
【セッションレポート】Anthropic が語る、長時間エージェントを本番で動かし続けるためのハーネス設計パターン #GoogleCloudNext
お疲れさまです。とーちです。
Google Cloud Next 2026 の Day 2 で、Anthropic のセッション「Long-running agents: Lessons from the enterprise frontier」を聴講してきました。数時間単位で動き続ける long-running agent (長時間エージェント) をエンタープライズ顧客と一緒に本番投入する中で、Anthropic が観測してきたモデルが陥りがちな挙動と、その外側を補う「ハーネス」の設計パターンを整理したセッションです。
Claude は Google Cloud の Gemini Enterprise Agent Platform 上でも利用可能で、本セッションはその文脈での発表でした。セッションで語られる設計パターンや実装例は、Claude Code ではなく Anthropic API(SDK)を使ってエージェントを構築する文脈での話です。
セッション概要
タイトル
Long-running agents: Lessons from the enterprise frontier
概要
AI agents that work for hours are already in production, and teams that are deploying them are pulling ahead. Design patterns for long-running agents are within reach today and will get more powerful as models advance. Anthropic will share lessons from enterprise teams building with Claude, available on Gemini Enterprise Agent Platform, including a framework for long-running agent design applied to 2 domains: codebase modernization and turning requirements into working applications. You'll experience agents in action and learn architectural patterns that make sustained autonomous work reliable.
※日本語訳:
数時間にわたり動き続ける AI エージェントはすでに本番投入されており、これを本格展開しているチームは先行している。long-running agent の設計パターンは今日の技術で実現可能であり、モデルの進化とともにより強力になっていく。Anthropic は、Gemini Enterprise Agent Platform 上でも利用可能な Claude を用いて、エンタープライズ顧客のチームと共に構築してきた知見を共有する。具体的には、コードベースの刷新 (codebase modernization) と、要件から動作するアプリケーションを生成する領域の 2 つに適用した long-running agent 設計のフレームワークを紹介する。実際に動くエージェントのデモと、持続的な自律作業を信頼性高く実現するアーキテクチャパターンを学ぶことができる。
スピーカー
