
MotherDuck(DuckDB)のMCPサーバーを導入して分析させてみた with Claude Code
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
MCPとは
MCP(Model Context Protocol)はアプリケーションがLLMにコンテキストを提供する方法を 標準化するオープンプロトコルです。 Anthropicが2024/11に公開しました。 USB-Cのように、異なるデータソースやツールをAIモデルに接続するための標準的な方法を提供します。
MCPの構成概要を以下引用して記載します。
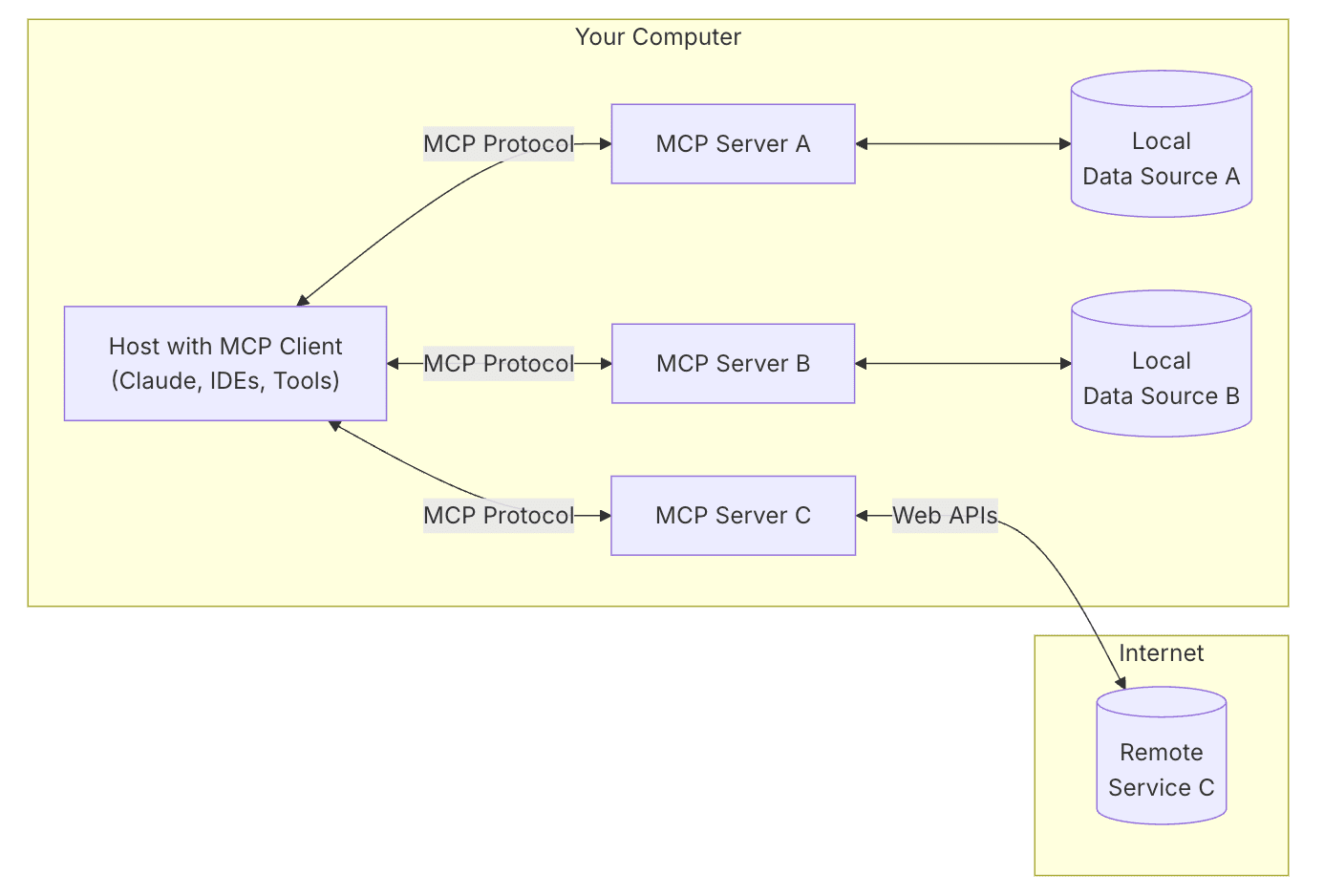
画像引用: Introduction - Model Context Protocol
| 役割 | 説明 |
|---|---|
| MCPクライアント | ClaudeやIDE、ツールに組み込まれます。 MCPプロトコルを通じて複数のMCPサーバーと接続します。 |
| MCPサーバー | MCPクライアントからのリクエストを受けて、 ローカルデータソースやリモートサービスへアクセスする軽量サーバーです。 |
