
LLMOpsプラットフォーム Langfuse のObservability機能を触ってみた
こんにちは。クラウド事業本部の桑野です。
業務でLangfuseというLLMOpsプラットフォームを触る機会がありました。
と言っても、Langfuseを触るというよりはLangfuseにデータを連携するプログラムを組むということを行っていて、Langfuseがあると何が嬉しいのかを整理できていませんでした。
今回はLangfuseを触ってみて、自分流に整理した内容を共有しようと思います。
Langfuseとは?
LLMを利用したアプリケーションの構築・改善ができるようにモデルを使った処理結果を追跡するための機能と分析のツールを持ち合わせています。
Langfuse公式ドキュメントで取り上げられているのは大きく3つです。
- Observability(可観測性)
- Prompt Management(プロンプト管理)
- Evaluation(評価)
今回はObservabilityについて焦点を当てたいと思います。
Observability(可観測性)
オブザーバビリティというのは、システム内部の状態を外部からどのくらい深く理解できるか、把握できるかという能力や仕組みのことを指します。
従来のアプリケーションのように特定の入力を与えれば、決まった出力が返される決定的(Determinism)な処理とは異なり、LLMを利用したアプリケーションは実行のたびに結果が変わる非決定的(Non-determinism)な性質を持ちます。
そのため、ある程度決まったプログラムの実行パターンから逸れたことをきっかけとしたリアクティブな対応が難しく、アプリケーション内で何が起こっているかを常に正確に把握し継続的に改善していくプロアクティブな対応が求められます。
そんなプロアクティブな対応を実現するために、LLMアプリケーションにオブザーバビリティが必要です。
Langfuseはオブザーバビリティに必要なトレース機能を提供します。
トレースというのは、プログラムの実行過程やデータ、イベントの流れなどを追跡、記録することを指し、LangfuseではLLMアプリケーション向けに主に以下の情報を整理してくれます。
- 送信されたプロンプト
- モデルのレスポンス
- トークンの使用状況
- レイテンシー
LangfuseはDockerを使ったセルフホスト形式にも対応しており、今回はそれを用いて実際に手を動かしてみようと思います。
また、Langfuseにトレースを取り込むために、PythonやJavaScriptのSDKが提供されています。
今回はPython SDKを用いて動作を確認してみます。
オブザーバビリティの考え方については以下の記事を参考にさせていただきました。
概念の整理
実際の連携コードや画面を触る前に、Langfuseのコンセプトを理解しておくことをおすすめします。
処理の内容はそんなに難しくないのですが、概念を理解しておかないとSDKを上手く活用できないと感じました。
公式ドキュメントを活用しながら、私なりに整理した理解を共有します。
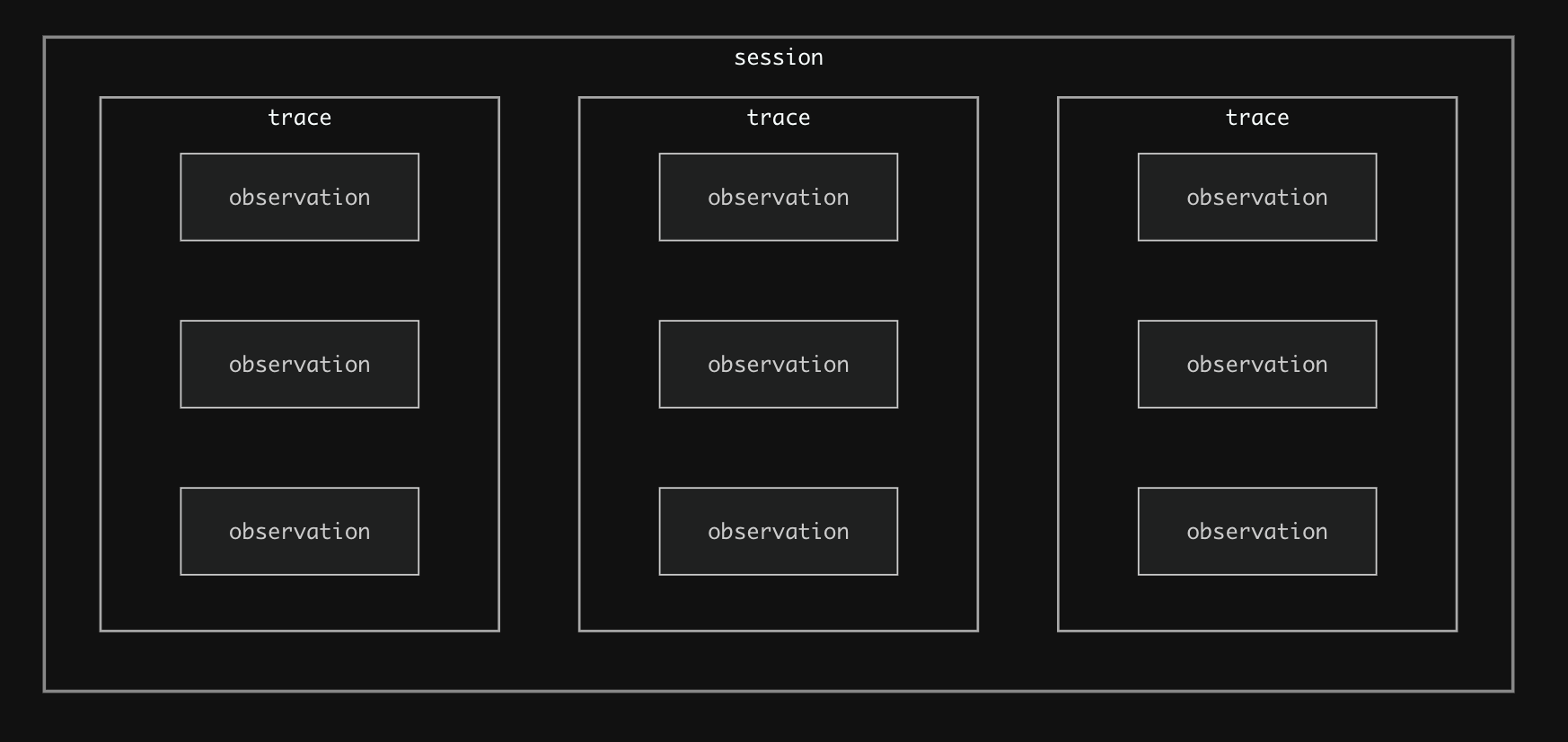
