
Personalizeの運用に必要なアップデートパターンを整理して実際にアップデートさせてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データアナリティクス事業本部機械学習チームの中村です。
今回は、Amazon Personalizeで運用時などにモデルをアップデートしていく際に必要となる機能について紹介します。
また実際に一例としてeventを記録するためのevent trackerを使ってイベントを記録し、その後レコメンデーション結果がどのように変化するか見ていきます。
冒頭まとめ
- eventの記録にはevent trackerが必要。items、usersの更新はtrackerが不要。
- レコメンデーションはput eventsにより以下のタイミングで結果が変わりうる(レシピによる)。
- put eventsに含まれるuserIdは入力に反映され即時結果が変わる。
- 含まれないuserIdも2時間後にはモデルの自動更新により変わる。
- 手動でモデル再学習するともちろん変わる。
- 自動更新の場合は、solutionVersionのlastUpdatedDateTimeに時刻が反映されない(現状)。
- put eventsされたものは、exportで後から確認できる。
- これはevent trackerを消した後でも問題ない。
アップデートの仕組み
アップデートはInteractions, Items, Usersそれぞれについて行えます。
-
Interactions
- Interactionsはevent trackerを作成し、それを用いてput_eventsを実行します。
- Putされたイベントは、同じユーザーに対するレコメンデーションを生成する際に即座に使用されます。(CustomレシピのSIMSまたはPopularity-Countを除く)
- モデルの更新ではなく、即座にモデルの入力データとして使われるという意味だと思われます。
- またモデルの更新時にも使われると考えられます。
-
Items
- Itemsは、put_itemsによりアップデートができます。event trackerは使いません。
- モデルの更新(trainingMode='UPDATE', 'FULL'どちらでも)により反映されます。
-
Users
- Usersは、put_usersによりアップデートができます。event trackerは使いません。
- 新規ユーザーの場合、当初は人気アイテムのみのレコメンドとなります。
- 最初のイベントから、イベント記録を増やしていくことで、ユーザーへPersonalizeされます。
Interactions, Items, UsersそれぞれDatasetさえ作成しておけば、データは空でもputすることができます。
そのため、モデルを学習して構築する前のデータ収集段階で、schemaのみ定義しDatasetを作成することで、データを登録していくことも可能です。
モデル自動更新について
Amazon Personalizeは、特定のレシピを選択するとアップデートされたデータを元にモデルを自動更新します。
自動更新が行われるのは、以下のレシピとなります。
- ユーザー個人にPersonalizeされるレシピは、高頻度(2時間毎)に更新されます。
- Domain特化レシピはライフサイクルをRecommender側に一任するため、trainingModeが
UPDATEなのかFULLなのか不明ですが、組み合わせて最適なものが選択されていると予想されます。 - CutomレシピもUser-Personalizationのみモデル自動更新が実施されますが、別途週1回手動で
trainingMode="FULL"で再学習することが推奨されています。
| Recipe | Type | モデル更新頻度 | 備考 |
|---|---|---|---|
| User-Personalization | Custom | 2時間毎 | trainingMode="UPDATE"のため、別途週1回手動でtrainingMode="FULL"で再学習することが推奨。 |
| Top picks for you | VIDEO ON DEMAND | 2時間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
| Recommended for you | ECOMMERCE | 2時間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
| Most popular | VIDEO ON DEMAND | 1週間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
| Because you watched X | VIDEO ON DEMAND | 1週間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
| More like X | VIDEO ON DEMAND | 1週間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
| Most viewed | ECOMMERCE | 1週間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
| Best sellers | ECOMMERCE | 1週間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
| Frequently bought together | ECOMMERCE | 1週間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
| Customers who viewed X also viewed | ECOMMERCE | 1週間毎 | ライフサイクルをRecommender側が管理するため、trainingModeは不明。 |
上記に記載されていないCustomレシピは、手動で再学習が必要なレシピとなります。
モデルの手動再学習