- Harsh Patel 氏 (Anthropic, Member of Technical Staff)
long-running agent の機運と現実のギャップ
最初にモチベーションとして示されたのが、「モデルが単独で自律的にこなせるタスクの長さがおおよそ 6 ヶ月ごとに倍になっている」というグラフでした。数年前の Claude 3 Opus では 4 分程度だったものが、Claude Opus 4.6 では 12 時間程度まで伸びている、という話です。
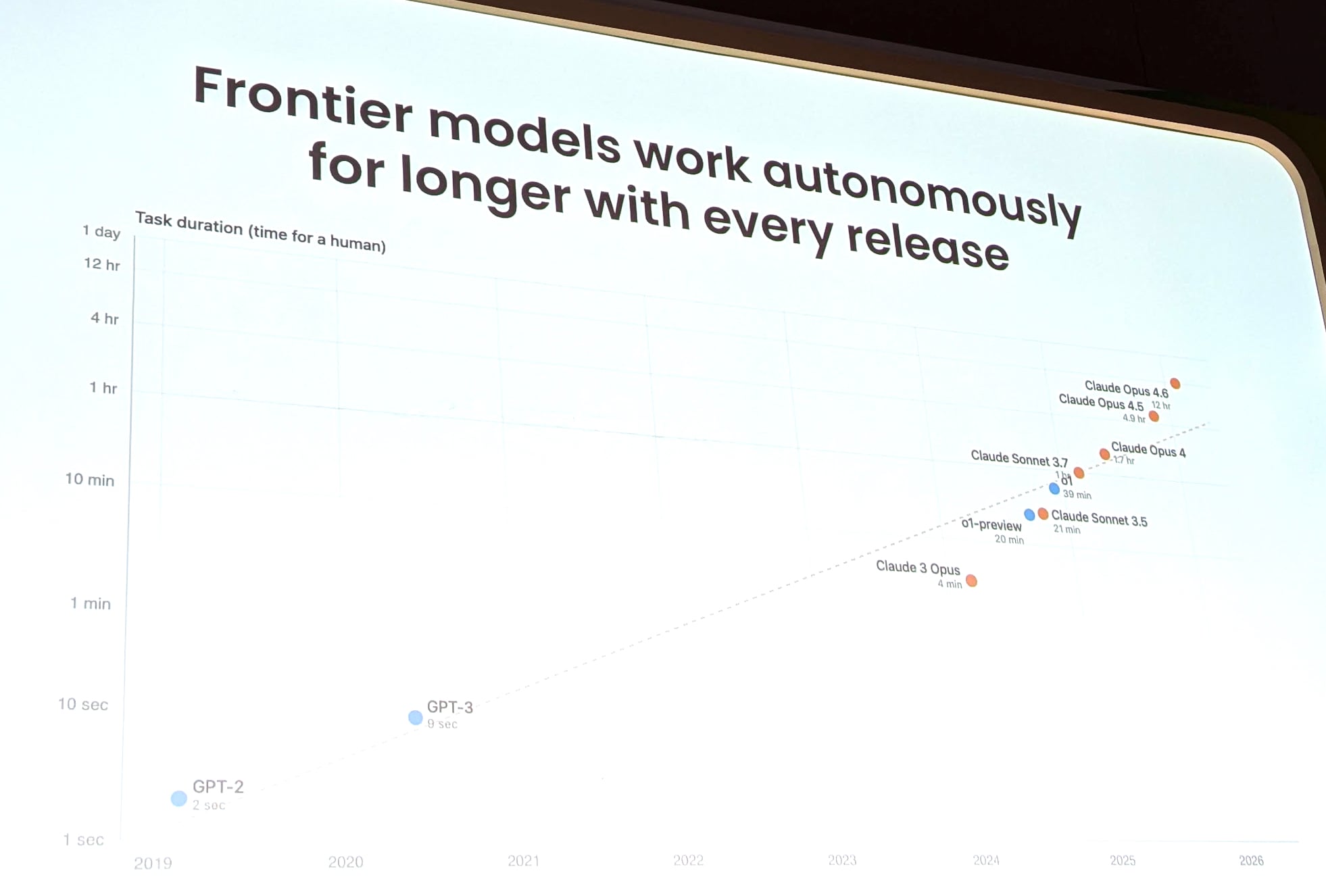
ただ、顧客から寄せられる声はそこまで良い話ばかりではないとのこと。
- Claude にプロンプトを投げてアプリを作らせる
- 15〜30 分は動いて、それなりのものができる
- しかしそこで止まってしまい、仕様の細部まで作り切れない
このギャップがなぜ起きるのか、そして実務でどう伸ばしていくのか、というのがセッションのテーマです。
モデルが長時間動かないときの 5 つのつまずきパターン
まず冒頭で、顧客やチーム内での実運用を通じて経験的に見えてきたモデルのつまずきパターンが整理されました。ここが重要なのは、机上で予測したものではなく、実際に動かして初めて分かったものだという点です。

context rot (コンテキストの劣化)
Transformer のアテンション機構(各トークンがコンテキスト内の全トークンとの関連度を計算して、どこに「注意」を向けるかを決める仕組み)に由来する問題で、コンテキストウィンドウに詰めるトークンが増えるほど、新しいトークンは過去のすべてのトークンに注意を向ける必要が出てきます。結果として、何十ターンもやり取りしたあと、序盤で指示した重要な仕様をピンポイントで思い出す精度が落ちていきます。
たとえ話として「1000 ページのマニュアルを渡した新人より、2〜3 ページの絞り込んだ資料を渡した新人のほうがきっちり仕事を終わらせる」という説明があり、この説明方法は顧客に説明するとにも使えそうだと思いました。
context anxiety (コンテキスト不安)
Sonnet 3.5 の頃に特に顕著だった挙動で、200K トークン上限が近づくとモデルが急に焦り出し、「終わっていないタスクを全部終わったことにする」ような振る舞いを見せるというもの。
チェックボックスは全部 OK になっているのに、実際にアプリを動かすと仕様どおりに動かない——この典型的なハマりパターンが、まさに context anxiety が起きているときの状態だそうです。
lossy compaction (要約による情報欠落)
コンテキストウィンドウがいっぱいになりそうなときに、これまでのやり取りを要約して圧縮するアプローチ (compaction) があります。ただ、要約すれば当然ながらタスクに関係する細部も落ちる可能性があります。さらに、Sonnet 3.5 では compaction でトークンを圧縮しても、context anxiety の焦り挙動が消えずに残るケースも観察されていたとのこと。
shallow plans (浅い計画)
「Claude.ai のクローンをワンショットで作って」のような大きな指示を投げると、Claude はテストやエラーハンドリングなど本番運用に必要な仕組みまで考慮した計画を立てずに、表面的な機能だけを実装し始めてしまう、というつまずきパターンです。
対策としては、モデルに丸投げせず、やるべきことを細かく分解して渡す必要があるという話でした。
self-leniency (自己評価の甘さ)
