
【アップデート】Amazon Lookout for Visionが異常箇所まで特定できるようになりました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データアナリティクス事業本部機械学習チームの中村です。
先日、Amazon Lookout for VisionをAKIBA.AWS ONLINE #9にて紹介しました。
その中でも触れましたが、以下のようにAmazon Lookout for VisionがSegmentationモデルに対応するアップデートがありました。
今回はこちらについてご紹介します。
Segmentationモデルとは
Segmentationモデルとは画像の異常検知モデルの1種です。(従来のものはClassificationモデルと呼ばれます)
Segmentationモデルには以下のような特徴があります。
- 異常部分の特定まで実施します。
- 異常の種類についても見分けます。
またデータセットとしても従来と異なる準備が必要となり、以下のようなアノテーションが必要となります。
- 異常部分のアノテーションまで実施する。
- その異常部分について、異常の種類をラベル付けする。
実際にマネジメントコンソールで試したところ、異常部分のアノテーションまで実施しておくとSegmentationモデルとなり、そうでない場合は従来のClassificationモデルとなるようです。
試してみた
それでは、Amazon Lookout for VisionのSegmentationモデルを実際に試してみます。
前提として、コンソールバケットは作成済みで進めていきます。
(コンソールバケットはリージョン毎に必要です。リージョンで未作成の場合も、初回画面に沿えば、簡単に作成できます。)
データセット
公式ブログの沿って宇宙人の人形データセットを使ってみます。
データは以下のGitHubから取得します。
以下のように足が欠けたり、頭部が欠けたり、色々な部分で異常が発生しているデータです。

また人形の背景が白背景になっており、人形の輪郭にうっすらと元の背景が残っているように見えます。
(この背景を白背景にするかどうかは、性能に少し関連があるかもしれません)
データの仕様は以下の通りです。
- データ数
