
Langfuse を DGX Spark で Self-host して LLM アプリの観測と評価を試してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
LLM を組み込んだアプリは、PoC で動かすところまでは早いんですが、その先で「先月の API 料金、結局いくらだった?」「あの応答、誰がレビューして OK 判定したっけ?」「プロンプトを差し替えたらスコアどれくらい動いた?」といった話を誰かが追わないといけなくなります。規模によってはログやスプレッドシートなどでしのぐこともできるかもしれませんが、運用フェーズに渡すころには、やはり 1 つの基盤に集約しておきたい欲求が強くなってきますね。
最近この用途で気に入って触っているのが、OSS の LLM 可観測プラットフォームである Langfuse です。トレース・コスト・スコア・プロンプト・人手レビューがひとまとめになっていて、しかも Self-host で全機能が解放されているのが大きな魅力です。手元の DGX Spark に立ち上げて、PoC から運用までを 1 本のスタックで回す感触を確かめながら、Langfuse の機能を順番に触ってみました。検証アプリは LangChain と Anthropic Claude Haiku 4.5 の組み合わせ、データセットは一般知識 QA 30 件で、ボリュームは小ぶりです。
Langfuse とは何か
使い方の話に入る前に、まず Langfuse がどんなツールなのかを 軽く整理しておきます。
開発元は Langfuse GmbH(ベルリン拠点)で、本記事執筆時点の最新版は server v3.172.1 / Python SDK v4.5.1。リポジトリは MIT ライセンスで、ee/ 配下のみ Enterprise Edition License という dual license 構成です。Cloud 版(langfuse.com)と Self-host 版が機能をほぼ揃えていて、Self-host でも商用利用が制限されないので、社内データを外に出したくない要件にすっと馴染みます(OSS 版のみ評価テンプレが空などの細かな差分はあり、章の中で触れていきます)。
他の LLM 可観測性ツールと並べると、Langfuse の立ち位置は次のようになります。
| 比較軸 | Langfuse | Arize Phoenix | LangSmith | MLflow Tracing |
|---|---|---|---|---|
| ライセンス | OSS(MIT、ee/ 配下のみ EE) | OSS(ELv2 + Apache) | 商用 SaaS | OSS(Apache) |
| コスト・トークン自動追跡 | per-model 単価で自動計算 | 限定的 | あり | なし |
| LLM-as-a-Judge | UI からマネージド設定 | phoenix-evals 同梱 |
同梱 | 外部連携 |
| Annotation 業務ワークフロー | Annotation Queue | span 単位の Annotation | あり | なし |
| OTel / OpenInference 準拠 | ネイティブ + 独自 SDK | ネイティブ | 独自 | 部分対応 |
| セルフホスト構成 | Docker Compose(6 サービス) | Docker x 1 | 限定的 | 単体可 |
OSS でフルスタックを Self-host できる選択肢は Langfuse の他にも複数あって、Phoenix も近い領域をカバーしています。Phoenix は Docker 1 本で立ち上がる軽さと OpenInference ネイティブの構造可視化が強みで、個人サンドボックスで span を眺めたい用途と相性が良いですね。Phoenix 自体のハンズオンは別記事に書いているので、興味があればこちらも合わせてどうぞ。
Langfuse が地味に効いてくるのはコスト追跡と Annotation Queue の 2 点で、PoC を超えて「誰かが料金やレビュー業務を回す」段階に進むとき、この 2 機能が標準で乗っているのは大きいです。LangSmith は LangChain / LangGraph と組むときに自然な選択肢、MLflow Tracing はすでに学習ワークフローも含めて MLflow で管理しているなら相性が良い、という棲み分けかなと思っています。
DGX Spark で Self-host する
ここからが手を動かすパートです。Langfuse の Self-host は公式リポジトリの docker-compose.yml をそのまま落としてきて、いくつかのシークレットを書き換えるだけで立ち上がります。DGX Spark は ARM64 ですが、6 サービスすべてが multi-arch イメージで配布されているので、--platform 指定なしで動きました。
起動するサービス
| サービス | image | port (host) | 役割 |
|---|---|---|---|
| langfuse-web | docker.io/langfuse/langfuse:3 | 3000 | Web UI + REST API + OTLP HTTP |
| langfuse-worker | docker.io/langfuse/langfuse-worker:3 | 127.0.0.1:3030 | バッチ評価 / コスト計算 |
| postgres | docker.io/postgres:17 | 127.0.0.1:5432 | メタデータ |
| clickhouse | clickhouse/clickhouse-server | 127.0.0.1:8123 / 9000 | トレース・スコアの大量書き込み |
| redis | docker.io/redis:7 | 127.0.0.1:6379 | キャッシュ + キュー |
| minio | cgr.dev/chainguard/minio | 9090 / 127.0.0.1:9091 | 大きなペイロードの S3 互換ストレージ |
サービス数だけ見ると重そうな印象を受けるかもしれませんが、worker と web を分けてバッチ処理を非同期化し、ClickHouse をトレースの本体ストアに据えて大量書き込みに耐える作りになっています。「ログを送りつける本体」と「集計・評価で処理を回す本体」を意識して分離しているのが、設計思想として興味深いところですね。
compose 設定とシークレット 7 個
公式 compose をそのまま落としてきて、必要なシークレットを .env で渡します。NEXTAUTH_SECRET / SALT / ENCRYPTION_KEY の 3 つは openssl rand -hex 32 で生成、PostgreSQL / ClickHouse / Redis / MinIO のパスワードは適当な強度の文字列を生成します。
cd ~/works/langfuse-handson
curl -fsSL -o compose.yaml \
https://raw.githubusercontent.com/langfuse/langfuse/main/docker-compose.yml
cat > .env <<EOF
NEXTAUTH_SECRET=$(openssl rand -hex 32)
SALT=$(openssl rand -hex 32)
ENCRYPTION_KEY=$(openssl rand -hex 32)
POSTGRES_USER=postgres
POSTGRES_PASSWORD=$(openssl rand -base64 24 | tr -d '/+=' | head -c 24)
POSTGRES_DB=postgres
DATABASE_URL=postgresql://postgres:\${POSTGRES_PASSWORD}@postgres:5432/postgres
CLICKHOUSE_USER=clickhouse
CLICKHOUSE_PASSWORD=$(openssl rand -base64 24 | tr -d '/+=' | head -c 24)
REDIS_AUTH=$(openssl rand -base64 24 | tr -d '/+=' | head -c 24)
MINIO_ROOT_USER=minio
MINIO_ROOT_PASSWORD=$(openssl rand -base64 24 | tr -d '/+=' | head -c 24)
LANGFUSE_S3_EVENT_UPLOAD_ACCESS_KEY_ID=minio
LANGFUSE_S3_EVENT_UPLOAD_SECRET_ACCESS_KEY=\${MINIO_ROOT_PASSWORD}
LANGFUSE_S3_MEDIA_UPLOAD_ACCESS_KEY_ID=minio
LANGFUSE_S3_MEDIA_UPLOAD_SECRET_ACCESS_KEY=\${MINIO_ROOT_PASSWORD}
LANGFUSE_S3_BATCH_EXPORT_ACCESS_KEY_ID=minio
LANGFUSE_S3_BATCH_EXPORT_SECRET_ACCESS_KEY=\${MINIO_ROOT_PASSWORD}
NEXTAUTH_URL=http://localhost:3000
TELEMETRY_ENABLED=true
EOF
chmod 600 .env
docker compose up -d
初期ユーザと API キーを compose で決め打ちにする
ここで便利なのが LANGFUSE_INIT_* 環境変数です。新規 DB の初回起動時にだけ反映される seed 機構で、初期ユーザ・組織・プロジェクト・プロジェクトの API キーまでまとめて固定値で作れます。スクリプト中の API キー差し替えが消えるので、ハンズオンの再現性が一段上がりました。
cat >> .env <<EOF
# Effective only on a fresh database
LANGFUSE_INIT_ORG_ID=handson-org
LANGFUSE_INIT_ORG_NAME="Handson Org"
LANGFUSE_INIT_PROJECT_ID=handson-project
LANGFUSE_INIT_PROJECT_NAME=langfuse-handson
LANGFUSE_INIT_PROJECT_PUBLIC_KEY=pk-lf-handson-public
LANGFUSE_INIT_PROJECT_SECRET_KEY=sk-lf-$(openssl rand -hex 16)
LANGFUSE_INIT_USER_EMAIL=you@example.com
LANGFUSE_INIT_USER_NAME="Your Name"
LANGFUSE_INIT_USER_PASSWORD=$(openssl rand -base64 18 | tr -d '/+=' | head -c 18)
EOF
docker compose down -v # 既に立てた後ならボリュームをリセットして再シード
docker compose up -d
ブラウザで http://localhost:3000 を開くと、もう Org と Project が並んでいます。
LANGFUSE_INIT_* で seed した Org とプロジェクトがそのまま並んでいる。中央のカードから Go to project で各タブに入る。
API キーをスクリプトから使う側の .env には、SDK が読み取る変数も追加しておきます。LANGFUSE_SECRET_KEY は先ほど LANGFUSE_INIT_PROJECT_SECRET_KEY で生成した値をそのまま流用したいので、grep で .env から引いて貼ります。
SECRET_KEY=$(grep '^LANGFUSE_INIT_PROJECT_SECRET_KEY=' .env | cut -d= -f2-)
cat >> .env <<EOF
LANGFUSE_PUBLIC_KEY=pk-lf-handson-public
LANGFUSE_SECRET_KEY=${SECRET_KEY}
LANGFUSE_HOST=http://localhost:3000
EOF
uv run --env-file=.env で実行すれば、これらが自動でロードされます。
Python クライアントの環境
サンプルは langfuse-python と LangChain で書きました。langfuse-python は v3 系から OpenTelemetry ネイティブな v4 系に移行していて、本記事は v4.5.1 で動かしています。サーバーが v3.172.1、SDK が v4.x で番号が並ばないので最初少し混乱しましたが、SDK 側の v4 メジャー bump が OTel への全面書き換えに伴うもので、サーバーとは独立して番号が進んでいる、という関係です。
uv venv --python 3.12
uv pip install \
"langfuse>=4.5" \
"langchain>=0.3" "langchain-anthropic" "langchain-openai" \
"openinference-instrumentation-langchain" \
"openinference-instrumentation-anthropic" \
"arize-phoenix-otel"
arize-phoenix-otel をここで入れているのは、後の章で「OpenInference で書かれた既存の OTel 計装コードを Langfuse に向けて流す」検証に使うためです。
OpenTelemetry / OpenInference / SDK の 3 経路でトレースを取る
Langfuse はトレースを送る経路を 3 つ用意しています。同じ trace を作るのに 3 通りの書き方があると最初は戸惑うんですが、それぞれ用途が分かれているので、自分のアプリに合いそうなものを選べば良いかなと思います。
| 経路 | コード例 | 利点 | 向いている場面 |
|---|---|---|---|
| Langfuse Python SDK | @observe() / start_as_current_observation() |
Generation の model から自動でコスト計算 |
Langfuse 専用で書く、最短経路 |
| OpenTelemetry OTLP | OTLPSpanExporter(endpoint="http://localhost:3000/api/public/otel/v1/traces") |
任意の OTel 計装が乗る | 既に OTel を使っているアプリにすぐ繋ぎたい |
| OpenInference | register(endpoint=...) で OpenInference 規約の計装を流用 |
フレームワーク横断の OpenInference 互換が効く | OpenInference で書かれた既存資産をそのまま使いたい |
SDK 経由
最小コードはこれだけです。get_client() でクライアントを取って、start_as_current_observation() をコンテキストマネージャで開いて、中で update() するとそのまま 1 トレースになります。
from langfuse import Langfuse
langfuse = Langfuse()
with langfuse.start_as_current_observation(
name="hello-smoke", as_type="span"
) as obs:
obs.update(
input={"question": "Hello, world?"},
output={"answer": "Self-host is alive."},
metadata={"phase": "0", "purpose": "smoke-test"},
)
trace_id = langfuse.get_current_trace_id()
langfuse.flush()
print(f"trace_id={trace_id}")
uv run --env-file=.env scripts/01_hello_smoke.py で実行すると、Langfuse の Web UI に hello-smoke という名前の trace が 1 件流れ込みます。
用語のメモを 1 つ。OpenTelemetry でいう「span」を、Langfuse は trace > observation という階層で扱います。observation はさらに span / generation / event の 3 タイプに分かれていて、generation だけがトークン数とコストを持ちます。as_type="generation" で開くか、LangChain の ChatModel などフレームワーク側に任せるのが自然な使い方ですね。
LangChain CallbackHandler 経由
実用上は LangChain の CallbackHandler を chain の callbacks に挟むのが一番楽です。invoke ごとに trace が作られて、内部の Runnable が observation のツリーになります。
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langfuse import Langfuse
from langfuse.langchain import CallbackHandler
handler = CallbackHandler()
langfuse = Langfuse()
llm = ChatAnthropic(model="claude-haiku-4-5", temperature=0)
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a concise assistant. Reply in a single sentence."),
("human", "{question}"),
]
)
chain = prompt | llm | StrOutputParser()
for q in ["What is the capital of Japan?",
"Who wrote 'Pride and Prejudice'?",
"Briefly: why is the sky blue?"]:
answer = chain.invoke(
{"question": q},
config={"callbacks": [handler], "run_name": "qa-handson"},
)
print(f"Q: {q}\nA: {answer}\n")
langfuse.flush()
run_name を渡すとその名前で trace が記録されます。Langfuse は API キーが Project に紐付いているので、複数プロジェクトを使い分けたい場合は環境変数のキーを差し替えるかたちですね。
OpenTelemetry / OpenInference 経由
Langfuse は /api/public/otel を OTLP HTTP のベースパスとして公開していて、トレース固定の signal-specific endpoint としては /api/public/otel/v1/traces を使います。OpenInference で書かれた既存の OTel 計装コードを、endpoint と headers の差し替えだけで Langfuse に流せる作りになっています。
import base64
import os
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from phoenix.otel import register
public_key = os.environ["LANGFUSE_PUBLIC_KEY"]
secret_key = os.environ["LANGFUSE_SECRET_KEY"]
basic = base64.b64encode(f"{public_key}:{secret_key}".encode()).decode()
