![[Amazon SageMaker] SO-ARM101 を Isaac Lab × Training Job (Managed Spot) で強化学習してみました](https://images.ctfassets.net/ct0aopd36mqt/wp-thumbnail-4e6e510f2f74e1cc7d0ec360f38d138a/c00e9d7f4e47022543b37632bc20bcc0/amazon-sagemaker?w=3840&fm=webp)
[Amazon SageMaker] SO-ARM101 を Isaac Lab × Training Job (Managed Spot) で強化学習してみました
1 はじめに
製造ビジネステクノロジー部の平内(SIN)です。
ここ DevelopersIOには、DGX Spark 上で Isaac Sim と Isaac Lab を使い、6 自由度ロボットアーム SO-ARM101 の Reach タスクを強化学習する非常に丁寧な記事が公開されています。
SO-ARM101 と Isaac Lab を学ぶ起点としてたいへん参考になる内容で、勉強させて頂いていたのですが、残念ながら手元に DGX Spark が無いため、そのまま記事の全てをなぞることが出来ませんでした。
そこで、今回は、環境を AWS で準備し、SO-ARM101 の Reach タスクをやってみました。
AWS 環境での機械学習で気になる点として コスト があると思いますが、本記事では Managed Spot Training を利用することで、1 回のトレーニングが 20 円程度に収まっています。
なお、SO-ARM101 や Isaac Lab の解説、および isaac_so_arm101 パッケージで提供されるタスクの仕様については、前掲の DGX Spark 記事に丁寧にまとめられていますので、そちらをご参照頂ければと思います。
2 検証環境
(1) 構成
作業した環境は、以下のとおりです。
| 項目 | 値 |
|---|---|
| インスタンス | ml.g5.2xlarge(NVIDIA A10G 24GB、8 vCPU、32 GiB RAM) |
| ベースイメージ | nvcr.io/nvidia/isaac-lab:2.3.2(NGC) |
| Isaac Sim | 5.1.0 |
| Isaac Lab | 2.3.2 |
| 強化学習タスク | Isaac-SO-ARM101-Reach-v0 isaac_so_arm101 |
| RL ライブラリ | RSL-RL(PPO) |
インスタンスに ml.g5.2xlarge を選定した理由は次の 3 点です。
- A10G(Ampere 世代)は第 2 世代 RT コアを搭載し、Isaac Sim の動作要件を満たす
- ホスト RAM が 32 GiB あり、Isaac Sim の公式最低要件(32 GB)をクリアする(
ml.g5.xlargeは 16 GiB) ml.g5.2xlarge for training job usageのクォータが標準で 1 立っている(※1)
(※1) g4,g5インスタンスのクォータについては、AWSアカウントを作成したタイミングで違いがあるようです。ご利用の環境で使用できない場合は、上限緩和申請が必要になります。
(2) SageMaker Training Job
AWS で強化学習を回す場合、いろいろな方法がありますが、EC2(GPU)インスタンスや、SageMaker Notebook だと、停止忘れの注意が常に必要になります。
その点、SageMaker Training Job は、ジョブ完了時点にインスタンスが自動で terminate されるので、停止忘れは、構造的に発生しません。
(3) Managed Spot Training
加えて Managed Spot Training を有効にすると、オンデマンドの 50〜70 % 程度の節約が見込めます(今回の作業では58%削減でした)。Spot 中断が発生した場合も、チェックポイントを設定しておけば、自動的に再開されます。
Managed Spot Training を使う場合、以下のパラメータを指定します。
use_spot_instances=Truemax_run:学習の最大実行時間(秒)max_wait:Spot 待機 + 実行を含む合算時間checkpoint_s3_uri:チェックポイントの保存先 S3 URI
(4) コスト
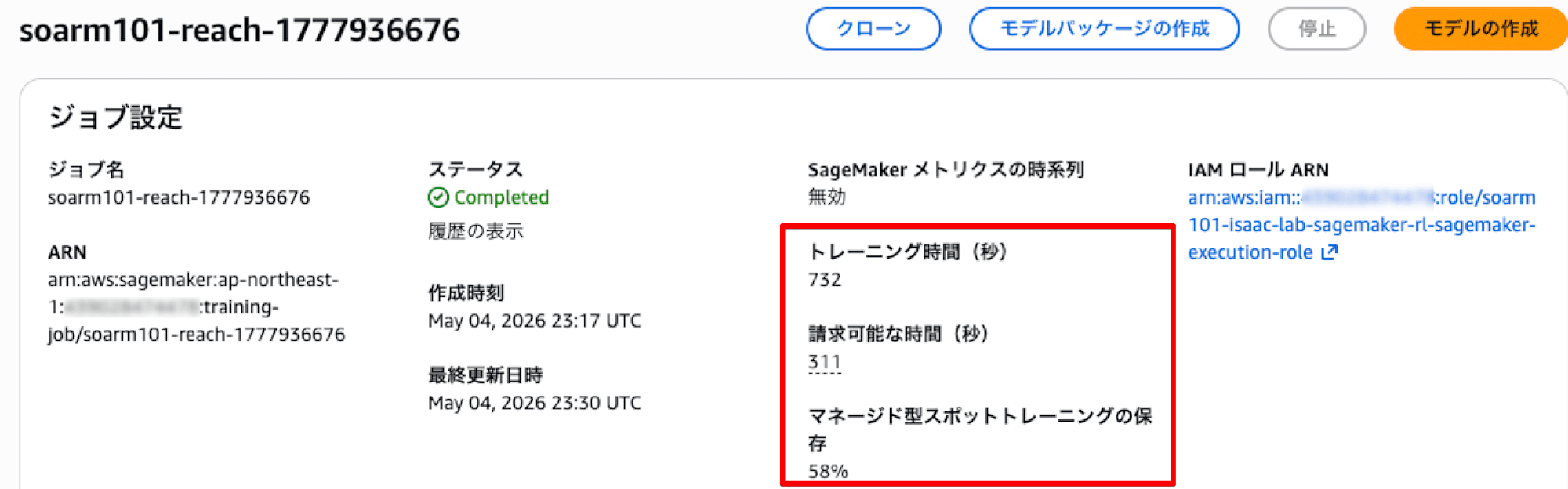
コスト目安は、Managed Spot、58 % off で、1 試行あたり 約 0.13 USD でした。
| 項目 | 値 |
|---|---|
| 学習時間 | 753 秒 |
| 課金時間(BillableTime) | 311 秒 |
| Spot 削減率 | 58 % |
| ml.g5.2xlarge オンデマンド単価(東京) | $1.515 / 時 |
| コスト | 311 / 3600 × $1.515 ≒ $0.13 |
なお、イメージサイズが、圧縮後でも 約 8.5 GB となるため、ECR ストレージ費用にも注意を向けてください。
3 CDK
AWSのベース環境として S3 バケット・ECR リポジトリ・SageMaker 実行ロール(IAM)を、CDKで作成しています。
Github cdk/lib/stack.ts
cd cdk
pnpm install
export AWS_REGION=ap-northeast-1
export ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
cdk bootstrap aws://${ACCOUNT_ID}/${AWS_REGION} # 初回のみ
cdk deploy \
-c account_id=${ACCOUNT_ID} \
-c region=${AWS_REGION}