今回やること
本ブログでは MotherDuckが公式に提供している mcp-server-motherduck を導入 してみます。 このMCPサーバーにより、MotherDuckおよびローカルのDuckDBと統合できます。 SQLを意識しないデータ分析を実現できそうですね。
なお、導入にあたってのMCPクライアントは Claude Code を使いますが、 他のツール(Claude Desktop, Clineなど)でも同様に実装できます。 Claude Code については以下ブログを参照ください。
改めて、今回導入する構成がこちら。
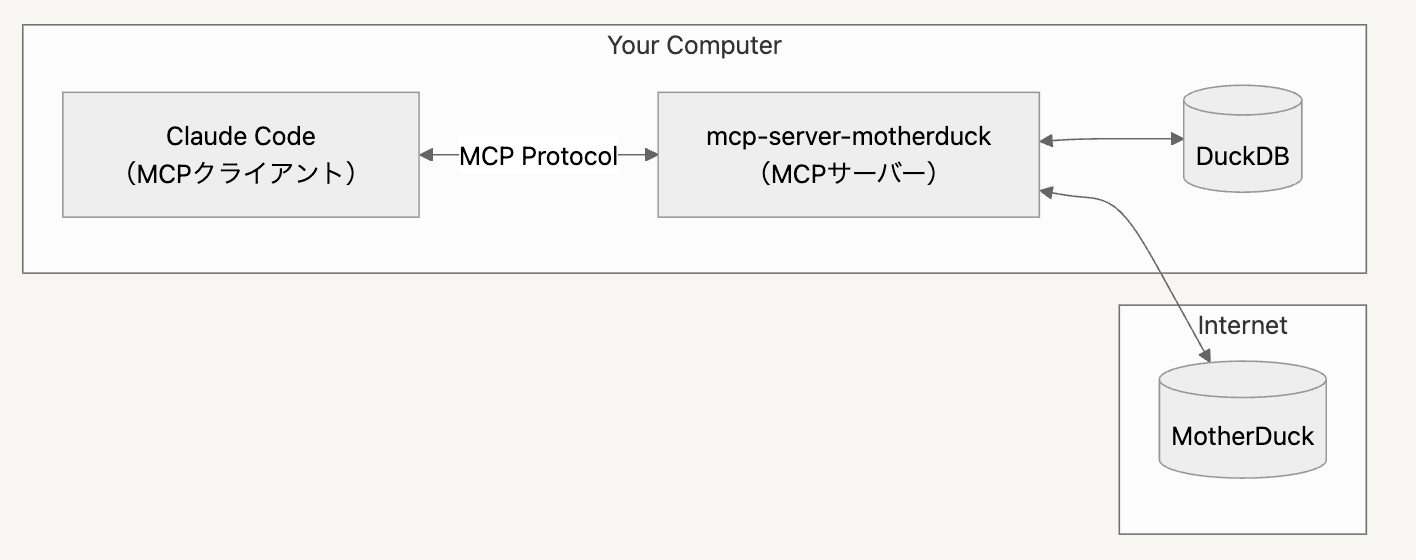
早速やっていきましょう。
MCPサーバーを導入する
mcp-server-motherduck の Getting Started どおりに進めます。
- MotherDuckアクセストークンを発行
- uvをインストール
- MCPクライアントにMCPサーバー接続を追加
MotherDuckアクセストークンを発行
MotherDuckアカウントが無ければ 事前に作成しておきます。 今回はFree Planのアカウントで試していきます。