- normal: 58
- anomaly: 60
- 解像度
- 550 x 380 (width x height)
以降では、上記のデータを以下のように分割して進めます。
- train
- normal: 40
- anomaly: 40
- test
- normal: 10
- anomaly: 10
- トライアル推論用
- normal: 8
- anomaly: 10
プロジェクト作成
『プロジェクトを作成』を押下してプロジェクトを作成していきます。
プロジェクト名を入力して、『プロジェクトを作成』を押下します。
データセット作成
『データセットを作成』を押下しデータセットを作成していきます。
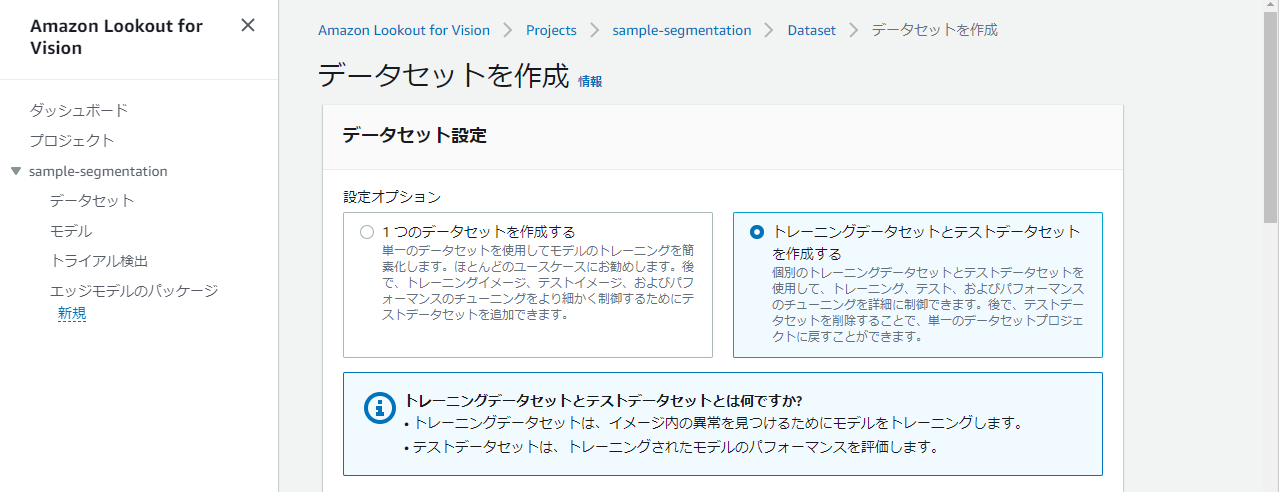
データセット設定は、トレーニングデータセット、テストデータセット双方を有効とした設定で実施します。
トレーニングデータのインポート方法はローカルからのアップロードを選択します。
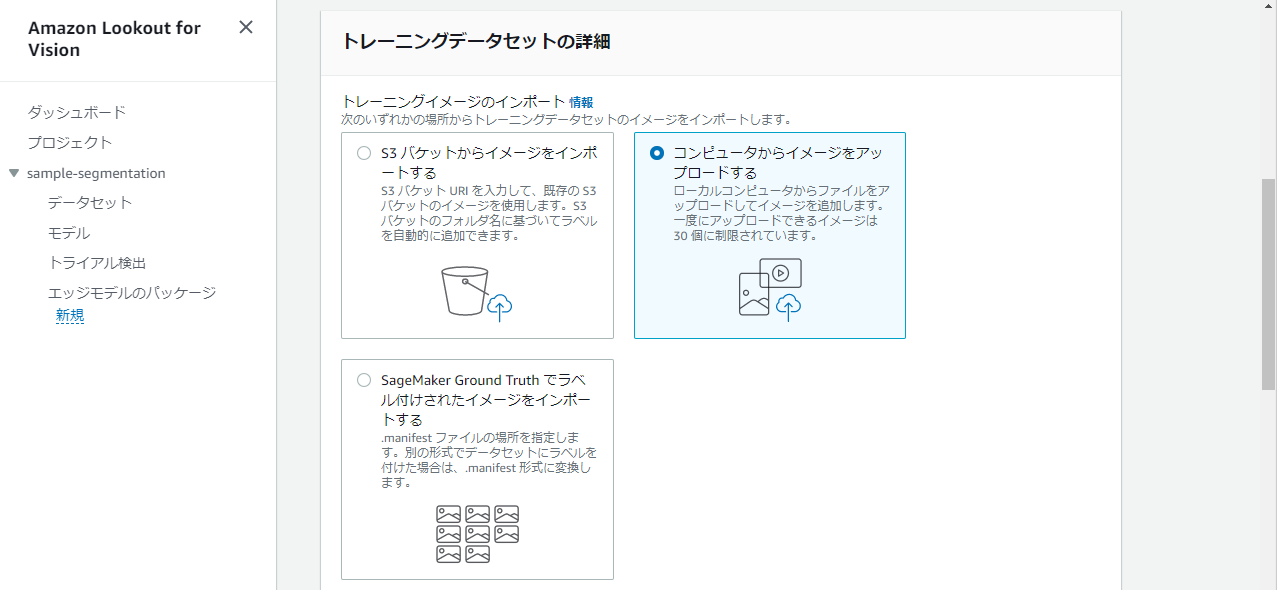
テストデータも同様にローカルからのアップロードを選択します。
