![[小ネタ] OpenSearch Service のコスト削減やパフォーマンス向上に関する Tips](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-b383cfad7452c18278d4772c71cae640/70681da1d5cfd4b8d3a7edcc29830075/amazon-opensearch-service?w=3840&fm=webp)
[小ネタ] OpenSearch Service のコスト削減やパフォーマンス向上に関する Tips
コーヒーが好きな emi です。
OpenSearch Service のコスト削減やパフォーマンス改善について調査する機会がありましたので、OpenSearch Service についておさらいしつつ、調査したことを残しておきます。
資料
主にこちらの BlackBelt Online Seminar の資料を参考にさせていただきました。
OpenSearch Service 概要おさらい
OpenSearch Service は検索・分析エンジンのマネージドサービスです。ユーザーはダッシュボードのエンドポイントを通じてサービスにアクセスでき、以下のような画面でデータを期間で検索したり、特定のワードで抽出したりできます。
▼ Amazon Security LakeのサブスクライバーにSIEM on Amazon OpenSearch Serviceを設定してみた | DevelopersIO より引用

主要コンポーネント
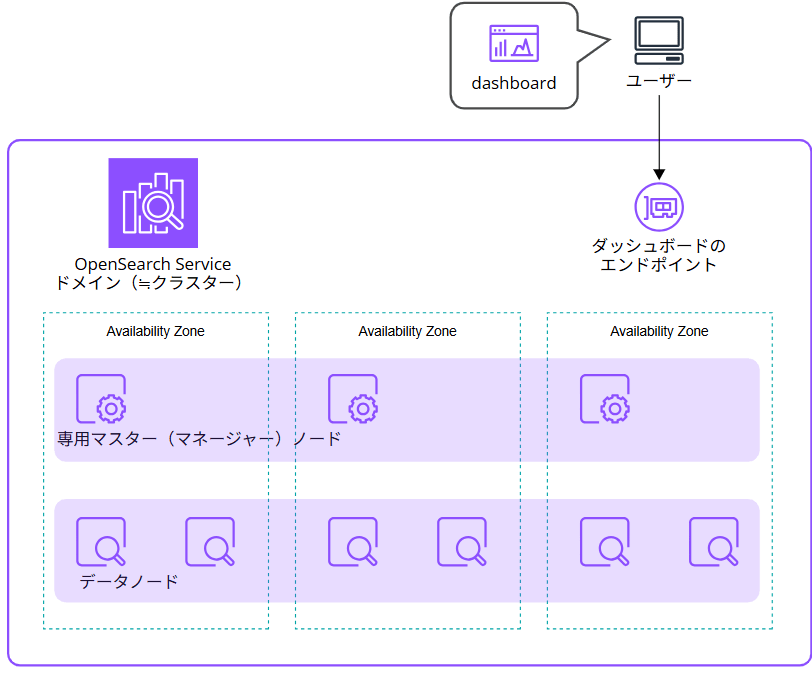
- ドメイン
- OpenSearch Service の一番大枠、外枠
- 設定、インデックス、ドキュメントなどのリソースを設定
- クラスター
- ドメインの中で実際に稼働するノード群。複数のノードの集合体で構成される
- 専用マスター(マネージャー)ノード
- クラスターの状態管理、ノードの追加・削除、インデックスの作成・削除、クラスター全体の設定変更
- データノード
- 実際のデータを保存・処理するノード
- インデックスデータの保存、ドキュメントのインデックス作成、検索・集計クエリの実行
- 実際のデータを保存・処理するノード
- 専用マスター(マネージャー)ノード
- ドメインの中で実際に稼働するノード群。複数のノードの集合体で構成される
- ダッシュボードのエンドポイント
- ユーザーがクラスターとやりとりするためのインターフェース
- クエリの実行、結果の可視化・分析が可能
1. ワークロードに応じた Hot ノードの選択
データノードに最新世代インスタンス(Graviton3、im4gn、OR1など)の利用が推奨されています。
OR インスタンス
OR(OpenSearch Optimized(最適化)インスタンス)は内部的にセグメントレプリケーションというアーキテクチャが採用されており、書き込みスループットが向上するとともにコストパフォーマンスが 30% 向上しています。
