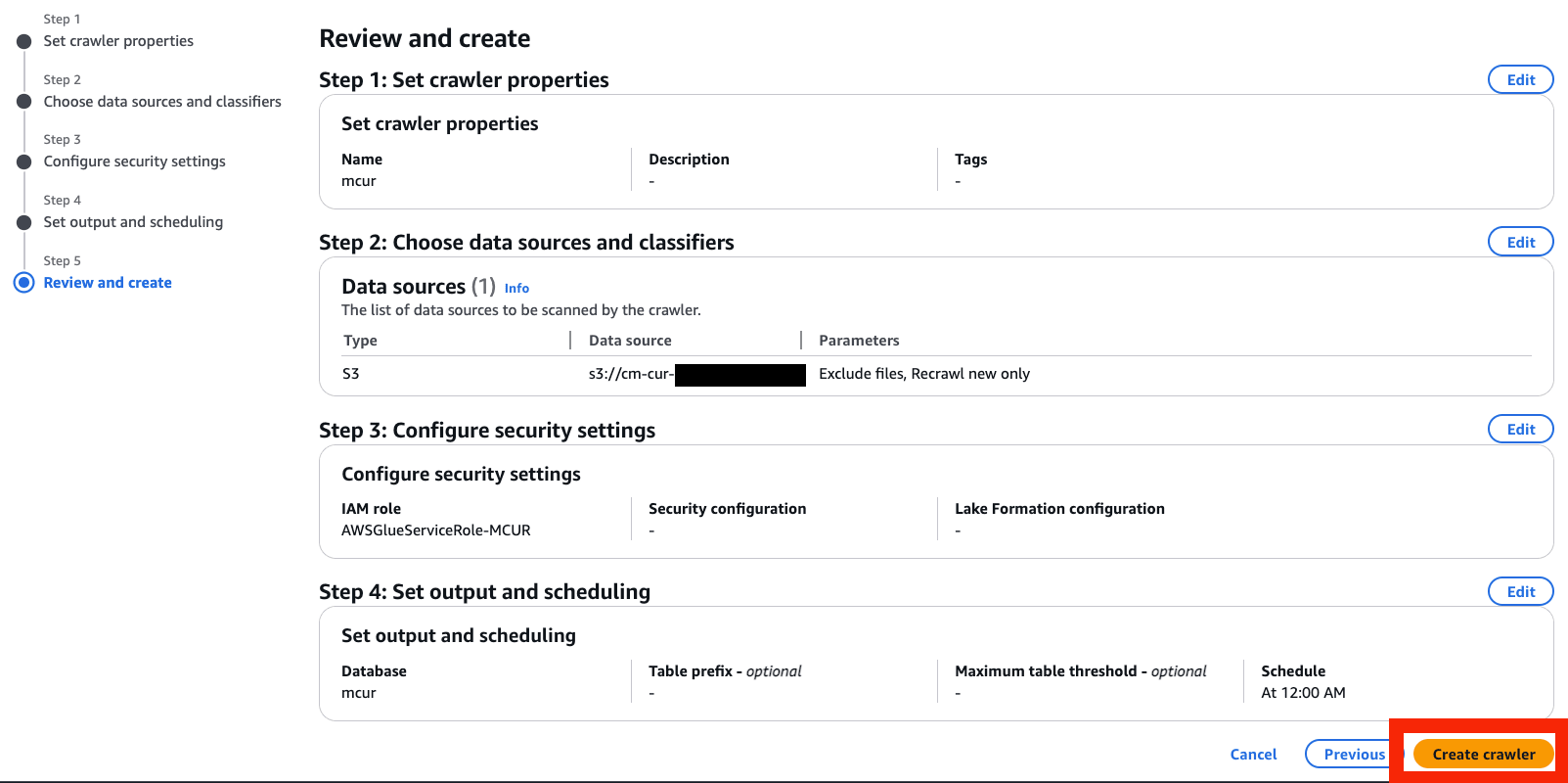
- Run crawler を選択
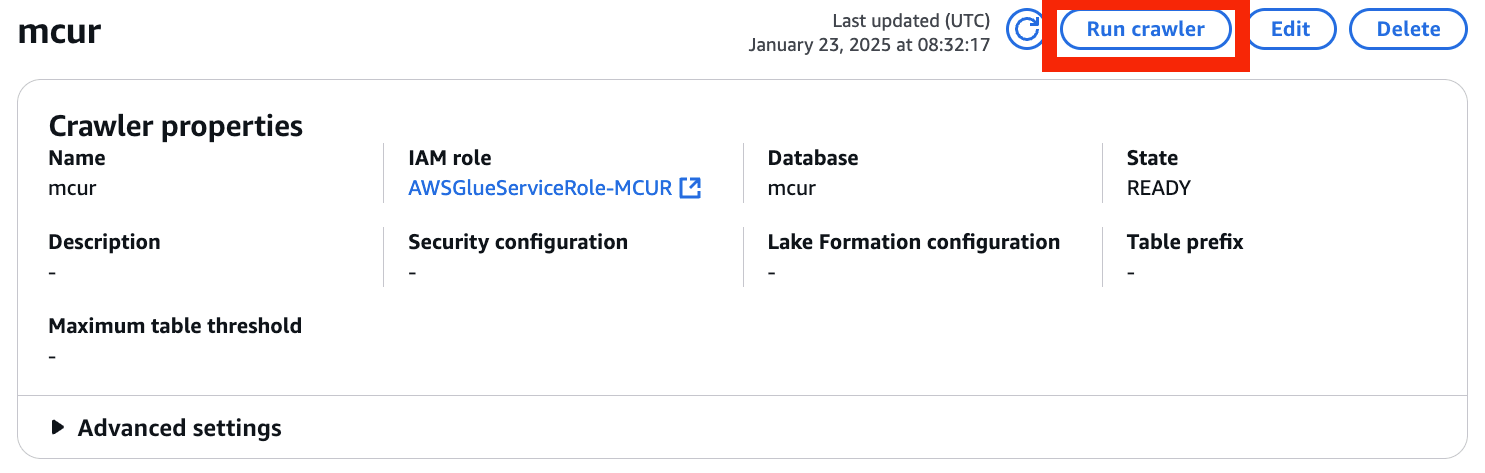
- Status が Completed になっていれば OKです!