Claude に自分の仕事を評価させると、かなり寛容に「できています」と自己肯定する傾向があるとのこと。検証が必要な用途では、モデルに自分の評価をさせるだけでは不十分で、批判的なフィードバックを返す仕組みを別で用意しないといけない、という指摘です。
私も実際に Claude に AWS CLI で AWS 環境を操作させて仕様の確認をさせたとき、実際にはできていないのに「できました」と報告されたことがありました。思い当たる節がある方も多いのではないでしょうか。
ハーネス設計の 4 つの柱
ここでは「ハーネス」の設計パターンが紹介されました。

ハーネスを一言で説明すると「モデル単体では安定して達成できないことを、外側の仕組みで前提として埋め込む足場」です。以下の 4 つの柱で整理されていました。
1. 明示的なシステムプロンプトとルーブリック
システムプロンプトとルーブリック (評価基準) の2つを明示的に設計することが、long-running な動作を可能にする前提になる、という話。ルーブリックは Claude が自身の作業を評価するための基準で、コードスタイルや設計方針・アーキテクチャの判断基準などを記述しておくものです。後述の evaluator エージェントと組み合わせて使います。
2. 外部アーティファクトへの情報の書き出し
context rot や lossy compaction を避けるため、コンテキストウィンドウの中にすべてを抱え込ませず、外部に永続化された成果物 (artifact) に状態を書き出す、というアプローチです。

具体的なやり方としては、たとえば以下のような流れ。
features.jsonのような JSON ファイルに、作るべき機能の仕様とテストを列挙しておく(おそらくタスクリストのように完了状態も管理されているイメージ)- 1 セッションで扱うのは、その中の粒度の小さい 1 機能だけ
- そのセッションでは仕様とテスト (最初は失敗する) を読み込み、テストが通るまで実装する
- 終わったらコミットして、そのセッションは閉じる
- 次のセッションでは、新しい、コンテキストウィンドウから JSON と履歴を読み直し、次のタスクに取り組む
Anthropic 内部の初期実験では、Sonnet 3.5 や Opus 3.5 で long-running の挙動を引き出そうとしたとき、新しい、コンテキストウィンドウに入るたびに前回までの作業内容を再収集する必要があり、トークンを大量に消費するだけでなく、前セッションの変更を巻き戻してしまうケースすらあったとのこと。
外部に状態を書き出しておき、新しい、コンテキストウィンドウではそれを読み直す、という構造にすると、context anxiety や要約による情報欠落を回避できる、という整理でした。
3. planner と builder の分離 (マルチエージェント)
shallow plans を避けるために、計画担当と実装担当を別のエージェントに分けるパターンです。

- planner エージェント: 最終的にどのような形になるかをにらんで、作るべき機能を細かく分解し、先述の JSON のような仕様に書き出す
- builder エージェント: planner が分解したタスクを 1 機能単位で受け取り、実装する
それぞれがシステムプロンプトで専門化されていて、役割を明確に分けるのがポイントです。一発で「Claude.ai のクローン作って」と投げるよりも、planner にじっくり仕様をほぐしてもらい、builder が順に作っていく、という流れのほうが long-running な挙動を安定して引き出せる、という話でした。
考え方としては Plan-then-Execute パターンに近いですが、planner と builder が別エージェント(別のコンテキストウィンドウ)で動き、計画を外部 JSON に書き出して複数セッションをまたぐ点が、long-running に特化した工夫ポイントだと思います。