Customレシピはモデルの再学習が必要です。前述のとおり、User-Personalizationは2時間毎に自動更新をしてくれますが、UPDATEモードのみですので、週1回FULLモードでの学習が推奨されています。
再学習は、solutionVersionを再作成します。作成後は、以前のsolutionVersionの自動更新は行われなくなり、最新のsolutionVersionのみ自動更新が有効となります。
匿名ユーザーの扱い
put_eventsには、userIdとは別にsessionId(required)を渡す必要があります。
ログインした後に同じsessionIdを使ってput_eventsを行えば、以前のアクションをsessionIdを用いて紐づけして、イベント履歴を扱うことができます。
実際に動きを確認してみる。
今回はCustomのUser-Personalizationレシピを使います。
Modules
import boto3
from boto3.session import Session
import json
from datetime import date, datetime
import time
import pandas as pd
import numpy as np
データ作成
- ml-test-small.zipのrating.csvを元にカラムを編集・追加します。
- カラム名はルールがあるので、それに沿ってリネームします。
- train:test=4:1で分割し、test側が未来のタイムスタンプになるようにします。
df_ratings = pd.read_csv("ml-latest-small/ratings.csv")
# columnsの書き換え
df_ratings = df_ratings.rename(columns={'userId': 'USER_ID', 'movieId': 'ITEM_ID', 'timestamp': 'TIMESTAMP'})
# ratingを削除
df_ratings = df_ratings.drop('rating', axis=1)
# train/test分割
df_ratings_train = df_ratings.sort_values('TIMESTAMP')[:len(df_ratings)//5*4]
df_ratings_test = df_ratings.sort_values('TIMESTAMP')[len(df_ratings)//5*4:]
df_ratings_train.to_csv("./ratings_train.csv", index=False)
df_ratings_test .to_csv("./ratings_test.csv" , index=False)
変数の事前定義
prefix = 'your bucket name'
region_name = 'ap-northeast-1'
bucket_name = f'{prefix}'
import_s3_uri_interaction = f's3://{bucket_name}/interactions.csv'
export_s3_uri_events = f's3://{bucket_name}/export/'
dataset_group_name = f'{prefix}-dataset-group'
schema_interaction_name = f'{prefix}-schema-interaction'
dataset_interaction_name = f'{prefix}-dataset-interaction'
import_job_interaction_name = f'{prefix}-import-job-interaction'
solution_name = f'{prefix}-solution-user-personalize'
iam_role_name = f'{prefix}-personalize-exection-role'
iam_custom_policy_name = f'{prefix}-personalize-execution-policy'
campaign_name = f'{prefix}-campaign'
event_tracker_name = f'{prefix}-event-tracker'
export_job_name = f'{prefix}-export-job'
client_s3 = boto3.client('s3', region_name=region_name)
client_personalize = boto3.client('personalize', region_name=region_name)
client_personalize_events = boto3.client('personalize-events', region_name=region_name)
client_personalize_runtime = boto3.client('personalize-runtime', region_name=region_name)
client_iam = boto3.client('iam', region_name=region_name)
S3 bucketの作成と設定
- bucket policyはexport用に
s3:PutObjectもつけます。
# create_bucket
location = {'LocationConstraint': region_name}
client_s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration=location)
# put_public_access_block
client_s3.put_public_access_block(
Bucket=bucket_name,
PublicAccessBlockConfiguration={
'BlockPublicAcls': True,
'IgnorePublicAcls': True,
'BlockPublicPolicy': True,
