
Krita 6 の PII 検出プラグインを Amazon Rekognition で高速化&精度向上させた
はじめに
前回の記事 では、EasyOCR を使って PII (個人情報) を含む領域を自動で選択する Krita 6 向けプラグインを試作しました。ただし筆者環境では、CPU のみで実行していたこともあり処理が遅く、また小さい文字の読み取り精度にも課題がありました。そこで今回は、Amazon Rekognition の DetectText を使う実装を追加し、速度と精度の改善を狙います。
今回も前回と同様に、プラグインは次の役割に絞ります。
- Krita の現在の表示結果を一時ファイルに書き出す
- 外部 Python で PII 検出を実行し、矩形を JSON に出力する
- JSON の矩形を選択範囲に反映する
検証環境
- OS: Windows 11
- Krita: Krita 6.0.0 beta1
- GPU: なし (CPU のみで OCR を実行)
- 外部 Python: Python 3.11.9
- boto3: 1.42.46
- pillow: 12.1.1
対象読者
- Krita 6 でスクリーンショットや画像内の個人情報をマスキングしたい方
- Krita の Python プラグイン開発に興味がある方
- Amazon Rekognition の DetectText API を使った OCR 実装を検討している方
- 前回の EasyOCR 版 からの速度・精度改善に興味がある方
- Python と AWS CLI の基本的な操作ができる方
参考
- How to make a Krita Python plugin — Krita Manual 5.2.0 documentation
- detect_text - Boto3 1.42.46 documentation
- What is Amazon Rekognition? - Amazon Rekognition
事前準備
DetectText を呼べる最小権限の IAM ポリシーを用意します。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "RekognitionText",
"Effect": "Allow",
"Action": [
"rekognition:DetectText"
],
"Resource": "*"
}
]
}
次に、ローカルの AWS CLI 設定でプロファイルを用意します。今回は krita-ocr というプロファイル名を使います。
[profile krita-ocr]
region = ap-northeast-1
実装
前回と同様に、Krita 側のプラグインは一時ファイルへの書き出しと、検出結果の選択範囲への反映だけを担当します。PII 検出そのものは外部 Python のスクリプトに分離し、boto3 経由で Amazon Rekognition DetectText を呼び出します。DetectText が返す行のバウンディングボックスをピクセル座標に変換し、余白を付けて JSON に書き出します。
なお、サンプルコードについては記事の末尾に記載しています。
使い方
pykrita配下にpii_mask_awsを配置し、Krita の Python プラグインマネージャで有効化 (前回記事 と同じ)- Krita で画像を開き、
ツール→スクリプト→PII (AWS): Detect (email/phone)を実行 - 検出が終わると、PII と判定した行の矩形が選択範囲として設定される