4. evaluator エージェントによる成果の検証
self-leniency に対応するための仕組みとして紹介されたのが、uncorrelated context window (互いに独立した、コンテキストウィンドウ) を持つ evaluator エージェントを立てる、というパターンです。

- generator / builder 側: 実装を進めるエージェント
- evaluator 側: builder とは完全に独立した、まっさらなコンテキストウィンドウで走るエージェント。以下を定義して構成する
- ルーブリック: 採点基準を記述したもの。Anthropic のエンジニアリングブログのフロントエンド例では、デザイン品質・独創性・技術的実行・機能性の4軸で定義し、Few-shot プロンプティングで具体的なスコア分解例も添えている
- 完了の定義: フルスタック開発では「何をもって完了とするか」を事前に合意しておく(スプリント契約)
- ツール: Playwright MCP などを渡すと、ライブページと直接対話してスクリーンショットを取得・検証し、具体的なバグを特定できる
発想としてはソフトウェア開発の PR レビューと同じで、実装者本人はどうしても設計時の判断に縛られるので、別の人間が見たほうが見落としに気づける、という話。
もう 1 点、実務的なアドバイスとして、ルーブリックどおりに動かないときは エージェントのトレースや transcript を実際に読んで、evaluator が何を返しているかを確認する こと、が繰り返し強調されていました。そのうえでルーブリックやシステムプロンプトにフィードバックを反映して育てていく、反復的な作業になるとのことです。
なお、一般的なサブエージェント構成ではメインセッションに結果のサマリーしか返ってこないため、詳細なトレースは確認できなかったはずです。登壇者がここで前提としているのは、おそらく後述の Claude Managed Agents を使う構成を前提としているのではないかと思います。
信頼できる動作領域を広げる、そして新モデルが出たら見直す
ここで 1 段抽象的なメタ原則の話に入ります。各モデルは「安定してこなせるタスクの領域」を持っていて、その形はでこぼこしていて一様ではないという整理です。
- ある種のコーディング作業は得意
- ある種の設計判断は苦手
- そのさらに外側には、プロンプトを工夫しても安定しないタスクが広がっている
ハーネス (プロンプト、ツール、スキル、マルチエージェント構成) の役割は、この「信頼できる領域」を外側に押し広げることだと説明されていました。
そして重要なのが、新しいモデルが出たら、そのハーネスの前提は一度崩して検証し直すべき という指摘です。
具体例として、Sonnet 3.5 では context anxiety (コンテキスト不安) を回避するために積極的なコンテキストリセット (窓をまるごと捨てて外部化した状態から再スタート) が必要でしたが、Opus 3.6 では経験的にそこまで厳格なリセットは必要なかったとのこと。planner によるタスク分解は引き続き有効でも、リセットの強度は落としてよい、というように前提が変わっていきます。
そこから導かれる実務的な原則は以下のとおり。
- ハーネスはできるだけシンプルに作る
- 新モデルが来たら、組み込んでいた仕掛けを 1 つずつ外して挙動を確認する
- そのモデルに不要になった足場は取り除く
