
HubSpotのWebhookとAWS Lambda+SQSで実現する、大規模な会社・コンタクト自動カスタム紐付けシステム
はじめに
HubSpotを運用する中で、標準の「コンタクト(連絡先)」と「会社」の紐付けロジックが課題になることがあります。特に日本企業では、法人番号やドメイン、会社名の表記揺れなど、独自のマッチングロジックが必要になるケースが多く、当社でも例外ではありませんでした。
本記事では、HubSpotのWebHookとAWS(API Gateway + Lambda + SQS)を組み合わせて、カスタムロジックによる会社・コンタクトの自動紐付けシステムを構築した事例を紹介します。
課題:HubSpot標準機能の限界
HubSpotには標準で会社とコンタクトを紐付ける機能がありますが、以下のような制限があります。
- ドメインのみを使って紐付けを実施する
- これは、グループ会社など同じドメインの複数企業などのケースにて問題になります
- 法人番号などの日本独自の識別子には対応していない
- 会社名の表記揺れ(株式会社の位置、略称など)に対応できない
- 複数の条件を組み合わせた柔軟なマッチングができない
解決策:WebHook + AWS サーバーレスアーキテクチャ
システム構成
HubSpot WebHook
↓
API Gateway (認証付き)
↓
Lambda (受信用・軽量)
↓
SQS Queue (キューイング)
↓
Lambda (処理用・並列制御)
↓
HubSpot API(会社、コンタクトの紐付けを実施)
なぜSQSを使うのか?
当初はWebHookをトリガーにLambdaから直接HubSpot APIを呼び出していましたが、以下の問題に直面しました。
- API制限(Rate Limit): 大量のWebHookが同時に発火すると「Too Many Requests」エラーが発生
- タイムアウト: 処理が長時間かかると、WebHookがタイムアウト
- リトライ処理: エラー時の再処理が困難
SQSを導入することで:
- WebHookは即座に200を返せる(レスポンス時間: 900秒→30秒)
- API呼び出しを制御可能(同時実行数: 5に制限)
- 失敗時は自動リトライ(3回失敗でDLQへ)
実装詳細
1. WebHook受信Lambda
import boto3
import json
from datetime import datetime
sqs = boto3.client('sqs')
def lambda_handler(event: dict, context: dict) -> dict:
"""WebHookを受信してSQSに送信"""
queue_url = os.environ.get("SQS_QUEUE_URL")
contact_id = event.get('queryStringParameters', {}).get('contact_id')
# SQSにメッセージを送信
message_body = {
"contact_id": contact_id,
"received_at": datetime.now().isoformat(),
}
sqs.send_message(
QueueUrl=queue_url,
MessageBody=json.dumps(message_body)
)
return {
"statusCode": 200,
"body": json.dumps({"state": "Queued"})
}
2. マッチングロジック
カスタムマッチングでは以下のように自由に条件を組み合わせることが可能です。
def merge_by(companies, contacts):
"""会社とコンタクトのマッチング"""
result = []
for company in companies:
for contact in contacts:
# 条件1: ドメインと法人番号/会社名の両方が一致
if is_match_domain(company, contact) and \
is_match_number_or_name(company, contact):
result.append({**company, **contact})
# 条件2: 法人番号が一致(フリーメール以外)
elif is_match_corporate_number(company, contact) and \
not is_free_mail(contact):
# ドメイン不一致でも紐付け候補として記録
pass
3. CDKによるインフラ定義
// SQSキューの作成
const queue = new sqs.Queue(this, 'ContactLinkerQueue', {
