![[OpenSearch Service] ML Commons(AI Connectors) を Workflow API で構築して、Slackメッセージのハイブリッド検索を作成してみました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-b383cfad7452c18278d4772c71cae640/70681da1d5cfd4b8d3a7edcc29830075/amazon-opensearch-service?w=3840&fm=webp)
[OpenSearch Service] ML Commons(AI Connectors) を Workflow API で構築して、Slackメッセージのハイブリッド検索を作成してみました
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
単語一致の「キーワード検索」と、文脈や意味で検索する「セマンティック検索」を組み合わせた「ハイブリッド検索」は、非常に強力な検索手段です。たとえば「会議」というキーワードで検索した場合、キーワード検索では「会議」を含むドキュメントしかヒットしませんが、セマンティック検索を組み合わせることで「ミーティング」や「打ち合わせ」といった同義語を含むドキュメントもヒットするようになります。
OpenSearch Service でセマンティック検索を実現するには、テキストをベクトル(数値の配列)に変換する仕組みが必要です。従来はアプリケーション側で Amazon Bedrock などを呼び出してベクトル化していましたが、ML Commons を使用することで、OpenSearch 内部で自動的にベクトル化を実行できるようになります。
さらに、Workflow API(Flow Framework) を使用すれば、AI Connector、Model、Ingest Pipeline、Search Pipeline といった複雑なリソース群を、1回のAPI呼び出しで一括作成できます。
本記事では、OpenSearch Service 上に ML Commons(AI Connectors)を活用したハイブリッド検索システムを構築し、Slack メッセージをインデックスして検索できる仕組みを作成してみました。
なお、今回のコードは GitHub で公開しています。
https://github.com/furuya02/slack-hybrid-search-workflow
2 ML Commons と Flow Framework
(1) ML Commons
ML Commons は、OpenSearch の機械学習プラグインです。外部 ML サービスとの連携やベクトル検索機能など、多数の機能を提供しています。
https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/ml.html
AI Connectors は ML Commons の中核的な機能の一つで、Amazon Bedrock、OpenAI、Cohere、SageMaker など外部の ML プラットフォームでホストされているモデルに接続するための仕組みです。OpenSearch 2.9 で導入され、ニューラル検索(セマンティック検索)や RAG などの AI 機能を実現します。
本記事では、Amazon Bedrock の Titan Embeddings V2 に接続する AI Connector を使用して、以下のような機能を利用しています。
| 機能 | 説明 |
|---|---|
| AI Connectors | 外部 ML サービス(Amazon Bedrock)への接続を定義 |
| Remote Models | AI Connector を使用するモデルの登録・デプロイ |
| Text Embedding Processor | Ingest Pipeline でドキュメント登録時にテキストを自動ベクトル化 |
| Neural Search Query | 検索時にクエリテキストを自動的にベクトル化して k-NN 検索を実施 |
| Hybrid Query | BM25 キーワード検索と Neural Search を組み合わせた検索 |
AI Connectors を使用するメリットとして、アプリケーション側(Lambda 等)で Bedrock を直接呼び出す必要がなくなる点が挙げられます。インジェスト時・検索時ともにベクトル化は OpenSearch 内部で自動実行されるため、Lambda のコードがシンプルになり、実行時間も短縮されます。
