
Arize Phoenix で LLM アプリの観測と評価を試してみた
はじめに
こんにちは、クラスメソッド製造ビジネステクノロジー部の森茂です。
LLM アプリを育てていくと、そのうち「どのリクエストが遅かったのか」「どのプロンプトで精度が落ちたのか」「新しい judge モデルに差し替えたらスコアがどれくらい動くのか」といった観測と評価の仕事が増えてきますね。
そこで今回は Arize Phoenix を主役に据えて、トレース収集・セッション集約・データセット管理・実験比較・LLM-as-judge 評価・プロンプト管理・アノテーションまで、ひととおり手を動かしてみたノートをまとめておきます。検証は DGX Spark 上で行いましたが、記事内のコードは Mac でも Linux でも動く形で書いています。
Arize Phoenix とは何か
Arize Phoenix は、Arize AI 社がスポンサードしている OSS の LLM 可観測性プラットフォームです。サーバー本体と arize-phoenix-evals は Elastic License 2.0、OTel への送信ラッパーである arize-phoenix-otel のみ Apache 2.0 で配布されています。いずれもセルフホストで商用利用が可能な緩やかなライセンスで、Docker 1 行でサーバーが立ち上がり、評価ライブラリと LLM プレイグラウンドも一式が同梱されているのが特徴です。
他の LLM 可観測性ツールと位置づけを比べるとこうなります。
| 比較軸 | Arize Phoenix | Langfuse | LangSmith | MLflow Tracing |
|---|---|---|---|---|
| ライセンス | OSS(EL 2.0) | OSS(MIT) | 商用 SaaS | OSS(Apache) |
| Prompt Playground | 同梱 | 同梱 | 同梱 | なし |
| LLM-as-judge Evals | 同梱 | 同梱 | 同梱 | 外部連携 |
| OTel / OpenInference 準拠 | ネイティブ | 独自 SDK 寄り | 独自 | 部分対応 |
| セルフホスト構成 | Docker 1 本 | Redis + Clickhouse | 限定的 | 単体可 |
OSS + 全機能同梱という点では Langfuse も同じで、どちらを選ぶかは細かい好みの世界に入ってきます。個人的には「OTel / OpenInference ネイティブ」と「Docker 1 本で立ち上がる」の 2 点が決め手で、手元のサンドボックスでは Phoenix に寄せています。Langfuse は SDK が独自寄りの分、LangChain 以外のフレームワーク越しにトレースを取るとき少し手間がかかる印象です。
3 分で動かす Phoenix
Phoenix の起動には大きく 3 つの選択肢があります。
| 選択肢 | ユースケース | 永続化 |
|---|---|---|
px.launch_app() |
Jupyter で手早く試したい | プロセス限り |
| Docker 1 行 | 手元でサクッと立てて開発に使いたい | SQLite(内蔵) |
| Docker Compose | チーム共有、認証やバックアップが必要 | PostgreSQL |
最小構成(Docker 1 行)
docker run -d --name phoenix \
-p 6006:6006 -p 4317:4317 \
arizephoenix/phoenix:14.9.1
ポート 6006 は Web UI と OTLP HTTP(/v1/traces)、4317 は OTLP gRPC 用です。ブラウザで http://localhost:6006 を開けば、もう空のプロジェクト一覧が見えています。
arizephoenix/phoenix:latest は multi-arch イメージとして amd64 と arm64 の両方をサポートしているので、手元の Mac(Apple Silicon)でも Linux サーバーでもそのまま動きます。docker manifest inspect で linux/arm64 の manifest が同梱されているのも確認できます。
PostgreSQL 永続化(Docker Compose)
services:
phoenix:
image: arizephoenix/phoenix:14.9.1
depends_on:
postgres:
condition: service_healthy
ports:
- '6006:6006'
- '4317:4317'
environment:
PHOENIX_SQL_DATABASE_URL: postgresql+psycopg://phoenix:phoenix@postgres:5432/phoenix
PHOENIX_WORKING_DIR: /mnt/phoenix
volumes:
- phoenix-data:/mnt/phoenix
postgres:
image: postgres:17
environment:
POSTGRES_USER: phoenix
POSTGRES_PASSWORD: phoenix
POSTGRES_DB: phoenix
volumes:
- phoenix-pg:/var/lib/postgresql/data
healthcheck:
test: ['CMD-SHELL', 'pg_isready -U phoenix']
interval: 3s
volumes:
phoenix-data:
phoenix-pg:
v14 系では読み取りレプリカ用の PHOENIX_SQL_DATABASE_READ_REPLICA_URL も追加されているので、本番運用の読み出し負荷分散まで視野に入れられます。小規模で試す段階では SQLite で十分ですが、span の保存期間を長めにしたい場合やチームで共有したい場合は PostgreSQL 版を選んでおくと後で楽です。
クライアント側の環境
本記事の検証コードは uv で環境を作りました。Python 3.12 以降なら同じ手順で動くはずです。
cd ~/works/phoenix-handson
uv venv --python 3.12
uv pip install \
"arize-phoenix>=14.9.1" \
"arize-phoenix-otel" \
"arize-phoenix-evals" \
"arize-phoenix-client" \
"openinference-instrumentation-langchain" \
