
AWS Step FunctionsからAmazon AthenaでINSERT INTOクエリを実行してみた
2022.08.03
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部 IoT事業部の若槻です。
Amazon Athenaでは、INSERT INTOクエリによりテーブルに対して新規レコードを追加することができます。
今回は、AWS Step FunctionsからAmazon AthenaでINSERT INTOクエリを実行してみました。
やってみた
実装
AWS CDK v2(TypeScript)で次のようなCDKスタックを作成します。
lib/process-stack.ts
import { Construct } from 'constructs';
import {
aws_s3,
aws_athena,
aws_stepfunctions,
aws_stepfunctions_tasks,
aws_glue,
aws_iam,
RemovalPolicy,
Stack,
StackProps,
} from 'aws-cdk-lib';
import * as glue_alpha from '@aws-cdk/aws-glue-alpha';
export class ProcessStack extends Stack {
constructor(scope: Construct, id: string, props: StackProps) {
super(scope, id, props);
// データソース格納バケット
const dataBucket = new aws_s3.Bucket(this, 'dataBucket', {
bucketName: `data-${this.account}-${this.region}`,
removalPolicy: RemovalPolicy.DESTROY,
});
// Athenaクエリ結果格納バケット
const athenaQueryResultBucket = new aws_s3.Bucket(
this,
'athenaQueryResultBucket',
{
bucketName: `athena-query-result-${this.account}`,
removalPolicy: RemovalPolicy.DESTROY,
}
);
// データカタログ
const dataCatalog = new glue_alpha.Database(this, 'dataCatalog', {