# `register()` is the OpenInference helper that ships with arize-phoenix-otel.
# Pointing `endpoint` at the Langfuse OTLP HTTP receiver and adding a Basic
# auth header is the only change required. `auto_instrument=True` discovers
# the installed OpenInference instrumentors by package introspection.
register(
project_name="otel-openinference-route",
endpoint=f"{os.environ['LANGFUSE_HOST']}/api/public/otel/v1/traces",
headers={"Authorization": f"Basic {basic}"},
auto_instrument=True,
)
llm = ChatAnthropic(model="claude-haiku-4-5", temperature=0)
chain = (
ChatPromptTemplate.from_messages(
[("system", "You are a concise assistant. Reply in a single sentence."),
("human", "{question}")]
)
| llm
| StrOutputParser()
)
for q in ["What is the capital of Japan?",
"Who wrote 'Pride and Prejudice'?"]:
print(f"Q: {q}\nA: {chain.invoke({'question': q})}\n")
違いは endpoint を Langfuse の OTLP HTTP エンドポイントに向けて、headers に Basic 認証を載せた点だけです。OpenInference は LLM 可観測性ツール各社が共通で採用している semantic convention なので、span の attribute(llm.token_count.prompt / llm.model_name 等)も自然と伝わります。「すでに OpenInference 計装で書かれた既存コードを Langfuse に向けたい」というケースでも、ほぼコード書き換えなしで動くのがありがたいですね。
トレースとスパンを読み解く
LangChain の chain を 3 回 invoke すると、Tracing タブに qa-handson という名前の trace が 3 件並びます。
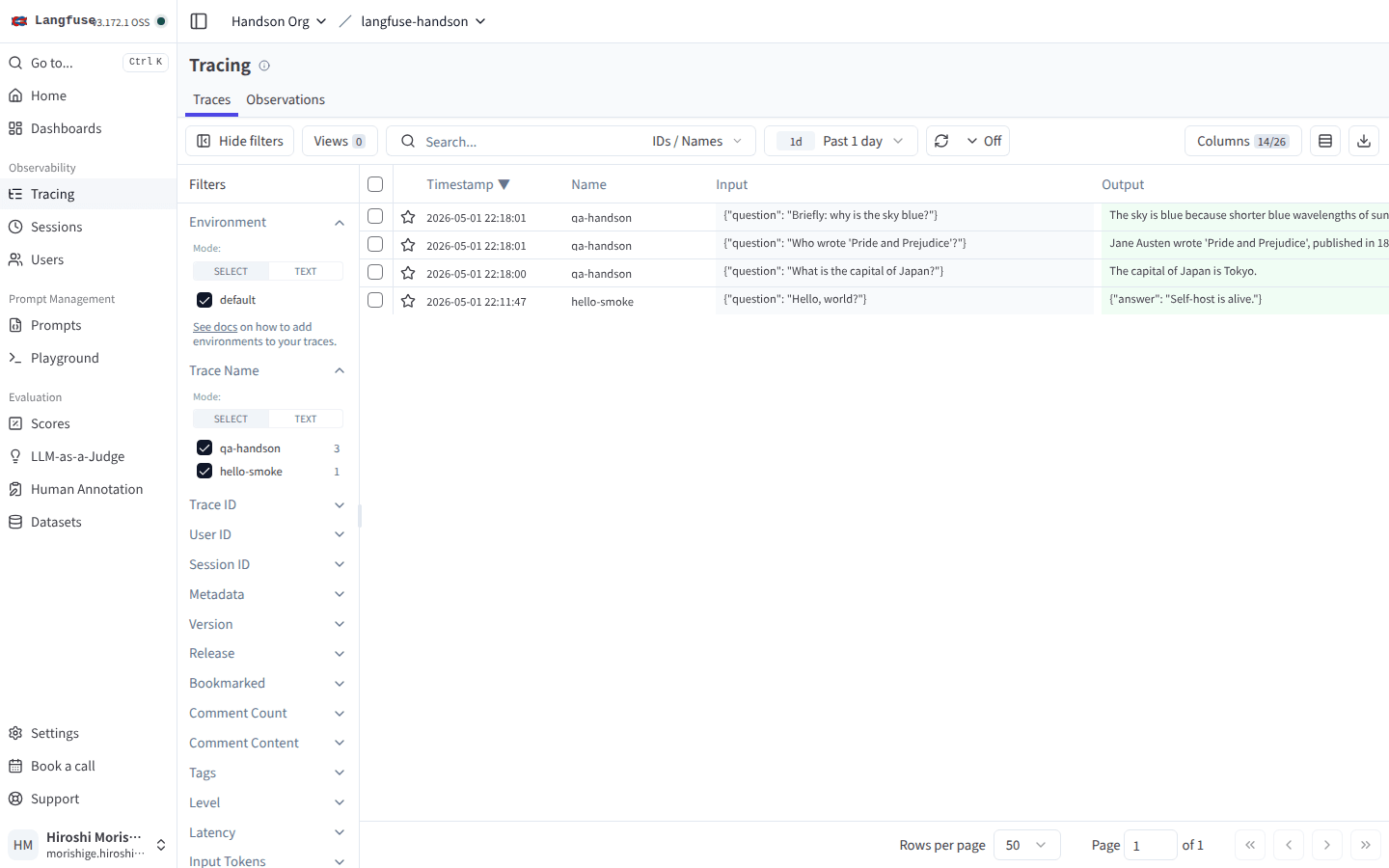
左ペインの Filters に Trace Name / Cost / Latency などの軸が並ぶ。中央のテーブルから 1 件クリックで右側に詳細パネルが開く。
左側のフィルタが充実していて、Trace Name / Trace ID / Session ID / Tags / Bookmarked / Latency / Cost / Score など多くの軸で絞り込めます。Cost と Latency が最初からフィルタ軸として用意されているので、「料金の高いトレースだけを集めたい」「P99 latency の長いものをまとめて見たい」という運用にすぐ繋がるのが便利ですね。
trace を 1 つクリックすると、左ペインに observation のツリー、中央の上に DAG、右に Input / Output と Metadata、その下に Token / Cost / Latency のサマリーが出ます。
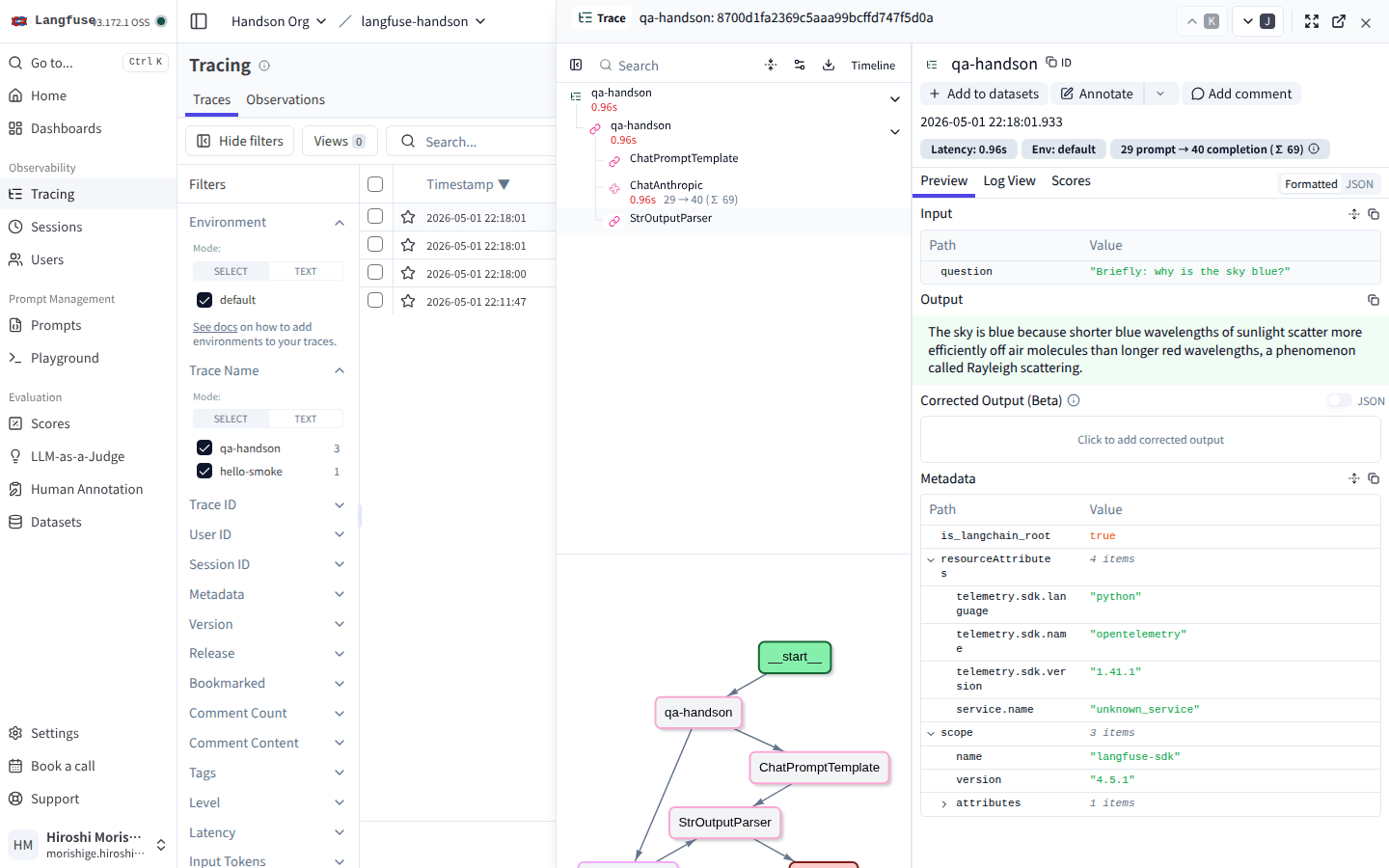
中央上のツリーで qa-handson 配下に LangChain の各 Runnable がぶら下がり、ChatAnthropic の行に 31 → 22 (Σ 53) tokens と $0.000141 が並ぶ。下部の DAG で実行順序も追える。
ここで注目したいのが、ChatAnthropic の行に 31 → 22 (Σ 53) というトークン数表示と、後の章で扱う $0.000141 の自動コストが並んでいる点です。Langfuse は Generation observation に対して、ingestion の段階で per-token のコストを計算します。LangChain の ChatAnthropic がトークン数を usage として送ってくれるので、その値に Langfuse の Models registry に登録された単価を掛けるだけで USD が出るわけですね。
なお、トレースのトップレベルには qa-handson という span がぶら下がり、その下に内側 qa-handson が入れ子になっているように見えます。これは LangChain の Runnable がネストした形をそのまま反映した結果で、外側がチェイン全体、内側が RunnableSequence です。チェインを多段にネストするほどこの入れ子は深くなるので、UI の Timeline 表示で確認するのが分かりやすいですね。
コストとトークンを自動追跡する
Langfuse の便利なところの一つが、ドル建てのコストを per-model 単価で自動計算してくれる点です。Models registry にモデル名と単価を登録しておけば、Generation observation の model フィールドにマッチした単価で、ingestion 時にコストが計算されて trace に記録されます。
Trace Cost が $0.00 のままになる初期状態
Dataset Run を 2 本回した直後、Experiments タブを開くと Trace Cost (avg) / (sum) が両方 $0.00 のままでした。
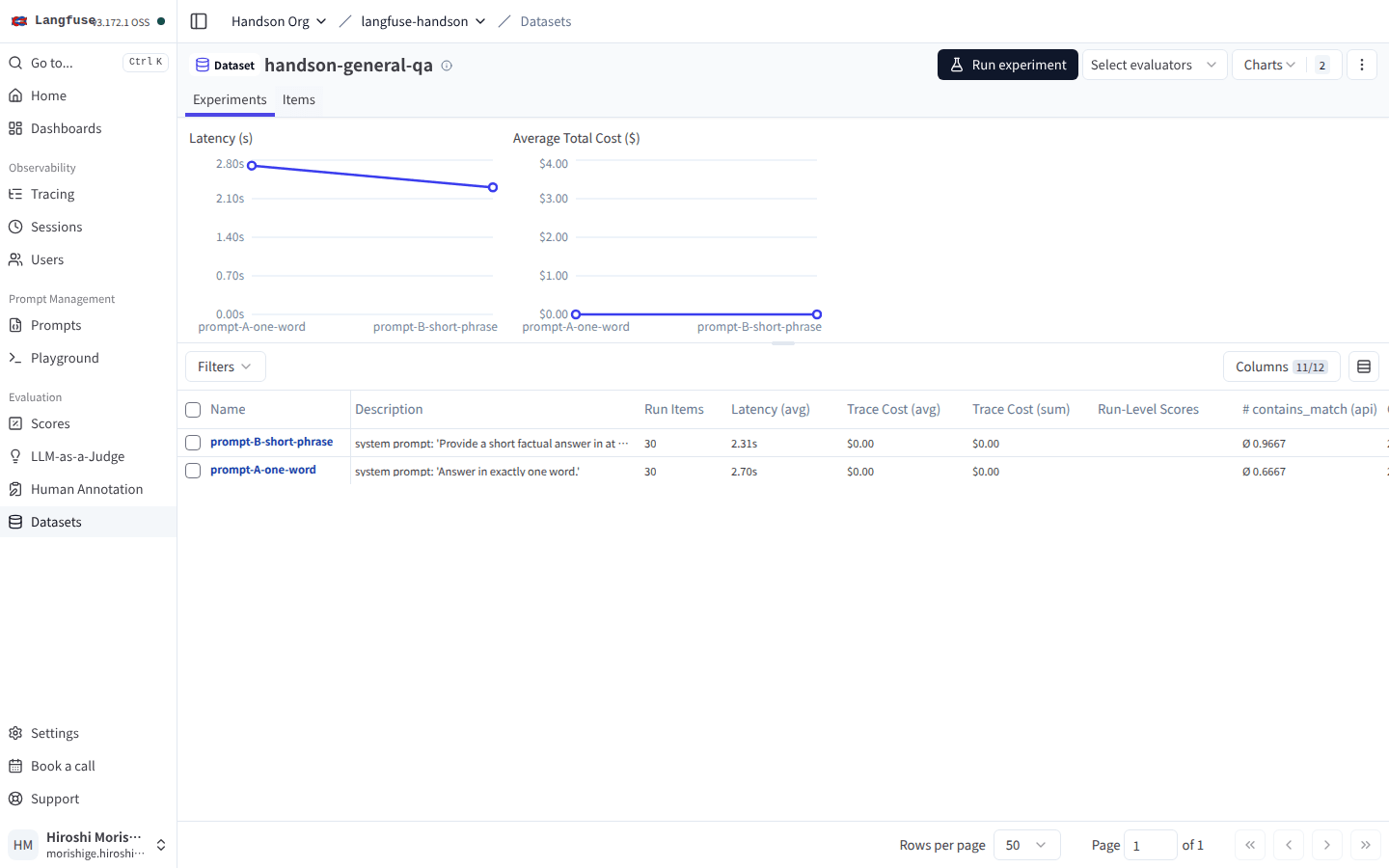
2 本の Run はちゃんと記録されているのに、Trace Cost (avg) と Trace Cost (sum) のカラムは両方 $0.00。トークン数だけ見ると正しく動いているように見えるのが厄介なところ。
トークン数はちゃんと記録されているのに、なぜコストだけゼロなのか。Settings > Model Definitions を開くと、すでに babbage-002 や claude-1.1 のような古めのモデルは登録されている一方で、claude-haiku-4-5 系は 1 件もありません。
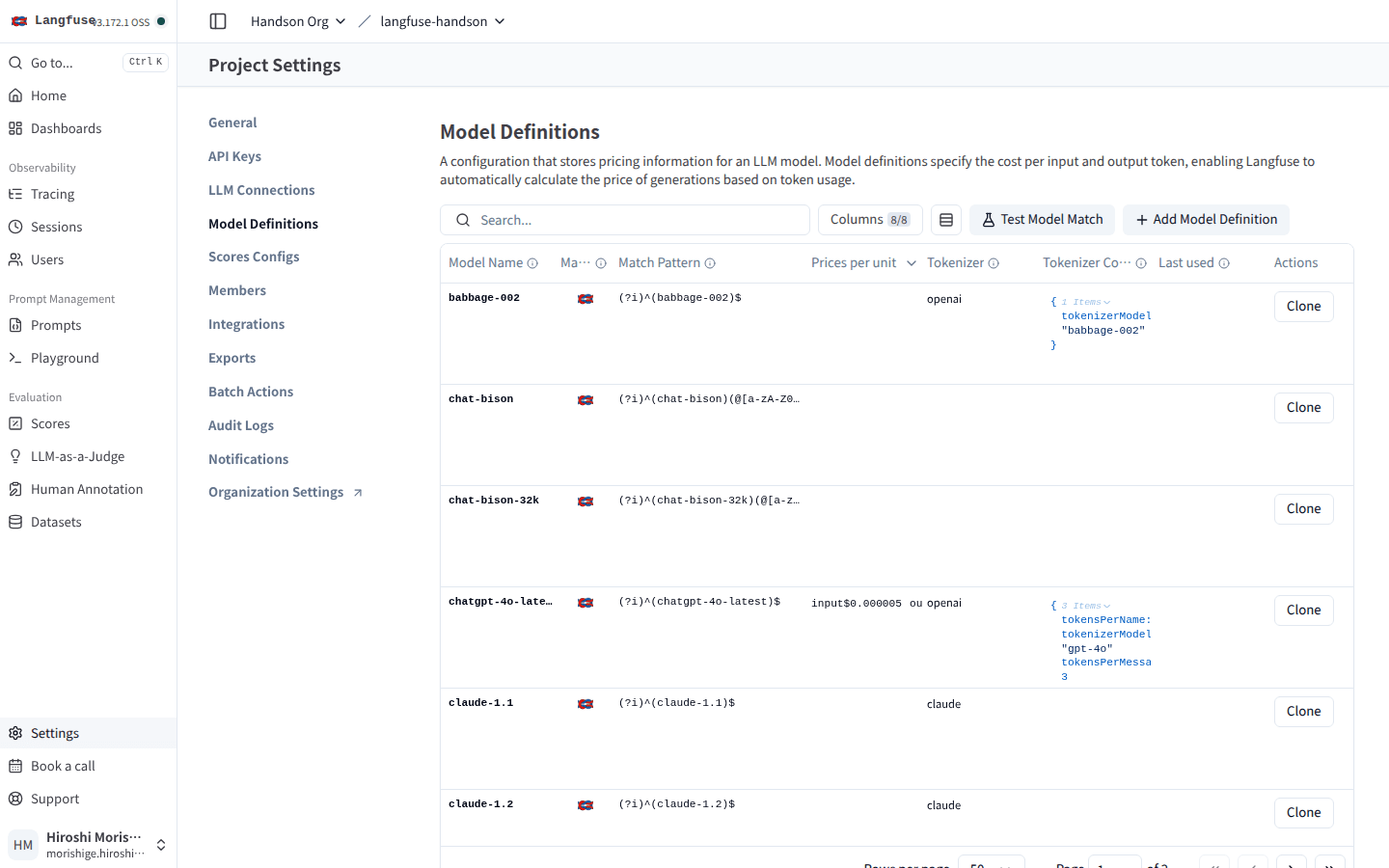
babbage-002 や claude-1.1 のような古いモデルは並んでいるが、検索ボックスに claude-haiku-4-5 を入れても何も出てこない。右上の + Add Model Definition から自分で 1 件追加する。
ここに自分で 1 行追加すれば動くはずです。
Add Model Definition で単価を登録する