'RestrictPublicBuckets': True,
},
)
# create bucket_policy
bucket_policy = {
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket",
"s3:PutObject"
],
"Resource": [
f"arn:aws:s3:::{bucket_name}",
f"arn:aws:s3:::{bucket_name}/*"
]
}
]
}
bucket_policy = json.dumps(bucket_policy)
# put_bucket_policy
client_s3.put_bucket_policy(
Bucket=bucket_name,
Policy=bucket_policy,
)
S3 bucketへのアップロード
- trainデータをアップロードします。
interactions_csv = pathlib.Path('./ratings_train.csv')
response = client_s3.upload_file(
str(interactions_csv),
bucket_name,
'interactions.csv',
)
Domain dataset group作成
- domain未指定で
Customを作成できます。
response_create_dataset_group = client_personalize.create_dataset_group(
name=dataset_group_name,
)
Schema作成
- Interactionsのみをデータとして使います。
schema_interaction = {
"type": "record",
"name": "Interactions",
"namespace": "com.amazonaws.personalize.schema",
"fields": [
{
"name": "USER_ID",
"type": "string"
},
{
"name": "ITEM_ID",
"type": "string"
},
{
"name": "TIMESTAMP",
"type": "long"
},
{
"name": "EVENT_TYPE",
"type": "string"
},
],
"version": "1.0"
}
schema_interaction = json.dumps(schema_interaction)
response_create_schema = client_personalize.create_schema(
name=schema_interaction_name,
schema=schema_interaction,
)
Dataset作成
response_create_dataset = client_personalize.create_dataset(
name=dataset_interaction_name,
schemaArn=response_create_schema['schemaArn'],
datasetGroupArn=response_create_dataset_group['datasetGroupArn'],
datasetType='Interactions'
)
IAMロール作成
- まずはcustom policyの作成します。
- export用に
s3:PutObjectを付けます。
- export用に
iam_custom_policy_document = {
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"s3:ListBucket",
"s3:GetObject",
"s3:PutObject"
],
"Effect": "Allow",
"Resource": [
f"arn:aws:s3:::{bucket_name}",
f"arn:aws:s3:::{bucket_name}/*"
]
},
]
}
response_create_policy = client_iam.create_policy(
PolicyName=iam_custom_policy_name,
PolicyDocument=json.dumps(iam_custom_policy_document),
)
- 次にroleを作成します。
- export用に
AmazonS3FullAccessを付けます。
- export用に
assume_role_policy_document = {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
create_role_response = client_iam.create_role(
RoleName = iam_role_name,
AssumeRolePolicyDocument = json.dumps(assume_role_policy_document)
)
client_iam.attach_role_policy(
RoleName = iam_role_name,
PolicyArn = "arn:aws:iam::aws:policy/AmazonS3FullAccess"
)
client_iam.attach_role_policy(
RoleName = iam_role_name,
PolicyArn = response_create_policy['Policy']['Arn']
)
response_get_role = client_iam.get_role(RoleName=iam_role_name)
import job作成
- importには5分程度かかりました。
response_create_dataset_import_job = client_personalize.create_dataset_import_job(
jobName=import_job_interaction_name,
datasetArn=response_create_dataset['datasetArn'],
