![[2026年2月18日号]個人的に気になったModern Data Stack情報まとめ](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4c47f61cc8c1b97c00c0efcc68eab01b/ebc4f0c0223a249eae2f9de257dedbcd/eyecatch_moderndatastack_1200_630.jpg?w=3840&fm=webp)
[2026年2月18日号]個人的に気になったModern Data Stack情報まとめ
さがらです。
Modern Data Stack関連のコンサルタントをしている私ですが、Modern Data Stack界隈は日々多くの情報が発信されております。
そんな多くの情報が発信されている中、この3週間ほどの間で私が気になったModern Data Stack関連の情報を本記事でまとめてみます。
※注意事項:記述している製品のすべての最新情報を網羅しているわけではありません。私の独断と偏見で気になった情報のみ記載しております。
Modern Data Stack全般
Semantic Layerに関する各社の意見
Semantic Layerの再流行や、新たな概念であるContext Graphについて、Preset社のブログ・Atlan社のCEOのブログ・MotherDuck社のブログから、考察記事が公開されました。
- Preset社のMaxime Beauchemin氏が、AIとGovernanceのためにSemantic Layerが「Menu」として復活した背景と、SupersetがSnowflakeやdbtなどあらゆるSemantic Layerに対応する戦略を発表した記事
- Data Warehouseを「Kitchen」、BIを「Dining Room」に例え、AI Agentには構造化されたSemantic Layerが不可欠であるとし、特定のベンダーに依存しない柔軟な統合を進める姿勢を示しています。
- Atlan社のPrukalpa氏による、Context Graphの流行がかつてのSemantic Layerの失敗と酷似していると警鐘を鳴らし、ベンダーロックインやデータの断片化を防ぐ重要性を説いた記事
- かつてSemantic Layerが普及しきれなかった理由として、BIベンダーのインセンティブ不一致(囲い込みたい欲求)、既存BI資産からの移行コストの高さ、そして「Execution Path(日々の業務フロー)」に組み込まれていなかったことを挙げています。Fivetranやdbtが成功したのは、それらが日々の業務そのものだったからだと分析しています。
- AI Agentが正しく機能するには「Execution Path」に組み込まれたContextが必要であり、特定のVertical Agentに閉じないOpenでPortableな設計が不可欠であると結論付けています。
- MotherDuck社のJacob Matson氏による、BIRDベンチマークを用いたLLMのText-to-SQL性能評価に関する考察記事
- 記事では、セマンティックレイヤーを介さずとも、適切なデータモデリングがなされていればテーブル名と列名を見ることで、最新のLLMが高い精度でクエリを生成できることを実験データと共に示しています。
Data Engineering Study #33が開催
私もアドバイザーを務めている、Data Engineering Studyの最新回が2026/1/30に開催されました。「LLMを活用したデータ民主化の進め方」という主題で、3社の方に登壇いただき、それぞれのLLM活用についてお話頂きました。
次回#34は、最新トレンドから学ぶ「BIツールの進化と実践」 ということで、昨今のBIツールのトレンドや事例を各社の方にお話しいただきます!ぜひご参加ください!
Data Extract/Load
Fivetran
CensusがFivetranに統合され、料金プランも変更
2026年2月1日に、CensusがFivetranに統合され「Activations」という機能名で提供されました。
既存のCensusアカウントをFivetranアカウントに統合する手順は、以下のブログが参考になると思います。
また、Activations向けにConsumption Tableも更新されています。Activation MARの定義ですが、「1 か月間に、Activation Syncが宛先のシステムに新規または更新を書き込んだユニーク行数」となりますので、例としてSalesforce宛に複数Syncを設定している場合は、そのSyncごとにMARと利用費が集計される形となります。
MAR Thresholdが小数点になっていますが、Standardの場合、「10,000 行/月 → USD 199.25/月」「100,000 行/月 → USD 333.99/月」という価格感となります。
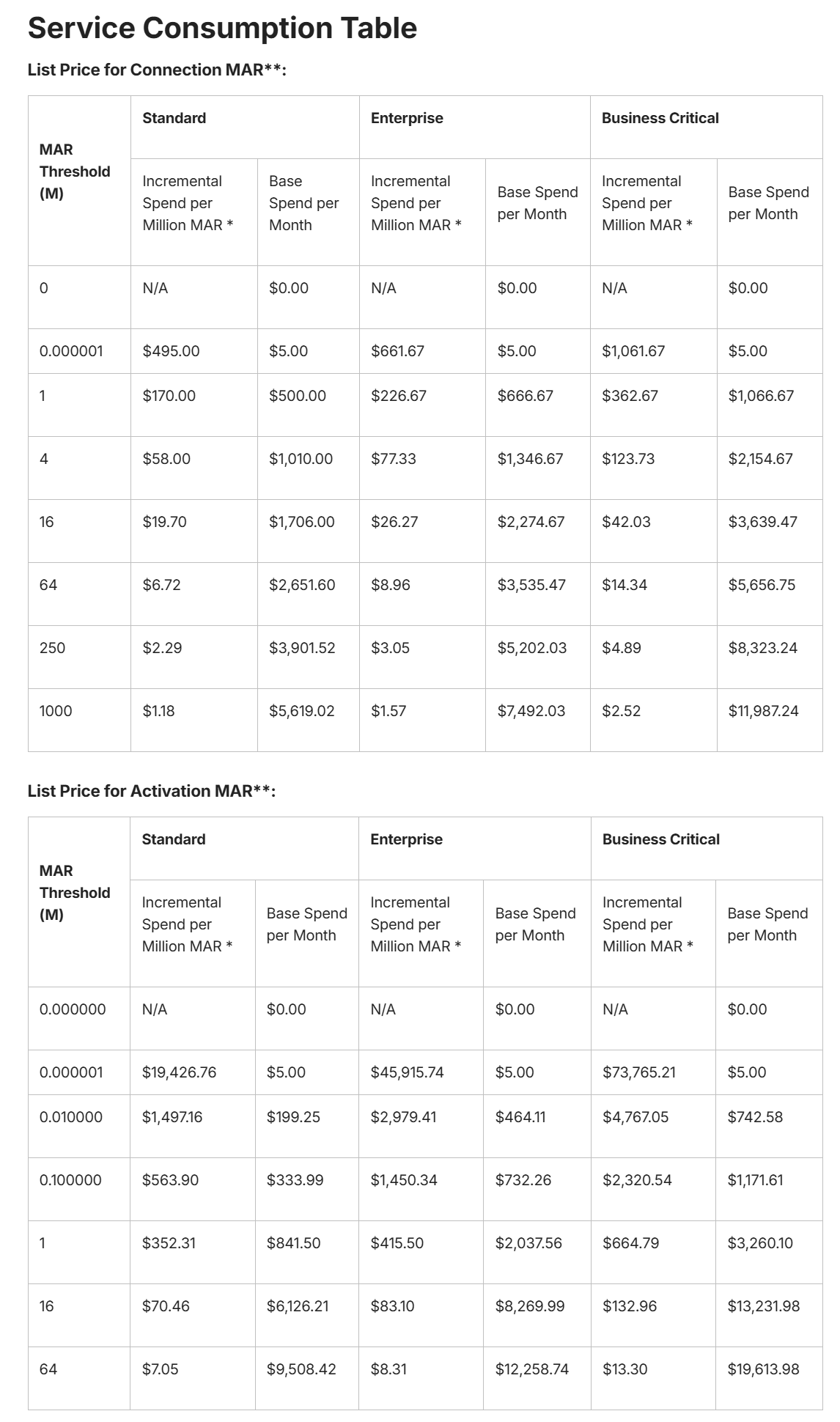