LangfuseのObservabilityは以下の3つのコンセプトに分かれます。
- Observations
- Trace
- Session
公式ドキュメントの図がわかりやすいです。
1. Observations
連携をするとなった際に、最も操作するのがこのオブザーベーションです。
ある1つのプログラムを実行する際、そのプログラムにはいくつかのステップに分かれるかと思います。
イメージを補完するためにドキュメントの例を見てみましょう。
チャットメッセージの処理フロー
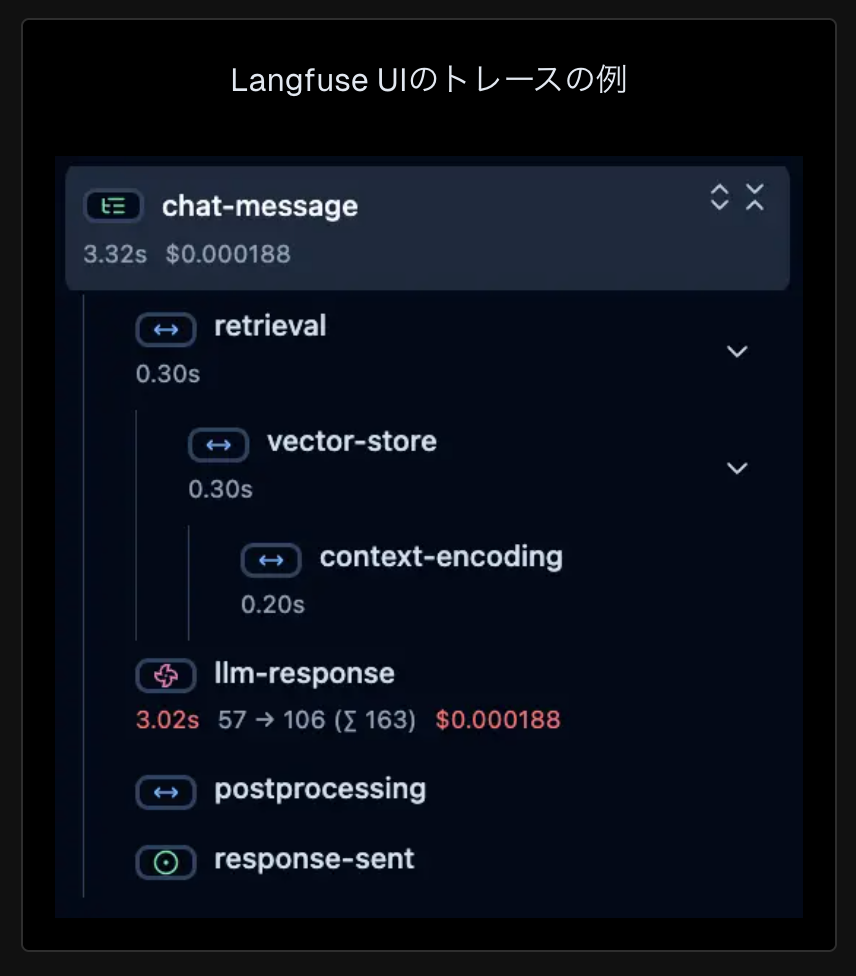
この処理フローは以下の通り分解されています。
- retrieval(検索)
- vector-store(ベクトルストアの参照)
- context-encoding(コンテキストのエンコーディング)
- vector-store(ベクトルストアの参照)
- llm-response(検索した情報を元にLLMが回答する)
- postprocessing(何かしらの後処理)
- response-sent(最終的な処理の結果をユーザーに返却する)
処理のまとまりを分割して記録することでどこに時間がかかっているかということが分析できます。
例では、LLMの応答が全体の応答時間の大部分を占めていることが言えます。
そして、このオブザーベーションは時間だけでなく、LLM特有の情報である、トークン使用量やかかったコストという部分を記録する枠組みも提供しています。
複数のLLM呼び出しを行う処理であれば、どこにコストがかかっているかといった部分も追跡することができるため、処理全体の調整を行うための判断材料として活用することができます。
オブザーベーションには種類があります。
追跡・記録したい処理のまとまりに対応した種類を適切に選択すると良いでしょう。
この例を対応づけるならこんな感じです。
オブザーベーションの種類に応じて記録する枠組みも変わってきます。
LLMの呼び出しを記録するためのgenerationであれば入出力トークンや使用したモデルといった内容を記録する入れ物が用意されています。
- retrieval(検索):
span(検索の一連の作業のまとまり)- vector-store(ベクトルストアの参照):
retriever(データ取得手順)- context-encoding(コンテキストのエンコーディング):
embedding(テキスト→埋め込みベクトルへの変換処理)
- context-encoding(コンテキストのエンコーディング):
- vector-store(ベクトルストアの参照):
- llm-response(検索した情報を元にLLMが回答する):
generation(LLM呼び出し) - postprocessing(何かしらの後処理):
guardrail(有害コンテンツのフィルタリングなら)/span(単なるフォーマット変換など) - response-sent(最終的な処理の結果をユーザーに返却する):
span(ストリーミング)/event(瞬間的な完了通知ならこちらを採用)
詳しくは以下の通りです。
2. Trace