- 必要に応じて選択範囲を調整し、最後に Krita 標準のモザイクなどを適用
結果
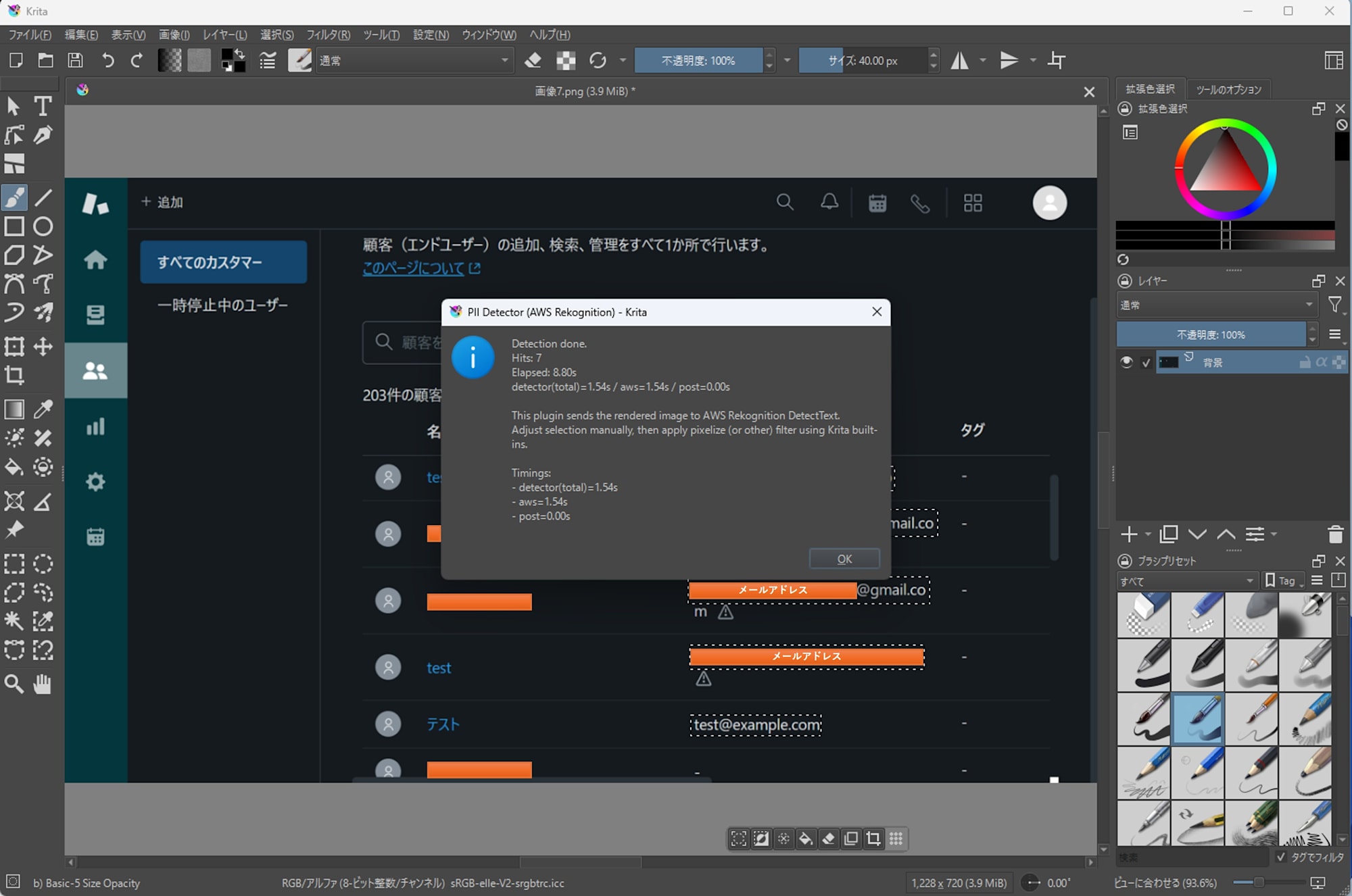
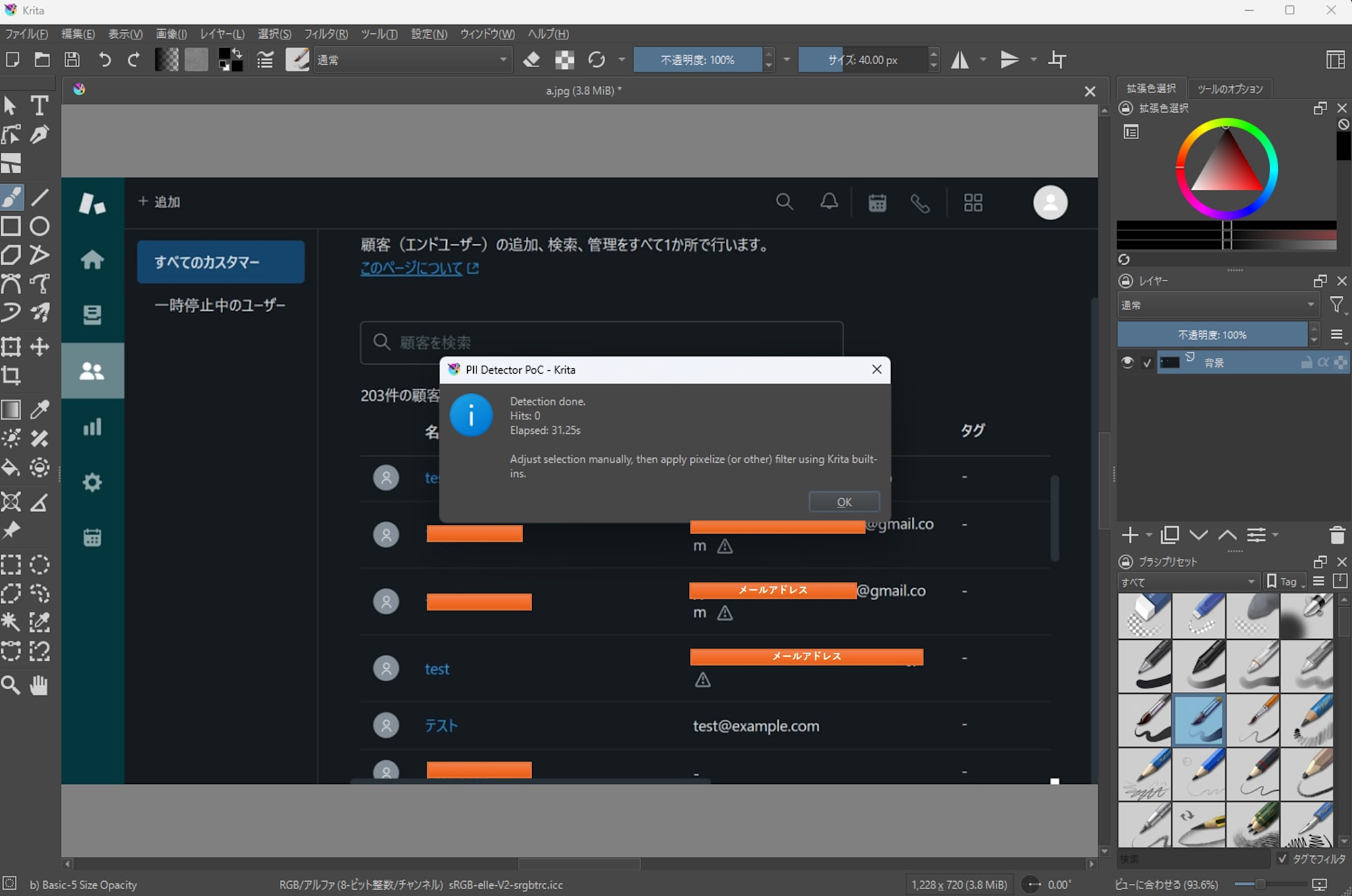
筆者環境では、同じ画像に対して、EasyOCR 版は 30 秒前後、Amazon Rekognition 版は 9 秒前後の時間がかかりました。計測は同一画像で 1 回ずつ実施しました。また、EasyOCR 版で発生していた検出漏れを削減しました。
Zendesk Console でのメールアドレス
- EasyOCR
- 5 件中 0 件検出
- 処理時間: 31.25s
- Amazon Rekognition
- 5 件中 5 件検出
- 処理時間: 8.80s
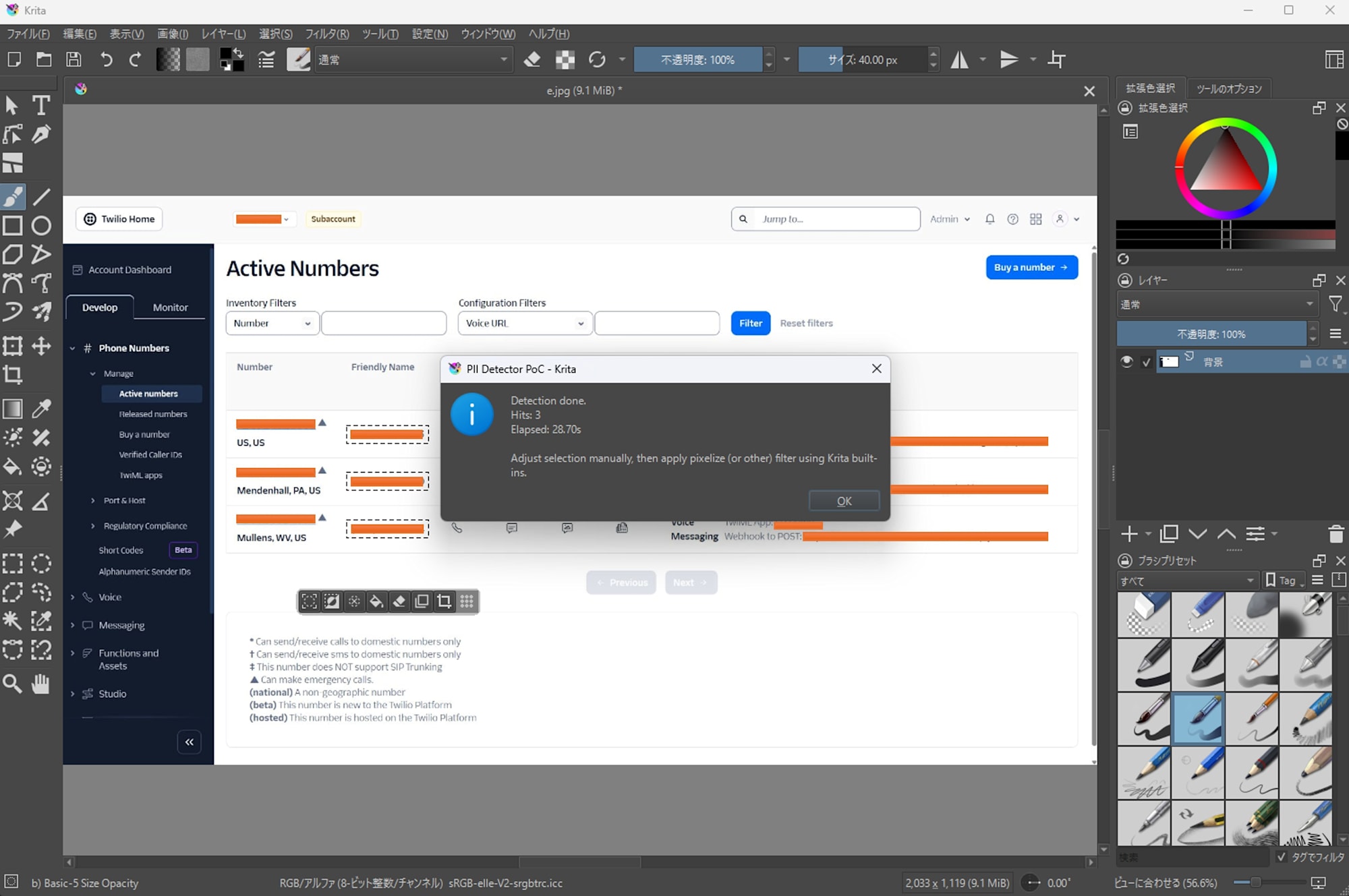
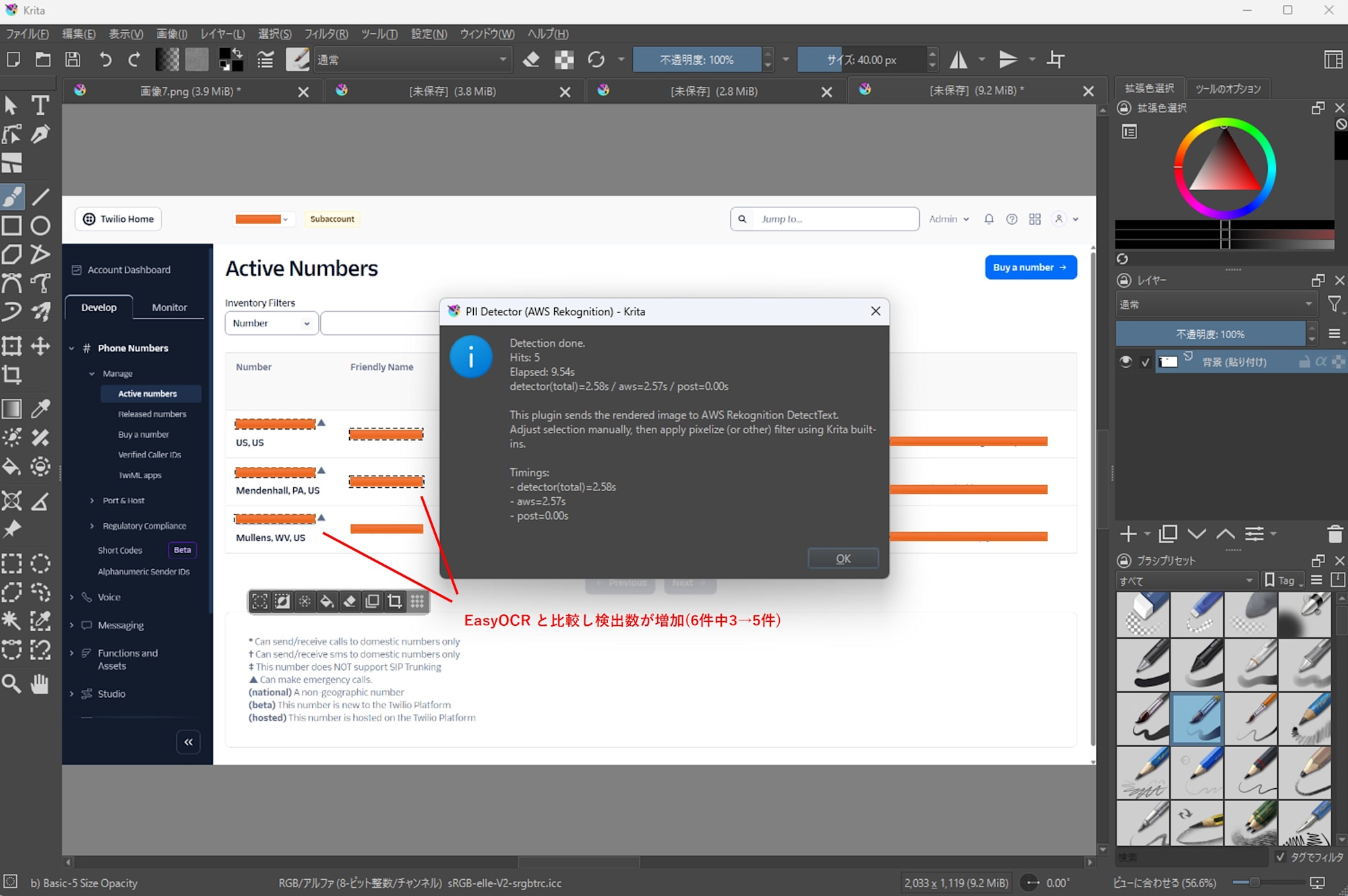
Twilio Console での電話番号
-
EasyOCR
- 6 件中 3 件検出
- 処理時間: 28.70s
-
Amazon Rekognition
- 6 件中 5 件検出
- 処理時間: 9.54s
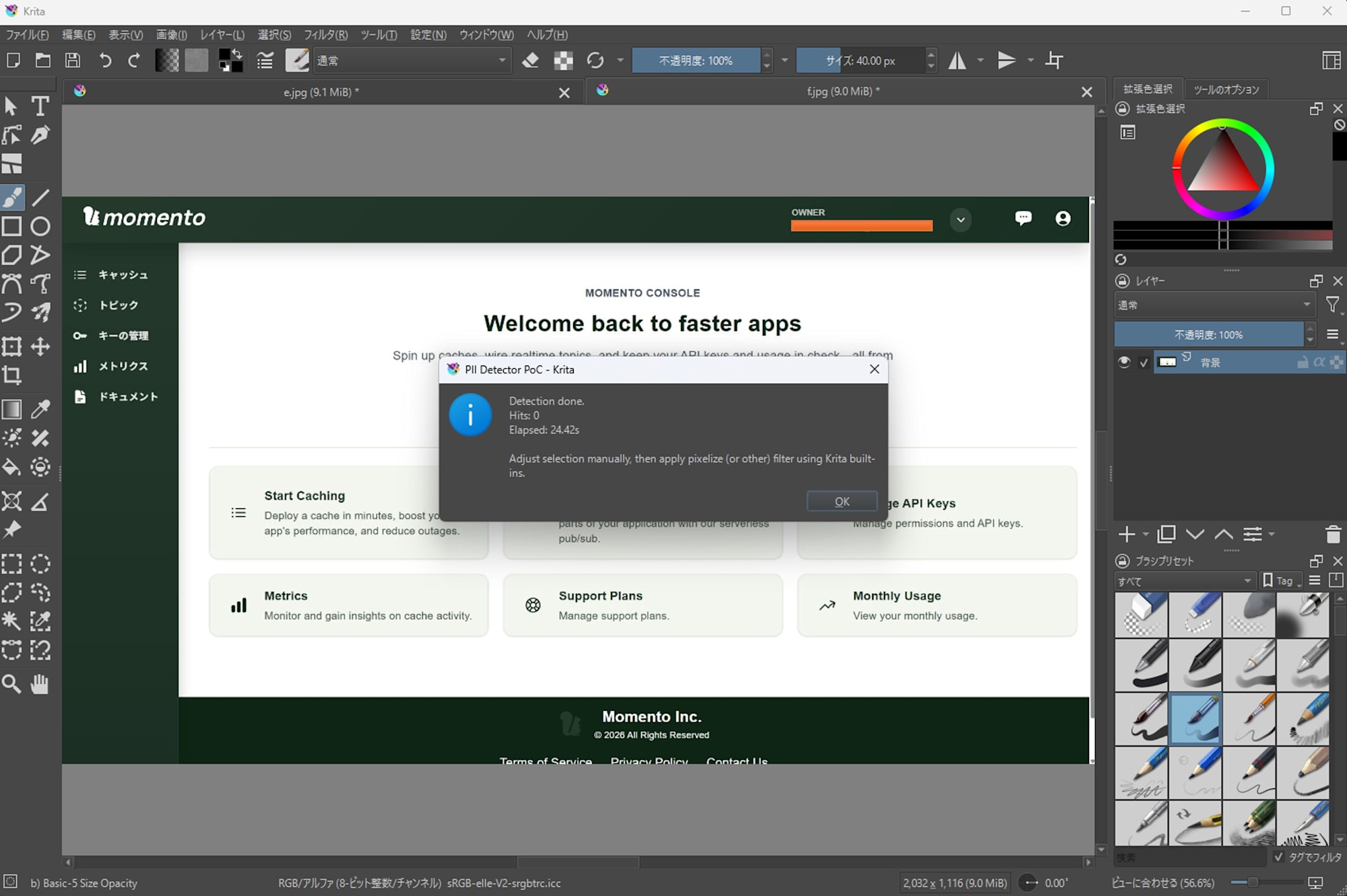
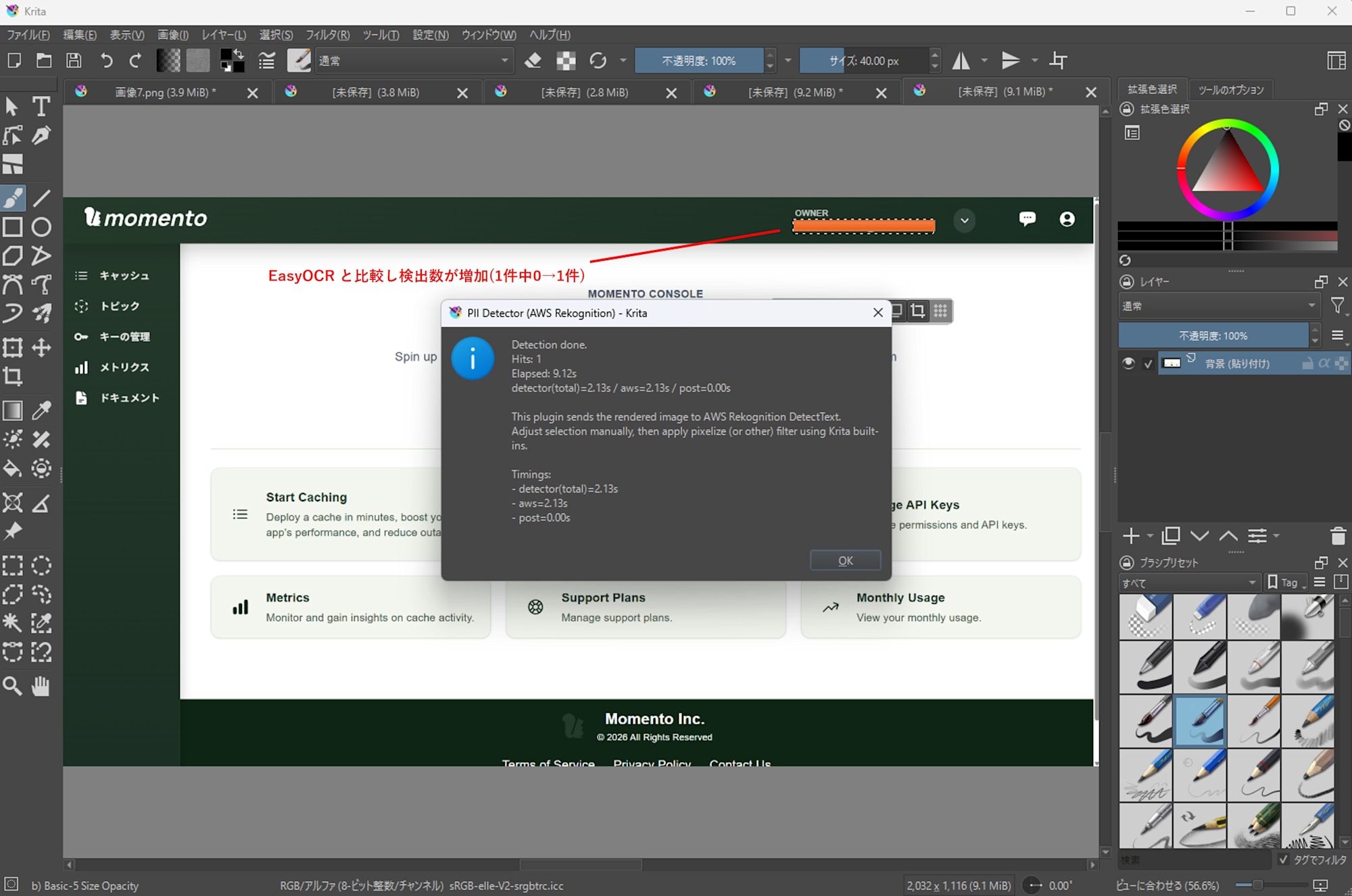
Momento Console でのメールアドレス (末尾が ... の略式)
-
EasyOCR
- 1 件中 0 件検出
- 処理時間: 24.42s
-
Amazon Rekognition
- 1 件中 1 件検出
- 処理時間: 9.12s
まとめ
Krita 6 の PII 検出プラグインに、Amazon Rekognition DetectText を使う実装を追加しました。筆者の CPU 環境では、EasyOCR 版より短時間で処理でき、検出漏れも削減できました。検出後のマスク処理は引き続き Krita 標準機能に任せるため、検出エンジンを切り替えても、作業手順をほとんど変更せずに利用できます。
付録: サンプルコード
付録: サンプルコード
pii_mask_aws/pii_mask_aws.py
# pykrita/pii_mask_aws/pii_mask_aws.py
from __future__ import annotations
import json
import os
import subprocess
import tempfile
import time
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple
from krita import Extension, InfoObject, Krita, Selection # type: ignore
try:
from PyQt6.QtWidgets import QMessageBox
except Exception: # pragma: no cover
from PyQt5.QtWidgets import QMessageBox # type: ignore
PLUGIN_TITLE = "PII Detector (Amazon Rekognition)"
PLUGIN_MENU_TEXT = "PII (AWS): Detect (email/phone)"
def _load_config() -> Dict[str, Any]:
