![[レポート] Observability & Security unite: Unify your data in Amazon CloudWatch に参加してきました! #COP361 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/4pUQzSdez78aERI3ud3HNg/fe4c41ee45eccea110362c7c14f1edec/reinvent2025_devio_report_w1200h630.png?w=3840&fm=webp)
[レポート] Observability & Security unite: Unify your data in Amazon CloudWatch に参加してきました! #COP361 #AWSreInvent
こんにちは!
運用イノベーション部の大野です。
re:Invent 2025 の 「Observability & Security unite: Unify your data in Amazon CloudWatch」に参加してきましたので、内容をご紹介いたします。
セッション概要
セッションタイトル
COP361 | Observability & Security unite: Unify your data in Amazon CloudWatch
説明
運用、セキュリティ、コンプライアンスのデータを別々のサイロで管理すると、トラブルシューティングが遅くなり、セキュリティ態勢が弱まります。Amazon CloudWatchの強化された機能がチームやユースケース全体で柔軟な分析を可能にし、データを統合する方法を学びます。主要な組織がCloudWatchの簡素化されたログ管理と統合分析を活用して、根本原因分析を加速し、包括的なインサイトを可能にする方法をご覧ください。
スピーカー
- Avinav Jami - Director of Software Development, AWS
- Nikhil Kapoor - Principal Product Manager - Technical, AWS
- Chandra GP - Director - Cloud Solutions Engineering, S&P Global Inc
セッションカテゴリなど
- Type: Breakout session
- Level: 300 – Advanced
- Features: Lecture-style
- Topic: Cloud Operations
- Role: Developer / Engineer, DevOps Engineer, Solution / Systems Architect
- Services: Amazon CloudWatch

セッションサマリ
本セッションでは、12/2のKeyNoteで発表されたCloudWatchの新機能である「Unified data store in CloudWatch」を活用した、分散した各種データを統合する方法とそのメリットについて、事例を交えて解説が行われました。
現在の課題:データのサイロ化
セッションの冒頭では、多くの組織が直面しているデータのサイロ化問題について説明がありました。
チームとツールの分離

多くの組織では、正当な理由からチームが分離されています。
- セキュリティチーム:会社と顧客を守るために専用のセキュリティツールを使用
- 運用チーム:システムのヘルスとパフォーマンスを監視するためのオブザーバビリティツールを使用
- コンプライアンスチーム:監査やコンプライアンス要件のための専用のデータストアを管理
これらのチームは、それぞれの専門分野に特化したツールを使用しており、それ自体は理にかなっています。
しかし、問題はデータがこれらのツールに紐づいてサイロ化してしまうことです。
サイロ化がもたらす問題
データのサイロ化により、以下のような問題が発生します。

- インシデント対応の遅延:セキュリティチームが問題を検知しても、開発チームが同じ状況を把握できず、コミュニケーションに時間がかかる
- コンテキストの欠如:セキュリティイベント(ファイアウォールの拒否など)とアプリケーションイベント(トラフィック増加など)を関連付けて分析できない
- データの重複とコスト増:同じログデータが複数の場所に複製され、運用オーバーヘッドとストレージコストが増大
例えば、セキュリティチームがDDoS攻撃を検知した際に、アプリケーションチームは単にトラフィック増加としてスケールアップを試みてしまう、といった状況が生じます。
両チームが同じデータを見ていれば、セキュリティ対応(攻撃者のIPをブロックするなど)と運用対応を適切に連携できるはずです。
CloudWatchの新機能:統合データストア
AWSは、これらの課題を解決するためにCloudWatch Logsを「Unified Store(統合ストア)」として再構築しました。
このソリューションは、4つの主要なフェーズで構成されています。

1. データ収集(Collection)
データ収集の強化として、以下の機能が追加されました。

- 65以上のサービスに対応:既存の対応に加え、30の新しいサービスが追加されました
- Network Load Balancer
- CloudFront
- その他多数
- サードパーティコネクタ:マネージドコネクタを通じて、サードパーティソースからのログ収集が可能に
- ローンチ時点で10社のコネクタが利用可能(CrowdStrikeなど)
- 今後さらに追加予定
- 組織レベルのサポート:AWS Organizationsレベルでの一括有効化
- CloudTrail、VPC Flow Logsなどを組織全体で有効化可能
2. データキュレーション(Curation)
収集したデータを分析しやすい形に整形する機能です。

- Out-of-the-box Transformers:OCSF(Open Cybersecurity Schema Framework)や標準的なデータ形式への変換をサポート
- CloudWatch Logs Pipelines:カスタムの変換処理を実行
- フィールド操作
- データ補完(Enrichment)
- マスキング処理
- ソースタイプの自動検出:データソースとタイプの情報を自動的に識別し、ダウンストリームで利用可能に
3. 柔軟なストレージ(Flexible Storage)
ストレージの柔軟性を高める新機能が追加されました。