dataSource={
'dataLocation': import_s3_uri_interaction
},
roleArn=response_get_role['Role']['Arn']
)
solution作成
- solution作成の時点ではまだ学習は行われません。
- レシピは、user-personalizationを使います。
response_create_solution = client_personalize.create_solution(
name=solution_name,
datasetGroupArn=response_create_dataset_group['datasetGroupArn'],
recipeArn='arn:aws:personalize:::recipe/aws-user-personalization',
)
solutionVersion作成
- solutionVersion作成で学習が行われます。
- 学習には25分程度時間がかかりました。
create_solution_version_response = client_personalize.create_solution_version(
solutionArn = response_create_solution['solutionArn']
)
- 学習完了後、solutionVersionの情報を確認します。
response_describe_solution_version = client_personalize.describe_solution_version(
solutionVersionArn=create_solution_version_response['solutionVersionArn']
)
- 出力の抜粋は以下となります。
- lastUpdatedDateTimeというものがありますが、モデルの自動更新の場合ここの時刻は変化ありませんでした。
- 今後更新後は更新時刻になると良いなと思います。
"solutionVersion": {
"solutionVersionArn": "...",
"solutionArn": "...",
"performHPO": false,
"performAutoML": false,
"recipeArn": "...",
"datasetGroupArn": "...",
"solutionConfig": {},
"trainingHours": 1.768,
"trainingMode": "FULL",
"status": "ACTIVE",
"creationDateTime": "2022-03-08T18:17:41.603000+09:00",
"lastUpdatedDateTime": "2022-03-08T18:40:19.318000+09:00"
},
put eventsの準備
- testデータをput用に使いますが、全件は多いため、100件だけを使用します。
df_ratings_put_sample = df_ratings_test.sample(100)
- また以下のルールで、
update_idsとno_update_idsを作成します。update_ids: df_ratings_put_sampleの100件に含まれるUSER_IDno_update_ids: train/test双方に含まれるUSER_IDのうち、df_ratings_put_sampleの100件に含まれないUSER_ID
- 後者は、あまり古いUSER_IDを使わないよう、train/test双方に含まれるものに限定するためです。
update_ids = df_ratings_put_sample['USER_ID'].unique()
no_update_ids = list(\
set(df_ratings_train ['USER_ID'].unique()) &\
set(df_ratings_test ['USER_ID'].unique()) -\
set(df_ratings_put_sample['USER_ID'].unique())\
)
campaignの作成
- リアルタイム推論結果取得のため、campaignを作成します。
- ここから削除するまで時間単位で料金が発生するので注意が必要です。
response_create_campaign = client_personalize.create_campaign(
name=campaign_name,
solutionVersionArn=create_solution_version_response['solutionVersionArn'],
minProvisionedTPS=1,
)
recommendation取得
-
ここから、以下の4パターンについてupdate_ids[0]とno_update_ids[0]のレコメンデーションを取得していきます。
- 初期状態(最初の学習直後)
- 100件のput eventsの直後
- put eventsの2時間後
- 再学習を実施し、その完了後
-
レコメンデーションは以下のように取得します。
response_get_recommendations = client_personalize_runtime.get_recommendations(
campaignArn=response_create_campaign['campaignArn'],
userId=f'{update_ids[0]}', # この部分をno_update_ids[0]に置き換えて実行が必要
numResults=20,
)
- 結果の一例は以下の通りです。
response_get_recommendations['itemList']にレコメンドのアイテムリストが格納されますので、DataFrameにするなどして比較できるようにします。- recommendationIdは、implicit(暗黙的)なIMPRESSIONデータとして使えます。
- IMPRESSIONについてはこちらの記事もご参照ください
{
"ResponseMetadata": {