"openinference-instrumentation-openai" \
"openinference-instrumentation-anthropic" \
"langchain" "langchain-openai" "langchain-anthropic" \
"openai" "anthropic" "pandas" "datasets"
arize-phoenix が Web UI と REST API の本体、arize-phoenix-otel は register() 関数のラッパー、arize-phoenix-evals は純正 LLM-as-judge、arize-phoenix-client は Python から Datasets・Experiments・Annotations を叩くクライアントです。細かくパッケージが分かれているのは、v14 で「サーバーと軽量クライアントを分離する」リファクタが入ったためですね。
起動して http://localhost:6006 を開くと Projects 画面が出てきます。本記事で作っていくプロジェクトは、ここにどんどん追加されていくので、後から「どのスクリプトがどの trace を生んだか」を辿る起点になります。
OpenInference で LLM アプリからトレースを取る
Phoenix の特徴は、独自 SDK に縛らずに OpenInference という OTel 向けの semantic convention をベースに、フレームワークからトレースを取る点です。LangChain / LlamaIndex / OpenAI SDK / Anthropic SDK / CrewAI / DSPy / Bedrock / Vertex AI など、主要な LLM フレームワークに対する openinference-instrumentation-* パッケージが用意されており、register() を呼ぶだけで auto-instrument が走ります。
一例として、LangChain の QA チェーンにトレースを仕込むコードがこちらです。
import os
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from phoenix.otel import register
tracer_provider = register(
project_name=os.environ.get("PHOENIX_PROJECT_NAME", "phoenix-handson-ch4"),
endpoint="http://localhost:6006/v1/traces",
auto_instrument=True,
)
# 環境変数で OpenAI / Anthropic / OpenAI 互換エンドポイントを切り替え
def build_llm():
if os.environ.get("OPENAI_API_KEY") or os.environ.get("OPENAI_BASE_URL"):
from langchain_openai import ChatOpenAI
return ChatOpenAI(
model=os.environ.get("OPENAI_MODEL", "gpt-4o-mini"),
temperature=0,
base_url=os.environ.get("OPENAI_BASE_URL"),
)
from langchain_anthropic import ChatAnthropic
return ChatAnthropic(model="claude-haiku-4-5", temperature=0)
prompt = ChatPromptTemplate.from_messages([
("system", "You are a concise assistant. Reply in a single sentence."),
("human", "{question}"),
])
chain = prompt | build_llm() | StrOutputParser()
for q in [
"What is the capital of Japan?",
"Who wrote 'Pride and Prejudice'?",
"Briefly: why is the sky blue?",
]:
print(chain.invoke({"question": q}))
ポイントは register(auto_instrument=True) の 1 行で、インストール済みの OpenInference 系パッケージをすべて検出してフックに差し込んでくれる点です。自分の環境だと openinference-instrumentation-langchain と openinference-instrumentation-anthropic が入っていたので、LangChain の Runnable 階層と Anthropic SDK の messages.create 呼び出しが両方スパンになって Phoenix に送られてきます。
環境変数でプロバイダーを差し替えられる作りにしているので、OpenAI API に API Key があればそちら、なければ Anthropic にフォールバック、OPENAI_BASE_URL を指定すればローカルの vLLM や Ollama も使えます。「手元のエンドポイントで試したい」という要件にそのまま乗せられるのはありがたいところです。
対応している主な Python 向けトレース取得パッケージをまとめるとこうなります。
| 分類 | パッケージ名 |
|---|---|
| LLM SDK | openinference-instrumentation-openai |
openinference-instrumentation-anthropic |
|
openinference-instrumentation-google-genai |
|
openinference-instrumentation-mistralai |
|
openinference-instrumentation-litellm |
|
| エージェント基盤 | openinference-instrumentation-langchain |
openinference-instrumentation-llama-index |
|
openinference-instrumentation-dspy |
|
openinference-instrumentation-crewai |
|