トレースは先ほどのいくつかのオブザーベーションをまとめたものです。
検索やLLM応答がそれぞれのオブザーベーションなら、トレースは1回のチャットメッセージの処理を指します。
ユーザーリクエストが発生してから、レスポンスが返されるまでの間の処理のことですね。
ここでは一つのリクエストとしての入力と出力や誰がそのリクエストを行ったのかというメタデータ(ユーザー識別可能な情報、セッション、タグ)が含まれます。
ユーザー情報についてはメールアドレスや、なんらかのIDを入れることになります。
タグについては、そのトレースが正常に終了したか、異常終了したかといった情報を渡すのに使えます。
セッションについては次で説明します。
3. Session
セッションはトレースをグループ化するためのものです。
イメージしやすい例として、先ほどのチャットメッセージのやり取りを複数回続けた場面を思い浮かべてもらうと良いと思います。
回答するLLMが一つ前の質問内容を覚えているという仕様であれば、その次の質問に対する回答は前回のやり取りを踏まえた内容になっていて欲しいと思います。
そしてそのやりとりをチェックした上でさらなるチューニングが必要かどうかを判断したいでしょう。
そんな際にセッションによるグルーピングが生きてきます。
セッションIDと呼ばれる一意性が保証される情報でグルーピングすることによって、後からトレースを追跡する際にフィルタリングすることが可能となります。
これらの概念を把握した上で実際に手を動かして検証してみます。
前提
以下の条件で検証しています。
前回からOSのバージョンが変わりました。
- OS:macOS Tahoe バージョン 26.2
- チップ:Apple M4
- Docker Client:28.4.0
- Docker Server:28.3.3
- Colima:0.8.4
- docker compose:2.39.3
- git:2.52.0
Colimaを使ったDocker環境の構築手順については以下の記事をご参照ください。
「手順」と「実践編」の1の手順を実施し、docker環境とdocker composeが使えるようになっていれば準備OKです。
環境構築手順
Python SDKの検証に使ったコードは以下のリポジトリにあります。
Python実行環境も作成できますので、必要に応じて利用してください。
1. Langfuseをセルフホストする
Langfuse Cloudで無料のアカウントを作成し、サービスを利用するという選択肢もありますが、今回はDockerで自分のローカル環境にLangfuseを構築していきます。
まずはLangfuseリポジトリをクローンします。
git clone https://github.com/langfuse/langfuse.git
cd langfuse
クローンできたら、コンテナを起動します。
docker compose up
コンテナが起動すると、langfuse-web-1というコンテナにReadyというログが表示されます。
表示されたら、ブラウザでhttp://localhost:3000を開きます。
以下の画面が表示されれば成功です!