databaseName: 'data_catalog',
});
// データカタログテーブル
const dataCatalogTable = new glue_alpha.Table(this, 'dataCatalogTable', {
tableName: 'data_catalog_table',
database: dataCatalog,
bucket: dataBucket,
s3Prefix: 'data/',
dataFormat: glue_alpha.DataFormat.JSON,
columns: [
{
name: 'id',
type: glue_alpha.Schema.STRING,
},
{
name: 'count',
type: glue_alpha.Schema.INTEGER,
},
],
});
// SerDeを既定のOpenX JSONからHive JSONにオーバーライド
const cfnTable = dataCatalogTable.node.defaultChild as aws_glue.CfnTable;
cfnTable.addPropertyOverride(
'TableInput.StorageDescriptor.SerdeInfo.SerializationLibrary',
glue_alpha.SerializationLibrary.HIVE_JSON.className
);
// Athenaワークグループ
const athenaWorkGroup = new aws_athena.CfnWorkGroup(
this,
'athenaWorkGroup',
{
name: 'athenaWorkGroup',
workGroupConfiguration: {
resultConfiguration: {
outputLocation: `s3://${athenaQueryResultBucket.bucketName}/result-data`,
},
},
recursiveDeleteOption: true,
}
);
// JSON ArrayをINSERT INTOクエリで指定可能な形式に変換
const getInsertedValuesTask =
new aws_stepfunctions_tasks.EvaluateExpression(
this,
'getInsertedValuesTask',
{
expression: aws_stepfunctions.JsonPath.format(
`{}.map( d => "('" + d.id + "'," + d.count + ")").join(',')`,
