
Amazon Athenaで各種Join処理の動作を確認してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
Amazon Athenaで複数のテーブルのデータを結合したい時があるのですが、その際にどのJoin Typeを使用すれば目的の結合方法になるのか、いつも迷ってしまいます。
そこで今回は、Amazon Athenaでの各種Join処理の動作を改めて確認してみました。
やってみた
環境準備
AWS CDK v2(TypeScript)で次のようなCDKスタックを作成します。
import { Construct } from 'constructs';
import {
aws_s3,
aws_athena,
RemovalPolicy,
Stack,
StackProps,
} from 'aws-cdk-lib';
import * as glue from '@aws-cdk/aws-glue-alpha';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// データソース格納バケット
const dataSourceBucket = new aws_s3.Bucket(this, 'dataSourceBucket', {
bucketName: `data-source-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
});
// マスターデータ格納バケット
const masterDataBucket = new aws_s3.Bucket(this, 'masterDataBucket', {
bucketName: `master-data-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
});
// Athenaクエリ結果格納バケット
const athenaQueryResultBucket = new aws_s3.Bucket(
this,
'athenaQueryResultBucket',
{
bucketName: `athena-query-result-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
},
);
// データカタログ
const dataCatalog = new glue.Database(this, 'dataCatalog', {
databaseName: 'data_catalog',
});
// データソースカタログテーブル
new glue.Table(this, 'dataSourceGlueTable', {
tableName: 'data_source_glue_table',
database: dataCatalog,
bucket: dataSourceBucket,
s3Prefix: 'data/',
dataFormat: glue.DataFormat.JSON,
columns: [
{
name: 'userId',
type: glue.Schema.STRING,
},
{
name: 'count',
type: glue.Schema.INTEGER,
},
],
});
// マスターデータカタログテーブル
new glue.Table(this, 'masterDataGlueTable', {
tableName: 'master_data_glue_table',
database: dataCatalog,
bucket: masterDataBucket,
s3Prefix: 'data/',
dataFormat: glue.DataFormat.JSON,
columns: [
{
name: 'userId',
type: glue.Schema.STRING,
},
{
name: 'name',
type: glue.Schema.STRING,
},
],
});
// Athenaワークグループ
new aws_athena.CfnWorkGroup(this, 'athenaWorkGroup', {
name: 'athenaWorkGroup',
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`,