MotherDuckコンソールにて [Settings > INTEGRATIONS > Access Tokens] 画面に移動します。 [Create token] を選択します。
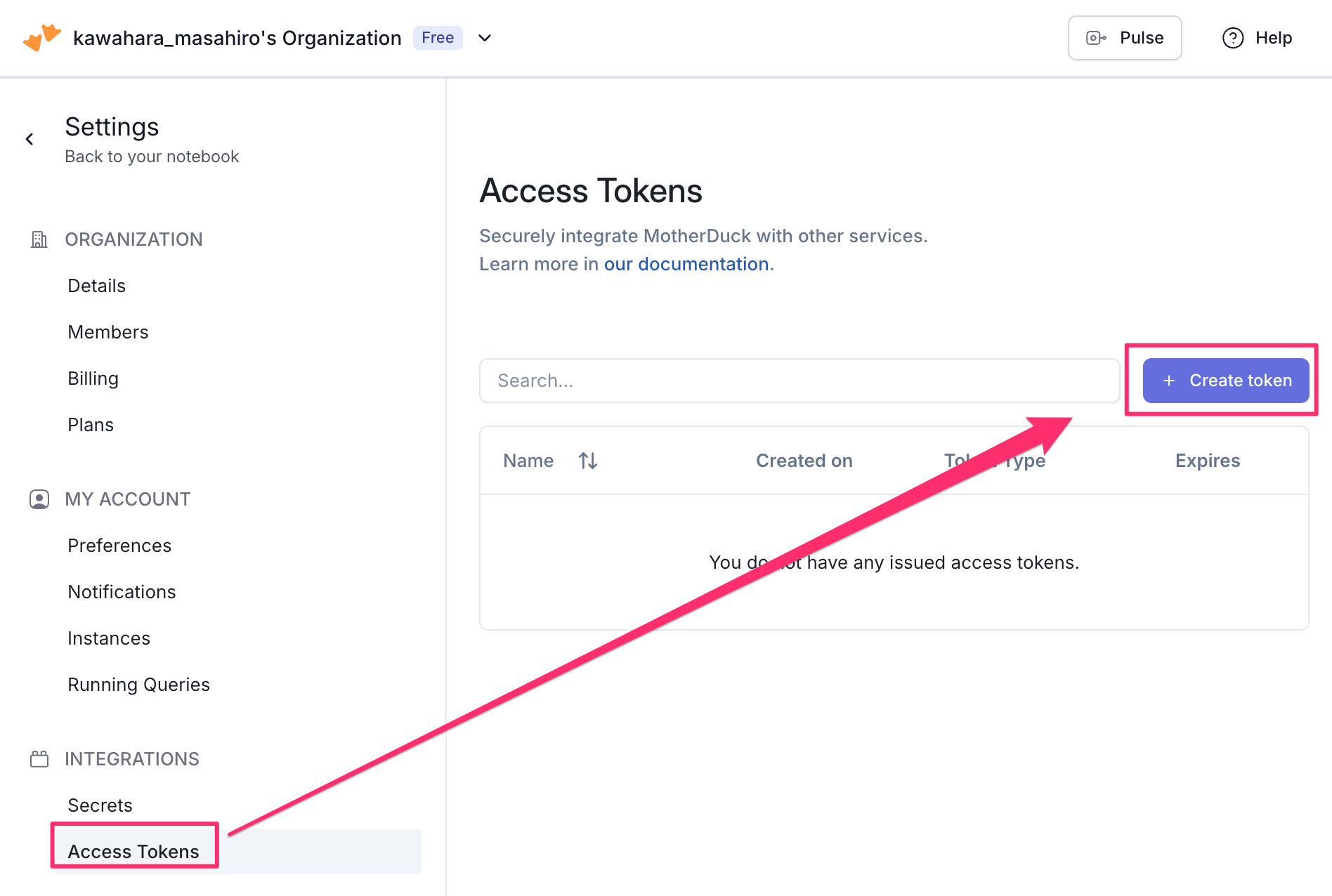
[Settings > INTEGRATIONS > Access Token] → [Create token]
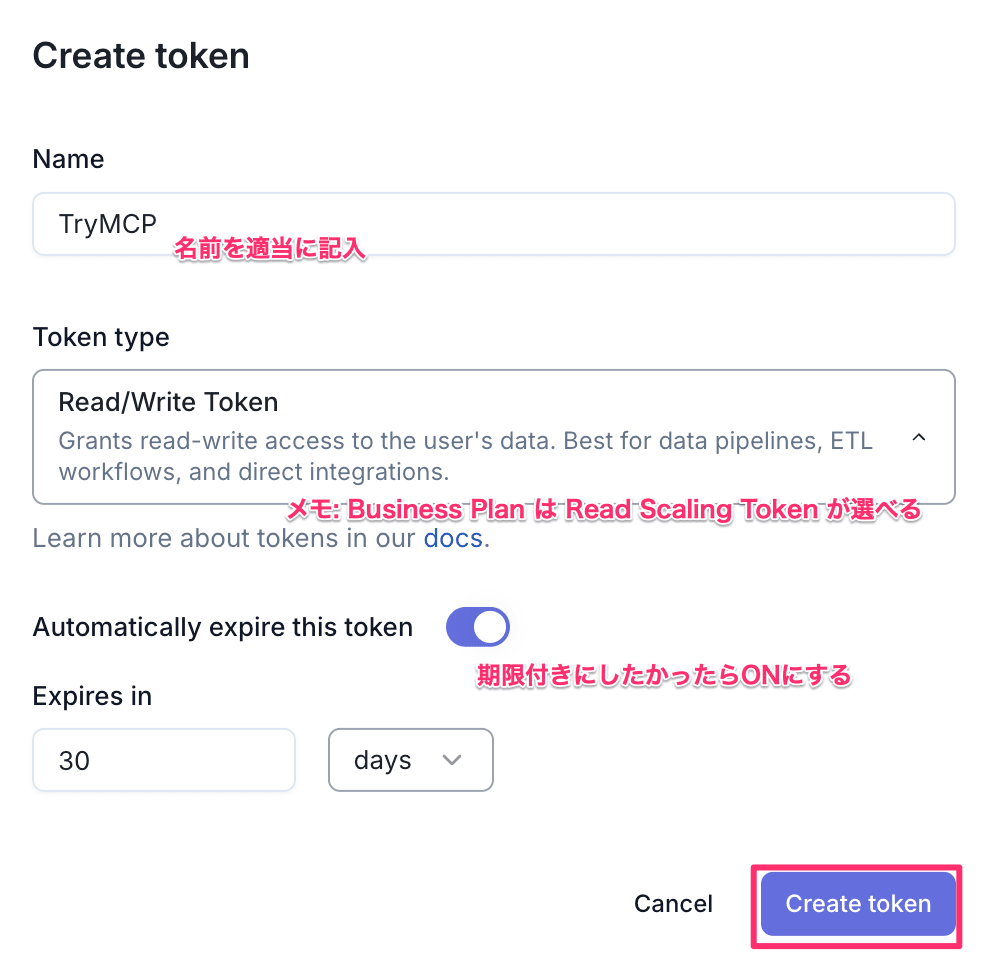
[Create token] を選択してトークンを発行
発行されたアクセストークンを手元にメモしておきます。
uvをインストール
Pythonパッケージマネージャーである uv が必要です。 自環境は macOS なので以下コマンドで導入しました。
brew install uv
which uv
# /opt/homebrew/bin/uv
uv --version
# uv 0.6.9 (Homebrew 2025-03-20)
MCPクライアントにMCPサーバー接続を追加
