
블로그 릴레이 - Amazon S3 Vectors 사용해보기
안녕하세요! 제조 비즈니스 테크놀로지부의 이병현입니다.
본 블로그는 당사의 한국어 블로그 릴레이의 2025년 33번째 블로그입니다.
이번 블로그의 주제는 「Amazon S3 Vectors 사용해보기」 입니다.
Amazon S3 Vectors 란?
Amazon S3에서 벡터 데이터를 저장하고 쿼리할 수 있는 서비스입니다.
임베딩된 데이터를 저장하고, 쿼리하려면 보통 벡터 데이터를 지원하는 스토리지 인프라를 구성하는 등 비용이나 인프라의 관리등이 필요했는데요, 이번에 공개된 Amazon S3 Vectors는 간단한 설정만으로 벡터 데이터를 저장하고 쿼리할 수 있는 매우 유용한 서비스입니다.
2025년 09월 현재는 프리뷰 상태이며, 한국 리전은 지원하고 있지 않습니다.
자세한 사항 및 추후 업데이트는 아래 링크를 참고해 주세요!
사용해보기
Amazon S3 Vectors 는 아래와 같은 흐름으로 사용하게 됩니다.
- 벡터 데이터를 저장할 버킷 생성
- 버킷의 인덱스 생성
- 인덱스에 임베딩된 벡터 데이터 저장
- 버킷의 인덱스에 저장된 벡터 데이터 검색
그러면 버킷 생성부터 시작해 보겠습니다.
참고로, 저는 프리뷰에서 지원하는 미국 버지니아 북부 (us-east-1) 리전에서 사용해보았습니다.
1. 버킷 생성
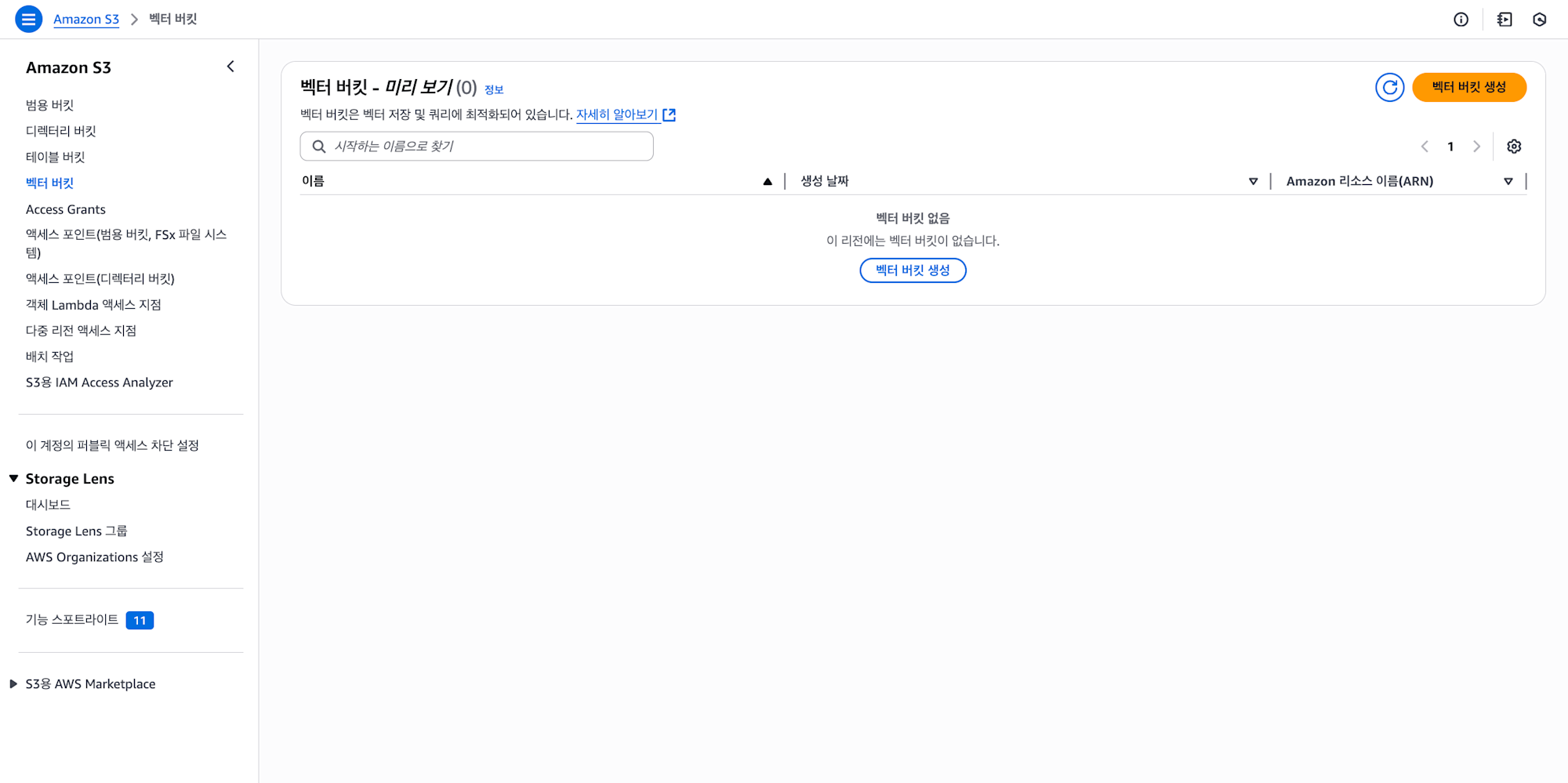
기존의 버킷 생성과는 다르게 벡터 버킷이라는 전용 메뉴에서 버킷을 생성해주시면 됩니다.
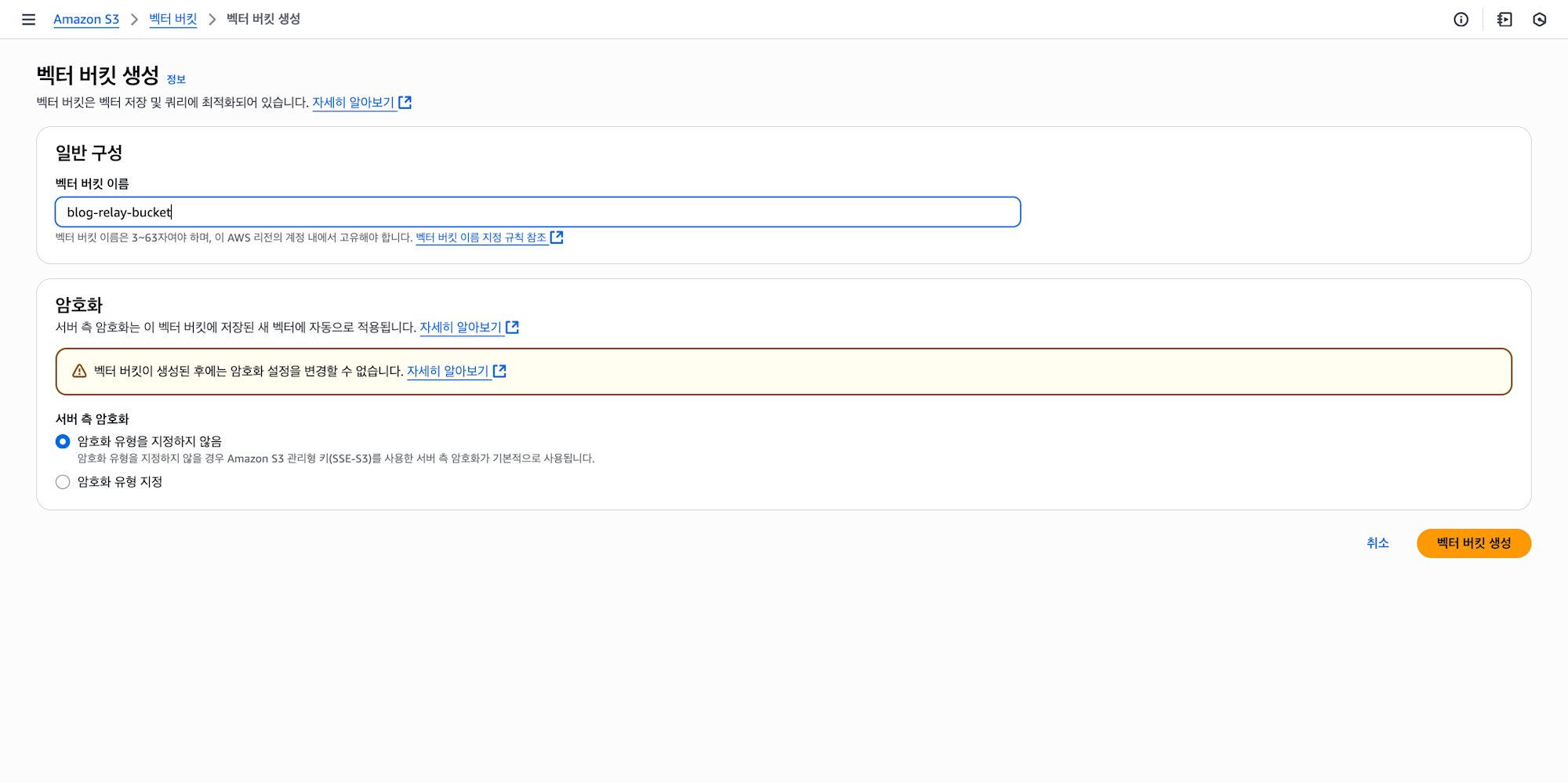
버킷의 이름이나, 암호화는 기존의 S3 와 유사하게 구성되어 있으며 적절한 이름과, 암호화 설정을 선택해주시면 됩니다.