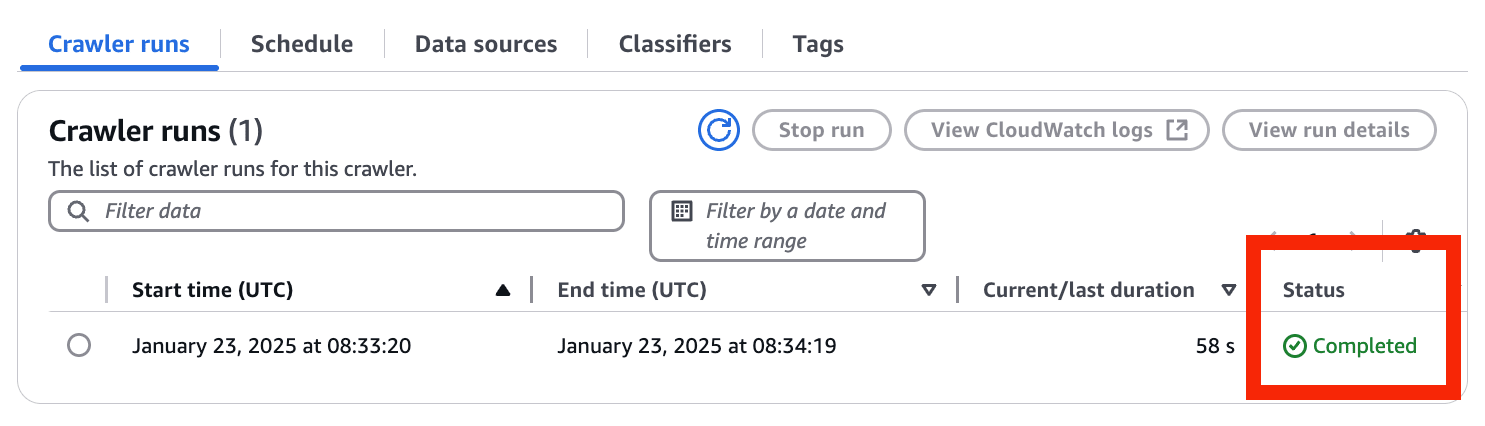
結果
それぞれリソースが作成されていることを確認します。
- AWS Glue > Databases > mcur(作成した Database 名) を選択
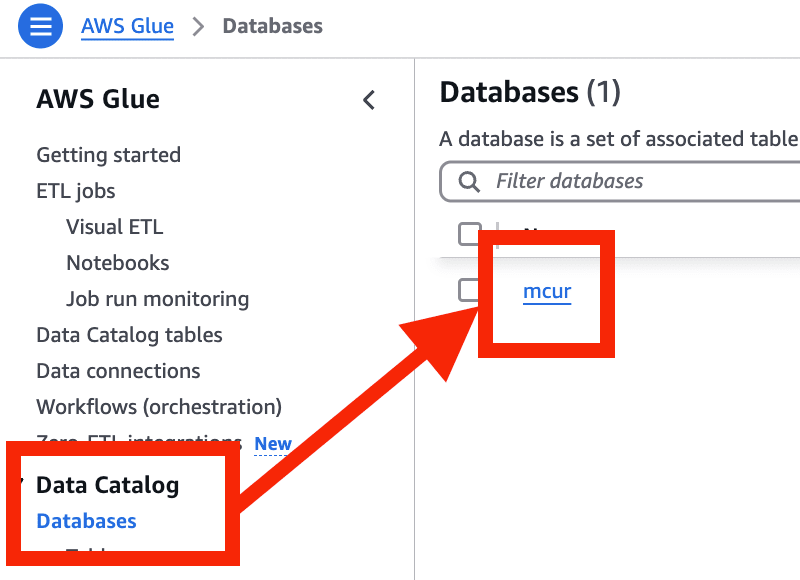
- cur を選択
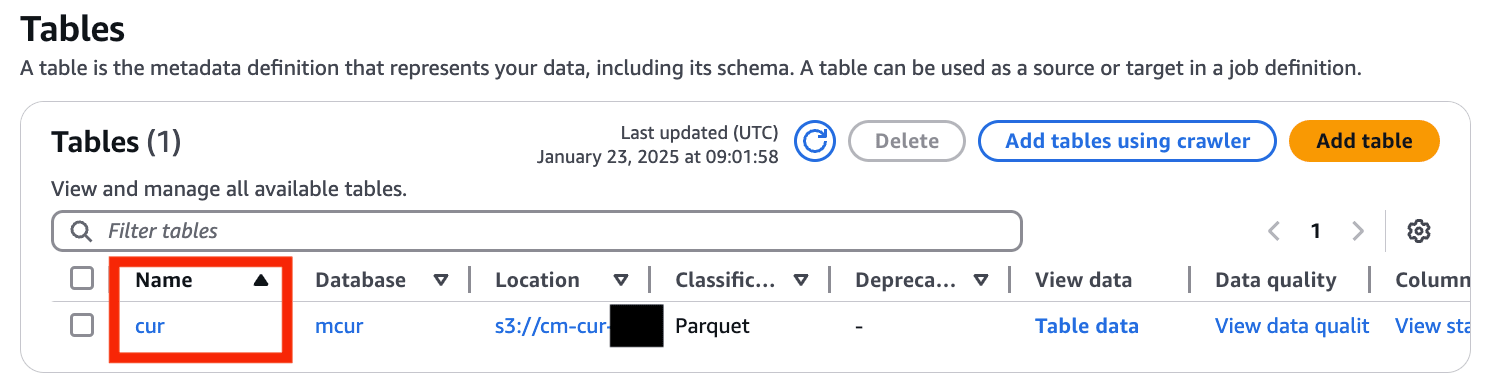
- 正常にリソースが作成されています!
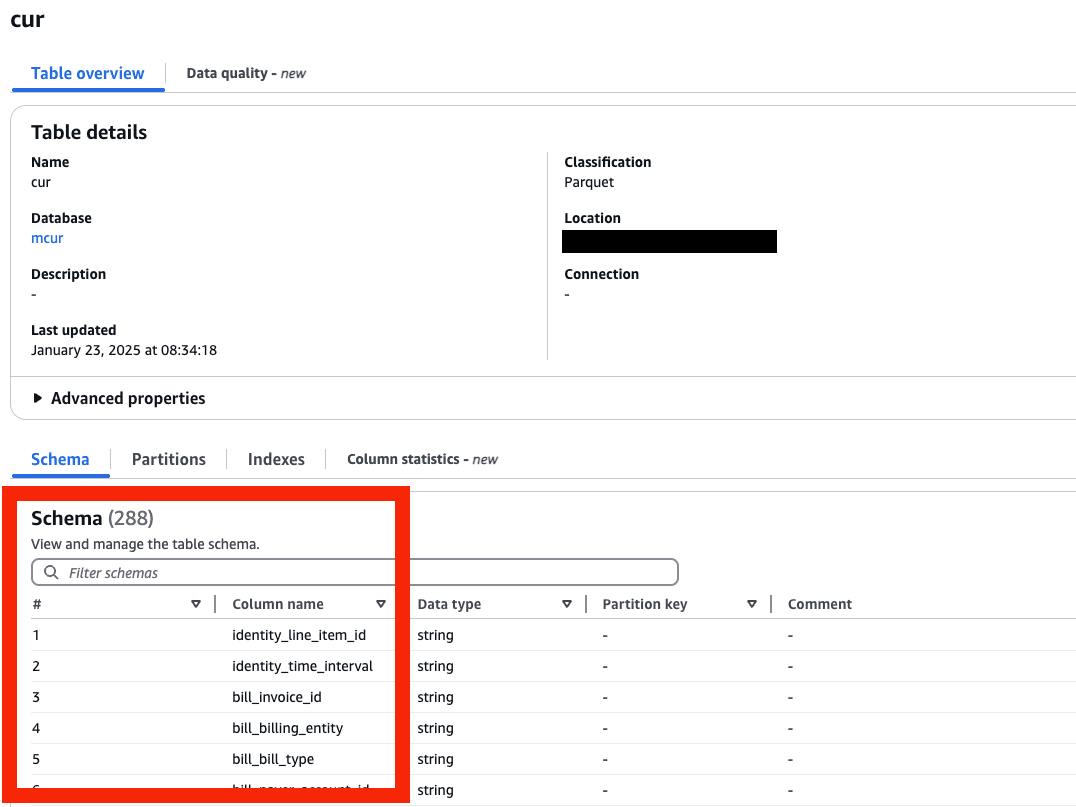
[パターン1] STEP3. Athena で確認
- マネジメントコンソール > Amazon Athena > クエリエディタ を選択
- データソースに AWSDataCatalog、データベースは 作成したデータベース を選択
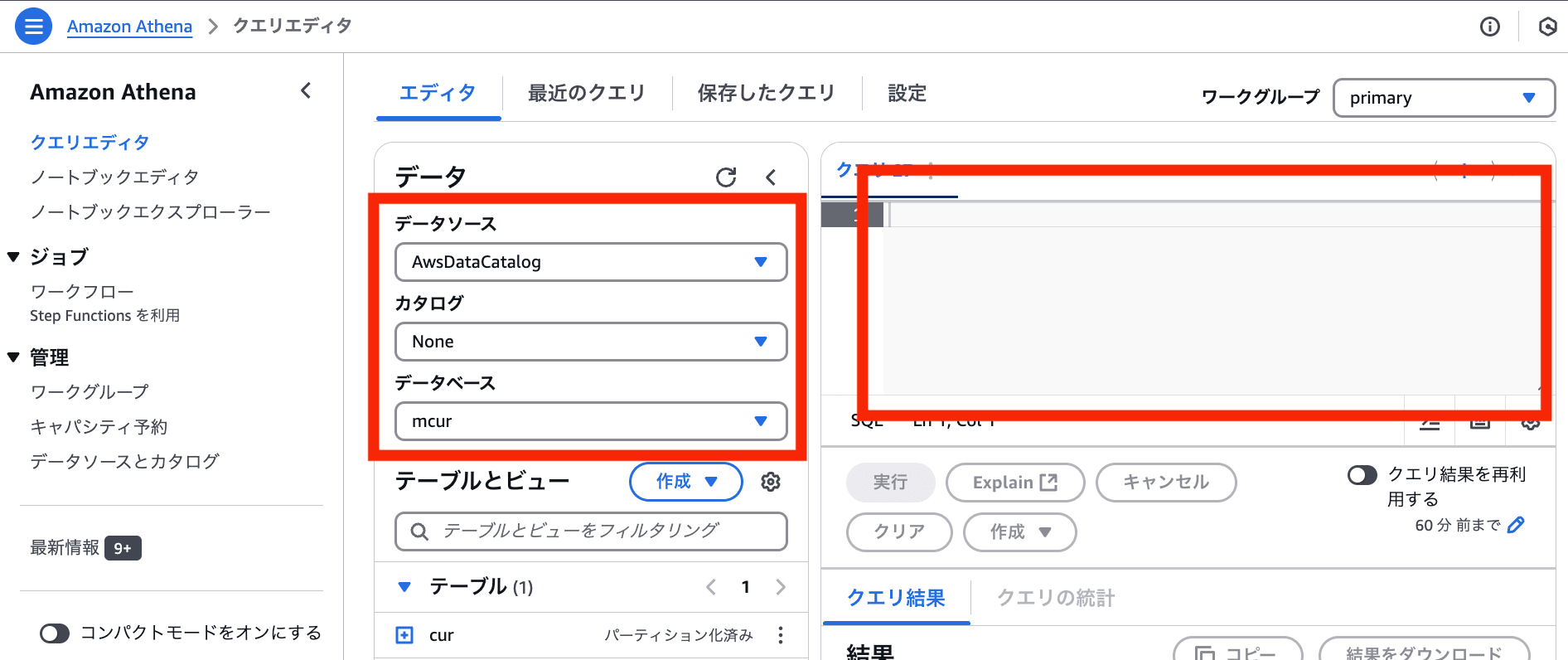
Athena を開いて環境準備が完了したことを確認するため、いくつかのクエリを実行してみます。
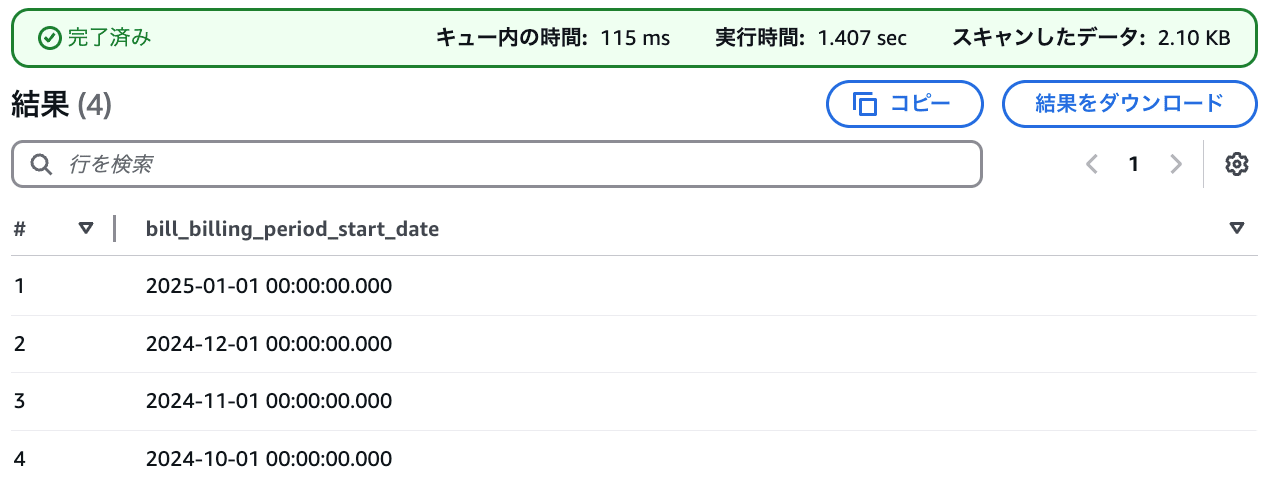
対象データの請求期間を確認
SELECT
distinct bill_billing_period_start_date
FROM
mcur.cur
ORDER BY
bill_billing_period_start_date desc;
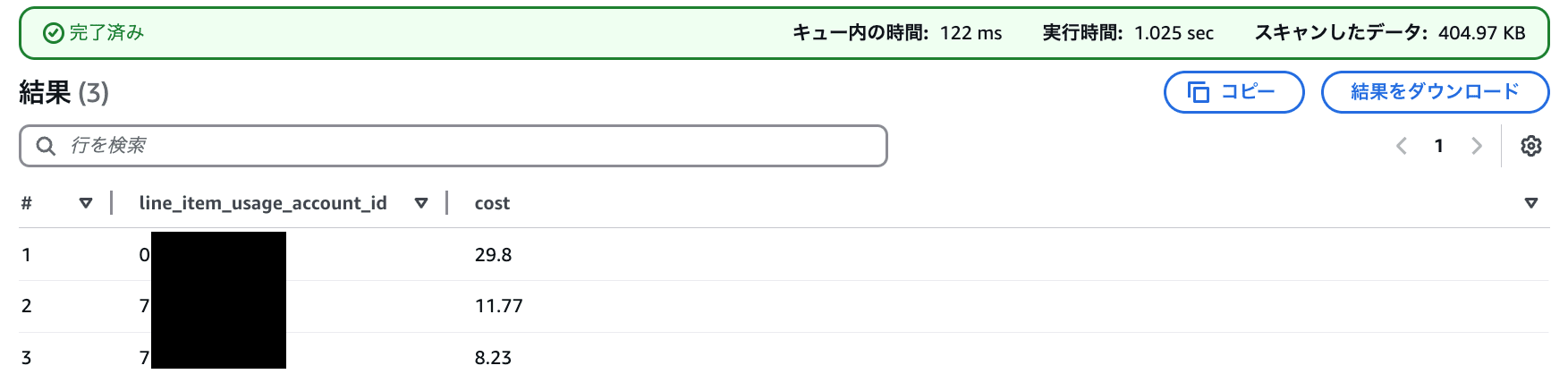
アカウント別利用費
SELECT
line_item_usage_account_id, round(sum("line_item_unblended_cost"),2) as cost
FROM
mcur.cur
WHERE
year = '2024' AND month = '10'
GROUP BY
line_item_usage_account_id
ORDER BY
cost desc;
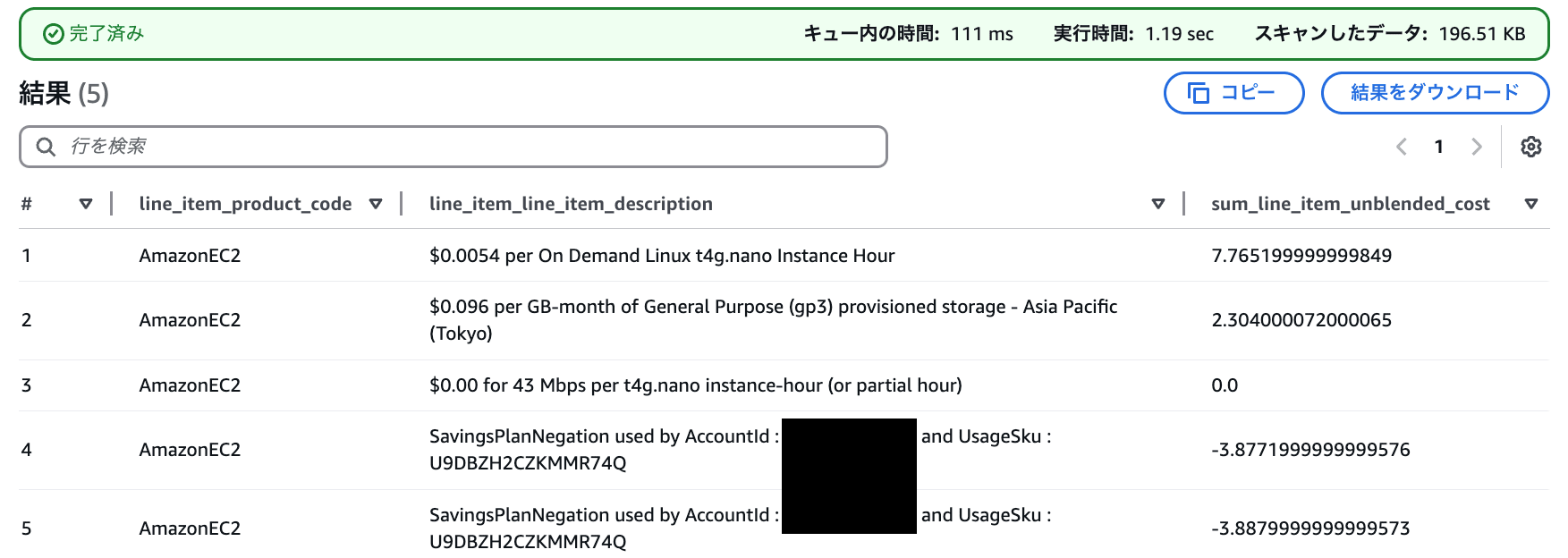