2. APIキーの発行
SDKを使ってLangfuseにトレースを連携するには、APIキーが必要となります。
そちらの準備をしていきます。
まずアカウントを作成します。
赤枠の「Sign up」をクリックし、Name、Email、Passwordをそれぞれ入力していきます。
入力が完了したら、そのまま管理画面にアクセスできます。
EmailとPasswordはログアウト後、再度ログインする際に必要となりますので忘れずに控えておきましょう。
アクセスができたら、最初に組織を作成します。
「新しい組織」をクリックします。
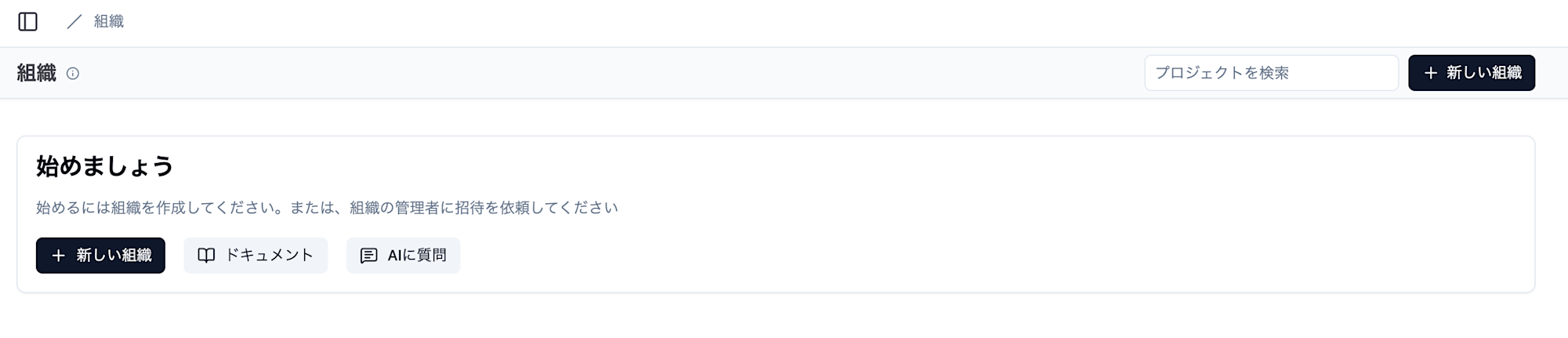
組織名を入力し、「作成」をクリックします。
何でも良いですが、今回はtestにしました。
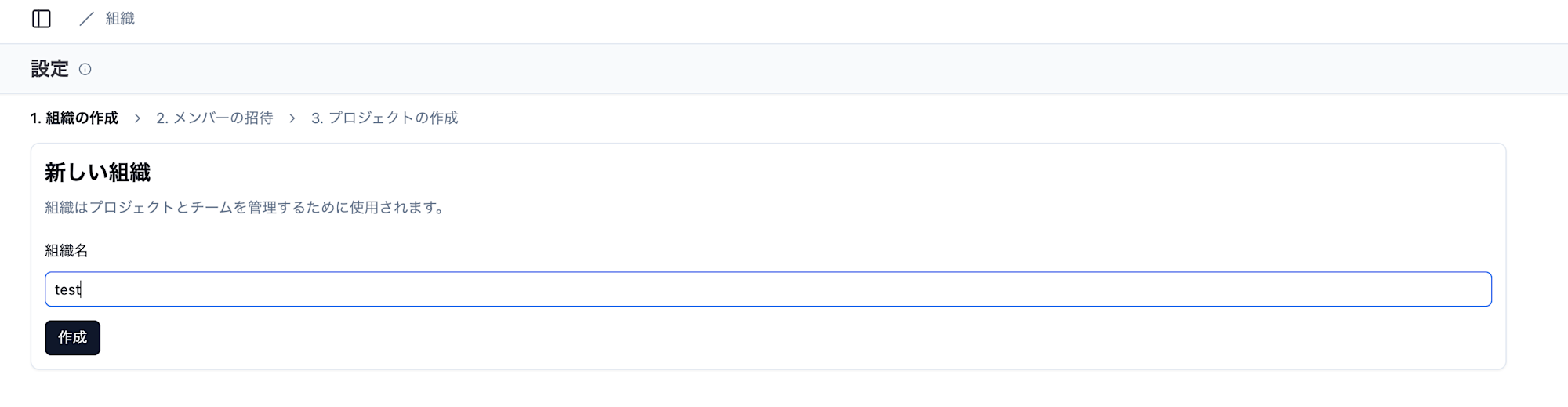
次の画面では先ほどの組織にメンバーを追加で招待することができます。
ローカル開発している現状、メンバーを追加しても仕方がないので「次へ」をクリックします。
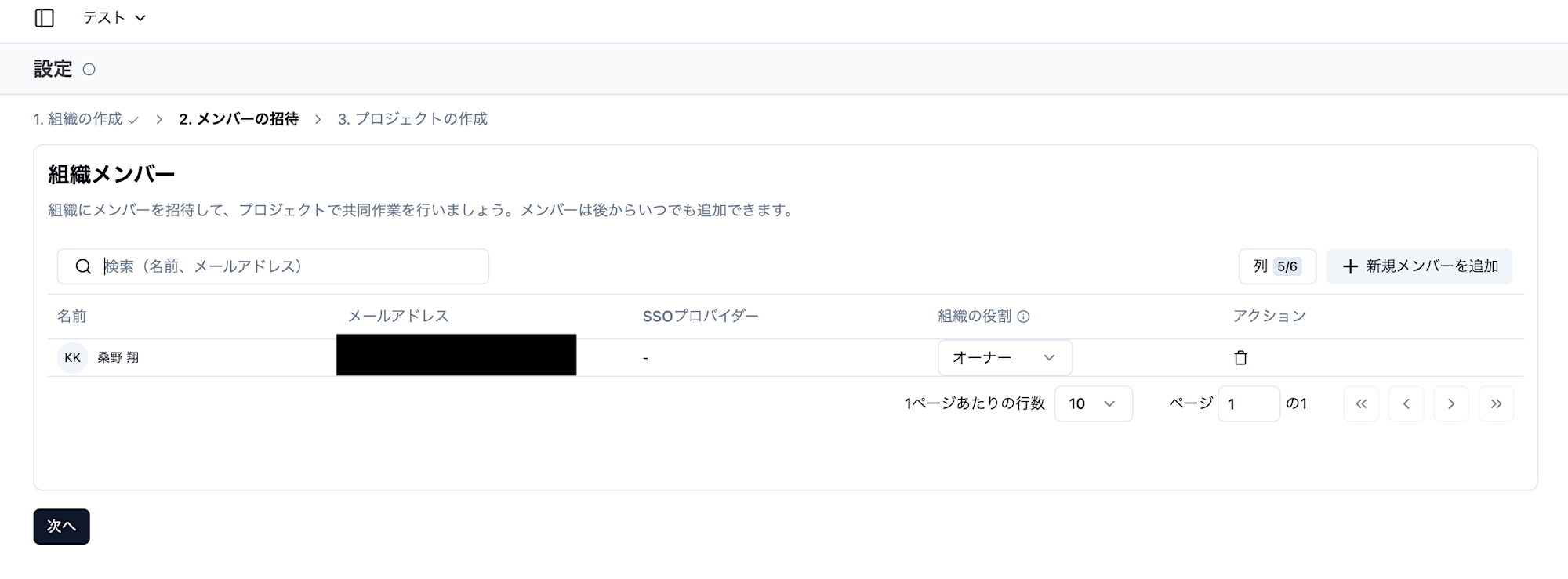
最後にプロジェクト名です。入力し「作成」をクリックします。
これも何でも良いですが、今回はtest-projectにしました。
ここまでの手順が完了すると、プロジェクトのトレース画面が表示されます。
「トレースの設定」をクリックします。
ようやく、APIキーの取得ができそうな画面が見えてきました。
「新しいAPIキーを作成する」をクリックします。
作成すると、秘密鍵と公開鍵が作成されます。
後ほどPython SDKで必要になりますので控えておくようにしましょう。
以上でAPIキーの発行は完了です。
3. Python SDK実行環境のセットアップ
Pythonを実行できる環境があれば、この手順はスキップしてください。
VSCode拡張機能Dev Containerを利用し、使い捨て可能な開発環境を構築します。
1. コンテナへの作成
リポジトリルートで以下のコマンドを実行します。
docker compose build
docker compose up -d
2. コンテナへのアクセス
コンテナが起動したら、VSCodeのコマンドパレットを開きます。
>Dev Containers: Open Folder in Container...
開発コンテナー: コンテナーでフォルダーを開く…を選択しましょう。
すると、Finderが表示されるので、backend/pythonを開きます。
3. 依存関係の解決
コンテナにアクセスしたら、以下のコマンドを実行します。
uv sync
VSCodeのインタープリターは.venvを選択します。