openinference-instrumentation-openai-agents |
|
| ツール・ガード | openinference-instrumentation-haystack |
openinference-instrumentation-guardrails |
|
openinference-instrumentation-mcp |
|
| クラウド | openinference-instrumentation-bedrock |
openinference-instrumentation-vertexai |
TypeScript 側も 2026-04 に @arizeai/phoenix-otel の 1.0 がリリースされていて、Vercel AI SDK や LangChain.js のトレース取得が同じノリで書けます。Python でバックエンドを書きつつ、Next.js のフロントから直接 OTLP を飛ばしたいケースでも揃えやすくなっていますね。
スクリプトを実行した直後に Phoenix の Spans タブを開くと、3 つの質問分のスパンが 15 件流れ込んでいるのが見えます。
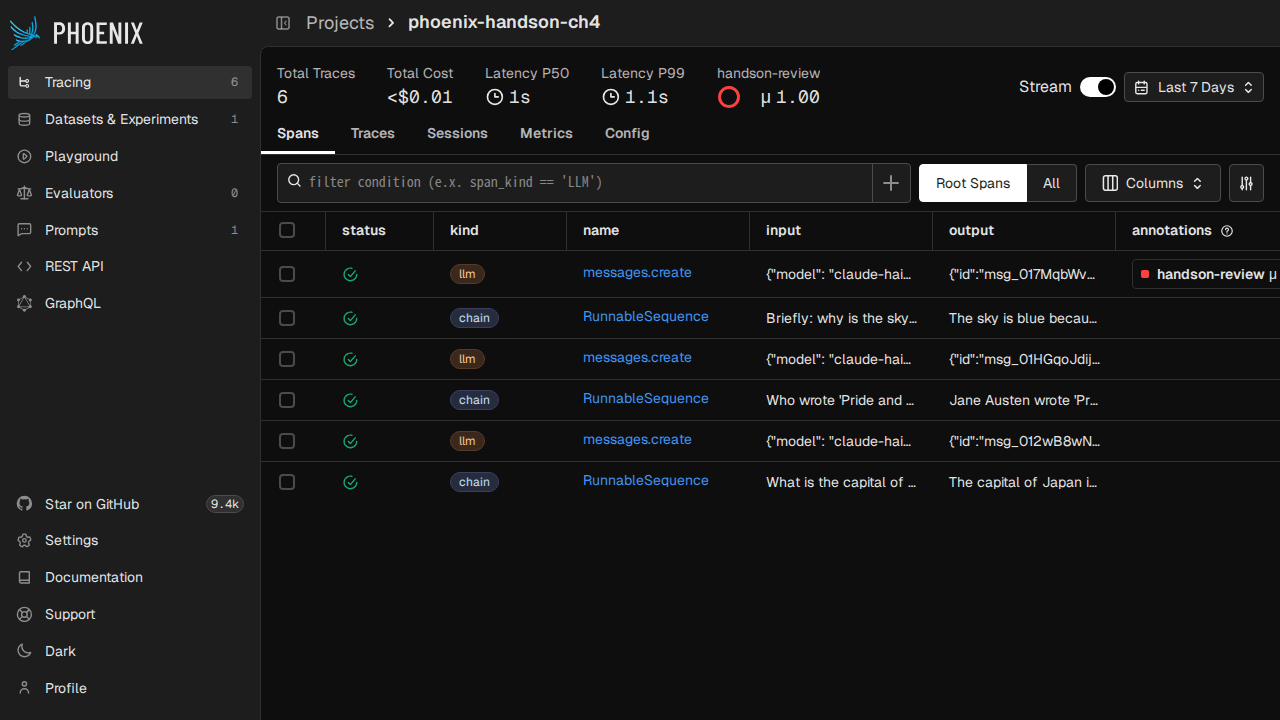
Tracing のスパンを読み解く
この 15 件のスパンは、3 つの質問 × 5 スパンずつの内訳で並んでいます。
| スパン名 | span_kind | 役割 |
|---|---|---|
RunnableSequence |
CHAIN | LangChain の LCEL パイプライン全体 |
ChatPromptTemplate |
PROMPT | プロンプトのレンダリング |
ChatAnthropic |
LLM | LangChain 抽象層から見た LLM 呼び出し |
messages.create |
LLM | Anthropic SDK の生レベル API |
StrOutputParser |
UNKNOWN | 出力パーサー(OpenInference に分類定義なし) |
CHAIN → PROMPT + LLM + UNKNOWN という入れ子で、親子関係は Phoenix の UI で waterfall 表示されます。各スパンには input.value / output.value / llm.token_count.prompt / llm.token_count.completion / llm.model_name などの attribute が自動で付与されるので、「どの質問でトークン数が跳ねたのか」「どこで時間を食ったのか」が一目で分かります。
トレースを開くと左ペインにスパンツリー、中央に Input / Output、右に Annotation エディタが出て、まさに「どこでどんな文字が通ったか」をそのまま追える作りになっています。
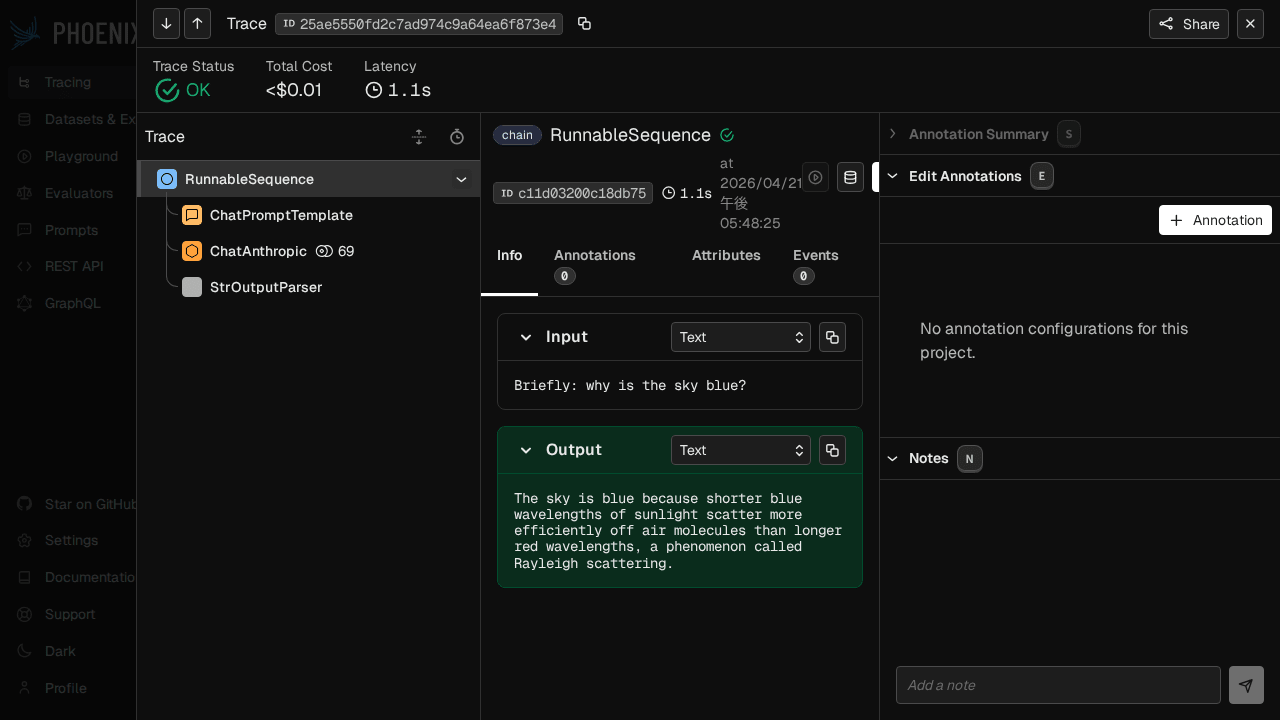
気になる点として、ChatAnthropic と messages.create が同じリクエストを表現する 2 段重ねの LLM スパンになるのは、LangChain 側と Anthropic SDK 側の OpenInference フックが両方有効になっているためです。どちらか片方に絞りたい場合は、register(auto_instrument=False) にして、使いたい Instrumentor だけを LangChainInstrumentor().instrument() のように明示的に有効化する方法があります。
StrOutputParser が UNKNOWN になっているのは、OpenInference の semantic convention に「出力パーサー」カテゴリが定義されていないため、LangChain 側が fallback として UNKNOWN を付けているからです。挙動としては正しいのですが、UI で眺めると少し気になるので、span_kind だけを頼りに集計するような運用は避けたほうが楽ですね。
Python からスパンをまとめて取得したいときは phoenix-client 経由で DataFrame を引けます。
from phoenix.client import Client
c = Client(base_url="http://localhost:6006")
df = c.spans.get_spans_dataframe(project_identifier="phoenix-handson-ch4")
print(df[["name", "span_kind", "status_code"]].head())
CSV エクスポートや pandas での集計が絡む場面では、UI を見るより API を叩くほうが速いです。
Sessions でマルチターン会話を束ねる
単発の Q&A ではなくチャットアプリを組むと「この会話はトータルで何秒かかったのか」「どのターンで脱線したのか」を見たくなります。Phoenix の Sessions 機能を使うと、関連するトレースを session.id というキーで束ねて表示できます。
openinference-instrumentation パッケージの using_session() コンテキストマネージャを使うと、その中で出る最上位スパンに attributes.session.id が自動で付きます。子スパンは親子関係から UI 側で辿ってくれるので、付与は最上位のみで OK です。
import os, uuid
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_anthropic import ChatAnthropic
from openinference.instrumentation import using_session
from phoenix.otel import register
register(project_name="phoenix-handson-ch6",
endpoint="http://localhost:6006/v1/traces",
auto_instrument=True)
def run_session(session_id: str, turns: list[str]) -> None:
llm = ChatAnthropic(model="claude-haiku-4-5", temperature=0)
history = [SystemMessage(content="You are a concise assistant. Keep every reply under 30 words.")]