Amazon EC2 利用費
SELECT
line_item_product_code,
line_item_line_item_description,
SUM(line_item_unblended_cost) AS sum_line_item_unblended_cost
FROM
mcur.cur
WHERE
year = '2024' AND month = '11'
AND line_item_product_code = 'AmazonEC2'
AND line_item_line_item_type NOT IN ('Tax','Refund','Credit')
GROUP BY
line_item_product_code,
line_item_line_item_description
ORDER BY
sum_line_item_unblended_cost DESC;
Savings Plan 利用状況
SELECT
bill_payer_account_id,
bill_billing_period_start_date,
line_item_usage_account_id,
savings_plan_savings_plan_a_r_n,
line_item_product_code,
line_item_usage_type,
sum(line_item_usage_amount) as Usage,
line_item_line_item_description,
pricing_public_on_demand_rate,
sum(pricing_public_on_demand_cost) as PublicCost,
savings_plan_savings_plan_rate,
sum(savings_plan_savings_plan_effective_cost) as SavingsPlanCost
FROM
mcur.cur
WHERE
line_item_line_item_Type like 'SavingsPlanCoveredUsage' AND year = '2025' AND month = '1'
GROUP BY
bill_payer_account_id,
bill_billing_period_start_date,
line_item_usage_account_id,
savings_plan_savings_plan_a_r_n,
line_item_product_code,
line_item_usage_type,
line_item_unblended_rate,
line_item_line_item_description,
pricing_public_on_demand_rate,
savings_plan_savings_plan_rate;

複数の CUR を集約するパターン
こちらのパターンでは組織に関係なく、特定アカウントでの各自の CUR を一つの S3 へ集約して、Athena で分析する環境を想定して構築しています。
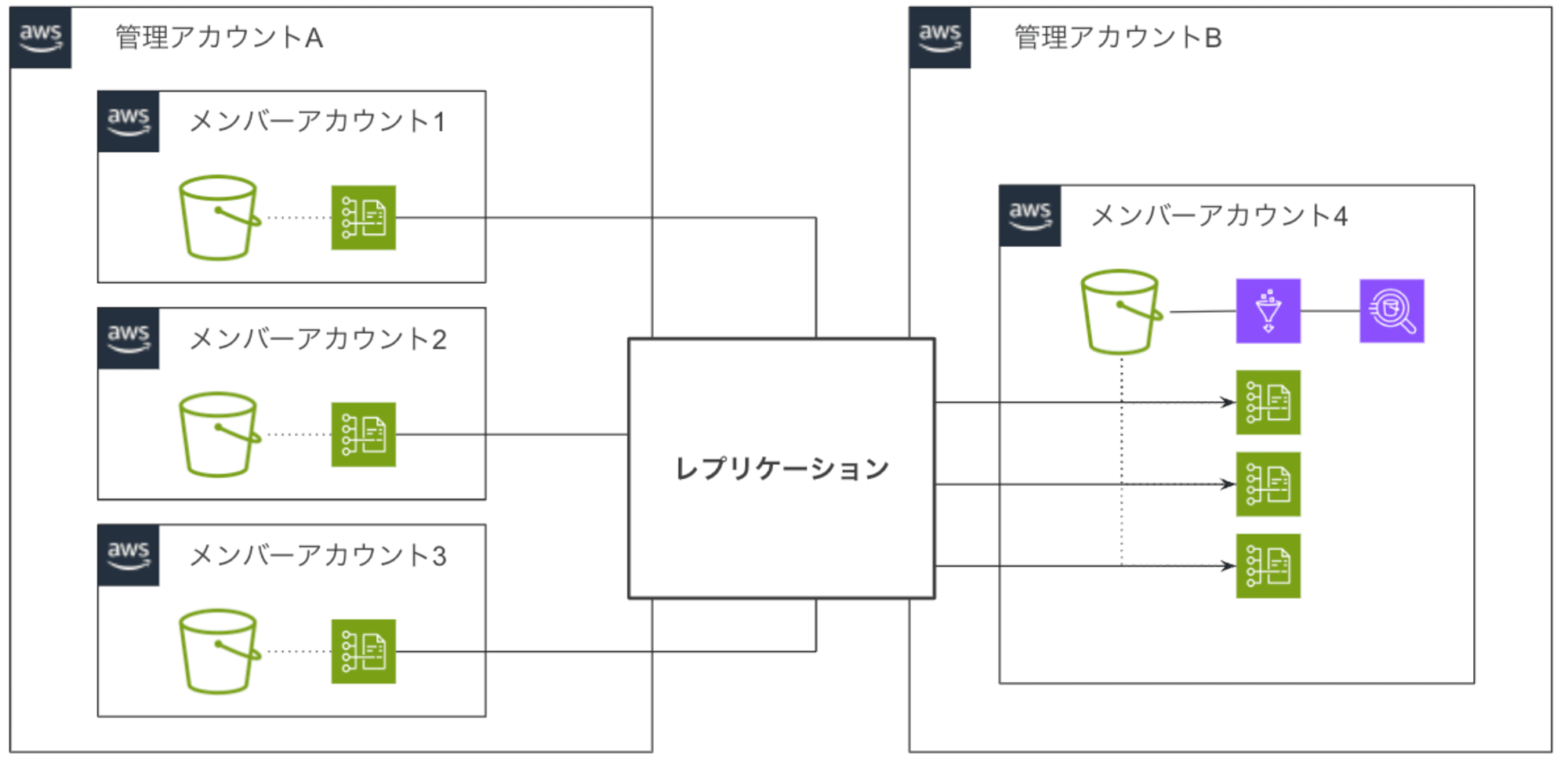
[パターン2] STEP1. メンバーズ CUR 準備
各アカウントで「単一の CUR を利用するパターン」と同様の手順で進めます。
[パターン2] STEP2. 集約先へのレプリケーション
クロスアカウントでのレプリケーション設定方法は下記ブログ記事を参考に進めます。
レプリケーション元
レプリケーション元バケットに4つ設定を追加します(既に設定がある項目は不要)
-
バージョニングを有効化
プロパティ > バケットのバージョニング > 編集 を選択
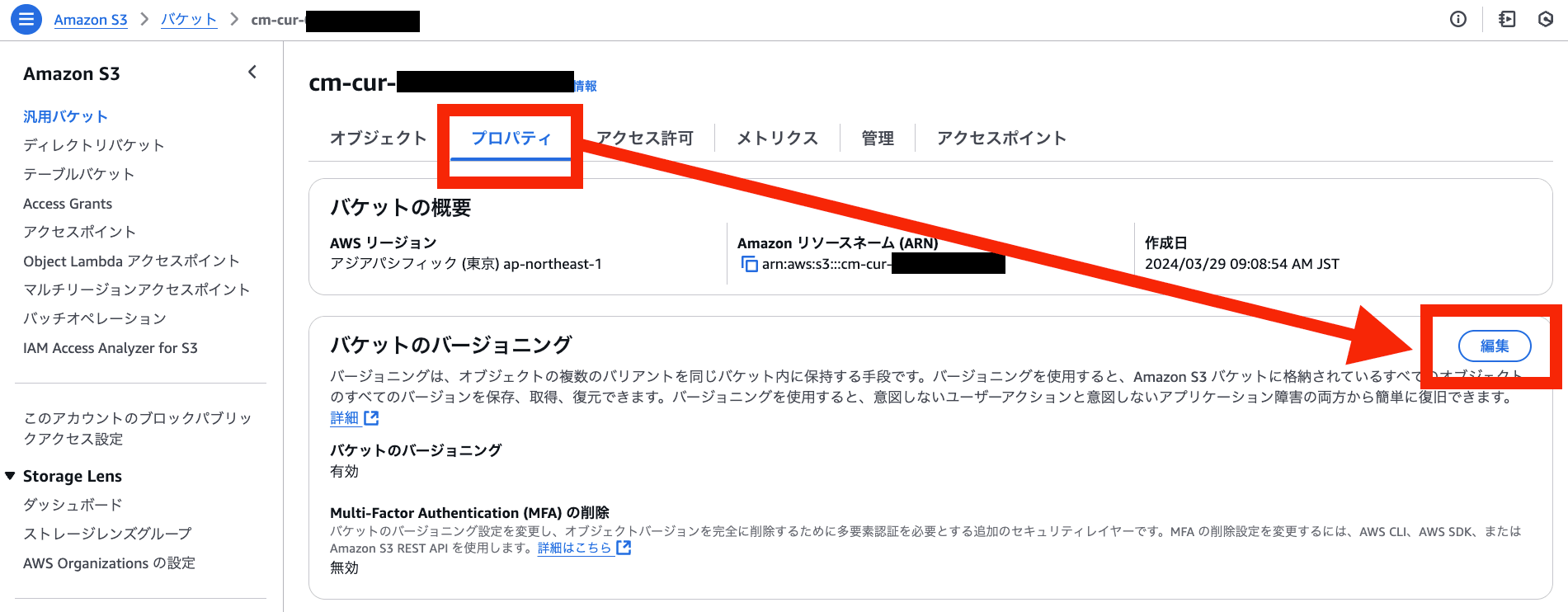
有効にする > 変更の保存 を選択

-
パブリックアクセスブロック有効化
アクセス許可 > ブロックパブリックアクセス (バケット設定) > 編集 を選択
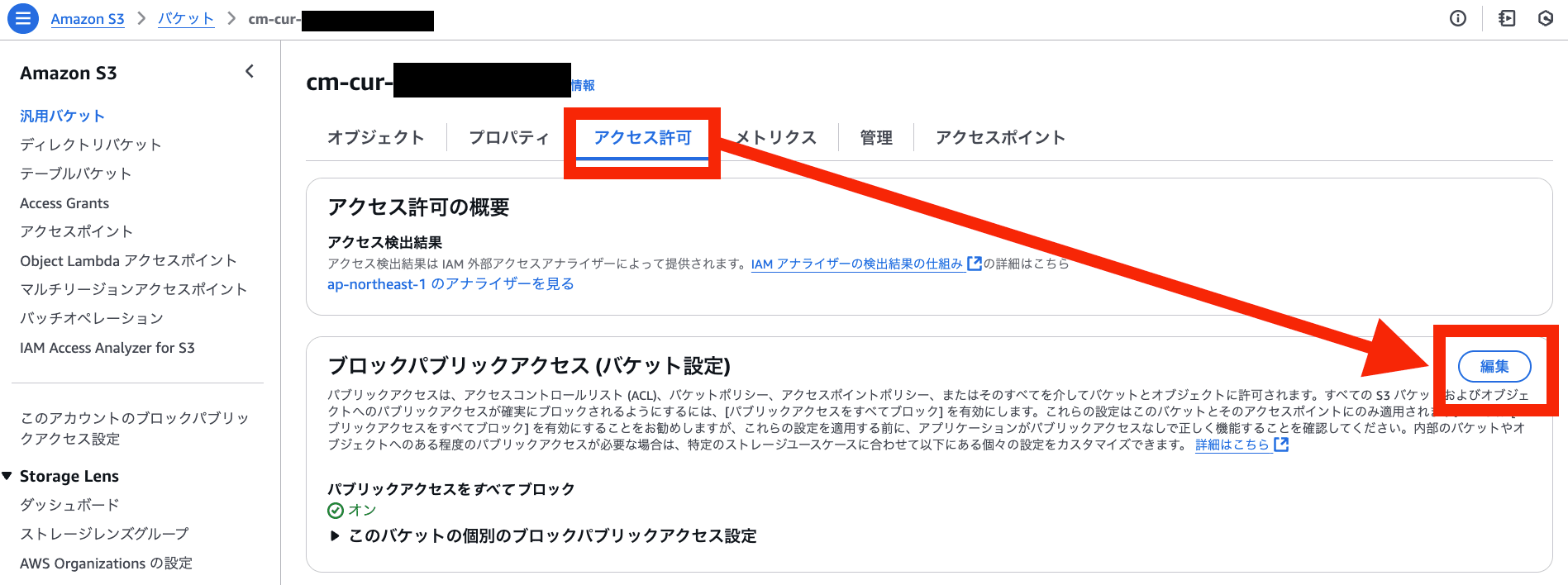
パブリックアクセスをすべて ブロック を有効化 > 変更の保存 を選択
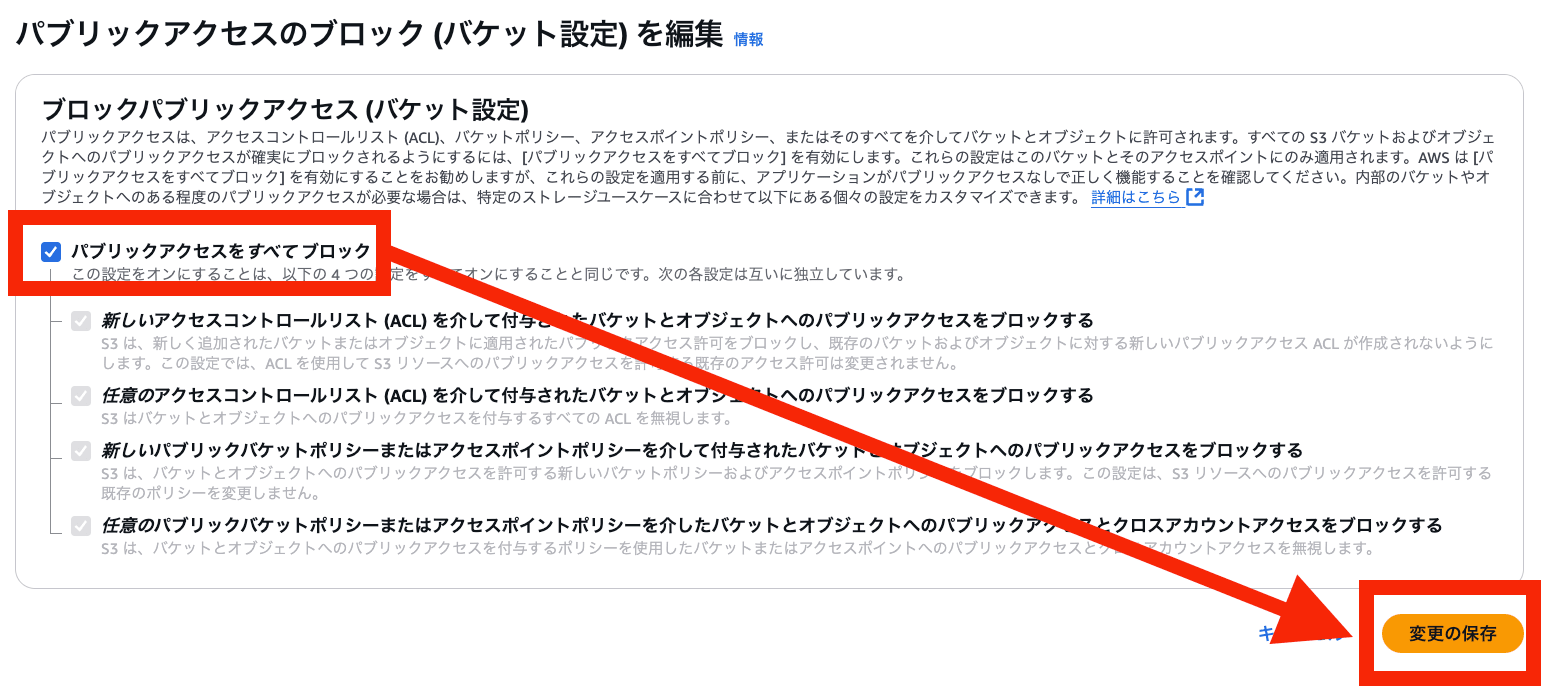
