![[2025年12月24日号]個人的に気になったModern Data Stack情報まとめ](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4c47f61cc8c1b97c00c0efcc68eab01b/ebc4f0c0223a249eae2f9de257dedbcd/eyecatch_moderndatastack_1200_630.jpg?w=3840&fm=webp)
[2025年12月24日号]個人的に気になったModern Data Stack情報まとめ
さがらです。
Modern Data Stack関連のコンサルタントをしている私ですが、Modern Data Stack界隈は日々多くの情報が発信されております。
そんな多くの情報が発信されている中、この2週間ほどの間で私が気になったModern Data Stack関連の情報を本記事でまとめてみます。
※注意事項:記述している製品のすべての最新情報を網羅しているわけではありません。私の独断と偏見で気になった情報のみ記載しております。
Modern Data Stack全般
DEW - The Year in Review 2025
Data Engineering Weeklyの特別編として、2025年のデータ・AIエンジニアリングを定義した7つのパラダイムシフトを振り返る記事が公開されました。
2025年は、単にデータを移動させるデータエンジニアリング時代が終わり、ビジネスが求める「インテリジェンス」を構築する「コンテキストの時代」へと移行した年であると総括されています。
記事では、以下の7つの主要なトレンドが紹介されています。(AIによる要約です。)
- Agent Engineering:AIエージェントを単なるチャットボットではなく、新しい計算エンジン(Compute Engine)として捉え、複雑なワークフローを確実に実行させるためのアーキテクチャ設計が重要視されました。Model Context Protocol (MCP) の標準化や、Anthropicが提唱したContext Engineeringなどの手法が注目を集めました。
- Evals Are The New Unit Tests:「Vibe Coding(なんとなくの感覚での開発)」が終わり、Judge-LLM フレームワークなどを用いた定量的で決定論的な評価(Evaluation)が、従来のユニットテストに代わる新しい開発基準となりました。
- The Streaming-Lakehouse Merger:Lambda Architecture の終焉が宣言されました。Apache Paimon や Apache Fluss の登場により、ストリームとテーブルの境界が消失し、リアルタイムとバッチを統合した Streaming Lakehouse が現実のものとなりました。
- The Efficiency Counter-Revolution:大規模な分散クラスタ(Spark 等)から、DuckDB や Polars を活用した Single-Node による垂直スケールへの回帰が進みました。また、パフォーマンスとコスト効率を求めて Rust による再実装(Rust Rewrite)が加速しました。
- Lakehouse 2.0:データ形式の争いが落ち着き、関心は Catalog(カタログ)へと移りました。カタログは単なるテーブルリストではなく、DuckLake のようにエンタープライズの制御プレーン(Control Plane)としての役割を担うようになりました。
- The Context Supply Chain:非構造化データや関係性を扱うため、Knowledge Graphs が再評価されました。RAG(Retrieval-Augmented Generation)は、ベクトル検索だけでなく GraphRAG へと進化し、意味(Meaning)を運ぶためのパイプライン構築が不可欠となりました。
- Governance 2.0:自律的なエージェントによる事故を防ぐため、ガバナンスは単なるコンプライアンスのチェック項目から、安全装置(Safety Brake)へと進化しました。Data Contracts の導入や、リネージを活用した詳細なポリシー制御が一般化しました。
2025年を経て、データエンジニアは「Point AからPoint Bへデータを運ぶ人」から、企業の認知神経システム(enterprise’s Cognitive Nervous System)を構築する Agent Engineers や Context Curators へと、その役割を根本的に変えたと結論づけています。
What If We Don't Need the Semantic Layer?