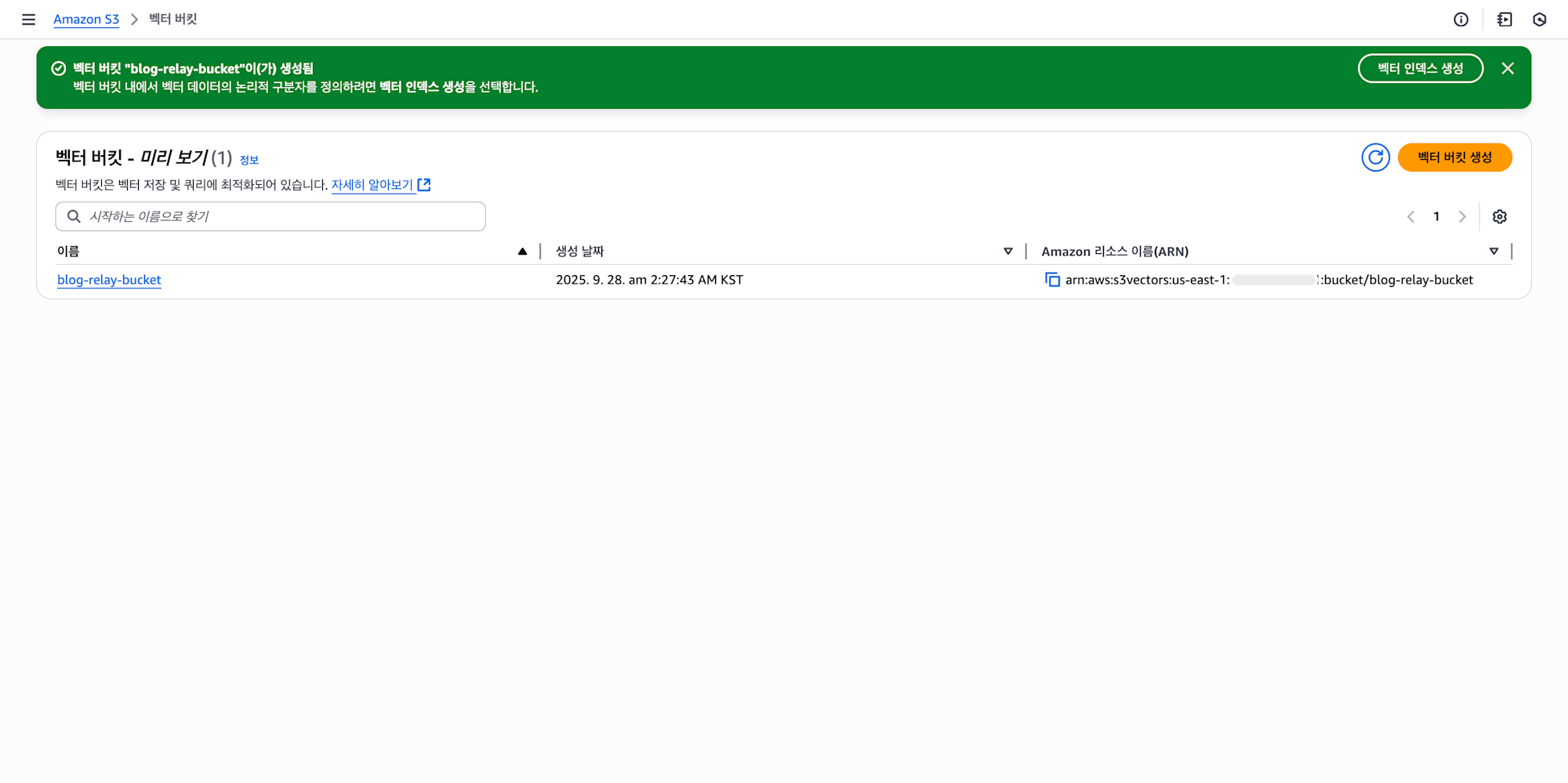
그러면 위처럼 버킷이 잘 생성된 것을 확인하실 수 있습니다!