cdk deploy の最後に出力される BucketName / EcrRepositoryUri / SageMakerRoleArn は、後続処理のため控えておきます。

作成されるリソースは、以下です。
- S3 バケット
soarm101-isaac-lab-sagemaker-rl-<ACCOUNT_ID>(30 日のライフサイクルが設定されています)
- ECR リポジトリ
soarm101-isaac-lab-sagemaker-rl(タグなしの image は 1 日で 削除されます)

- SageMaker 実行ロール
soarm101-isaac-lab-sagemaker-rl-sagemaker-execution-role(AmazonSageMakerFullAccess+ 上記 S3 / ECR への権限)
4 Docker 構成
Dockerは、Isaac Lab の標準的な学習・動画生成の呼び出しを、SageMaker Training Job 上で動かすために薄くラップしたものになっており、主な構成要素は以下です。
- Dockerfile:ベースイメージ(NGC の Isaac Lab 公式コンテナ)の上に必要な最小限の要素を積み上げている
- train.py / play.py / entrypoint.sh:コンテナ実行時に動くラッパースクリプト
- patch_play.py / patch_reach_visualizer.py:Dockerfile の build 中に isaac_so_arm101 にあてるパッチ
たとえば train.py ラッパーが、内部で実行しているコマンドは、
./isaaclab.sh -p scripts/reinforcement_learning/rsl_rl/train.py \
--task Isaac-SO-ARM101-Reach-v0 --headless
Isaac Lab 公式 ドキュメント Reinforcement Learning - Using Existing Scripts の例とほぼ同じで、タスクを Isaac-SO-ARM101-Reach-v0 に差し替えているだけです。
(1) Dockerfile
Github Dockerfile
Dockerfile はベースイメージの上に 5 つのグループを順に積み上げています。
| # | グループ | 役割 |
|---|---|---|
| 1 | ベースイメージ | OS / GPU / Isaac Sim / Isaac Lab / embedded Python |
| 2 | OS パッケージ | ffmpeg / python3 |
| 3 | isaac_so_arm101 | SO-ARM101 用の Reach タスクを embedded Python に install |
| 4 | ビルド時パッチ | isaac_so_arm101 に当てる小修正 |
| 5 | SageMaker 連携 | wrapper / boto3 / EULA 環境変数 / ENTRYPOINT |
以下、グループごとに見ていきます。
グループ 1:ベースイメージ
FROM nvcr.io/nvidia/isaac-lab:2.3.2
NGC が配布する Isaac Lab 公式コンテナです。継承するだけで以下が image 内にすべて揃います。
- Ubuntu ベースの Linux + NVIDIA driver 互換層
- Isaac Sim 5.1 本体(Omniverse Kit、USD、PhysX、RTX renderer)
- Isaac Sim 同梱の embedded Python(CUDA 対応
torch、isaaclab、isaaclab_rl、gymnasium等を最適化版でプリインストール) - Isaac Lab 公式リポジトリ全体が
/workspace/isaaclab/配下に配置(isaaclab.shを含む)
これにより、image 内から /workspace/isaaclab/isaaclab.sh -p ... を呼ぶだけで Isaac Lab 公式の使い方をそのまま実行できます。
グループ 2:OS パッケージ追加
RUN apt-get update \
&& apt-get install -y --no-install-recommends ffmpeg python3 \
&& rm -rf /var/lib/apt/lists/*
ffmpeg は、Isaac Lab の動画録画ラッパー(gymnasium.wrappers.RecordVideo)が使用します。
python3 は、base image の Python ではビルド時パッチを実行できなかったため、スクリプト実行用に標準版を別途追加しています。
グループ 3:isaac_so_arm101(SO-ARM101 用 Reach タスク実装)
ARG ISAAC_SO_ARM101_REF=e4624dea075b00a36dbc66bebd531d191c92e8cd
RUN git clone https://github.com/MuammerBay/isaac_so_arm101.git /opt/isaac_so_arm101 \
&& git -C /opt/isaac_so_arm101 checkout ${ISAAC_SO_ARM101_REF} \
&& /workspace/isaaclab/isaaclab.sh -p -m pip install -e /opt/isaac_so_arm101 --no-deps
公式 Isaac Lab には Franka Panda 等の Reach タスクは含まれていますが、SO-ARM101 用の Reach タスクは入っていません。そのため、 MuammerBay/isaac_so_arm101 を install しています。これにより Isaac-SO-ARM101-Reach-v0 などのタスクが gym レジストリに登録されます。