},
},
recursiveDeleteOption: true,
});
}
}
次のデータを各テーブルのLocationに格納します。
- rawデータテーブル
| # | userId | count |
|---|---|---|
| 1 | u001 | 3 |
| 2 | u001 | 1 |
| 3 | u002 | 5 |
| 4 | u002 | 8 |
| 5 | u003 | 2 |
| 6 | u999 | 4 |
- masterデータテーブル
| # | userId | name |
|-|-|-|-|
| 1 | u001 | John |
| 2 | u002 | Bob |
| 3 | u003 | Tom |
| 4 | u004 | Peter |
$ cat dataSouce
{"userId":"u001","count":3}
{"userId":"u001","count":1}
{"userId":"u002","count":5}
{"userId":"u002","count":8}
{"userId":"u003","count":2}
{"userId":"u999","count":4}
$ cat masterData
{"userId":"u001","name":"John"}
{"userId":"u002","name":"Bob"}
{"userId":"u003","name":"Tom"}
{"userId":"u004","name":"Peter"}
$ aws s3 cp dataSouce s3://${DATA_SOURCE_BUCKET_NAME}/data/dataSouce
$ aws s3 cp masterData s3://${MASTER_DATA_BUCKET_NAME}/data/masterData
動作確認
次のようなクエリを実行して前述の2つのテーブルデータを結合します。その際に様々なJoin Typeを指定して(ハイライト行)、得られる結果を確認してみます。
WITH
raw AS (
SELECT * FROM data_catalog.data_source_glue_table
