panda-gym と Stable-Baselines3 で 7 自由度ロボットアームの強化学習を Jetson AGX Orin で試してみました
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
ロボットアームの強化学習を試してみたいということで、panda-gym(Franka Panda 7 自由度アームのシミュレータ)を Stable-Baselines3 の SAC + Hindsight Experience Replay(HER)で学習してみました。使用したのは、Jetson AGX Orin(JetPack 6.2.1)です。
結果としては、PandaReach-v3 を 25 000 step / 約 15 分の学習で deterministic 評価 100 %(50/50 episode 成功) にまで達成できました。
下の動画は、学習前のランダム policy(左)と学習後の deterministic policy(右)の挙動の違いです。学習前は、goal の緑球に向かう方向すら定まらず 50 step の制限時間を超えて失敗となる一方、右は各開始状態から 1〜3 step で goal に到達しています。
コードは、下記で公開しております。
検証環境は、以下のとおりです。
| 項目 | 値 |
|---|---|
| ハードウェア | Jetson AGX Orin |
| GPU | Orin(CUDA 12.6) |
| OS | Ubuntu 22.04.5 LTS(aarch64)/ L4T R36.4.4 / JetPack 6.2.1 |
| Docker | 28.3.2 + nvidia runtime |
| ベースイメージ | dustynv/pytorch:2.7-r36.4.0(PyTorch 2.7 + Python 3.10) |
| panda-gym | 3.0.7 |
| stable-baselines3 | 2.7.0 |
| gymnasium | 0.29.1 |
2 panda-gym と SAC + HER
2.1 panda-gym とは
panda-gym は、PyBullet ベースで Franka Panda アームの典型的なロボット学習タスクを Gymnasium API でラップしたシミュレータです。
- アーム:Franka Emika Panda、7 関節
- API:Gymnasium 互換(強化学習の標準インタフェース)
- 観測値:単一配列ではなく
observation(アーム状態)/achieved_goal(現在のエンドエフェクタ位置)/
desired_goal(目標位置、毎エピソードで変わる)の 3 キーを持つ dict - 報酬:sparse(goal までの距離が閾値以下なら 0、それ以外は -1)が標準
- タスク設計:policy
が 状態と目標を一緒に受け取る goal-conditioned な設計 - 用意されているタスク:
Reach/Push/Slide/PickAndPlace/Stack/Flip
本記事でターゲットにしたタスクは、Reach のみです。「Reach」は「アームの先端を 3D空間の指定座標に持っていく」タスクです。
2.2 SAC + HER
連続行動空間の off-policy アルゴリズム(過去のデータを replay buffer に溜めて再利用するタイプ)である SAC(Soft Actor-Critic) と、その replay buffer の中身を加工する経験再利用テクニック HER(Hindsight Experience Replay) の組合せは、panda-gym 公式 example でも採用されているように、goal-conditioned sparse-reward タスクで推奨されていることから。本記事もこれを採用しました。
SAC が学習する policy(「観測 → 行動」を決める関数。Reach の場合はアームの関節情報と goal 位置を入力に、エンドエフェクタの 3 次元移動量を出力する)は、確率的(stochastic)な分布として表現されます。学習中はその分布から行動をサンプリングして探索しますが、評価時には探索ノイズを抜いた deterministic モード(行動分布の平均値をそのまま使う)で動かしています。本記事の動画・評価値の「学習後の deterministic policy」はこの評価モードのことで、model.predict(observation, deterministic=True) で取り出しています。
本記事では、メイン学習を HER 有り で実施していますが、HER の効果を測るために HER 無し の対照実験も実施しました。
3 Docker 構成
リポジトリ直下に Dockerfile を 1 つ置き、ビルドおよびコンテナ起動は docker コマンドを直接叩く構成にしています。
3.1 Dockerfile
Github Dockerfile
dustynv/pytorch:2.7-r36.4.0 をベースに、必要なシステムパッケージと panda-gym 周辺の Python パッケージを入れています。
PyBullet は PyPI に aarch64 wheel が無い ので、pip install panda-gym の中でソースビルドが走ります(gcc で 5〜10 分)。
Dockerfile(抜粋)
FROM dustynv/pytorch:2.7-r36.4.0
# 1) 汎用ツール
RUN apt-get update && apt-get install -y --no-install-recommends git ca-certificates
# 2) 動画エンコード(imageio[ffmpeg] のバックエンド)
RUN apt-get update && apt-get install -y --no-install-recommends ffmpeg
# 3) PyBullet をソースビルドするための C/C++ ツールチェーン
RUN apt-get update && apt-get install -y --no-install-recommends build-essential cmake
# 4) PyBullet を headless で描画するための OpenGL 系ライブラリ
RUN apt-get update && apt-get install -y --no-install-recommends libgl1 libglib2.0-0 libegl1 libosmesa6
# 5) Python build tools
RUN pip install --no-cache-dir --upgrade pip setuptools wheel
# 6) panda-gym 周辺パッケージ
# - PyBullet は source build される(aarch64 wheel が PyPI に無い)
# - PyTorch は base image 同梱なので入れない
RUN pip install --no-cache-dir \
"panda-gym==3.0.7" \
"stable-baselines3==2.7.0" \
"gymnasium==0.29.1" \
"tensorboard==2.16.2" \
"imageio[ffmpeg]==2.34.1"
# 7) ワークスペース
WORKDIR /workspace/panda-gym-sb3-rl-starter
3.2 ビルドと起動
イメージビルド
リポジトリ直下で以下を実行します。タグは panda-gym-sb3-rl-starter:latest で固定します。
$ docker build -t panda-gym-sb3-rl-starter:latest .