| 項目 | 従来方式 | AI Connectors 使用時 |
|---|---|---|
| クエリのベクトル化 | Lambda → Bedrock → OpenSearch | OpenSearch 内部で自動実行 |
| Lambda の Bedrock 権限 | 必要 | 不要 |
| Lambda のコード | Bedrock 呼び出しコードが必要 | シンプル(テキストを渡すだけ) |
| レイテンシ | Lambda→Bedrock→OpenSearch の2ホップ | Lambda→OpenSearch の1ホップ |
(2) Flow Framework(Workflow API)
OpenSearch Workflow API は、Flow Framework プラグインとして OpenSearch 2.13 で導入された機能です。複雑なセットアップや前処理タスクを自動化し、1回のAPI呼び出しで複雑な構成を完了できます。
主な特徴は以下のとおりです。
- JSON/YAML対応: ワークフロー定義を JSON または YAML 形式で記述可能
- 依存関係の自動解決: ノード間の依存関係を定義すると、適切な順序で自動実行
- 一括削除:
_deprovisionAPI で作成したリソースをまとめて削除可能 - テンプレート化: 設定をテンプレートとして管理し、異なる環境に簡単に適用可能
本記事では、Workflow API を使用して以下の6つのリソースを一括作成しています。
| No | リソース | ノードタイプ | 用途 |
|---|---|---|---|
| 1 | AI Connector | create_connector |
Bedrock との接続定義 |
| 2 | Model | register_remote_model |
コネクタを使用するモデルの登録 |
| 3 | Model Deploy | deploy_model |
モデルのデプロイ |
| 4 | Ingest Pipeline | create_ingest_pipeline |
ドキュメント登録時のベクトル化 |
| 5 | Index | create_index |
k-NN 対応インデックス |
| 6 | Search Pipeline | create_search_pipeline |
ハイブリッド検索のスコア正規化 |
これらのリソースは以下のような依存関係を持ち、Workflow API が自動的に適切な順序で作成してくれます。
create_connector
↓ connector_id
register_model
↓ model_id
deploy_model
↓ model_id
create_ingest_pipeline
↓ pipeline_id
create_index
↓ index_name
create_search_pipeline
個別に API を呼び出す場合は6回以上の API 呼び出しが必要で、各ステップで取得した ID を手動で次のステップに渡す必要がありますが、Workflow API を使用すれば previous_node_inputs の定義により、これらが自動的に引き渡されます。
3 構成
今回作成したシステムの構成です。大きく分けて「インジェスト(メッセージ投入)」と「検索」の2つの処理フローがあります。
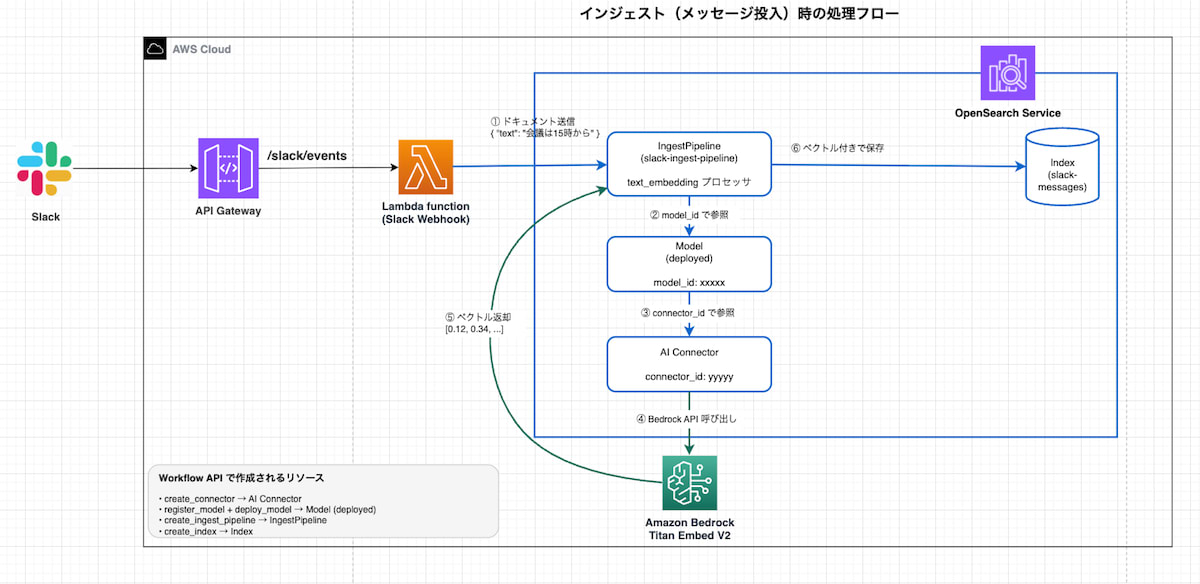
(1) インジェスト時の処理フロー
Slack でメッセージが投稿されると、Slack Events API 経由で API Gateway → Lambda にイベントが届き、Lambda が OpenSearch Service にドキュメントを送信します。OpenSearch 内部では Ingest Pipeline が動作し、AI Connector 経由で Bedrock を呼び出してテキストを自動的にベクトル化します。
(2) 検索時の処理フロー
検索リクエストが API Gateway → Lambda に届くと、Lambda は OpenSearch に対してハイブリッド検索クエリを送信します。OpenSearch 内部では Neural Search が AI Connector 経由で Bedrock を呼び出し、クエリテキストをベクトル化した上で、BM25 キーワード検索と k-NN ベクトル検索を並行実行します。Search Pipeline が両方のスコアを正規化・統合して、最終的な検索結果を返します。