with using_session(session_id):
for user_text in turns:
history.append(HumanMessage(content=user_text))
result = llm.invoke(history)
history.append(result)
run_session(f"handson-{uuid.uuid4()}", [
"Tell me three famous sights in Kyoto.",
"Which one is closest to Kyoto Station?",
"How long does it take on foot?",
])
これを 2 セッション分実行してから Phoenix の Sessions タブを開くと、session id ごとに最初の入力・最後の出力・開始終了時刻・annotation がまとめて表示されます。セッションクリックで各ターンのトレースに飛べるので、デバッグのときに「どのターンでハルシネーションしたか」を追いやすくなります。
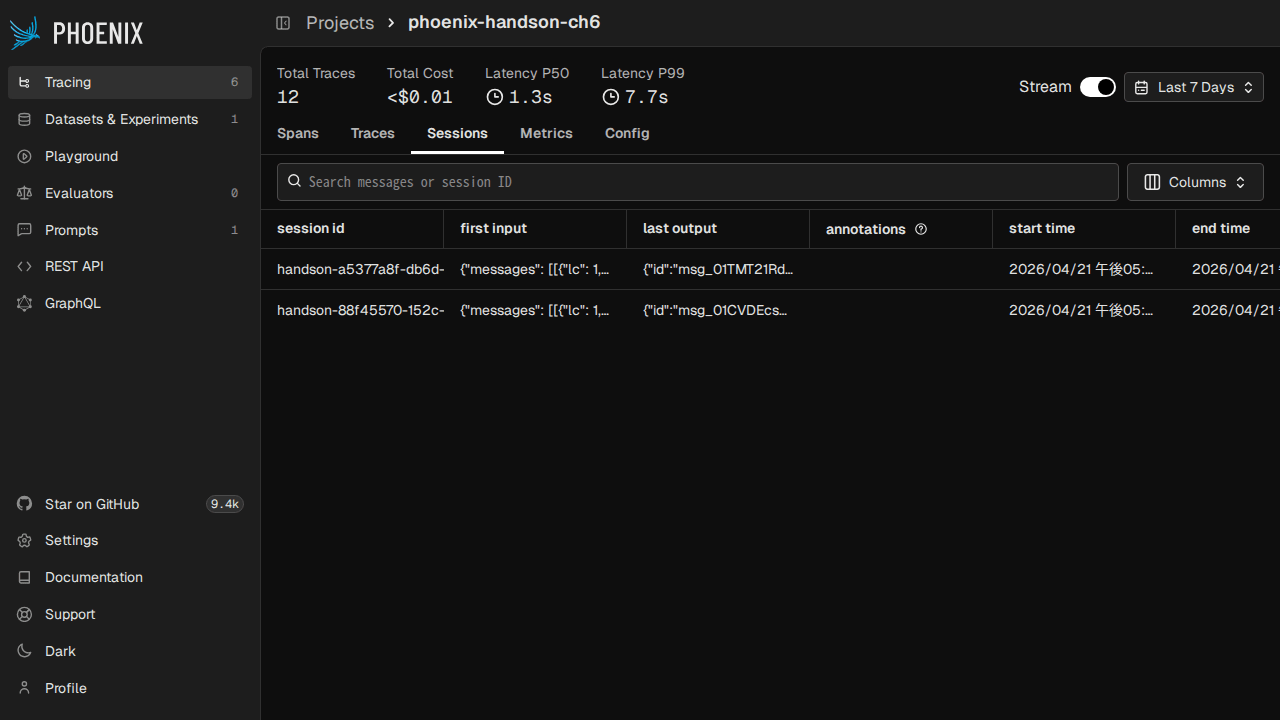
v14 系で増えた Sessions API を使うと、SDK から順序付きで会話を取り出せます。
from phoenix.client import Client
c = Client(base_url="http://localhost:6006")
turns = c.sessions.get_session_turns(session_id="<session-id>")
Sessions の挙動でよくハマるのは、using_session() を使わずに直接 span に attribute を書こうとするパターンです。tracer.start_as_current_span(...) の中で span.set_attribute("session.id", "xxx") と書いても UI には反映されますが、子 span への伝搬は自動ではないので、LangChain などのフレームワーク越しに使うときは using_session() 側のほうが素直です。
Datasets で回帰テスト用データを整える
「プロンプトを差し替えたら以前と比べてスコアがどう動いたか」を見るには、固定のデータセットを用意しておくのが王道です。Phoenix は phoenix.client.Client.datasets.create_dataset に pandas DataFrame を渡すだけでデータセットが立ち上がります。
import pandas as pd
from phoenix.client import Client
QA = [
("What is the capital of France?", "Paris"),
("Who painted the Mona Lisa?", "Leonardo da Vinci"),
# ... 一般知識 QA 30 件
]
df = pd.DataFrame(QA, columns=["question", "answer"])
df["id"] = [f"qa-{i:03d}" for i in range(len(df))]
client = Client(base_url="http://localhost:6006")
ds = client.datasets.create_dataset(
name="handson-general-qa",
dataframe=df,
input_keys=["question"],
output_keys=["answer"],
metadata_keys=["id"],
)
print(f"dataset id={ds.id} rows={len(df)}")
実行すると dataset id と version_id が払い出され、UI の Datasets タブに 30 行が見えます。input_keys / output_keys / metadata_keys の振り分けは、あとで Experiments を書くときに example["input"]["question"] のようにアクセスする名前になるので、ここで決めた名前は少し先まで効いてきます。
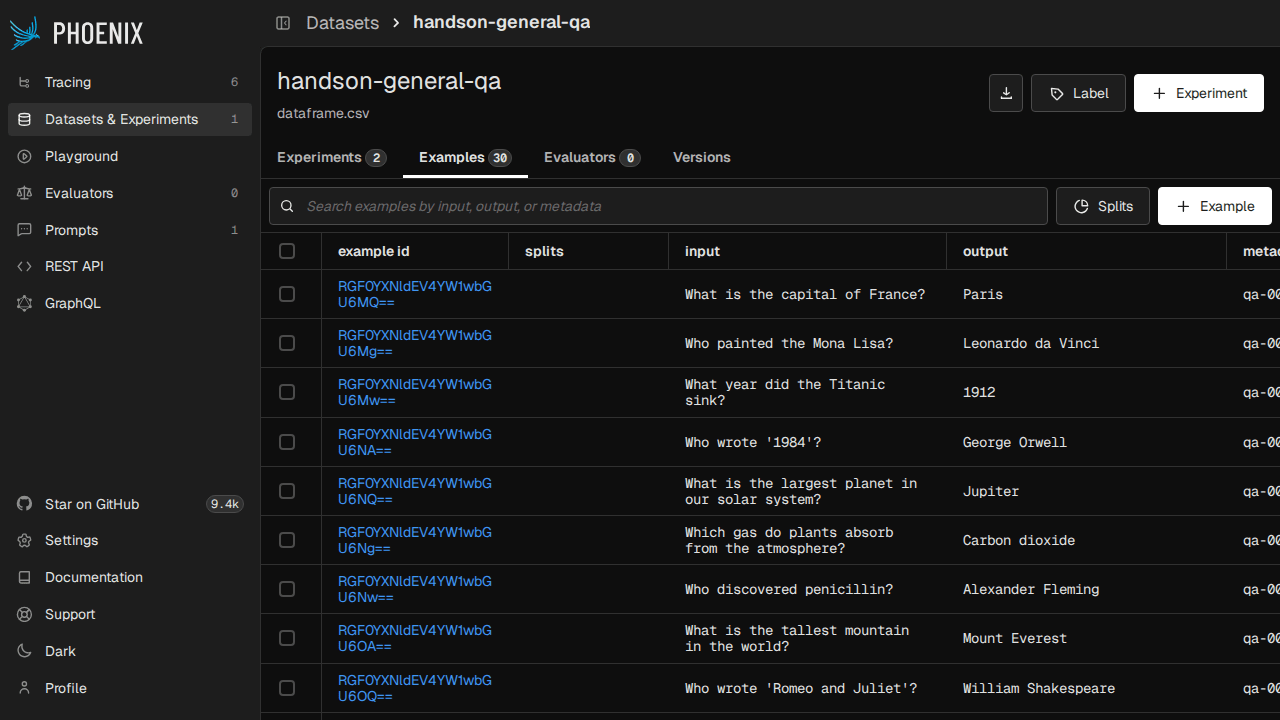
v14 では Splits という概念が追加されていて、同じデータセットを train / test のように分けて管理できます。たとえば 30 件のうち 20 件を train、10 件を test にして、train で prompt を仕上げてから test で最終評価、という流れが Phoenix 内で完結します。
データセット作成のルートは DataFrame の他に CSV アップロード(UI)、JSONL の直接 PUT(REST)、HuggingFace Datasets からの取り込みなども用意されています。個人的には Python から作ってそのまま ds.id を次のステップに渡すのが一番楽でした。
Experiments でプロンプトと judge を比較する
Datasets が揃ったら、同じ入力に対して複数の実装をぶつけて比較するのが Experiments の仕事です。run_experiment に「タスク関数」と「評価関数(evaluator)」を渡すと、各 example に対してタスクを実行 → evaluator で採点 → DB に記録 → 比較 UI に並ぶ、というところまでやってくれます。
今回は「1 語だけで答えろ」プロンプト A と「最大 3 語で答えろ」プロンプト B を、同じ 30 件 QA に対して走らせてみました。評価には (1) 期待値が出力に含まれているかの contains_match(コード評価)と (2) LLM-as-judge で yes/no を判定させる llm_correctness(Claude Haiku 4.5 を judge に使う)を並べます。
from anthropic import Anthropic
from phoenix.client import Client
anthropic = Anthropic()
client = Client(base_url="http://localhost:6006")
dataset = client.datasets.get_dataset(dataset="handson-general-qa")
def _ask(system: str, question: str) -> str:
resp = anthropic.messages.create(
model="claude-haiku-4-5", max_tokens=128, system=system,
messages=[{"role": "user", "content": question}],
)
return resp.content[0].text.strip()
def task_one_word(example):
return _ask("Answer in exactly one word.", example["input"]["question"])
def task_short_phrase(example):
return _ask("Provide a short factual answer in at most 3 words.", example["input"]["question"])
def contains_match(output, expected):
return float(expected.get("answer", "").lower() in str(output).lower())
def llm_correctness(input, output, expected):
prompt = (
f"Question: {input['question']}\n"
f"Expected answer: {expected['answer']}\n"
f"Model answer: {output}\n\n"
"Is the model answer semantically correct? Reply 'yes' or 'no'."