「Add Model Definition」ボタンから Create Model モーダルを開きます。Anthropic 用のテンプレートボタンを押すと input / output の 2 行が事前に並ぶので、そのまま Anthropic 公式の Claude Haiku 4.5 価格($1 / 1M input、$5 / 1M output)を入れます。
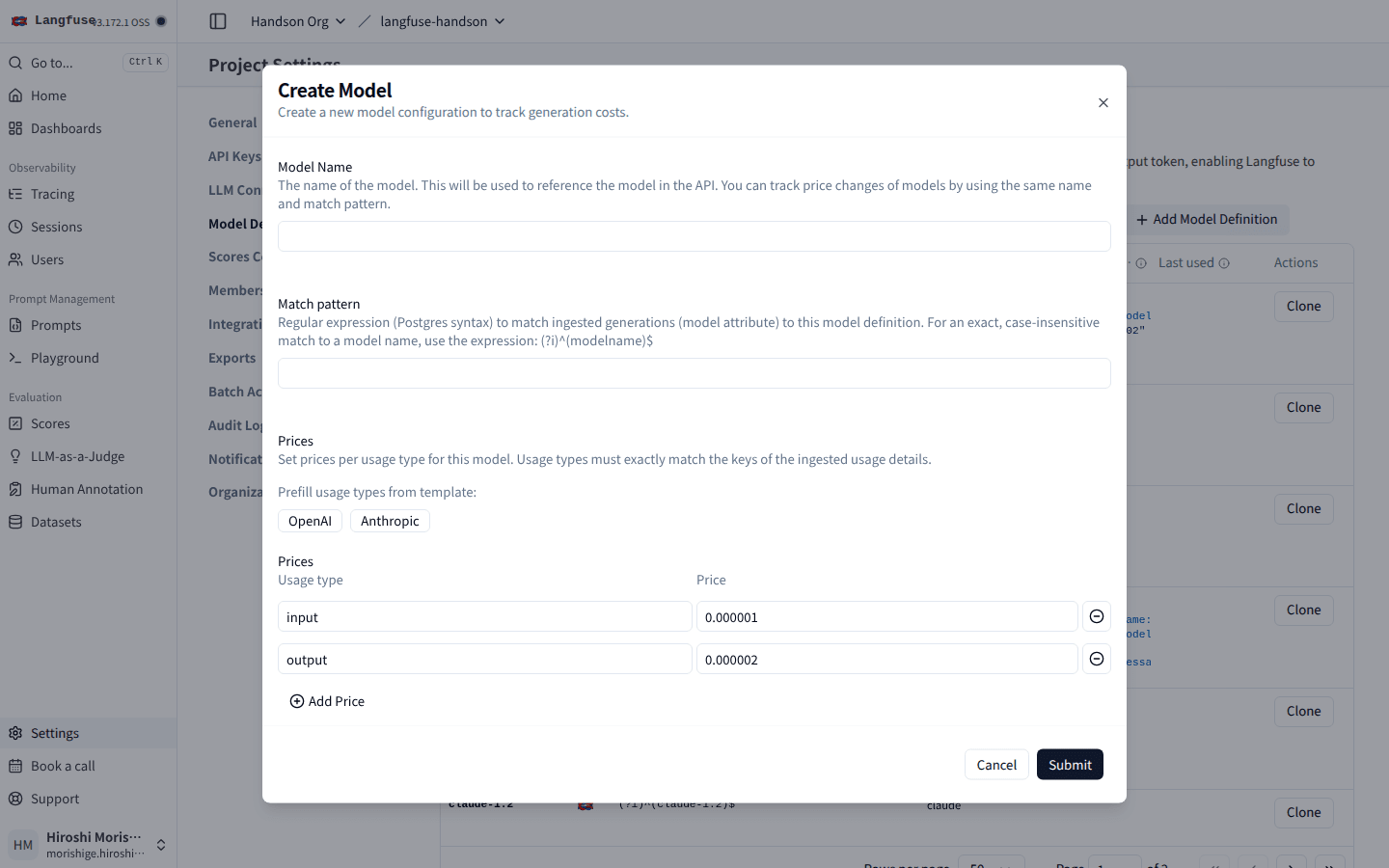
Model Name は claude-haiku-4-5、Match pattern には正規表現を入れる。中段の Anthropic テンプレートを押すと input / output の 2 行が事前に並ぶので、そこに per-token の値($1 と $5 を 1M で割った数値)を入力する。
最初に書いた Match pattern は (?i)^(claude-haiku-4-5)$ という完全一致でした。ここでもう 1 件落とし穴があって、Anthropic API が実際に返す model は claude-haiku-4-5-20251001 のような snapshot サフィックス付きなんですね。完全一致だと当然マッチしません。実際 Run を回してから API でぶら下がっている generation を見ると、こうなっていました。
$ curl -u "$PUBLIC_KEY:$SECRET_KEY" \
'http://localhost:3000/api/public/observations?type=GENERATION&limit=1' \
| jq '.data[0] | {model, usageDetails, costDetails}'
{
"model": "claude-haiku-4-5-20251001",
"usageDetails": {"input": 29, "output": 4, "total": 33},
"costDetails": {}
}
costDetails が空。Match pattern を snapshot サフィックスも拾うように (?i)^claude-haiku-4-5(-\d+)?$ に書き直して、もう一度 Dataset Run を実行します。今回は SDK 経由で 1 行で更新できます。
from langfuse import Langfuse
lf = Langfuse()
m = lf.api.models.create(
model_name="claude-haiku-4-5",
match_pattern=r"(?i)^claude-haiku-4-5(-\d+)?$",
unit="TOKENS",
input_price=0.000001,
output_price=0.000005,
)
print(f"id={m.id} pattern={m.match_pattern}")
再 Run でコストが乗る
新しい run name で Dataset Run を流し直して数秒待つと、Generation 詳細にちゃんとドル建てのコストが入りました。
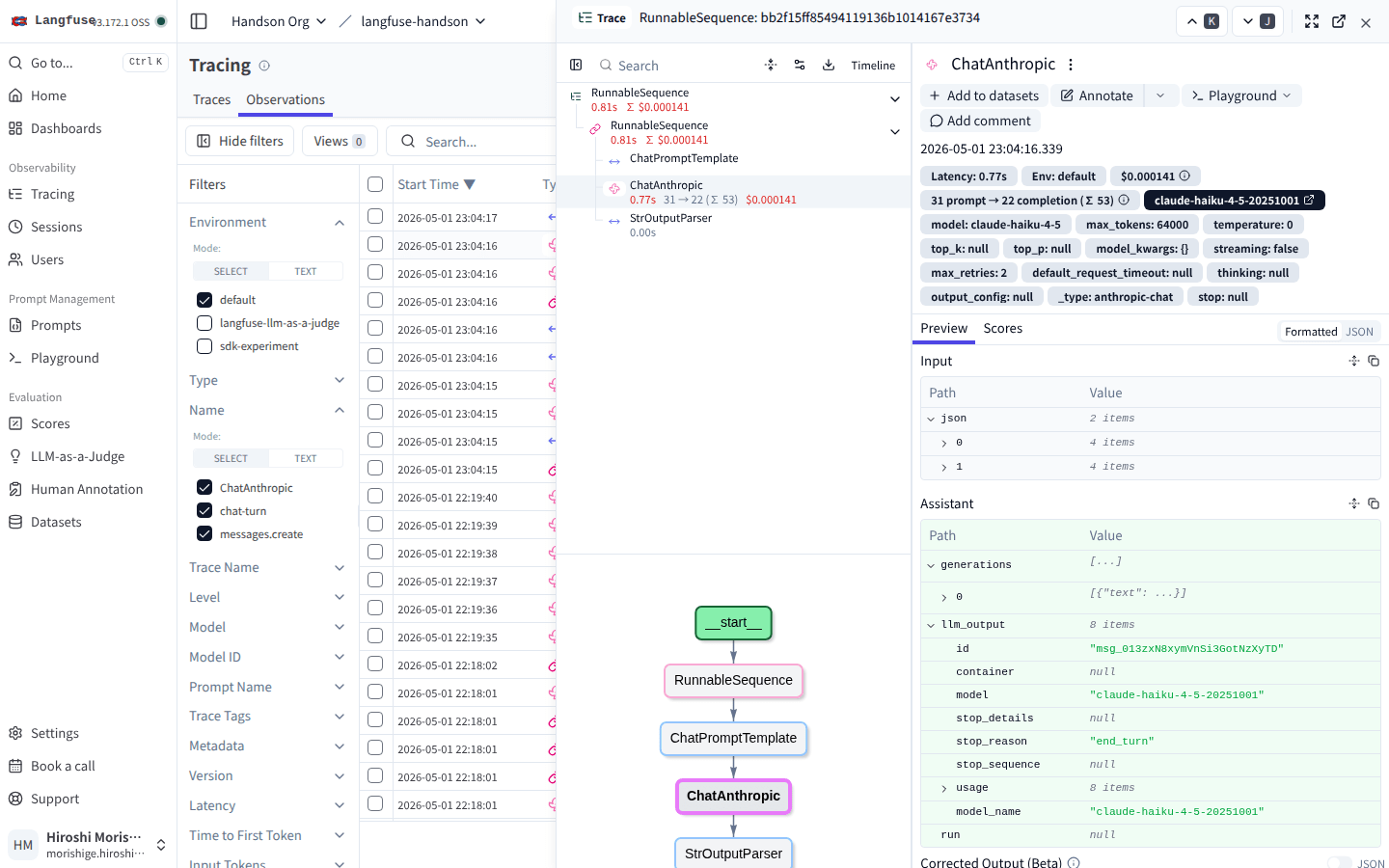
モデル名のバッジが claude-haiku-4-5-20251001(snapshot 付き)になっていて、Latency 0.77s の隣に $0.000141 が出ている。右側の Metadata 欄には model max_tokens temperature などのパラメータが全部展開される。
Experiments タブのコストカラムも、新しい Run にだけ値が入っています。
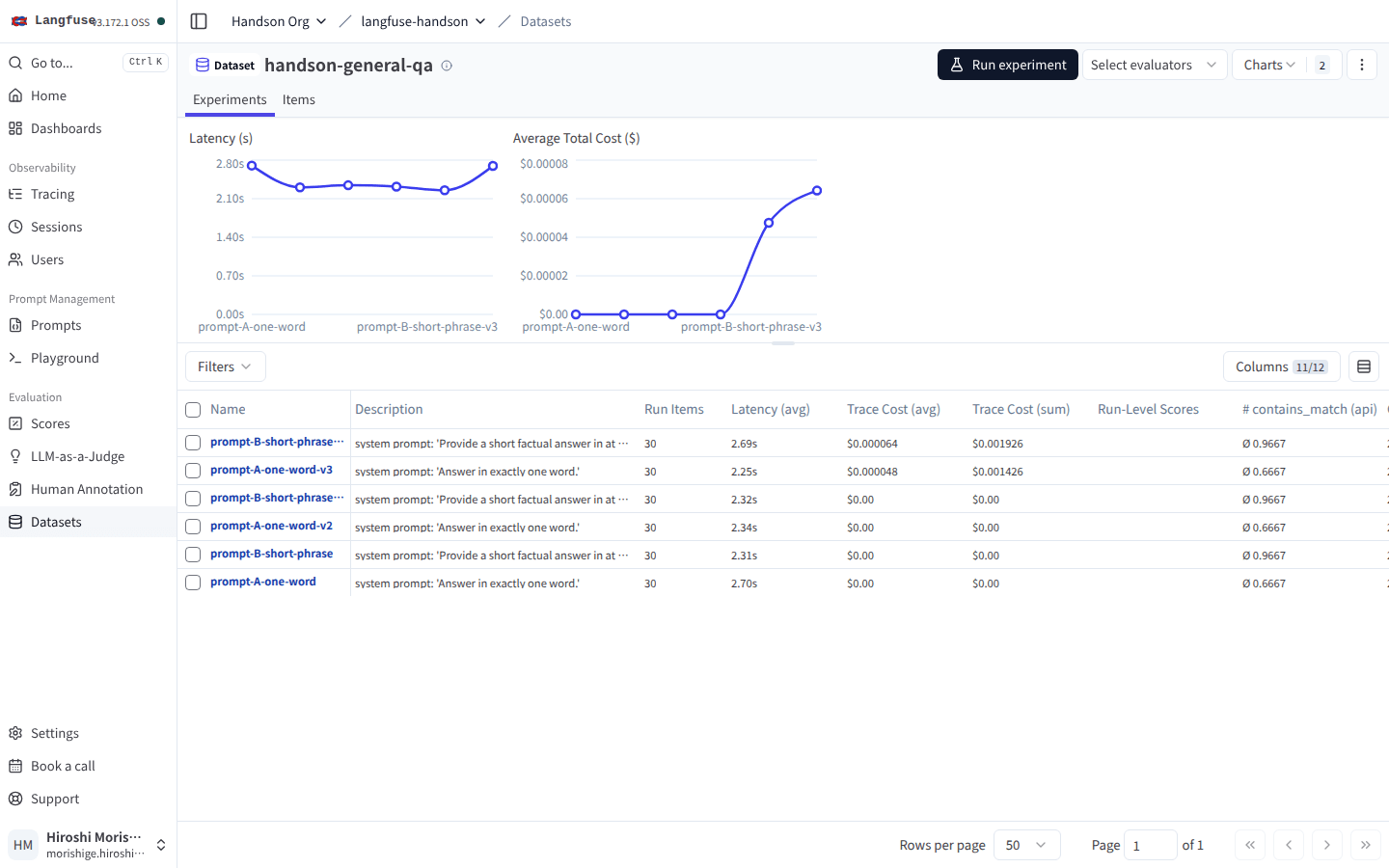
上部 Average Total Cost ($) のグラフが、最初の 2 本(v1 / v2)まで $0 のフラットだったのが v3 で一気に立ち上がる。下のテーブルでも v3 の Trace Cost (sum) に $0.001426 / $0.001926 と値が入る。
実測で取れた値はこんな感じです(Dataset 30 件、Claude Haiku 4.5、max_tokens=128)。
| Run | contains_match | Latency (avg) | Trace Cost (sum) |
|---|---|---|---|
| prompt-A-one-word-v3 | 0.6667 | 2.25s | $0.001426 |
| prompt-B-short-phrase-v3 | 0.9667 | 2.31s | $0.001926 |
30 件の Dataset Run まるまる走らせても 0.2 セント未満。こういう「料金感」を即座に把握できる UI が標準でついているのは、Cloud に課金されるサービスを書いている時にぐっと便利になります。
なお、Models registry の単価を後から変えても、過去の Generation のコストは再計算されません。コストは ingestion 時点の値で固定で、後付けの単価変更を反映するには新しいトレースを流すか、あるいは過去レコードを書き戻す Job を別途回すしかないようです。Langfuse の docs にもその旨が書かれているので、Models 定義は早めに揃えておくのがよさそうです。
マルチターン会話を Sessions に集約する
チャットボットや Agent ループを書いていると、1 つの会話に対して invoke が何回も走るので、UI 側で「この会話を 1 行にまとめて見たい」場面が出てきます。Langfuse はこのまとまりを Session と呼んでいて、langfuse_session_id という metadata を invoke ごとに渡すと、同じ ID の trace が UI 側で 1 行に集約されます。
import uuid
from langchain_anthropic import ChatAnthropic
from langchain_core.messages import HumanMessage, SystemMessage
from langfuse import Langfuse
from langfuse.langchain import CallbackHandler
handler = CallbackHandler()
langfuse = Langfuse()
llm = ChatAnthropic(model="claude-haiku-4-5", temperature=0)
def run_session(session_id: str, user_id: str, turns: list[str]) -> None:
history = [SystemMessage(content="You are a concise assistant. Keep every reply under 30 words.")]
for user_text in turns:
history.append(HumanMessage(content=user_text))
result = llm.invoke(
history,
config={
"callbacks": [handler],