ビルド後のイメージサイズは 14.5 GB となりました。
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
panda-gym-sb3-rl-starter latest f933905c568b 1 hours ago 14.5GB
コンテナの daemon 起動
学習は 15 分前後かかります。SSH が切断されてもコンテナが落ちないよう、sleep infinity で daemon 起動しておき、必要に応じて docker exec で対話シェルに入る運用にします。
$ docker run -d --name panda_gym_sb3 \
--runtime nvidia \
--network host \
-v "$(pwd):/workspace/panda-gym-sb3-rl-starter" \
-w /workspace/panda-gym-sb3-rl-starter \
panda-gym-sb3-rl-starter:latest \
sleep infinity
--runtime nvidia で GPU を渡し、リポジトリ全体を /workspace/panda-gym-sb3-rl-starter にマウントしているので、ホスト側で編集したコードはそのままコンテナ内で動きます。
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e4e68636a8b1 panda-gym-sb3-rl-starter:latest "sleep infinity" 9 seconds ago Up 7 seconds panda_gym_sb3
対話シェルに入る
$ docker exec -it panda_gym_sb3 bash
#
コンテナ停止 + 削除
$ docker stop panda_gym_sb3 && docker rm panda_gym_sb3
3.3 ビルド後のテスト
イメージのビルドが終わったら、以下の 2 段階で動作確認を行いました。
第 1 段階: 公式サンプルコード(render_mode="human")
まず、panda-gym 公式 に置かれているサンプルコードを test.py として保存し、Docker 上で動作するかを確認します。

render_mode="human" は X server に GUI ウィンドウを開くため、Jetson のローカル X への接続を 1 度だけ許可しておきます(再起動でリセット)。
$ DISPLAY=:0 xhost +local:
§3.2 で起動した daemon コンテナには X11 オプションを渡していないので、第 1 段階のテストだけは X11 ソケットと DISPLAY を追加した one-shot コンテナ(--rm)で別途起動します。
$ docker run --rm -it \
--runtime nvidia \
--network host \
-e DISPLAY=:0 \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v "$(pwd):/workspace/panda-gym-sb3-rl-starter" \
-w /workspace/panda-gym-sb3-rl-starter \
panda-gym-sb3-rl-starter:latest \
python3 test.py
Jetson のモニタに Bullet Physics のウィンドウが開き、Franka Panda アームがランダム動作すれば成功です。
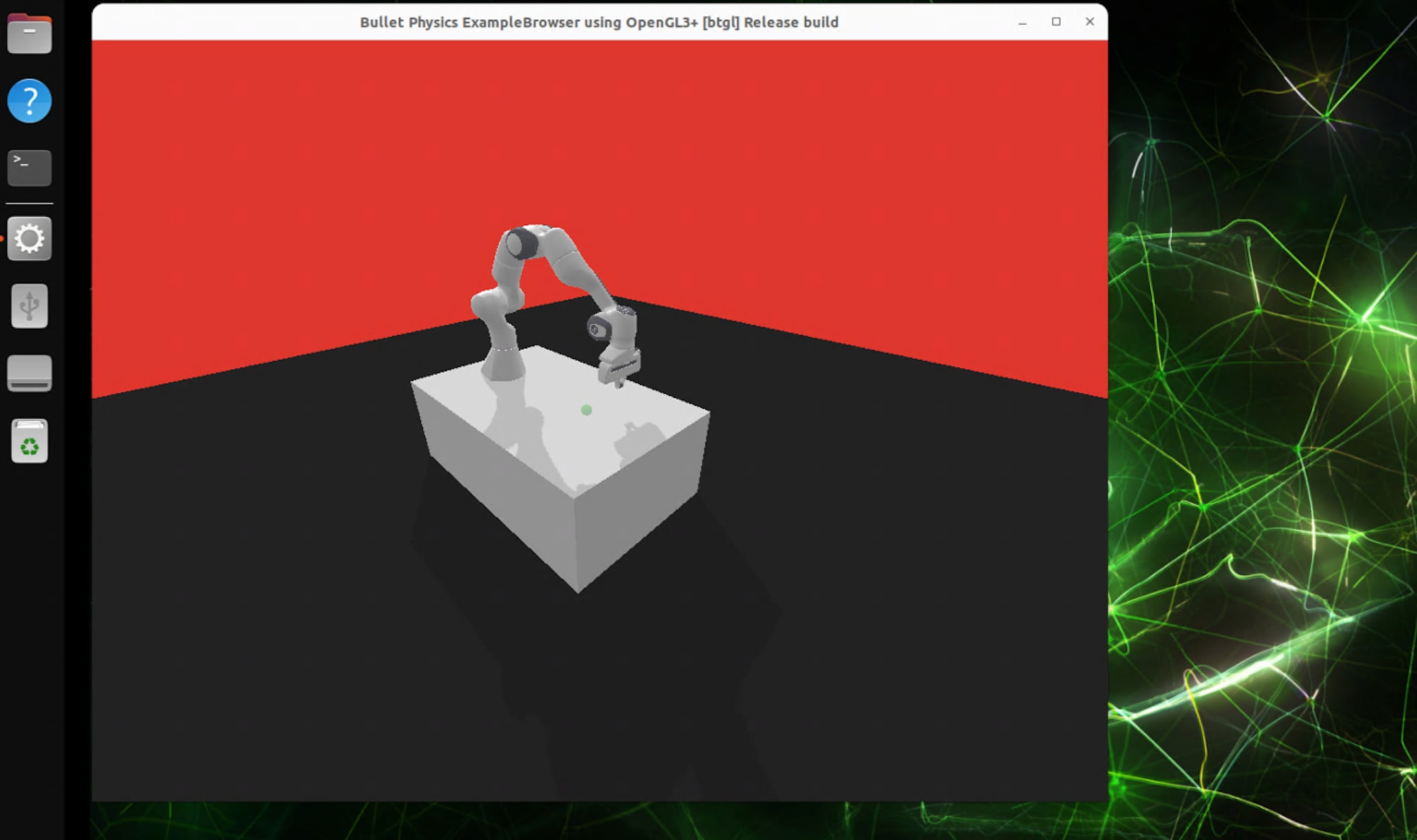