ISAAC_SO_ARM101_REF で指定したハッシュは、現時点(2026.05.05)の main HEAD に pin するためのものです。
--no-deps を付けているのは、ベースイメージに入っている依存パッケージ(CUDA 対応 torch、isaaclab 本体など)を上書きしてしまわないようにするためです。
グループ 4:ビルド時パッチ
COPY scripts/patch_play.py scripts/patch_reach_visualizer.py /tmp/
RUN python3 /tmp/patch_play.py \
&& python3 /tmp/patch_reach_visualizer.py \
&& rm /tmp/patch_play.py /tmp/patch_reach_visualizer.py
isaac_so_arm101 のソースを書き換える 2 つのスクリプト(後述)を当てています。
グループ 5:SageMaker 連携
ENV ACCEPT_EULA=Y
ENV PRIVACY_CONSENT=Y
RUN /workspace/isaaclab/isaaclab.sh -p -m pip install boto3
WORKDIR /opt/ml/code
COPY src/train.py src/play.py src/entrypoint.sh /opt/ml/code/
RUN chmod +x /opt/ml/code/entrypoint.sh
ENTRYPOINT ["/opt/ml/code/entrypoint.sh"]
SageMaker Training Job 上で動かすためのラッパー層です。
ACCEPT_EULA=Y は、NVIDIA Omniverse の利用規約を環境変数で受諾します。SageMaker は非対話環境のため、起動時の対話受諾ができません。
PRIVACY_CONSENT=Y は、任意ですが、NVIDIA への利用データ送信に opt-in する意思表示です。設定しなくても動作します。詳細は Container Installation - Isaac Sim 公式 Docs を参照してください。
boto3 は、play.py が S3 から学習済モデルを download するために使います。
WORKDIR となっている /opt/ml/code/ は、SageMaker が予約するパスです。
(2) entrypoint.sh
Github entrypoint.sh
Dockerfile の ENTRYPOINT で指定されているスクリプトです。SageMaker のジョブ起動時に呼ばれ、環境変数 MODE の値に応じて学習用の train.py と動画生成用の play.py を切り替えます。
#!/usr/bin/env bash
set -eu
case "${MODE:-train}" in
train) exec /workspace/isaaclab/isaaclab.sh -p /opt/ml/code/train.py "$@" ;;
play) exec /workspace/isaaclab/isaaclab.sh -p /opt/ml/code/play.py "$@" ;;
*) echo "unknown MODE: ${MODE:-train}" >&2; exit 2 ;;
esac
isaaclab.sh -p 経由で呼び出すことで、Isaac Sim 同梱の Python ランタイムから実行できます。
exec を使うと、シェルプロセスがそのまま Python プロセスに置き換わるため、SageMaker から送られる SIGTERM が中間プロセスを介さず Python に届きます。Spot 中断時のチェックポイント保存に必要な動作です。
(3) train.py:チェックポイント自動再開と SIGTERM 対応
Github train.py
内部で呼び出している学習スクリプトの本体は、isaac_so_arm101 同梱の以下です(Dockerfile で pin している commit e4624de 時点)。
isaac_so_arm101/scripts/rsl_rl/train.py
これは Isaac Lab 公式の scripts/reinforcement_learning/rsl_rl/train.py をベースに、Isaac-SO-ARM101-Reach-v0 などのタスクを register するための import を加えた薄い派生で、PPO の学習ループ自体は公式版と同じです。
ただし、この train.py をそのまま SageMaker Training Job + Managed Spot Training の上で動かすには、外側にラッパーを 1 枚噛ませる必要があります。src/train.py がそのラッパーで、追加で次の 4 点を担っています。
(a) 起動時にチェックポイントを自動 resume する
SageMaker は /opt/ml/checkpoints を checkpoint_s3_uri と双方向同期します。Spot 中断後の再起動時には前回までの model_*.pt がここに復元されているので、最新の 1 つを --resume --checkpoint <path> で train.py に渡します。
(b) SIGTERM を child プロセスに転送する
Managed Spot Training は中断時に SIGTERM を送り、約 2 分の grace 後に SIGKILL します。RSL-RL 自身は SIGTERM 受信時に最終チェックポイントを flush してから exit する実装なので、ラッパーは subprocess.Popen で起動した child に SIGTERM を素通しするだけで十分です。