2. 인덱스 생성
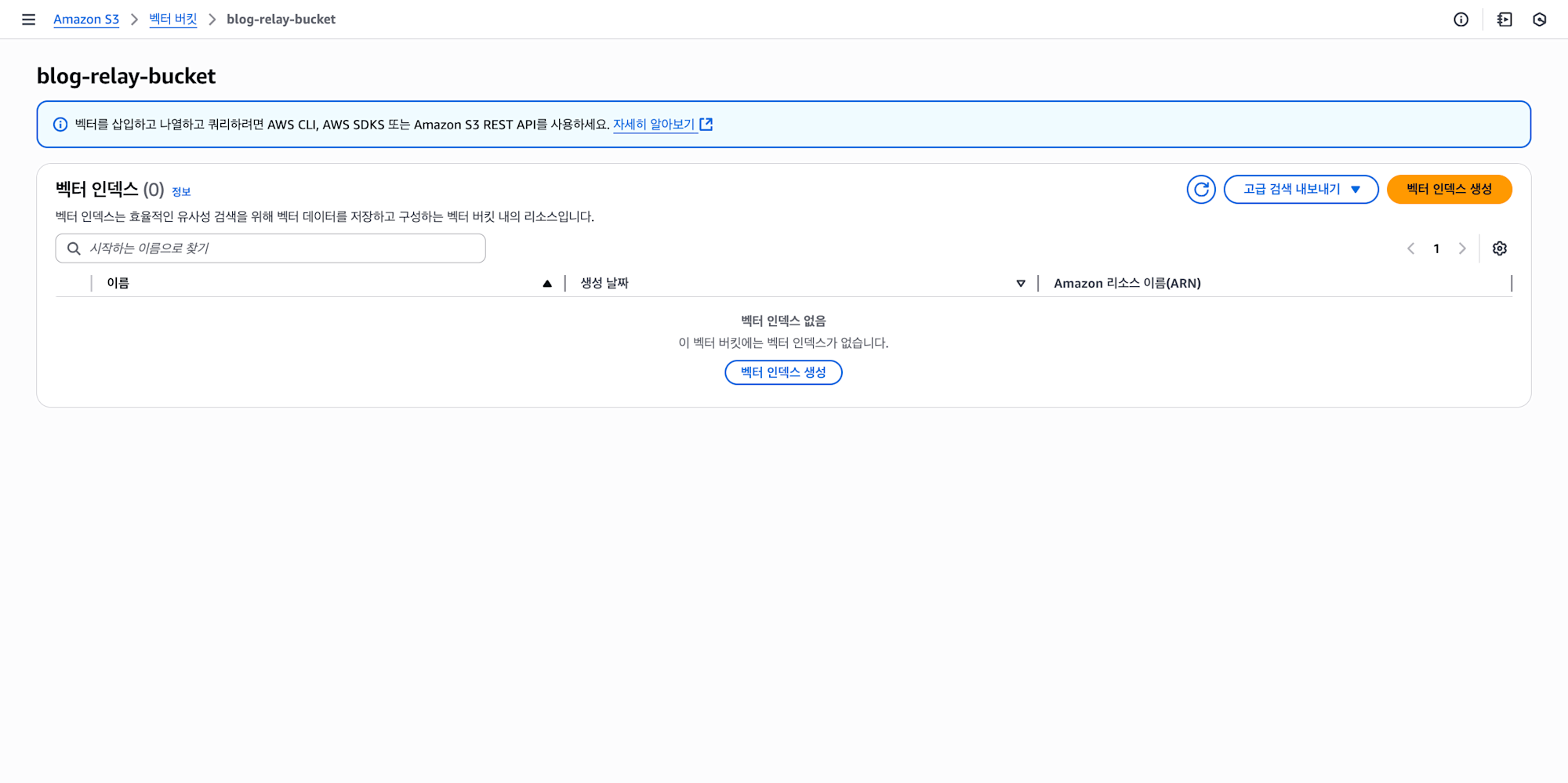
기존의 S3 에서는 버킷에서 디렉토리를 폴더로 나누었다면, 벡터 버킷의 경우 저장과 쿼리를 위해 인덱스로 나누게 됩니다.