ちなみに、これまで OpenSearch 最適化インスタンスは OR1 のみリリースされていたのですが、つい先日 OR2 インスタンスがリリースされ、東京リージョンでも使えるようになっています。
OpenSearch 最適化インスタンスには、OpenSearch バージョン 2.11 以上のドメインが必要です。 OpenSearch 最適化インスタンスを選択した場合、一度ドメインを作成するとインスタンスファミリーを変更することはできません。
Im4gn インスタンス
Im4gn インスタンスは Graviton2 プロセッサを搭載したストレージ最適化インスタンスです。AWS Nitro SSD を使用しており、EBS ではなくインスタンス自体の内部の NVMe ストレージを使用します。
前世代の i3 と⽐較して容量に対するコストパフォーマンスが良く、RI を適⽤することで EBS 搭載インスタンスタイプよりコスト効果が出る場合もあるそうです。
Im4gn インスタンスタイプには、Elasticsearch バージョン 7.9 以降、または任意の OpenSearch バージョンが必要であり、EBS ストレージボリュームはサポートされていません。
インスタンス自体に内蔵された高性能 NVMe SSD に書き込むことで、EBS を使用する場合よりも高い IOPS 性能とレイテンシの低減が実現できます。
Im4gn インスタンスは他の Graviton インスタンスタイプ (C6g、M6g、R6g、R6gd) とのみ互換性があり、Graviton インスタンスと非 Graviton インスタンスは同じクラスター内で共存できません。
新しいインスタンスタイプを使う際は OpenSearch Service 自体のバージョンも追随する必要があります。
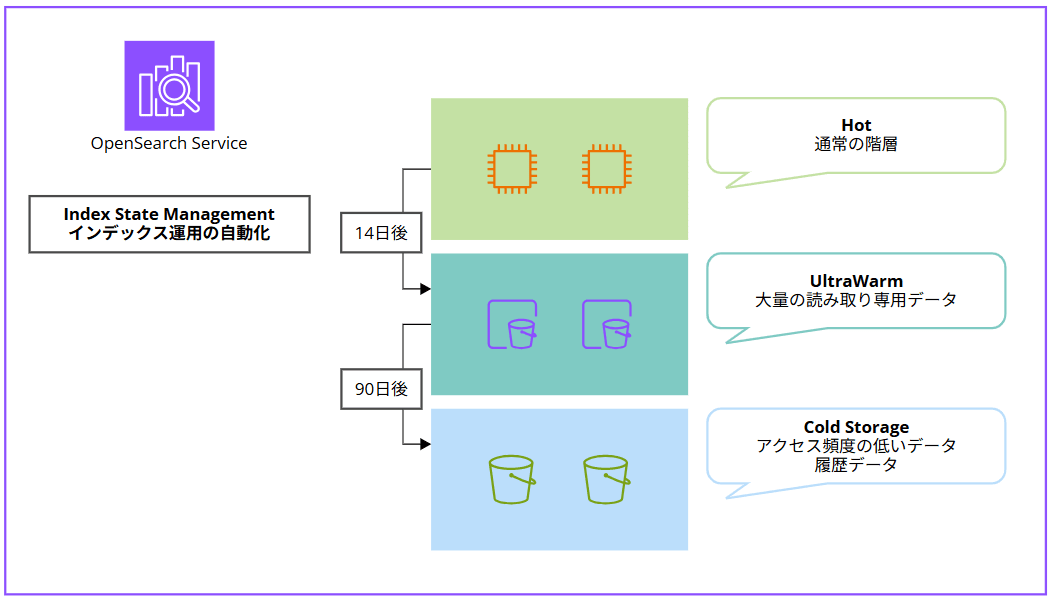
2. データの階層化による最適化
OpenSearch Service には Hot、UltraWarm、Cold Storage というストレージクラスがあり、適切な階層化を行うことでコスト削減できます。
データアクセスパターンに応じて Index State Management(ISM)という自動階層化機能を使うことで、インデックスのライフサイクルを自動管理できます。
(例)
| 期間 | ストレージタイプ | 用途 |
|---|---|---|
| 0~14日 | ホットストレージ(EBS) | リアルタイム検索が必要なデータ |
| 14日~90日 | UltraWarm(EBS、キャッシュ、S3) | 過去のログデータ、監査データ |
| 90日以上 | コールドストレージ(S3) | アーカイブ、規制対応データ |
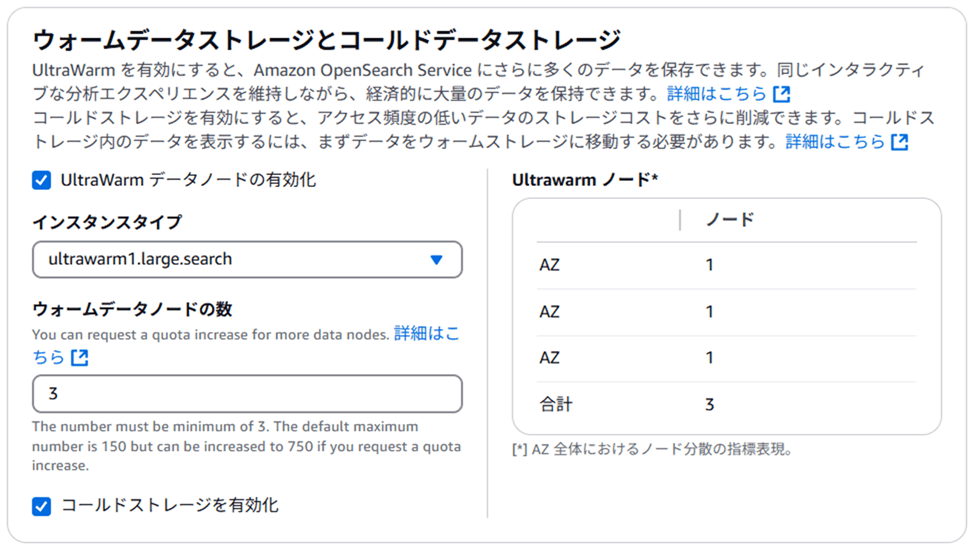