)
resp = anthropic.messages.create(
model="claude-haiku-4-5", max_tokens=5,
messages=[{"role": "user", "content": prompt}],
)
return 1.0 if resp.content[0].text.strip().lower().startswith("yes") else 0.0
client.experiments.run_experiment(
dataset=dataset, task=task_one_word,
evaluators=[contains_match, llm_correctness],
experiment_name="prompt-A-one-word",
)
client.experiments.run_experiment(
dataset=dataset, task=task_short_phrase,
evaluators=[contains_match, llm_correctness],
experiment_name="prompt-B-short-phrase",
)
手元の実行では running tasks のプログレスバーが出て、30 件のタスクが約 30 秒、30 件 × 2 evaluator = 60 件の評価が約 27 秒で流れます。プロンプト A / B それぞれで 120 件の評価が Phoenix に記録され、Experiments タブを開くと実験名で並び、スコアの平均・中央値・分布が比較できます。
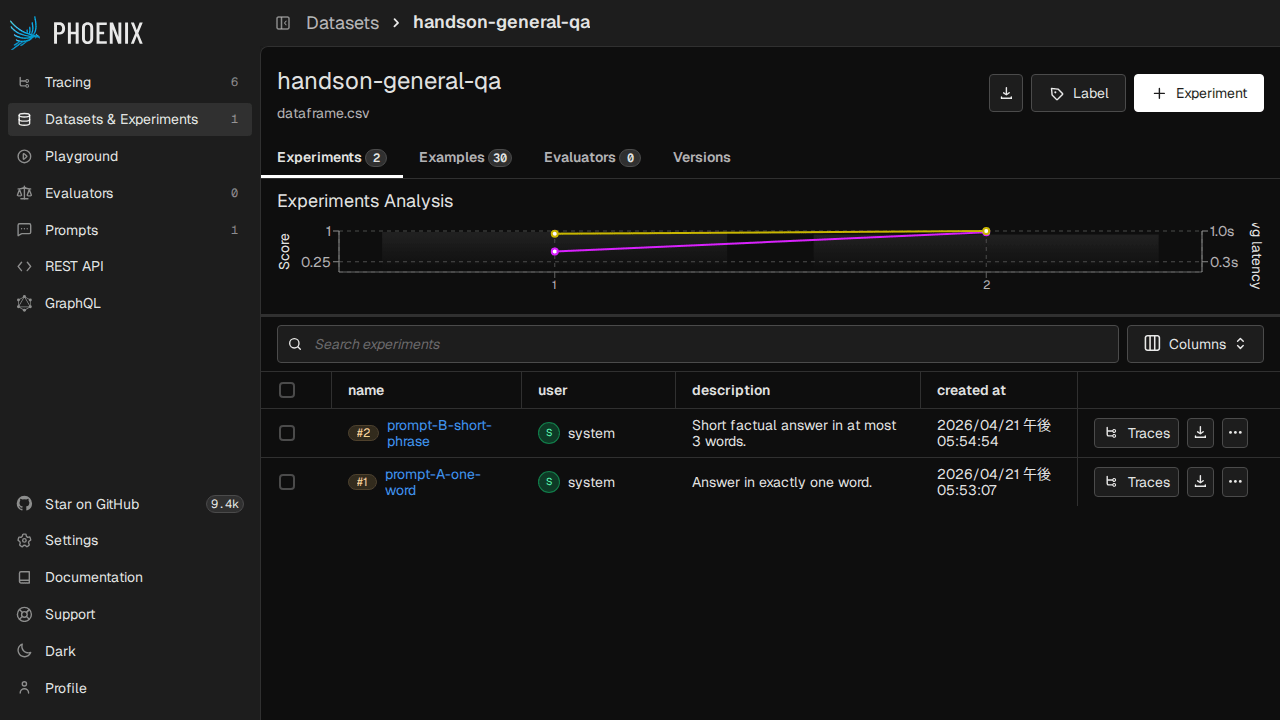
同じ Dataset に紐付いた Experiments は、そのままダブルクリックで「example 単位のサイドバイサイド差分」ビューに入れるので、「この質問だけプロンプト A で落ちているな」が見つけやすいです。
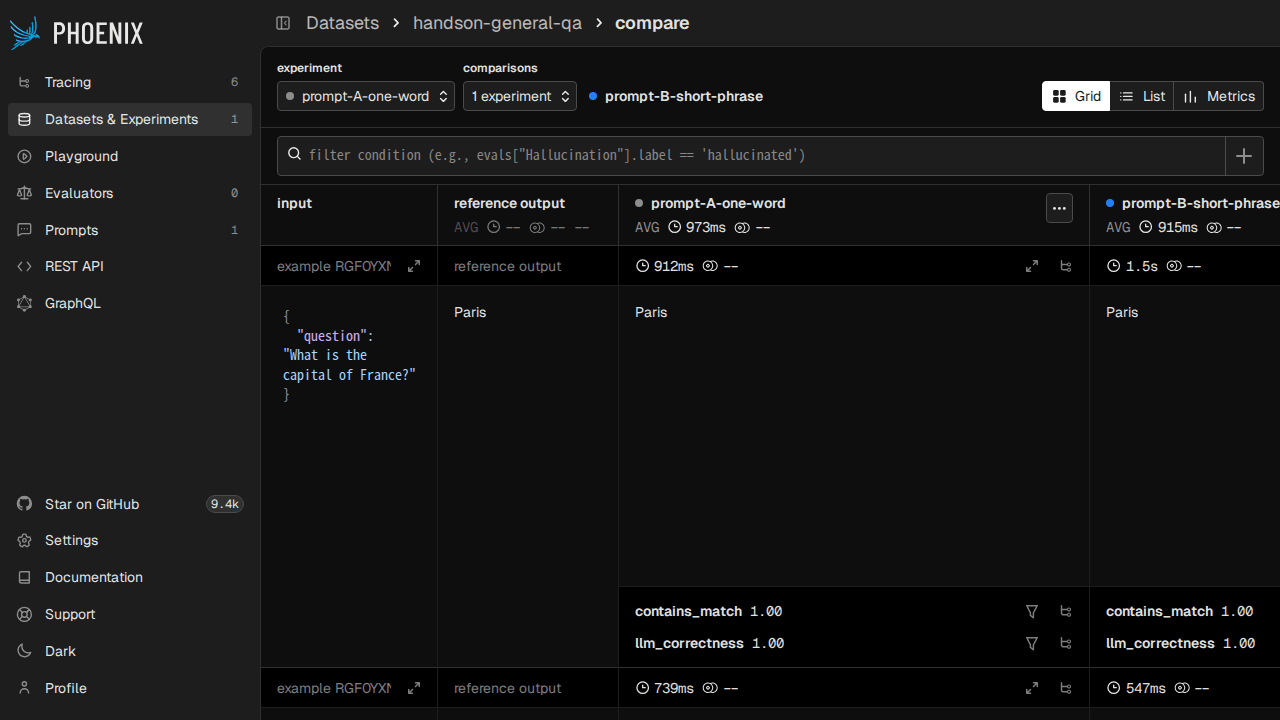
タスク関数のシグネチャは柔軟で、example だけを受け取る形のほか、input / expected / metadata などのキーで分解受け取りもできます。evaluator も関数の引数名で紐付くので、同じ evaluator を Experiments・Evals 両方で使い回すのが楽です。戻り値は dict / bool / float / str / (float, str) タプル / EvaluationResult のどれでも OK なので、スクリプト的に書き捨てるノリで済みます。
LLM-as-judge を phoenix-evals で動かす
Experiments の中でも evaluator は書けますが、「出力だけ pandas に取ってきて後から評価したい」という日もあります。そんなときは arize-phoenix-evals パッケージが独立して使えるので、Jupyter などから気軽に呼べます。v3 系のモダン API では、LLM プロバイダーを LLM(provider=..., model=...) で指定し、CorrectnessEvaluator や ConcisenessEvaluator のような metric クラスに注入する形に変わりました。
import pandas as pd
from anthropic import Anthropic
from phoenix.evals import LLM, evaluate_dataframe
from phoenix.evals.metrics import ConcisenessEvaluator, CorrectnessEvaluator
QA = [
("What is the capital of France?", "Paris"),
("Who painted the Mona Lisa?", "Leonardo da Vinci"),
# ... 10 件
]
anthropic = Anthropic()
def answer(q: str) -> str:
r = anthropic.messages.create(model="claude-haiku-4-5", max_tokens=128,
messages=[{"role": "user", "content": q}])
return r.content[0].text.strip()
rows = [{"input": q, "output": answer(q), "expected": ex} for q, ex in QA]
df = pd.DataFrame(rows)
judge = LLM(provider="anthropic", model="claude-haiku-4-5")
scored = evaluate_dataframe(df, evaluators=[
CorrectnessEvaluator(llm=judge),
ConcisenessEvaluator(llm=judge),
])
print(scored[["correctness_score", "conciseness_score"]].describe())
手元で 10 QA × 2 evaluator を走らせると、CorrectnessEvaluator は 10 件すべて correct(score=1.0)、ConcisenessEvaluator は 1 件だけ concise で 9 件が verbose という結果になりました。Claude Haiku 4.5 は質問に対して「回答 + 補足 + 背景情報」を返してくる傾向があるので、「正しいけど冗長」という分布が素直に可視化された形です。
