
Microsoftが出した新しいAIモデル3種を試してみた
こんにちは、せーのです。2026 年 4 月、Microsoft が MAI(Microsoft AI)シリーズとして画像・音声まわりの新モデルを打ち出しました。OpenAI や AWS、Anthropic がそれぞれ別の軸で手を打つなかで、「なぜ今、Microsoft は音声と画像なのか」と感じたので、公開情報を整理しつつ Microsoft Foundry(Azure AI Foundry) 上で実際に触ってみました。
この頃のAIベンダー各社は、ちょっとずつ方向が違う
OpenAI: 動画から手を引き、エンタープライズ寄りへ
2026 年 3 月、Sora の終了計画が公表されました(アプリ版・API 版でスケジュールあり)。公式ヘルプでは利用終了にあたっての案内がまとまっています。社外の報道では、生成コストや収益性、リソースを次世代モデルやエンタープライズ向けに振りたい、といった文脈で語られています。細部はすべて検証できるわけではありませんが、「動画生成に張り付き続ける」より「会社としての主戦場をはっきりさせる」ムードが強まっているように見えます。
AWS: Nova で価格とスループットの話を前面に
Amazon Nova は、公式の料金ページでmicro〜proまで幅広い価格帯が示されており、「同じクラウド上で推論を回すコスト」を争点にしやすい立ち位置です。Bedrock への統合やルーティング系の機能とセットで、「とにかくエンタープライズの単価感を下げる」ストーリーがはっきりしています。
Anthropic: Claude Code からナレッジワーク全体へ
Claude Code を中心とした開発者向けの伸びは、プレスや分析記事でもよく取り上げられています。2026 年に入ってからは、開発者以外の業務利用やパートナーエコシステムの強化など、「コード以外のナレッジワーク」への横展開が続いています。
違いを整理すると、動画縮小・低コスト推論・コード/業務ワークフローのいずれかに旗を鮮明に立てる動きが目立つ、というイメージです。
Microsoft が MAI で押し出すもの
Microsoft 側の公開情報では、次のような整理ができます。
- OpenAI との関係見直し: 自社でフロンティア級モデルを育てる余地を広げる、といった文脈が報道されています。
- Copilot 製品群への載せ方: Teams での会議文字起こし(Transcribe-1)、PowerPoint まわりの画像生成(Image-2)、検索・ブラウザー体験への音声・画像、といった「プロダクトへの組み込み」が前面です。
- 今回の三兄弟:
- MAI-Image-2: テキストからの画像生成。Arena 系のランキングや日本語テキストの扱いが話題になりやすいタイプです。
- MAI-Transcribe-1: 多言語の音声認識。Azure の既存 STT と比べてどれだけ速いか、が売り文脈に入ります。
- MAI-Voice-1: 音声合成。低遅延で長めの音声を一気に、という説明が出ています。
要するに、「チャットの頭脳」だけでなく、会議・資料・音声 UIまで一気通貫で握りにいく、という見え方です。
業界トレンドとしての「マルチモーダル」
テキストだけのチャットボット市場はすでに巨大で、性能競争も一段落というより「当たり前の基準(table stakes)」側に寄ってきています。そこで次の投資先として、音声エージェントや画像・動画など マルチモーダルの話が増えています。Fast Company や ElevenLabs のブログなどでも、2026 年はその延長線上、と読める記事が並びます。