4. APIキーの登録
コンテナにアクセスした後は、SDKで使うAPIキーを環境変数から読み込ませます。
コンテナのワークスペース直下にある.env.exampleファイルをコピーし、.envファイルを作成します。
作成した.envファイルのLANGFUSE_SECRET_KEYとLANGFUSE_PUBLIC_KEYにそれぞれ秘密鍵と公開鍵を記述します。
5. 動作確認
VSCodeの「実行とデバッグ」メニューからsrc/langfuse_sync.pyのデバッグができます。
Debug langfuse_syncを実行し特にエラーがなければ、OKです。
Python SDKを触ってみる
おおよその流れとしては以下のとおりです。
- Clientの初期化
- Clientの呼び出し
- Traceの連携
1. Clientの初期化
Langfuseクラスを使います。
このクラスインスタンスを作成する際、最大3つの引数を渡すことができます。
- public_key
- secret_key
- base_url
見覚えのある名前ですね。
上から順に公開鍵、秘密鍵、Langfuseのエンドポイント情報を渡すことができます。
どれもoptionalで、指定されていない場合は環境変数から読み取るようになっています。
使い方としては以下のとおりです。
langfuse = Langfuse(
public_key="xxxxxx"
secret_key="xxxxxx"
base_url="http://localhost:3000"
)
ちなみにpublic_keyやsecret_keyにfalseと判定されるような値を渡した場合、そもそも渡さなかった場合には以下の対応で環境変数を読み取りにいきます。
- 公開鍵:LANGFUSE_PUBLIC_KEY
- 秘密鍵:LANGFUSE_SECRET_KEY
- ベースURL:LANGFUSE_BASE_URL
2. Clientの呼び出し
get_clientという関数を使って「1」の手順で初期化したLangfuseクライアントを呼び出すことができます。
Langfuseクラスは内部でLangfuseResourceManagerというクラスを使用しており、そちらで生成したクライアントを管理しています。
get_clientもLangfuseResourceManagerを参照するため、get_client実行以前にLangfuseインスタンスを生成していれば、そちらを取得することが可能です。
3. Traceの連携
全体像は以下の通りです。
import time
from langfuse import get_client
SLEEP_TIME = 0.1 # 検証用スリープ時間(秒)