Claude Code におけるMCPサーバー追加の方法はチュートリアルドキュメントに記載があります。 Getting Started に JSONファイルで設定例が記載されているので、 それに併せて接続を追加します。
以下コマンドでMCPサーバーを追加します。 <YOUR_MOTHERDUCK_TOKEN_HERE> 部分を適宜置き換えてください。
mcp_json=$(cat <<EOF
{
"command": "uvx",
"args": [
"mcp-server-motherduck",
"--db-path",
"md:",
"--motherduck-token",
"<YOUR_MOTHERDUCK_TOKEN_HERE>"
]
}
EOF
)
claude mcp add-json mcp-server-motherduck "${mcp_json}"
# Added MCP server mcp-server-motherduck to local config
これで導入は完了です。
いろいろ試してみる
MCPサーバーの動作確認
Claude Code (執筆時点のバージョン: 0.2.56 ) を起動します。
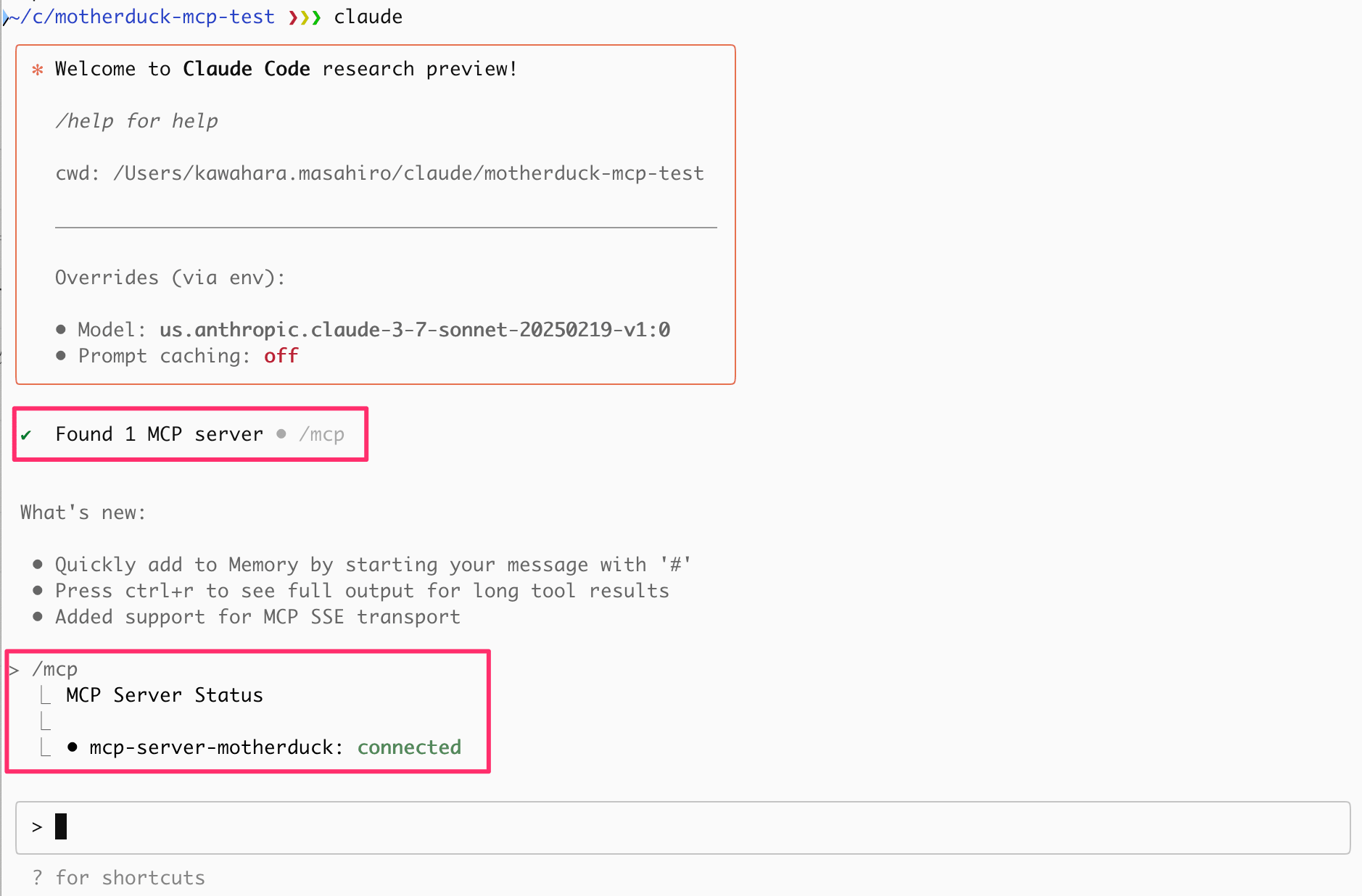