モデル側が 6〜12 週間おきに新しくなる現状を前提にすると、ハーネスを軽く保ち、モデルに合わせて育て続ける姿勢が前提になりそうです。
Claude Managed Agents
セッションの後半では、ハーネス設計をスクラッチで組まなくて済むように、Anthropic が数週間前に public preview で出した Claude Managed Agents の紹介がありました。公式ドキュメントで確認したところ、Claude Managed Agents は Anthropic API のエンドポイントとして提供されるサービスで、SDK 経由で利用します。

提供される主な要素は以下の通り。
- 宣言的なエージェント定義: 使うモデル、システムプロンプト、ツール、MCP サーバー、スキルを宣言的に指定する
- セッション: 環境内で動作するエージェントのインスタンス。特定のタスクを実行し、出力を生成する
- 実行基盤: Anthropic 側のインフラで、計算資源やサンドボックス付きの実行環境を提供する
- イベント: アプリケーションとエージェント間でやり取りされるメッセージ(ユーザーの指示、ツール実行結果、ステータス更新など)。セッションでは上記 3 つが紹介されていたが、公式ドキュメントではイベントが独立した 4 つ目の概念として定義されている
ポイントは、オーケストレーションや実行環境を Anthropic 側が引き受けてくれるので、ユーザーは問題領域に集中できる、という点です。
デモ: Claude.ai クローンを 3 エージェントで作る
セッション全体を通じて例として使われていた「Claude.ai のクローンを作る」というタスクを、Managed Agents の基本機能を使って組んだ例も紹介されていました。
- planner エージェント: モデルは Claude Opus 4.7、システムプロンプトで「WHAT を定義し HOW は書かない read-only な仕様作成エージェント」として定義、ツールは read / glob / grep など参照系に制限
- builder エージェント: planner を
callable agentsに指定することで、builder のシステムプロンプトから planner に計画作成を委譲できる - evaluator エージェント: プログラムのエントリーポイントかつオーケストレーターとして機能し、planner と builder の実行を束ねつつ、ルーブリックを与えて別のコンテキストウィンドウで成果を批判的に評価する

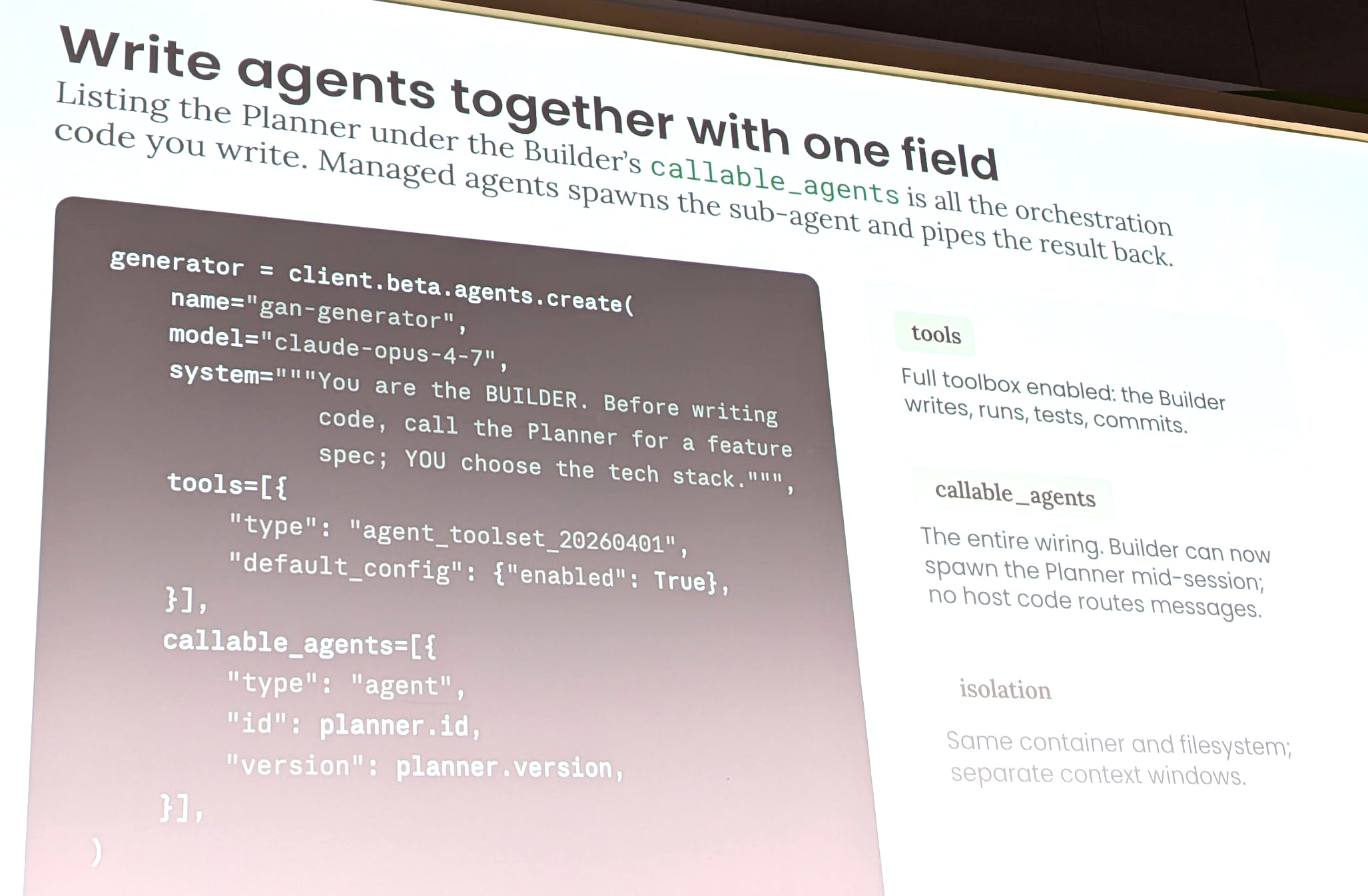

エージェント同士の呼び出しは、callable_agents 引数に相手のエージェント ID を指定するだけで成立します。Managed Agents 側がオーケストレーションを自動的に処理してくれるので、ユーザー側でエージェント間通信のコードを書く必要はない、という作りです。
私自身はまだ Anthropic SDK を触ったことがないため、聴いていてもいまいち使うイメージがつかめていないのが正直なところです。実際に手を動かして SDK を触ってみないとなと思いました。
Q&A から
セッションの最後に Q&A が 4 問ほどあり、実務的に気になるポイントが整理されていたので抜粋します。
レートリミットや上限を超えた場合どうなるか
Claude Managed Agents はクラウドサービス側の API をネイティブにパススルーする作りで、コンシューマ向けにあるような利用上限の概念は持っていないとのこと。基盤 API 側のレートリミット上で動作するので、アプリ側の制限に引っ張られる作りではない、という回答でした。