def test_put_trace():
langfuse = get_client()
user_query = "ユーザーからの質問"
tags = ["test", "chat"]
success = False
with langfuse.start_as_current_observation(
as_type="span", name="chat-session", input=user_query
) as chat_app:
# トレースの属性を設定
chat_app.update_trace(
name="chat-process", user_id="kuwan0", session_id="1", tags=tags
)
try:
with langfuse.start_as_current_observation(
as_type="span", name="retrieval", input=user_query
) as retrieval:
# ここから検索の計測が始まる
print("検索処理")
time.sleep(SLEEP_TIME)
with langfuse.start_as_current_observation(
as_type="retriever",
name="vector-store",
input=user_query,
) as vector_store:
# ここからベクトルストア参照の計測が始まる
print("ベクトルストア参照処理")
time.sleep(SLEEP_TIME)
with langfuse.start_as_current_observation(
as_type="embedding",
name="context-encoding",
input=user_query,
) as context_encoding:
# ここからコンテキストのエンコーディング参照の計測が始まる
print("コンテキストエンコーディング処理")
time.sleep(SLEEP_TIME)
embedding_result = "エンベディング結果"
context_encoding.update(output=embedding_result)
vector_store_result = "検索されたドキュメント"
vector_store.update(output=vector_store_result)
retrieval_result = "検索結果のコンテキスト"
retrieval.update(output=retrieval_result)
with langfuse.start_as_current_observation(
as_type="generation",