起動後、 /mcp を実行してMCPサーバーを確認
試しに MotherDuck クラウド上にあるデータベースやテーブルをリストしてもらいます。
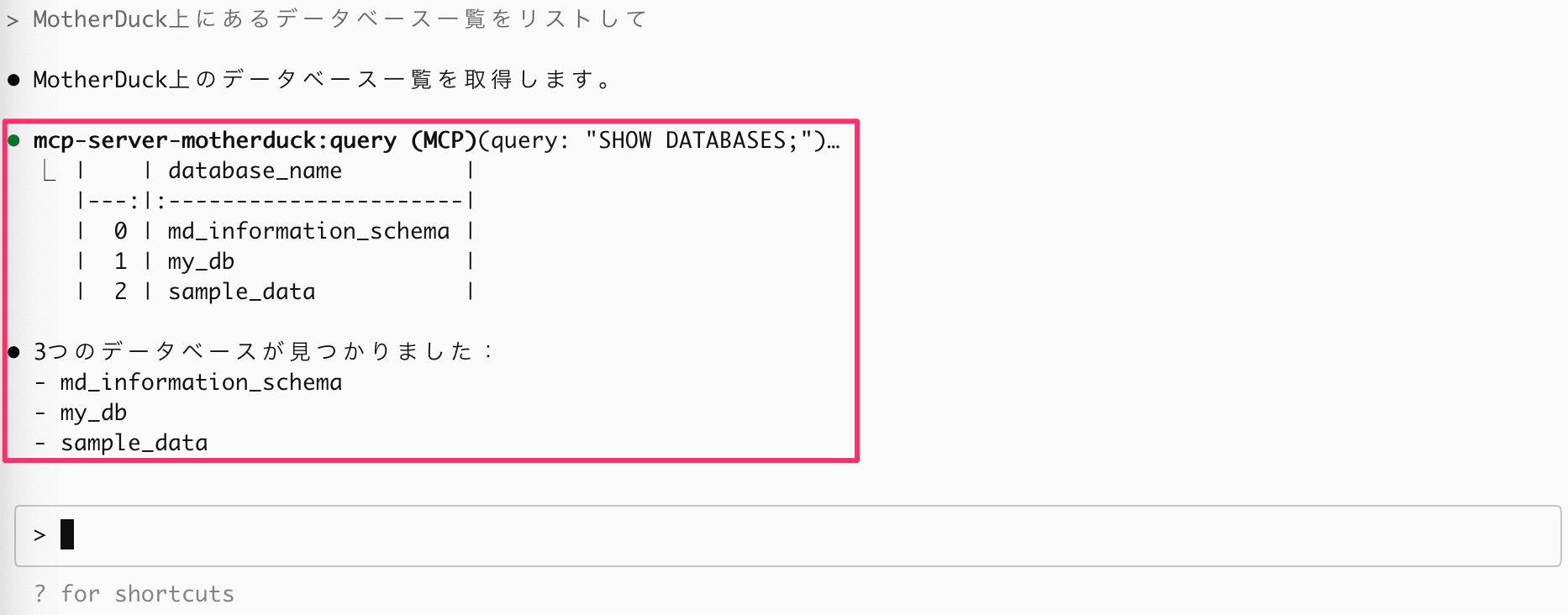
データベース一覧を持ってきてくれた
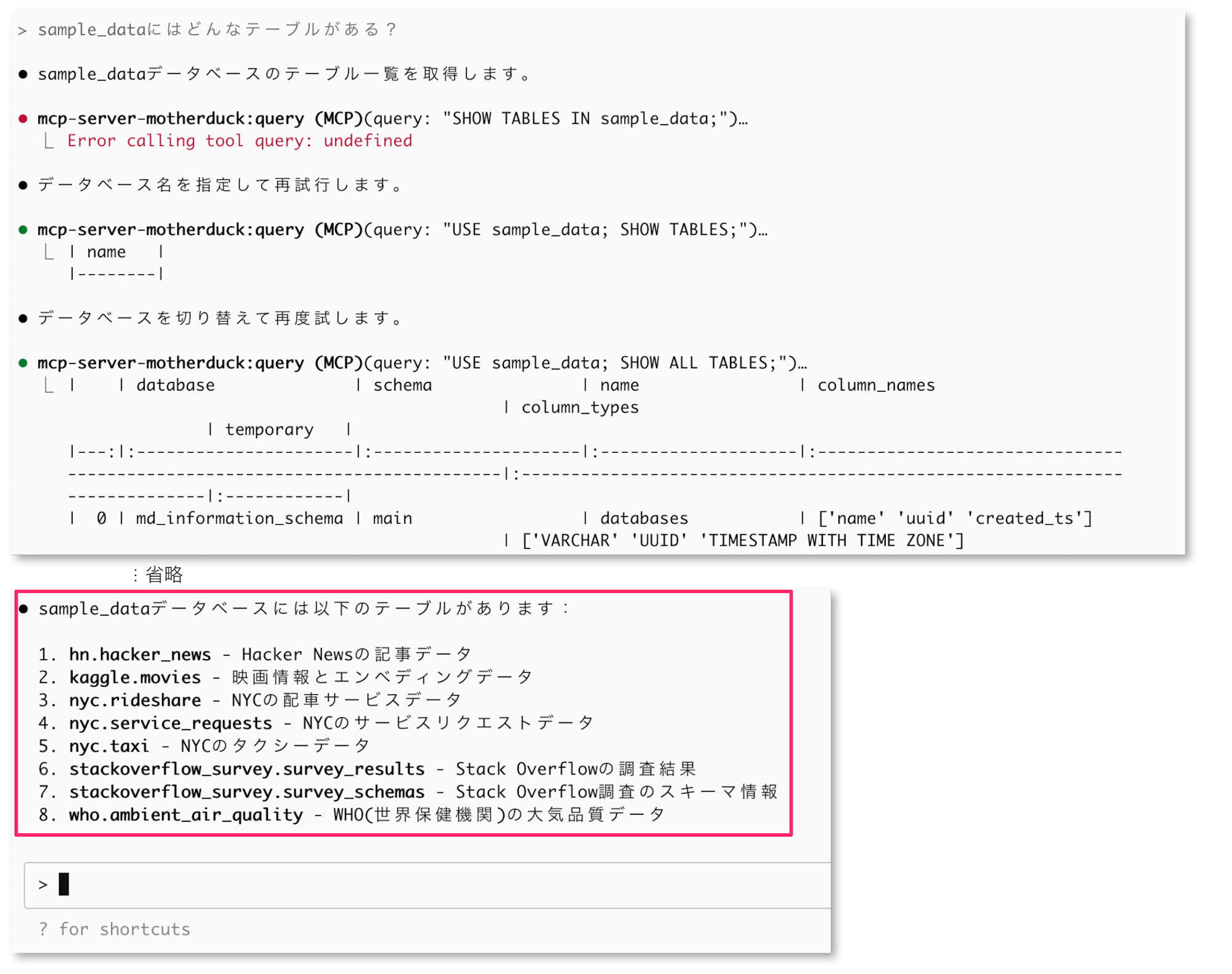
3回目のトライでテーブル一覧を持ってきてくれた
ローカルCSVを分析
生成AIに作らせたサンプルCSVをローカルに置きます。
head sales.csv
# id,日付,商品名,カテゴリ,価格,数量,顧客ID,顧客年齢,顧客性別,地域
# 1,2023-01-03,ノートパソコン,電子機器,85000,1,C001,34,男性,東京
# 2,2023-01-04,コーヒーメーカー,家電,12000,2,C002,45,女性,大阪
# 3,2023-01-05,ワイヤレスイヤホン,電子機器,15000,3,C003,28,男性,福岡
# 4,2023-01-06,スマートウォッチ,電子機器,25000,1,C004,52,女性,北海道
# 