
S3を支える大規模デプロイメント戦略 「Large-scale software deployments: Inside Amazon S3’s release pipeline」参加レポート #AWSreInvent
はじめに
今回はS3のデプロイ方法について紹介したセッション「Large-scale software deployments: Inside Amazon S3’s release pipeline」の参加レポートです。S3という世界中にデプロイされる複雑なシステムを安定的に稼働させ、機能を追加するために、どのようなパイプラインを構築しているのか紹介されていました。複雑化したシステムのデプロイに関する知見が盛り沢山だったので、ぜひご確認ください。
本稿では、特に気になった部分をピックアップして紹介します。セッションでは、細かく紹介されなかった前提の話や筆者の解釈に基づいて記載している部分もあります。セッションの正確な内容や全体が気になる場合は、上記の動画本編をご確認ください。
動画
登壇概要
日本語訳した登壇概要を記載します。
世界最大級の分散システムの一つであるAmazon S3が、どのようにソフトウェアデプロイメントを大規模に管理しているか学びたいですか?このセッションでは、大規模な環境で信頼性の高い更新を可能にする、私たちのデプロイメントツール、フィーチャーフラグ戦略、段階的ロールアウト技術についての実践的な知見を明らかにします。ロールバックの処理方法、依存関係の管理、更新中のサービスヘルスの監視方法など、重要なデプロイメントから得られた実際の教訓を共有します。自社のデプロイメントパイプラインを拡張している方も、クラウドインフラストラクチャ運用に興味がある方も、リスクを最小限に抑えながら信頼性を最大化する堅牢なデプロイメントプロセスを構築するための貴重な戦略を得ることができます。
登壇者
- George M. Lewis II | Senior Manager of Software Development Amazon S3