以下のような画面で UltraWarm データストレージを有効化できます。UltraWarm データストレージを有効化すると、コールドストレージも有効化できるようになります。
Direct Query(ダイレクトクエリ)を使うと S3 に保存されたデータに直接アクセスするためよりコスト削減になります。
3. ドメインの設定とサイジング
データノードとコーディネーターノードを分離することで、検索や集計処理のパフォーマンスが向上しダッシュボードの応答速度改善が期待できます。(2024/10 アップデート)
- コーディネーターノード:クエリ検索、結果集約、クラスター管理など
- データノード:インデックスデータの保管、CRUD 操作、集計など
4. 構成に関わらないベストプラクティス
- 最新バージョンの利用によるパフォーマンス向上(OpenSearch 2.17 は 1.3 に比べ 6 倍の性能)
- GP3 ボリュームへの移行
- リザーブドインスタンス(RI)の購入
- ストレージ圧縮用の zstd コーデックの活用
- データの圧縮(エンコード)と展開(デコード)を行うアルゴリズム(COmpressor/DECompressorの略)
- ストレージ使用量の削減(データを小さく保存)
- I/O 操作の削減(読み書きするデータ量が減る)
- コスト削減(ストレージコストの低減)
- データの圧縮(エンコード)と展開(デコード)を行うアルゴリズム(COmpressor/DECompressorの略)
- match_only_textフィールドタイプでストレージ使用量を削減
- 通常のテキストフィールドから派生した軽量版で、単語の位置情報や頻度情報を省略することでストレージ使用量を削減
- サンプリングや Index Rollups で保存データ量を最適化
- サンプリング:データの一部だけを選択的に取り込むことでストレージ使用量とコストを削減する手法
- Rollups(ロールアップ):詳細なデータを集計して小さなサイズのサマリーインデックスに変換し、クエリパフォーマンスを向上させる機能
おわりに
OpenSearch Service の各種機能を駆使することでコスト削減とパフォーマンス向上が見込めることが分かりました。すぐに出来そうなコスト削減方法としては RI の購入ですが、SRE 的な活動を地道に行うことでより最適化できそうですね。
また、直近では Amazon Q Developer が OpenSearch Service と統合され、運用データの調査と視覚化を支援する AI 支援機能が提供されました。まだ試してはいないのですが、AI も活用することでより最適な運用が可能になりそうです。
本記事への質問やご要望については画面下部のお問い合わせ「DevelopersIO について」からご連絡ください。記事に関してお問い合わせいただけます。
参考