5,2023-01-07,キーボード,電子機器,8000,2,C005,31,男性,東京
# 6,2023-01-08,マウス,電子機器,5000,4,C006,29,女性,京都
# 7,2023-01-09,ブレンダー,家電,7500,1,C007,41,女性,愛知
# 8,2023-01-10,スピーカー,電子機器,18000,2,C002,45,女性,大阪
# 9,2023-01-11,タブレット,電子機器,45000,1,C008,37,男性,沖縄
wc -l sales.csv
# 101 sales.csv
このCSVに対して分析を指示してみました。
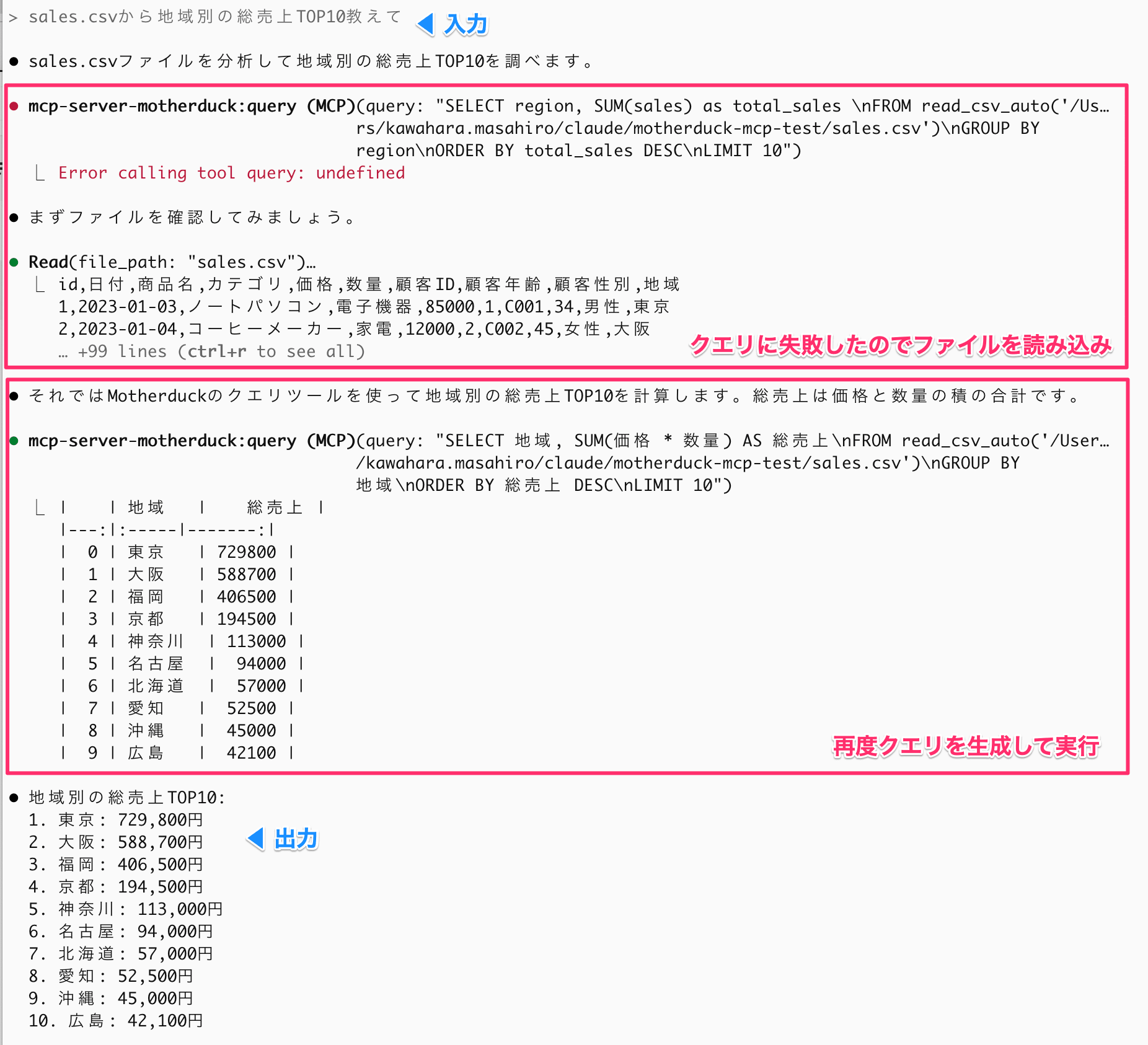
sales.csvから地域別の総売上を求めてもらう
良い感じですね。
ちなみに Claude Code では -p(--print) オプションで 非インタラクティブな実行も可能です。 以下例です。
claude --allowedTools="mcp__mcp-server-motherduck__query" \
-p "sales.csvから地域別の総売 上TOP10を求めて。結果はMarkdownテーブルだけ返して"