),
master AS (
SELECT * FROM data_catalog.master_data_glue_table
)
SELECT
raw.userId, raw.count, master.name
FROM raw
<Join Type> master
ON raw.userId = master.userId
INNER JOIN
INNER JOINを使用すると、JOIN句の左辺と右辺のいずれのテーブルにもあるレコードが結合結果として取得されます。
クエリを実行した様子です。
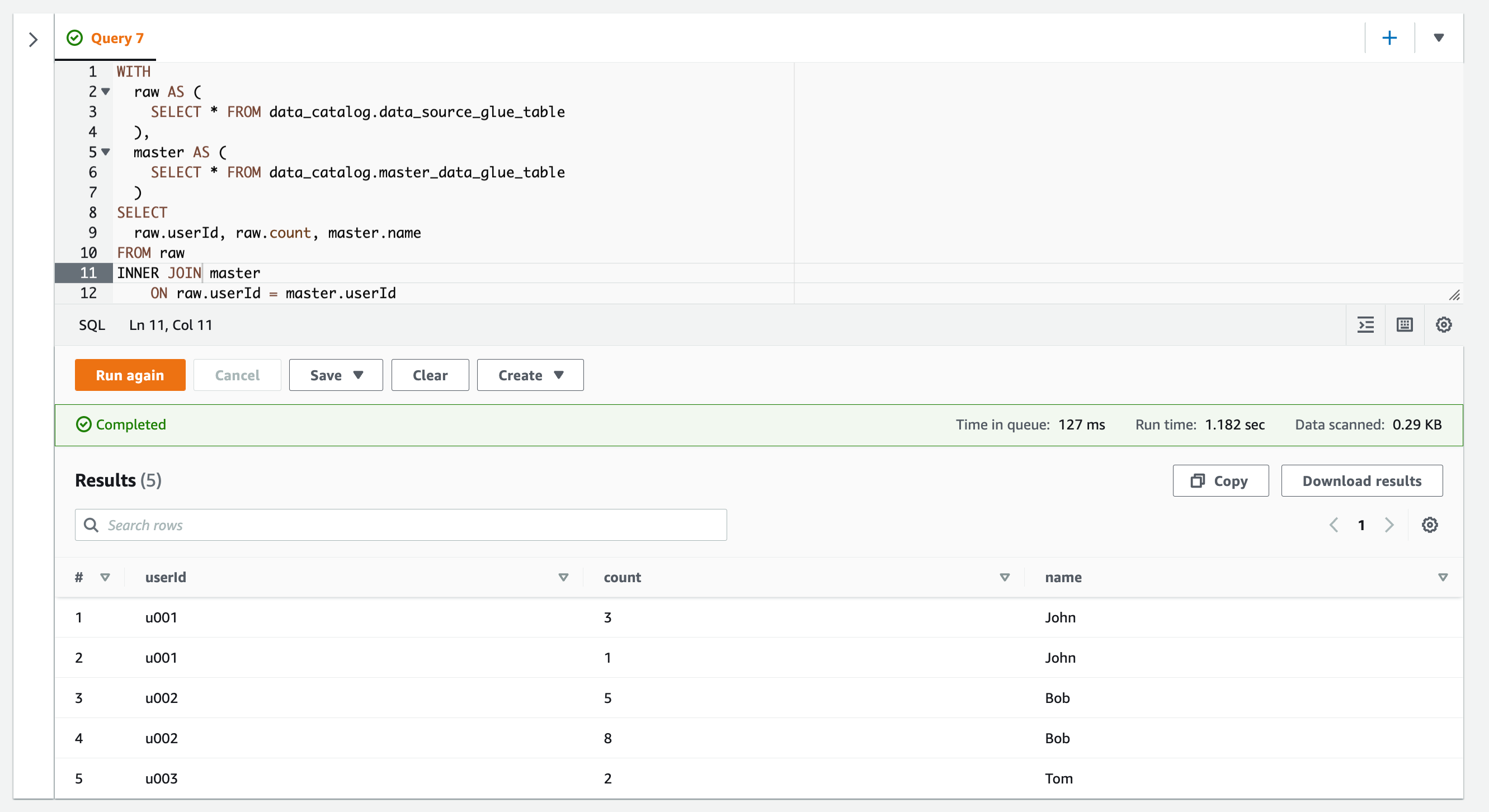
rawおよびmasterのいずれのテーブルにもあるレコードのみ取得できています。
| # | userId | count | name |
|---|---|---|---|
| 1 | u001 | 3 | John |
| 2 | u001 | 1 | John |
| 3 | u002 | 5 | Bob |
| 4 | u002 | 8 | Bob |
| 5 | u003 | 2 | Tom |
ちなみに、単にJOINと指定しても既定でINNER JOINとなるので、同じ結果を得ることができます。
LEFT JOIN
LEFT JOINを使用すると、JOIN句の左辺のテーブルのみにあるレコードが結合結果として取得されます。
クエリを実行した様子です。
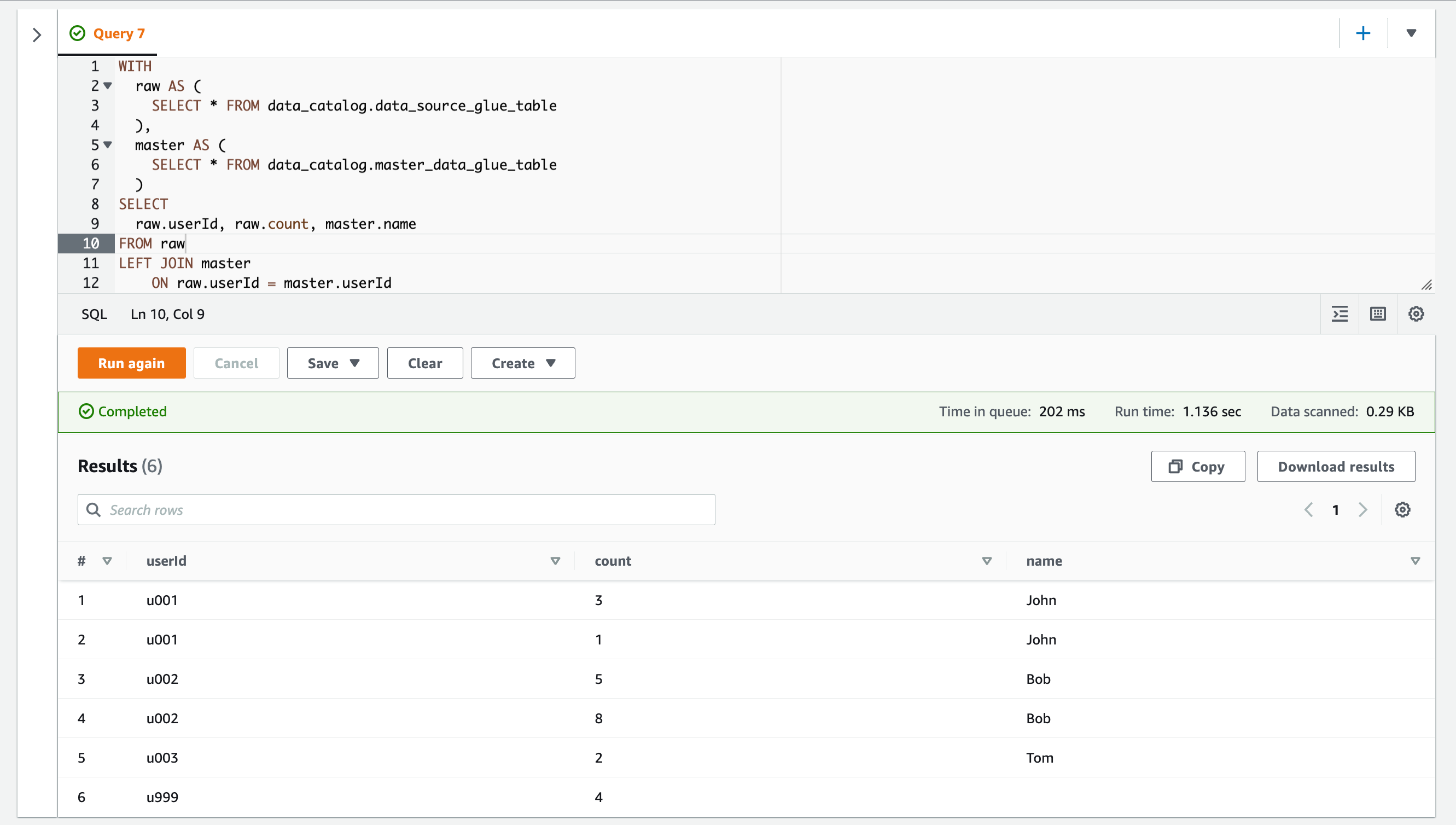
左辺のrawテーブルにあるレコードのみ取得できています。
| # | userId | count | name |
|---|---|---|---|
| 1 | u001 | 3 | John |
| 2 | u001 | 1 | John |
| 3 | u002 | 5 | Bob |
| 4 | u002 | 8 | Bob |
| 5 | u003 | 2 | Tom |
| 6 | u999 | 4 |
ちなみにLEFT JOINはLEFT OUTER JOINの略となり、いずれの指定でも同じ結果を得ることができます。
RIGHT JOIN