また、今回のCensusのFivetran統合に伴い、Census Storeの機能が終了するとCensusのリリースノートに言及がありました。これらの機能をご利用の場合は、ご注意ください。
Data Warehouse/Data Lakehouse
Snowflake
SnowflakeのコーディングエージェントとしてCortex Code CLIが一般提供&SnowsightでのCortex Codeがパブリックプレビュー
Snowflakeの新機能として、コーディングエージェント機能である「Cortex Code」がリリースされました。現時点では、CLI版のCortex Code CLIが一般提供、SnowsightでのCortex Codeがパブリックプレビューとなっています。
弊社でも検証してブログを書いています。Cortex Code CLIはClaude Codeのような操作感で、別ファイルのガイドラインに沿ったSQL生成も可能ですので、ぜひご活用ください。
Semantic View Autopilotが一般提供
SnowflakeでSemantic Layerの役割を担う、Semantic View Autopilotが一般提供となりました。(リリースノートに記載はないのですが、以下のXの投稿や、公式Docはすでに公開されています。)
Semantic View Autopilotは、物理テーブルを抽象化してビジネスに即した論理レイヤーを定義するSemantic Viewを、AIの支援を受けて自動生成する機能です。既存のTableauファイルからSemantic Viewの生成、Query Historyや提供されたSQLクエリからのSemantic View生成、などに対応しています。
SnowflakeがTensorStaxを買収
Snowflakeが、Data Engineering向けのAutonomous AIを開発するTensorStaxの買収を発表しました。
TensorStaxは、Airflowやdbtなどが混在する複雑な環境下において、Pipelinesの構築や検証、変更への適応を自律的に行うシステムです。
この買収により、SnowflakeはAgentic AIを用いてIngestionやTransformationのプロセスを自動化し、データエンジニアの負荷軽減を目指すとしています。なお、TensorStaxの技術は既にSnowflakeのCortex Codeに統合されているとのことです。
Cortex Search Service用にPDFをパースしてチャンキングするdbtのIncremental model
私の記事で恐縮ですが、Cortex Search Service用にPDFをパースしてチャンキングするdbtのIncremental modelを考えて、ブログを投稿しております。
AI_PARSE_DOCUMENT関数で毎度全てのデータをフルスキャンするとコストがかかってしまうため、dbtのIncremental modelでディレクトリテーブルに対して更新されたファイルのレコードのみ検知して処理するように実装しています。
BigQuery
BigQueryでのConversational Analytics機能がプレビュー
BigQueryで利用できるConversational Analytics機能がプレビューとなりました。
実際の使用感としては以下の記事が参考になります。プロンプトや検証済みクエリを追加することで、回答精度を上げていく仕様となっています。
Databricks
Lakebaseが一般提供
Databricksが、Serverless PostgresサービスであるDatabricks LakebaseのGA(一般提供開始)を発表しました。
従来のデータベースにおけるComputeとStorageの結合によるリソース競合や管理コストの課題を解決するため、アーキテクチャを分離し、インフラ管理不要で利用できる点が特徴です。現在はAWSでGA、Azureではベータ版として提供されています。
ClickHouse
SmartNews社とLINEヤフー社の事例が公開
ClickHouse社のブログにて、SmartNews社とLINEヤフー社の事例が公開されていました。日本企業でもClickHouseの導入が広がってきている印象です。
Onehouse
Onehouse LakeBaseを発表
Onehouseが、AI Agentsなどの低レイテンシなワークロード向けに、Lakehouse上のデータを直接高速にサービングする新製品「Onehouse LakeBase」を発表しました。
従来のApache SparkやTrinoといったLakehouseエンジンは大規模なスキャンやスループットに最適化されており、AI Agentsが推論ループの中で頻繁に行うPoint lookupやHigh concurrencyなクエリ処理には不向きでした。また、これを回避するためにデータをWarehouseや専用のOperational Databaseにコピーする手法は、パイプラインの複雑化やデータのサイロ化を招いていました。
