
Amazon Bedrock + Lambda로 문서 요약해 S3에 저장하기
안녕하세요 클래스메소드 김재욱(Kim Jaewook) 입니다. 이번 블로그에서는 Amazon Bedrock + Lambda로 문서를 요약해 S3에 저장하는 방법을 정리해 봤습니다.
IAM 정책 설정
먼저 Lambda에 연결할 IAM 역할을 생성합니다. 정책은 다음과 같습니다.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"bedrock:InvokeModel",
"bedrock:InvokeModelWithResponseStream"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::S3 버킷명"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::S3 버킷명/*"
}
]
}
bedrock:InvokeModel→ Lambda에서 Bedrock 모델을 호출할 수 있는 권한bedrock:InvokeModelWithResponseStream→ 스트리밍 응답을 받을 수 있는 권한 (Claude 모델처럼 긴 답변 처리 가능)Resource: "*"→ 모든 Bedrock 모델에 대해 호출 허용s3:ListBucket→ 버킷 안의 객체 목록을 조회 가능- Lambda에서
Prefix를 사용해 특정 폴더(예: documents/) 문서 목록을 가져오기 위해 필요 Resource는 버킷 자체 ARN(arn:aws:s3:::버킷명) → 객체가 아니라 버킷 단위 권한s3:GetObject→ S3 객체(파일) 읽기 권한s3:PutObject→ S3 객체(파일) 쓰기 권한/*→ 버킷 안 모든 객체에 대해 접근 가능, 버킷 자체에는 접근 X- 예: documents/example.txt 읽기/쓰기 가능
S3 버킷에 문서 업로드
S3 버킷에 분석을 위한 텍스트 파일을 업로드합니다. 텍스트 파일의 이름은 example.txt로 지정했습니다.
# ABC Tech 사내 운영 매뉴얼 (Internal Policy v1.0)
## 1. 회사 기본 정보
* 회사명: ABC Tech
* 설립연도: 2021년
* 주요 서비스: SaaS 기반 업무 관리 플랫폼
---
## 2. 근무 시간 정책
* 기본 근무 시간: 오전 9시 ~ 오후 6시
* 점심 시간: 12시 ~ 1시
* 유연 근무제:
* 출근: 오전 8시 ~ 10시 사이 선택 가능
* 퇴근: 출근 시간 기준 9시간 후
---
## 3. 휴가 정책
* 연차 휴가: 연 15일
* 반차: 0.5일 단위 사용 가능
* 병가:
* 연 최대 10일
* 3일 이상 시 진단서 필요
---
## 4. 재택근무 정책
* 주 2회까지 가능
* 사전 승인 필수
* 긴급 상황 시 추가 허용 가능
---
## 5. 환불 정책 (고객 대상)
* 구매 후 7일 이내: 100% 환불 가능
* 7일 이후: 환불 불가
* 단, 서비스 장애 발생 시 예외적으로 환불 가능
---
## 6. 보안 정책
* 모든 직원은 2단계 인증(2FA)을 사용해야 함
* 외부 저장장치 사용 금지
* 회사 데이터는 승인된 클라우드에만 저장
---
## 7. IT 자원 사용 정책
* 개인 용도의 과도한 사용 금지
* 불법 소프트웨어 설치 금지
* 회사 계정 공유 금지
---
## 8. 문의 및 지원
* IT 지원: [it-support@abctech.com](mailto:it-support@abctech.com)
* 인사팀: [hr@abctech.com](mailto:hr@abctech.com)
---
## 9. 징계 규정
* 보안 위반: 1차 경고, 2차 정직
* 무단 결근: 3회 시 해고 가능
---
## 10. 기타
* 본 정책은 2026년 1월 1일부터 적용
* 회사 정책은 필요 시 변경될 수 있음
Lambda 생성
런타임은 Python 3.14을 선택했고, 해당 Lambda에 IAM 역할도 지정해 줍니다.