MotherDuckのブログにて、従来のSemantic Layerの必要性に疑問を投げかけ、AIを活用した新しいアプローチを提案する記事が公開されました。
記事では、dbtやLookerなどの現代的なツールであっても、事前にメトリクスやリレーションシップを手動で定義する必要があるトップダウン型のアプローチは、分析の柔軟性を制限し、維持コストがかかると指摘しています。
その代替案として、クエリ履歴をLLMで分析し、ユーザーが実際にどのようにデータを利用しているかに基づいて意味定義を自動発見する手法が紹介されています。さらに、AnthropicやOpenAIの機能統合やMCPを活用してドメイン知識を「AI Skills」としてカプセル化することで、動的に進化するデータアクセスの仕組みが提案されています。
Data Extract/Load
Airbyte
Agent Connectorsをリリース
Airbyteが、AI agent向けに最適化されたオープンソースのPython SDK群である「Agent Connectors」をリリースしました。
以下のような特徴を持っています。今後は、読み取り専用のアクセスだけでなく、レコードの作成やワークフローの開始を可能にするWrite Operationsへの対応や、対応コネクタ数を数百規模へ拡大することも予定しているようです。
- Gong, Zendesk Support, GitHub, Salesforceなど、主要な10のSaaSに対応したPythonパッケージの提供
- AI agentがコンテキストに応じた意思決定を行うための、リアルタイムなデータへのアクセス(fetch, search, discovery)の実現
- Strongly typed(強い型付け)なインターフェースによる、LLMや開発者が解釈しやすいAPIレスポンスの提供
- PydanticAIやLangChainなどの主要なagent frameworkへの統合、およびMCP(Model Context Protocol)ベースのインターフェースへの対応
- 認証管理、Schema validation、エラーハンドリングを内包した、一貫性のあるメソッドシグネチャの提供
実際に以下のリポジトリで公開されています。
Data Warehouse/Data Lakehouse
Snowflake
Snowflake Postgresがパブリックプレビュー
SnowflakeがSnowflake Postgresをパブリックプレビューとしてリリースしました。
Snowflake Postgresは、Snowflakeプラットフォーム上でPostgresインスタンスを直接作成・管理・利用できる機能です。Snowflakeが管理する専用のVirtual Machine上でPostgresデータベースサーバーが稼働し、既存のPostgresクライアントを使用して直接接続することができます。
Workspace内でNotebookを開発・実行できる機能がパブリックプレビュー
SnowflakeのWorkspace内で、Notebookの開発・実行できる機能がパブリックプレビューとなりました。
Container Runtimeがベースなのでコンピュートの単価は安く、外部パッケージも簡単にインストールできますし、WorkspaceなのでGitでの管理も簡単に可能というメリットがあります。
私も試してみて、以下のように記事にまとめております。
Write Once, Read ManyのBackup機能が一般提供
Write Once, Read ManyのBackup機能が一般提供となりました。プレビュー時は「Snapshot」と呼ばれていた機能です。
私もプレビュー時に一度試していて、ブログにしています。※すべてのSQLコマンド・ビュー・権限で、BACKUPという用語を用いた名称に変更されていますので、ご注意ください。
terraform-provider-snowflakeのロードマップが更新
terraform-provider-snowflakeのロードマップが更新されました。
Snowflakeで利用できるがTerraformではまだ定義できないリソースとのギャップを埋めていくことなど、言及があります。
MotherDuck/DuckDB
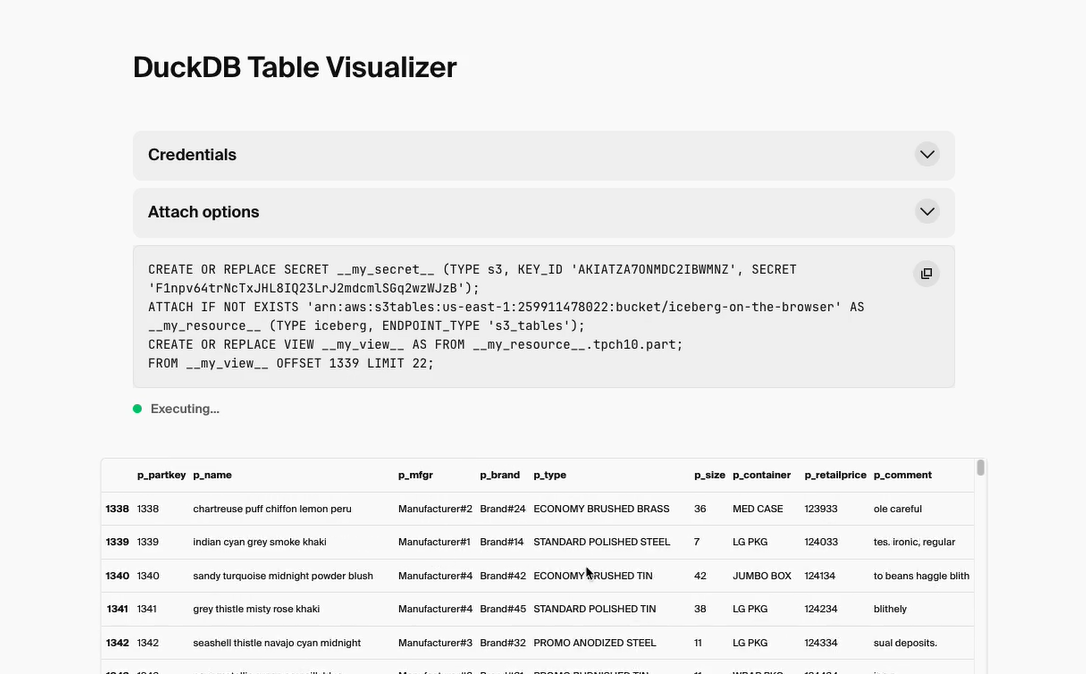
DuckDB-Iceberg拡張機能がDuckDB-Wasmでサポート
DuckDB-Iceberg拡張機能がDuckDB-Wasmでサポートされ、Iceberg RESTカタログの読み取りと編集が可能になりました。これによりユーザーは、コンピューティングノードのインストールや管理をすることなく、ブラウザからIcebergデータにアクセスできるようになりました。