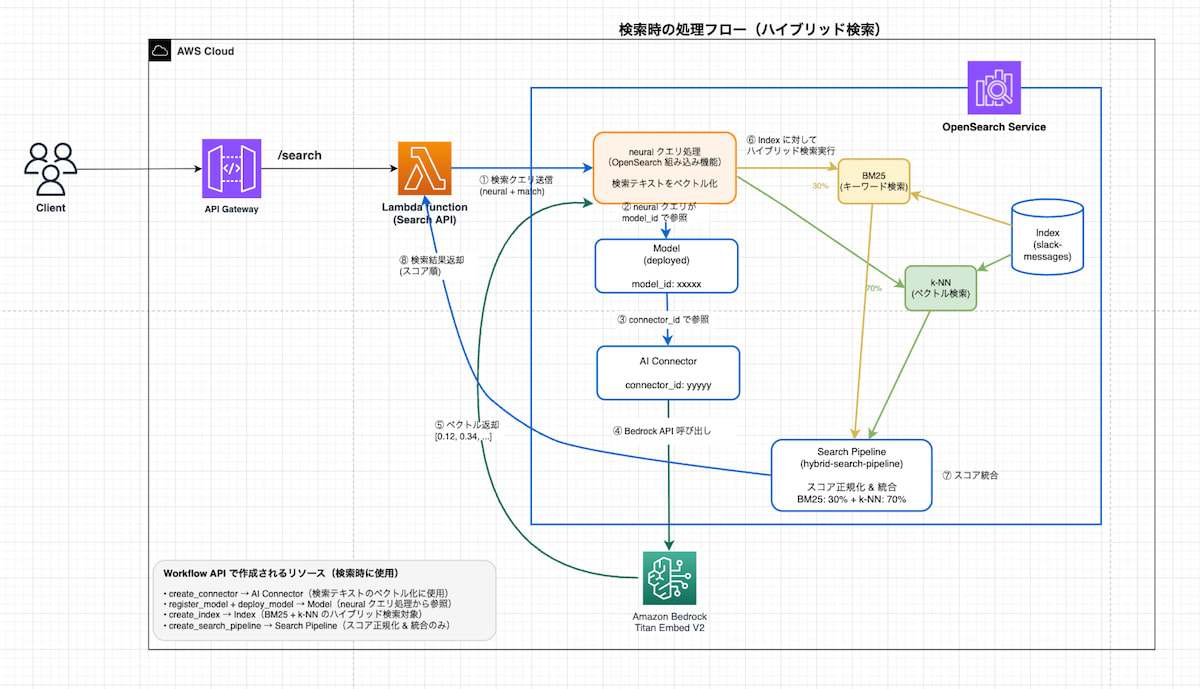
検索は以下の3つのモードをサポートしています。
| モード | 説明 | スコア計算 |
|---|---|---|
hybrid |
キーワード検索とベクトル検索の組み合わせ(デフォルト) | BM25 x 0.3 + k-NN x 0.7 |
keyword |
BM25 によるキーワード検索のみ | BM25 スコア |
vector |
k-NN によるベクトル検索のみ | k-NN スコア |
4 環境構築(CDK)
CDK により、OpenSearch Service ドメイン、Lambda、API Gateway および必要な IAM ロールを作成できます。
(1) CDK Deploy
$ git clone https://github.com/furuya02/slack-hybrid-search-workflow.git
$ cd slack-hybrid-search-workflow
$ cd cdk
$ pnpm install
$ pnpm cdk deploy
デプロイ完了後、出力される DomainEndpoint と OpenSearchBedrockRoleArn を .env に設定します。
(2) OpenSearch Service
デプロイされた OpenSearch Service ドメインです。
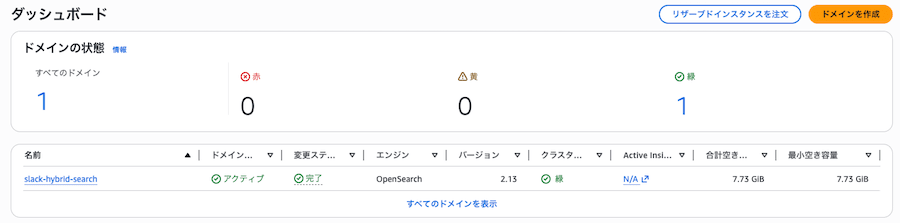
サンプル構成のため、インスタンスは t3.medium.search、シングル AZ となっています。

なお、t3.medium.search は AWS コンソールのプルダウンからは選択できないインスタンスタイプです。CLI(CDK を含む)からであれば利用可能です。
また、今回の構成は t3.medium.search x 1ノードのため、レプリカシャードを配置するノードがなく、クラスタの状態が黄色になりますが、検証用の最小構成ということで、そのまま進めます。
(3) IAM
CDK で作成される IAM ロールは以下の2つです。
| ロール名 | 用途 |
|---|---|
OpenSearchBedrockRole |
OpenSearch が Bedrock(Titan Embeddings V2)を呼び出すためのロール |
SlackHybridSearchLambdaRole |
Lambda 関数が OpenSearch Service にアクセスするためのロール |
OpenSearchBedrockRole は es.amazonaws.com が引き受けるロールで、AI Connectorsのためにbedrock:InvokeModel の権限を付与します。
SlackHybridSearchLambdaRole は lambda.amazonaws.com が引き受けるロールで、OpenSearch Service ドメインへの HTTP アクセス権限(es:ESHttpGet, es:ESHttpPost 等)を持ちます。
また、OpenSearch Service ドメインのアクセスポリシーには、上記2つのロールと管理者ロール(Workflow API 実行用)を許可しています。
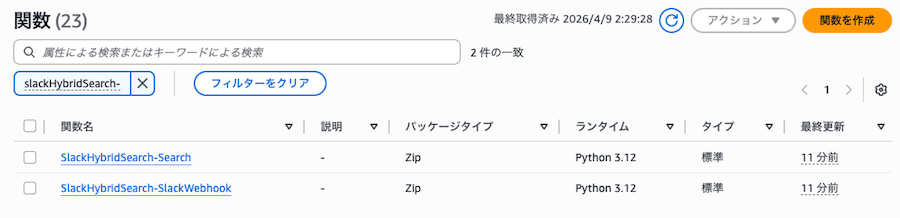
(4) Lambda
CDK で2つの Lambda 関数が作成されます。
| 関数名 | 用途 |
|---|---|
SlackHybridSearch-SlackWebhook |
Slack イベントを受信し、メッセージを OpenSearch にインデックス |
SlackHybridSearch-Search |
ハイブリッド検索を実行 |
SlackWebhook Lambda は、Slack からのイベントを受信し、メッセージを OpenSearch にインデックスする関数です。以下はコードの要点です。
def lambda_handler(event, context):
body = json.loads(event.get('body', '{}'))
# URL 検証(Slack App 設定時)
if body.get('type') == 'url_verification':