「確認」 を入力 > 確認 を選択

-
ライフサイクルルール設定
管理 > ライフサイクルルールを作成する を選択
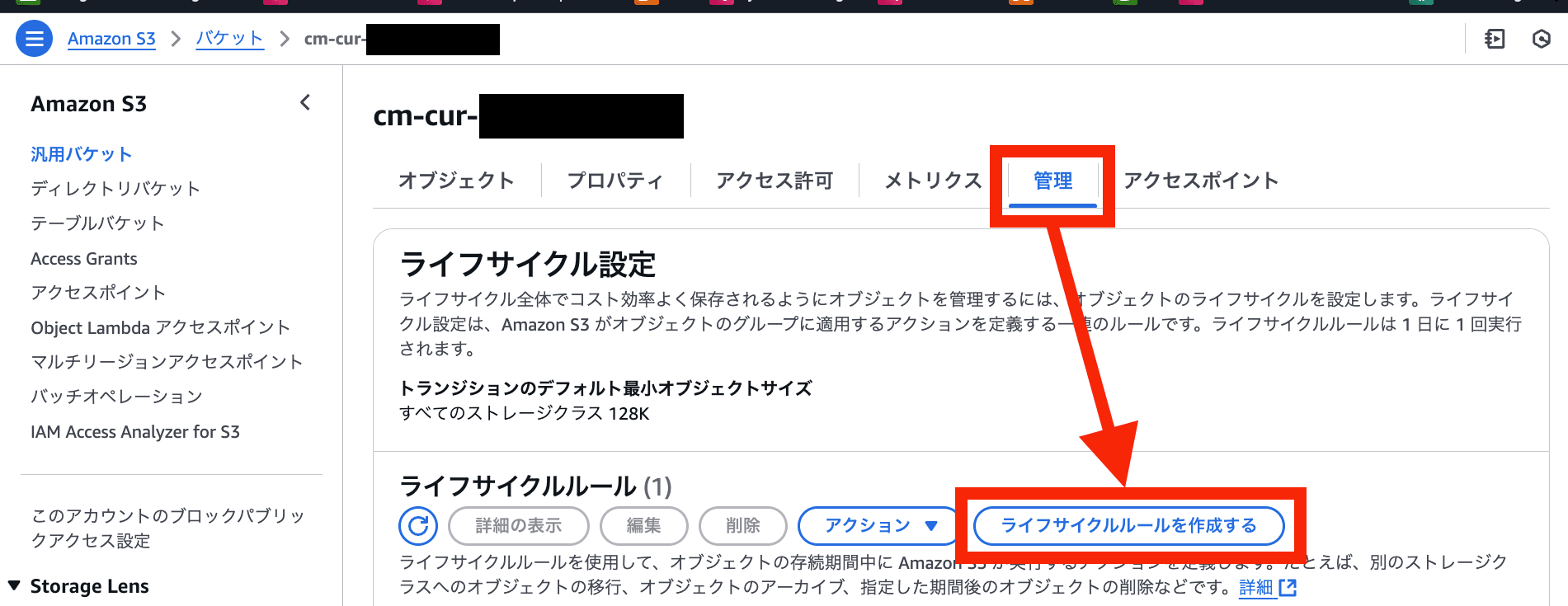
各項目を入力&選択 > ルールの作成 を選択
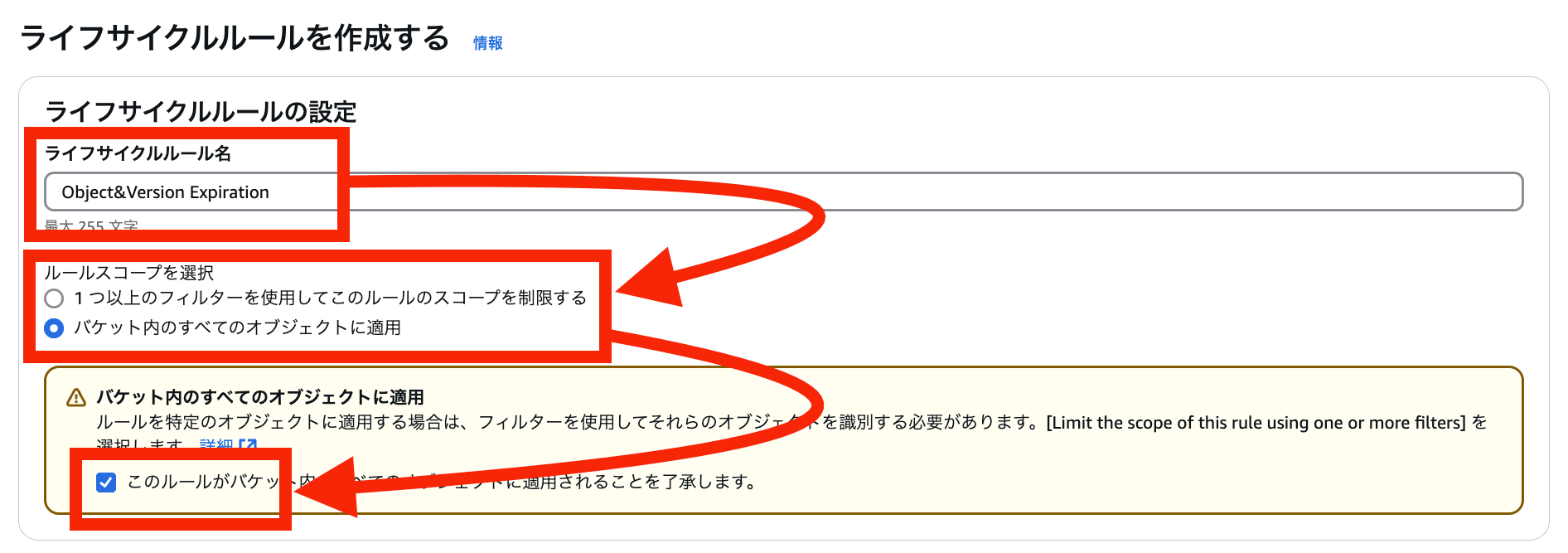



-
レプリケーション設定追加
管理 > レプリケーションルール > レプリケーションルールを作成 > 前述のブログ記事を参考に設定 > 保存 を選択
レプリケーション(集約)先
レプリケーション先バケットでは4つ設定を追加します(既に設定がある項目は不要)
- バージョニングを有効化(レプリケーション元と同じ手順)
- ライフサイクルルール設定(〃)
- パブリックアクセスブロック有効化(〃)
- バケットポリシー
アクセス許可 > バケットポリシー > 編集 > 前述のブログ記事を参考に記載 > 変更の保存
※ 既存でポリシーがある場合は、既存ポリシーへ追加する形で追記
{
"Version": "2008-10-17",
"Statement": [
{ ** 既存ポリシー **
},
{
"Sid": "1",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::111111111111:role/cur-parquet-replication",
"arn:aws:iam::222222222222:role/cur-parquet-replication",
"arn:aws:iam::333333333333:role/cur-parquet-replication"
]
},
"Action": [
"s3:ReplicateDelete",
"s3:ReplicateObject",
"s3:ReplicateTags",
"s3:ObjectOwnerOverrideToBucketOwner"
],
"Resource": "arn:aws:s3:::cm-cur-999999999999/*"
}
]
}