"run_name": "chat-turn",
"metadata": {
"langfuse_session_id": session_id,
"langfuse_user_id": user_id,
},
},
)
history.append(result)
run_session(f"handson-{uuid.uuid4()}", user_id="alice", turns=[
"Tell me three famous sights in Kyoto.",
"Which one is closest to Kyoto Station?",
"How long does it take on foot?",
])
run_session(f"handson-{uuid.uuid4()}", user_id="bob", turns=[
"Recommend two day trips from Tokyo.",
"Which is better for first-time visitors?",
"What is the round-trip cost roughly?",
])
langfuse.flush()
2 セッション分実行してから Sessions タブを開くと、session_id ごとに 1 行に集約されます。
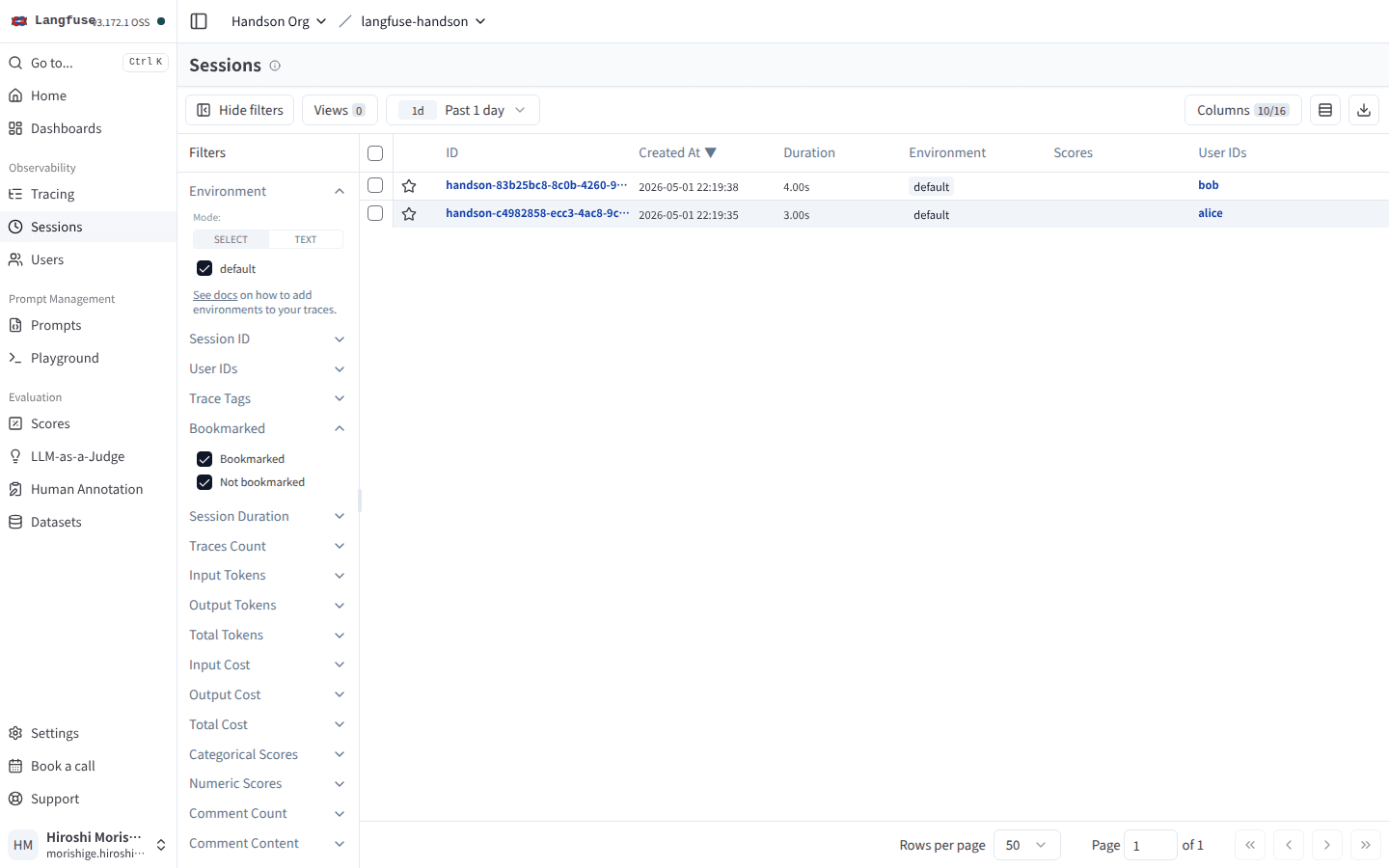
session ごとに 1 行に集約され、Duration や Total Tokens、User IDs カラムに alice / bob が並ぶ。左 Filters の Session ID / User IDs / Total Cost で会話単位の絞り込みもできる。
metadata に langfuse_user_id を入れているので、User IDs の列も自動で埋まりました。Sessions の左フィルタには Input Tokens / Output Tokens / Input Cost / Output Cost / Total Cost まで揃っていて、ユーザー単位・期間単位での「どの会話に料金がかかったか」を絞り込める作りになっています。
メタデータのキーで指定する形に統一されているので、LangChain 以外の SDK(OpenAI SDK 直接、CrewAI など)から呼ぶ場合も同じ langfuse_session_id / langfuse_user_id を渡すだけで揃います。フレームワーク横断で同じキー名で書けるのは楽でした。
回帰評価用のデータセットを Datasets に登録する
プロンプトやモデルを差し替えたあとに「前回より良くなったかどうか」を判断するには、毎回同じ入力で評価できるデータセットが必要になります。Langfuse の Datasets は SDK の create_dataset でハコを作り、create_dataset_item で 1 件ずつ詰めていく素朴な構造です。
from langfuse import Langfuse
QA = [
("What is the capital of France?", "Paris"),
("What is the capital of Australia?", "Canberra"),
# ... 一般知識 QA 30 件
]
DATASET_NAME = "handson-general-qa"
langfuse = Langfuse()
langfuse.create_dataset(
name=DATASET_NAME,
description="30 general-knowledge QAs for the langfuse handson article",
metadata={"source": "blog-handson", "size": len(QA)},
)
for i, (question, answer) in enumerate(QA):
langfuse.create_dataset_item(
dataset_name=DATASET_NAME,
input={"question": question},
expected_output={"answer": answer},
metadata={"qa_id": f"qa-{i:03d}"},
)
langfuse.flush()
UI の Datasets タブで詳細ページを開くと、30 件の Items が Input / Expected Output / Metadata の 3 ペインで並びます。
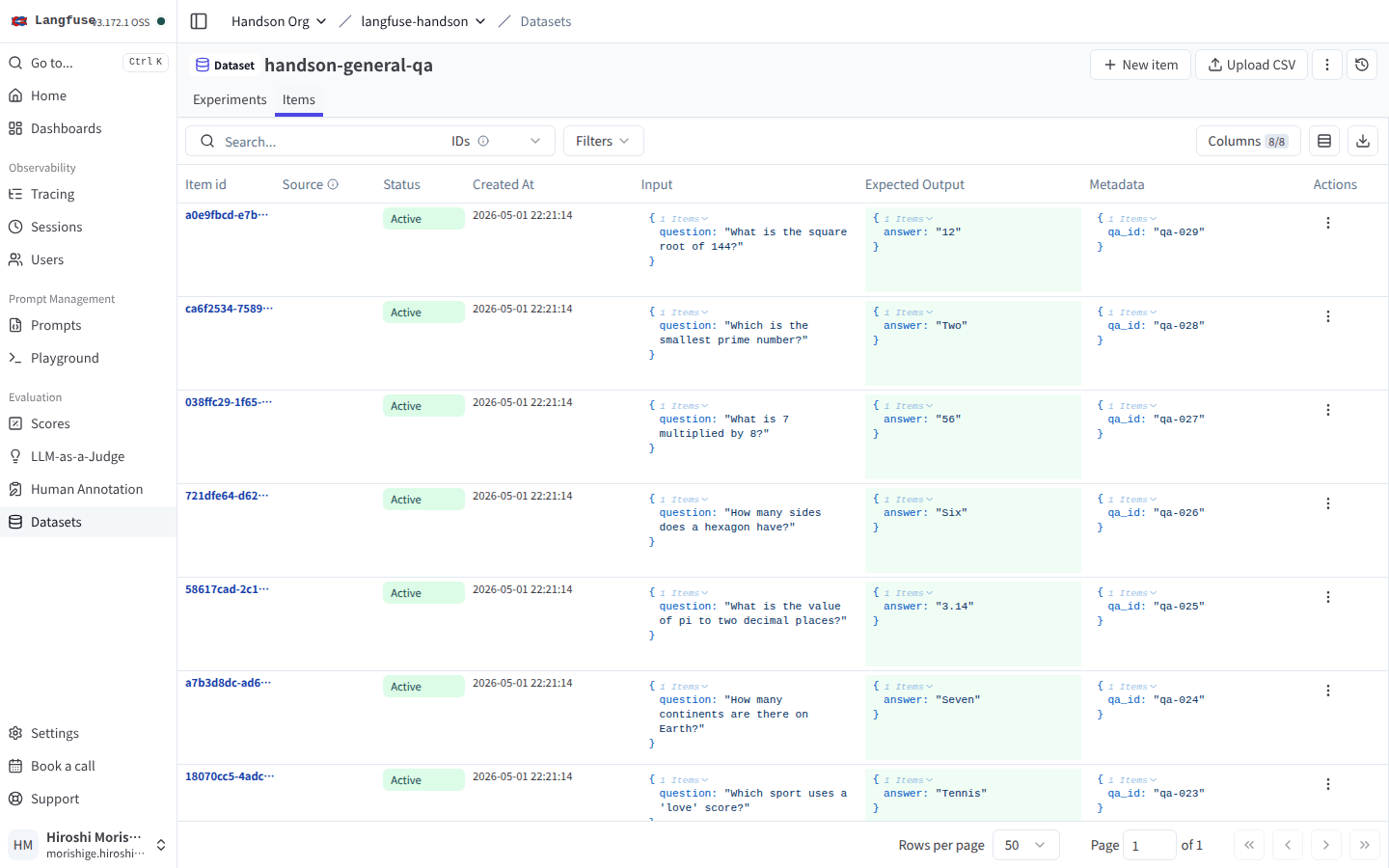
Item id(UUID 短縮)/ Status(Active)/ Input(question)/ Expected Output(answer)/ Metadata(qa_id)の 5 ペインで 30 件が並ぶ。右上の + New item から UI で追加することも可能。
input_keys / output_keys のような事前定義は不要で、input / expected_output / metadata という 3 つの dict をそのまま投げます。後で Dataset Run のコードでアクセスするときは item.input["question"] のような形になるので、キー名はここで決めた名前がそのまま効く点だけ注意ですね。
UI 側からは CSV アップロード / 1 件ずつ手で入力 / SDK 投入の 3 経路があるので、ノートブック検証中は SDK で揃えて、運用フェーズで CSV を取り込むような使い方もできそうです。
Dataset Run でプロンプトとモデルを比較する
「1 単語で答えろ(プロンプト A)」と「3 単語以内で答えろ(プロンプト B)」の 2 通りを、同じ 30 件 QA に流して比較してみます。Langfuse は langfuse.run_experiment(...) 1 本でこの「Dataset Run」をまとめて実行できます。
from langchain_anthropic import ChatAnthropic
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langfuse import Langfuse
from langfuse.experiment import Evaluation
from langfuse.langchain import CallbackHandler
DATASET_NAME = "handson-general-qa"
RUNS = [
("prompt-A-one-word-v3", "Answer in exactly one word."),
("prompt-B-short-phrase-v3", "Provide a short factual answer in at most 3 words."),
]
handler = CallbackHandler()
langfuse = Langfuse()
llm = ChatAnthropic(model="claude-haiku-4-5", temperature=0, max_tokens=128)
def build_chain(system_prompt: str):