return {'statusCode': 200, 'body': json.dumps({'challenge': body.get('challenge')})}
# メッセージイベント処理
if body.get('type') == 'event_callback':
e = body.get('event', {})
if e.get('type') != 'message' or e.get('bot_id') or e.get('subtype') or not e.get('text'):
return {'statusCode': 200, 'body': '{}'}
doc = {
'message_id': e.get('client_msg_id'),
'channel_id': e.get('channel'),
'user_id': e.get('user'),
'text': e.get('text'),
'timestamp': e.get('ts')
}
# Ingest Pipeline を指定してインデックス(ベクトル化は OpenSearch 内部で自動実行)
get_client().index(index=INDEX, body=doc, pipeline=PIPELINE, refresh=True)
return {'statusCode': 200, 'body': '{}'}
ドキュメントのインデックス時に pipeline パラメータで Ingest Pipeline を指定することで、ベクトル化が自動的に実行されます。
Search Lambda は、ハイブリッド検索を実行する関数です。検索モードに応じてクエリを構築します。
def lambda_handler(event, context):
body = json.loads(event.get('body', '{}'))
query, mode, size = body.get('query', ''), body.get('mode', 'hybrid'), body.get('size', 10)
neural = {'neural': {'text_embedding': {'query_text': query, 'model_id': MODEL_ID, 'k': size}}}
if mode == 'keyword':
q = {'match': {'text': query}}
res = get_client().search(index=INDEX, body={'size': size, 'query': q})
elif mode == 'vector':
res = get_client().search(index=INDEX, body={'size': size, 'query': neural})
else: # hybrid
q = {'hybrid': {'queries': [{'match': {'text': query}}, neural]}}
res = get_client().search(index=INDEX, body={'size': size, 'query': q},
params={'search_pipeline': PIPELINE})
# ... 結果を整形して返却
ハイブリッドモードでは、BM25 キーワード検索と Neural Search(ベクトル検索)を組み合わせたクエリを送信し、Search Pipeline でスコアを統合しています。
完全なソースコードは以下を参照してください。
(5) API Gateway
CDK で REST API が作成され、以下のエンドポイントが構成されます。
| メソッド | パス | 統合先 Lambda | 用途 |
|---|---|---|---|
| POST | /slack/events |
SlackHybridSearch-SlackWebhook | Slack Events API Webhook |
| POST | /search |
SlackHybridSearch-Search | ハイブリッド検索 |
| GET | /search |
SlackHybridSearch-Search | ハイブリッド検索 |
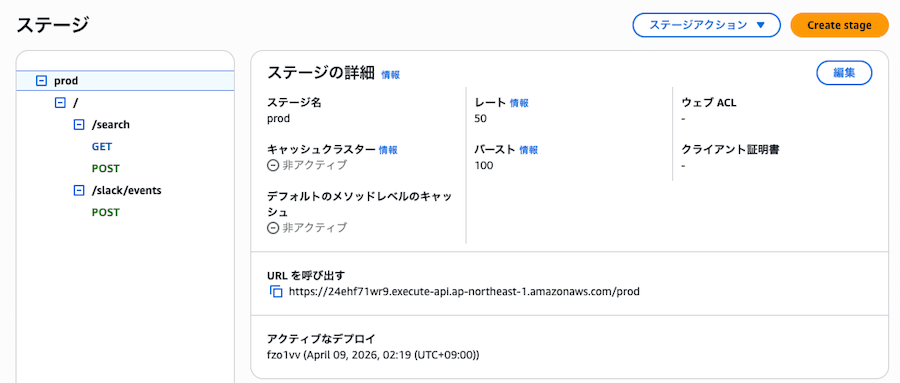