그러면 인덱스를 생성해보겠습니다.
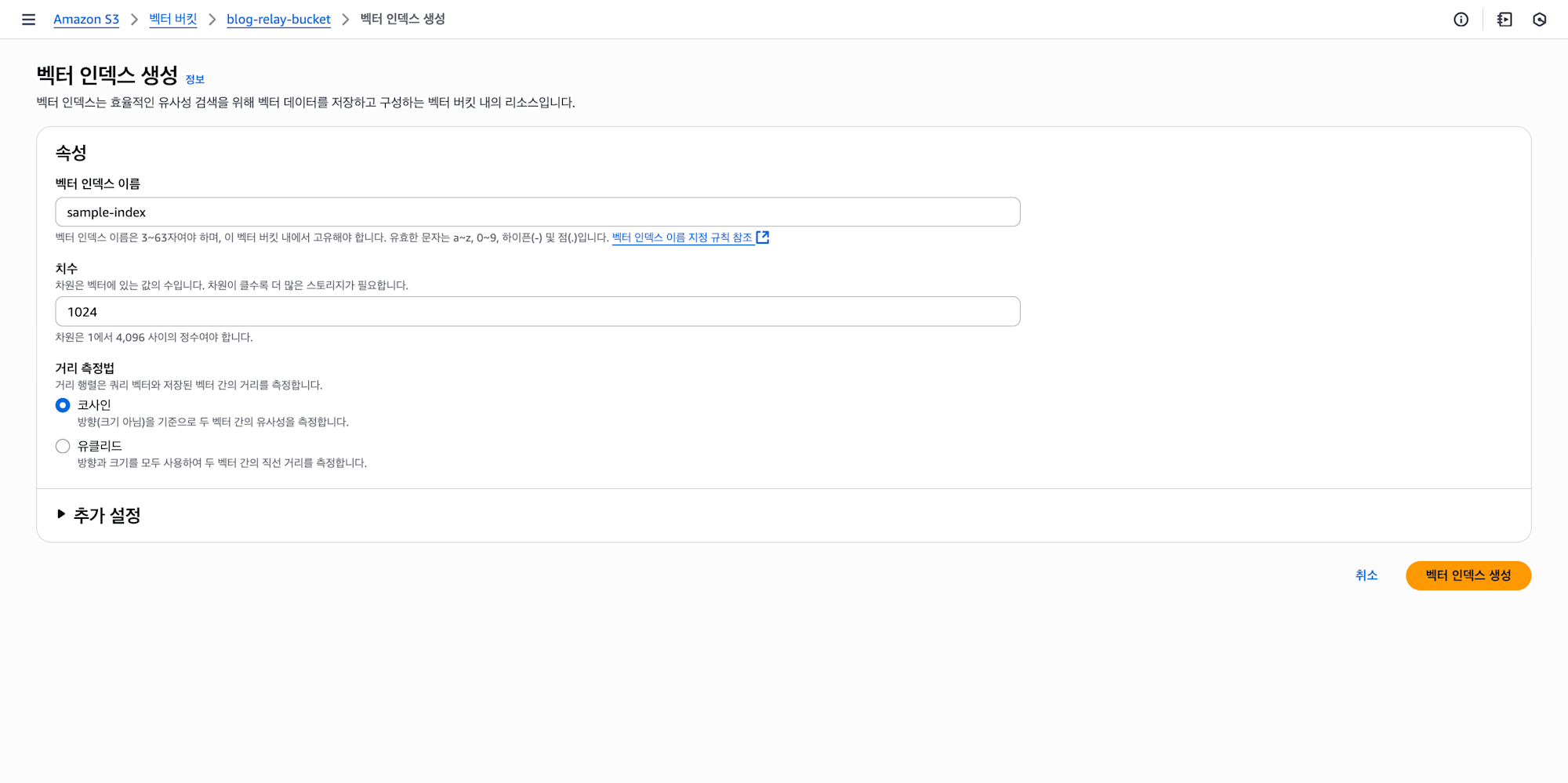
인덱스 이름과 치수(dimensions) 그리고 거리 측정법을 선택할 수 있습니다.