name="llm-response",
input=retrieval_result,
) as llm_response:
# ここからLLM回答の計測が始まる
print("LLM呼び出し処理")
time.sleep(SLEEP_TIME)
llm_result = "LLMからの回答"
llm_response.update(output=llm_result, model="dummy-model")
with langfuse.start_as_current_observation(
as_type="guardrail",
name="postprocessing",
input=llm_result,
) as postprocessing:
# ここから後処理の計測が始まる
print("後処理(有害コンテンツのフィルタリング)")
time.sleep(SLEEP_TIME)
postprocessing_result = "フィルタリング済み回答"
postprocessing.update(output=postprocessing_result)
with langfuse.start_as_current_observation(
as_type="span",
name="response-sent",
input=postprocessing_result,
) as response_sent:
# ここから後処理の計測が始まる
print("ストリーミングの返却")
time.sleep(SLEEP_TIME)
response_sent_result = "成功"
response_sent.update(output=response_sent_result)
chat_app.update(output=response_sent_result)
success = True
except Exception:
success = False
finally:
# フロー全体の結果に応じてタグを設定
result_tag = "success" if success else "failed"
chat_app.update_trace(tags=[*tags, result_tag])
実行した結果、以下のようなトレースが出来上がります。

クライアントを作成した後、Langfuse.start_as_current_observationという関数を使用します。
この関数は名前の通り、オブザーベーションを作成します。
as_typeでオブザーベーションの種類を選択できるのですが、トップレベルで呼び出すものはspanを指定します。