return (
ChatPromptTemplate.from_messages(
[("system", system_prompt), ("human", "{question}")]
)
| llm
| StrOutputParser()
)
def make_task(chain):
def task(*, item, **_):
return chain.invoke(
{"question": item.input["question"]},
config={"callbacks": [handler]},
).strip()
return task
def contains_match(*, input, output, expected_output, **_):
expected = (expected_output or {}).get("answer", "")
return Evaluation(
name="contains_match",
value=1.0 if expected.lower() in str(output).lower() else 0.0,
comment=f"expected={expected!r}",
)
dataset = langfuse.get_dataset(DATASET_NAME)
for run_name, system_prompt in RUNS:
chain = build_chain(system_prompt)
langfuse.run_experiment(
name=DATASET_NAME,
run_name=run_name,
description=f"system prompt: {system_prompt!r}",
data=dataset.items,
task=make_task(chain),
evaluators=[contains_match],
max_concurrency=4,
)
langfuse.flush()
ここで自分が一回踏んだのが、evaluator の戻り値の型でした。最初 dict を返してみたところ、Langfuse SDK 側で Evaluator failed: 'dict' object has no attribute 'name' という警告が大量に出て、スコアが記録されません。Langfuse v4 は langfuse.experiment.Evaluation の専用 dataclass を期待するので、型をきちんと揃えれば一発で通りました。
実行結果はこんな感じです。
| Run | contains_match | Latency (avg) |
|---|---|---|
| prompt-A-one-word-v3 | 0.67 | 2.25s |
| prompt-B-short-phrase-v3 | 0.97 | 2.31s |
「1 単語ぴったり」プロンプトは正解の文字列が含まれていない応答が増えて 0.67 まで落ちましたが、「3 単語以内」プロンプトは 0.97 で安定しました。Latency 差は 0.06 秒程度なので、応答の冗長さが contains_match の差に直結しているのが分かります。
実装したタスクと evaluator はそのまま LLM-as-a-Judge にも繋がっていきます。
LLM-as-a-Judge をマネージド設定で動かす
Custom Evaluator を作って Dataset Run に紐付けると、新しい Run が来るたびに自動で評価がかかるようになります。コード側に評価呼び出しを書かず、UI で「いつ・どの evaluator を・どの対象に流すか」を設定する形で運用できるのが特徴ですね。
LLM Connection を登録する
評価には LLM が必要なので、まず Settings > LLM Connections でプロバイダ接続を作ります。SDK で投入するのが API キーをコンソールに残さずに済んでおすすめです。
import os
from langfuse import Langfuse
lf = Langfuse()
lf.api.llm_connections.upsert(
provider="anthropic-judge",
adapter="anthropic",
secret_key=os.environ["ANTHROPIC_API_KEY"],
custom_models=["claude-haiku-4-5"],
with_default_models=True,
)
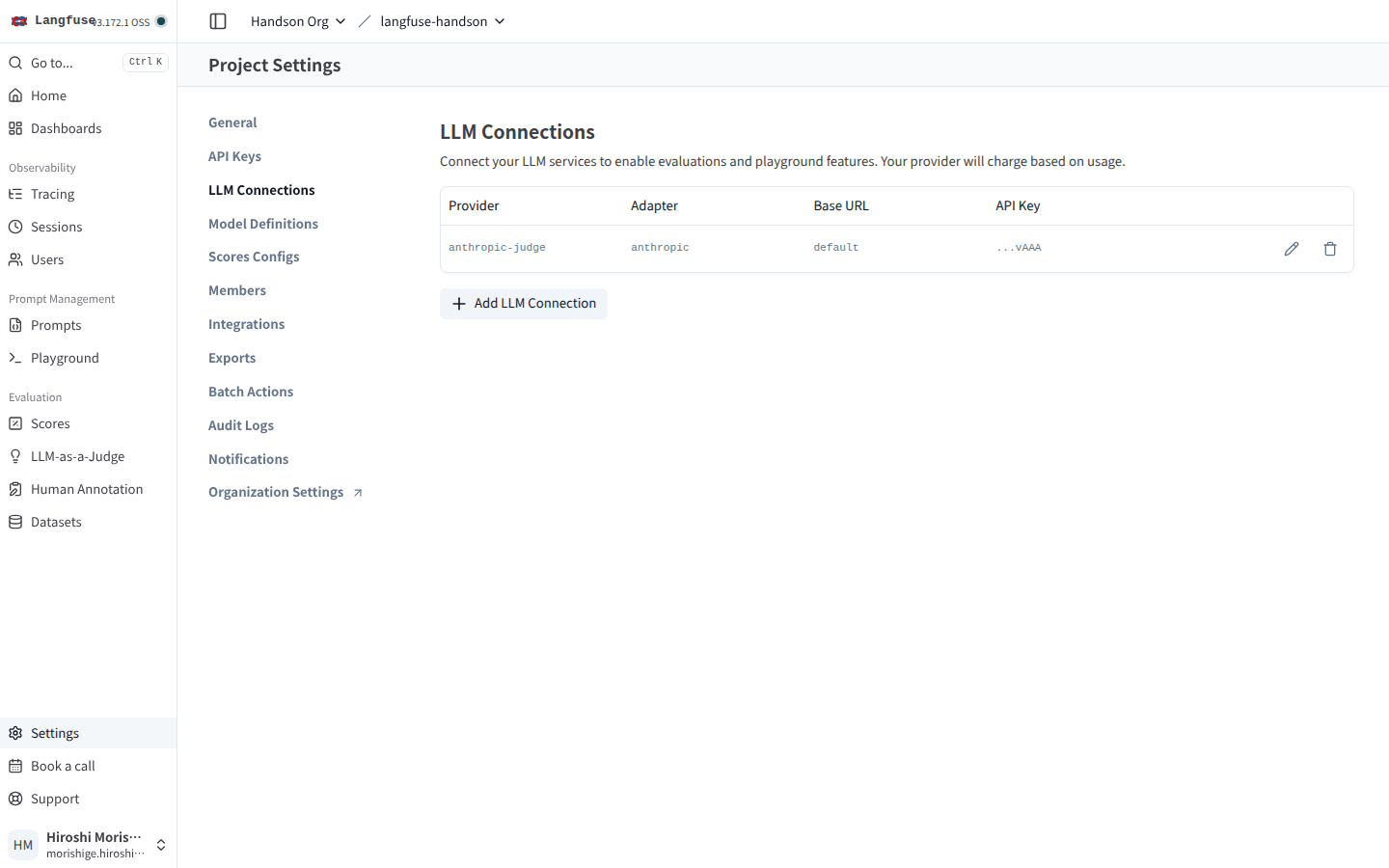
UI 側ではマスクされた API key 末尾と Provider 名が並ぶだけで、API キー全体は DB に encrypt されて保存されます(Settings > LLM Connections の API Key 列に ...vAAA のような末尾だけが残っている形)。
API Key カラムは末尾 4 文字の ...vAAA だけ表示され、本体は DB に encrypt されて保存される。+ Add LLM Connection から OpenAI / Anthropic / Bedrock / Vertex / Azure などを追加できる。
Default Evaluation Model を設定する
LLM-as-a-Judge ページで「Set up evaluator」を初めて開くと、まず Default Evaluation Model を設定するように促されます。先ほど作った anthropic-judge プロバイダの claude-haiku-4-5 を選んで Save。これは複数の Evaluator が共有するデフォルト値で、個別の Evaluator 側でモデルを上書きすることもできます。
Custom Evaluator を作る
ここで OSS 版固有の挙動として知っておきたいのが、「Select Evaluator」のテンプレート集が空だった点です。Cloud 版や商用版だと Hallucination / Helpfulness / Toxicity といったテンプレートが事前に並んでいるはずですが、Self-host の OSS 版では No evaluators found. Create a new evaluator to get started. と表示されました。
そのまま「Create Custom Evaluator」を押して、自前の Evaluator を作ります。
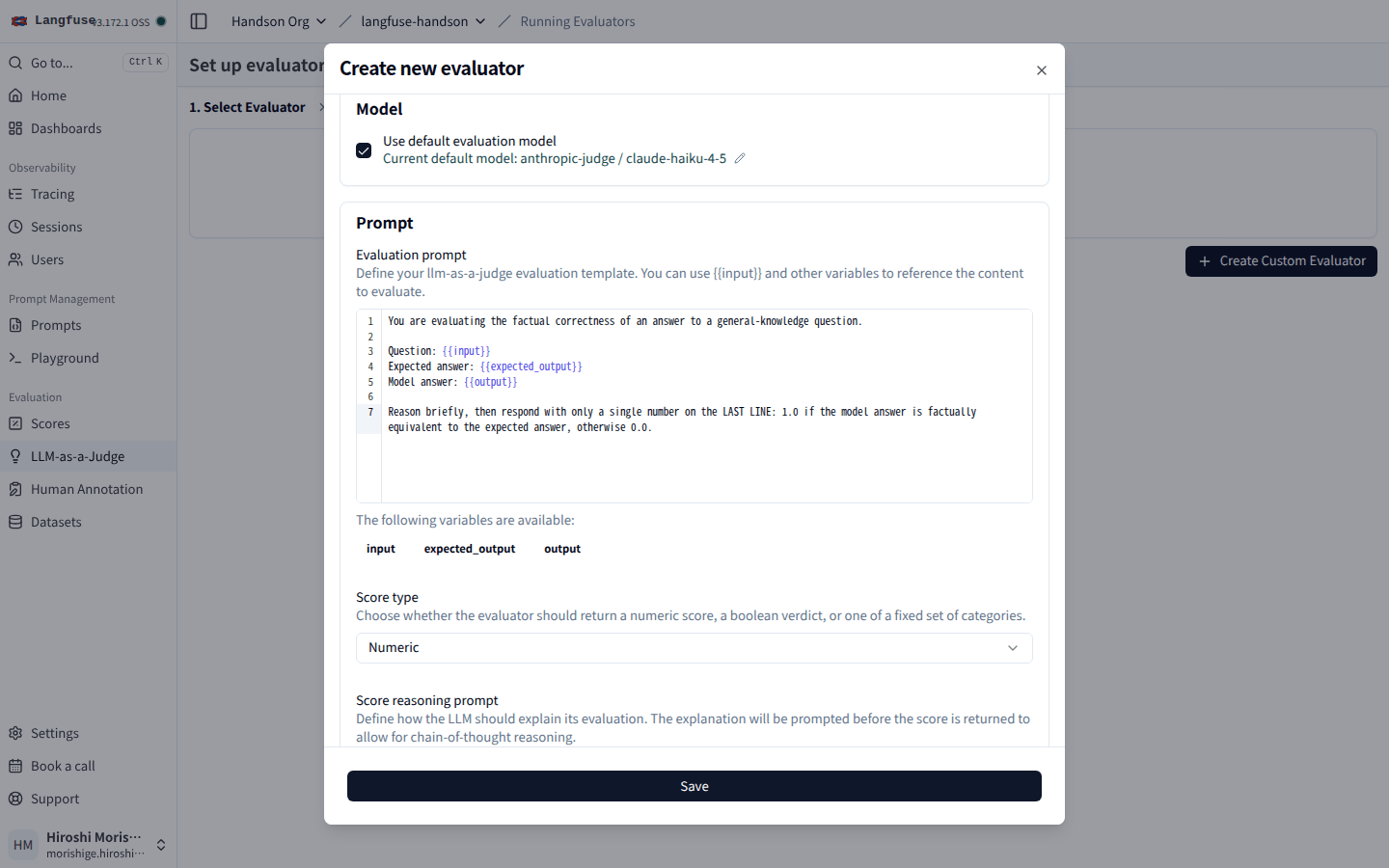
Evaluation prompt のエディタ下に The following variables are available: input, expected_output, output が表示され、テンプレ変数を機械的に検出してくれる。Score type は Numeric / Boolean / Categorical から選ぶ。
評価プロンプトはこんな内容にしました。
You are evaluating the factual correctness of an answer to a general-knowledge question.