RIGHT JOINを使用すると、JOIN句の右辺のテーブルのみにあるレコードが結合結果として取得されます。
クエリを実行した様子です。
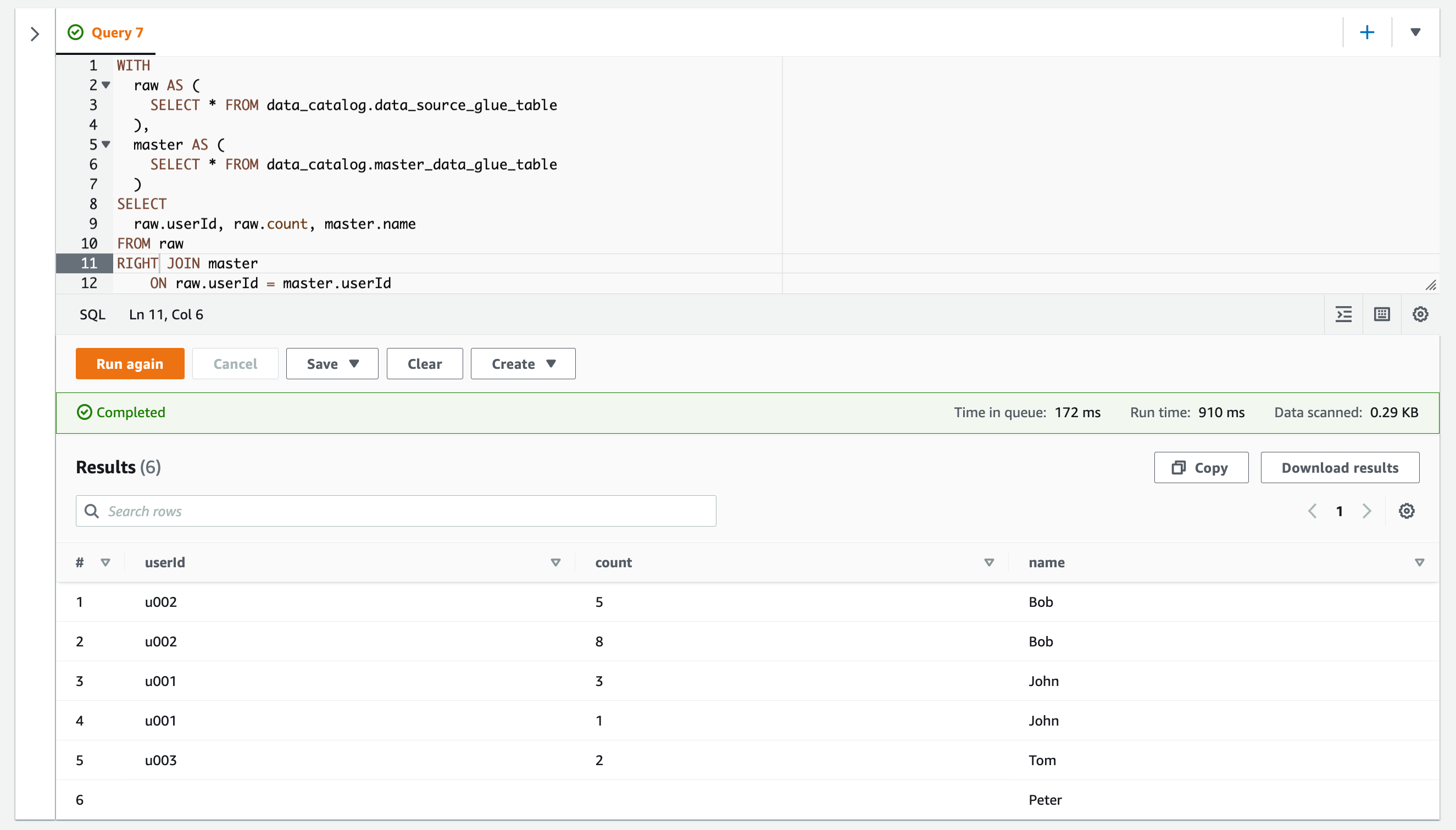
右辺のmasterテーブルにあるレコードのみ取得できています。
| # | userId | count | name |
|---|---|---|---|
| 1 | u002 | 5 | Bob |
| 2 | u002 | 8 | Bob |
| 3 | u001 | 3 | John |
| 4 | u001 | 1 | John |
| 5 | u003 | 2 | Tom |
| 6 | Peter |
ちなみにRIGHT JOINについてもRIGHT OUTER JOINの略となり、いずれの指定でも同じ結果を得ることができます。
FULL JOIN
FULL JOINを使用すると、JOIN句の右辺および左辺テーブル上のすべてのレコードが結合結果として取得されます。
クエリを実行した様子です。
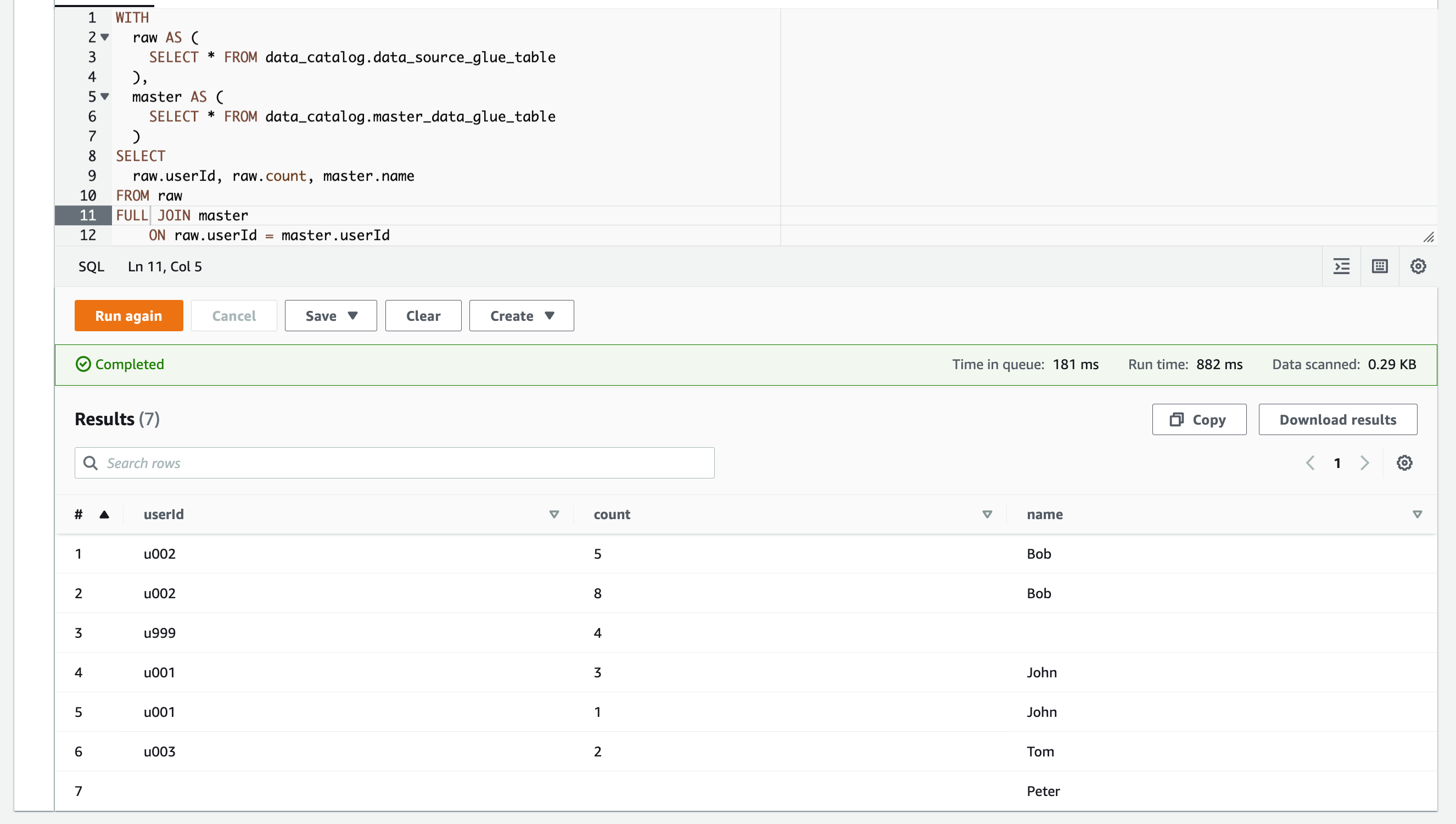
左辺のrawまたは右辺のmasterのテーブルにあるレコードがすべて取得できています。
| # | userId | count | name |
|---|---|---|---|
| 1 | u002 | 5 | Bob |
| 2 | u002 | 8 | Bob |
| 3 | u999 | 4 | |
| 4 | u001 | 3 | John |
| 5 | u001 | 1 | John |
| 6 | u003 | 2 | Tom |
| 7 | Peter |
ベン図で表した場合
INNER JOIN(JOIN)、FULL JOIN、LEFT JOIN、RIGHT JOINをそれぞれベン図で表すと次のようになります。一目瞭然で覚えやすいですね。

types - SQL JOIN - Dofactoryより
おわりに
Amazon Athenaでの各種Join処理の動作を改めて確認してみました。
これでもうJOINも怖くありませんね。
参考
以上