スコアはラベル(correct / concise など)と 0.0〜1.0 の score、そして LLM が書いた explanation がセットで返ってきます。explanation の日本語化や rubric のカスタマイズは create_classifier / create_evaluator で任意の prompt template を書けるので、「日本語の自社規約でアウトプットをチェックする」ような用途にもそのまま持っていけます。
Evals で用意されている代表的な metric は次のとおりです。arize-phoenix-evals 3.x 系では旧 API の QAEvaluator 等もレガシーとして残っていますが、新しく書くなら phoenix.evals.metrics のクラス API が無難ですね。
| 分類 | Evaluator |
|---|---|
| 回答品質 | CorrectnessEvaluator / FaithfulnessEvaluator(旧 HallucinationEvaluator の後継) |
| 文体・拒否 | ConcisenessEvaluator / RefusalEvaluator |
| RAG | DocumentRelevanceEvaluator |
| エージェント | ToolSelectionEvaluator / ToolInvocationEvaluator / ToolResponseHandlingEvaluator |
| コード評価 | MatchesRegex / PrecisionRecallFScore / exact_match |
Prompt Hub でプロンプトをバージョン管理する
プロンプトを git 管理する派も多いと思いますが、Phoenix には Prompt Hub が同梱されているので「実験に使ったプロンプトそのもの」を Phoenix 内で履歴管理できます。Python クライアントから PromptVersion を作って push するだけでバージョンが増えていきます。
from phoenix.client import Client
from phoenix.client.types import PromptVersion
c = Client(base_url="http://localhost:6006")
v1 = PromptVersion(
[
{"role": "system", "content": "You are a concise assistant. Reply in a single sentence."},
{"role": "user", "content": "{{question}}"},
],
model_name="claude-haiku-4-5",
model_provider="ANTHROPIC",
description="v1 baseline concise prompt",
template_format="MUSTACHE",
)
v2 = PromptVersion(
[
{"role": "system", "content": "You are a precise factual assistant. Answer with exactly one short sentence, no preamble."},
{"role": "user", "content": "{{question}}"},
],
model_name="claude-haiku-4-5",
model_provider="ANTHROPIC",
description="v2 stricter one-sentence prompt",
template_format="MUSTACHE",
)
pv1 = c.prompts.create(name="handson-concise-qa", version=v1)
pv2 = c.prompts.create(name="handson-concise-qa", version=v2)
c.prompts.tags.create(prompt_version_id=pv1.id, name="baseline")
c.prompts.tags.create(prompt_version_id=pv2.id, name="production")
latest = c.prompts.get(prompt_identifier="handson-concise-qa")
baseline = c.prompts.get(prompt_identifier="handson-concise-qa", tag="baseline")
model_provider は ANTHROPIC / OPENAI / AZURE_OPENAI / GOOGLE / AWS(Bedrock) / OLLAMA / GROQ / DEEPSEEK / XAI / TOGETHER など主要どころを網羅しています。template_format は MUSTACHE / F_STRING / NONE から選べて、上の例は {{question}} をプレースホルダとして使っています。