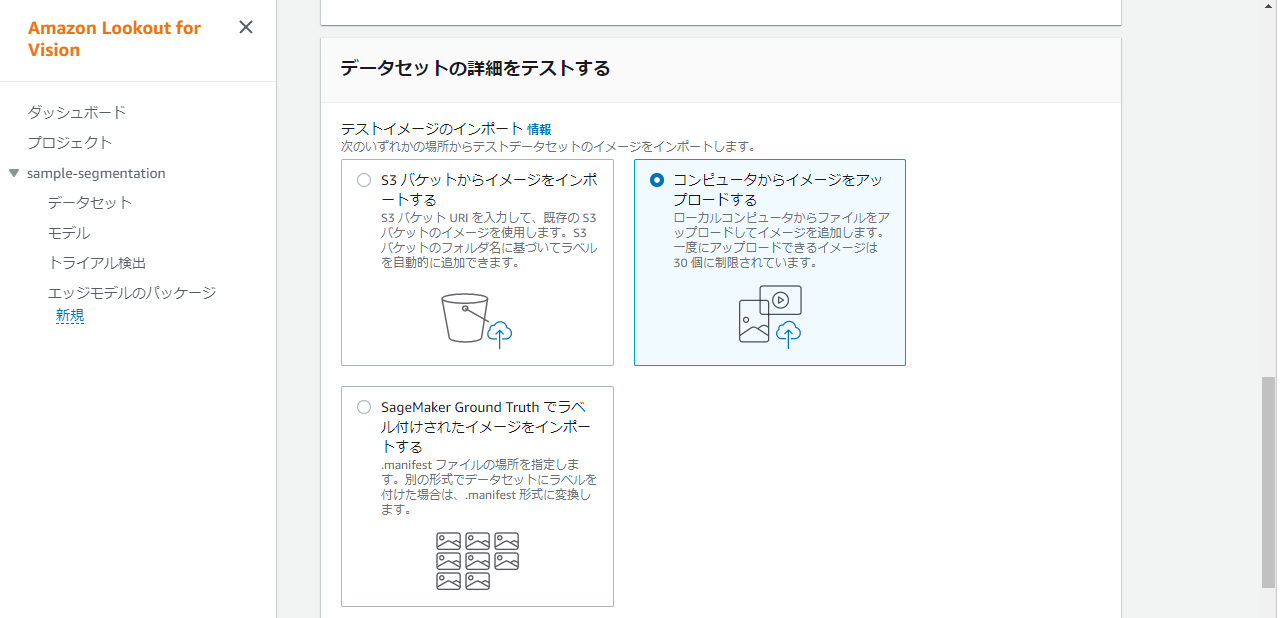
最後に『データセットを作成』を押下します。

イメージのアップロード
データセット画面を表示して、トレーニング側のタブで『イメージを追加』を押下します。
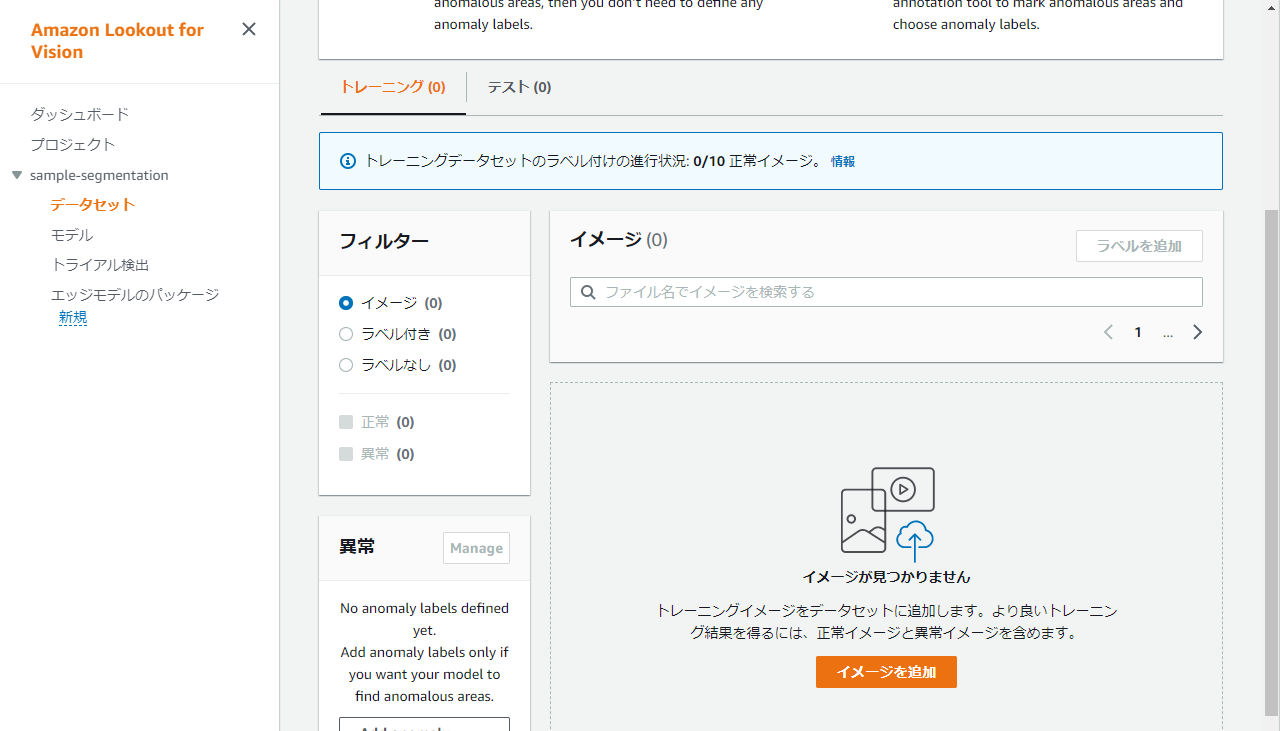
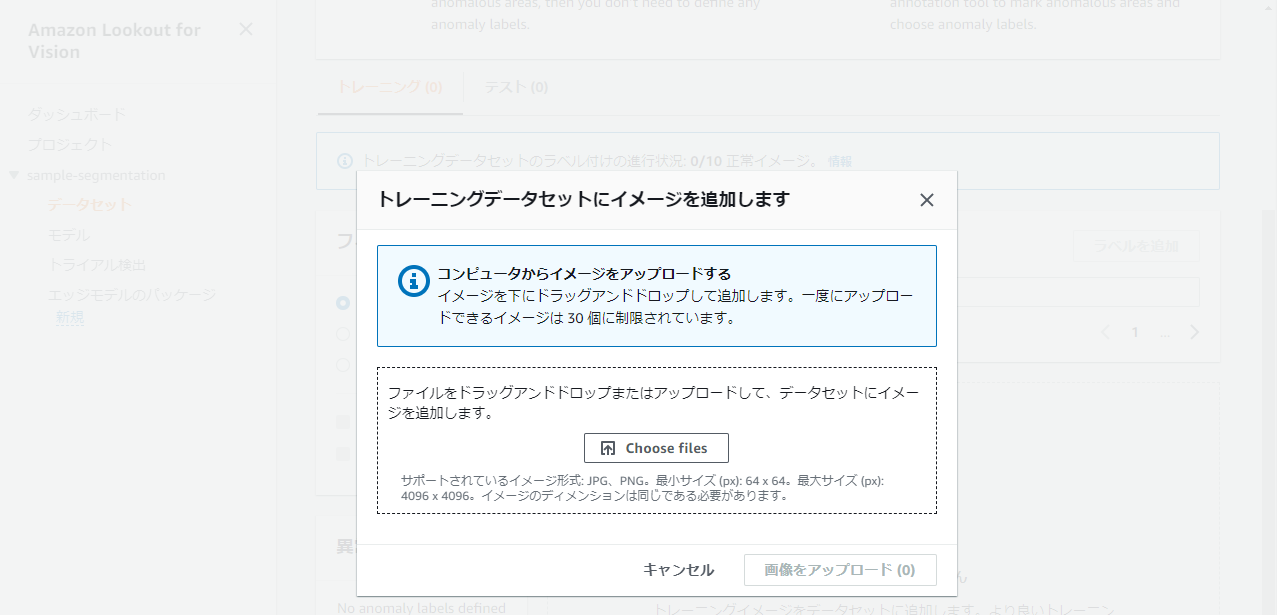
Choose filesでデータをアップロードします。
トレーニングとしては、normal:40個、anomaly:40個をアップロードします。
30個ずつしかアップロードできないため、複数回に分けてアップロードが必要です。
ラベル付け
アップロードが終わりましたら、normal/anomalyのラベル付けをします。
『ラベルを追加』ボタンを押下して開始します。
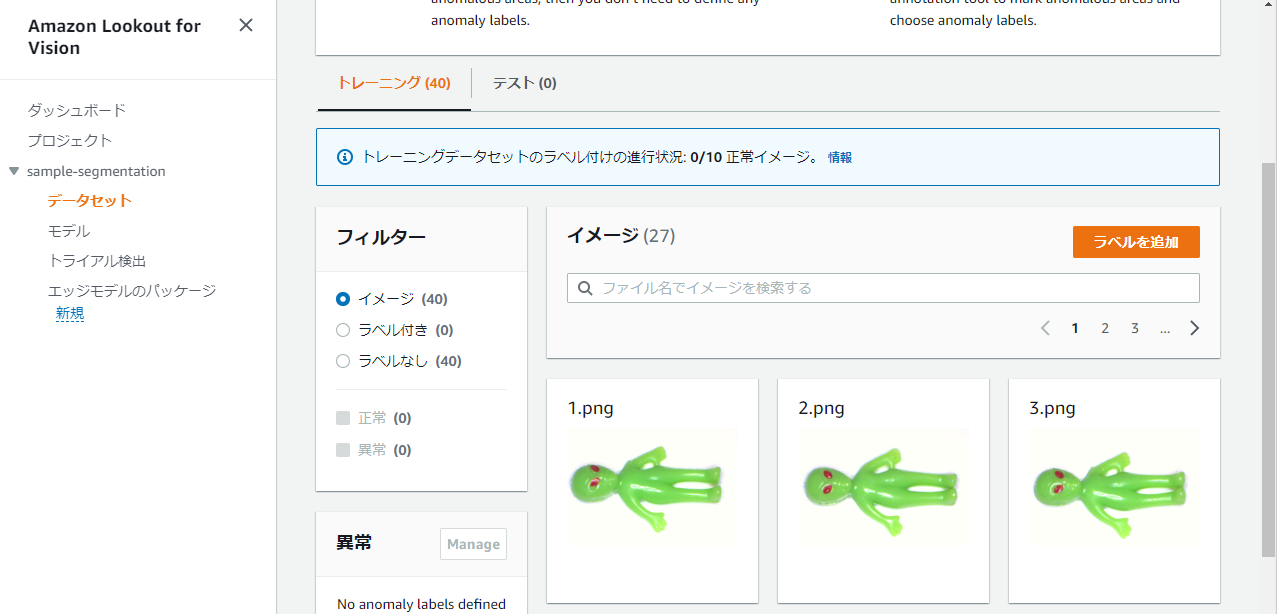
一つ一つにラベル付け用のボタンが表示されますので、そちらを使用するか、チェックボックスでまとめてラベル付けしていきます。