# | 地域 | 総売上 |
# |:-----|-------:|
# | 東京 | 729800 |
# | 大阪 | 588700 |
# | 福岡 | 406500 |
# | 京都 | 194500 |
# | 神奈川 | 113000 |
# | 名古屋 | 94000 |
# | 北海道 | 57000 |
# | 愛知 | 52500 |
# | 沖縄 | 45000 |
# | 広島 | 42100 |
※ 非インタラクティブな実行では allowedTools パラメータで 明示的に実行できるコマンドを指定する必要があります。 MCPサーバーの機能を使うには mcp__(サーバー名)__(ツール名) を許可してあげます(参考にしたIssue)。
ローカルParquetを分析
次にParquetファイルの分析を試してみます。 クラスメソッドメンバーズ提供のCUR(Cost and Usage Reports)のParquetファイルを ローカルに落としました。 そのCURからAWSコスト分析をしてもらいます。
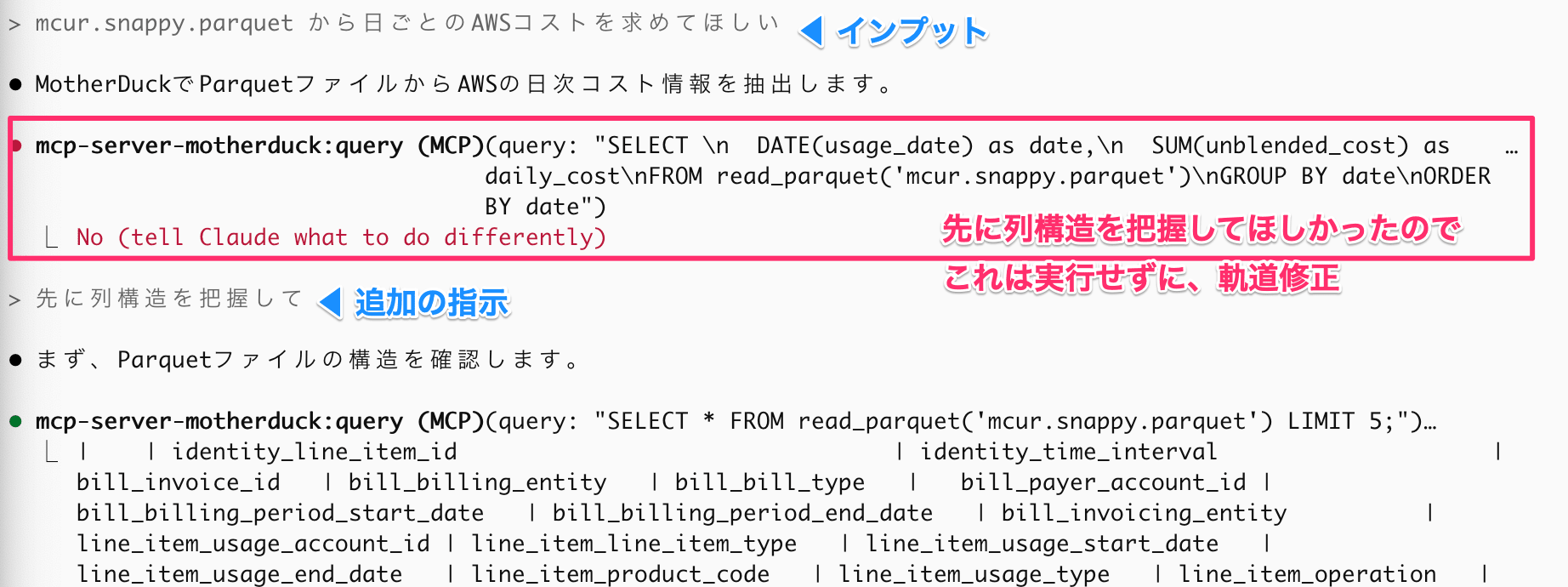