[パターン2] STEP3. Glue Crawler の実行
「単一の CUR を利用するパターン」と同様の手順で進めます
[パターン2] STEP4. Athena で確認
環境準備が完了したことを確認するため、いくつかのクエリを実行してみます。
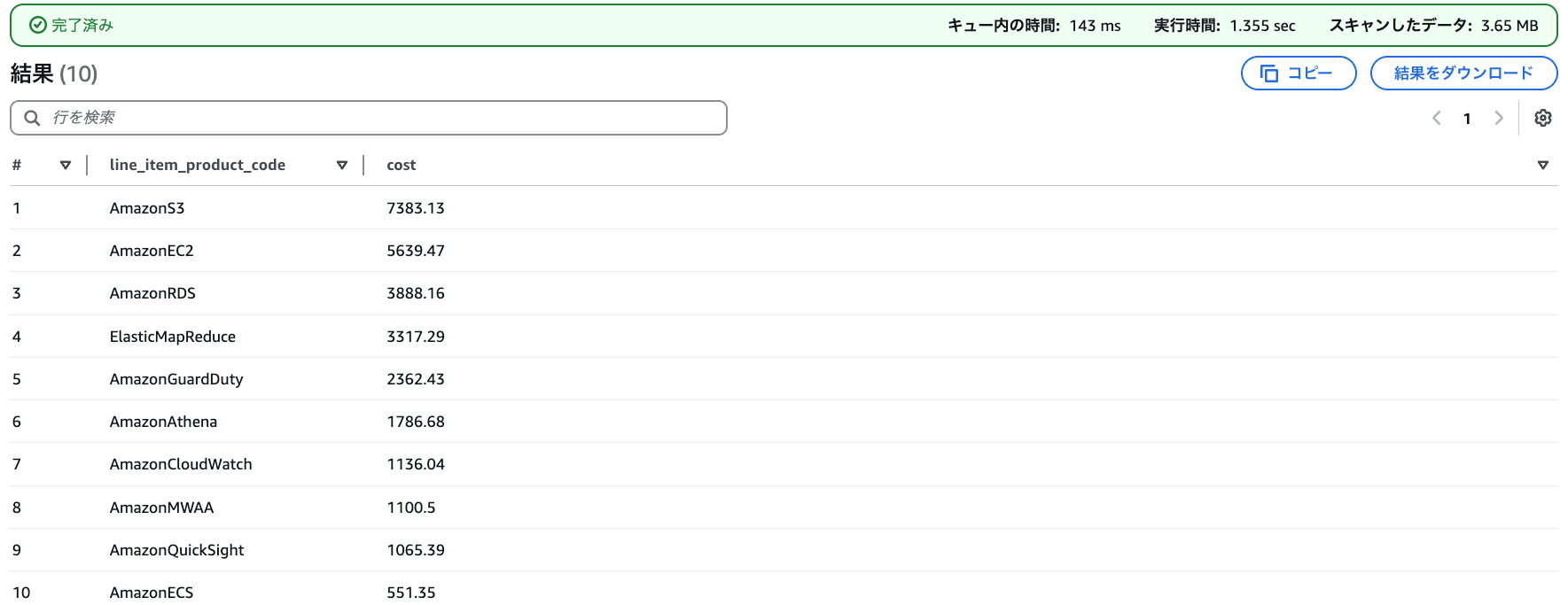
AWS サービス別の利用費(TOP10)
SELECT
line_item_product_code,
round(sum("line_item_unblended_cost"),2) as cost FROM
mcur.cur
WHERE
year = '2024' AND month = '12'
GROUP BY
line_item_product_code
ORDER BY
cost desc
LIMIT 10;
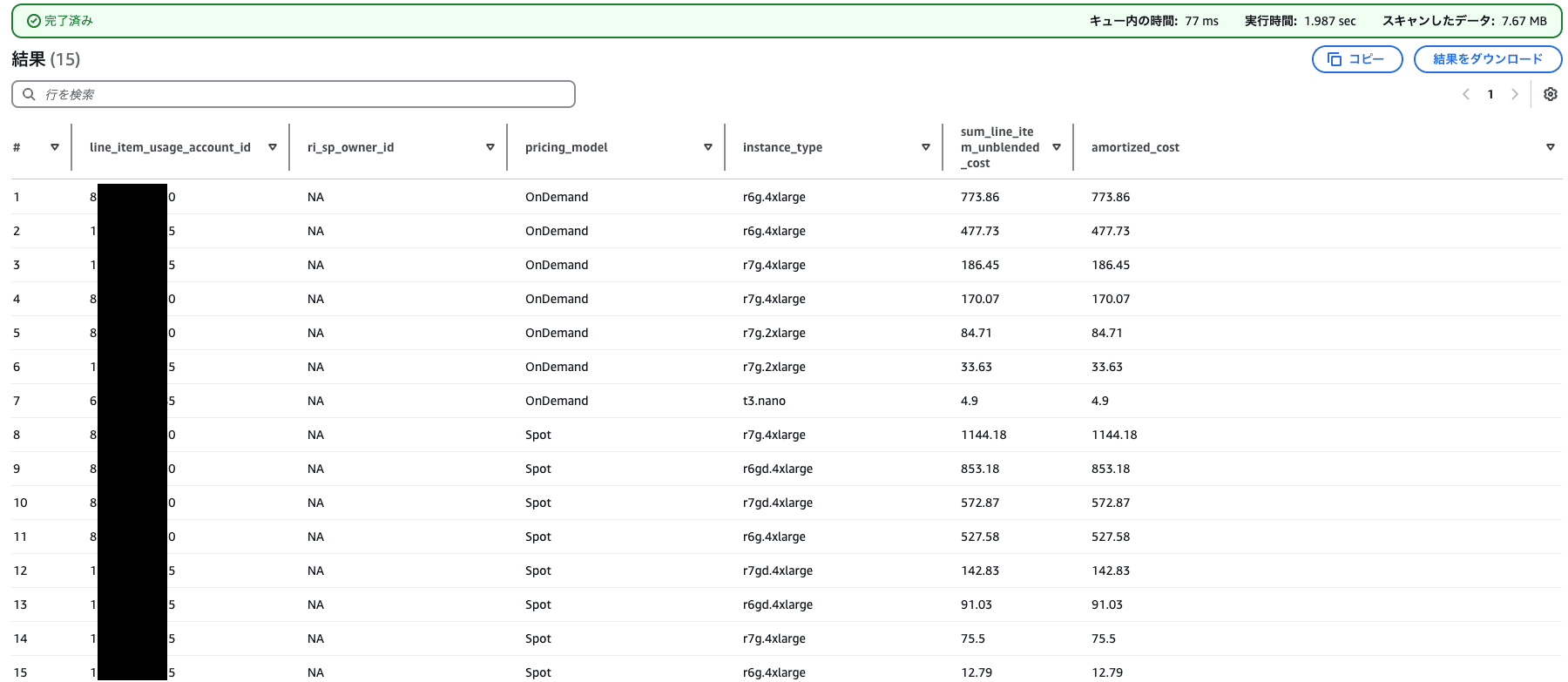
各アカウントでの購入オプション(オンデマンド、RI&SP、スポット)x インスタンスタイプ別 Amazon EC2 インスタンス利用費
SELECT
line_item_usage_account_id,
CASE
WHEN reservation_reservation_a_r_n <> '' THEN split_part(reservation_reservation_a_r_n,':',5)
WHEN savings_plan_savings_plan_a_r_n <> '' THEN split_part(savings_plan_savings_plan_a_r_n,':',5)
ELSE 'NA'
END AS ri_sp_owner_id,
(CASE
WHEN (line_item_usage_type LIKE '%SpotUsage%') THEN 'Spot'
WHEN
(((product_usagetype LIKE '%BoxUsage%')
OR (product_usagetype LIKE '%DedicatedUsage:%'))