- Vandana Rungta | Principal Software Engineer Amazon S3
前半はGeorge M氏がステートレスな部分のデプロイパイプラインの構成やデプロイ方法について話し、後半はステートフルな部分のデプロイ方法をVandana氏が話していました。
内容

全体のアジェンダとしては、以下のような構成でした。
- S3はどのように安全にデプロイされているのか
- マルチパーティションによるデプロイ
- アプリケーション機能のコントロール
- ステートフルパイプライン
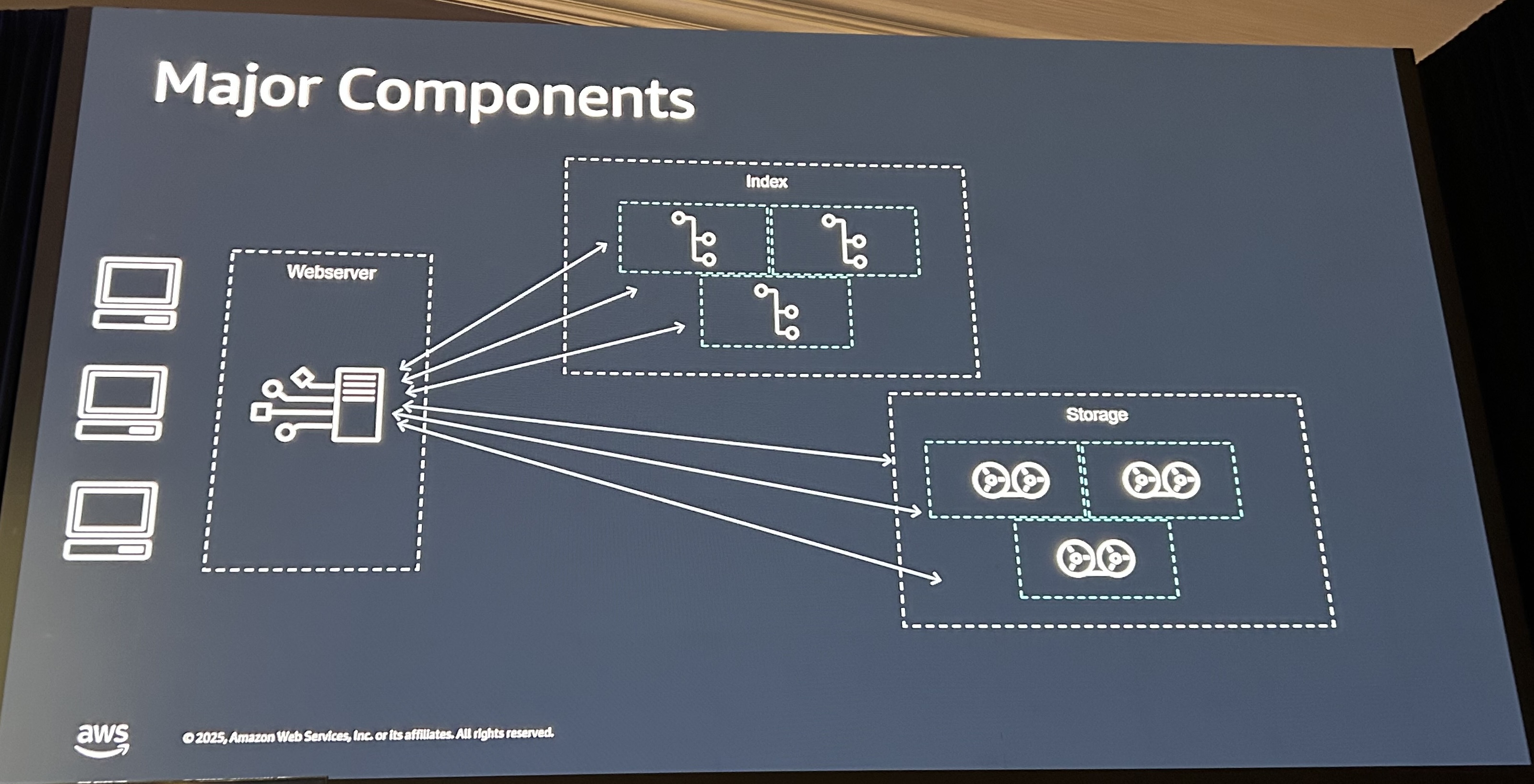
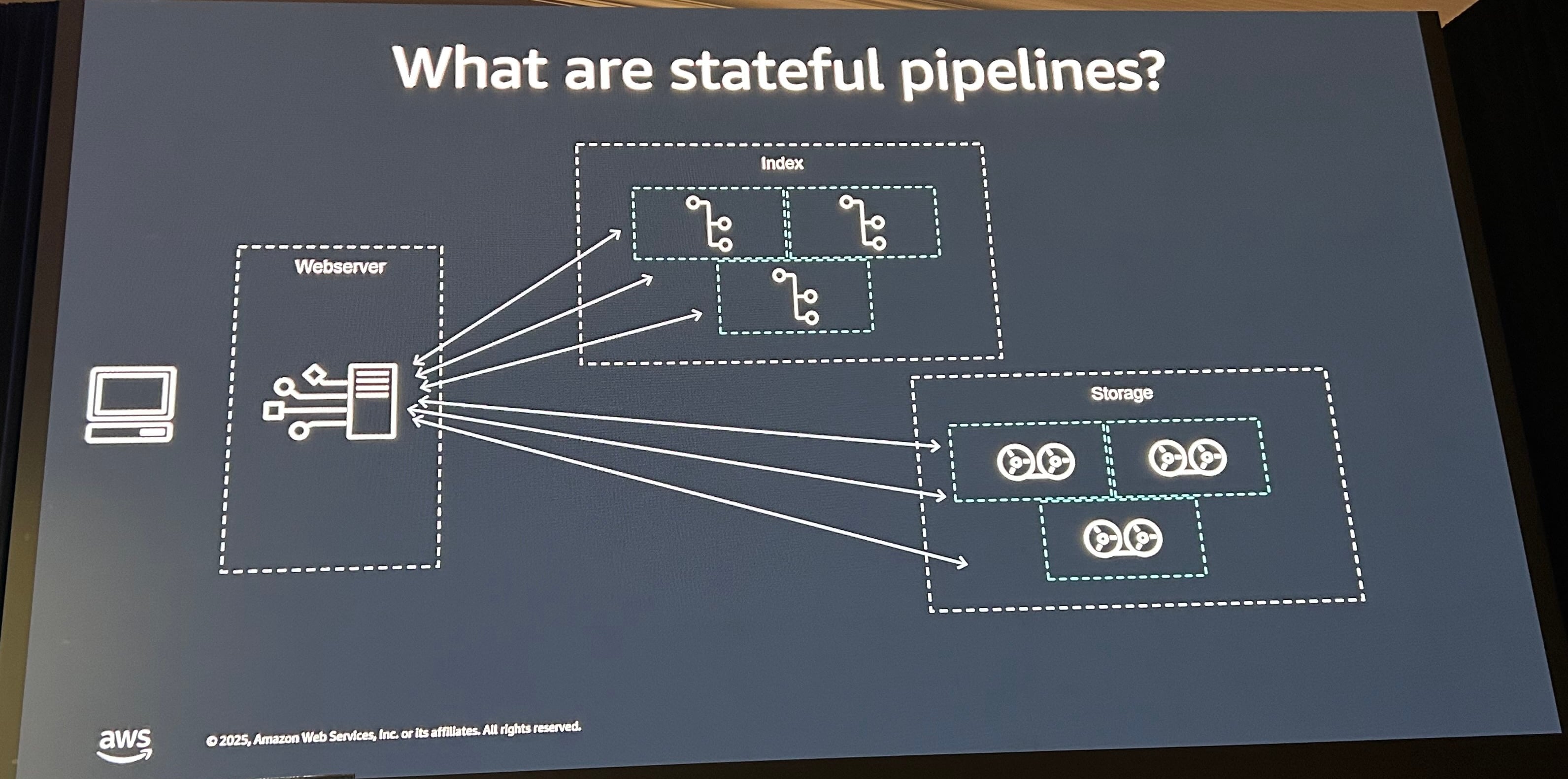
S3自体は、3つの重要なコンポーネントで実装されています。S3というアプリケーションの中心でもある、Web Serverの部分をいかにデプロイや管理しているかという話に前半は焦点が当たっていました。
- Web Server: S3 APIのフロントエンドとなるサーバ
- Storage: S3にアップロードされたデータの保管先
- Index: ストレージへのインデックス
S3自体をデプロイする際のテストでは、ユニットテストや基礎的なテストに時間を費やしていないそうです。S3というシステムをスケールさせるために、以下3つの構造で実装されています。
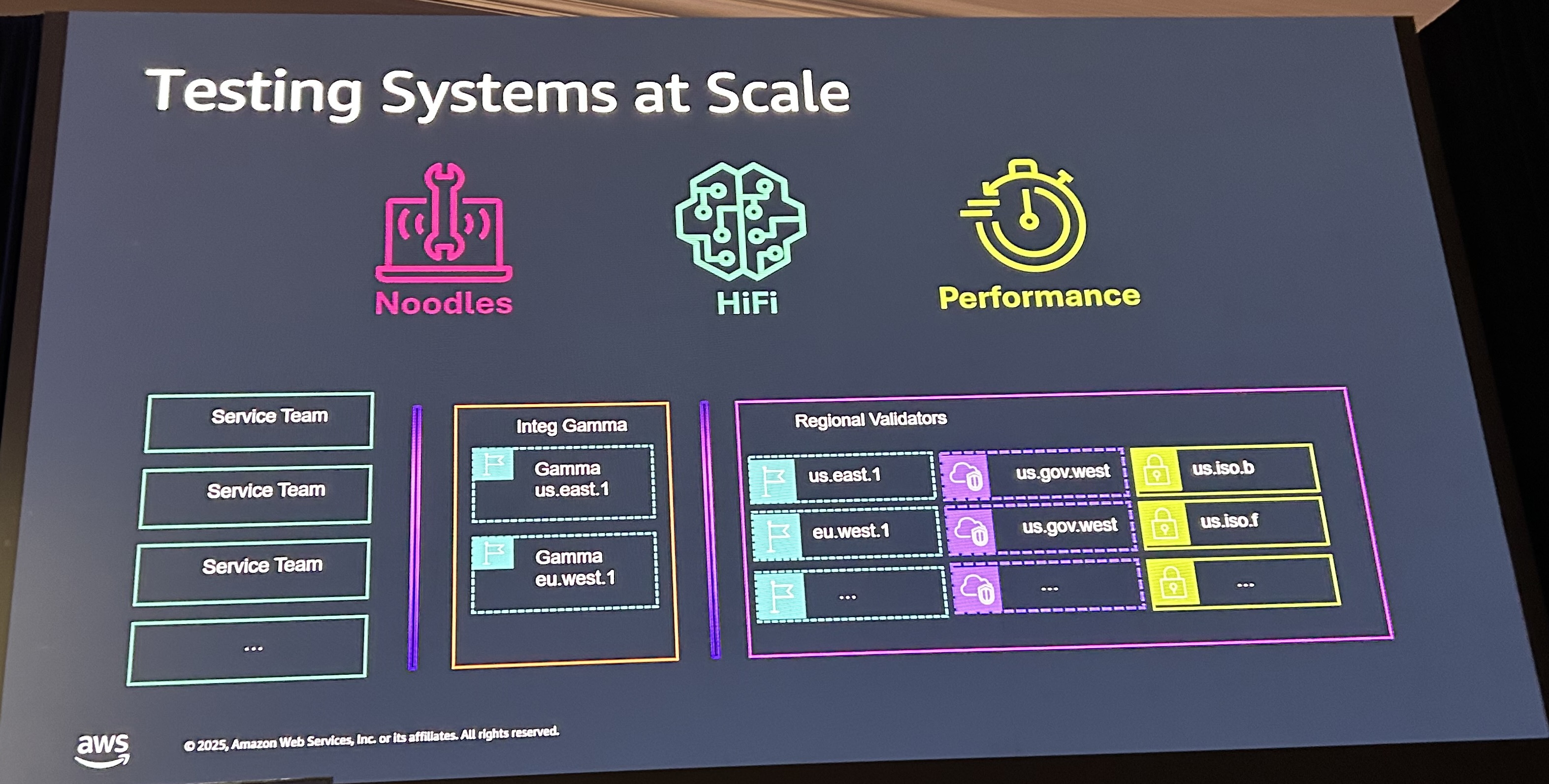
- Noodles - S3のパブリックAPIを動的なテストを作成するためのテストプラットフォーム
- Hifi - High Fidelity Model Based Testing
- Performance - パフォーマンスに関するテスト
Noodlesについて