LakeBaseは、Apache HudiやApache Icebergといったオープンなテーブルフォーマット上に直接構築されたServing layerです。リンク先の記事によると、Postgres wire protocol互換のエンドポイントを提供し、既存のBIツールやAI AgentsのRuntimeから容易に接続可能とのことです。これにより、データを移動させることなく、Lakehouseを単なる分析基盤から「AI Agentsのための高速なデータベース」へと拡張することが可能になります。
Data Transform
dbt
dbt-agent-skillsが公開
dbt Labs社のGitHubアカウントにて、dbtに特化したAgent Skillsであるdbt-agent-skillsが公開されました。
どういったものか概要を知るうえでは、myshmehさんが投稿している以下の記事が参考になります。
Business Intelligence
Looker
新機能のリリース
2026年2月17日のリリースノートで、Conversational Analyticsのiframe埋め込み、BigQueryを利用している場合にMerging Results機能がBigQueryでクエリを実行するように仕様変更(今までMerging ResultsはLookerインスタンス内のメモリを用いた処理で大規模データが処理できなかった)、などのアップデートがありました。
Tableau
Tableau 2026.1の情報が公開
coming-soonのページが更新され、2026.1の情報が公開されていました。
個人的には、「Tableau Prep: In-Database Processing - Snowflake (Beta)」と「Tableau Prep: Hyper-as-a-Service」が気になりました。
Hex
Context Studioを発表
Hexが、AIエージェントの動作をワークスペース全体で「観察・評価・改善」するための新機能「Context Studio」を発表しました。
主な機能と活用方法は以下の通りです。
- Observe agent behavior
- ワークスペース全体でエージェントがどのように使用されているかをレビューできます。ユーザーがどのような質問をしているか、どのTopicsが頻繁に現れるか、またエージェントがWarningsを発したり不確実性を表明したりしている箇所を特定します。
- Identify opportunities for improvement
- TopicsやWarningsを活用して、エージェントの回答精度を向上させるために追加のContextやGuidanceが必要なポイントをピンポイントで特定します。
- Improve context safely
- エージェントが依拠するGuidanceやData definitions(Unstructured guides、Endorsed assets、Semantic modelsなど)を更新できます。変更内容は、ProductionにPublishする前にコントロールされた環境でテストすることが可能です。
Omni
dbt Semantic Layerとの統合機能を発表
dbt Semantic Layerで定義されたDimensionやMetricsなどの情報を、Omniに統合できる機能が発表されました。
Superset
Apache Supersetの6.0がリリース
Apache Superset 6.0がリリースされました。デザインシステムの刷新やアーキテクチャの大幅な変更を含むアップデートとなっています。
Data Quality・Data Observability
Soda
最新バージョンであるSoda 4.0がリリース
Sodaが最新バージョンであるSoda 4.0をリリースしました。
本バージョンでは「Self-driving data quality platform」を掲げ、Data ContractsをベースにAI、エンジニア、ビジネス部門が連携してデータ品質管理を自動化する機能が強化されています。
以下のような新機能がリリースされています。
- スキーマと品質ルールを統合管理するData Contracts Engineの導入
- AIが自然言語からData Contractsを自動生成・支援するContract Copilot
- 異常検知の精度を高めるSmarter Anomaly TreatmentとRecord-level Anomaly Detection
- スキャン結果やfailed rowsをユーザーのDWHに保存して分析できるDiagnostics Warehouse
- Data Contractsの変更管理を行うData Contract Requests and Approvals