- クロスアカウント・クロスリージョン集中化:複数のアカウントやリージョンからログを1つの場所に集約
- ローカルアカウントでのログアクセスを維持しつつ、中央集権的な管理が可能
- バックアップリージョンの設定も可能
- 異なる保持期間の設定:ソースストアと集中ストアで異なる保持期間を設定可能
- 変換の独立適用:集中化の過程でログを変換し、セキュリティ用とオブザーバビリティ用で異なるバージョンのデータを作成可能
4. 分析とインサイト(Analytics & Insights)
強力な分析機能が追加されました。

S3 Tables連携
- CloudWatch LogsからS3 Tablesを直接作成可能
- お好みの分析エンジン(Athena、Redshift、Sparkなど)で分析可能
- Apache Iceberg形式でデータを保存
Facets(ファセット)
次世代のインデックス作成機能として「Facets」が導入されました。
- クエリ不要でフィールド値を確認:CloudWatch Logs Insightsにアクセスすると、インデックス化されたフィールドとその値の分布を即座に確認可能
- インタラクティブな絞り込み:フィールド値をクリックするだけで、ベースクエリが自動的にフィルタリングされる
- 探索的分析の支援:「どこから始めればいいかわからない」という状況で、まずファセットでデータの概要を把握し、そこから深掘りできる
S&P Global社の導入事例
S&P Global社のChandra GP氏から、実際の導入事例が紹介されました。
S&P Global社について
- 創業100年以上の歴史を持つ金融データ・分析のリーディングプロバイダー
- 約40,000人の従業員
- 世界15のリージョンでAWSを運用
- 大規模なVPCとEC2インスタンスを保有し、大量のログを生成
従来の課題
ログパイプラインの改訂にあたり、複数の要件が寄せられていました。
- コンプライアンス要件:生ログを専用のログアカウントに保存
- セキュリティ要件:キュレートしたログをセキュリティアカウントに配置し、クラウドセキュリティ監視を実現
- ビジネスユニット要件:中央集権化しつつも、ローカルでのログアクセス・検索を維持
- セキュリティオペレーション:脅威インテリジェンスとインシデント対応のためのキュレートログ
- SIEM連携:セキュリティ情報イベント管理システムへの最適化されたデータ送信
従来のアーキテクチャの問題点
CloudWatchの新機能導入前は、以下のような複雑な構成が必要でした。
- 複数のCloudサブスクリプションからローカルアカウントにログを収集
- 中央アカウントへの送信
- セキュリティアカウントへの送信
- コンプライアンスアカウントへの送信
- 多数の中間コンポーネント(Lambda、Kinesis Data Firehoseなど)
新アーキテクチャでの改善
CloudWatchの新機能を活用することで、以下の効果が得られたとのこと。
- アーキテクチャの大幅な簡素化:中間コンポーネントを削減
- コスト削減:データ複製とパイプライン管理のオーバーヘッドを削減
- 全ステークホルダーの要件を満たす:収集、キュレーション、ストレージの各フェーズで適切にデータを処理
料金体系
多くの新機能は追加料金なしで利用できます。
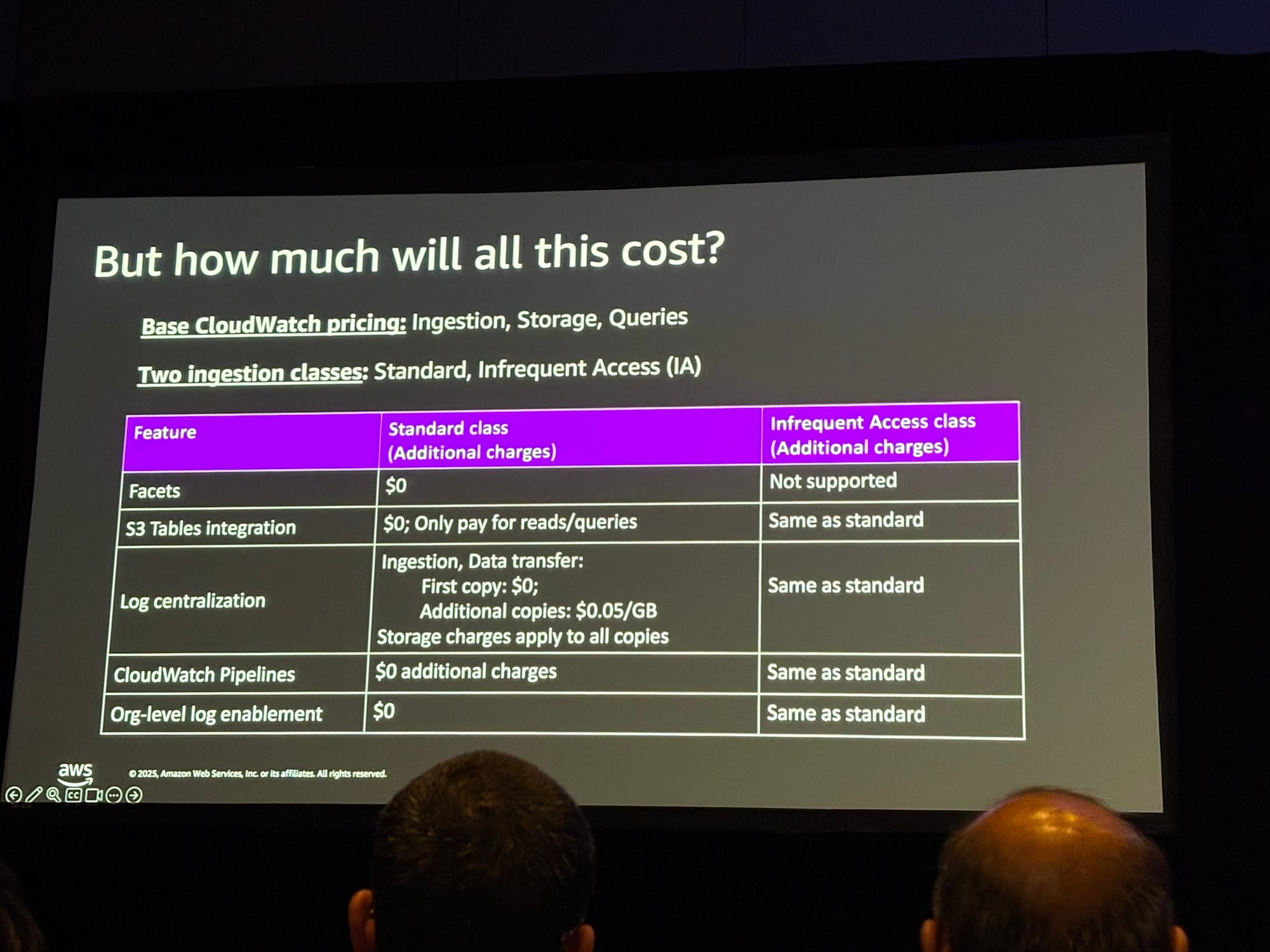
無料の機能
- Out-of-the-box配信:追加料金なし
- ファセット分析:スタンダードクラスで無料
- スキーマ検出:無料
- S3 Tables連携:CloudWatch側での追加料金なし(S3側の通常料金は適用)
- 集中化のレプリケーション:最初のコピーの取り込みは無料
- Pipelines変換:追加料金なし
CloudWatch Logsの料金体系
既存の3つの料金ディメンションに変更はありません。
- 取り込み(Ingestion)
- ストレージ(Storage)
- クエリ(Query)
ストレージクラス
- スタンダードクラス:リアルタイム運用向け。インデックス、アラーム、ファセットなど全機能が利用可能
- Infrequent Accessクラス:コンプライアンスやアーカイブ向け。スタンダードの半額でストレージコストを抑制
導入モデル
分散型集中化モデル