Noodlesは以下のような構文で記述します。S3 Object Lambdaという、S3へのGET/HEAD/LIST操作に応じて起動するLambdaのテストの記述です。機能名の説明とシナリオがあって、その中にGiven(前提条件)、And(条件追加)、When(実行)、Then(期待結果)があります。この例では、Aliceがsalesというaccess pointへのIAMポリシー権限を持っている場合に、myapというaccess pointにアクセスして、403になることを確認するテストになっています。
Feature: Object Lambda Control API authorizes requests correctly
Scenario: Alice cannot fetch Object Lambda APs with a prefix different from those specified in IAM policy
Given Alice has myap object lambda access point
And Alice has following IAM policy:
{
"Version": "2012-10-17",
"Statement": {
"Effect": "Allow",
"Action": ["s3:GetAccessPointForObjectLambda"],
"Resource": ["arn:{region:defaultPartition}:s3-object-
lambda:*:*:accesspoint/sales*"]
}
}
When Alice tries to retrieve myap object lambda access point
Then Alice should get 403 with AccessDenied
この構文はGherkin記法と呼ばれるもので、この記述をベースにJavaではCucumberを使うことで実際のテストコードに変換されます。このGherkin記法を使うことで、実装の詳細によらなくても同じ機能を満たしているかのテストができます。
このテストは、操縦者(puppeteer)となる1つのAWSアカウントが存在し、その操縦者がプールされたN個のアカウントに対して、テスト内容に基づいたテストを並列して実行します。テスト内容をインフラに記述するだけで自動でテストが行われます。またS3バケットのクリーンアップや古いバケットの削除なども別で自動で行われます。