(c) RSL-RL の cwd を /workspace/isaaclab に固定する
RSL-RL は実行ディレクトリ相対の logs/rsl_rl/ にログとチェックポイントを書き出します。cwd="/workspace/isaaclab" を Popen に渡しておかないと、ログが想定外の場所に出てしまい、後段のコピーが空振りします。
(d) 成果物を /opt/ml/model/ にリレーする
/opt/ml/model/ 配下は、ジョブ終了時に SageMaker が tar.gz に固めて output_path の S3 にアップロードします。RSL-RL の logs/rsl_rl/ と /opt/ml/checkpoints/model_*.pt をここにコピーしておくことで、TensorBoard ログと最終チェックポイントを 1 つの model.tar.gz で取り出せるようにしています。
train.py(抜粋)
import os
import shutil
import signal
import subprocess
from pathlib import Path
CKPT_DIR = Path("/opt/ml/checkpoints")
MODEL_DIR = Path("/opt/ml/model")
ISAACLAB_DIR = Path("/workspace/isaaclab")
LOG_DIR = ISAACLAB_DIR / "logs" / "rsl_rl"
CKPT_DIR.mkdir(parents=True, exist_ok=True)
MODEL_DIR.mkdir(parents=True, exist_ok=True)
# (a) 前回までのチェックポイントが復元されていれば resume
ckpts = sorted(CKPT_DIR.glob("model_*.pt"))
resume_args = ["--resume", "--checkpoint", str(ckpts[-1])] if ckpts else []
cmd = [
str(ISAACLAB_DIR / "isaaclab.sh"), "-p",
"/opt/isaac_so_arm101/src/isaac_so_arm101/scripts/rsl_rl/train.py",
"--task", os.environ.get("TASK_NAME", "Isaac-SO-ARM101-Reach-v0"),
"--headless",
"--num_envs", os.environ.get("NUM_ENVS", "64"),
"--max_iterations", os.environ.get("MAX_ITERATIONS", "1000"),
"--logger", "tensorboard",
"--experiment_name", os.environ.get("EXPERIMENT_NAME", "so_arm101_reach"),
*resume_args,
]
# (c) RSL-RL は cwd 相対で logs/ を書くので、isaaclab を cwd にする
proc = subprocess.Popen(cmd, cwd=str(ISAACLAB_DIR))
# (b) Spot 中断時の SIGTERM を child へ素通し
signal.signal(signal.SIGTERM, lambda *_: proc.send_signal(signal.SIGTERM))
return_code = proc.wait()
# (d) 成果物を /opt/ml/model/ にコピー(→ ジョブ終了時に S3 へ自動アップロード)
shutil.copytree(LOG_DIR, MODEL_DIR / "rsl_rl", dirs_exist_ok=True)
for ckpt in CKPT_DIR.glob("model_*.pt"):
shutil.copy2(ckpt, MODEL_DIR / ckpt.name)
(4) play.py
Github play.py
内部で呼び出している再生スクリプトの本体は、isaac_so_arm101 同梱の以下です(Dockerfile で pin している commit e4624de 時点)。
isaac_so_arm101/scripts/rsl_rl/play.py
これは Isaac Lab 公式の scripts/reinforcement_learning/rsl_rl/play.py をベースに、Isaac-SO-ARM101-Reach-Play-v0 などのタスクを register するための import を加えた薄い派生で、policy のロード・推論・mp4 録画ループ自体は公式版と同じです。
src/play.py は、この play.py を SageMaker Training Job の上で動かすため、追加で次の 4 点を担っています。
(a) 学習済モデル(model.tar.gz)を S3 から取得・展開する
play.py 本体は --checkpoint <path> というローカルパスしか受け付けません。SageMaker 上では学習ジョブの成果物が S3 にしかないので、ラッパー側で環境変数 MODEL_S3_URI が指す model.tar.gz を boto3 で download して WORK_DIR に展開する必要があります。
(b) 最新のチェックポイントを自動選択する
model.tar.gz には学習途中で保存された複数の model_*.pt が含まれていることがあります。末尾の番号が最大のもの(例:model_999.pt)を選んで --checkpoint に渡します。
(c) cwd を /workspace/isaaclab に固定する
train.py ラッパーと同じ理由です。isaaclab.sh の内部処理が cwd 相対のパスに依存しているため、subprocess.run(..., cwd=str(ISAACLAB_DIR)) で固定しておきます。