"RequestId": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"HTTPStatusCode": 200,
"HTTPHeaders": {
"content-type": "application/json",
"date": "Thu, 10 Mar 2022 08:56:31 GMT",
"x-amzn-requestid": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"content-length": "1173",
"connection": "keep-alive"
},
"RetryAttempts": 0
},
"itemList": [
{
"itemId": "1387",
"score": 0.0083764
},
{
"itemId": "4993",
"score": 0.0080211
},
{
"itemId": "1196",
"score": 0.0062859
},
// ...略...
],
"recommendationId": "RID-XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
}
event trackerの作成
- event(interaction)をputするため、event trackerを作成します。
response_create_event_tracker = client_personalize.create_event_tracker(
name=event_tracker_name,
datasetGroupArn=response_create_dataset_group['datasetGroupArn']
)
eventの登録
- testデータから100件を抽出したdf_ratings_put_sampleを登録します。
- session_idが必須となりますので、まずはユーザー毎に固有のsession_idを作成します。
session_id_map = {}
for user_id in df_ratings_put_sample['USER_ID'].unique():
session_id_map[f'{user_id}'] = str(uuid.uuid4())
session_ids = [ session_id_map[f'{row.USER_ID}'] for row in df_ratings_put_sample.itertuples()]
df_ratings_put_sample['SESSION_ID'] = session_ids
- 100件すべてをputします。
- 以下は最低限必須の項目(カラム)のみputしています。
- schema作成時にeventTypeを定義しない場合でもeventTypeが必須となる点は注意が必要です。
- 使わない場合でも公式の説明通り
eventTypePlaceholderでputします。 - またこのAPIは、同一ユーザーであれば、eventListを複数登録できますが、最大10件までしか同時にputできないという使用上の制限があります。
for row in tqdm(df_ratings_test.itertuples()):
client_personalize_events.put_events(
trackingId=response_create_event_tracker['trackingId'],
userId=f'{row.USER_ID}',
sessionId=row.SESSION_ID,
eventList=[
{
'sentAt': row.TIMESTAMP,
'eventType': 'eventTypePlaceholder',
'itemId': f'{row.ITEM_ID}',
},
]
)
-
この直後に、再度
recommendation取得で説明したようにupdate_ids[0]とno_update_ids[0]のレコメンデーションを取得して比較してみましょう。 -
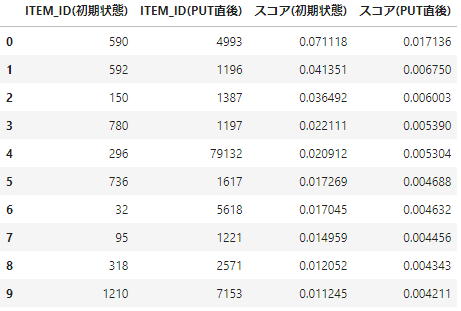
まずはput eventsに含まれていたUSER_IDを見てみます。
- 直後でもレコメンド結果が変わっていることがわかります。
- これは登録されたイベントがすぐさまレコメンドのモデルの入力として使われているためと考えられます。
- 初期状態と比べると大きく変化しているようです。
-
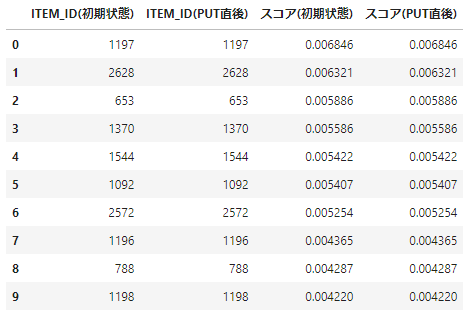
次にput eventsに含まれていなかったUSER_IDを見てみます。
- こちらは、putされたeventとUSER_IDが違うため入力に影響がないため、結果にも変化がないと考えられます。
2時間後の結果取得
-
put eventsから2時間後、再度レコメンデーションを取得して比較してみます。
-
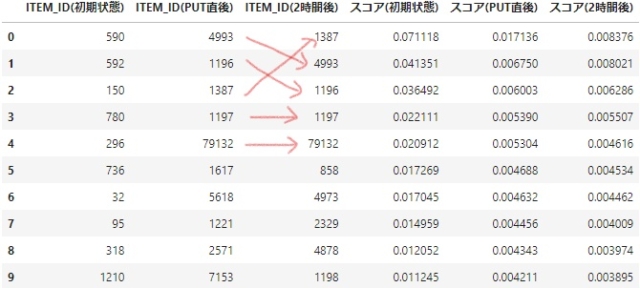
まずはput eventsに含まれていたUSER_IDを見てみます。
- 直後と2時間後を比較すると、上位の順番が変わっている傾向があります。
- 下位はスコア差が小さいせいか、大きく順位が変わってるようです。
- ただし初期状態と直後の差に比べると、変化は小さい印象です。
-
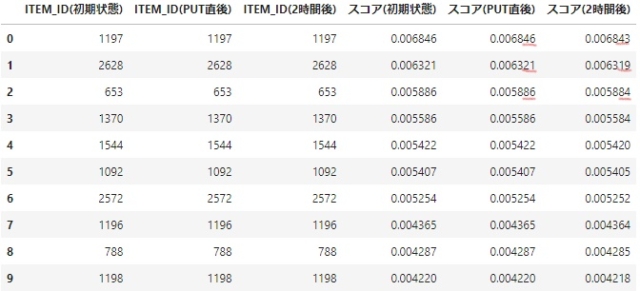
次にput eventsに含まれていなかったUSER_IDを見てみます。
- こちらは、順位は変わらないのですが、スコアが少しだけ変わっていることがわかります。
- そのため、モデルが変わっていることは確かだと考えられます。
再学習(FULL)の実行
- 再学習を実施します。コード上は最初の
create_solution_versionと変わりません。
create_solution_version_response = client_personalize.create_solution_version(
solutionArn = response_create_solution['solutionArn']
)
campaignの更新