저의 경우 사용할 임베딩 모델에 필요한 1024 치수를 사용하고, 거리 측정은 코사인 유사도를 사용하겠습니다.
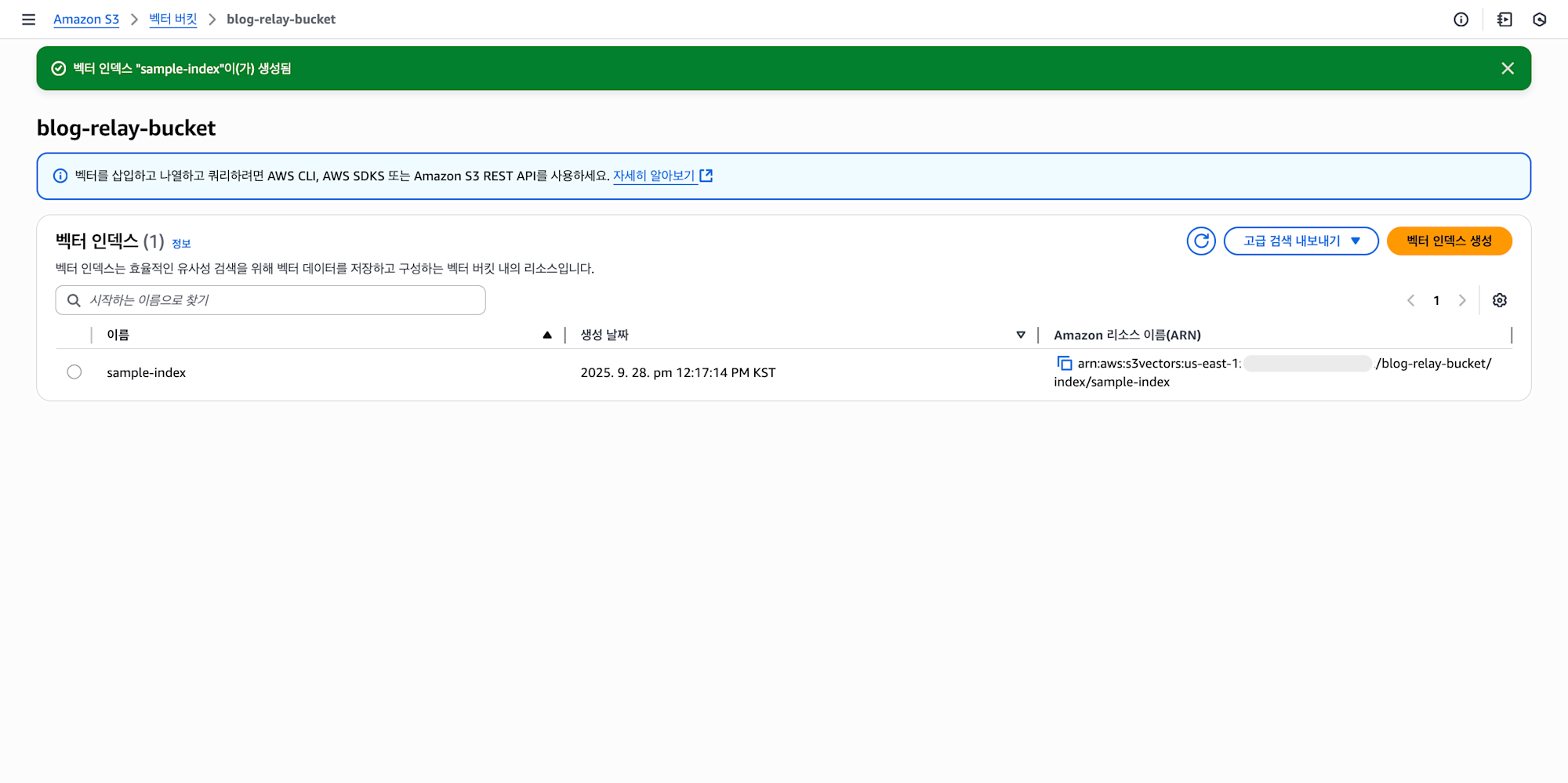
그러면 위와 같이 저희가 설정한 인덱스가 잘 생성되는 것을 확인하실 수 있습니다!