- 各アカウントのログがローカルで利用可能な状態を維持
- バックグラウンドで中央のオブザーバビリティアカウントにレプリケーション
- セキュリティアカウントにも選択的にレプリケーション
- チームがそれぞれのニーズに応じてログを活用可能
中央集権化モデル

- S&P Global社が採用したモデル
- コンプライアンスの「Single Source of Truth(信頼できる唯一の情報源)」として機能
- 中央から各チームへのデータ配信を制御
- 複数リージョンの運用やディザスタリカバリにも対応
デモンストレーション
セッションでは、実際のデモンストレーションが行われました。
ファセットを使った問題の特定
複数のアカウントとリージョンにまたがる決済処理アプリケーションを例に、
- CloudWatch Logs Insightsにアクセス
- ファセットでエラーの種類を確認(通知失敗、処理エラー、バリデーション失敗など)
- サービス名でフィルタリング(Payment Serviceを選択)
- クエリを書かずにリアルタイムでデータが絞り込まれる
- 複数アカウント・リージョンのエラーログを1か所で確認
CloudTrailとの連携
問題の根本原因を特定する際は、
- ファセットでCloud Trailを選択
- Lambda関数への変更履歴を確認
- 誰が、いつ、どのパラメータを変更したかを特定
S3 Tablesとの連携
Athena Studioから、
- CloudWatch LogsのS3 Tablesがデータカタログに表示
- 任意の分析ツールでクエリ可能
- ビジネスデータと組み合わせた高度な分析が可能
感想
KeyNoteでは最後の方にさらっと流されたアップデートでしたが、かなりインパクトの大きい内容でしたね...
事例で紹介されたS&P Global社のように、複数アカウントでリソース数も多い場合のログ管理と活用について課題を抱えている企業様は多いと思いますが、その解決策として大いに活躍が期待できそうです。
また、S3 Tables連携により、CloudWatchに取り込んだログをAthenaやRedshiftなど既存の分析ツールで活用できる点や、
トラブルシュートをアシストしてくれるファセット機能が実装されている点もユーザーフレンドリーで馴染みやすいサービスだなという印象です。
今後もこの機能について記事を執筆しようと思いますので、ご興味ある方はご覧いただけますと幸いです!
以上、大野でした!