- campaignは再度作成の必要はなく、updateすることができます。
- updateはcreateと同様に5分程度時間がかかりました。
- updateが完了していない状態でも、
get_recommendationは可能で、その場合は以前のsolutionVersionを使われる点にご注意ください。
response_update_campaign = client_personalize.update_campaign(
campaignArn=response_create_campaign['campaignArn'],
solutionVersionArn=create_solution_version_response['solutionVersionArn'],
minProvisionedTPS=1,
)
-
campaignの更新が終わったら、再度レコメンデーションを取得して比較してみます。
-
まずはput eventsに含まれていたUSER_IDを見てみます。
- 結果は以前と大きく異なっています。
- 一部だけ、自動更新時と同じ順位のITEM_IDもありますが、順位は違います。
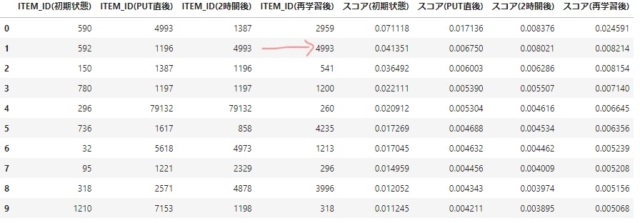
-
次にput eventsに含まれていなかったUSER_IDを見てみます。
- こちらも大きく変わっていることがわかります。
- FULL学習のやり直しは、put eventに含まれないUSER_IDにも影響があることがわかります。
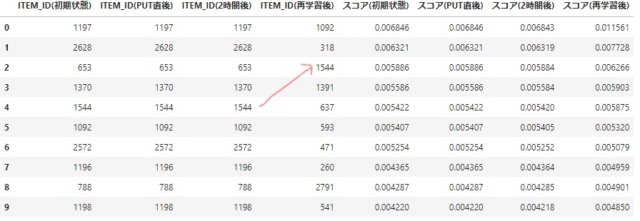
putしたeventのexport
- putしたイベントが、exportできるかどうかを確認します。
- ingestionModeは
PUTとする必要があります。 - ingestionModeはを
BULKにした場合、importされたデータがexportされ、ALLにした場合は、PUTとBULKの両方がexportできます。
- ingestionModeは
response_create_dataset_export_job = client_personalize.create_dataset_export_job(
jobName=export_job_name,
datasetArn=response_create_dataset['datasetArn'],
ingestionMode='PUT',
roleArn=response_get_role['Role']['Arn'],
jobOutput={
's3DataDestination': {
'path': export_s3_uri_events,
}
}
)
export結果の確認
- exportされるcsvはURIが以下のようなフォーマットとなります。
XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXXの箇所はUUIDとなります。
f"${export_s3_uri_events}/AMZN_Personalize/{datasetGroupのARN}/{datasetのARN}/{export_job_name}/yyyy-mm-dd/part-00000-XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX-c000.csv"
- 中身を確認したところ、きちんと100件分取得できていることを確認できました。
timestamp,session_id,event_type,user_id,item_id,impression,recommendation_id
1461562058000,04b25408-6ca9-4b31-97ae-b008dbac2c14,eventTypePlaceholder,122,107406,"",""
1496205576000,e8bf4a45-424b-404a-a0a6-14426607f67a,eventTypePlaceholder,47,6870,"",""
1479542372000,5ff54425-81e5-48e7-8fb1-7c0d9cc2218b,eventTypePlaceholder,610,42946,"",""
1490298147000,cfdfe15b-d46f-4cc5-b1f0-716b83a4e65e,eventTypePlaceholder,305,8529,"",""
1529899377000,49e5d88d-82c9-4bb7-9868-28d7b7500a52,eventTypePlaceholder,586,173145,"",""
1535827140000,0fe3c106-37ea-4793-b134-c683fda6d120,eventTypePlaceholder,596,1968,"",""
1515249212000,1ed3781d-cd62-433c-95df-8e2e2704e794,eventTypePlaceholder,382,4085,"",""
1525289571000,67701939-208a-437f-94ca-870d80041d9f,eventTypePlaceholder,567,34048,"",""
- ちなみに、event trackerを削除した後でもPUTされたものをexportすることは可能です。
campaignの削除
- 最後にこれ以上料金がかからないよう、campaignを削除しておきます。
client_personalize.delete_campaign(
campaignArn=response_create_campaign['campaignArn']
)
- その他のリソース(createしたもの)も不要となりましたタイミングで削除してください。
まとめ
いかがでしたでしょうか。
AWS公式ドキュメントにはもちろん自動更新などについてきちんと記載がありますが、
実際にどのように変わるのか、動かしてみてみないと不安な部分もありましたので、今回結果を見ながら確認することができ良かったと思います。
こちらの記事がモデル運用時のアップデートする際の参考になれば幸いです。