cfg_path = Path(__file__).with_name("config.json")
if not cfg_path.exists():
raise RuntimeError(f"config.json not found: {cfg_path}")
return json.loads(cfg_path.read_text(encoding="utf-8"))
def _msg(title: str, text: str) -> None:
app = Krita.instance()
w = app.activeWindow()
parent = w.qwindow() if w is not None else None
QMessageBox.information(parent, title, text)
def _err(title: str, text: str) -> None:
app = Krita.instance()
w = app.activeWindow()
parent = w.qwindow() if w is not None else None
QMessageBox.critical(parent, title, text)
def _export_projection_png(doc, out_path: Path) -> None:
# projection (見た目通り) を書き出す
doc.exportImage(str(out_path), InfoObject())
def _rects_to_selection(doc_w: int, doc_h: int, rects: List[Dict[str, int]]) -> Selection:
sel = Selection()
sel.resize(doc_w, doc_h)
sel.clear()
for r in rects:
x, y, w, h = int(r["x"]), int(r["y"]), int(r["w"]), int(r["h"])
if w <= 0 or h <= 0:
continue
tmp = Selection()
tmp.resize(doc_w, doc_h)
tmp.clear()
tmp.select(x, y, w, h, 255)
sel.add(tmp)
return sel
def _clean_env_for_external_python() -> Dict[str, str]:
"""
Krita 同梱 Python / Qt 周りの環境変数が外部 Python を汚染しがちなので、
Python 系と Qt 系だけ除去して、AWS_* などは温存する。
"""
env = os.environ.copy()
for k in list(env.keys()):
if k.upper().startswith("PYTHON"):
env.pop(k, None)
for k in ["QT_PLUGIN_PATH", "QML2_IMPORT_PATH"]:
env.pop(k, None)
return env
def _detector_sanity_check(detector_path: Path) -> Optional[str]:
try:
head = detector_path.read_text(encoding="utf-8", errors="ignore")[:2000]
except Exception:
return None