aws_stepfunctions.JsonPath.stringAt('$.input.records')
),
resultPath: '$.getInsertedValuesTaskOutPut',
}
);
// Athenaクエリ実行
const startAthenaQueryExecutionTask =
new aws_stepfunctions_tasks.AthenaStartQueryExecution(
this,
'startAthenaQueryExecutionTask',
{
queryString: aws_stepfunctions.JsonPath.format(
`INSERT INTO "${dataCatalog.databaseName}"."${dataCatalogTable.tableName}" VALUES {}`,
aws_stepfunctions.JsonPath.stringAt('$.getInsertedValuesTaskOutPut')
),
workGroup: athenaWorkGroup.name,
integrationPattern: aws_stepfunctions.IntegrationPattern.RUN_JOB,
resultPath: '$.startAthenaQueryExecutionTaskOutPut',
}
);
// State Machine
const stateMachine = new aws_stepfunctions.StateMachine(
this,
'stateMachine',
{
stateMachineName: 'stateMachine',
definition: getInsertedValuesTask.next(startAthenaQueryExecutionTask),
}
);
// Glue Data Catalogリソースへのアクセス権をState Machineに追加
stateMachine.role.addToPrincipalPolicy(
new aws_iam.PolicyStatement({
actions: ['glue:Get*', 'glue:List*'],
effect: aws_iam.Effect.ALLOW,
resources: [dataCatalog.databaseArn, dataCatalogTable.tableArn],
})
);
}
}