Noodlesを作った最大の成果として、Noodlesさえあれば開発者のIDEや環境に依存せず、同じテストを実行可能になったことです。
登壇では触れられませんでしたが、AWSのサービス自体はリファレンスとなるデプロイパイプラインを持っており、このパイプラインが複数のテスト工程を持っています。この工程の中で、特定のリージョンから順にデプロイされる機構が組まれています。詳細が気になった場合は、以下のブログをご確認ください。
Hifi(High Fidelity Model - Based Testing)
Noodlesは機能的なテストでしたが、Hifiでは、仕様(モデル)を「何をすべきか」で定義し、「どうやるか」は定義しません。複数の機能間で仕様にズレが生じないよう、モデルだけを定義します。実装の詳細には踏み込みません。これにより複数の機能で互換性を保ったAPIが開発できます。
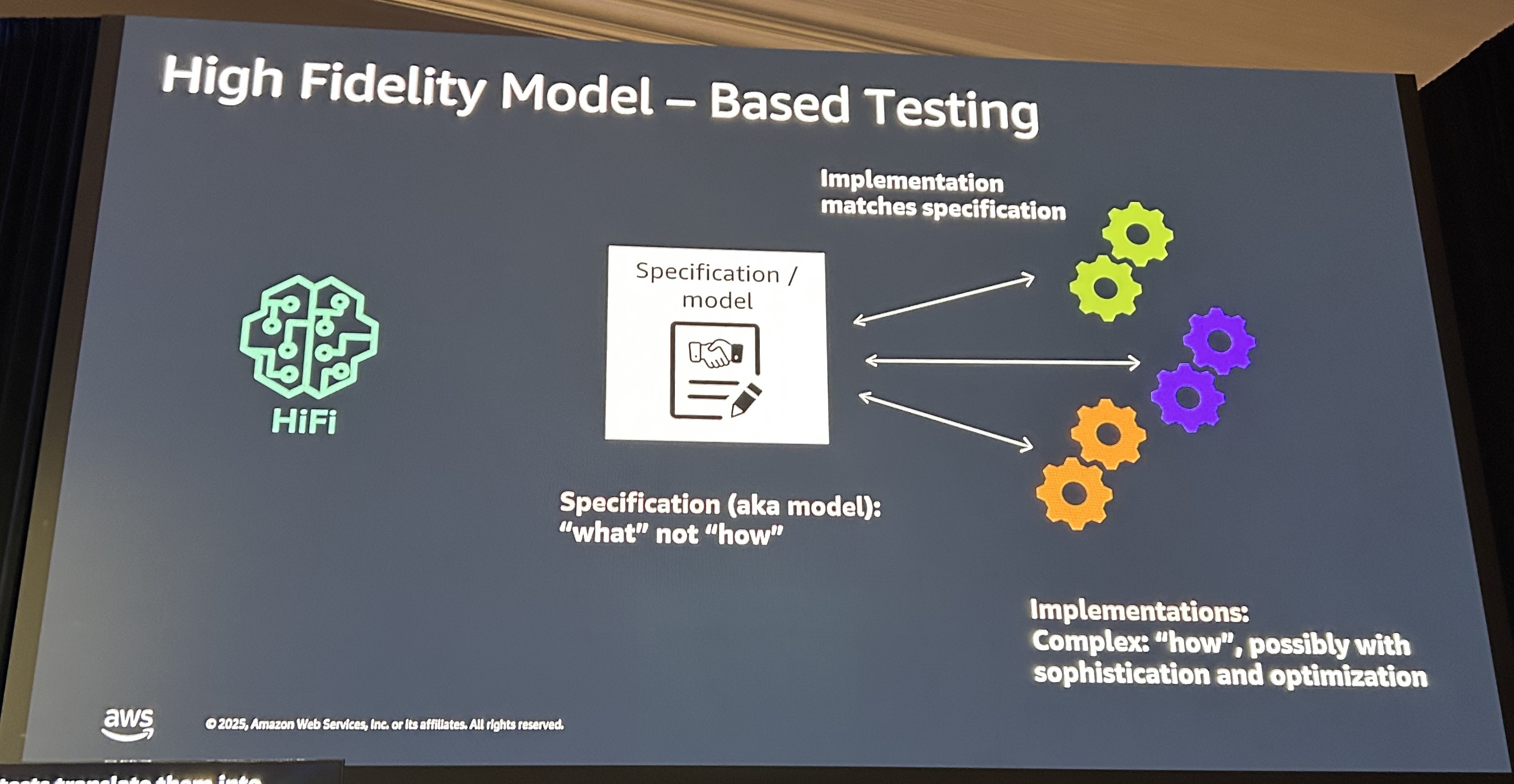
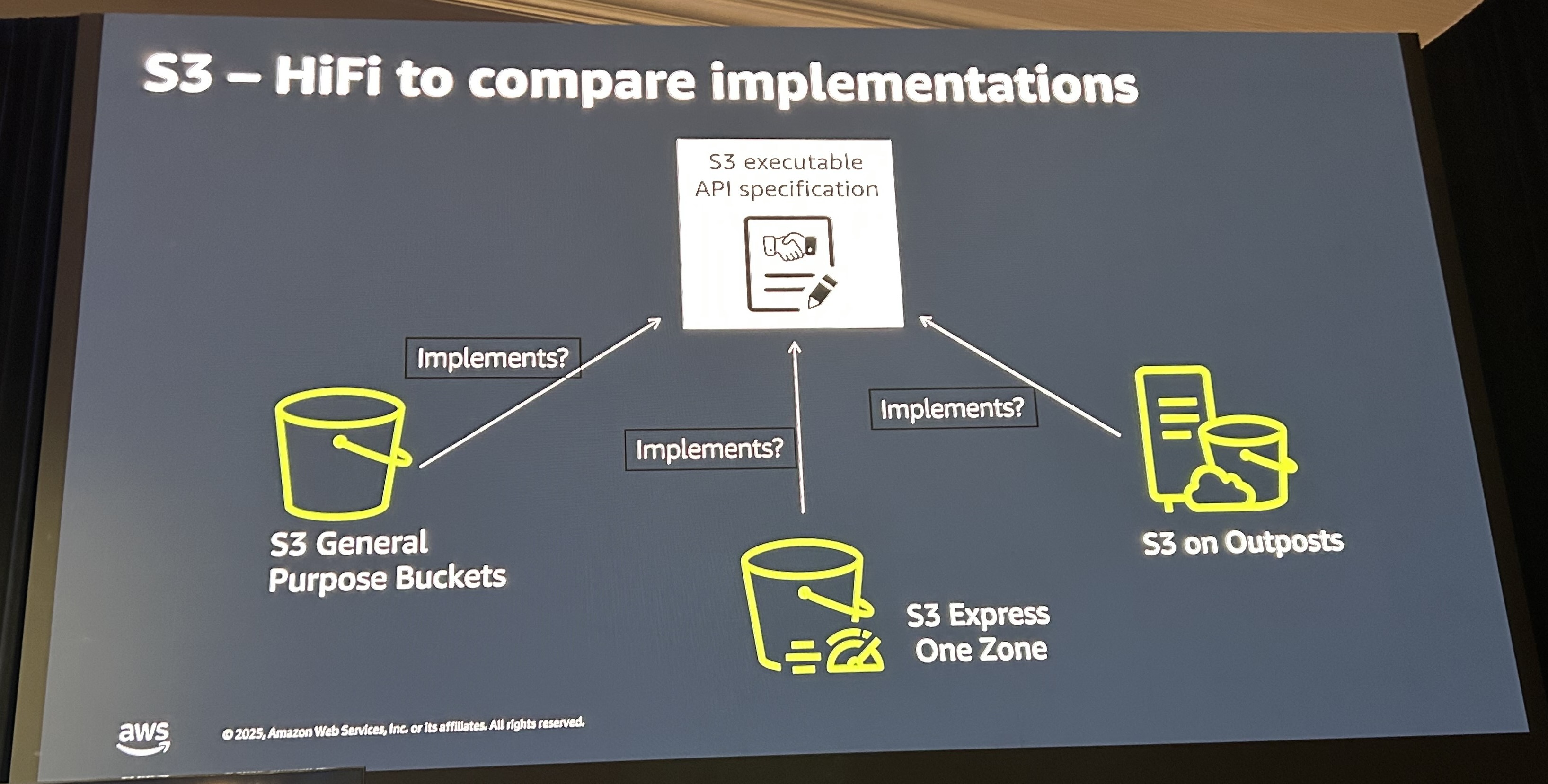
例として、S3における複数の実装が挙げられていました。S3の一般的なバケットとExpress One Zone、Outposts上のS3でS3 PutObjectです。PutObjectの中には、数十のヘッダー、コンテンツタイプ、暗号化、キャッシュなどなど多くの機能を持っています。この機能が様々なユースケースで実行されても問題ないことを確認します。たとえば、SSE-S3 と SSE-KMSそれぞれの暗号化ヘッダーが両方付与され競合している場合や、不正な形式のヘッダーが複数ある場合エラーの優先順位はどうなるのか。先ほど挙げた3種類のS3はそれぞれ実装が異なりますが、仕様が同じになるようこのHiFiでテストされています。
Hifiには3つのコンポーネントがあります。かなり割愛して紹介するので詳細は動画でご確認ください。