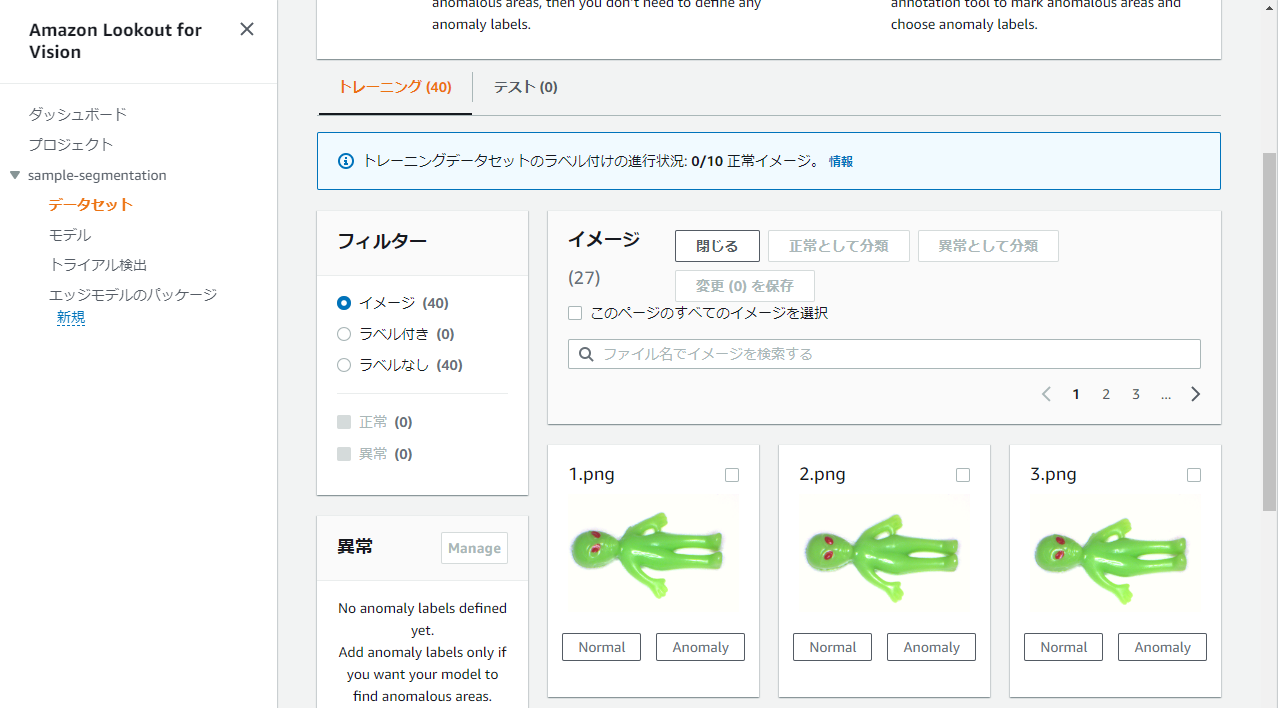
以下のようにnormalとanomalyを付け終えました。
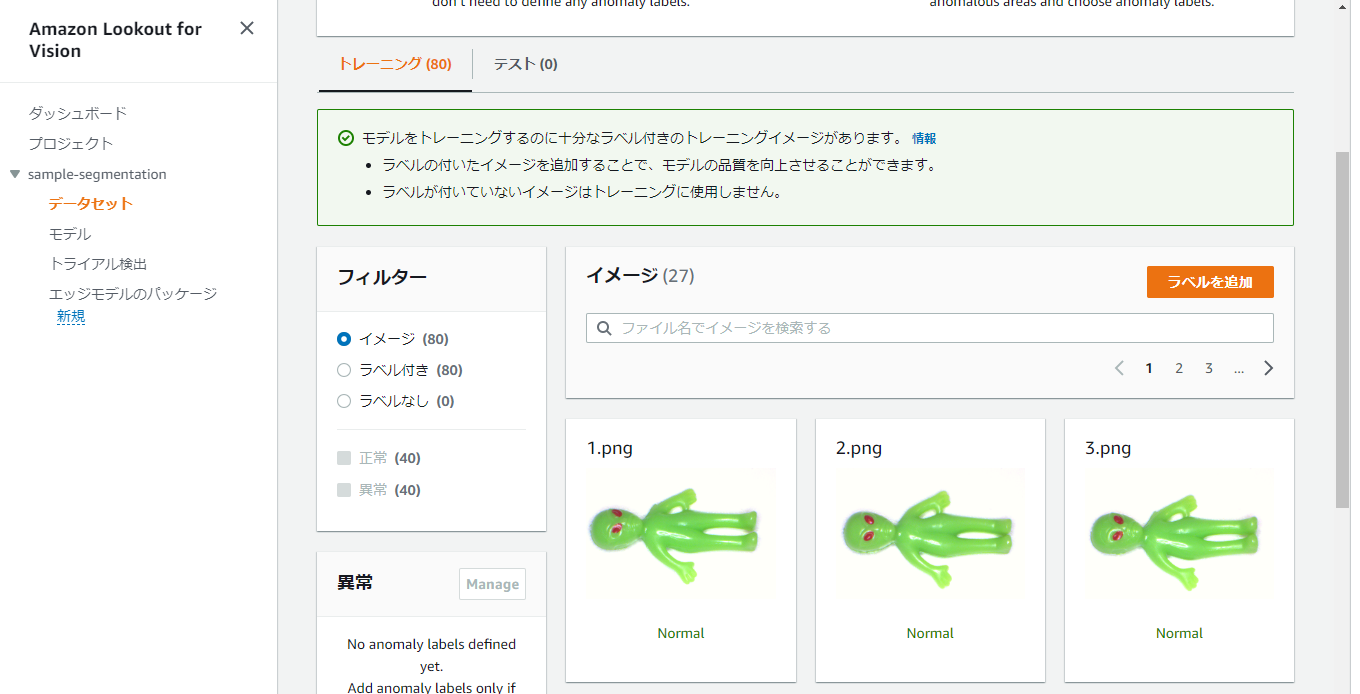
さらにここから、異常箇所のアノテーションを実施します。
『ラベルを追加』ボタンを再度押下して、anomalyデータについては以下のような画面でピクセル単位のアノテーションを実施します。
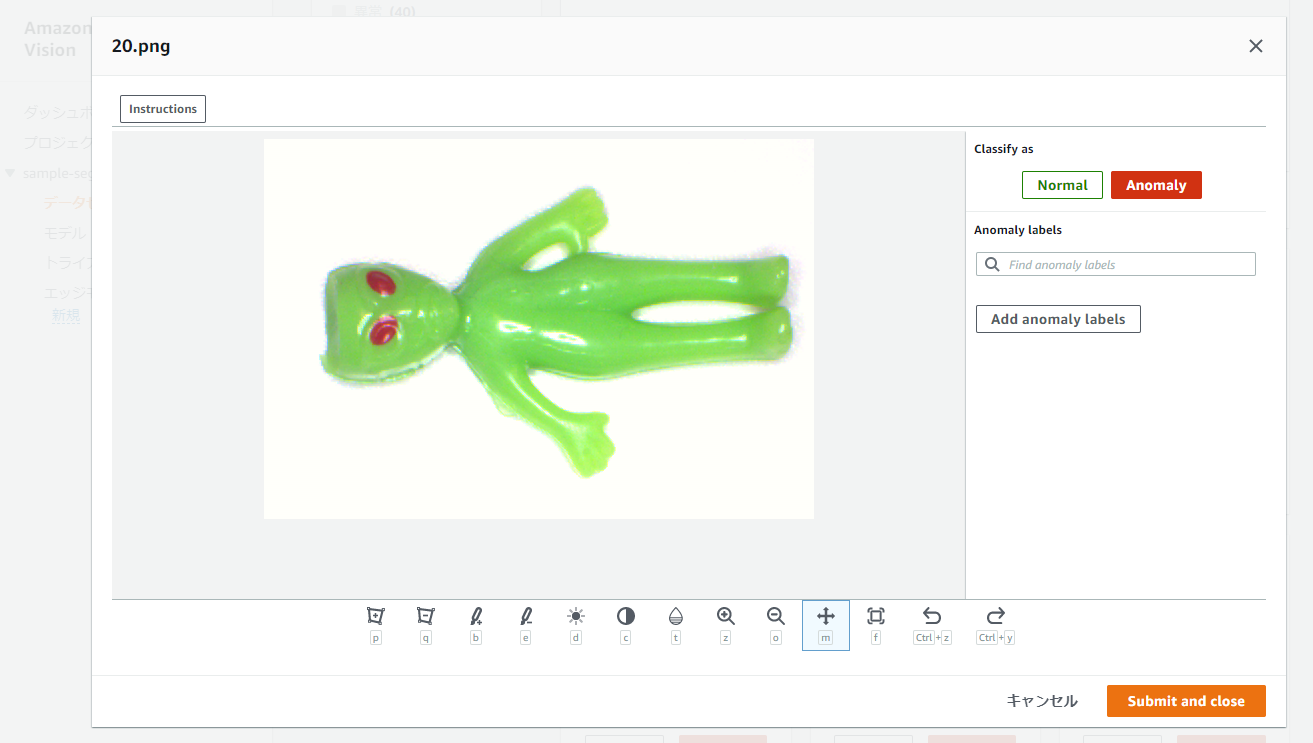
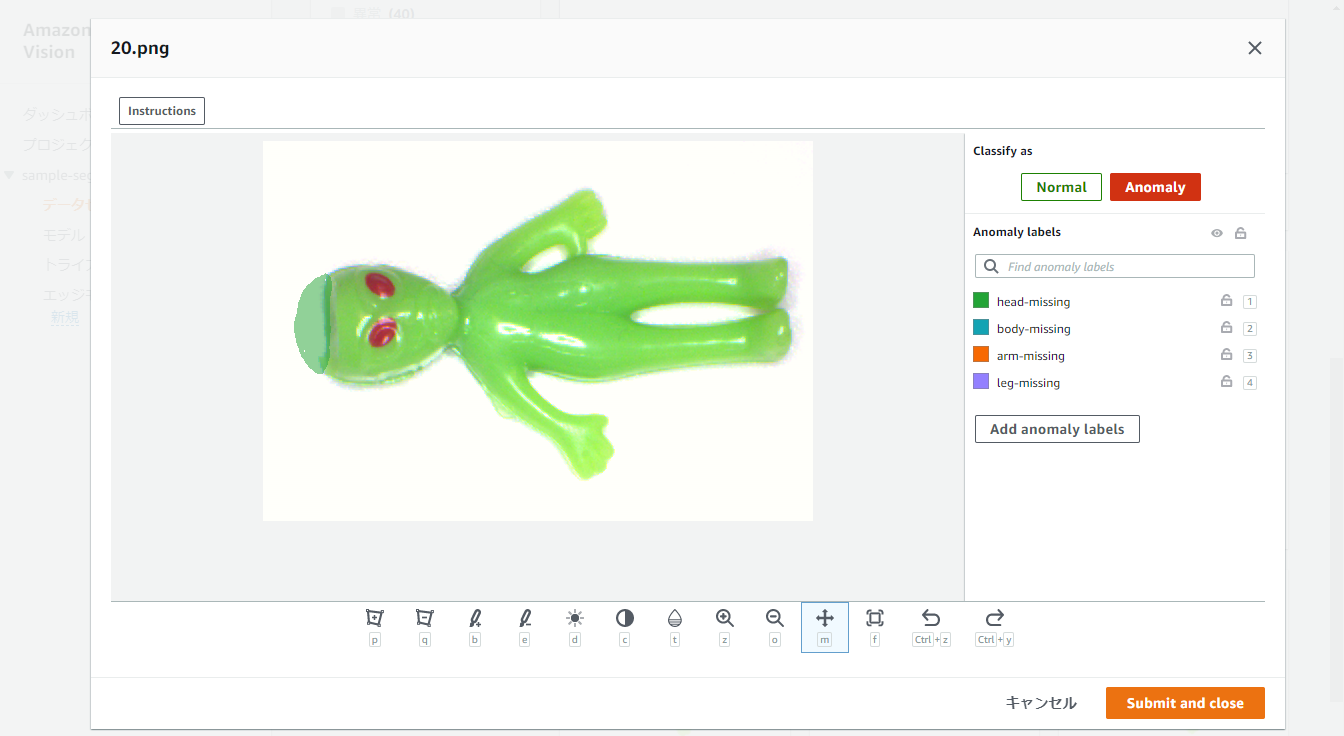
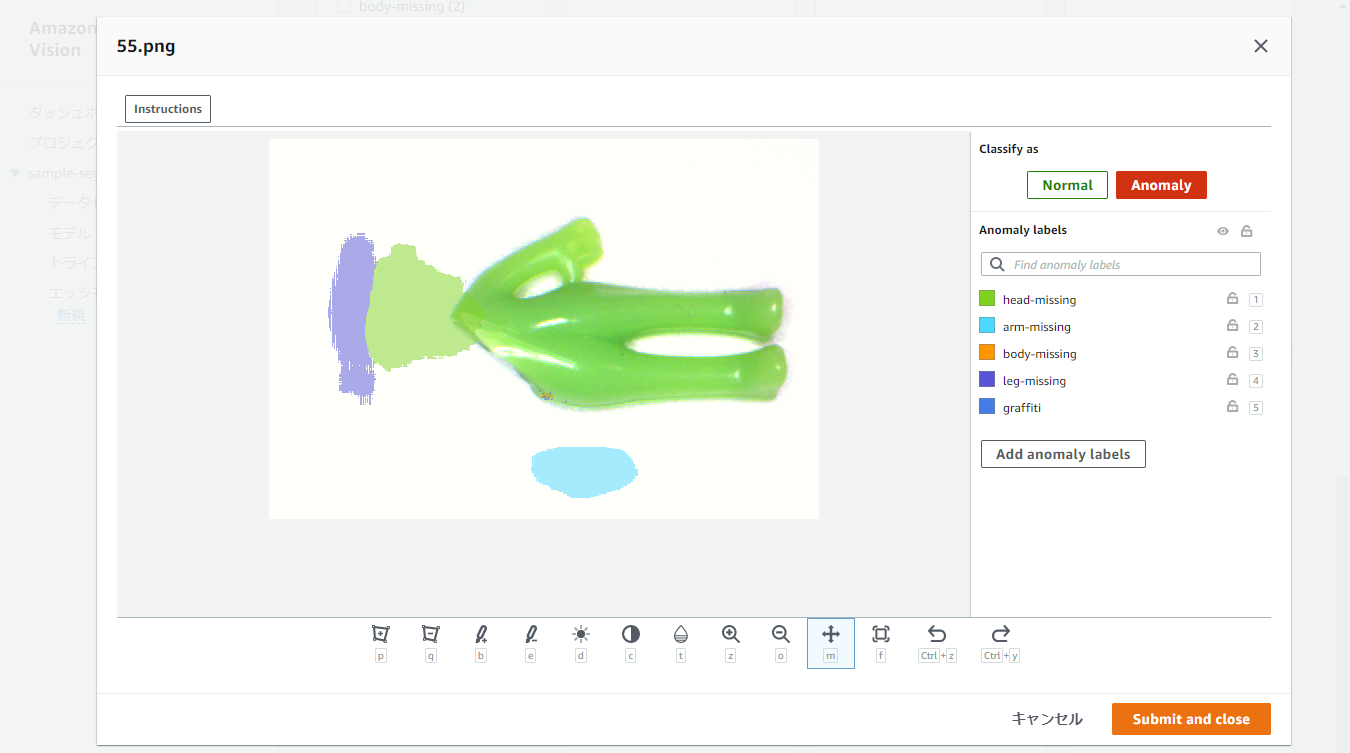
例えば上記の画像については、head-missingという名前を付けてアノテーションしました。
アノテーションには左から3番目のBrushを使用しました。
また、例えば以下に示す別のサンプルでは、4種類のアノテーションを行いました。
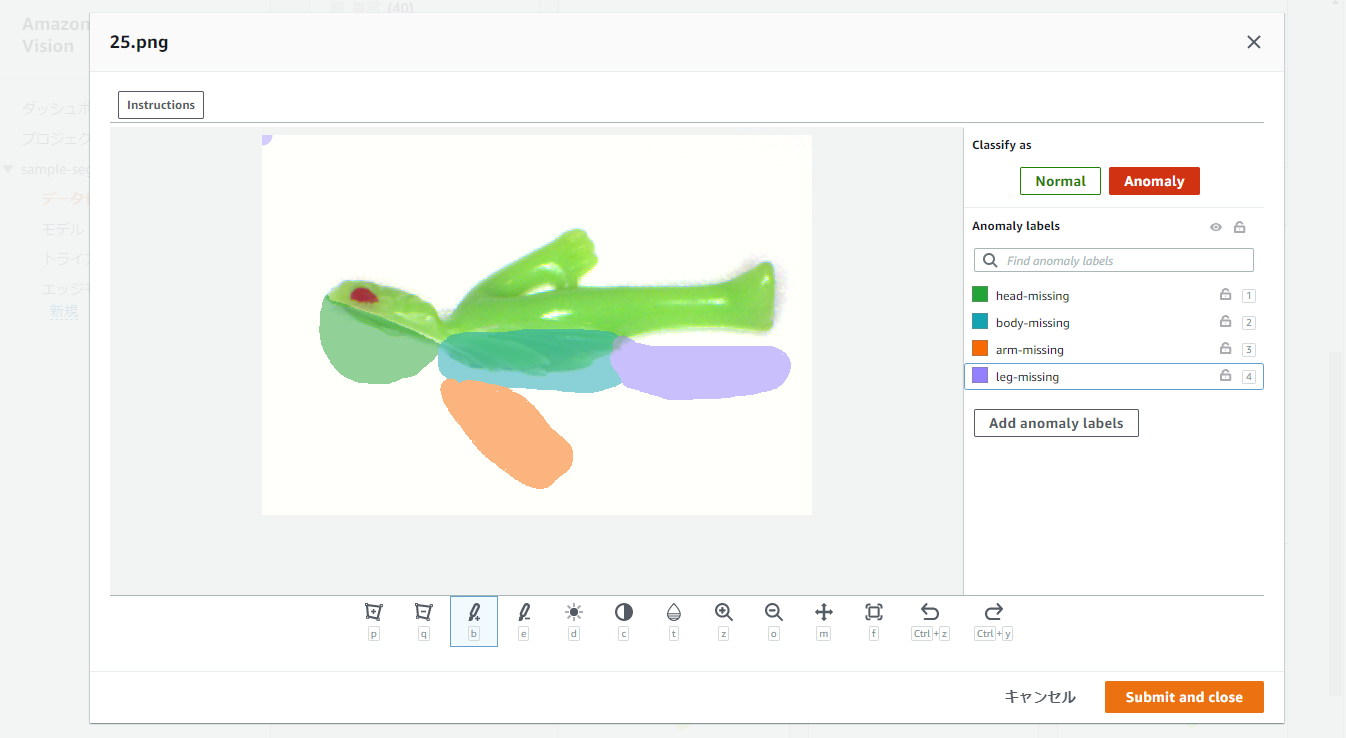
これをすべてのanomalyデータに対して行います。