glue_alpha.Tableクラスで既定のJSON SerDeとなるOpenX JSON SerDeはINSERT INTOクエリに非対応なので、プロパティをオーバーライドしてHive JSON SerDeとしています。- INSERT対象のレコードはJSON Array形式でInputや前段のタスクのレスポンスから取得される想定です。しかしINSERTクエリではレコードを
(col1value,col2value,...)[,(col1value,col2value,...)][,...]という形式で指定する必要があるのでaws_stepfunctions_tasks.EvaluateExpressionで形式変換を行っています。
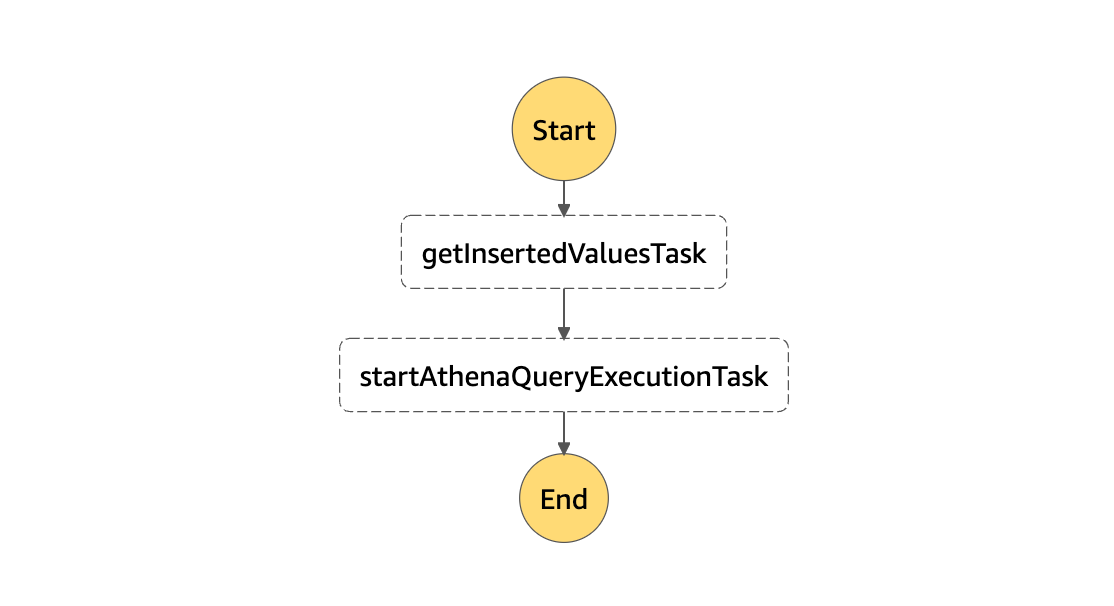
上記をCDK Deployしてスタックをデプロイします。すると次のようなDefinitionのState Machineが作成されます。
Definition
{
"StartAt": "getInsertedValuesTask",
"States": {
"getInsertedValuesTask": {
"Next": "startAthenaQueryExecutionTask",
"Type": "Task",
"ResultPath": "$.getInsertedValuesTaskOutPut",
"Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXXXXXX:function:ProcessStack-Evalda2d1181604e4a4586941a6abd7fe42dF-2nzgHa97p3jq",
"Parameters": {
"expression.$": "States.Format('{}.map( d => \"(\\'\" + d.id + \"\\',\" + d.count + \")\").join(\\',\\')', $.input.records)",
"expressionAttributeValues": {}
}
},
"startAthenaQueryExecutionTask": {
"End": true,
"Type": "Task",
"ResultPath": "$.startAthenaQueryExecutionTaskOutPut",
"Resource": "arn:aws:states:::athena:startQueryExecution.sync",
"Parameters": {
"QueryString.$": "States.Format('INSERT INTO \"data_catalog\".\"data_catalog_table\" VALUES {}', $.getInsertedValuesTaskOutPut)",