import boto3
import json
import uuid
from typing import List
bedrock = boto3.client("bedrock-runtime", region_name="ap-northeast-1")
s3 = boto3.client("s3")
BUCKET_NAME = "YOUR_BUCKET_NAME"
CLAUDE_MODEL_ID = "jp.anthropic.claude-sonnet-4-6"
MAX_CHARS_PER_DOC = 2000
TOP_K = 3
def embed_text(text: str) -> List[float]:
return [float(ord(c)) for c in text[:128]]
def cosine_similarity(v1: List[float], v2: List[float]) -> float:
dot = sum(a*b for a,b in zip(v1,v2))
norm1 = sum(a*a for a in v1) ** 0.5
norm2 = sum(b*b for b in v2) ** 0.5
return dot / (norm1*norm2 + 1e-10)
def read_s3_object(bucket: str, key: str) -> str:
resp = s3.get_object(Bucket=bucket, Key=key)
body = resp["Body"].read()
for enc in ["utf-8", "cp949", "latin1"]:
try:
return body.decode(enc)
except UnicodeDecodeError:
continue
return body.decode("utf-8", errors="ignore")
def load_documents_from_s3() -> List[dict]:
prefixes = ["documents/", ""]
docs = []
for prefix in prefixes:
objects = s3.list_objects_v2(Bucket=BUCKET_NAME, Prefix=prefix)
for obj in objects.get("Contents", []):
key = obj["Key"]
if key.endswith("/"):
continue
content = read_s3_object(BUCKET_NAME, key)
docs.append({"key": key, "text": content, "embedding": embed_text(content)})
return docs
def lambda_handler(event, context):
session_id = str(uuid.uuid4())
user_question = event.get("message", "이 문서를 3줄로 요약해줘")
try:
documents = load_documents_from_s3()
if not documents:
return {
"statusCode": 400,
"body": json.dumps({
"error": "S3에서 문서를 찾을 수 없습니다. documents/ 폴더 또는 루트에 텍스트 파일을 업로드하세요."
}, ensure_ascii=False)
}
question_vec = embed_text(user_question)
documents_sorted = sorted(documents, key=lambda d: cosine_similarity(d["embedding"], question_vec), reverse=True)
top_docs_text = "\n\n".join([d["text"][:MAX_CHARS_PER_DOC] for d in documents_sorted[:TOP_K]])
source_keys = [d["key"] for d in documents_sorted[:TOP_K]]
prompt = f"다음 문서를 읽고 질문에 답해 주세요:\n\n{top_docs_text}\n\n질문: {user_question}\n답변:"
request_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1024,
"system": "당신은 한국어로만 답변하는 AI 어시스턴트입니다. 항상 한국어로 답변하세요.",
"messages": [{"role": "user", "content": prompt}]
}
response = bedrock.invoke_model(
modelId=CLAUDE_MODEL_ID,
body=json.dumps(request_body)
)
response_body = json.loads(response["body"].read())
answer = response_body["content"][0]["text"]
object_key = f"bedrock-results/{session_id}.json"
s3.put_object(
Bucket=BUCKET_NAME,
Key=object_key,
Body=json.dumps({
"question": user_question,
"answer": answer,
"source_docs": source_keys
}, ensure_ascii=False)
)
return {
"statusCode": 200,
"body": json.dumps({
"message": "Claude 기반 RAG 결과 S3에 저장 완료",
"s3_object_key": object_key,
"answer": answer,
"source_docs": source_keys
}, ensure_ascii=False)
}
except Exception as e:
return {
"statusCode": 500,
"body": json.dumps({"error": str(e)})
}
마지막으로 구성에서 제한 시간을 늘려줍니다. 최소 5초 이상 시간 소모하기 때문에 디폴트 값인 3을 지정하면 에러가 발생합니다.
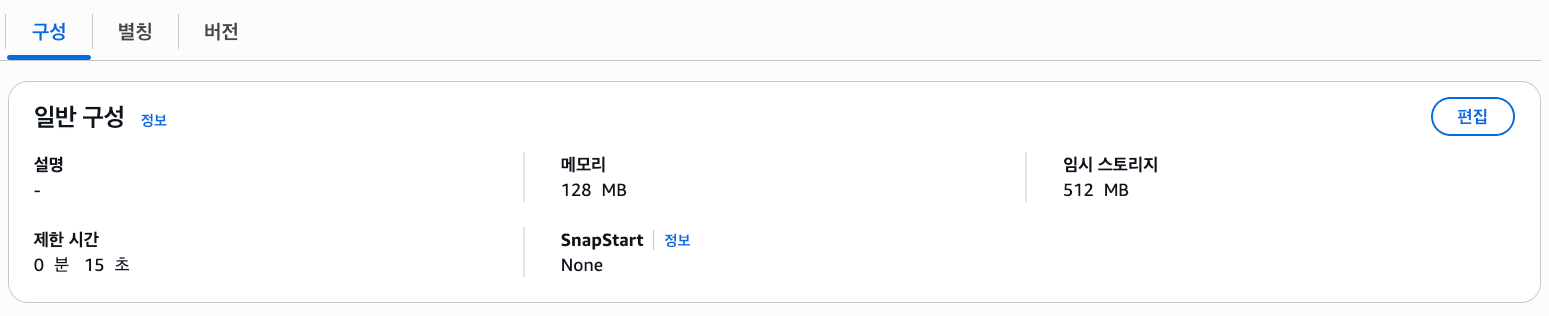
결과 확인
Lambda를 실행하면 아래와 같은 결과 값이 출력됩니다.