if "from krita import" in head or "import krita" in head:
return (
"Detector script looks like a Krita plugin (it imports 'krita').\n"
"config.json 'detector' may be pointing to the wrong file.\n\n"
f"detector: {detector_path}"
)
return None
def _format_timings(data: Dict[str, Any]) -> Tuple[str, str]:
"""
Returns:
- short line for message
- verbose block for message
"""
timings = data.get("timings")
if not isinstance(timings, dict):
return "", ""
def _f(key: str) -> Optional[float]:
v = timings.get(key)
try:
return float(v)
except Exception:
return None
total = _f("total_sec")
aws = _f("aws_sec")
post = _f("post_sec")
parts: List[str] = []
if total is not None:
parts.append(f"detector(total)={total:.2f}s")
if aws is not None:
parts.append(f"aws={aws:.2f}s")
if post is not None:
parts.append(f"post={post:.2f}s")
if not parts:
return "", ""
short = " / ".join(parts)
verbose = "\n".join([f"- {p}" for p in parts])
return short, verbose
class PIIRekognitionExtension(Extension):
def __init__(self, parent):
super().__init__(parent)
def setup(self) -> None:
pass
def createActions(self, window) -> None:
a1 = window.createAction(
"pii_detect_aws_email_phone",
PLUGIN_MENU_TEXT,
"tools/scripts",
)
a1.triggered.connect(self.detect)
def detect(self) -> None:
app = Krita.instance()
doc = app.activeDocument()
if doc is None:
_err(PLUGIN_TITLE, "No active document.")
return
try:
cfg = _load_config()
except Exception as e:
_err(PLUGIN_TITLE, f"Failed to load config.json:\n{e}")
return
py = Path(str(cfg.get("python", "")))