3. 벡터 데이터 저장
그러면, 실제로 만든 인덱스에 텍스트를 임베딩해서 저장해보겠습니다.
예시 문장을 만들고, 해당 문장들을 임베딩 모델을 통해 임베딩하고 얻은 벡터 값을 벡터 버킷의 인덱스에 저장하는 형태입니다.
아래 코드는 공식 문서의 예시 코드를 수정해 사용했습니다.
Inserting vectors into a vector index
import boto3
import json
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
texts = [
"Star Wars: A farm boy joins rebels to fight an evil empire in space",
"Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong",
"Finding Nemo: A father fish searches the ocean to find his lost son"
]
embeddings = []
for text in texts:
print(f"🚀 : vec.py:14: text={text}")
# 입력한 텍스트를 임베딩
response = bedrock.invoke_model(
modelId="amazon.titan-embed-text-v2:0",
body=json.dumps({"inputText": text})
)
response_body = json.loads(response["body"].read())
print(f"🚀 : vec.py:20: response_body={response_body["embedding"][0:3]}")
embeddings.append(response_body["embedding"])
# 임베딩을 s3에 추가
s3vectors.put_vectors(
vectorBucketName="blog-relay-bucket",
indexName="sample-index",
vectors=[
{
"key": "Star Wars",
"data": {"float32": embeddings[0]},
"metadata": {"source_text": texts[0], "genre":"scifi"} # 키와 데이터 외에 메타데이터도 추가 가능
},
{
"key": "Jurassic Park",
"data": {"float32": embeddings[1]},
"metadata": {"source_text": texts[1], "genre":"scifi"}
},
{
"key": "Finding Nemo",
"data": {"float32": embeddings[2]},
"metadata": {"source_text": texts[2], "genre":"family"}
}
]
)
위의 코드를 실행해보면, 아래와 같이 해당 텍스트에 대해 임베딩 된 벡터 값을 볼 수 있습니다. (벡터 값은 3개 이후는 생략)
🚀 : vec.py:14: text=Star Wars: A farm boy joins rebels to fight an evil empire in space
🚀 : vec.py:20: response_body=[-0.024966709315776825, 0.03783351927995682, -0.026106879115104675]
🚀 : vec.py:14: text=Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong
🚀 : vec.py:20: response_body=[-0.03530469909310341, 0.05504326894879341, 0.016251258552074432]
🚀 : vec.py:14: text=Finding Nemo: A father fish searches the ocean to find his lost son
🚀 : vec.py:20: response_body=[-0.06587030738592148, 0.07032894343137741, 0.047515518963336945]
실제로 벡터가 추가되었는지 버킷의 벡터 리스트를 아래 커맨드로 확인해보겠습니다.
aws s3vectors list-vectors \
--vector-bucket-name "blog-relay-bucket" \
--index-name "sample-index" \
--segment-count 1 \
--segment-index 0 \
--return-data \
--return-metadata
커맨드가 성공하면 아래와 같이 추가한 벡터들의 리스트를 확인할 수 있습니다.
{
"vectors": [
{
"key": "Star Wars",
"data": {
"float32": [
-0.024966709315776825,
0.03783351927995682,
-0.026106879115104675,
...
]
},
"metadata": {
"genre": "scifi",
"source_text": "Star Wars: A farm boy joins rebels to fight an evil empire in space"
}
},
{
"key": "Jurassic Park",
"data": {
"float32": [
-0.03530469909310341,
0.05504326894879341,
-0.06949643045663834,
...
]
},
"metadata": {
"source_text": "Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong",
"genre": "scifi"
}
},
{
"key": "Finding Nemo",
"data": {
"float32": [
-0.06587030738592148,
0.07032894343137741,
0.047515518963336945,
...