ここからは実際に Foundry を触った記録です。手順書より 結果と違和感を中心に書きます。
やってみた
Microsoft Foundry に入るところから
ブラウザで Microsoft Foundry にサインインし、プロジェクトを選びます。モデル カタログには、今回の MAI モデル向けの案内カードも出てきます。
各モデルは デプロイ(Pay-as-you-go) を作成してからプレイグラウンドで試します。初回は「既存のデプロイがない」空状態から、ウィザードに沿って作成する流れでした。
リージョンはモデルによって利用可能な地域が限られるので、デプロイ画面の案内に従うのが安全です(手元では米東部系を利用)。
MAI-Image-2: 日本語の「焼鳥」も、庭園も
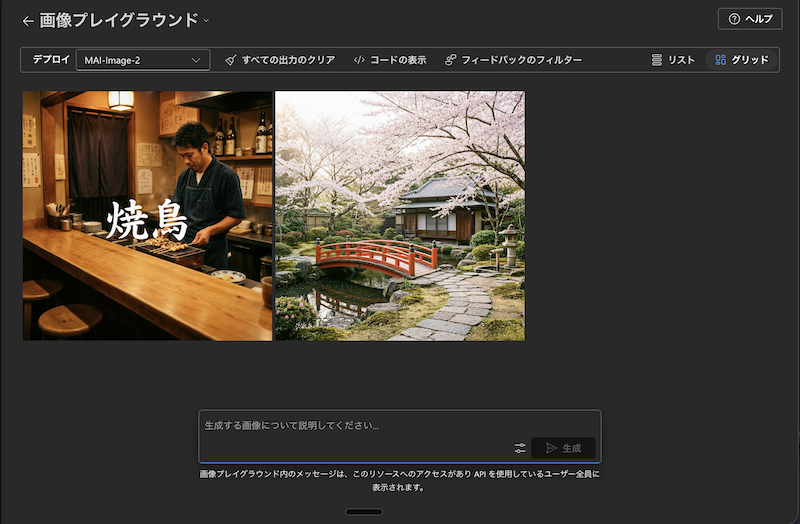
画像プレイグラウンドで MAI-Image-2 を選び、英語プロンプトで日本庭園と桜、やきとり屋のシーンに 日本語の看板文字を載せる、といった指定を試しました。
体感では 数秒〜10 秒前後で返ってきます。結果としては、桜と橋と石畳のバランスが安定していたり、店内の照明や串の質感が過剰に崩れない、といった「商用資料のたたき台」として十分なレベルに見えました。日本語の「焼鳥」は明朝体っぽく読みやすく載り、文字だけが崩壊するパターンも少なかったです。
MAI-Transcribe-1: リアルタイムとファスト、同じファイルで比較
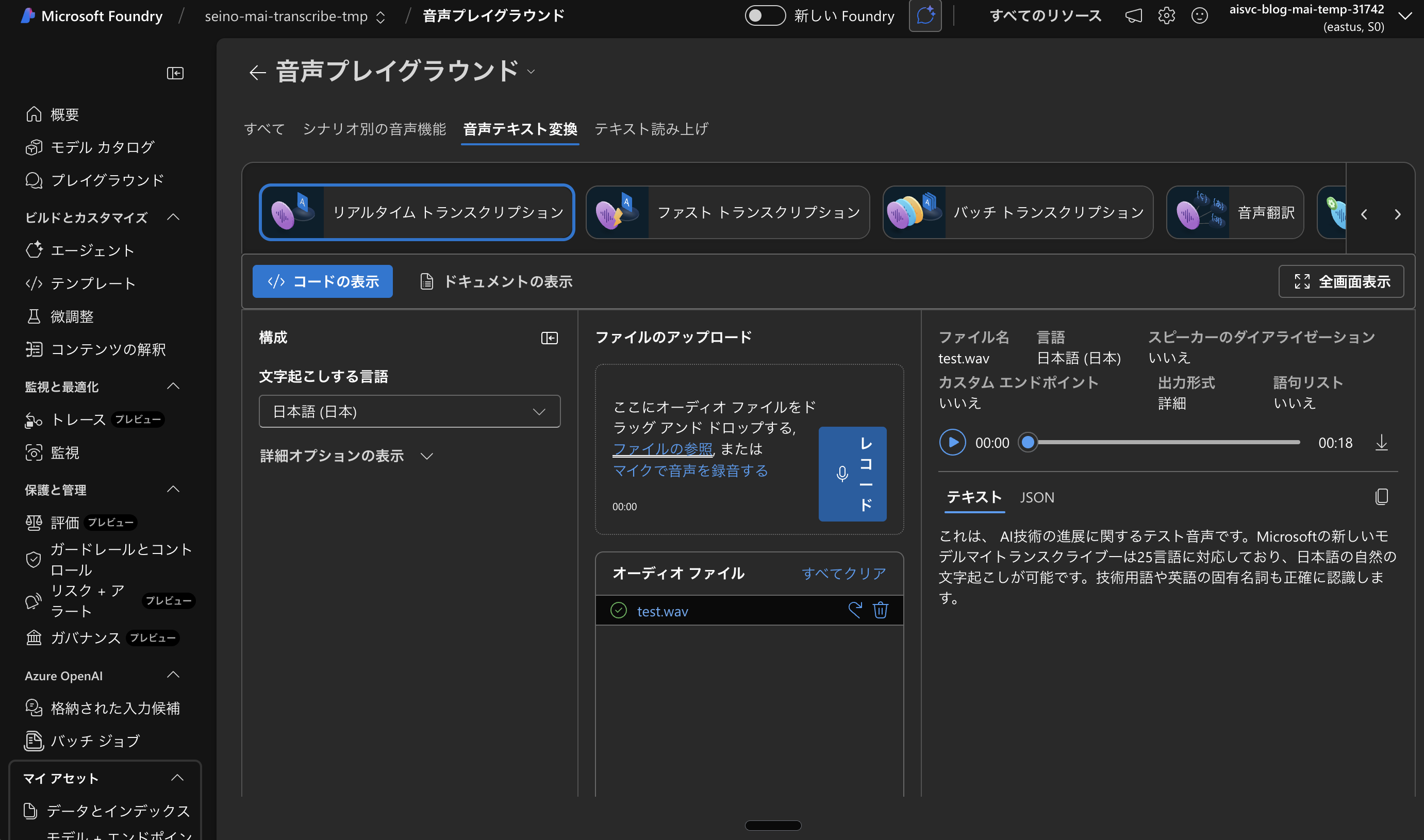
音声プレイグラウンドの「音声テキスト変換」から、リアルタイム トランスクリプションと ファスト トランスクリプションを切り替えて試しました。どちらも 同じ 1 本の wav を入力にしています。
元になった音声は、合成で作った約 18 秒の日本語です(内容は技術紹介の短文。会議の実録ではなく、検証用にキャプチャしやすいようにしたもの)。実際に聞きながら読む場合は mai-transcribe-test.wav から再生・ダウンロードできます。
リアルタイム側では、内容はほぼ合っていて句読点も自然でした。一方で、まだ世に出たばかりのモデル名 「MAI-Transcribe-1」 は、カタカナの聞き取りに寄せられて 「マイトランスクライブー」 のように崩れる場面がありました。固有名詞が学習データに乗りきっていないときによくあるパターンだと推測できます。
ファスト側は、同じ 18 秒に対して処理が 約 2 秒未満(手元では 1.86 秒程度)と非常に速く、体感では「音声長の数分の一」でテキストが返ってきました。ただしモデル名は 「MyTranscribe1」 のように英語として解釈されたり、一部の語が別の漢字に寄ったりと、ケースによってはリアルタイムのほうが安定する場面もありました。
違いを整理すると、リアルタイムは「聞き心地と句読点」寄り、ファストは「とにかく速く全文が欲しい」寄り、という使い分けになりそうです。
上記の wav をプレイグラウンドに入れて表示した画面が次のキャプチャです。書き起こし結果の見え方(UI 上のテキスト)のイメージとして参照ください。
MAI-Voice-1: Playground が無反応だったので Speech API で迂回
Foundry の Voice 系プレイグラウンドでは、手元の環境では 「試してみる」が反応しないことがあり、仕方なく Azure AI Speech の TTS REST API 側で検証しました。リリースノート上、Dragon HD ボイスは MAI-Voice-1 モデルを利用と読めるので、ja-JP-Nanami:DragonHDLatestNeural と、従来の ja-JP-NanamiNeural を比較します。