AND ("line_item_line_item_type" LIKE 'SavingsPlanCoveredUsage'))
OR (line_item_line_item_type = 'SavingsPlanNegation')
THEN 'SavingsPlan'
WHEN
(("product_usagetype" LIKE '%BoxUsage%')
AND ("line_item_line_item_type" LIKE 'DiscountedUsage'))
THEN 'ReservedInstance'
WHEN
((("product_usagetype" LIKE '%BoxUsage%')
OR ("product_usagetype" LIKE '%DedicatedUsage:%'))
AND ("line_item_line_item_type" LIKE 'Usage'))
THEN 'OnDemand'
ELSE 'Other' END) pricing_model,
CASE
WHEN
line_item_usage_type like '%BoxUsage'
OR line_item_usage_type LIKE '%DedicatedUsage'
THEN product_instance_type
ELSE SPLIT_PART (line_item_usage_type, ':', 2) END instance_type,
ROUND(SUM (line_item_unblended_cost),2) sum_line_item_unblended_cost,
ROUND (
SUM((
CASE
WHEN line_item_usage_type LIKE '%SpotUsage%'
THEN line_item_unblended_cost
WHEN
((product_usagetype LIKE '%BoxUsage%')
OR (product_usagetype LIKE '%DedicatedUsage:%'))
AND (line_item_line_item_type LIKE 'Usage')
THEN line_item_unblended_cost
WHEN
((line_item_line_item_type LIKE 'SavingsPlanCoveredUsage'))
THEN TRY_CAST(savings_plan_savings_plan_effective_cost AS double)
WHEN ((line_item_line_item_type LIKE 'DiscountedUsage'))
THEN reservation_effective_cost
WHEN (line_item_line_item_type = 'SavingsPlanNegation')
THEN 0
ELSE line_item_unblended_cost END)), 2) amortized_cost
FROM mcur.cur
WHERE year = '2024'
AND month = '11'
AND line_item_operation LIKE '%RunInstance%' AND line_item_product_code = 'AmazonEC2'
AND (product_instance_type <> '' OR (line_item_usage_type LIKE '%SpotUsage%' AND line_item_line_item_type = 'Usage'))
GROUP BY
1, -- account id
3, -- pricing model
4, -- instance type
2 -- ri_sp_owner_id
ORDER BY
pricing_model,
sum_line_item_unblended_cost DESC;
最後に
どちらのパターンでも Parquet 版メンバーズ CUR を利用した Athena でのコスト分析環境を構築することが出来ました。
今回、確認した以外にも Athena サンプルクエリは豊富に用意されているため、ぜひ環境を構築して、他のクエリも試してみてください。