デプロイ後、SlackWebhookUrl(Slack App の Event Subscriptions に設定する URL)と SearchApiUrl(検索 API の URL)が出力されます。
5 環境構築(Workflow API)
CDK デプロイが完了したら、次に Workflow API を使用してハイブリッド検索に必要なリソースを作成します。
(1) セットアップスクリプトの実行
$ cd slack-hybrid-search-workflow
$ ./scripts/setup-workflow-api.sh
このスクリプトは、workflow-template.json の変数(${BEDROCK_ROLE_ARN} と ${AWS_REGION})を .env の値で置換し、Workflow API に ?provision=true パラメータ付きで POST します。これにより、ワークフローの作成とプロビジョニング(リソース作成)が同時に実行されます。
# スクリプトの要点
WORKFLOW_JSON=$(cat "$SCRIPT_DIR/workflow-template.json" | \
sed "s|\${BEDROCK_ROLE_ARN}|$BEDROCK_ROLE_ARN|g" | \
sed "s|\${AWS_REGION}|$AWS_REGION|g")
curl -s -X POST \
"https://${DOMAIN_ENDPOINT}/_plugins/_flow_framework/workflow?provision=true" \
--aws-sigv4 "aws:amz:$AWS_REGION:es" \
--user "$AWS_ACCESS_KEY_ID:$AWS_SECRET_ACCESS_KEY" \
-H "Content-Type: application/json" \
-H "x-amz-security-token: $AWS_SESSION_TOKEN" \
-d "$WORKFLOW_JSON"
実行すると、workflow_id が返却されます。
{
"workflow_id": "dv_zYZ0BS3ey_-URlTo8"
}
なお、Workflow API を使用せず個別の API を順番に呼び出してセットアップする方法もあります。参考として setup-hybrid-search.sh がリポジトリに含まれています。
(2) ワークフローテンプレートの構成
workflow-template.json には、6つのノード(リソース)が定義されています。ここでは、各ノードの要点を紹介させください。
AI Connector
Bedrock Titan Embeddings V2 への接続を定義します。aws_sigv4 プロトコルで IAM ロール認証を使用し、Neural Search 時に必要な pre_process_function と post_process_function(Painless スクリプト)も定義しています。
{
"id": "create_connector",
"type": "create_connector",
"user_inputs": {
"name": "Bedrock Titan Connector",
"protocol": "aws_sigv4",
"credential": { "roleArn": "${BEDROCK_ROLE_ARN}" },
"parameters": {
"region": "${AWS_REGION}",
"service_name": "bedrock",
"model": "amazon.titan-embed-text-v2:0"
},
"actions": [{
"action_type": "predict",
"method": "POST",
"url": "https://bedrock-runtime.${AWS_REGION}.amazonaws.com/model/amazon.titan-embed-text-v2:0/invoke",
"request_body": "{ \"inputText\": \"${parameters.inputText}\", \"dimensions\": 1024, \"normalize\": true }",
"pre_process_function": "...",
"post_process_function": "..."