下記の記事では、ブラウザからIcebergテーブルのデータをクエリするデモ動画も公開されています。併せてご覧ください。
Data Transform
dbt
dbt-core v1.11が正式リリース
dbt-coreの最新バージョンであるv1.11が正式にリリースされました。アップグレードガイドも併せて公開されています。機能面で言えば、UDFのサポートなどが含まれます。
関連して、2025年12月の最新情報をまとめた公式ブログも公開されています。
Business Intelligence
Omni
Omniの2025年のプロダクトハイライト
Omniが2025年における主要な製品アップデートをまとめた振り返り記事を公開しました。
AIアシスタントであるBlobbyを中心としたAI機能の進化に加え、BIの枠を超えた分析エクスペリエンスや、dbtとの強力な連携を含む開発者向け機能など、データから洞察を得るまでのスピードを加速させる多数の機能が導入されています。
以下のような新機能や改善がリリースされています。(AIによる要約です。)
AI機能の拡張
- AIアシスタントBlobbyによるTopic内での自律的な分析
- 自然言語でデータ探索が可能なAI chat
- ダッシュボード上の数値を要約・解釈するAI summary visualization
- MCP Serverの提供によるCursor、Claude Code、ChatGPTとの連携
- ダッシュボードの内容について質問できるDashboard AI
- 複雑なタスクを実行するagentic harness(Plan, Think, Act)の実装
分析および可視化機能
- ライブデータ上でExcelと同様の構文やショートカットが利用できるspreadsheet機能
- 高度な集計を容易にするLOD (level of detail) fields
- tabbed dashboardsおよび柔軟なレイアウトを可能にするcontainers
- boxplot、heatmaps、trellis chartsなどの新しいvisualizations
- 地図の不透明度調整やカスタムshapefilesへの対応を含むmapsの強化
デベロッパーエクスペリエンス
- dbtとの双方向の連携
- テナントごとにカスタムフィールドを定義できるshared model extensions
- Gitブランチを活用したコンテンツのバージョン管理
- プログラムからほぼ全ての操作を可能にするAPI libraryの拡充
パフォーマンスと基盤
- 最大50k行のデータをスムーズに描画する新しい可視化レンダリングエンジン
- Snowflake、Databricksの各種メトリクスビューとの連携
- ベンダーニュートラルな標準を目指すOpen Semantic Interchange (OSI)への取り組み
Lightdash
Lightdashの2025年の総括記事
Lightdashが2025年の活動を振り返る「Zapped 2025: Year in review」を公開しました。2024年のSeries A資金調達を経て、2025年はさらなる成長を遂げ、世界32カ国で58,153名のユーザーが利用するプラットフォームへと進化しています。
記事によると、技術面ではLightdash AIの導入やSOC2の準拠、さらにClickHouseとのパートナーシップ締結などエンタープライズ向けの機能拡充とセキュリティ強化が進んでおり、東京でのMeetup開催を含む世界10カ国でのイベント実施などコミュニティとの接点も大幅に増加しているとのことです。
2025年には、主に以下のような機能追加やアップデートが行われました。(AIによる要約です。)
- Lightdash AI agentによる自然言語でのデータ探索
- SOC2コンプライアンスの認定取得
- Gauge chartsやMap chartsといった新しいチャートタイプの追加
- Chart UIの改善
- ClickHouseとの新規パートナーシップ締結
- Parameters機能の導入
- Dark modeのサポート
- Data developers向けの管理・計測機能の強化
Data Catalog
OpenMetadata
最新バージョンであるv1.11がリリース
OpenMetadata及びそのSaaS版であるCollateについて、最新バージョンであるv1.11がリリースされました。
OpenMetadataではPython SDKを使用して、ETLパイプライン内に直接データテストを組み込むことができる「Data Quality as Code」、CollateではSlack連携もできる対話型インターフェースの「AskCollate」やCollateのUIから直接SQLを実行できる「Collate SQL Studio」が新機能として追加されています。