この時点で、Docker コンテナの起動・GPU アクセス(--runtime nvidia)・X11 経由のホスト描画・OpenGL 3+ レンダラ・ソースビルドした PyBullet・panda-gym の URDF ロードと物理シミュレーションが、すべて正常に動作していることが確認できます。
第 2 段階: スモークテスト(render_mode="rgb_array")
Github smoke_test.py
続いて、ヘッドレス描画パス(rgb_array)で PNG を保存できるかを確認します。学習・評価時の動画録画でこのパスを使うため、こちらも事前に通しておきます。
第 2 段階以降は §3.2 で起動した daemon コンテナの中で実行します。docker exec で対話シェルに入り、その中で Python スクリプトを叩く運用です。
$ docker exec -it panda_gym_sb3 bash
# python3 smoke_test.py
PandaReach-v3 を起動して 50 step ランダム行動 → 最初と最後のフレームを smoke_first.png / smoke_last.png に保存する最小スクリプトです。
smoke_test.py(抜粋)
import gymnasium as gym
import imageio
import panda_gym # registers Panda* envs
env = gym.make("PandaReach-v3", render_mode="rgb_array")
observation, info = env.reset(seed=0)
frames = []
for _ in range(50):
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
frames.append(env.render())
if terminated or truncated:
observation, info = env.reset()
env.close()
imageio.imwrite("smoke_first.png", frames[0])
imageio.imwrite("smoke_last.png", frames[-1])
実行すると以下のように環境情報が表示され、PNG が 2 枚保存されます。
# python3 smoke_test.py
pybullet build time: May 1 2026 22:07:57
argv[0]=--background_color_red=0.8745098114013672
argv[1]=--background_color_green=0.21176470816135406
argv[2]=--background_color_blue=0.1764705926179886
env: PandaReach-v3
observation_space: Dict('achieved_goal': Box(-10.0, 10.0, (3,), float32), 'desired_goal': Box(-10.0, 10.0, (3,), float32), 'observation': Box(-10.0, 10.0, (6,), float32))
action_space: Box(-1.0, 1.0, (3,), float32)
observation keys: ['observation', 'achieved_goal', 'desired_goal']
achieved_goal: [ 3.8439669e-02 -2.1944595e-12 1.9740014e-01]