}]
}
}
(3) pre_process_function と post_process_function
上記の AI Connector 定義で "pre_process_function": "..." と "post_process_function": "..." としていた部分について補足します。
Neural Search(vector / hybrid モード)で検索を実行する際、OpenSearch 内部では query_text が text_docs という配列形式に変換されます。一方、Bedrock Titan Embeddings V2 は inputText という文字列形式の入力を期待します。この形式の不一致を解消するのが pre_process_function です。
Neural Search の内部形式 Bedrock が期待する形式
{ "text_docs": ["会議の議事録"] } → { "parameters": { "inputText": "会議の議事録" } }
pre_process_function を設定しない場合、Some parameter placeholder not filled in payload: inputText というエラーが発生します。
pre_process_function(Painless スクリプト)
text_docs 配列から最初の要素を取り出し、Bedrock の inputText パラメータに変換します。
StringBuilder builder = new StringBuilder();
builder.append("\"");
String first = params.text_docs[0]; // 配列の最初の要素を取得
builder.append(first);
builder.append("\"");
def parameters = "{" +"\"inputText\":" + builder + "}";
return "{" +"\"parameters\":" + parameters + "}";
post_process_function(Painless スクリプト)
Bedrock から返却された embedding 配列を、OpenSearch が期待する形式に変換します。
def name = "sentence_embedding";
def dataType = "FLOAT32";
if (params.embedding == null || params.embedding.length == 0) {
return params.message;
}
def shape = [params.embedding.length];
def json = "{" +
"\"name\":\"" + name + "\"," +
"\"data_type\":\"" + dataType + "\"," +
"\"shape\":" + shape + "," +
"\"data\":" + params.embedding +
"}";
return json;
注意点として、この pre/post_process_function が必要になるのは 検索時(Neural Search)のみ です。インジェスト時は text_embedding プロセッサが直接 Bedrock を呼び出すため、これらの関数は使用されません。
| 処理 | pre_process_function | post_process_function |
|---|---|---|
| インジェスト時(ドキュメント登録) | 不要 | 不要 |
| 検索時(vector / hybrid モード) | 必須 | 必須 |
| 検索時(keyword モード) | 不要(Neural Search を使用しない) | 不要 |
この非対称性は、インジェスト時の text_embedding プロセッサと検索時の Neural Search で、Bedrock への呼び出し経路が異なることに起因していると言えそうで。
Model 登録・デプロイ
previous_node_inputs により、前のノードで作成されたリソースの ID が自動的に引き渡されます。
{
"id": "register_model",
"type": "register_remote_model",
"user_inputs": { "name": "Titan Embeddings V2", "function_name": "remote" },
"previous_node_inputs": { "create_connector": "connector_id" }
},
{
"id": "deploy_model",
"type": "deploy_model",
"previous_node_inputs": { "register_model": "model_id" }
}
Ingest Pipeline
ドキュメント登録時に text フィールドを text_embedding フィールドにベクトル化するパイプラインです。model_id は ${{deploy_model.model_id}} という構文で、前のノードで作成されたモデル ID を自動参照します。
{
"id": "create_ingest_pipeline",
"type": "create_ingest_pipeline",
"user_inputs": {
"pipeline_id": "slack-ingest-pipeline",
"configurations": {
"processors": [{
"text_embedding": {
"model_id": "${{deploy_model.model_id}}",
"field_map": { "text": "text_embedding" }
}
}]
}
},
"previous_node_inputs": { "deploy_model": "model_id" }
}
Index
k-NN 検索を有効化し、text_embedding フィールドに 1024次元のベクトルを格納するインデックスです。default_pipeline を設定することで、ドキュメント登録時に Ingest Pipeline が自動適用されます。
インデックスのフィールド構造は、Slack Events API のコールバックで取得できる情報を基準に設計しています。
| フィールド | 型 | 説明 |
|---|---|---|
message_id |
keyword |
Slack のクライアントメッセージ ID |
channel_id |
keyword |
チャンネル ID |
user_id |
keyword |
送信ユーザー ID |
text |
text |
メッセージ本文(キーワード検索対象) |
text_embedding |
knn_vector (1024次元) |
text から自動生成されるベクトル(Ingest Pipeline が生成) |
timestamp |
keyword |
メッセージのタイムスタンプ |
thread_ts |
keyword |
スレッドのタイムスタンプ |
team_id |
keyword |
ワークスペース ID |
event_time |
long |
イベント発生時刻 |
text_embedding フィールドは、Ingest Pipeline の text_embedding プロセッサによって text フィールドから自動生成されるため、アプリケーション(Lambda)側で値を設定する必要はありません。
{
"id": "create_index",
"type": "create_index",
"user_inputs": {
"index_name": "slack-messages",
"configurations": {
"settings": { "index": { "knn": true, "default_pipeline": "slack-ingest-pipeline" } },
"mappings": { "properties": {
"message_id": { "type": "keyword" },
"channel_id": { "type": "keyword" },
"user_id": { "type": "keyword" },
"text": { "type": "text" },
"text_embedding": {
"type": "knn_vector", "dimension": 1024,
"method": { "name": "hnsw", "engine": "faiss", "space_type": "l2" }
},
"timestamp": { "type": "keyword" },
"thread_ts": { "type": "keyword" },
"team_id": { "type": "keyword" },
"event_time": { "type": "long" }
}}
}
}
}
Search Pipeline
ハイブリッド検索時のスコア正規化・統合を行うパイプラインです。BM25 と k-NN のスコアを min_max で 0〜1 に正規化し、重み付け平均(BM25: 0.3、k-NN: 0.7)で統合します。
{
"id": "create_search_pipeline",
"type": "create_search_pipeline",
"user_inputs": {
"pipeline_id": "hybrid-search-pipeline",
"configurations": {
"phase_results_processors": [{
"normalization-processor": {
"normalization": { "technique": "min_max" },
"combination": { "technique": "arithmetic_mean", "parameters": { "weights": [0.3, 0.7] } }
}
}]
}
}
}
完全なテンプレートは以下を参照してください。
(4) ステータス確認
ワークフローの実行状態を確認し、各リソースの ID を取得します。
$ curl -s -X GET \
"https://${DOMAIN_ENDPOINT}/_plugins/_flow_framework/workflow/${WORKFLOW_ID}/_status" \
--aws-sigv4 "aws:amz:ap-northeast-1:es" \
--user "${AWS_ACCESS_KEY_ID}:${AWS_SECRET_ACCESS_KEY}" \
-H "x-amz-security-token: ${AWS_SESSION_TOKEN}" | jq .