visibilityTimeout: Duration.minutes(15),
deadLetterQueue: {
queue: dlq,
maxReceiveCount: 3,
},
});
// 処理用Lambda(同時実行数を制限)
const lambdaSqsProcessor = new PythonFunction(this, 'SqsProcessor', {
timeout: Duration.seconds(900),
reservedConcurrentExecutions: 5, // API制限対策
environment: {
HUBSPOT_ACCESS_TOKEN: process.env.HUBSPOT_ACCESS_TOKEN,
WEBHOOK_CREDENTIALS: process.env.WEBHOOK_CREDENTIALS
},
});
// SQSトリガーの設定
lambdaSqsProcessor.addEventSource(new SqsEventSource(queue, {
batchSize: 10,
maxBatchingWindow: Duration.seconds(20),
}));
セキュリティ対策
API Gateway認証
HubSpotのWebhookからのリクエストを検証するため、Lambda Authorizerを実装します。
def lambda_handler(event, context):
"""Webhook署名を検証"""
signature = event['headers'].get('x-hubspot-signature')
credentials = os.environ.get('WEBHOOK_CREDENTIALS')
# HMAC-SHA256で署名を検証
expected_signature = calculate_signature(
credentials,
event['body']
)
if signature != expected_signature:
raise Exception('Unauthorized')
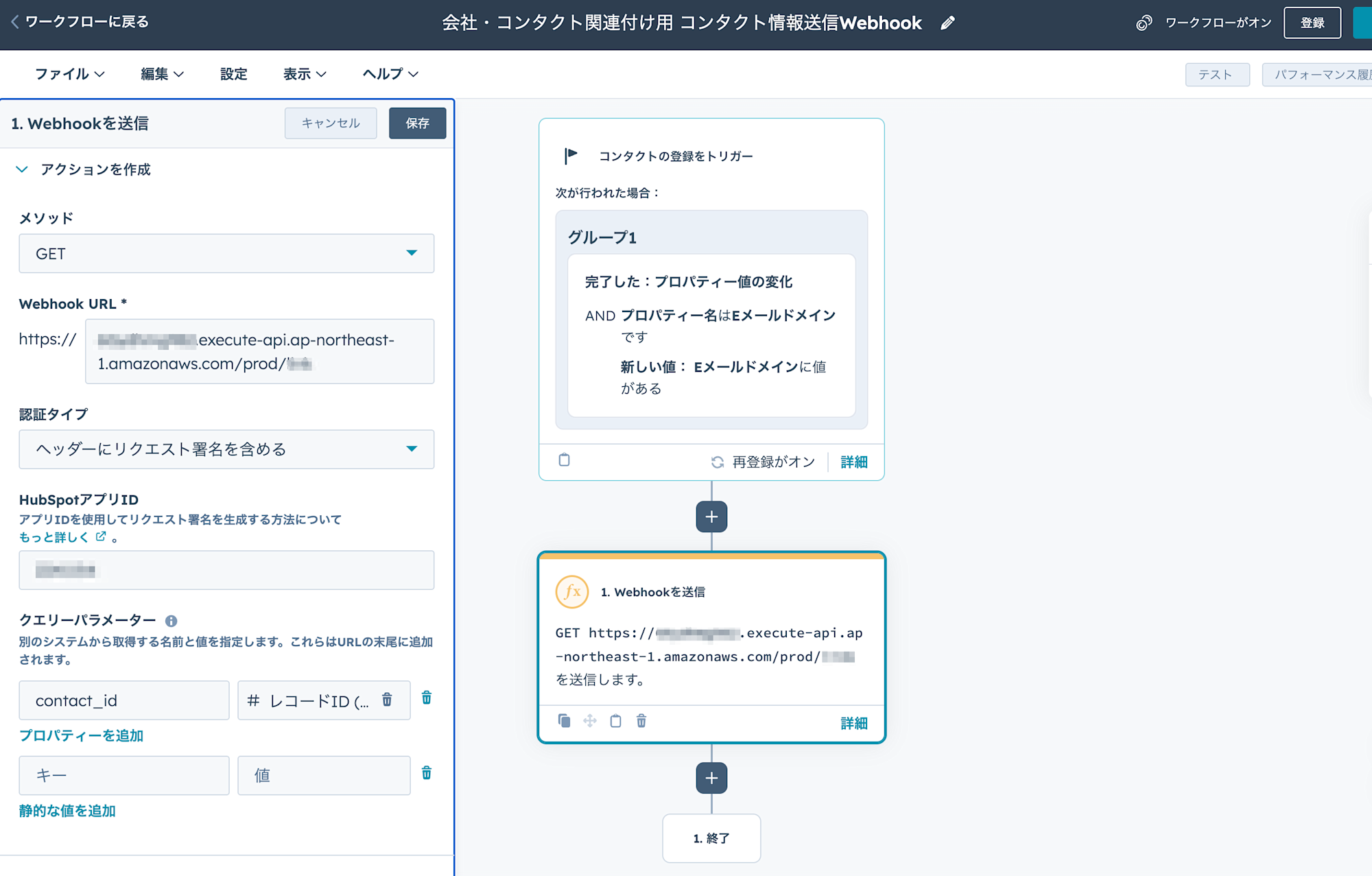
HubSpot側でのWebhook設定
HubSpotで特定の条件を満たした際に、Webhookにリクエストを送る設定を行います。
ワークフローを定義して、Webhook URLにCDKで生成した、API Gatewayのリンクを設定します。
また、認証タイプに「ヘッダーにリクエスト署名を含める」を選択し、利用するHubSpotアプリIDを設定します。
ここでアプリIDで指定したアプリのクレデンシャル(クライアントシークレット)が認証に使用されます。
CDKでデプロイ時に.envにて、
WEBHOOK_CREDENTIALS=[クライアントシークレット]
と渡すように留意しましょう。
運用のポイント
1. モニタリング
- CloudWatch Metrics: SQSのキュー長、Lambda実行時間
- DLQの監視: 処理失敗メッセージの確認
- API制限の監視: HubSpot APIのレート制限状況
2. チューニング項目
同時実行数: 5 # HubSpot APIの制限に応じて調整
バッチサイズ: 10 # 一度に処理するメッセージ数
API呼び出し間隔: 1秒 # レート制限回避
可視性タイムアウト: 15分 # 処理時間に応じて調整
3. コスト最適化
- WebHook受信Lambda: メモリ256MB、タイムアウト30秒
- 処理Lambda: メモリ1024MB、タイムアウト15分
- SQS: 標準キューを使用(FIFOは不要)
成果とメリット
このシステム導入により、次の成果とメリットを得ることができました。
- 処理能力向上: 大量のWebHookを確実に処理
- エラー率低下: API制限エラーがほぼゼロに
- 柔軟性: 日本企業特有のマッチングロジックを実装
- 可観測性: 処理状況の可視化とデバッグが容易に
まとめ
HubSpotのWebHookとAWSのサーバーレスアーキテクチャを組み合わせることで、スケーラブルで信頼性の高い自動紐付けシステムを構築できました。
特にSQSを挟むことで、以下が実現できます。
- WebHookのタイムアウト問題の解消
- API制限への柔軟な対応
- エラー処理とリトライの自動化
同様の課題を抱えている方の参考になれば幸いです。
参考リンク
本記事のコードは簡略化しています。実際の実装では、エラーハンドリング、ログ出力、テストコードなどを含めて実装してください。