desired_goal: [ 0.04108851 -0.06906398 0.01229206]
frames captured: 50 shape: (480, 720, 3)
saved: smoke_first.png, smoke_last.png
# ls -la *.png
-rw-r--r-- 1 root root 14692 May 2 08:08 smoke_first.png
-rw-r--r-- 1 root root 14384 May 2 08:08 smoke_last.png
| smoke_first(reset 直後) | smoke_last(ランダム 50 step 後) |
|---|---|
 |
 |
右側の smoke_last でアームの姿勢が初期状態から変化しており、緑の goal sphere が描画されていれば、第 1 段階の GUI とは別経路の ヘッドレス描画パス(env.render() 経由の offscreen レンダリング)と PNG 書き出しが出来ていることを確認できます。
4 学習
Github train.py
env と agent のループを回して transition を集め、SAC を更新して学習済みモデルを作るフェーズです。担当スクリプトは train.py です。
train.py(抜粋)
import gymnasium as gym
import panda_gym
from stable_baselines3 import SAC
from stable_baselines3.her.her_replay_buffer import HerReplayBuffer
env = gym.make("PandaReach-v3")
model = SAC(
policy="MultiInputPolicy",
env=env,
replay_buffer_class=HerReplayBuffer,
replay_buffer_kwargs=dict(n_sampled_goal=4, goal_selection_strategy="future"),
learning_rate=1e-3,
buffer_size=1_000_000,
batch_size=256,
gamma=0.95,
tau=0.05,
learning_starts=1000,
policy_kwargs=dict(net_arch=[64, 64], n_critics=1),
verbose=1,
tensorboard_log="logs/tb",
)
model.learn(total_timesteps=25000)
model.save("logs/sac_her_pandareach")
主要パラメータの意図:
MultiInputPolicy:dict observation(observation/achieved_goal/desired_goal)を扱うためn_sampled_goal=4/goal_selection_strategy="future":HER の標準的な設定gamma=0.95:割引率(将来報酬の減衰率)。SAC のデフォルトは 0.99(実効ホライズン約 100 step 相当)だが、Reach は 1 episode 最大 50 step と短く 100 step 先まで考慮する意味が薄いため、0.95(実効ホライズン約 20 step)に下げてバリアンスを抑えているtau=0.05:target network(学習を安定化させるための policy / Q network のコピー)のソフト更新係数。SAC のデフォルト 0.005 の 10 倍にして target を速く追従させる。Reach のように環境が単純で学習が速いタスクではこの方が収束が早いnet_arch=[64, 64]/n_critics=1:goal-conditioned のシンプルなタスクには小さなネットワークで十分