detector = Path(str(cfg.get("detector", "")))
aws_profile = str(cfg.get("aws_profile", "")).strip()
aws_region = str(cfg.get("aws_region", "")).strip()
min_conf = float(cfg.get("min_conf", 0.40))
pad = int(cfg.get("pad", 2))
scale = int(cfg.get("scale", 0))
if not py.exists():
_err(PLUGIN_TITLE, f"python not found:\n{py}")
return
if not detector.exists():
_err(PLUGIN_TITLE, f"detector not found:\n{detector}")
return
bad = _detector_sanity_check(detector)
if bad:
_err(PLUGIN_TITLE, bad)
return
tmp_dir = Path(tempfile.gettempdir()) / "krita_pii_detector_aws"
tmp_dir.mkdir(parents=True, exist_ok=True)
in_png = tmp_dir / "input.png"
out_json = tmp_dir / "hits.json"
try:
_export_projection_png(doc, in_png)
except Exception as e:
_err(PLUGIN_TITLE, f"Failed to export image:\n{e}")
return
cmd: List[str] = [
str(py),
"-E",
"-s",
str(detector),
"--in",
str(in_png),
"--out",
str(out_json),
"--min-conf",
str(min_conf),
"--pad",
str(pad),
"--scale",
str(scale),
]
if aws_profile:
cmd += ["--aws-profile", aws_profile]
if aws_region:
cmd += ["--aws-region", aws_region]
t0 = time.perf_counter()
try:
p = subprocess.run(
cmd,
capture_output=True,
text=True,
check=False,
env=_clean_env_for_external_python(),
)
except Exception as e:
_err(PLUGIN_TITLE, f"Failed to run detector:\n{e}")
return
elapsed = time.perf_counter() - t0
print(f"[{PLUGIN_TITLE}] detector elapsed(subprocess): {elapsed:.2f}s")
if p.stdout.strip():
print(f"[{PLUGIN_TITLE}] detector stdout:\n{p.stdout}")
if p.stderr.strip():
print(f"[{PLUGIN_TITLE}] detector stderr:\n{p.stderr}")
if p.returncode != 0:
_err(
PLUGIN_TITLE,
f"Detector failed (code={p.returncode}).\n\n"
f"Elapsed: {elapsed:.2f}s\n\nSTDERR:\n{p.stderr}\n\nSTDOUT:\n{p.stdout}",
)
return
try:
data = json.loads(out_json.read_text(encoding="utf-8"))
hits = data.get("hits", [])
except Exception as e:
_err(PLUGIN_TITLE, f"Failed to read JSON:\n{e}")
return
rects = [h["rect"] for h in hits if isinstance(h, dict) and "rect" in h]
sel = _rects_to_selection(doc.width(), doc.height(), rects)
doc.setSelection(sel)
timing_short, timing_verbose = _format_timings(data)
timing_line = f"\n{timing_short}" if timing_short else ""
_msg(
PLUGIN_TITLE,
f"Detection done.\nHits: {len(rects)}\nElapsed: {elapsed:.2f}s{timing_line}\n\n"
"This plugin sends the rendered image to Amazon Rekognition DetectText.\n"
"Adjust selection manually, then apply pixelize (or other) filter using Krita built-ins.\n"
+ (f"\nTimings:\n{timing_verbose}\n" if timing_verbose else ""),
)
Krita.instance().addExtension(PIIRekognitionExtension(Krita.instance()))
detector/pii_detect_aws.py
# detector/pii_detect_aws.py
from __future__ import annotations
import argparse
import json
import re
import sys
import time
import unicodedata
from dataclasses import dataclass
from pathlib import Path
from typing import Any, Dict, List, Optional, Tuple
# boto3 は外部 venv で入っている前提
try:
import boto3 # type: ignore
except Exception as e: # pragma: no cover
boto3 = None # type: ignore
_BOTO3_IMPORT_ERROR = e
else:
_BOTO3_IMPORT_ERROR = None
# 通常のメール
EMAIL_RE = re.compile(r"\b[A-Z0-9._%+\-]+@[A-Z0-9.\-]+\.[A-Z]{2,}\b", re.IGNORECASE)