(d) 録画された mp4 を /opt/ml/model/videos/ にリレーする
play.py は録画した mp4 を「checkpoint と同じディレクトリ」(つまり WORK_DIR 配下)の videos/ に書き出します。そのままでは SageMaker の S3 自動アップロード対象から外れるため、/opt/ml/model/videos/ に明示コピーすることで、output/<play-job>/output/model.tar.gz の中に動画が含まれるようにしています。
play.py(抜粋)
import os
import shutil
import subprocess
import tarfile
from pathlib import Path
from urllib.parse import urlparse
import boto3
ISAACLAB_DIR = Path("/workspace/isaaclab")
MODEL_DIR = Path("/opt/ml/model")
WORK_DIR = Path("/opt/ml/code/play_work")
WORK_DIR.mkdir(parents=True, exist_ok=True)
MODEL_DIR.mkdir(parents=True, exist_ok=True)
# (a) S3 から学習済モデルを取得して展開
parsed = urlparse(os.environ["MODEL_S3_URI"])
tarball = WORK_DIR / "model.tar.gz"
boto3.client("s3").download_file(parsed.netloc, parsed.path.lstrip("/"), str(tarball))
with tarfile.open(tarball, "r:gz") as tf:
tf.extractall(WORK_DIR)
# (b) 末尾番号が最大の model_*.pt を選択
ckpt = sorted(WORK_DIR.rglob("model_*.pt"), key=lambda p: int(p.stem.split("_")[-1]))[-1]
cmd = [
str(ISAACLAB_DIR / "isaaclab.sh"), "-p",
"/opt/isaac_so_arm101/src/isaac_so_arm101/scripts/rsl_rl/play.py",
"--task", os.environ.get("TASK_NAME", "Isaac-SO-ARM101-Reach-Play-v0"),
"--headless",
"--video",
"--video_length", os.environ.get("VIDEO_LENGTH", "200"),
"--num_envs", os.environ.get("NUM_ENVS", "4"),
"--checkpoint", str(ckpt),
]
# (c) play.py も cwd を /workspace/isaaclab に固定
proc = subprocess.run(cmd, cwd=str(ISAACLAB_DIR))
# (d) 録画 mp4 を /opt/ml/model/videos/ にコピー(→ ジョブ終了時に S3 へ自動アップロード)
for videos in WORK_DIR.rglob("videos"):
if videos.is_dir() and any(videos.iterdir()):
shutil.copytree(videos, MODEL_DIR / "videos", dirs_exist_ok=True)
break
(5) ビルド時パッチ:patch_play.py
Github patch_play.py
isaac_so_arm101 の main ブランチ(commit e4624de)に含まれる play.py は、先頭付近の import で次のエラーになります。
ModuleNotFoundError: No module named 'isaaclab.utils.pretrained_checkpoint'
この問題は前掲の DGX Spark 記事でも触れられており、同記事内では try-except でラップする手順が紹介されています。本記事では同等の対応を Docker ビルド時のパッチで自動化しており、差分は次の 1 行です。
# Before(isaac_so_arm101 の play.py、旧 path)
from isaaclab.utils.pretrained_checkpoint import get_published_pretrained_checkpoint
# After(パッチ後、新 path)
from isaaclab_rl.utils.pretrained_checkpoint import get_published_pretrained_checkpoint
(6) ビルド時パッチ:patch_reach_visualizer.py
Github patch_reach_visualizer.py
isaac_so_arm101 の Reach 環境(reach_env_cfg.py)はデフォルトで、ゴール姿勢のマーカーが Isaac Lab 標準の frame marker(XYZ 軸の矢印) になります。これが、ちょっと分かりにくかったので、reach_env_cfg.py を Docker ビルド時に書き換え、goal_pose_visualizer_cfg を マゼンタの球(半径 0.025 m)に置換しています。
挿入される marker 定義の抜粋:
GOAL_SPHERE_MARKER_CFG = VisualizationMarkersCfg(