学習ループの仕組みとしては、env が observation を返す → agent(SAC)が action を出す → env が次の observation と sparse reward を返す、というループを 25 000 step 回します(この一連の動きは model.learn(...) の内部で行われています)。HerReplayBuffer は失敗エピソードを「実際の到達点を goal にした成功エピソード」として再ラベルして buffer に追加で詰め直すので、報酬信号がほぼ出ない初期でも学習が前に進みます。SAC は集まった transition バッチで policy network と Q network を更新し、最終的にモデルを logs/sac_her_pandareach.zip に書き出して終了します。
# python3 train.py
ログを見ていると、当初、到達率(success_rate)が、0.2 程度だったものが、学習が進むと、1 (100%) となり、エピソード平均長(ep_len_mean)も 2 程度まで下がっていくことが確認できます。
---------------------------------
| rollout/ | |
| ep_len_mean | 42.2 |
| ep_rew_mean | -42 |
| success_rate | 0.208 |
...
---------------------------------
| rollout/ | |
| ep_len_mean | 2.8 |
| ep_rew_mean | -1.8 |
| success_rate | 1 |
学習中、Jetson AGX Orin の GPU 使用率は 17 % 程度と低めでした。
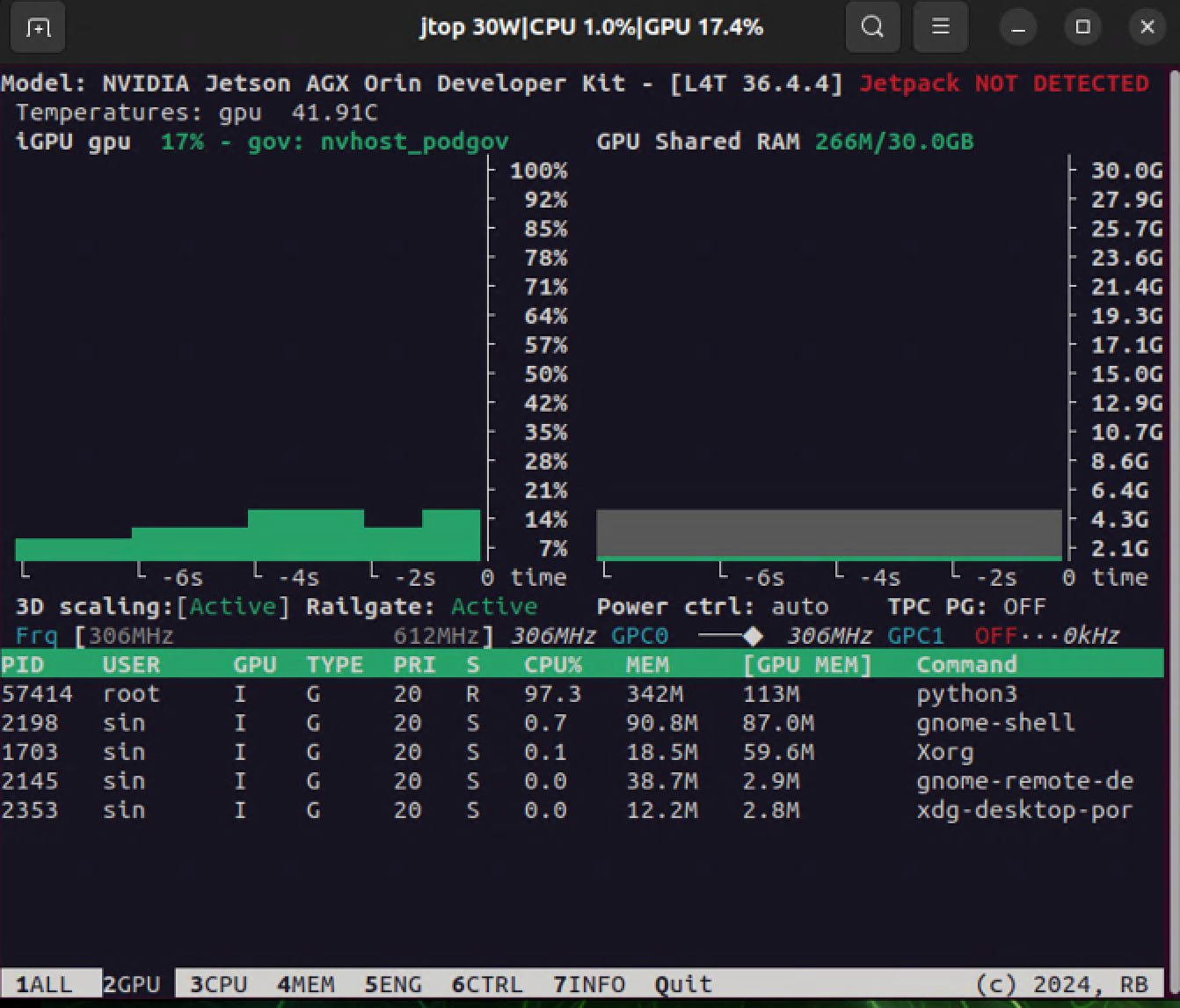
これは PandaReach-v3 が観測 12 次元 / 行動 3 次元という小さなタスクで、ネットワークも net_arch=[64, 64] と極小なので、GPU 1 回あたりの計算がすぐ終わってしまうためです。実際のボトルネックは PyBullet の物理シミュ(CPU)と Python ループの方で、GPU は次のバッチを待っている時間が大半のようです。
約 15 分で生成されるモデルは 190 KB 程度のサイズです。
-rw-r--r-- 1 root root 190618 May 2 18:44 sac_her_pandareach.zip
5 学習結果
5.1 PandaReach-v3 with HER(25 000 step)
| 指標 | 値 |
|---|---|
| 学習時間 | 15 分 12 秒 |
| 学習終了時の rolling success rate | 100 % |
| Deterministic 評価(50 episode) | 100 %(50/50) |
| Mean reward(評価) | -1.80 |
| 平均到達ステップ | 2.81 |
学習曲線を見ると、学習開始から 4500〜5500 step あたりで一気に立ち上がり、5000 step を超えたところで Success Rate(成功率) が 1.0 に張り付く、という綺麗な遷移が観察できます。あわせて Episode Reward Mean(エピソード平均報酬)も -50 付近 → -2 付近にジャンプし、Entropy Coefficient が単調減少していて、policy が決定論寄りに収束している様子が読み取れます。