やりとり#1(分析してほしい内容を依頼)

やりとり#2(試行が続きます)
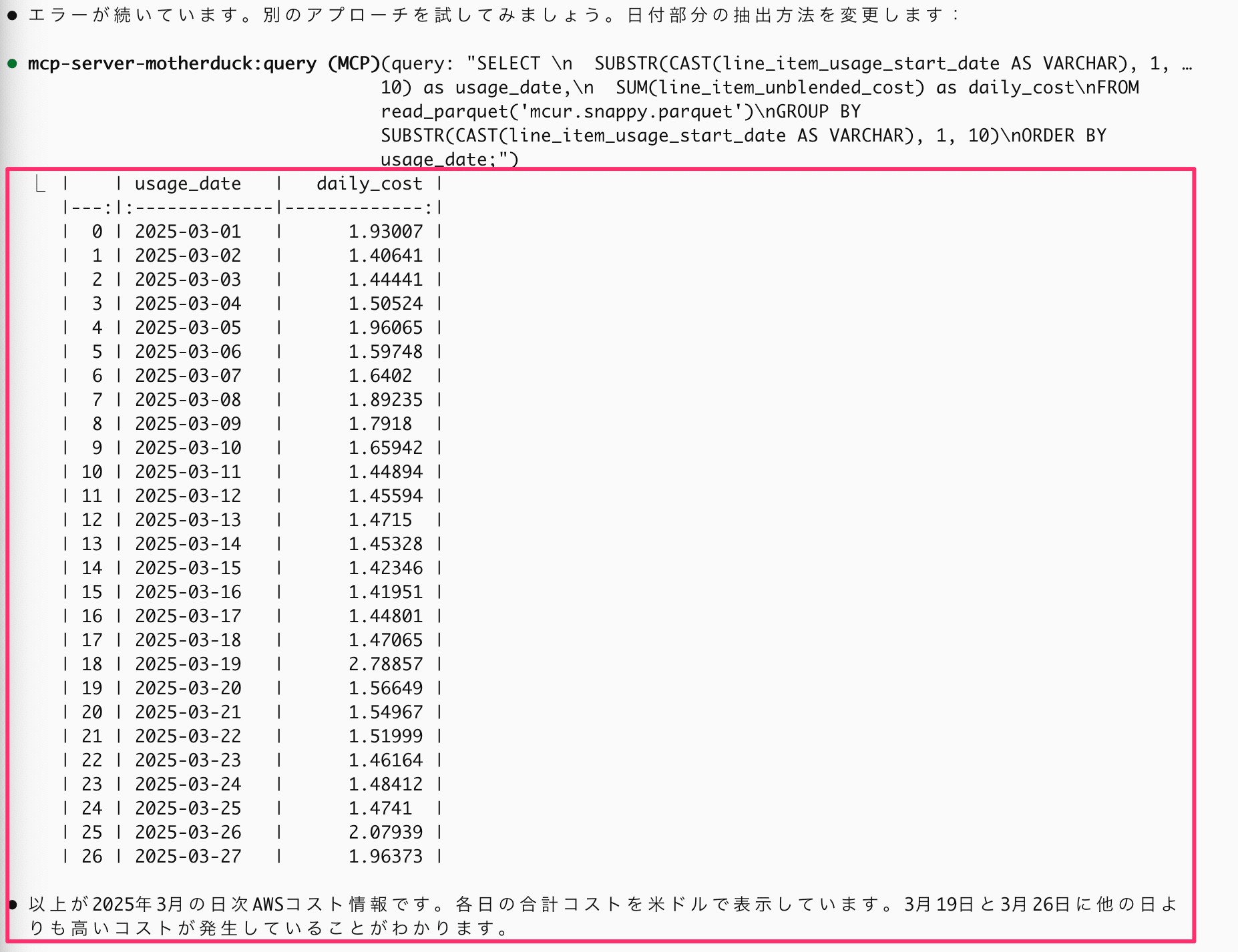
やりとり#3(求められました!)
最終的に実行されたSQLがこちら。
SELECT
SUBSTR(CAST(line_item_usage_start_date AS VARCHAR), 1, 10) as usage_date,
SUM(line_item_unblended_cost) as daily_cost
FROM read_parquet('mcur.snappy.parquet')
GROUP BY SUBSTR(CAST(line_item_usage_start_date AS VARCHAR), 1, 10)
ORDER BY usage_date;
おわりに
MotherDuck(DuckDB)のMCPサーバーを導入してみました。 SQLクエリを書かずにログ/データ分析、レポート作成まで 自動化できる未来が見えました。 熱い。
列名などを調べずに、いきなり答えを求めようとする部分は 事前の指示でなんとかなりそうです。
以上、参考になれば幸いです。