- Model Coponent: S3の仕様を実行可能なコードで表現したシミュレーター
- Test Generator: Model Coponentや実際のデータからテストケースを生成
- Validator Component: 実際のS3とHifiモデルの結果を比較。差異があればレポート
Modelを作る際は、単にAPIの仕様書を確認するだけではなく、実際のユーザーの利用方法をログから確認し、そこから追加の仕様を作成しています。この実際のユーザーの使用状況を確認するという話は何度も言及されていました。
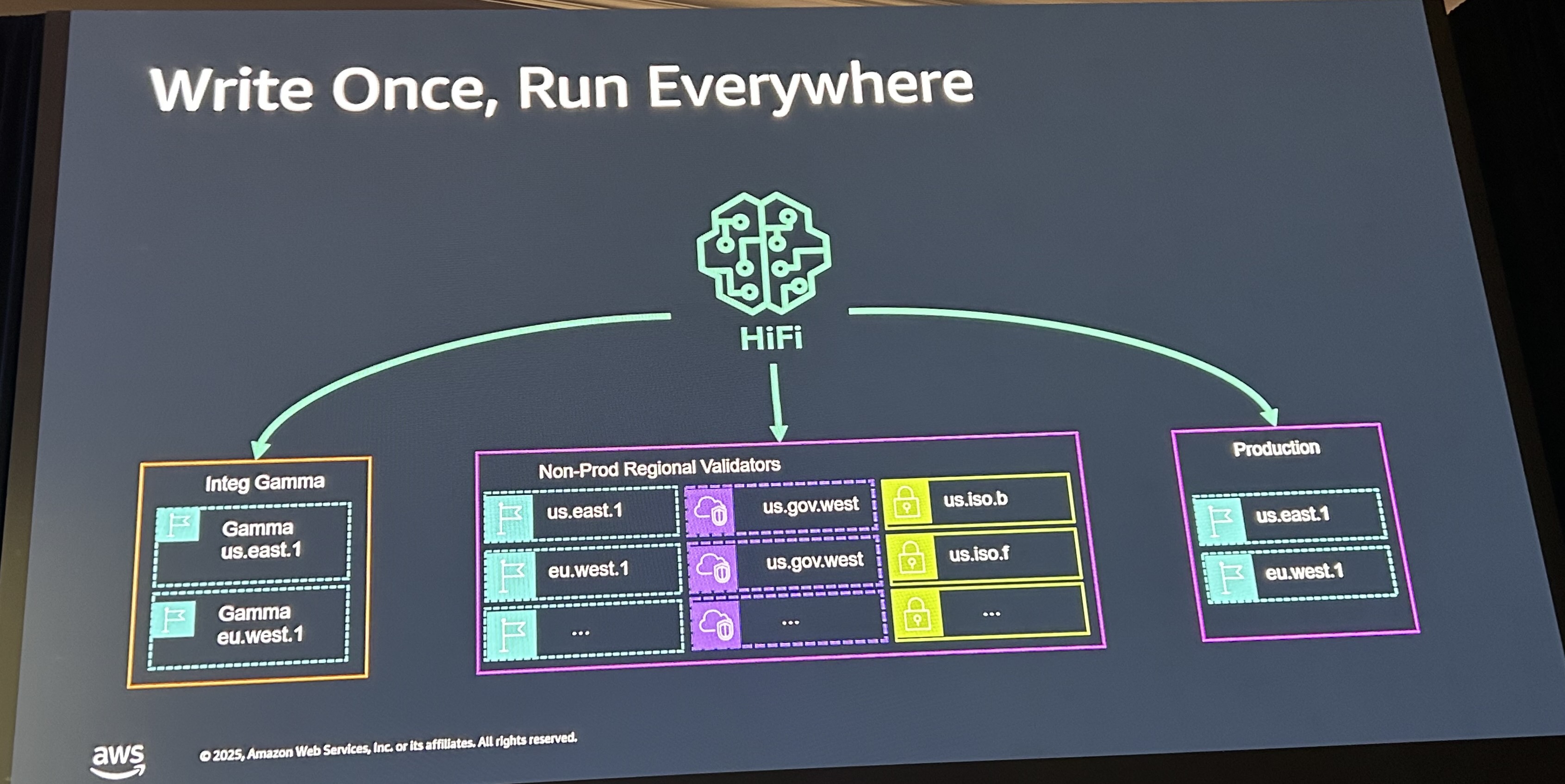
上記は、Model作成→テストケース生成→検証という3つのフェーズに分かれています。このフェーズが、単一のAWS環境だけでなく、Integ Gammaの環境や非本番のリージョンごとの環境、一部の本番環境で動いています。今後はすべての地域の本番環境にも反映する予定です。
Performance Test
パフォーマンス評価には、主に3つの方法をとっています。
- SW Feature Perfomance
- Instance Performance
- Region Rating
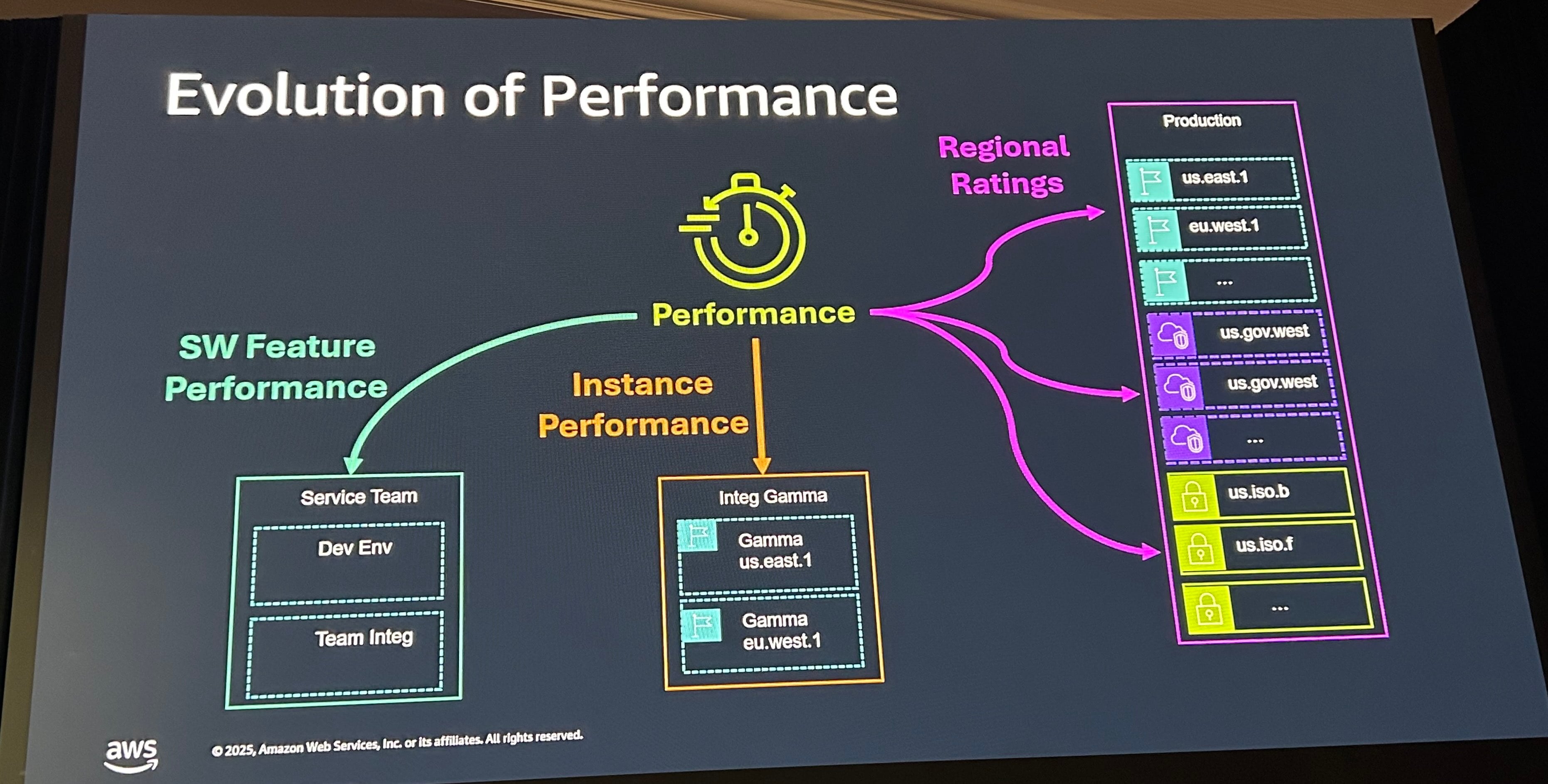
SW Feature Perfomanceは、別々のホストで機能を実行し比較します。ホストに依存した性能劣化が起きていないかを確認します。また、暗号化やマルチパートアップロードなど個別の機能の性能を見て、性能が劣化していないかを確認します。
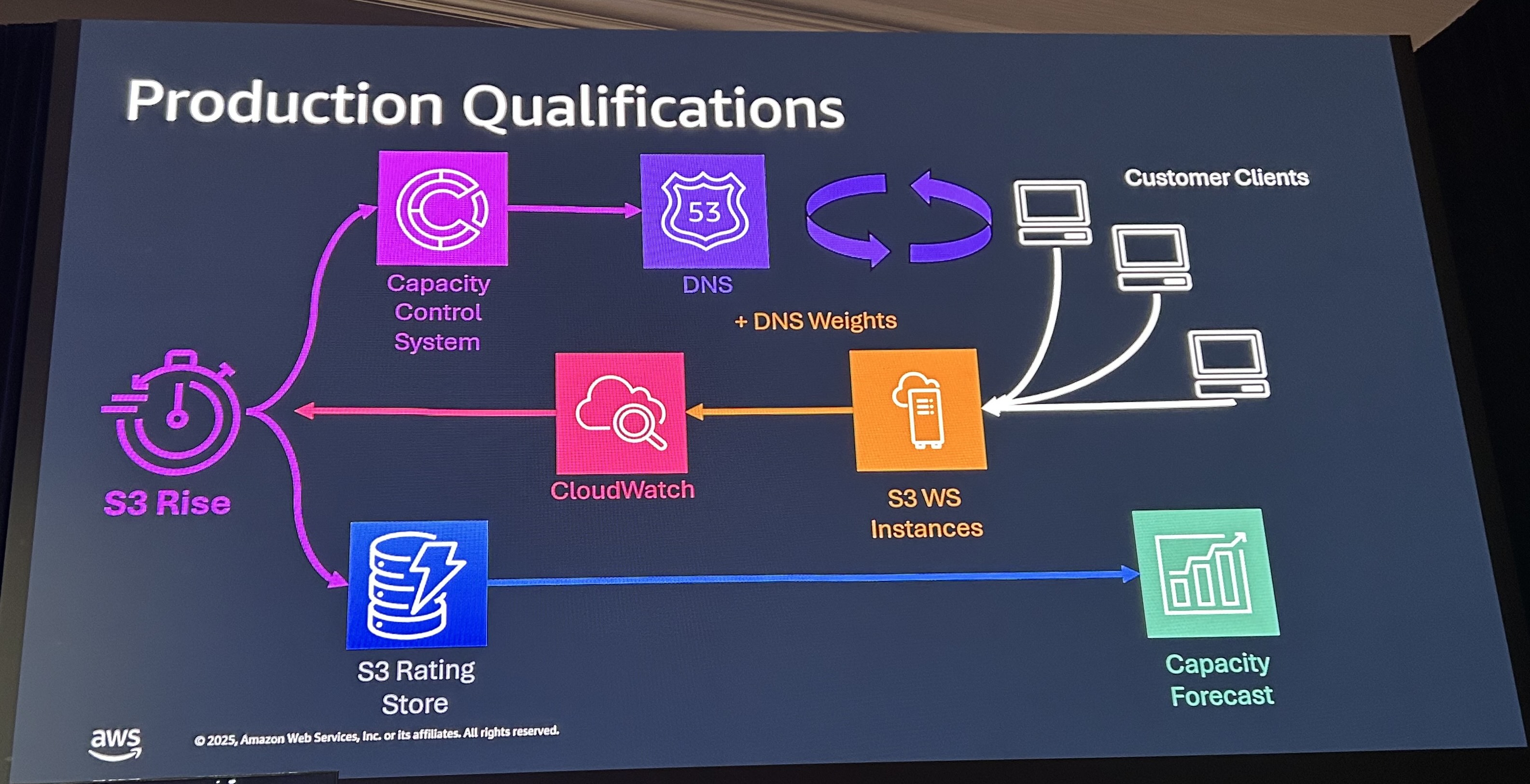
Instanceのパフォーマンス問題に対処するため、S3 Riseという機能も作っています。S3の容量キャパシティーやDNSと連動するシステムです。個別のS3 Instanceに多くのトラフィックが流れレイテンシ上がる場合などでCloudWatchにリクエストが飛びます。状況によってDNSの接続先切り替えが行われます。また顧客ごとのリクエストレートは、Rating Storeに保存され、Forecastで将来予測も行われます。この仕組みによってInstance PerformanceとRegion Ratingに対応しています。