prim_path="/Visuals/Command/goal_sphere",
markers={
"goal": sim_utils.SphereCfg(
radius=0.025,
visual_material=sim_utils.PreviewSurfaceCfg(
diffuse_color=(1.0, 0.0, 1.0) # マゼンタ(赤・緑・青の座標軸と被らない色)
),
),
},
)
マーカー定義は、Isaac Lab の公式 API ドキュメントとリポジトリから次の 3 点を引いて組み立てています。
- 差し替え先と雛形:Isaac Lab 標準の
reach_env_cfg.pyにはgoal_pose_visualizer_cfg: VisualizationMarkersCfgという field があり、任意のVisualizationMarkersCfgインスタンスに差し替え可能。雛形(VisualizationMarkersCfg(prim_path=..., markers={...})の構造と/Visuals/Command/...の命名規約)はisaaclab/markers/config.pyのFRAME_MARKER_CFGからそのまま借用 - 形状:
isaaclab.sim.spawners.shapesが用意するSphereCfg/CuboidCfg/CylinderCfg/CapsuleCfg/ConeCfgのうち、ゴール(点)の表現として最も自然なSphereCfgを選択 - 色付け:
PreviewSurfaceCfg(Omniverse の標準 PBR マテリアル)のdiffuse_color: tuple[float, float, float](RGB 各成分[0, 1])をSphereCfgのvisual_materialに渡す
この 3 段(VisualizationMarkersCfg + SphereCfg + PreviewSurfaceCfg)の組み合わせで、本記事のマーカー定義となっています。
5 ECR への push
Github push_to_ecr.sh
リポジトリ root に同梱の scripts/push_to_ecr.sh でログイン・ビルド・push を一括実行できます。事前に NGC(nvcr.io)へのログインが必要です。
cd .. # リポジトリ root に戻る
docker login nvcr.io # NGC Personal Key を使ってログイン
./scripts/push_to_ecr.sh
6 ジョブ起動
Github submit.py
submit.py(抜粋)
import os
import sagemaker
from sagemaker.estimator import Estimator
session = sagemaker.Session()
account_id = session.boto_session.client("sts").get_caller_identity()["Account"]
region = session.boto_region_name
image_uri = f"{account_id}.dkr.ecr.{region}.amazonaws.com/soarm101-isaac-lab-sagemaker-rl:latest"
bucket = f"soarm101-isaac-lab-sagemaker-rl-{account_id}"
role = os.environ["SAGEMAKER_ROLE_ARN"]
estimator = Estimator(
image_uri=image_uri,
role=role,
instance_count=1,
instance_type="ml.g5.2xlarge",
output_path=f"s3://{bucket}/output/",
use_spot_instances=True,
max_run=1 * 3600, # 学習自体は1時間以内を想定
max_wait=2 * 3600, # Spot待機含めて最大2時間
checkpoint_s3_uri=f"s3://{bucket}/checkpoints/",
checkpoint_local_path="/opt/ml/checkpoints",
environment={
"NUM_ENVS": "64",
"MAX_ITERATIONS": "1000",
},
)
estimator.fit()
環境変数に必要な値をセットして、submit.pyを実行します。
export AWS_REGION=ap-northeast-1
export ACCOUNT_ID=$(aws sts get-caller-identity --query Account --output text)
export SAGEMAKER_ROLE_ARN=arn:aws:iam::${ACCOUNT_ID}:role/soarm101-isaac-lab-sagemaker-rl-sagemaker-execution-role
export ECR_IMAGE_URI=${ACCOUNT_ID}.dkr.ecr.${AWS_REGION}.amazonaws.com/soarm101-isaac-lab-sagemaker-rl:latest
export S3_BUCKET=soarm101-isaac-lab-sagemaker-rl-${ACCOUNT_ID}
python submit.py
ジョブの進行状況は AWS マネジメントコンソールの SageMaker > Training jobs から確認できます。
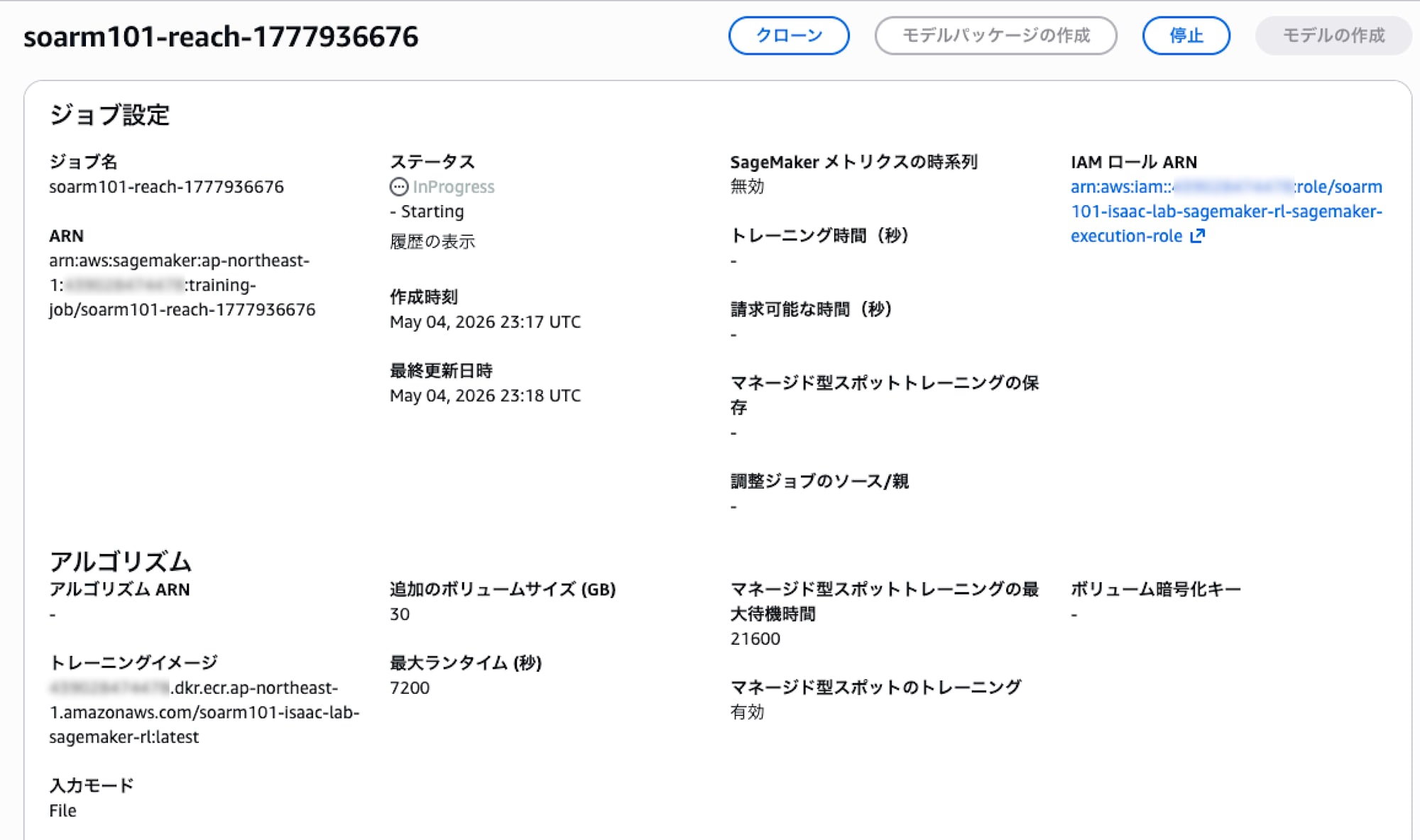
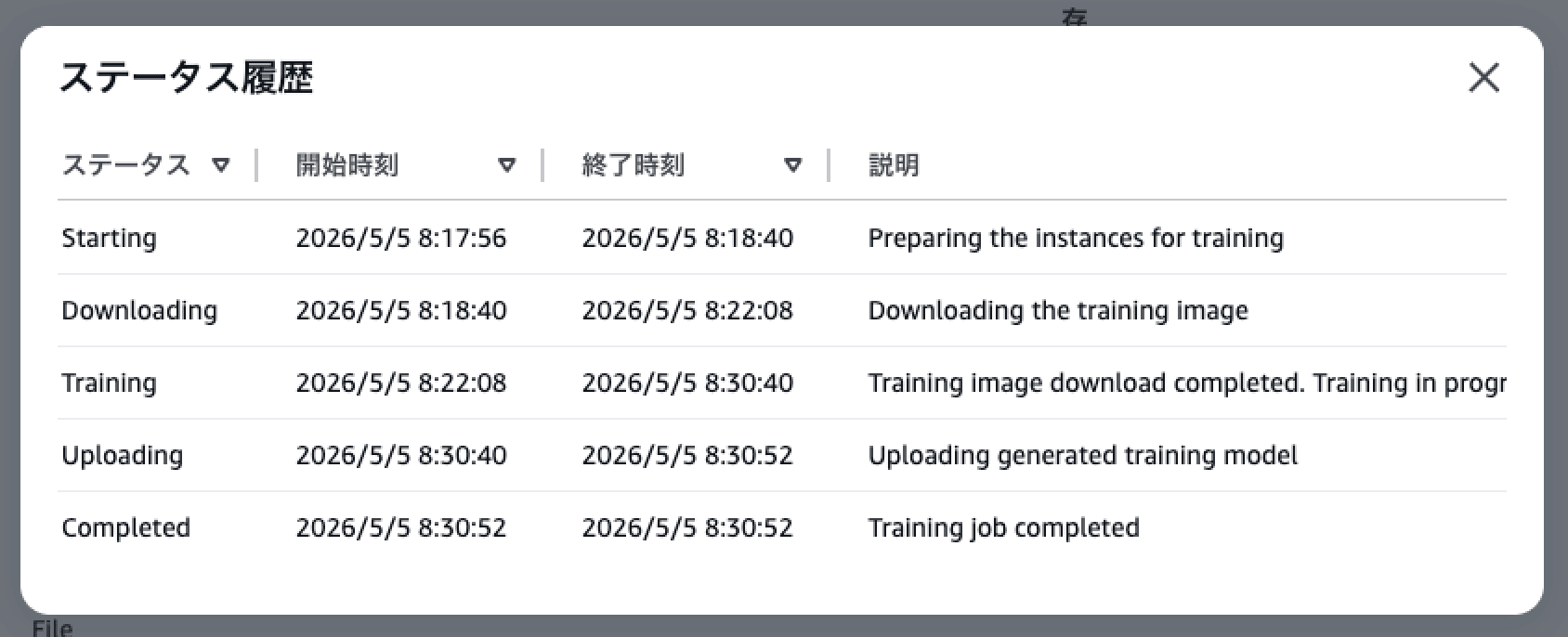
完了時点で、トレーニング時間、請求時間、スポットの割引率が表示されています。