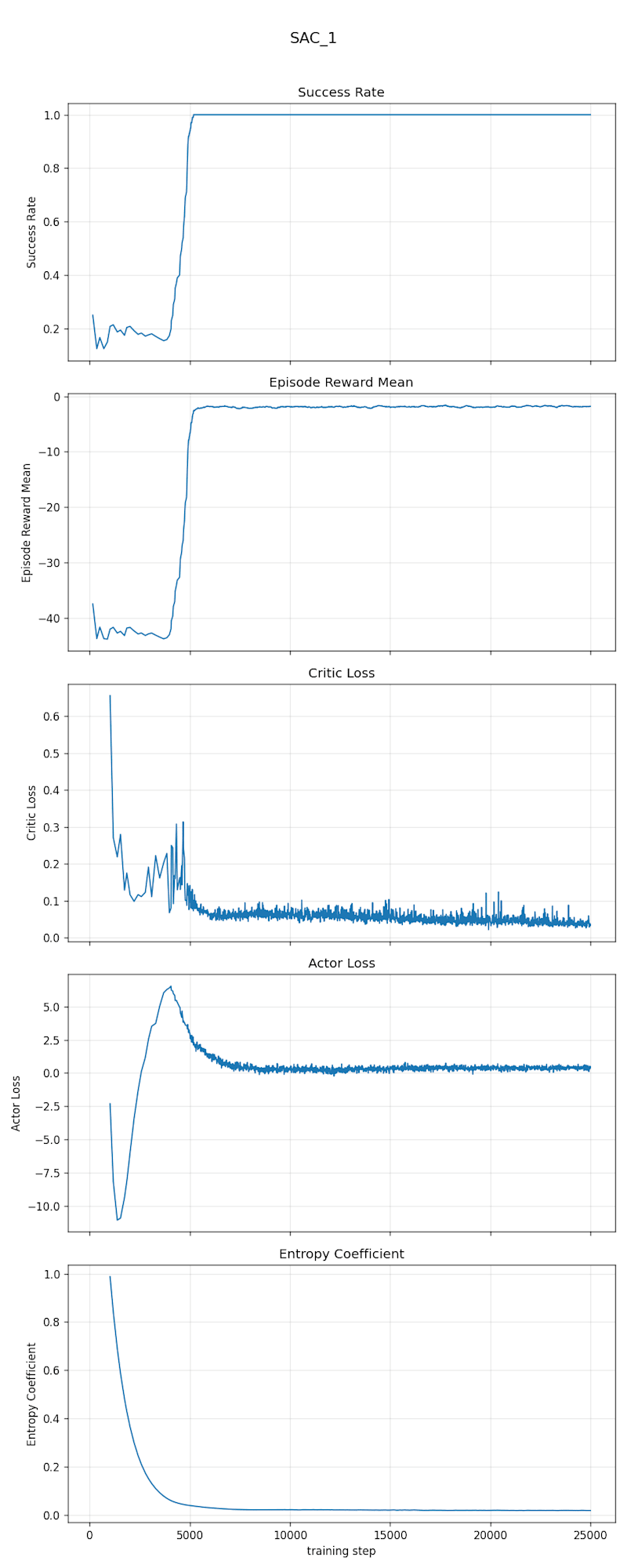
この学習曲線は、TensorBoard ログから plot_curves.py で書き出しています。
Github plot_curves.py
logs/tb/ 配下の run ごとに、success_rate / ep_rew_mean / critic_loss / actor_loss / ent_coef を 縦 5 段に並べた 1 枚の PNG として plots/ に書き出しています。
# python3 plot_curves.py
5.2 HER on / off の比較(PandaReach-v3)
同じハイパラで HER を無効化するとどうなるか、対照実験を行いました(25 000 step、--no-her フラグ)。
| 設定 | 学習時間 | 100 % 達成 step |
|---|---|---|
| HER on | 15 分 12 秒 | 約 5 000 step |
| HER off | 12 分 35 秒 | 約 9 500 step |
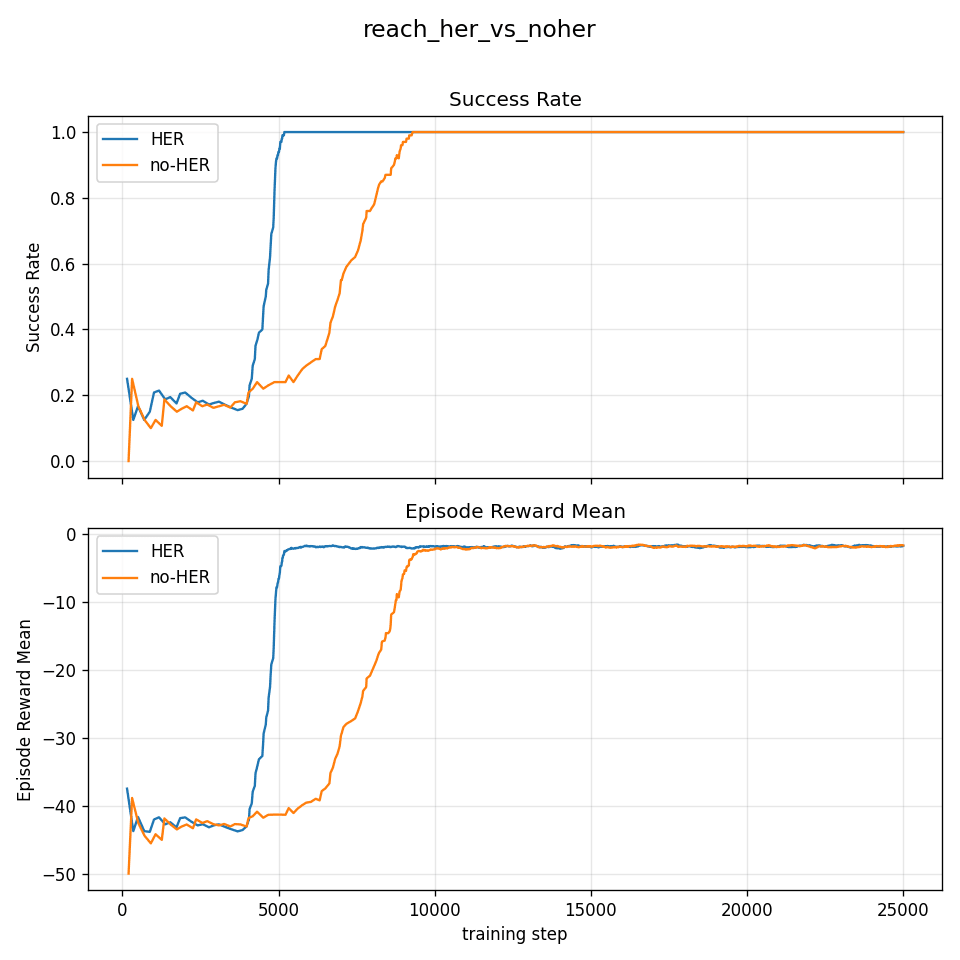
今回は、どちらも 100 %まで到達していますが、HER 有りの方が約 2 倍速く 100 % に到達 しています。(Reach 以外の複雑なタスクでは、HER が必須かもしれません。)
この比較プロットは、plot_compare.py で 2 つの TensorBoard run の success_rate(上段)と ep_rew_mean(下段)を縦 2 段に並べ、各 subplot に 2 本の曲線を重ねたものです。
Github plot_compare.py
# python3 plot_compare.py --runs SAC_1:HER SAC_2:no-HER --name reach_her_vs_noher
6 推論
学習済みモデル(logs/sac_her_pandareach.zip)を deterministic モードで動かして、policy が実際にどう動くかを評価します。eval.py をメインに、加えて学習前のベースライン比較用に demo_random.py を併用します。
6.1 eval.py
Github eval.py
eval.py(抜粋・推論部分のみ)
import gymnasium as gym
import imageio
import numpy as np
import panda_gym # registers Panda* envs
from stable_baselines3 import SAC
env = gym.make("PandaReach-v3", render_mode="rgb_array")
model = SAC.load("logs/sac_her_pandareach", env=env)
successes = 0
rewards = []
frames = []
for episode_index in range(50):
observation, info = env.reset(seed=1000 + episode_index)
episode_reward = 0.0
episode_success = False
for step in range(env.spec.max_episode_steps):
action, _ = model.predict(observation, deterministic=True)
observation, reward, terminated, truncated, info = env.step(action)