"ResultConfiguration": {},
"WorkGroup": "athenaWorkGroup"
}
}
}
}
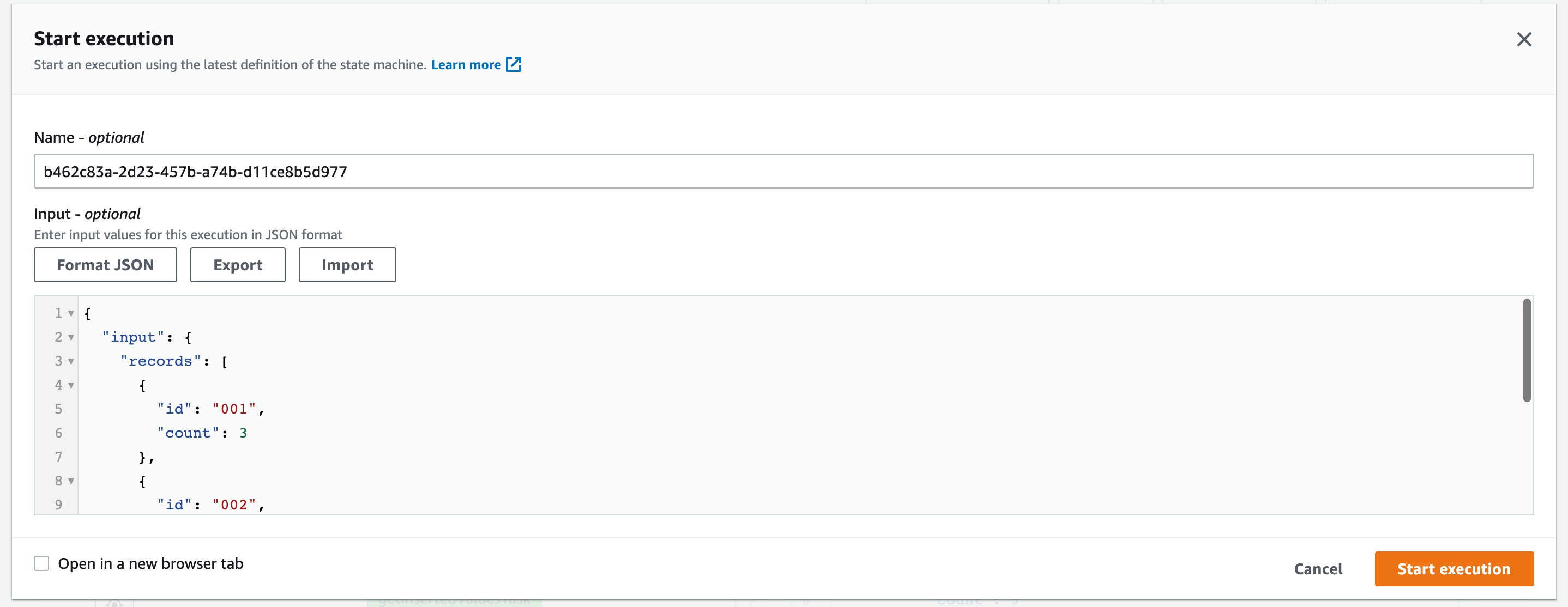
動作確認
次のInputを指定してState Machineを実行します。
Input
{
"input": {
"records": [
{
"id": "001",
"count": 3
},
{
"id": "002",
"count": 5
},
{
"id": "003",
"count": 1
}
]
}
}
実行が成功しました。
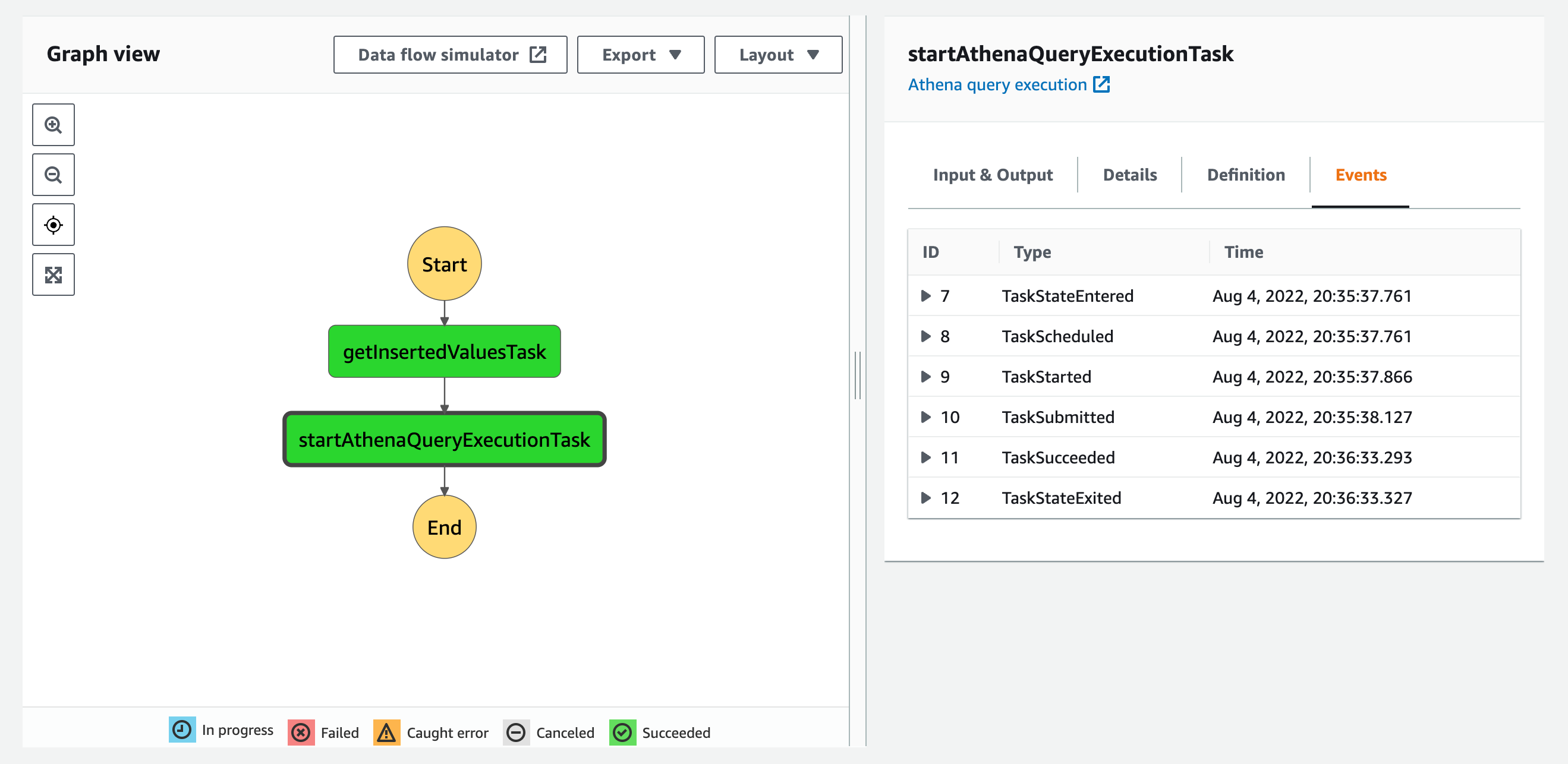
State Machineから実行されたクエリは以下になります。
INSERT INTO "data_catalog"."data_catalog_table" VALUES ('001',3),('002',5),('003',1)
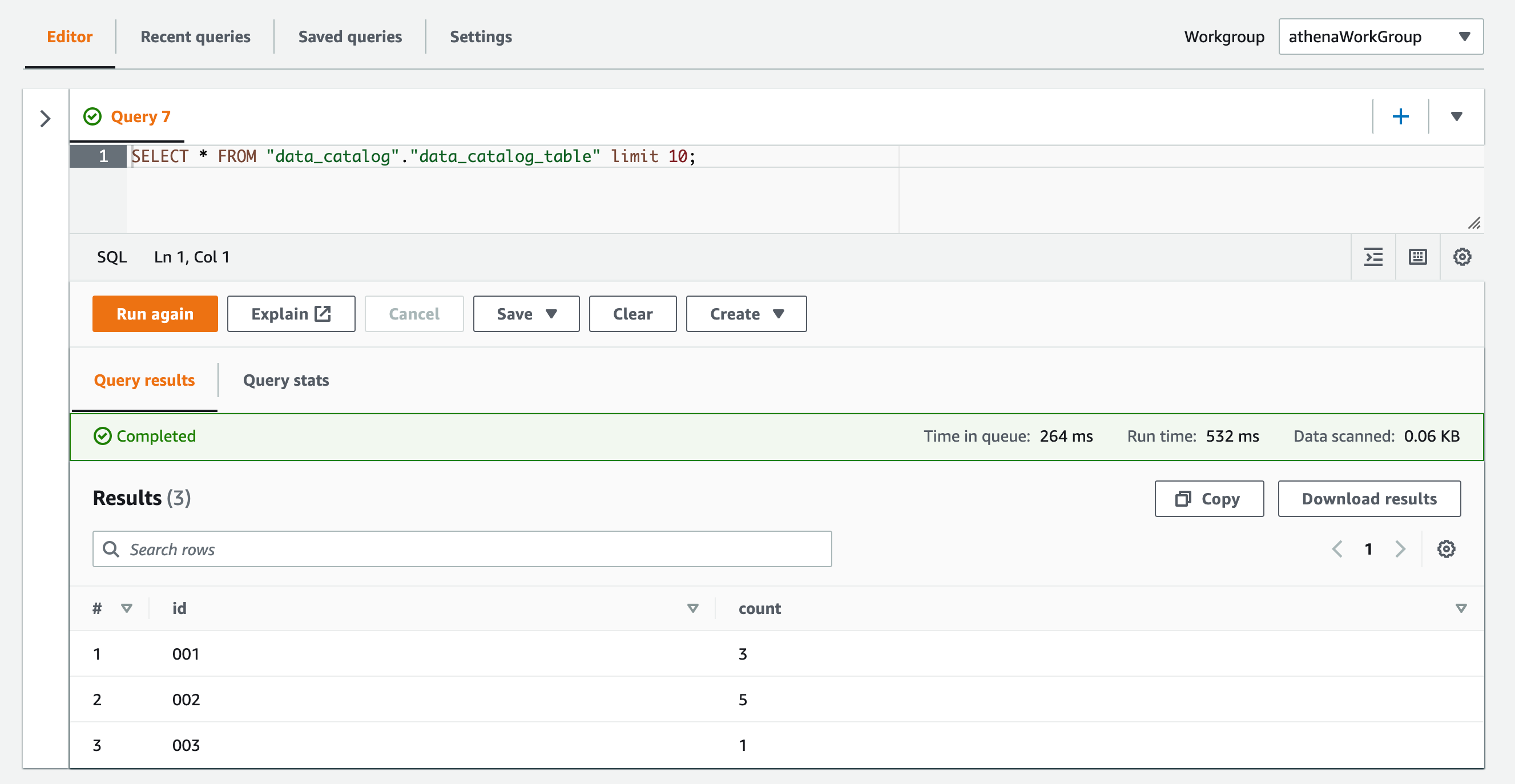
テーブルに対してSELECTクエリを実行すると、データを取得することができました。レコードがちゃんとINSERTされていますね!
おわりに
AWS Step FunctionsからAmazon AthenaでINSERT INTOクエリを実行してみました。
以前にAWS Step FunctionsでJSON LinesデータをS3 BucketにPut Objectしようとして出来なかったことがありましたが、複数件のレコードをS3バケットに格納したいのであればのAthenaのINSERTクエリを使用する方法を使うべきでしたね。
参考
- [aws-glue] glue.DataFormat.TSV is broken · Issue #11239 · aws/aws-cdk
- class SerializationLibrary · AWS CDK
- AWS Step FunctionsでAthenaクエリ実行の開始および結果取得をしてみた(AWS CDK v2) | DevelopersIO
- Amazon AthenaでINSERT INTOクエリが”HIVE_UNSUPPORTED_FORMAT”エラーとなる際の対処 | DevelopersIO
- [AWS Step Functions / AWS CDK] EvaluateExpressionタスクを使って配列の操作(要素追加、結合、Map処理など)をしてみた | DevelopersIO
以上