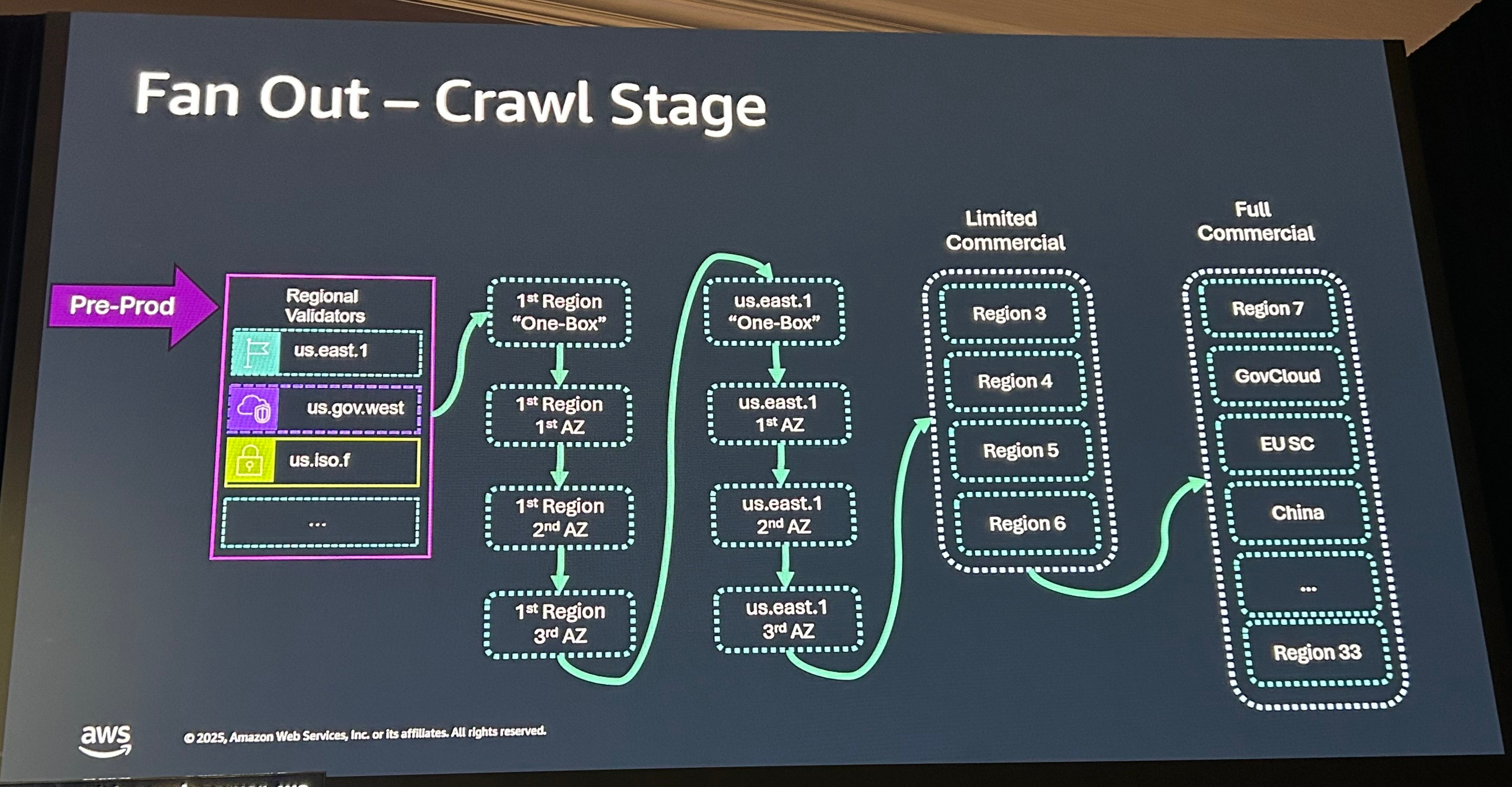
マルチパーティションによるデプロイ
Blast Radius(爆発半径=障害の影響範囲)についても触れられています。Blast Radiusを減らすため、非本番のリージョン環境でテストが行われた後、リージョンの1BOX、1AZ、2AZと徐々にデプロイ範囲を広げていきます。us-east-1 全体にデプロイされた後、限定された4つのリージョンにデプロイされ、最終的にはGovCloudやChinaを含むすべてのリージョンに展開されます。ただし、ソフトウェアのパッチは1AZ単位で行われることが個別に明言されていました。
上記のデプロイの間に以下のメトリクスとアラームで状況を監視します。
- コアメトリクス
- アプリケーションメトリクス: ビジネスKPI、エラー/レスポンスレート
- インフラメトリクス: CPU、Memory、Disk、Network利用状況
- デプロイメーカー: デプロイのStart/End Time
- 必須のアラーム
- エラーレートが通常の5%以上上昇しスパイクした場合
- レスポンス悪化
- ヘルスチェックの失敗
- CPU 利用率80%以上
- メモリ利用率85%以上
- ディスク使用率90%以上
上記のデプロイメトリクスとデプロイ先ゾーンを組み合わせることで、ロールバックが必要なタイミングを自動判断できます。
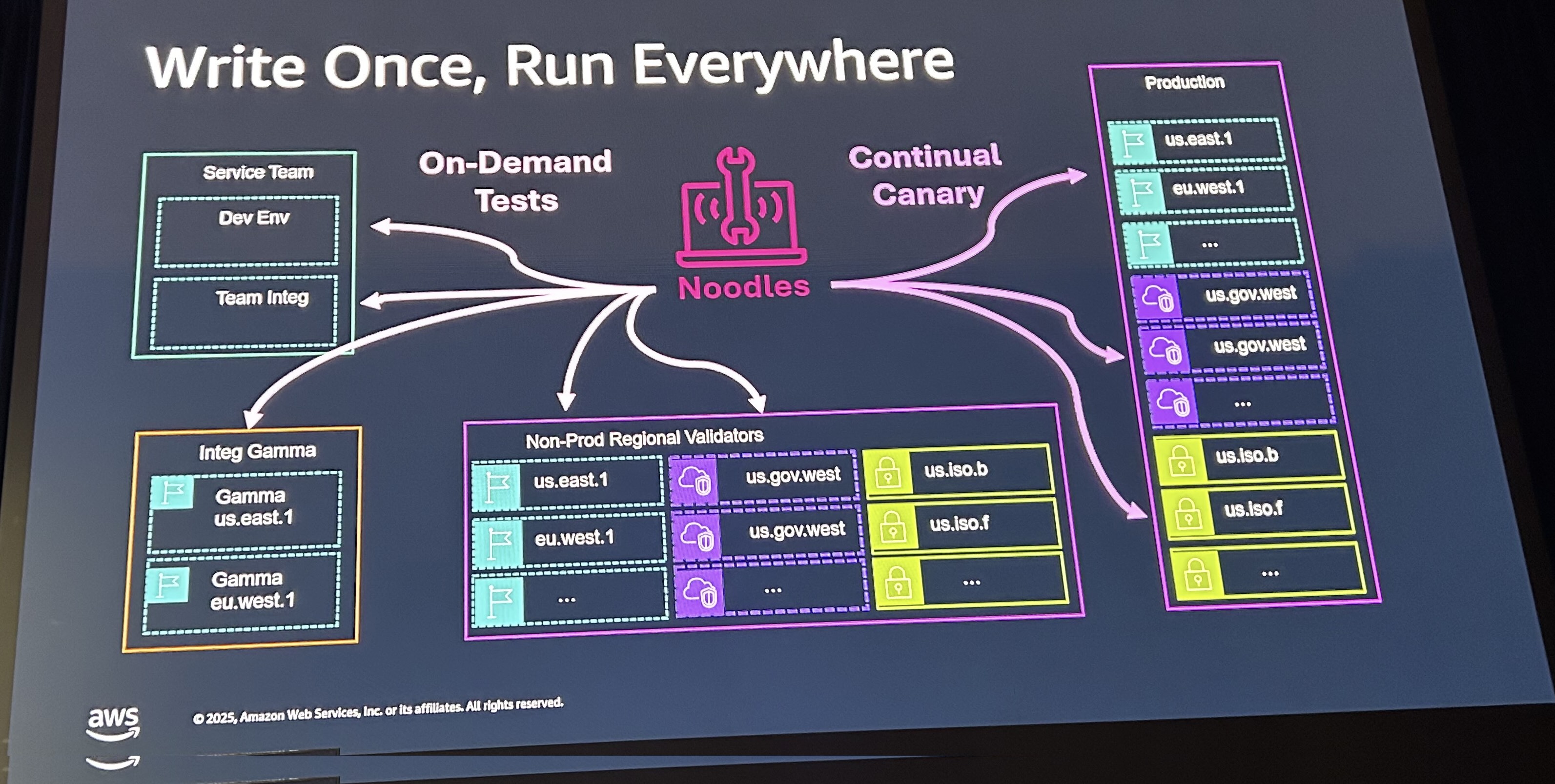
上記はメトリクスでの判断でしたが、メトリクスに表れないサイレントな障害も発生する可能性があります。その対応のためカナリアを使います。実際の顧客のようにリクエストするクライアントを用意しテストします。カナリアは先程紹介したNoodlesを使って、各テスト環境や本番リージョンで自動的に実行されます。