現在のLangfuseでは最初のスパンを作成したタイミングでトレースが自動的に作成されるようです。
トレースの設定はどのように更新するかというと、スパンコンテキストからupdate_traceという関数を呼び出すことで実現できます。
with句を使うことでブロックを抜けた際に自動的に終了時間を計測してくれます。
デコレータや手動で計測することも可能ですが、個人的にはこの方法が一番手軽で使い勝手が良いんじゃないかと考えています。
ネストしたい場合は、ネストしたいwithブロックの中で新しいstart_as_current_observation関数を呼び出すとOKです。
SDKv2ではトレースを明示的に作成することができたため、トップレベルのスパンが不要だったのですが、v3でOpenTelemetryベースのアーキテクチャに変更されたことで、スパンがトレースのエントリポイントになったようです。
冗長に見える構成は実は標準化のために必要だったので、あまり気にしなくて良いと思います。
また、トレース単位で集計された画面を写していましたが、セッションIDによる集計画面も用意されています。
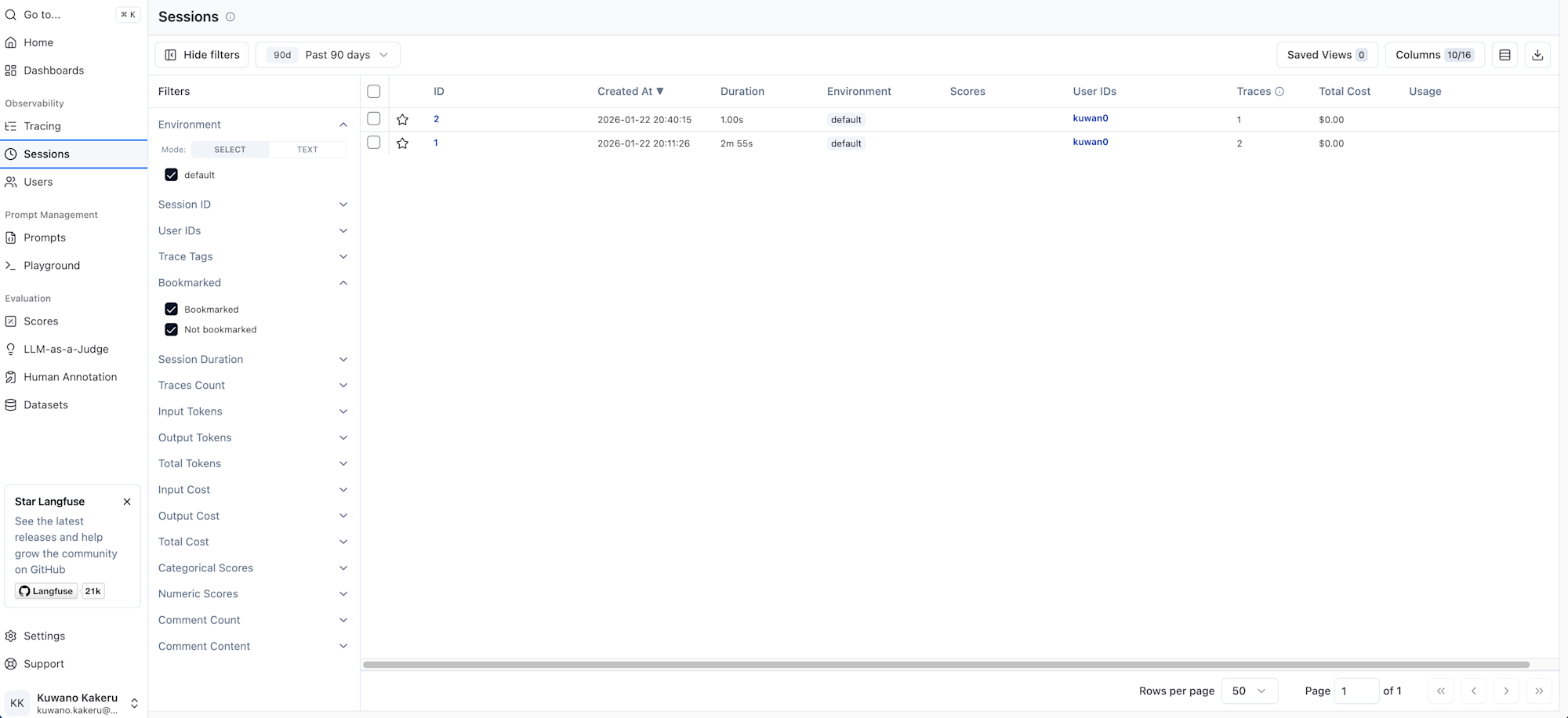
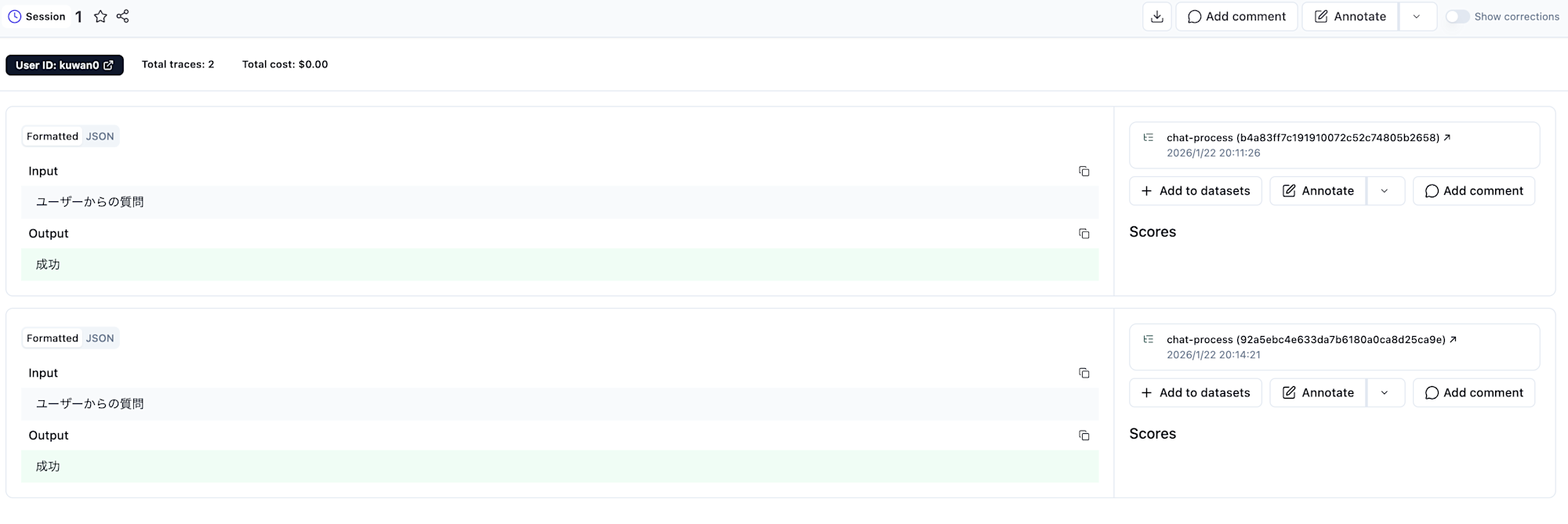
セッションIDが同じだと、以下のようにまとめて見れるため、チャットアプリのようなユーザーとシステムで複数回やり取りが発生するような処理はセッションで管理すると良さそうです。
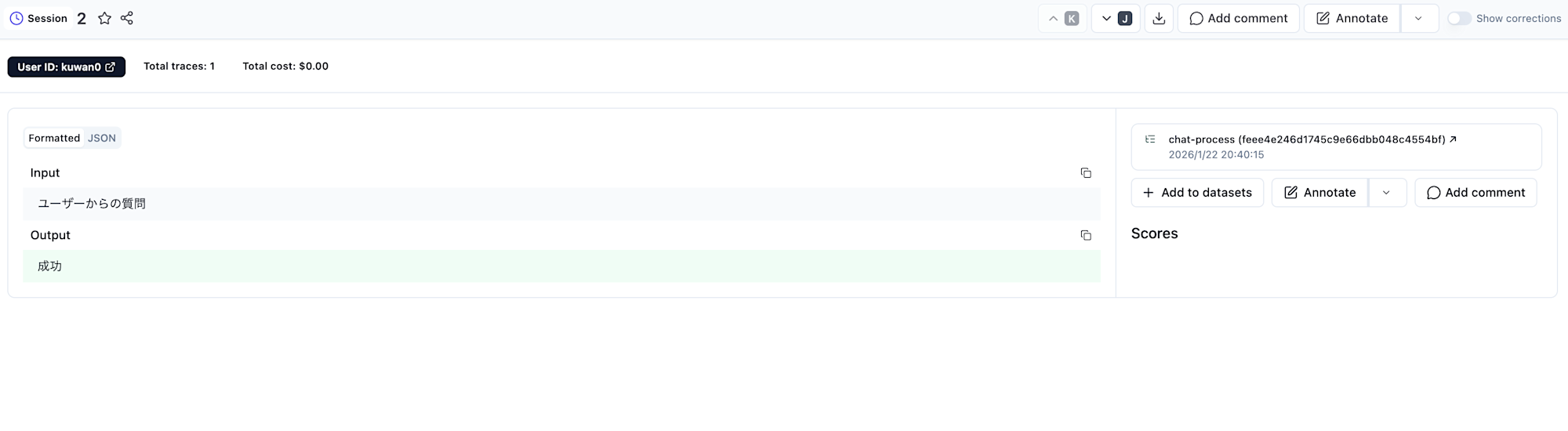
セッションIDを変更すると、別のやり取りと見なすことができそうですね。
まとめ
いかがだったでしょうか。
今までにオブザーバビリティやトレースについて触れたことがなかったり、収集したトレースをどのように活かすかということを考えたことがありませんでした。
そのため、その辺りの構造がどうなっているのか、なんでこの構造なのかということが全然理解できていませんでした。
Langfuseはオブザーバビリティを高めるために、どのような情報を収集すれば良いかという部分を定義してくれています。
データ構造を考える手間や、収集したデータを人間が処理しやすい形で見せるUIの準備を減らしてくれるので、その分ワークフローの改善やLLMのチューニングに積極的に投資することを後押ししてくれるツールなのだと考えています。
Langfuseのコンセプトを自分の中に落とし込むのは大変でしたが、それさえクリアしてしまえばSDKを使って簡単に連携することができますね。
今後もお付き合いすることになると思いますので、新しい気づきがあれば別の記事で共有できればと思います。
最後までご覧いただきありがとうございました。