完了後に s3://<bucket>/output/<job-name>/output/model.tar.gz として成果物が保存されます。
$ s3-tree soarm101-isaac-lab-sagemaker-rl-XXXXXXXXXXXX
soarm101-isaac-lab-sagemaker-rl-XXXXXXXXXXXX
└── output
└── soarm101-reach-1777936676
├── debug-output
│ └── training_job_end.ts
├── output
│ └── model.tar.gz
└── profiler-output
├── framework
│ └── training_job_end.ts
└── system
├── incremental
│ └── 2026050423
│ ├── 1777936680.algo-1.json
│ ├── 1777936740.algo-1.json
│ ├── 1777936800.algo-1.json
│ ├── 1777936860.algo-1.json
│ ├── 1777936920.algo-1.json
│ ├── 1777936980.algo-1.json
│ ├── 1777937040.algo-1.json
│ ├── 1777937100.algo-1.json
│ ├── 1777937160.algo-1.json
│ ├── 1777937220.algo-1.json
│ ├── 1777937280.algo-1.json
│ ├── 1777937340.algo-1.json
│ └── 1777937400.algo-1.json
└── training_job_end.ts
7 学習結果
学習が完了すると、成果物は s3://<bucket>/output/<job-name>/output/model.tar.gz にアップロードされます。本節ではジョブの完走確認と、policy の動作を動画で確認する手順を扱います。
(1) 学習ログでの確認
学習が完走したかどうかは、CloudWatch Logs(log group /aws/sagemaker/TrainingJobs、log stream <job-name>/algo-1-*)の最後を見るのが早いです。

Learning iteration 999/1000
Computation: 3623 steps/s (collection: 0.269s, learning 0.155s)
Mean action noise std: 0.11
Mean value_function loss: 0.0002
Mean surrogate loss: -0.0062
Mean entropy loss: -5.0717
Mean reward: 0.21
Mean episode length: 360.00
Episode_Reward/end_effector_position_tracking: -0.0223
Episode_Reward/end_effector_position_tracking_fine_grained: 0.0238
Episode_Reward/end_effector_orientation_tracking: 0.0000
Episode_Reward/action_rate: -0.0009
Episode_Reward/joint_vel: -0.0007
Curriculum/action_rate: -0.0050
Curriculum/joint_vel: -0.0010
Metrics/ee_pose/position_error: 0.0992
Metrics/ee_pose/orientation_error: 3.0592
Episode_Termination/time_out: 1.0000
--------------------------------------------------------------------------------
Total timesteps: 1536000
Iteration time: 0.42s
Time elapsed: 00:07:13
ETA: 00:00:00
確認ポイントは次の 3 点です。
Learning iteration 999/1000まで到達している(途中で落ちていない)Mean rewardがプラスで安定(policy が報酬を獲得できている。本ジョブは 0.21)Metrics/ee_pose/position_errorが 0.1 m 前後に収束(エンドエフェクタとゴールの距離。本ジョブは 0.0992 m(約 10 cm))
Episode_Termination/time_out: 1.0000 は、全エピソードが物理エラー(衝突・ジョイント上限違反など)で途中終了せず、時間切れまで正常完走したことを示します。
(2) 学習済モデルから動画を生成する
本記事では、学習済の policy を再生して mp4 動画を出力するジョブを用意しています(ラッパー実装は §4 (4) play.py 参照)。
下記のように MODE=play で submit.py を実行します(JOB_NAME には学習ジョブ名をセット)。
export JOB_NAME=<学習 submit.py の出力に表示されたジョブ名>
MODE=play \
MODEL_S3_URI=s3://${S3_BUCKET}/output/${JOB_NAME}/output/model.tar.gz \
USE_SPOT=true MAX_RUN_HOURS=1 MAX_WAIT_HOURS=2 \
python submit.py
ジョブ完了後、動画は s3://<bucket>/output/<play-job>/output/model.tar.gz の中の videos/*.mp4 として取り出せます。
$ tree .