state が COMPLETED であることを確認します。resources_created から各リソースの ID を確認できます。
{
"state": "COMPLETED",
"resources_created": [
{ "workflow_step_name": "create_connector", "resource_id": "<connector_id>" },
{ "workflow_step_name": "register_model", "resource_id": "<model_id>" },
{ "workflow_step_name": "deploy_model", "resource_id": "<model_id>" },
{ "workflow_step_name": "create_ingest_pipeline", "resource_id": "slack-ingest-pipeline" },
{ "workflow_step_name": "create_index", "resource_id": "slack-messages" },
{ "workflow_step_name": "create_search_pipeline", "resource_id": "hybrid-search-pipeline" }
]
}
特に register_model(または deploy_model)の resource_id が次のステップで使用する model_id です。
6 Lambda の環境変数を更新
ベクトル化は OpenSearch 内部で実行されますが、検索時の Neural Search クエリには、使用するモデルを model_id で指定する必要があります。そのため、Workflow API で作成された model_id を Search Lambda の環境変数に設定する必要があります。
$ aws lambda update-function-configuration \
--function-name SlackHybridSearch-Search \
--environment "Variables={OPENSEARCH_ENDPOINT=<DomainEndpoint>,INDEX_NAME=slack-messages,SEARCH_PIPELINE=hybrid-search-pipeline,MODEL_ID=<model_id>}"
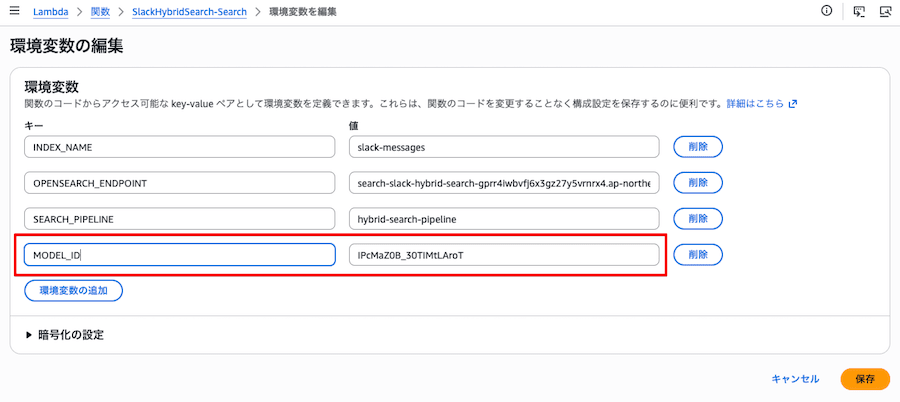
環境変数 MODEL_ID は CDK デプロイでは設定されません。Workflow API でリソースを作成した後に取得できる値のため、ここで手動の設定が必要になります。
7 検索テスト
サンプルデータを使用して、ハイブリッド検索の動作を確認します。
(1) サンプルデータの投入
リポジトリに含まれるサンプルデータ投入スクリプトを実行します。Slack 風のメッセージデータ(100件)が OpenSearch にインデックスされます。
$ ./scripts/load-sample-data.sh
(2) 検索テスト
API エンドポイントを取得し、3つの検索モードを試してみます。
# API エンドポイントを取得
$ API_ENDPOINT=$(aws cloudformation describe-stacks \
--stack-name SlackHybridSearchStack \
--query "Stacks[0].Outputs[?OutputKey=='ApiEndpoint'].OutputValue" \
--output text)
キーワード検索
$ curl -s -X POST "${API_ENDPOINT}search" \
-H "Content-Type: application/json" \
-d '{"query": "会議", "mode": "keyword"}' \
| jq -r '.results[] | "\(.score | tostring | .[0:6]) | \(.text)"'
キーワード検索では「会議」という単語を含むメッセージがヒットします。
ベクトル検索
$ curl -s -X POST "${API_ENDPOINT}search" \
-H "Content-Type: application/json" \
-d '{"query": "パフォーマンスを改善したい", "mode": "vector"}' \
| jq -r '.results[] | "\(.score | tostring | .[0:6]) | \(.text)"'
ベクトル検索では、クエリと意味的に類似するメッセージがヒットします。「パフォーマンスを改善したい」というクエリに対して、「レイテンシが高い」「処理速度が遅い」といった直接的にはキーワードが一致しないメッセージもヒットする点が特徴です。
ハイブリッド検索
$ curl -s -X POST "${API_ENDPOINT}search" \
-H "Content-Type: application/json" \
-d '{"query": "Lambda が遅い", "mode": "hybrid"}' \
| jq -r '.results[] | "\(.score | tostring | .[0:6]) | \(.text)"'
ハイブリッド検索では、キーワード一致と意味的類似性の両方を加味した結果が返されます。BM25 スコアと k-NN スコアが Search Pipeline で正規化・統合され、バランスの取れた検索結果が得られます。
(3) サンプルデータの削除
Slack 連携の動作確認に影響しないよう、ここでサンプルデータを削除しておきます。
# 全ドキュメントを削除
$ curl -s -X POST "https://${DOMAIN_ENDPOINT}/slack-messages/_delete_by_query" \
--aws-sigv4 "aws:amz:ap-northeast-1:es" \
--user "${AWS_ACCESS_KEY_ID}:${AWS_SECRET_ACCESS_KEY}" \
-H "x-amz-security-token: ${AWS_SESSION_TOKEN}" \
-H "Content-Type: application/json" \
-d '{"query": {"match_all": {}}}' | jq .