また、これをテストデータに対しても同様に実施します。
これらのアノテーション結果は、コンソールバケットに*.png.stagingという名前で画像データとして保存されます。
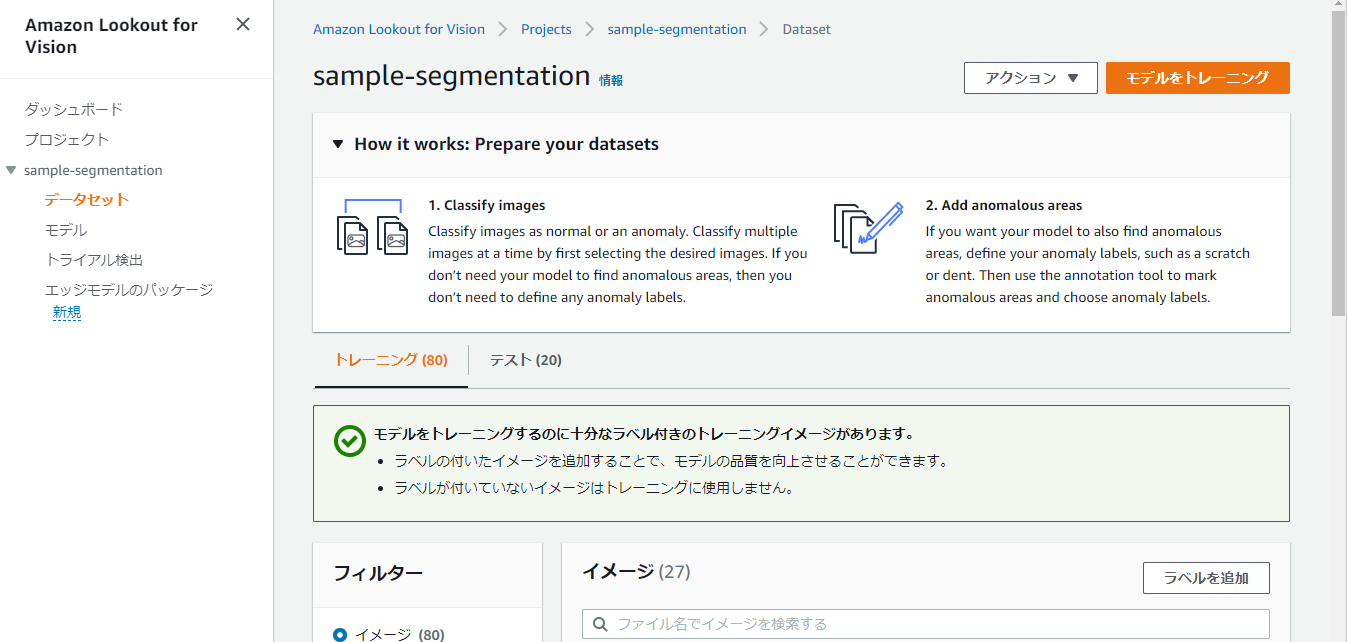
トレーニング
ラベル付けが一通り終わりましたら、データセットの画面で『モデルをトレーニング』を押下します。
画面遷移後、さらに『モデルをトレーニング』を押下します。
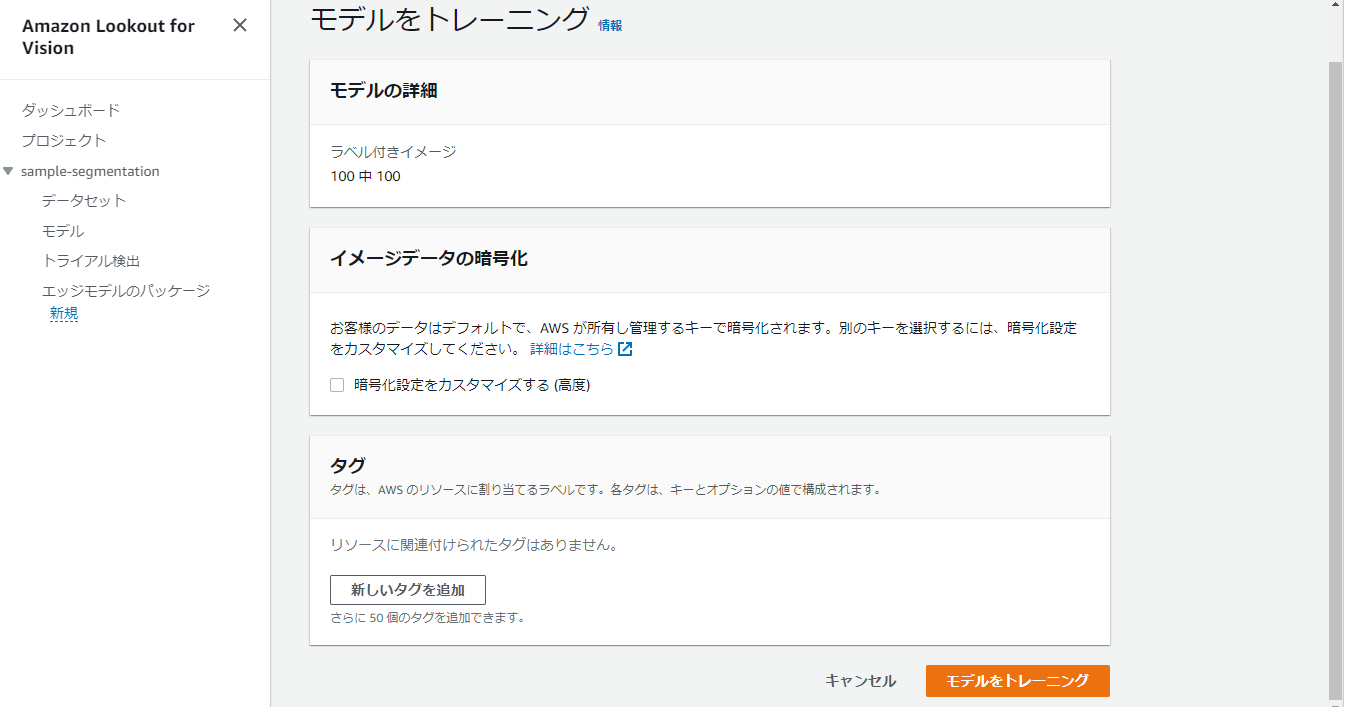
トレーニングが開始され、進行中となります。
今回のデータセットでは、約20分でトレーニングが完了しました。
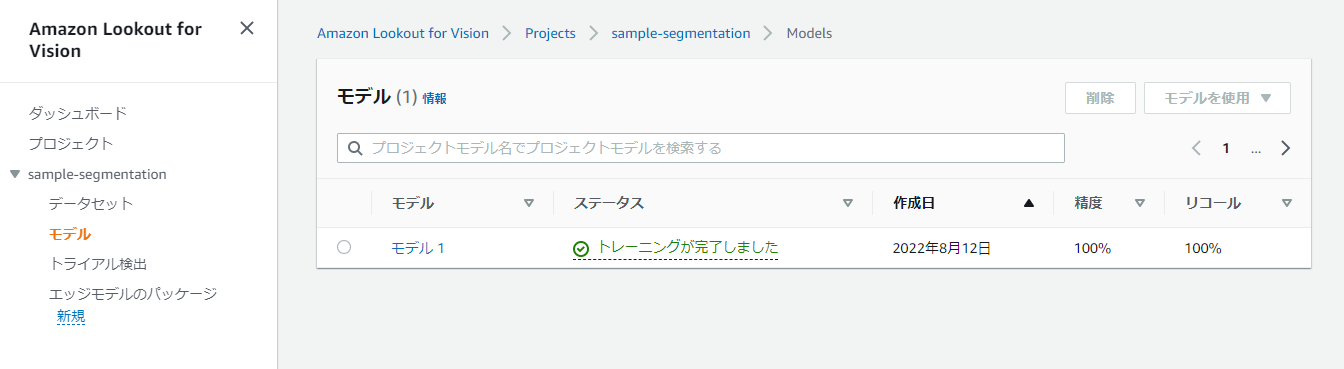
学習結果の確認
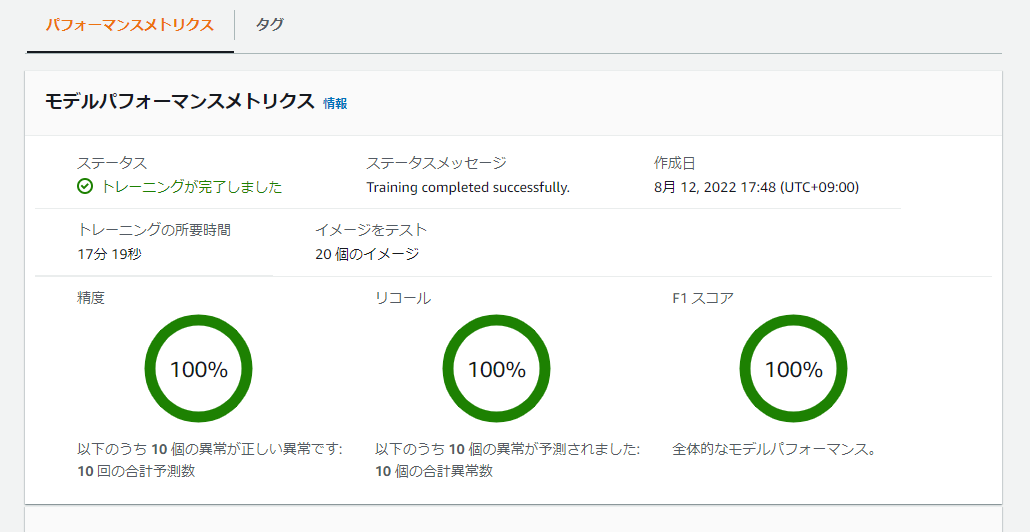
モデルを選択すると評価結果が得られます。
まずは、概要として事前にインポートしたテストデータに対するPrecision、Recall、F1スコアを見ることができます。