.
├── model.tar.gz
└── videos
└── play
└── rl-video-step-0.mp4
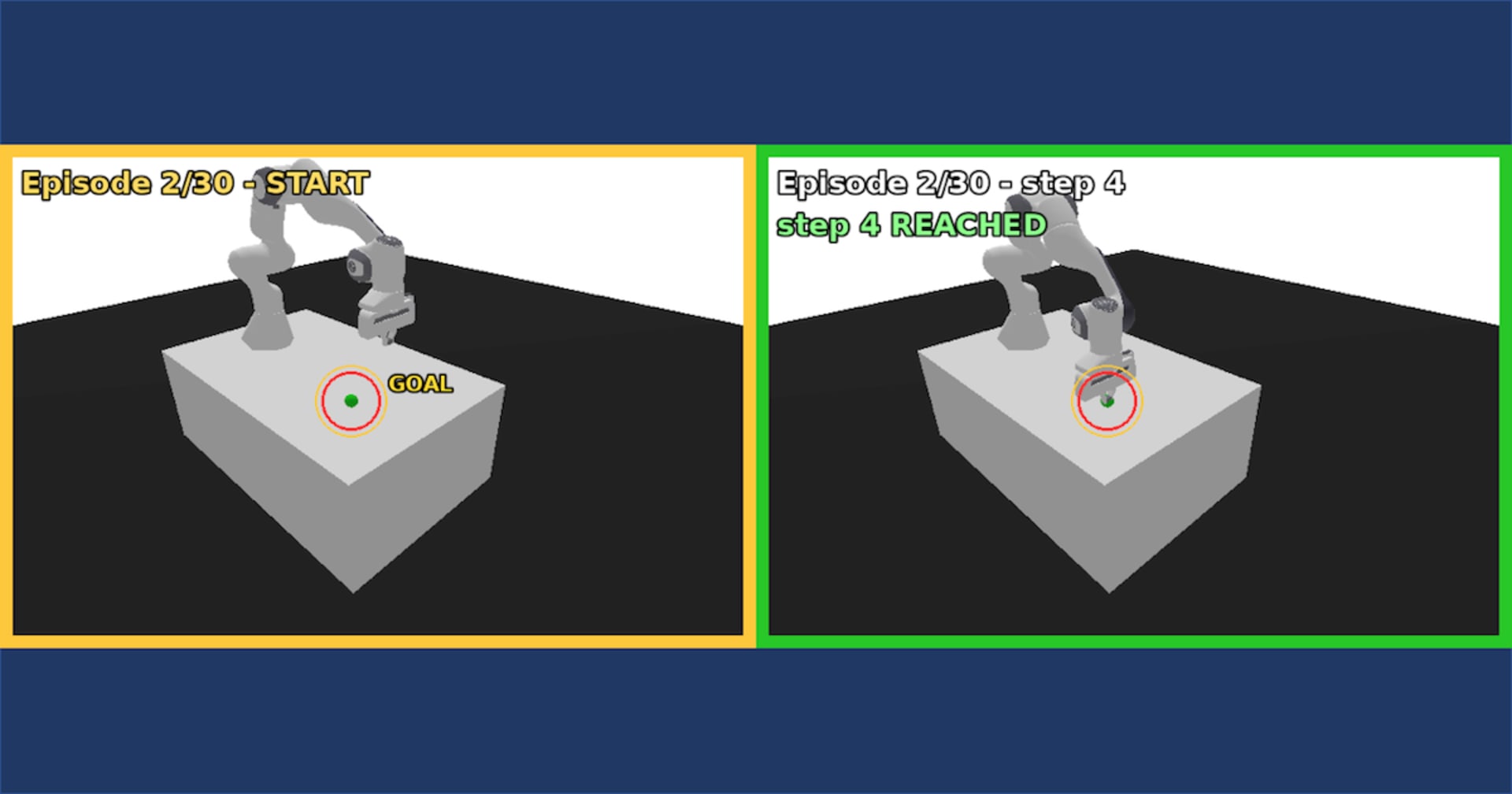
下記は実際に得られた動画から切り出した画像です。

学習済 policy が マゼンタ球(ゴール)を追従する 1 episode 約 6 秒の動画から切り出した静止画です。1 episode ごとにゴール球が新しい位置にランダム再配置され、アームが追従します。本ジョブの最終
position_errorは 0.0992 m(約 10 cm)で完璧追従ではないため、ピック & プレースなど精密操作を行う場合は、学習回数をもっと伸ばすチューニングが必要そうです。
8 まとめ
今回は、AWS の SageMaker Training Job + Managed Spot Training で SO-ARM101 の Reach タスクを Isaac Lab で強化学習する手順を試してみました。
NGC が提供する nvcr.io/nvidia/isaac-lab:2.3.2 をベースイメージとして使用すれば、Dockerfile で追加するのは ffmpeg / isaac_so_arm101 / SageMaker 用ラッパーなど最小限で済みます。
DGX Spark や RTX 搭載の PC が手元に無くても、AWS で SO-ARM101 の Reach タスクを学習できてよかったです。