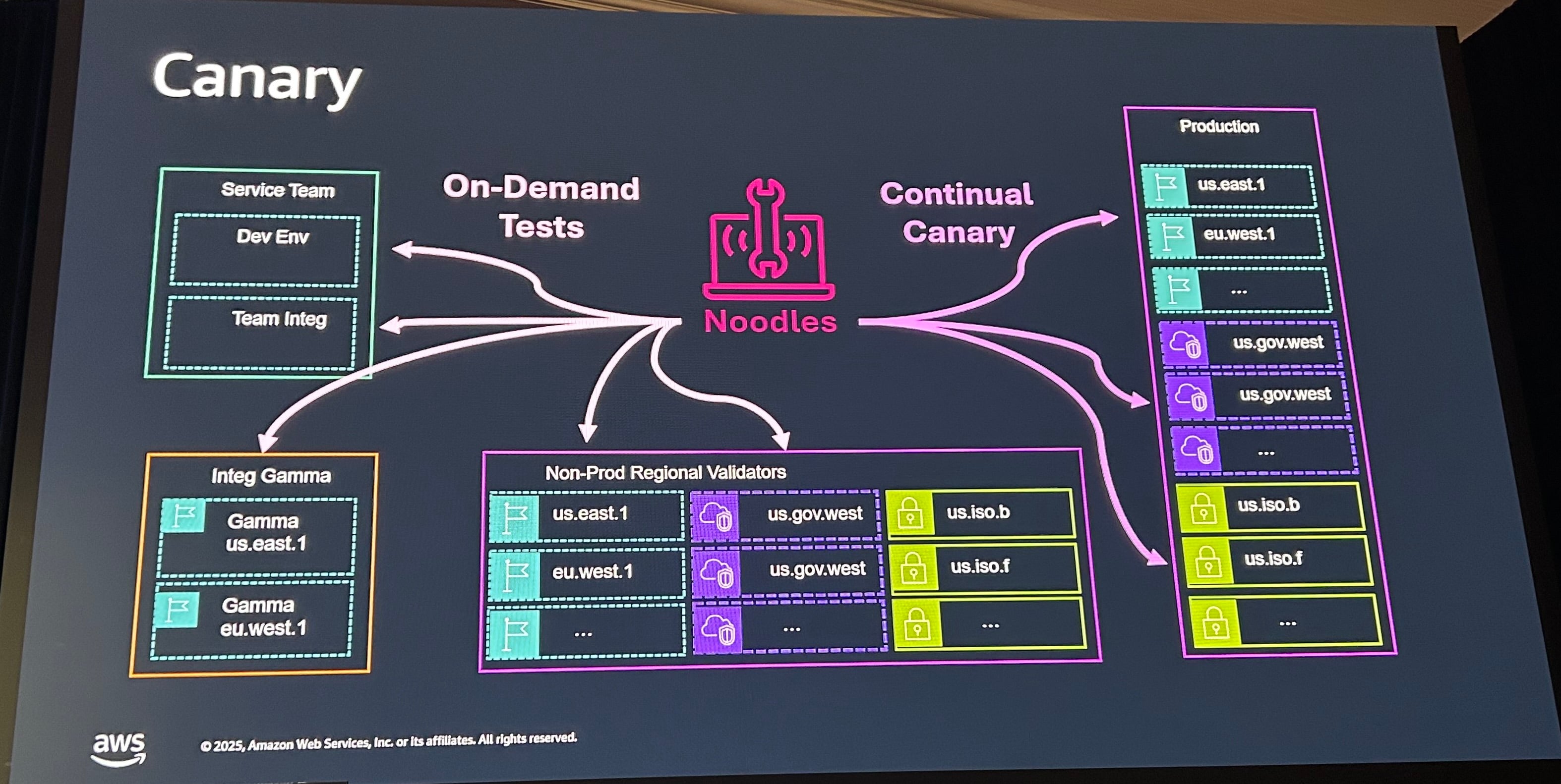
一般的にはCloudWatch Synthetics(Synthetics Monitoringのサービス)を使うことを推奨していました。S3のチームでは、S3がCloudWatch Syntheticsに依存すると、CloudWatch側もS3に依存しているので循環参照にならないようにするため使用していないようです。
次にFeature Flagについてです。re:Inventのタイミングでリリース予定の機能がONになります。S3独自の点としては、独自のドッグフーディングのため許可リストが使用されます。まず自分たち自身を許可リストに追加し、AWS内部のアカウントで実行してから大規模なアカウントで実行します。
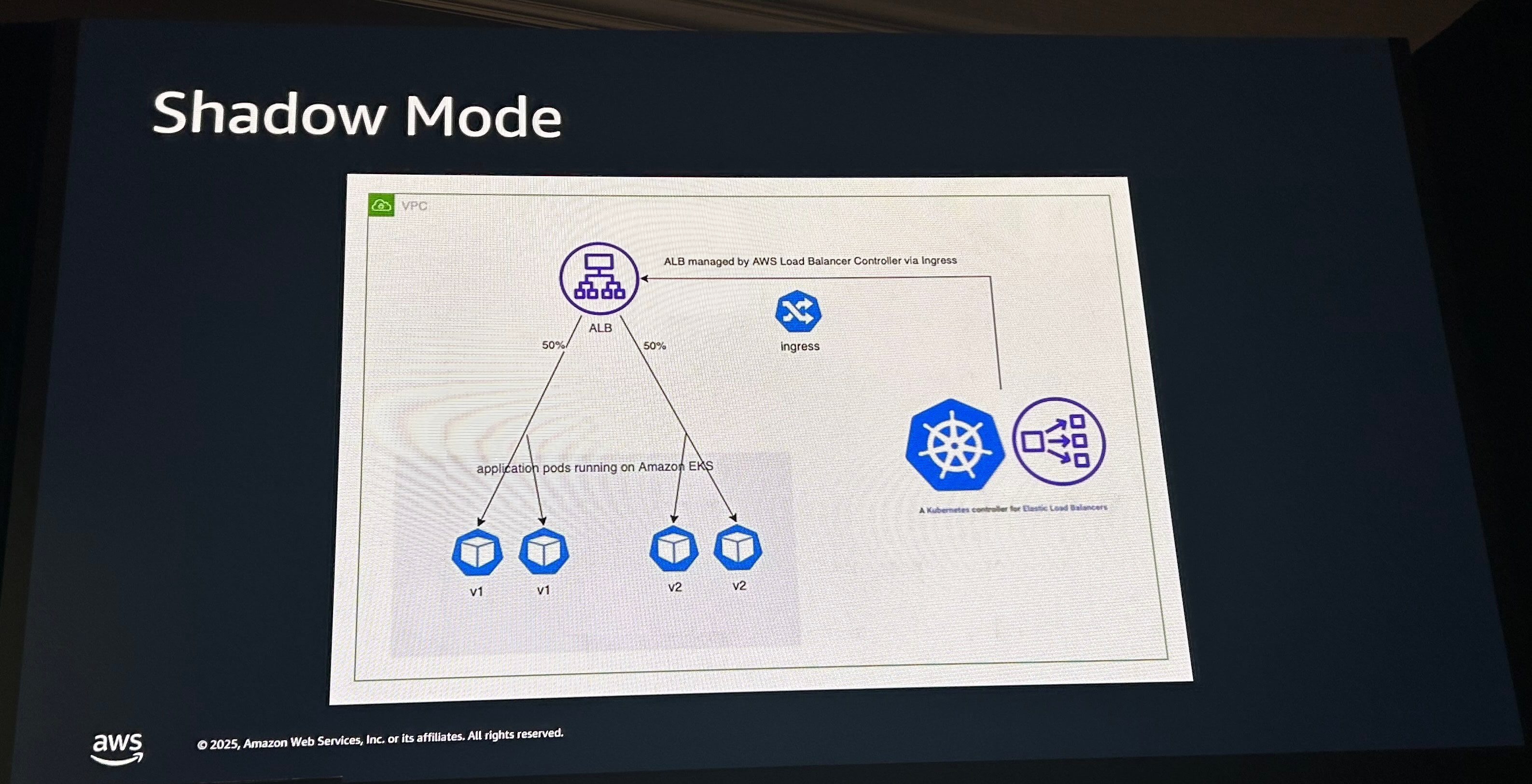
最後にシャドウモードの利用について紹介します。既存の本番環境と並行してシャドウでサービスが起動されます。 シャドウサービスにも本番サービスと同じトラフィックが流れますが、顧客へレスポンスは返しません。レスポンスはログやメトリクスとして記録され、 本番の情報と比較されます。依存するソフトウェアのアップデートの影響による性能劣化の問題に気づくことができます。
ここまではステートレスな部分のデプロイに関する紹介でした。ステートフルな部分のデプロイについては後半でご紹介します。
ステートフルパイプライン
ステートフルパイプラインは、状態をもつものとして最初に紹介した画像の右側部分、IndexとStorageが対象になります。データを取り出すためのIndexと、実際のデータが格納されるストレージです。これらのホストは状態を持つため、単に再起動はできません。