Question: {{input}}
Expected answer: {{expected_output}}
Model answer: {{output}}
Reason briefly, then respond with only a single number on the LAST LINE: 1.0 if the model answer is factually equivalent to the expected answer, otherwise 0.0.
{{input}} / {{expected_output}} / {{output}} の 3 変数が使えます。Score type は Numeric を選択。Save するとそのまま Step 2 「Run Evaluator」に進みます。
Run on: Experiments を選ぶ
Step 2 では評価対象を選びます。Observations / Traces (Legacy) / Experiments の 3 タブがあって、Dataset Run の評価をしたい場合は Experiments を選びます。
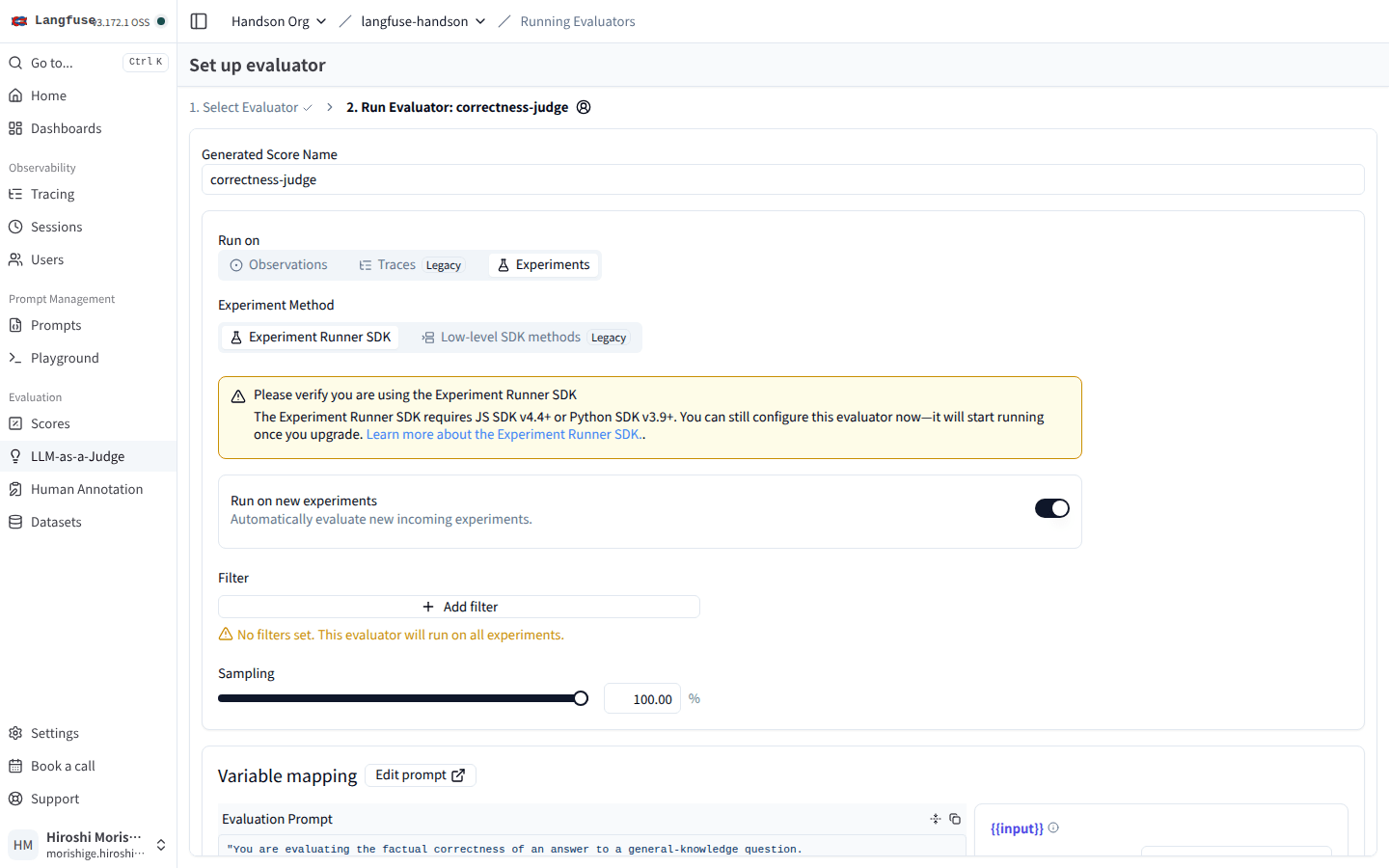
Run on を Experiments に切り替えた状態。Run on new experiments を ON、Sampling を 100% にしておくと、これ以降の Dataset Run に自動で評価が乗る。
「Experiment Runner SDK」と「Low-level SDK methods (Legacy)」の 2 つの方法があり、本記事のように langfuse.run_experiment() で Dataset Run を投げているコードは前者に該当します。Run on new experiments を ON、Sampling 100% で Save すれば、これ以降の Dataset Run には自動で評価が走ります。
Active 状態を確認 → 新しい Run で自動評価
Evaluator 一覧に戻ると、correctness-judge が Active で並びます。
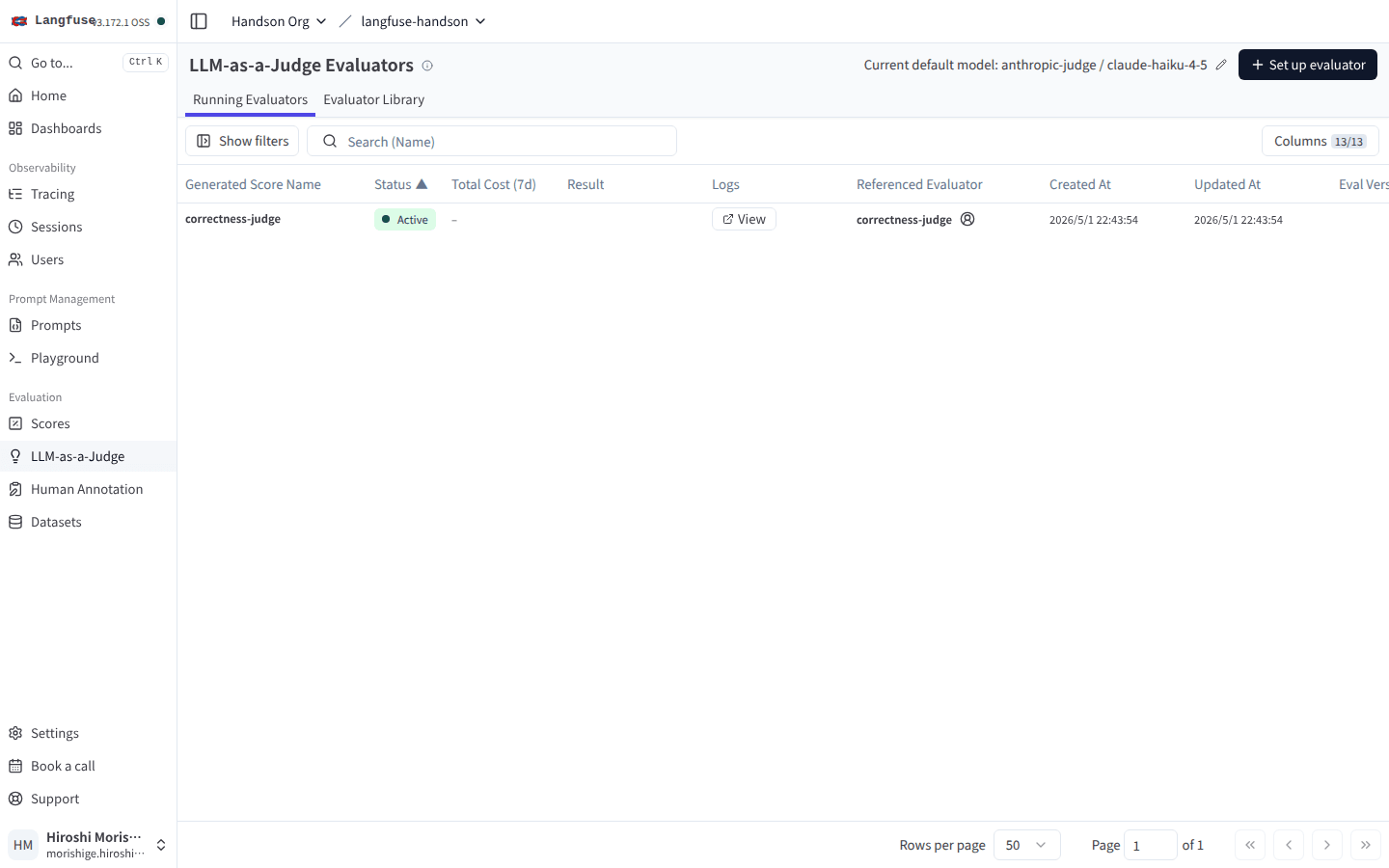
Status カラムが緑の Active になっていれば、Run on 設定に該当する trace に対して自動評価が走る。Logs 列の View から実行履歴とエラーを追える。
新しい Run name で Dataset Run を実行すると、30 件 × 2 Run = 60 件のうちタイムアウトを除く 59 件で自動採点が完了しました。Dataset Experiments タブでも、各 Run の右側に correctness-judge の平均スコアが Run-Level Scores として並びます。
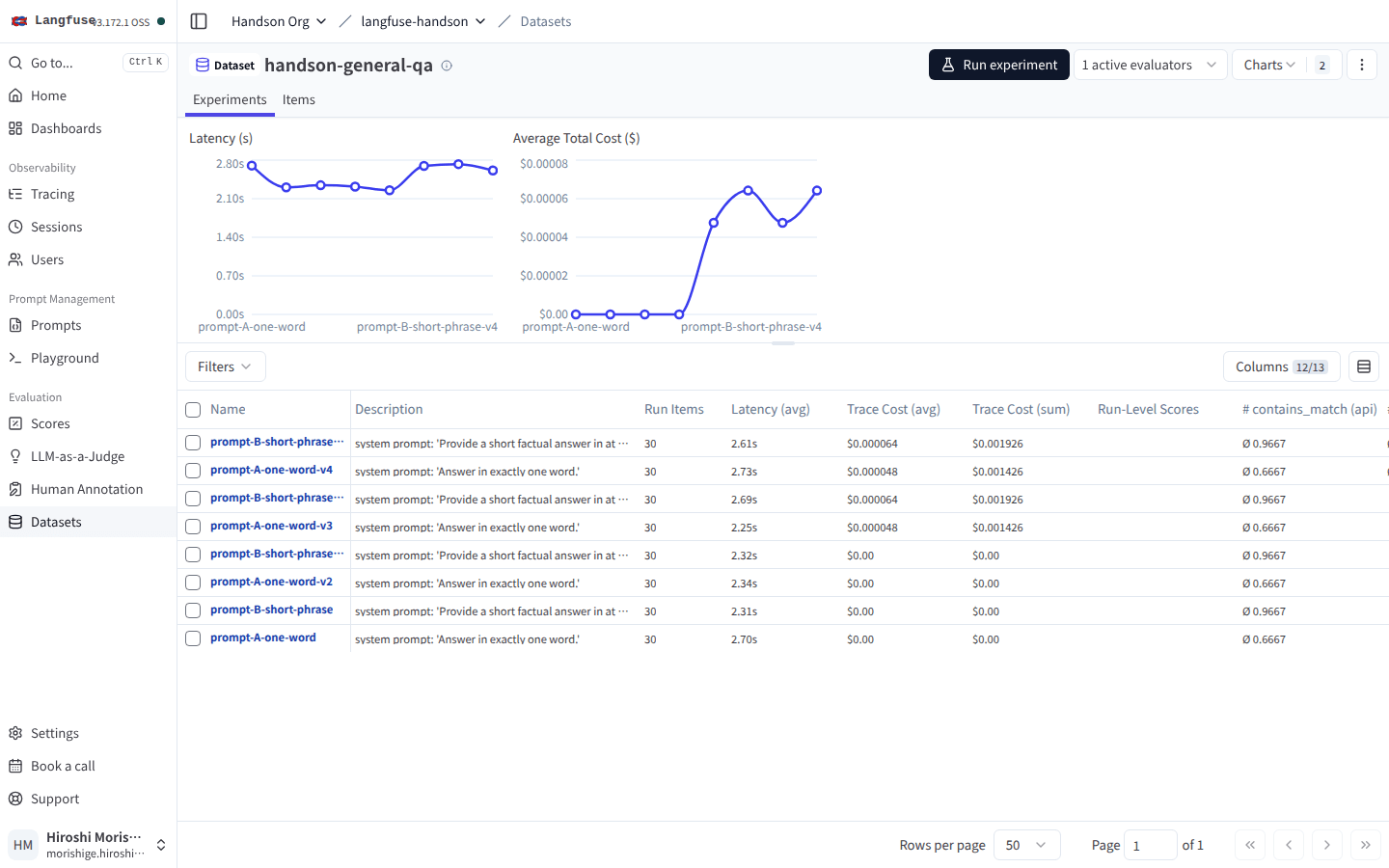
右上に 1 active evaluators バッジが立ち、各 Run の Run-Level Scores カラムに correctness-judge のスコアが、SDK 側で計算した contains_match と並んで入る。
採点コメントを Scores ページから引いてみると、judge LLM の判定理由がコメントとして残っているので、後から「なぜこの問題が 0 点になったのか」を辿れます。
The question asks "What is the capital of Australia?" However, the model answer is …
The user is asking me to evaluate the factual correctness of …
Evaluator を一度設定してしまえば、自分のコードに評価呼び出しが入らないのが楽ですね。「データを増やしながら評価が自動で乗る」運用に寄せやすい構造になっています。
Prompt Management でプロンプトをラベル運用する
アプリ側のリポジトリにプロンプトをハードコードしておくと、軽い文言修正のたびにデプロイが走って小回りが効きません。Langfuse の Prompt Management にプロンプトを置いておくと、production や baseline のようなラベルを付けてバージョンを管理でき、アプリ側からは get_prompt(name, label="production") のラベル指定で引いてこられます。プロンプトの差し替えはラベルの付け替えだけで完結するので、デプロイなしで本番のふるまいを切り替えられるのが利点ですね。
from langfuse import Langfuse
PROMPT_NAME = "handson-concise-qa"
langfuse = Langfuse()
v1 = langfuse.create_prompt(
name=PROMPT_NAME,
prompt=[
{"role": "system", "content": "You are a concise assistant. Reply in a single sentence."},
{"role": "user", "content": "{{question}}"},
],
config={"model": "claude-haiku-4-5", "temperature": 0, "max_tokens": 128},
labels=["baseline"],
type="chat",
commit_message="v1 baseline concise prompt",
)
v2 = langfuse.create_prompt(
name=PROMPT_NAME,
prompt=[
{"role": "system", "content": "You are a precise factual assistant. Answer with exactly one short sentence, no preamble."},
{"role": "user", "content": "{{question}}"},
],
config={"model": "claude-haiku-4-5", "temperature": 0, "max_tokens": 128},