# 省略されたメール例: koshii.takumi@classmet...
# - ドメイン末尾に "..." が付いているものを拾う
# - 後ろに空白/行末/典型的な区切り記号が来る想定
TRUNC_EMAIL_RE = re.compile(
r"[A-Z0-9._%+\-]+@[A-Z0-9.\-]{2,}\.{3,}(?=\s|$|[)\]】〉》>、。,.])",
re.IGNORECASE,
)
def _nfkc(s: str) -> str:
s = unicodedata.normalize("NFKC", s)
# 省略記号を "..." に統一(OCR/フォント差)
s = s.replace("…", "...") # U+2026
s = s.replace("⋯", "...") # U+22EF
# 日本語の三点リーダ "・・・"(中黒系)もまとめて扱う
s = s.replace("・・・", "...")
return s
def _looks_like_email(s: str) -> bool:
t = _nfkc(s)
if EMAIL_RE.search(t):
return True
if TRUNC_EMAIL_RE.search(t):
return True
return False
def _read_png_size(path: Path) -> Tuple[int, int]:
"""
Pillow なしで PNG の IHDR から width/height を読む。
"""
with path.open("rb") as f:
sig = f.read(8)
if sig != b"\x89PNG\r\n\x1a\n":
raise RuntimeError("Input is not a PNG (unexpected signature).")
# IHDR: length(4) type(4) data(13) crc(4)
length = int.from_bytes(f.read(4), "big")
ctype = f.read(4)
if ctype != b"IHDR":
raise RuntimeError("PNG IHDR chunk not found where expected.")
ihdr = f.read(13)
if len(ihdr) != 13:
raise RuntimeError("PNG IHDR too short.")
width = int.from_bytes(ihdr[0:4], "big")
height = int.from_bytes(ihdr[4:8], "big")
if width <= 0 or height <= 0:
raise RuntimeError(f"Invalid PNG size: {width}x{height}")
return width, height
def _maybe_scale_image(in_path: Path, scale_percent: int) -> Tuple[Path, int, int]:
"""
scale_percent:
- 0: no scaling
- 1..100: scale to that percentage
Returns: (path_to_send, width, height)
"""
w, h = _read_png_size(in_path)
if scale_percent <= 0 or scale_percent == 100:
return in_path, w, h
# Optional: use Pillow if available
try:
from PIL import Image # type: ignore
except Exception:
raise RuntimeError(
"scale is requested but Pillow is not available in the external Python.\n"
"Install pillow, or set scale=0 in config.json."
)
new_w = max(1, int(round(w * (scale_percent / 100.0))))
new_h = max(1, int(round(h * (scale_percent / 100.0))))
out_path = in_path.with_name(in_path.stem + f"_scaled{scale_percent}.png")
with Image.open(in_path) as im:
im = im.convert("RGB")
im = im.resize((new_w, new_h))
im.save(out_path, format="PNG")
return out_path, new_w, new_h
def _clamp(v: int, lo: int, hi: int) -> int:
return max(lo, min(hi, v))
def _pad_rect(x: int, y: int, w: int, h: int, pad: int, img_w: int, img_h: int) -> Dict[str, int]:
x2 = x + w
y2 = y + h
x = _clamp(x - pad, 0, img_w)
y = _clamp(y - pad, 0, img_h)
x2 = _clamp(x2 + pad, 0, img_w)
y2 = _clamp(y2 + pad, 0, img_h)
return {"x": x, "y": y, "w": max(0, x2 - x), "h": max(0, y2 - y)}
def _looks_like_phone(s: str) -> bool:
s0 = _nfkc(s)
# quick reject if too short
if len(s0) < 6:
return False
digits = re.sub(r"\D", "", s0)
if not digits:
return False
has_plus = "+" in s0
has_sep = any(ch in s0 for ch in ["-", " ", "(", ")", " ", "/", "/"])
# E.164-ish
if has_plus and 8 <= len(digits) <= 15:
return True
# Domestic-ish: avoid too-short sequences (years, prices, etc.)
# Typical: 10-11 digits (JP mobile/landline), with separators is more likely a phone.
if 10 <= len(digits) <= 11 and has_sep:
return True
# Some OCR outputs remove separators but keep “tel:” or similar markers
if 10 <= len(digits) <= 15 and re.search(r"\b(tel|phone|fax)\b", s0, re.IGNORECASE):
return True
return False
@dataclass
class DetLine:
text: str
confidence: float
# Rekognition bbox is normalized: left/top/width/height
left: float
top: float
width: float
height: float
def _extract_lines(rek_resp: Dict[str, Any]) -> List[DetLine]:
out: List[DetLine] = []
dets = rek_resp.get("TextDetections", [])
if not isinstance(dets, list):
return out
for d in dets:
if not isinstance(d, dict):
continue
if d.get("Type") != "LINE":
continue
text = d.get("DetectedText")
conf = d.get("Confidence")
geom = d.get("Geometry", {})
bbox = geom.get("BoundingBox", {}) if isinstance(geom, dict) else {}
if not isinstance(text, str):
continue
try:
conf_f = float(conf)
except Exception:
conf_f = 0.0
try:
left = float(bbox.get("Left", 0.0))
top = float(bbox.get("Top", 0.0))
width = float(bbox.get("Width", 0.0))
height = float(bbox.get("Height", 0.0))
except Exception:
continue
# Sanity clamp normalized coordinates
left = max(0.0, min(1.0, left))
top = max(0.0, min(1.0, top))
width = max(0.0, min(1.0, width))
height = max(0.0, min(1.0, height))
out.append(DetLine(text=text, confidence=conf_f, left=left, top=top, width=width, height=height))
return out
def _bbox_to_rect_px(line: DetLine, img_w: int, img_h: int) -> Tuple[int, int, int, int]:
x = int(round(line.left * img_w))
y = int(round(line.top * img_h))
w = int(round(line.width * img_w))
h = int(round(line.height * img_h))
# clamp within image
x = _clamp(x, 0, img_w)
y = _clamp(y, 0, img_h)
w = _clamp(w, 0, img_w - x)
h = _clamp(h, 0, img_h - y)
return x, y, w, h
def _build_hits(lines: List[DetLine], img_w: int, img_h: int, min_conf: float, pad: int) -> List[Dict[str, Any]]:
hits: List[Dict[str, Any]] = []
for ln in lines:
if ln.confidence < (min_conf * 100.0): # Rekognition confidence is 0..100
continue
t = _nfkc(ln.text)
kinds: List[str] = []
if _looks_like_email(t):
kinds.append("email")
if _looks_like_phone(t):
kinds.append("phone")
if not kinds:
continue
x, y, w, h = _bbox_to_rect_px(ln, img_w, img_h)
rect = _pad_rect(x, y, w, h, pad, img_w, img_h)
# 1行に email と phone が混在するケースもあるので、kind ごとに分けて hits へ
for k in kinds:
hits.append(
{
"kind": k,
"text": "masked",
"confidence": float(ln.confidence),
"rect": rect,
}
)
return hits
def _make_session(profile: Optional[str], region: Optional[str]):
if boto3 is None:
raise RuntimeError(f"boto3 import failed: {_BOTO3_IMPORT_ERROR}")
kwargs: Dict[str, Any] = {}
if profile:
kwargs["profile_name"] = profile
session = boto3.session.Session(**kwargs)
client_kwargs: Dict[str, Any] = {}
if region:
client_kwargs["region_name"] = region
return session, session.client("rekognition", **client_kwargs)
def _main(argv: Optional[List[str]] = None) -> int:
ap = argparse.ArgumentParser(description="PII detector using Amazon Rekognition DetectText (LINE-based).")
ap.add_argument("--in", dest="in_path", required=True, help="Input image path (PNG recommended).")
ap.add_argument("--out", dest="out_path", required=True, help="Output JSON path.")
ap.add_argument("--min-conf", dest="min_conf", type=float, default=0.40, help="Min confidence (0..1).")
ap.add_argument("--pad", dest="pad", type=int, default=2, help="Padding in pixels.")
ap.add_argument(
"--scale",
dest="scale",
type=int,
default=0,
help="Scale percent for OCR (0=no scaling, 1..100). Recommended 0 or 100.",
)
ap.add_argument("--aws-profile", dest="aws_profile", default="", help="AWS profile name (optional).")
ap.add_argument("--aws-region", dest="aws_region", default="", help="AWS region (optional).")
args = ap.parse_args(argv)
in_path = Path(args.in_path)
out_path = Path(args.out_path)
if not in_path.exists():
raise RuntimeError(f"Input not found: {in_path}")
min_conf = float(args.min_conf)
if not (0.0 <= min_conf <= 1.0):
raise RuntimeError("--min-conf must be in range 0..1")
scale = int(args.scale)
if scale < 0 or scale > 100:
raise RuntimeError("--scale must be 0..100")
aws_profile = args.aws_profile.strip() or None
aws_region = args.aws_region.strip() or None
t0 = time.perf_counter()
# Optional scaling
scaled_path, img_w, img_h = _maybe_scale_image(in_path, scale)
img_bytes = scaled_path.read_bytes()
# AWS call
t_aws0 = time.perf_counter()
_, client = _make_session(aws_profile, aws_region)
rek = client.detect_text(Image={"Bytes": img_bytes})
t_aws1 = time.perf_counter()
# Postprocess
t_post0 = time.perf_counter()
lines = _extract_lines(rek)
hits = _build_hits(lines, img_w, img_h, min_conf=min_conf, pad=int(args.pad))
t_post1 = time.perf_counter()
t1 = time.perf_counter()
data: Dict[str, Any] = {
"engine_used": "rekognition.detect_text",
"image_w": img_w,
"image_h": img_h,
"timings": {
"total_sec": float(t1 - t0),
"aws_sec": float(t_aws1 - t_aws0),
"post_sec": float(t_post1 - t_post0),
},
"hits": hits,
}
out_path.parent.mkdir(parents=True, exist_ok=True)
out_path.write_text(json.dumps(data, ensure_ascii=False, indent=2), encoding="utf-8")
return 0
if __name__ == "__main__":
try:
raise SystemExit(_main())
except Exception as e:
# Krita 側で stderr を表示できるように、短くはっきり出す
print(f"[pii_detect_aws] ERROR: {e}", file=sys.stderr)
raise