# 削除確認(0件になっていることを確認)
$ curl -s -X GET "https://${DOMAIN_ENDPOINT}/slack-messages/_count" \
--aws-sigv4 "aws:amz:ap-northeast-1:es" \
--user "${AWS_ACCESS_KEY_ID}:${AWS_SECRET_ACCESS_KEY}" \
-H "x-amz-security-token: ${AWS_SESSION_TOKEN}" | jq .
8 Slack 連携
(1) Slack App の設定
Slack App を作成し、Event Subscriptions を設定します。
Slack App の作成
- https://api.slack.com/apps で「Create New App」をクリック
- 「From scratch」を選択し、アプリ名とワークスペースを指定
OAuth & Permissions の設定
左メニューから「OAuth & Permissions」を選択し、Bot Token Scopes に以下を追加します。
channels:history- チャンネルのメッセージを読み取るchannels:read- チャンネル情報を読み取る
Event Subscriptions の設定
- 左メニューから「Event Subscriptions」を選択
- 「Enable Events」を On に切り替え
- 「Request URL」に CDK 出力の
SlackWebhookUrlを設定- URL を入力すると Slack が検証リクエストを送信し、Lambda が応答して「Verified」と表示されます
- 「Subscribe to bot events」で
message.channelsを追加 - 「Save Changes」をクリック
アプリのインストールとチャンネルへの追加
- 左メニューの「Install App」からワークスペースにインストール
- Slack でメッセージを監視したいチャンネルを開く
- チャンネル名をクリック → 「インテグレーション」タブ → 「アプリを追加する」
(2) 動作確認
メッセージの投稿
監視対象のチャンネルでメッセージを投稿します。
今日の定例会議は15時からです。議事録は後で共有します。
インデックスへの登録確認
$ curl -s -X GET "https://${DOMAIN_ENDPOINT}/slack-messages/_count" \
--aws-sigv4 "aws:amz:ap-northeast-1:es" \
--user "${AWS_ACCESS_KEY_ID}:${AWS_SECRET_ACCESS_KEY}" \
-H "x-amz-security-token: ${AWS_SESSION_TOKEN}" | jq .
ドキュメント数が増えていることを確認します。
検索で投稿したメッセージを確認
# キーワード検索
$ curl -s -X POST "${API_ENDPOINT}search" \
-H "Content-Type: application/json" \
-d '{"query": "定例会議", "mode": "keyword"}' \
| jq -r '.results[] | "\(.score | tostring | .[0:6]) | \(.text)"'
# ハイブリッド検索(意味的にも検索)
$ curl -s -X POST "${API_ENDPOINT}search" \
-H "Content-Type: application/json" \
-d '{"query": "ミーティングの予定", "mode": "hybrid"}' \
| jq -r '.results[] | "\(.score | tostring | .[0:6]) | \(.text)"'
ハイブリッド検索では、「ミーティングの予定」というクエリでも、意味的な類似性によりメッセージがヒットすることを確認できます。
9 最後に
OpenSearch Service の ML Commons(AI Connectors)と Workflow API を使用して、Slack メッセージのハイブリッド検索システムを構築してみました。
AI Connectors を活用することで、ベクトル化の処理が OpenSearch 内部で完結するため、Lambda のコードは非常にシンプルになりました。また、Workflow API により、複数のリソースを1回の API 呼び出しで一括作成できる点も便利でした。
構築にあたっては、検索時の pre/post_process_function の設定にやや手間取りましたが、一度テンプレートとして完成させてしまえば、異なる環境への展開も容易に行えると思います。
コードは GitHub で公開しています。
https://github.com/furuya02/slack-hybrid-search-workflow