データの保全には、Integrity(完全性)、Consistency(一貫性)、Resiliency(レジリエンス)、Durability(耐久性)すべてが揃っている必要があります。完全性のため、E2Eでチェックサムを使用し、アップロードから処理、保存、送信でチェックされます。これにより、メモリ内のビット反転やビット腐敗(bit rot)に気づけます。一貫性では、強力な整合性をホスト更新時にも満たすよう設計されています。レジリエンスのため、システムの健全性やデータの整合性を確認し、侵害があれば自動で復旧します。耐久性ではコンポーネントの年間故障率モデルを使い、冗長性の量を正確に計算します。
ホスト予約システムを整備し、提供ホストをグループにまとめて適用しています。すべてのプロセスがこの予約システムを介して実行されます。
- パッチ適用
- ファームウェア更新
- ドライブ交換
- ソフトウェアデプロイ
- ラックの保守
- 手動オペレーション
- 自動ワークフロー
予約されると安全性の確認として、 ホストの予約情報、 ホストが停止可能か全体のキャパシティ確認、 メンテナンスのリミットを確認し、安全にデプロイできるかを確認します。また専用のソフトウェアとして、ホストの状態やゾーン間の分離、デプロイの実行状況、グループ間の関連性などを確認するものを作成しています。
これら紹介したテクニックが皆さんのシステムにも役立つことを願っています。
所感
S3という普段使っているサービスの裏側で一体何が起きているのか。クラウドの裏側にあるホストを感じられつつ、大規模なサービスを維持するためにはどんな手法が取られているのか非常に参考になりました。特に、Gherkin記法からテストコードを生成し、Noodlesというテストプラットフォームを整備している話や複数のS3サービス間で仕様を一致させるためのHifiの話はかなり興味深かったです。
実装の詳細までは入りこまずに、仕様の部分で一致しているかを確認するという手法は、Kiroを使って提唱しているSpec駆動開発やAI-DLCの文脈にもつながる部分を感じました。このようなシステムの作り方をしているからこそ、出てくる発想なのだと再理解できました。
本記事は自分の補足を交えつつ割愛している部分もあるので、よければ特に動画の前半を見てみてください。どなたかの参考になれば幸いです。