]
},
"metadata": {
"source_text": "Finding Nemo: A father fish searches the ocean to find his lost son",
"genre": "family"
}
}
]
}
4. 벡터 데이터 검색
추가한 벡터 데이터를 검색해보겠습니다.
검색하고 싶은 텍스트를 임베딩 모델로 임베딩하고, 해당 값을 이용하면 쿼리를 하는 형태입니다.
import boto3
import json
bedrock = boto3.client("bedrock-runtime", region_name="us-east-1")
s3vectors = boto3.client("s3vectors", region_name="us-east-1")
input_text = "adventures in space" # 검색하고 싶은 텍스트
# 검색하고 싶은 텍스트를 임베딩
response = bedrock.invoke_model(
modelId="amazon.titan-embed-text-v2:0",
body=json.dumps({"inputText": input_text})
)
model_response = json.loads(response["body"].read())
embedding = model_response["embedding"]
# 임베딩으로 검색
response = s3vectors.query_vectors(
vectorBucketName="blog-relay-bucket",
indexName="sample-index",
queryVector={"float32": embedding},
topK=3,
filter={"genre": "scifi"}, # 메타데이터 필터
returnDistance=True,
returnMetadata=True
)
print(json.dumps(response["vectors"], indent=2))
그러면 아래와 같이 메타데이터로 필터된 결과값 중 검색한 텍스트인 "우주 모험"("adventures in space") 과 가까운 결과값이 나오게 됩니다.
[
{
"key": "Star Wars",
"metadata": {
"genre": "scifi",
"source_text": "Star Wars: A farm boy joins rebels to fight an evil empire in space"
},
"distance": 0.7918925285339355
},
{
"key": "Jurassic Park",
"metadata": {
"source_text": "Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong",
"genre": "scifi"
},
"distance": 0.859985888004303
}
]
그러면 메타데이터 필터를 지우고 "아빠 물고기 찾기"("find father fish") 라는 텍스트로 쿼리해보겠습니다.
그러면 아래와 같이 쿼리 결과값이 잘 나오는 것을 알 수 있었습니다.
[
{
"key": "Finding Nemo",
"metadata": {
"source_text": "Finding Nemo: A father fish searches the ocean to find his lost son",
"genre": "family"
},
"distance": 0.39454972743988037
},
{
"key": "Star Wars",
"metadata": {
"genre": "scifi",
"source_text": "Star Wars: A farm boy joins rebels to fight an evil empire in space"
},
"distance": 0.9100900888442993
},
{
"key": "Jurassic Park",
"metadata": {
"genre": "scifi",
"source_text": "Jurassic Park: Scientists create dinosaurs in a theme park that goes wrong"
},
"distance": 0.9819673299789429
}
]
마무리
벡터 데이터를 저장하고 쿼리하기 위해 복잡하거나 비싼 인프라를 설정하고 관리하는 형태에서 위의 벡터 버킷으로 바꾼다면 매우 편리하고 쉽게 사용할 수 있을 것 같습니다.
위의 벡터 버킷은 여러 다른 AWS의 서비스와도 통합이 가능합니다. Amazon Bedrock을 통해 RAG로 사용하거나, Amazon OpenSearch Service 에 통합해 더 빠른 검색을 지원할 수도 있습니다.
Amazon S3 Vectors 소개: 대규모 벡터를 지원하는 최초 클라우드 스토리지 (미리 보기)
이런 구성의 간편함과 다른 서비스와의 통합을 통해, 앞으로 벡터 검색이 조금 더 쉽고 가깝게 느껴질 것 같습니다!
이상, 한국어 블로그 릴레이의 2025년 33 번째 블로그 「Amazon S3 Vectors 사용해보기」 편이었습니다. 다음 34 번째 블로그 릴레이는 9월 5주에 공개됩니다.
끝까지 읽어주셔서 감사합니다! 이상, 제조 비즈니스 테크놀로지부의 이병현입니다.
문의 사항은 클래스메소드 코리아로!
클래스메소드 코리아에서는 다양한 세미나 및 이벤트를 진행하고 있습니다.
진행중인 이벤트에 대해 아래 페이지를 참고해주세요.
AWS에 대한 상담 및 클래스 메소드 멤버스에 관한 문의사항은 아래 메일로 연락주시면 감사드립니다!
Info@classmethod.kr