episode_reward += float(reward)
frames.append(env.render())
if info.get("is_success"):
episode_success = True
if terminated or truncated:
break
rewards.append(episode_reward)
if episode_success:
successes += 1
env.close()
print(f"success_rate: {successes / 50:.2%} ({successes}/50)")
print(f"mean_reward: {float(np.mean(rewards)):.2f}")
imageio.mimsave("videos/eval.mp4", frames, fps=4)
抜粋では PIL による各フレームへのアノテーション(GOAL マーカー / step カウンタ / 成功失敗枠)と、それに必要な 3D → 2D 投影のカメラ行列ユーティリティ を省略しています。完全版は GitHub を参照してください。
学習済モデルをロードし、env を render_mode="rgb_array" で 50 episode 走らせます。各 step で model.predict(observation, deterministic=True) で action を決定、env.step() で 1 step 進めて env.render() で 720×480 の RGB フレームを取り出します。
各フレームには PIL で次のアノテーションを上書きします:
- 開始時:黄枠 + 「GOAL」マーカー(3D の
desired_goal座標を view/projection 行列で 2D 投影して赤+黄の二重円を描画) - 動作中:白テキストで step カウンタ
- 終了時:緑(成功)/ 赤(失敗)枠 +
step N REACHED/MISSED表示
最後に imageio.mimsave で MP4 化。出力は videos/eval.mp4、加えて成功率と mean_reward を標準出力に表示します。
# python3 eval.py --episodes 50 --video-episodes 30
6.2 学習後の policy の挙動
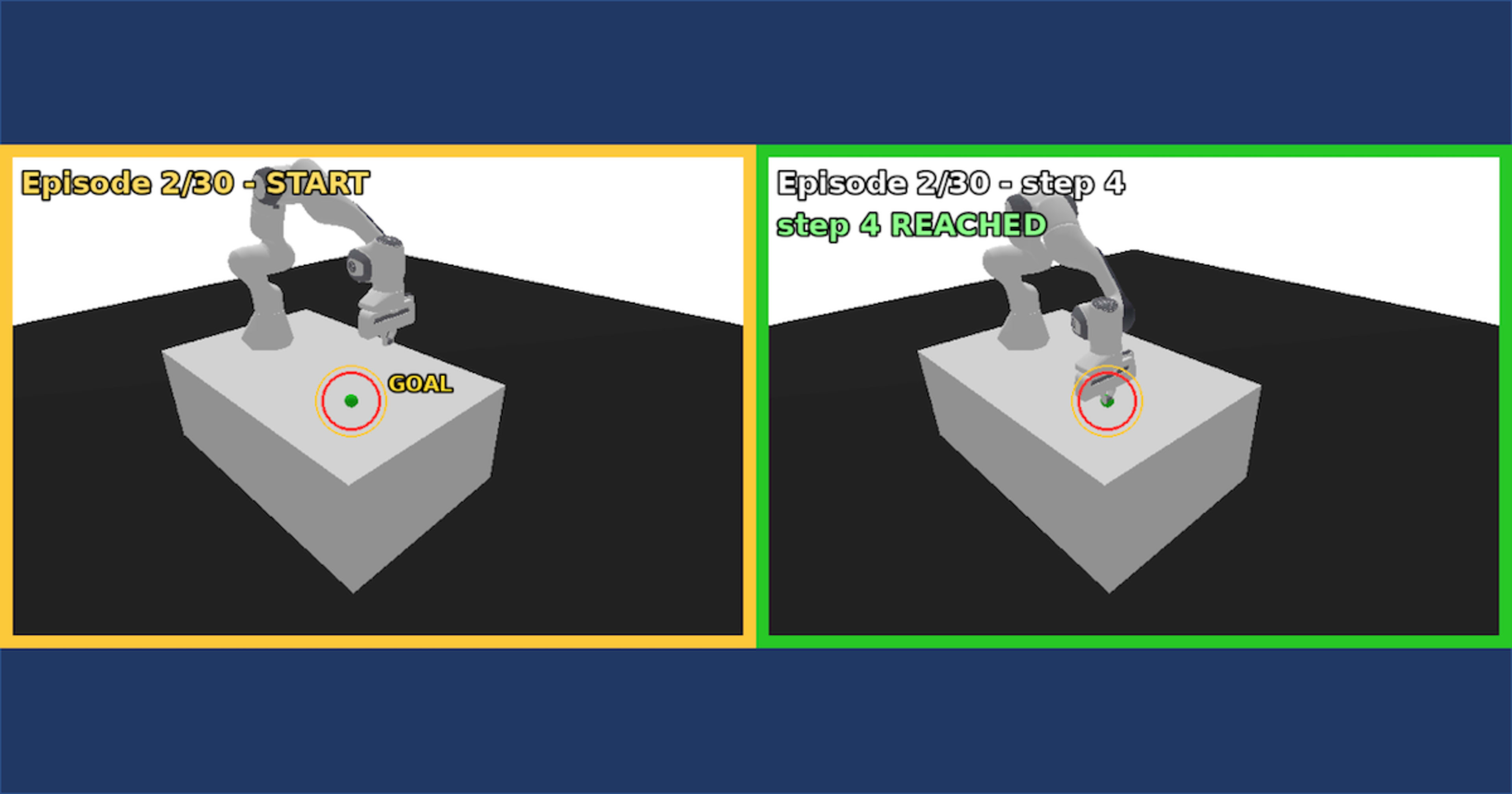
学習後の deterministic policy は、毎回違う goal 位置に対して 1〜3 step で到達します。下は START 状態(左、黄枠 + GOAL マーカー)と REACHED 直後(右、緑枠 + step N REACHED 表示)の代表フレームです。
| START | REACHED |
|---|---|
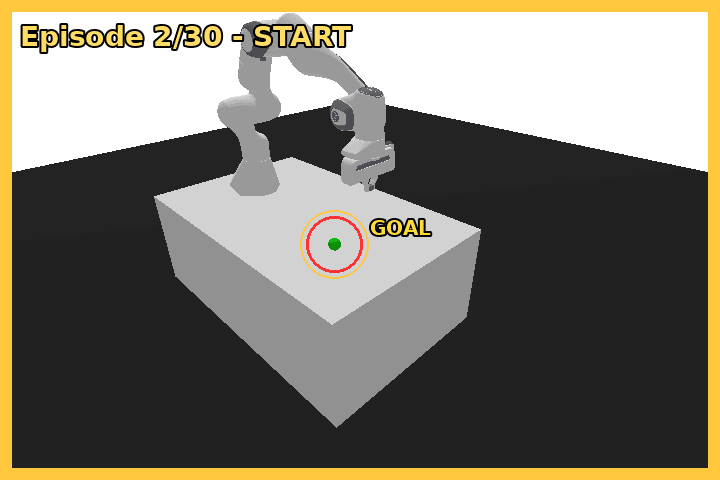 |
 |
6.3 demo_random.py
Github demo_random.py
「学習前」の状態を比較するために demo_random.py を使用しました。中身は eval.py とほぼ同じで、model.predict の代わりに env.action_space.sample()(一様乱数)を呼んでいます。出力は videos/random.mp4 です。
demo_random.py(抜粋・推論部分のみ)
import gymnasium as gym
import imageio
import panda_gym # registers Panda* envs
env = gym.make("PandaReach-v3", render_mode="rgb_array")