読み上げさせた文は次のとおりです(検証時と同じテキストです)。
これはMicrosoft MAI-Voice-1のテスト音声です。日本語での自然な音声合成をお試しください。
この文をそれぞれのボイスで音声化し、MP3 として書き出したものが次のリンクです。
- 従来の Neural(
ja-JP-NanamiNeural): mai-voice-nanami.mp3 - Dragon HD/MAI-Voice-1(
ja-JP-Nanami:DragonHDLatestNeural): mai-voice-nanami-dragon-hd.mp3
聞き比べると、Dragon HD のほうがイントネーションの起伏が大きく、文節の切れ方やアクセントの乗り方が自然で、棒読み感が減る印象でした。短文でも差ははっきり分かります。REST 経由の応答は ほぼ即時で、会話型 UI の裏側を想像しやすいです。
検証で使った音声ファイルは **Amazon S3(公開読み取り)**に置いてあります。Transcribe 用の wav も上記 Transcribe の節から同じく取得できます。
公開時点の価格やクォータは変わりうるので、必ず Azure AI Foundry / Speech の公式の料金・制限をあわせて確認してください。
まとめ
各社が「動画」「単価」「コードと業務」に旗を振るなかで、Microsoft は Copilot 製品に載せやすい音声・画像・合成を自前モデルで押し出してきています。実際に Foundry で触ってみると、画像は日本語看板の再現度が高く、音声認識は リアルタイムとファストのトレードオフがはっきり、音声合成は Dragon HD と従来 Neural の差が耳で分かる、という感触でした。
まだモデル名の聞き逃しや UI の不安定さは残るので、「全部が完成形」というより プロダクトに載るまでの中継地点として見るのがよさそうです。もっとスマートな試し方や、うまくハマったプロンプトを御存知の方がいれば、ぜひ X などで教えてください。
参考資料
Microsoft / MAI
- Microsoft takes on AI rivals with three new foundational models | TechCrunch
- Microsoft aims to reduce dependency on OpenAI | Neowin
- Speech サービスのリリースノート(TTS の Dragon HD と MAI-Voice-1 の記載) | Microsoft Learn
OpenAI(Sora 終了・エンタープライズ寄り)
- What to know about the Sora discontinuation | OpenAI Help Center
- The state of enterprise AI | OpenAI
AWS Nova
Anthropic
- Claude Code and new admin controls for business plans | Anthropic
- Claude Partner Network(エコシステム投資の発表) | Anthropic
マルチモーダル・音声トレンド
- Why 2026 belongs to multimodal AI | Fast Company
- Voice agents and Conversational AI: 2026 developer trends | ElevenLabs
料金・クォータ(随時更新)
- Azure AI Foundry の価格 | Microsoft Azure(公式の料金ページを確認してください)