Phoenix UI の Prompts タブでは、バージョンごとの差分(v1 と v2 の system prompt の変更箇所)が色付きで表示され、production タグでピン留めされたバージョンが何かも一覧できます。
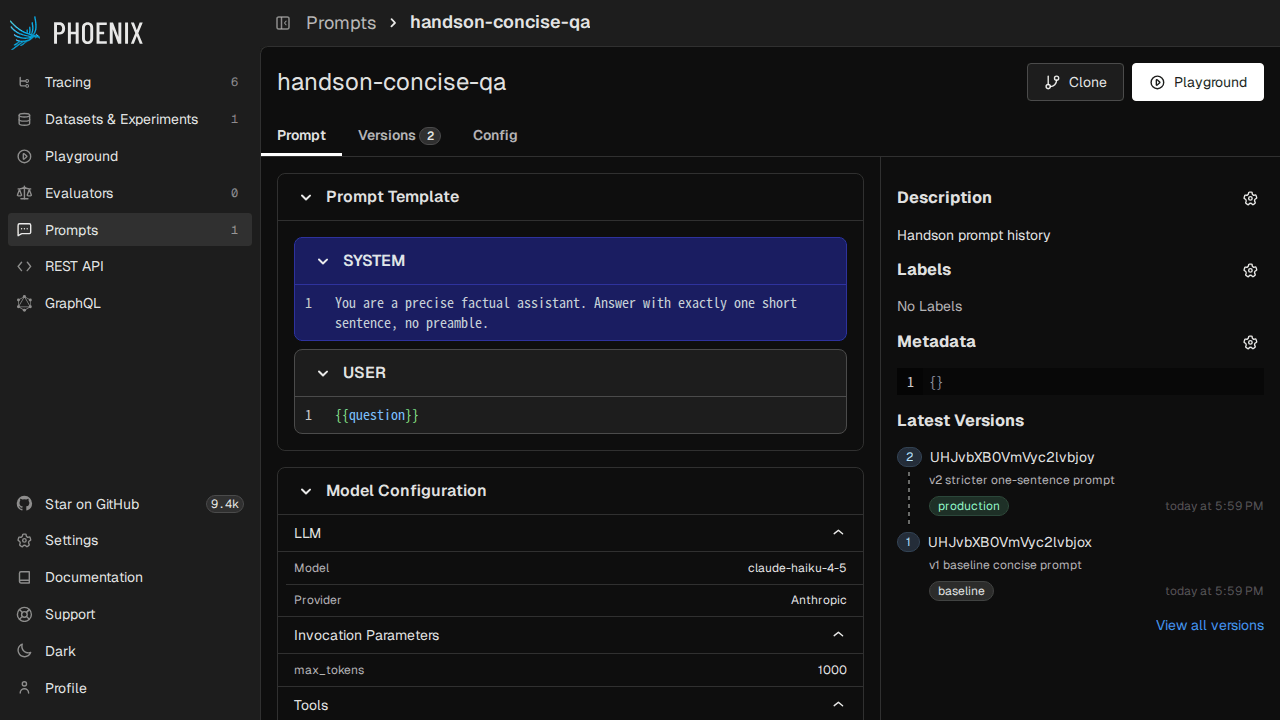
また Playground 画面ではプロンプトを直接編集して「その場で LLM に投げて結果を見る」動作確認ができます。Custom Providers として OpenAI 互換エンドポイントを登録すれば、手元の vLLM や Ollama に対しても Playground から叩けます。
履歴の確認は CLI からも px prompts(一覧)や px prompt <identifier>(参照)で参照できます。git とは別の履歴系として Phoenix Hub を使うなら、CI の中で phoenix-client から push する運用が自然かもしれません。
Annotations で自動スコアと人手レビューを揃える
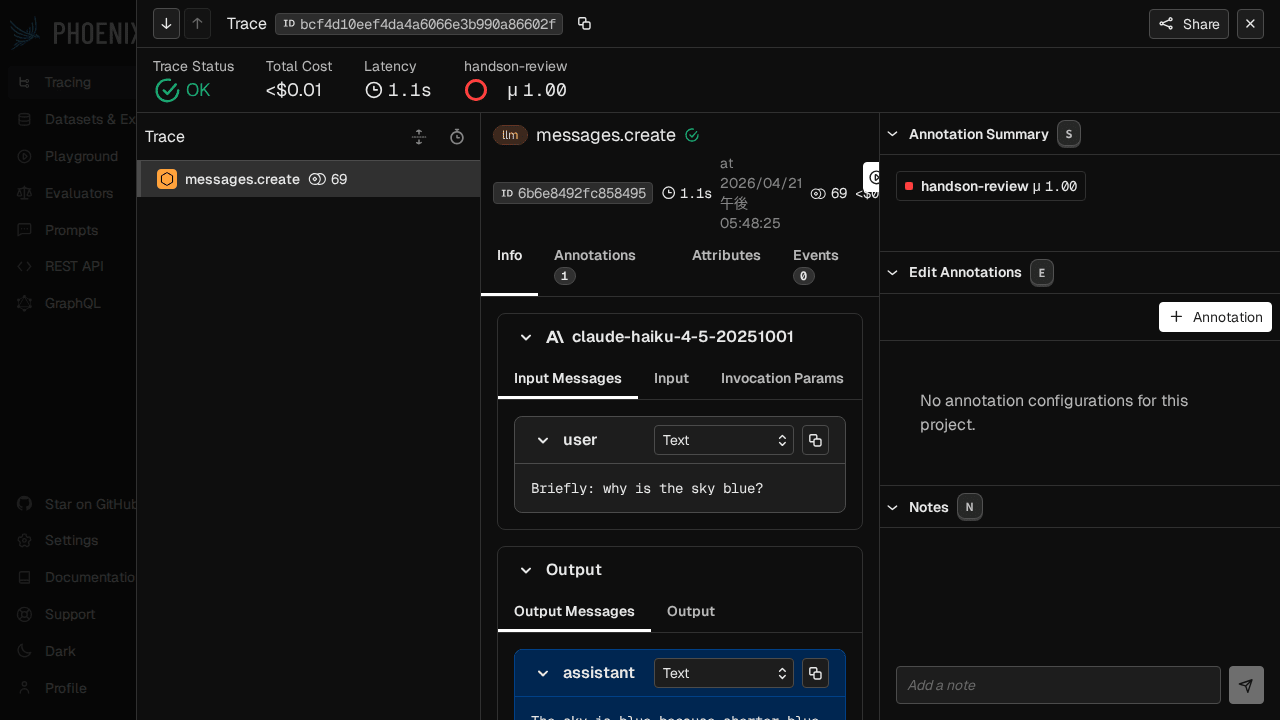
可観測性ツールを運用していると、「自動評価のスコアに加えて、レビュアーが付けた手動のラベルも同じ画面で見たい」という要望が出てきます。Phoenix はこれを Annotations という機構で統一していて、自動スコアも人手フィードバックも span_annotations テーブルに同じスキーマで乗ります。
既存 span に対して手動で annotation を付けるのは Python クライアントの 1 行です。
from phoenix.client import Client
c = Client(base_url="http://localhost:6006")
spans_df = c.spans.get_spans_dataframe(project_identifier="phoenix-handson-ch4")
llm_span_id = str(spans_df[spans_df["span_kind"] == "LLM"].index[0])
c.spans.add_span_annotation(
span_id=llm_span_id,
annotation_name="handson-review",
annotator_kind="HUMAN",
label="correct",
score=1.0,
explanation="Manually reviewed in handson session — looks good.",
sync=True,
)
annotator_kind は LLM / CODE / HUMAN の 3 択で、同じ span に複数の annotation を付けてもそれぞれ別に保存されます。UI の各 span 詳細ビューでは、annotation 一覧が展開表示され、誰が・いつ・どのラベルとスコアを付けたかが追えます。
v14 で REST エンドポイントが整理されて、旧 /v1/evaluations は廃止、以下の 3 つに分割されています。
| エンドポイント | 対象 |
|---|---|
POST /v1/span_annotations |
スパン単位の評価 |
POST /v1/trace_annotations |
トレース単位の評価 |
POST /v1/document_annotations |
RAG ドキュメント単位 |
evaluator から流した自動スコアと、手でフラグを立てた human レビューを同じ画面で串刺し検索できるので、「LLM judge が 0.9 と言っているけど人は NG を付けている span」のような食い違いを見つけやすくなります。バッチで流したい場合は c.spans.log_span_annotations_dataframe(df) で pandas DataFrame から一括登録できるので、評価パイプラインの出力をまとめて書き戻すのも簡単です。
触っていない機能と競合比較、そしてハマりどころ
Phoenix には他にもいくつか面白い機能があって、今回はさわりきれませんでした。気になったものを一覧にしておきます。
| 機能 | 概要 |
|---|---|
| Inferences | px.Dataset にエンベディングを入れて UMAP + HDBSCAN 可視化 |
| A2A Tracing | Agent-to-Agent プロトコル(Google / Anthropic 提案)のトレース |
| PostgreSQL read replica | v14.0 から、読み取り側を別 DB に逃がして負荷分散 |
| Shareable Project URL | /redirects/projects/<name> で名前ベースの共有 URL |
| LDAP / OAuth2 認証 | v12.20〜 のエンタープライズ向け認証統合 |
Inferences は歴史的には Phoenix の出発点だった機能(embedding ドリフト可視化)ですが、最近のドキュメントは Tracing 中心になっていて、公式のポジションとしては「レガシー寄り」で残っているようです。RAG の retriever チューニングで使いたいときは便利なので、用途が合えば触ってみる価値はあります。
競合との使い分けマップ
| シナリオ | 向いているツール |
|---|---|
| OSS で全機能をセルフホストしたい | Arize Phoenix |