labels=["production"],
type="chat",
commit_message="v2 stricter one-sentence prompt with no preamble",
)
production = langfuse.get_prompt(PROMPT_NAME, label="production")
print(f"production resolves to v{production.version}")
UI の Prompts タブで handson-concise-qa を開くと、左に Versions リスト、右に選択中バージョンの内容が表示されます。
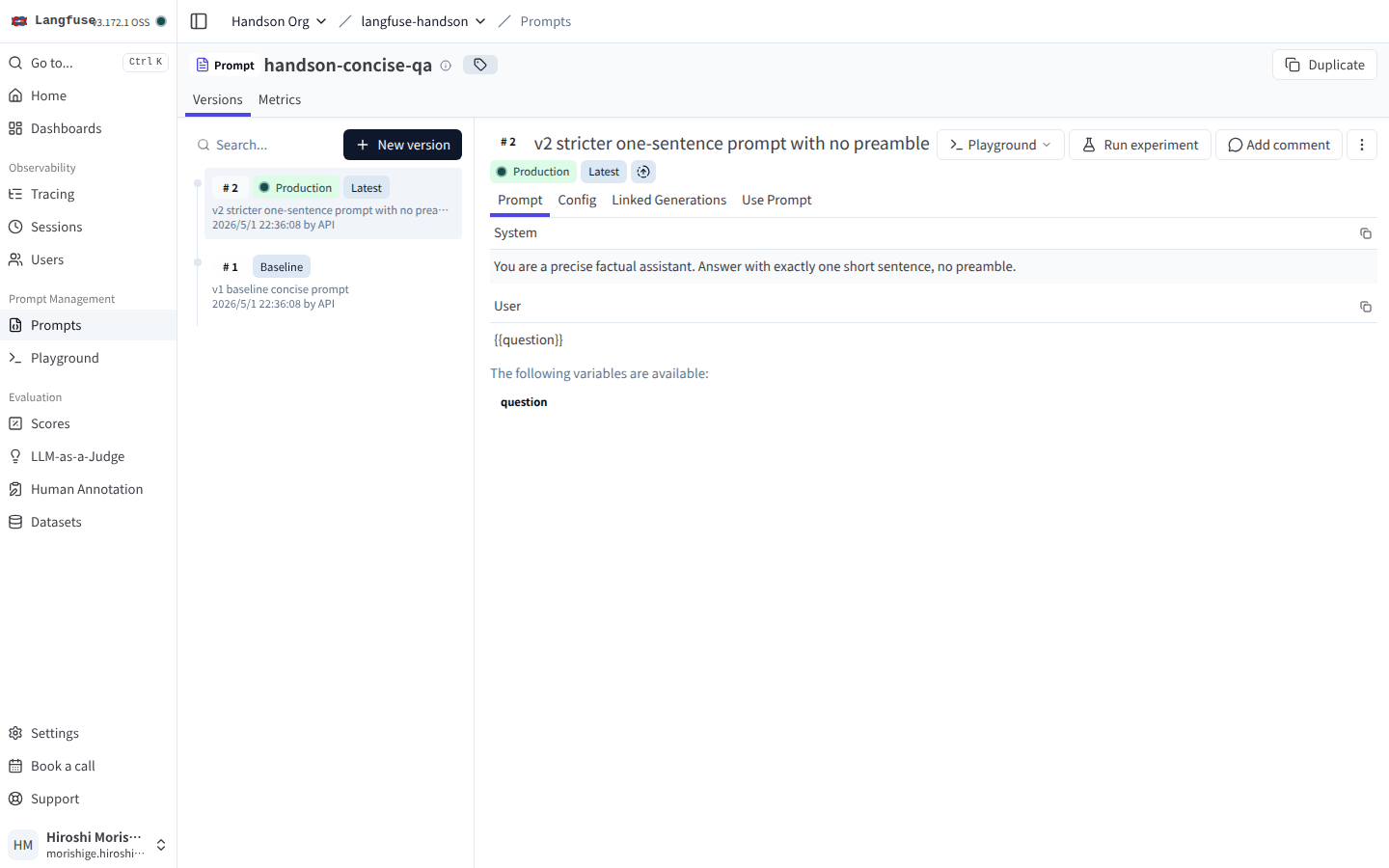
左ペインの Versions リストにバージョンが時系列で並び、選択中バージョンの System / User メッセージが右側に表示される。Production / Baseline のラベルが緑のバッジで付いている。
ラベルは同じ Prompt 内で一意になっていて、production を v2 に付けると v1 から自動で外れる作りになっています。「production を v2 にロールフォワード」という操作が、新しいバージョンに production ラベルを付けるだけで完結するのが運用上は分かりやすいですね。
get_prompt(name, label="production") でアプリ側がプロンプトを引いてくるとき、SDK には簡単な caching が入っています。デフォルトで TTL 60 秒、get_prompt(..., cache_ttl_seconds=600) で長くしたり、fallback=... で初回失敗時のフォールバックを書いたりもできるので、本番アプリに組み込んでもネットワーク越しの呼び出しは抑えられそうです。
UI の Playground 画面では、登録済みのプロンプトを直接編集して LLM Connection 経由で実行できるので、本記事のようなテキストモデルだけでなく、CR 系の VLM や OpenAI 互換エンドポイントに繋いだローカル LLM でも、その場でプロンプトを動かして応答を眺める使い方ができます。
Annotation Queue で人手レビューを業務化する
Langfuse の便利なところの三つ目です。Annotation Queue という業務 UI が別建てで用意されていて、「キューに trace を突っ込む → reviewer が 1 件ずつ採点する → 完了をトラックする」という流れを SDK + UI でセットにできます。スコア API を 1 件ずつ叩く形に比べて、レビュー業務の進捗管理まで含めて回しやすいのが利点ですね。
from langfuse import Langfuse
langfuse = Langfuse()
# 1. 採点に使う Score Config を作る
helpful = langfuse.api.score_configs.create(
name="reviewer-helpful",
data_type="NUMERIC",
min_value=0.0,
max_value=1.0,
description="Reviewer-graded helpfulness, 0.0 (not helpful) to 1.0 (very helpful).",
)
# 2. Queue を作る
queue = langfuse.api.annotation_queues.create_queue(
name="handson-review-queue",
description="Manual review queue for the langfuse handson article",
score_config_ids=[helpful.id],
)
# 3. 直近の qa-handson trace を 3 件だけキューに入れる
for trace in langfuse.api.trace.list(name="qa-handson", limit=3).data:
langfuse.api.annotation_queues.create_queue_item(
queue_id=queue.id,
object_id=trace.id,
object_type="TRACE",
)
UI で Queue を開くと、Pending 状態の Item が並びます。
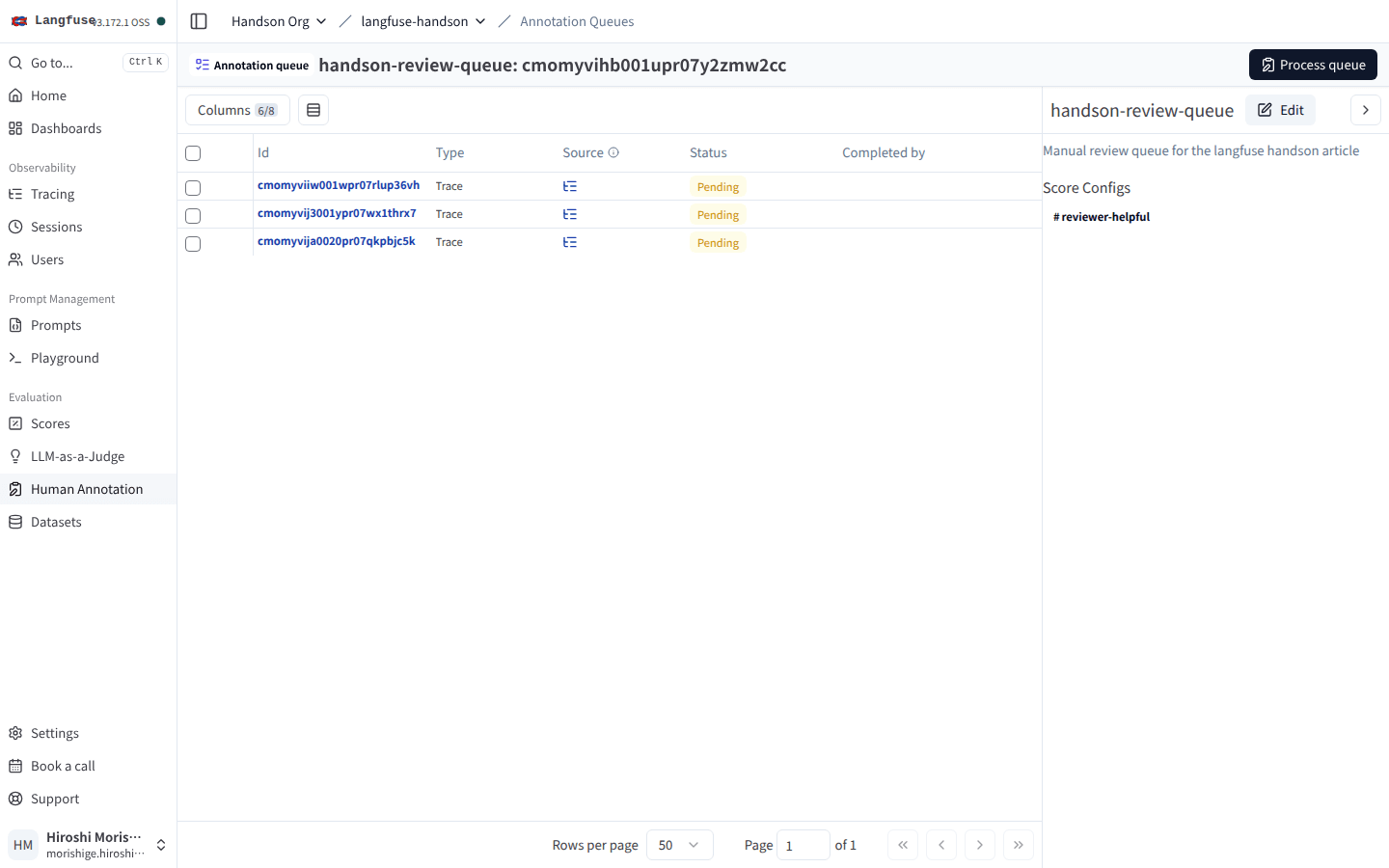
右パネルに紐付いた Score Configs(reviewer-helpful)が表示されていて、右上の Process queue から reviewer 専用の集中採点画面に切り替えられる。
右パネルの「Process queue」ボタンを押すと、reviewer 専用の集中画面に切り替わって、Item を 1 件ずつ表示しながら Score Config に従って採点していけます。複数人にキューを割り当てたり、レビュー済みの件数をダッシュボードで集計したりすることもできるので、「LLM judge と人の評価を 1 つの基盤で並べる」運用にすぐ持ち込めるのがありがたいですね。
「正解データを集めるバイト的な作業を、月次で 100〜1000 件回す」用途や、「LLM judge と人の評価を 1 つの基盤で並べたい」場面には、ちょうどフィットする機能ですね。
DGX Spark + vLLM のローカル LLM をトレースする
最後におまけ的な章として、DGX Spark のローカル vLLM に LangChain ChatOpenAI 経由で繋ぎ、Langfuse でトレースを取る流れも試しておきます。クラウド API 課金が発生しないモデルでも、token 数とレイテンシだけはきちんと観測したいという需要は多いはずです。
Nemotron 3 Nano 30B-A3B NVFP4 を vLLM で起動する
DGX Spark の Blackwell(GB10)はネイティブで NVFP4 を扱えるので、Nemotron 3 Nano 30B-A3B の NVFP4 量子化版をそのまま起動します。