他のクラウドやオンプレミスで動かせるか
エンタープライズ顧客は独自のネットワーキング要件やセキュリティ要件を持っているため、実行環境に対する仮定は最小限にしている、との説明。オンプレでも他クラウドでも、実行環境として接続すれば Managed Agents から利用できる、シンプルな抽象を用意している、という回答でした。
ハーネスを見直すタイミングはいつか、どこまで作り直すべきか
まず定量的な評価指標 (evaluation) を持っていることが前提、という話から始まりました。そのうえで、新しいモデルが出たタイミングを節目として、ハーネスに組み込んでいたコンポーネントを 1 つずつ外してみて、最終評価スコアに影響が出なければ、そのコンポーネントはモデル側に吸収されたと判断して取り除く、という進め方です。
Opus → 3.5 → 3.6 → 3.7 と進化する中で、実際にこれをやってきたとのこと。
マルチエージェント構成で得られた学びと、単一エージェントとの評価の違い
ここは明快で、「まず一番シンプルで素朴な 1 エージェント構成から始めて、必要になったときにだけ複雑化する」の一言に尽きるとのこと。マルチエージェントにすると当然ながらレイテンシとコストが跳ね上がるので、定量評価で優位性が出ない限り避ける、という姿勢でした。
user-defined app run と builder / generator の関係
デモのコードで evaluator 側のエントリーポイントがどう builder / planner に繋がるのかが分かりにくい、という質問に対しては、orchestration は Managed Agents 側で引き受けるので、ユーザーは宣言的に終端の振る舞いを書くだけでよい、という回答でした。エージェントはそれぞれ callable agents で ID を宣言しており、セッション ID を軸に Managed Agents がイベントを流してくれる、という構造です。
まとめ
- long-running agent の設計は経験的な営みで、モデルを実際に動かさないと見えないつまずきパターンがある
- 主要なつまずきパターンは、context rot、context anxiety、lossy compaction、shallow plans、self-leniency の 5 つ
- これらを補うのがハーネスで、柱は (1) 明示的なプロンプトとルーブリック、(2) 外部アーティファクトへの状態書き出し、(3) planner / builder の分離、(4) uncorrelated context window による evaluator
- ハーネスはシンプルに作り、新モデルが出たら前提を崩して検証し直す
- Claude Managed Agents は宣言的なエージェント定義とオーケストレーションを提供し、ハーネスを素早く試行錯誤するための基盤になる
所感
planner・builder・evaluator の 3 エージェントを組み合わせるという考え方は、API での利用だけでなく、Claude Code を使う中でも転用できそうだと感じました。今後 Claude Code のスキルを作る上でこういった構成を取り入れると、面白い動きができるかもしれないなと思っています。
あとは self-leniency、Claude に自分の仕事を評価させると甘くなる、という話。たしかに、、という感じで、別の、コンテキストウィンドウで動く evaluator を立てるという発想は Claude Managed Agents も含めて一度手を動かして試してみたいなと思いました。
以上、とーちでした。