| チーム全体でプロンプト管理を徹底したい(有料可) | Langfuse / LangSmith |
| LangChain 密結合で追加コストをかけたくない | LangSmith |
| ML / LLM を MLflow に統合したい | MLflow Tracing + Phoenix 併用 |
| クラウドで楽に始めたい | Phoenix Cloud / Langfuse Cloud |
Phoenix と Langfuse はどちらも魅力的で、自分の中では「単一コンテナで OTel ネイティブ、OpenInference 資産を活かしたい → Phoenix」「MIT で会社の規定に通しやすく、Redis / Clickhouse を含む重め構成にも抵抗がない → Langfuse」という棲み分けです。LangSmith は LangChain / LangGraph の一員として使うなら自然ですが、OSS ではないので選定判断が変わります。
v14 で踏んだ細かいハマり
最後に、ハンズオン中に引っかかった点をまとめておきます。記事を書いている時点(Phoenix 14.9.1 / phoenix-otel 0.15.0 / phoenix-evals 3.0.0)での挙動です。
- プロジェクト名が
defaultに集約される:register()でproject_nameを指定するか、PHOENIX_PROJECT_NAME環境変数で渡さないと、既存プロジェクトに混ざります。 - Annotation の書き込みは
/v1/span_annotationsに移動: v13 以前の/v1/evaluationsを叩いていると 404 になります。Python クライアント経由なら気にしなくて OK ですが、シェルで直接 POST していた人は移行が必要です。加えて、旧px.Client()は廃止され、phoenix-clientパッケージのClient(base_url=...)に移行しているので、v13 以前のコードをそのままにしていると import から通りません。 - LangChain + Anthropic で LLM スパンが二重に出る:
ChatAnthropic(LangChain 側のトレース)とmessages.create(Anthropic SDK 側のトレース)が両方スパンになります。整理したい場合はregister(auto_instrument=False)にして、必要な Instrumentor を明示的に呼びます。 StrOutputParserの span_kind がUNKNOWN: OpenInference の semantic convention に「出力パーサー」のカテゴリがないためで、表示上の都合です。フィルタリングでspan_kind=LLMに絞るときに取りこぼさないよう注意。- gRPC で大文字ヘッダーを送ると
H2Error: protocol_error: HTTP/2 の仕様でヘッダーキーは小文字固定なので、自前で OTLP を書くときは小文字でそろえます。PHOENIX_API_KEY経由にしておくと自動で正しい形で付きます。 - PostgreSQL に切り替えた初回起動で空テーブルになる:
PHOENIX_SQL_DATABASE_URLを設定した状態で初めて起動すると migration が自動実行されるはずなのに、タイミングによっては空 DB のまま UI が立つことがあります。その場合はコンテナをdocker restartするか、phoenix db migrateを明示的に叩くと復旧します。 - ARM64 Docker イメージは multi-arch だがタグによって混同する:
:latestは multi-arch ですが、arizephoenix/phoenix:14.9.1のようなバージョン固定タグでも問題なく ARM64 を掴みます。どうしても x86 を掴んでほしいときは--platform linux/amd64を明示します。 authlib.joseの Deprecation 警告: 14.9.1 時点でjoserfcへの移行が完了していないため警告が出ますが、挙動には影響ありません。気になる場合はwarnings.filterwarningsで抑制できます。
まとめ
Arize Phoenix をひととおり触ってみて、「観測・評価・プロンプト管理・人手レビューが 1 つの OSS に揃っている」ことの強さを改めて感じました。OpenInference で LangChain / OpenAI SDK / Anthropic SDK / LlamaIndex などフレームワーク越しにトレースを取れるので、既存の LLM アプリに差し込むのも数行で済みますし、評価系も arize-phoenix-evals 単体で完結しているので Jupyter でさっと回せます。
試してみる順番としては、まず Docker 1 行で立ち上げてローカルの LLM アプリを register() で繋いで span を眺めるのが最短です。そこから Datasets / Experiments / Prompts / Annotations を 1 つずつ足していけば、自然に「継続的に育てるワークフロー」が出来上がります。
Phoenix Cloud やエンタープライズ認証(LDAP / OAuth2)まで行くとさらに話が広がりますが、まずは手元で全機能を無料で触れるのが一番のセールスポイントかなと思っています。気になる方は、ぜひ今回の検証スクリプトを雛形にして自分のアプリに組み込んでみてください。