#!/usr/bin/env bash
set -euo pipefail
VENV=/path/to/your/vllm/.venv
# Mamba/SSM kernels JIT-compile through ninja; the venv ships ninja but
# its bin/ is not on PATH by default, so subprocess lookup fails.
export PATH="$VENV/bin:$PATH"
export VLLM_CACHE_ROOT="$HOME/.cache/vllm-local"
exec "$VENV/bin/vllm" serve nvidia/NVIDIA-Nemotron-3-Nano-30B-A3B-NVFP4 \
--host 0.0.0.0 --port 8001 \
--served-model-name nemotron-3-nano-nvfp4-local \
--max-model-len 8192 --max-num-seqs 4 \
--gpu-memory-utilization 0.5 \
--enforce-eager \
--moe-backend flashinfer_cutlass \
--trust-remote-code
環境にもよるかもしれませんが、このスクリプトで一度詰まった点を残しておきます。Nemotron 3 系は Mamba と Transformer のハイブリッド構成で、SSM 層の triton kernel が起動時に JIT コンパイルされます。コンパイラとして ninja を呼ぶ際 subprocess の PATH を見るので、venv 内に ninja を入れているだけだと FileNotFoundError: [Errno 2] No such file or directory: 'ninja' で engine init が落ちます。PATH に venv の bin を足すだけで解消するので、起動スクリプトに上のコメントの 1 行を入れておくのがおすすめです。
カスタム単価 $0/$0 でローカル LLM を Langfuse 側に登録する
ローカルで動く LLM はクラウド料金が発生しないので、Models registry にカスタム単価 0 で登録しておきます。
from langfuse import Langfuse
lf = Langfuse()
lf.api.models.create(
model_name="nemotron-3-nano-nvfp4-local",
match_pattern=r"(?i)^nemotron-3-nano-nvfp4-local$",
unit="TOKENS",
input_price=0.0,
output_price=0.0,
)
これで「トークン数は記録するけれどコストは $0 で固定」という表現になります。Cloud と Self-host のモデルが混在するパイプラインで、料金カラムをそのまま比較できる形です。
LangChain ChatOpenAI 経由で Langfuse に流す
vLLM は OpenAI 互換 API を出すので、LangChain の ChatOpenAI で base_url を指すだけで繋がります。api_key は vLLM 側で検証していないので EMPTY で OK です。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langfuse import Langfuse
from langfuse.langchain import CallbackHandler
handler = CallbackHandler()
langfuse = Langfuse()
llm = ChatOpenAI(
model="nemotron-3-nano-nvfp4-local",
temperature=0,
max_tokens=256,
base_url="http://localhost:8001/v1",
api_key="EMPTY",
)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a concise assistant. Reply in 1-2 sentences."),
("human", "{question}"),
])
chain = prompt | llm | StrOutputParser()
for q in [
"What is the capital of Japan?",
"Who invented the World Wide Web?",
"In one sentence: why do neural networks need a non-linear activation?",
]:
answer = chain.invoke(
{"question": q},
config={
"callbacks": [handler],
"run_name": "vllm-local-qa",
"metadata": {"langfuse_user_id": "dgx-spark", "stack": "vllm-nvfp4"},
},
)
print(f"Q: {q}\nA: {answer}\n")
langfuse.flush()
UI を覗くと、ChatOpenAI ノードが Generation として記録され、トークン数と $0 のコストが並びます。
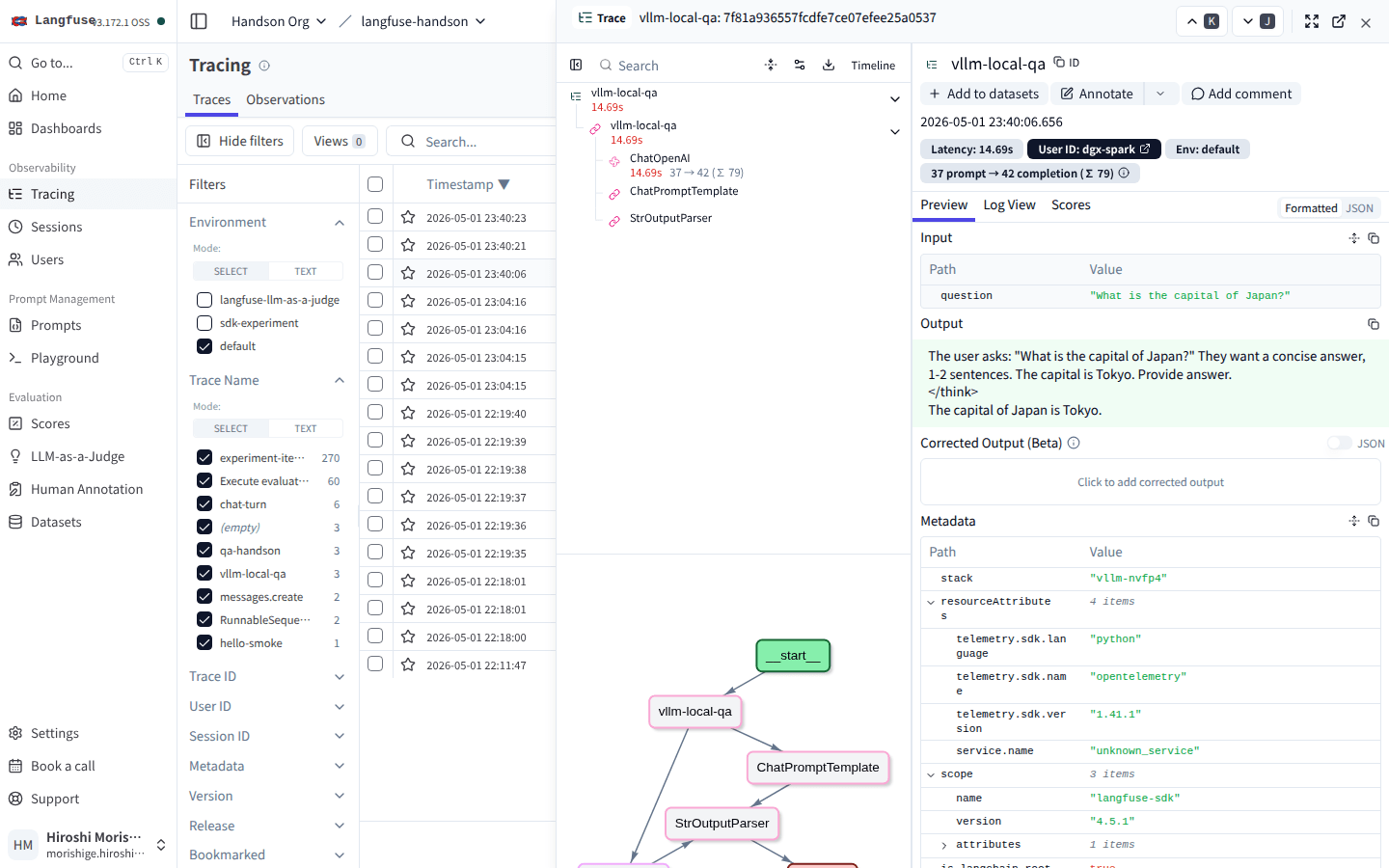
Output 欄に Nemotron 3 系の reasoning モードらしい <think>...</think> がそのまま残っている。Metadata に stack: vllm-nvfp4 と User ID dgx-spark を入れているのでフィルタしやすい。
応答に <think>...</think> が混ざっているのは、Nemotron 3 系がデフォルトで reasoning モード ON だからですね。短い応答が欲しい場合は extra_body={"chat_template_kwargs": {"enable_thinking": False}} のように OpenAI 互換の追加引数で抑制できます。
ここで API 側のレスポンスを直接覗くと、コスト計算がきちんと「ローカル LLM = ゼロ」で固定されているのが確認できました。
$ curl -u "$PUBLIC_KEY:$SECRET_KEY" \
'http://localhost:3000/api/public/observations?type=GENERATION&limit=1' \
| jq '.data[0] | {model, usageDetails, costDetails}'
{
"model": "nemotron-3-nano-nvfp4-local",
"usageDetails": {"input": 44, "output": 78, "total": 122},
"costDetails": {"input": 0, "output": 0, "total": 0}
}
「クラウド API のコストはきっちり追跡したいけど、オンプレで自前ホストする LLM は $0 で表現したい」という要件は、自分の周りでも増えてきているので、この組み合わせが綺麗にハマるのは地味に大事なポイントですね。
触れなかった機能と運用上の細かい注意点
本記事の本筋から外れるので深掘りできなかった機能と、ハンズオン中に踏んだ細かいハマりを最後に並べておきます。まずは触れなかった機能の方から。
| 機能 | 概要 |
|---|---|
| Playground | Prompt Management 上のプロンプトをそのまま LLM Connection で試せる |
| Public sharing | Trace 単位で公開リンクを払い出して外部レビュアーに渡せる |
| Batch Exports | 大量のトレースを S3 互換ストレージに定期書き出し(運用ログ向け) |
| SCIM / RBAC | エンタープライズ向けのユーザー管理(Org 単位) |
| Posthog / Slack 連携 | Integrations 経由でメトリクス送信や通知 |
Playground は Prompt Management で管理しているプロンプトをその場で実行できるので、UI 上だけで「プロンプト微調整 → 結果確認 → ラベル更新」が回せるのが面白いですね。Public sharing は trace に外部公開リンクを発行できる機能で、社外レビュアーに「この応答だけ見てもらう」用途で使えそうでした。
まとめ
Langfuse を DGX Spark に Self-host して、トレース収集からコスト追跡・データセット・LLM-as-a-Judge・プロンプト管理・人手アノテーションまでひととおり触ってみました。docker compose up から HTTP 200 まで 25 秒、LANGFUSE_INIT_* で初期ユーザ + Org + Project + API キーまで一括生成、ARM64 でも素直に動くので、「サンドボックスから運用までスムーズに移行できる OSS の LLM 可観測基盤」としての完成度はかなり高いなと感じました。
業務寄りの場面で特に効いてくるのは、Models registry の単価から USD を自動計算してくれるコスト追跡、コードに評価呼び出しを書かずに済む LLM-as-a-Judge の管理画面、そして人手レビューをキュー → 採点 → トラックという業務の流れに沿わせる Annotation Queue の 3 点です。「PoC で動かす」段階から「誰かが料金とレビュー業務を回す」段階に進むときに、これらが標準で乗っているのは大きな利点ですね。
試してみる順番としては、まず docker compose up で立ち上げて、LANGFUSE_INIT_* を埋めて自分の Project を一発で作ってしまうのが最短です。そこから LangChain の CallbackHandler で trace を流す → Models registry に単価を登録して USD を見える化 → Datasets と Dataset Run でプロンプトを比較 → LLM-as-a-Judge を Active 化 → Annotation Queue でレビューを回す、と少しづつ足していけば、自然に「継続的に育てる観測ワークフロー」が手元に揃います。
Cloud 版(langfuse.com)も同じ機能セットを使えるので、まず Self-host で試してから慣れてきたら Cloud に乗せ換える、あるいは逆に Cloud で始めて Self-host に持ち込む、どちらの順でも違和感が少ないのは安心材料ですね。
検証スクリプト一式は himorishige/dgx-spark-blog の langfuse-handson/ ディレクトリに置いてあります。手元で再現される際の雛形として、自由に持って行ってください。