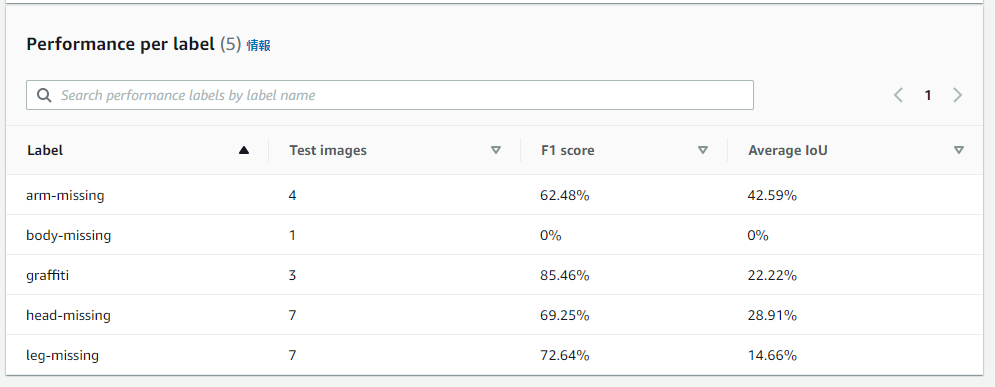
さらにその下に、異常の種類ごとのスコアを確認することができます。
各テストデータごとの結果についても以下のように確認が可能です。
ただしくSegmentationできるものもあれば、そうでないものもありそうです。
トライアル検出の実行
最後に残りの画像データについてトライアル検出を実行します。
以下の画面で『トライアル検知を実行』を押下します。
タスク名を入力し、モデルを選択します。イメージはローカルからアップロードする方法を選択します。
その後ページ下部の『異常を検出』を押下します。
ダイアログのボタンを押下します。

ファイル選択画面が表示されるため、ローカルのファイルを選択します。
今回、画像ファイルのファイル名がnormalとanomalyで同名であったため、別々のトライアル検出タスクを実行して確認しました。
以下がnormalな画像ファイルのトライアル検証結果です。
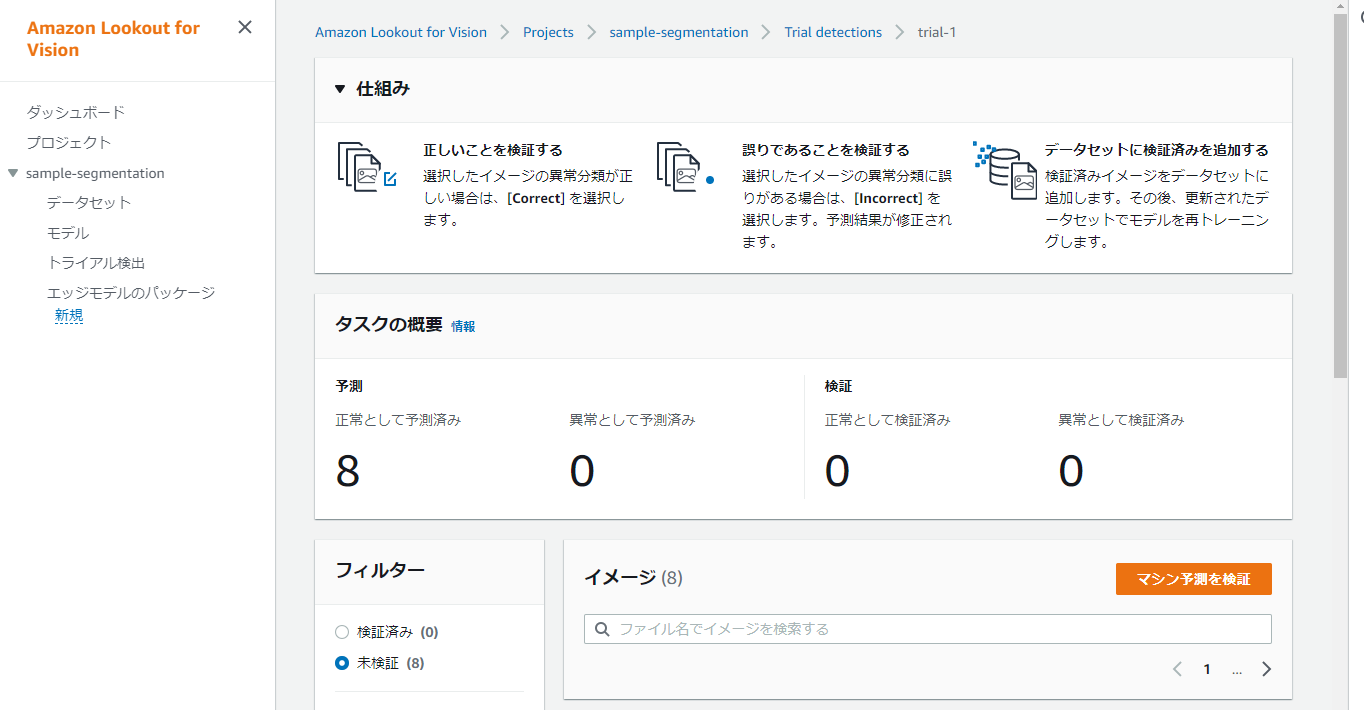
すべて正常と推論できていることが分かります。