Response:
{
"statusCode": 200,
"body": "{\"message\": \"Claude 기반 RAG 결과 S3에 저장 완료\", \"s3_object_key\": \"bedrock-results/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxx.json\", \"answer\": \"## 문서 요약\\n\\n1. **ABC Tech**는 2021년 설립된 SaaS 기반 업무 관리 플랫폼 회사로, 유연 근무제·재택근무(주 2회)·연차 15일 등 직원 친화적 근무 환경을 운영합니다.\\n\\n2. **보안 및 IT 정책**으로 2단계 인증(2FA) 의무화, 외부 저장장치 사용 금지, 불법 소프트웨어 설치 금지 등 엄격한 내부 규정을 적용합니다.\\n\\n3. **고객 환불**은 구매 후 7일 이내에만 가능하며, 보안 위반이나 무단 결근 등 규정 위반 시 경고·정직·해고 등의 징계가 적용되고, 본 정책은 **2026년 1월 1일부터 시행**됩니다.\", \"source_docs\": [\"example.txt\"]}"
}
S3 버킷도 확인해 보면 [bedrock-results/] 경로에 json 파일이 생성된 것을 확인할 수 있습니다.
json 내부는 다음과 같이 문서를 요약한 내용이 들어가 있습니다.
{"question": "이 문서를 3줄로 요약해줘", "answer": "## 문서 요약\n\n1. **ABC Tech**는 2021년 설립된 SaaS 기반 업무 관리 플랫폼 회사로, 유연 근무제·재택근무(주 2회)·연차 15일 등의 근무 정책을 운영합니다.\n\n2. **보안 및 IT 정책**으로 2단계 인증(2FA) 필수, 외부 저장장치 사용 금지, 불법 소프트웨어 설치 금지 등을 규정하고 있으며, 위반 시 경고·정직 등의 징계가 부과됩니다.\n\n3. **고객 환불 정책**은 구매 후 7일 이내 100% 환불 가능하며, 본 정책 전반은 **2026년 1월 1일부터 적용**됩니다.", "source_docs": ["example.txt"]}
마무리
이번 블로그에서는 Amazon Bedrock과 AWS Lambda, S3를 활용하여 문서를 자동으로 요약하고, 그 결과를 다시 S3에 저장하는 과정을 자세히 살펴보았습니다.
핵심 포인트를 정리하면, 먼저 Lambda에서 Bedrock Claude 모델을 호출하여 질문을 전달하고, S3에 저장된 문서를 불러와 간단한 RAG(유사 문서 기반 질의) 방식을 적용했습니다. 이를 통해 모델이 질문에 적합한 문서를 참고하도록 하고, 최종적으로 요약된 답변을 JSON 파일 형태로 S3에 저장했습니다.
이 과정을 통해 얻을 수 있는 장점은 명확합니다. 문서량이 많거나, 수동으로 정리하기 어려운 내부 정책, 매뉴얼, 보고서 등도 모델을 활용해 빠르게 요약할 수 있고, 그 결과를 안전하게 S3에 보관하여 필요할 때 언제든 조회할 수 있습니다. 또한, Lambda를 활용해 자동화함으로써 반복적인 작업을 최소화하고, Bedrock 모델을 직접 호출하는 구조로 인해 별도의 지식 기반(Knowledge Base) 없이도 문서 요약이 가능하다는 점도 중요한 특징입니다.
이번 실습을 통해 확인할 수 있었던 점은, S3 문서 관리와 모델 호출 권한(IAM 정책) 설정이 얼마나 중요한지였습니다. 권한이 제대로 설정되지 않으면 Lambda에서 모델 호출이나 S3 파일 읽기/쓰기 과정에서 쉽게 에러가 발생할 수 있기 때문에, 정책 구성에 꼼꼼히 신경 써야 합니다. 또한, 모델 호출 시 문서 크기나 토큰 수 제한을 고려해 적절히 분할하거나 Top-K 방식으로 문서를 선택하는 전략도 필수적입니다.
결과적으로, Bedrock과 Lambda, S3를 결합한 워크플로우는 간단하면서도 확장성이 높은 문서 요약 솔루션을 구축할 수 있다는 점을 보여주었습니다. 모델 호출, S3 연동, Lambda 실행까지 한 번에 이해하고 적용할 수 있다는 점에서, AWS 환경에서 실무용 자동화 파이프라인을 설계하는 데 좋은 예시가 될 수 있습니다.
이번 포스팅에서 다룬 코드를 따라 해보면, 사내 문서 자동 요약이나 정책 문서 정리, 고객 문의 문서 요약 등 다양한 업무에 바로 적용할 수 있는 기반을 만들 수 있습니다.