successes = 0
frames = []
for episode_index in range(10):
observation, info = env.reset(seed=2000 + episode_index)
episode_success = False
for step in range(env.spec.max_episode_steps):
action = env.action_space.sample()
observation, reward, terminated, truncated, info = env.step(action)
frames.append(env.render())
if info.get("is_success"):
episode_success = True
if terminated or truncated:
break
if episode_success:
successes += 1
env.close()
print(f"random policy: {successes}/10 success")
imageio.mimsave("videos/random.mp4", frames, fps=4)
実行すると videos/random.mp4 に保存されます。
# python3 demo_random.py --episodes 10
7 動画合成
videos/eval.mp4(学習後)と videos/random.mp4(学習前)を ffmpeg の hstack で左右に並べて 1 本にしたものが videos/comparison.mp4 です(短い方の長さに切り詰めています)。
# ffmpeg -i videos/random.mp4 -i videos/eval.mp4 \
-filter_complex "[0:v][1:v]hstack=inputs=2:shortest=1" \
-c:v libx264 -pix_fmt yuv420p \
videos/comparison.mp4
これが、冒頭の動画です。
8 まとめ
今回は、panda-gym + Stable-Baselines3 + SAC + HER + Jetson AGX Orin という組み合わせで、学習・推論を試してみました。
簡単な Reach タスクのみですが 25 000 step / 15 分で 100 % 成功率に到達できました。また、ごく僅かですが、HER の効果も確認できました。
dustynv/pytorch:2.7-r36.4.0 ベースの Docker は、aarch64 Linux + JetPack 6.2.1 の組合せで PyBullet が利用可能だったことは、一つのテンプレになるかもしれません。
ソースは GitHub(https://github.com/furuya02/panda-gym-sb3-rl-starter)に置きました。
9 参考リンク
- panda-gym (GitHub) - PyBullet ベースの Franka Panda アーム RL シミュレータ
- panda-gym (公式ドキュメント) - panda-gym の使い方・タスク一覧
- Stable-Baselines3 (公式ドキュメント) - SB3 全体のドキュメント
- Stable-Baselines3 SAC - SAC の API リファレンス
- Stable-Baselines3 HER - HerReplayBuffer の API リファレンス
- Gymnasium (公式ドキュメント) - Gymnasium API
- PyBullet / Bullet3 (GitHub) - 物理シミュレータ本体