またトライアル推論したデータは、『マシン予測を検証』ボタンを押下することで、データセットに含めることができます。
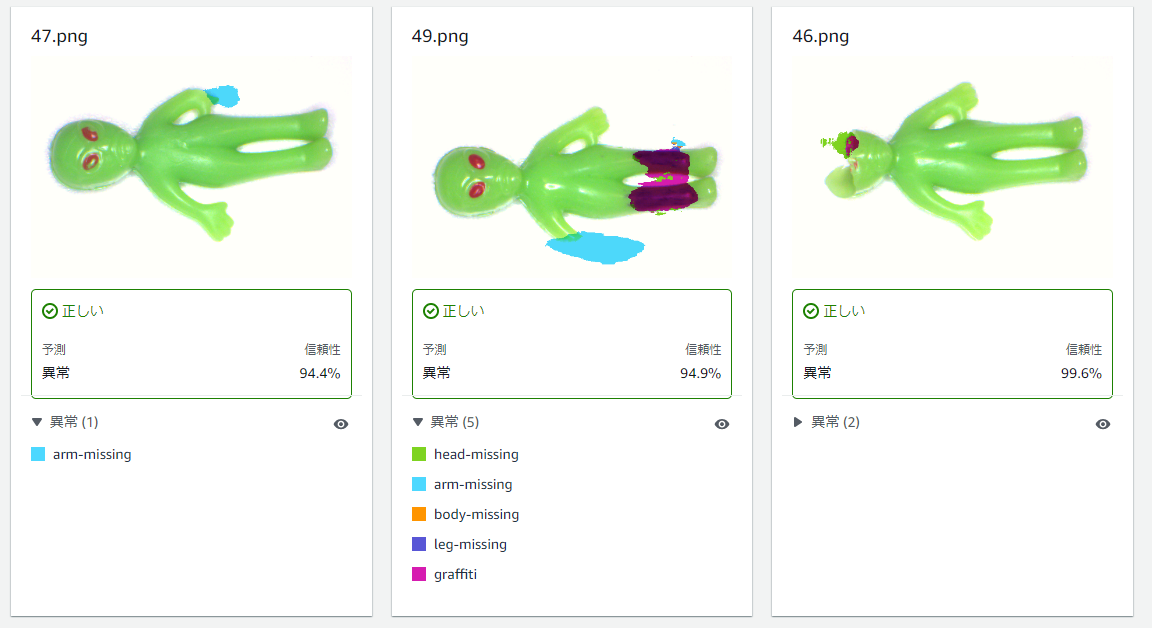
次に、anomalyな画像ファイルのトライアル検証結果です。
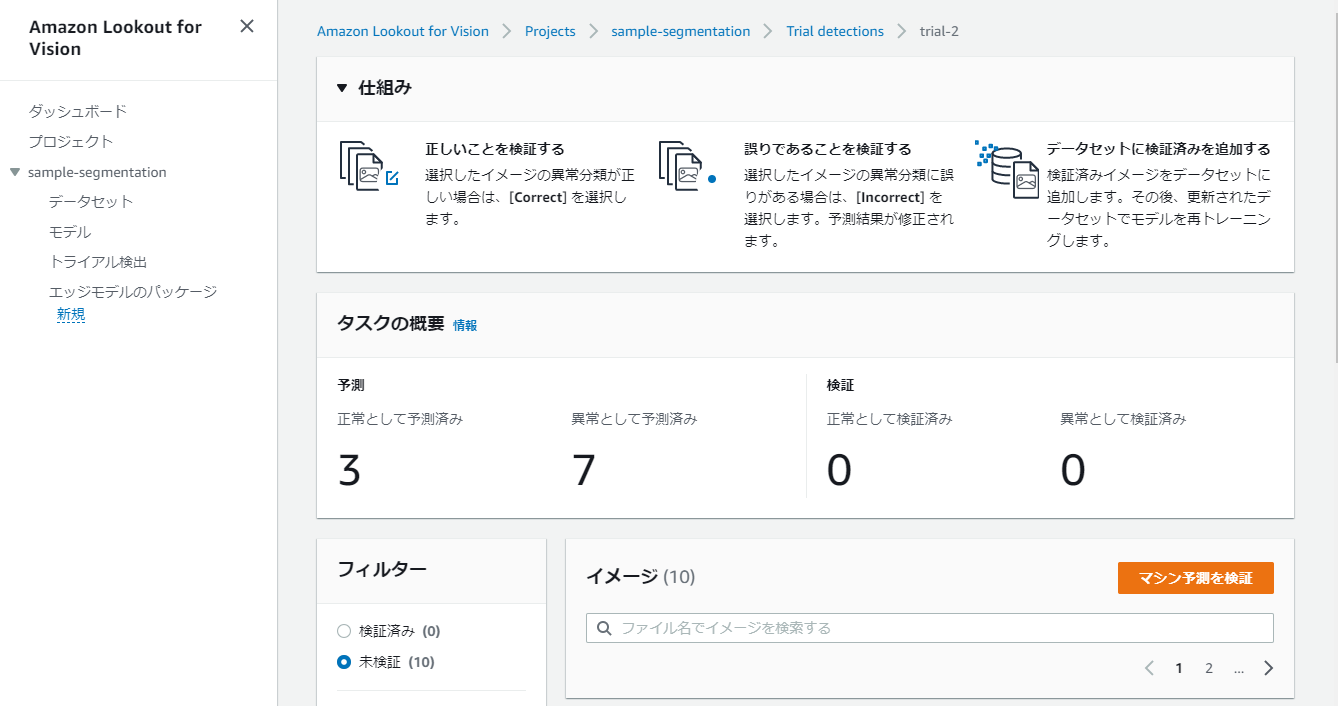
3件を誤って正常と判定していることが分かります。
こちらも、『マシン予測を検証』ボタンを押下することで、予測結果を手動で修正し、データセットに含めることができます。
また、検証の際にSegmentation結果も修正することができます。
例えば以下のようなデータはnormal/anomalyの判定は正解していますが、Segmentation結果は修正が必要です。
まとめ
いかがでしたでしょうか。
Segmentationモデルは異常箇所やその種類まで判定できますので、従来のClassificationモデルに対してできることがかなり広がった印象を受けました。
今後活用していきたいと思います。
この記事が、画像の異常検知を試されたい方の参考になれば幸いです。










