
API Gateway + Lambda + Pollyでテキストを音声に変換して、Flutterから再生してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、ゲームソリューション部のsoraです。
今回は、API Gateway + Lambda + Pollyでテキストを音声に変換して、Flutterから再生してみたことについて書いていきます。
構成
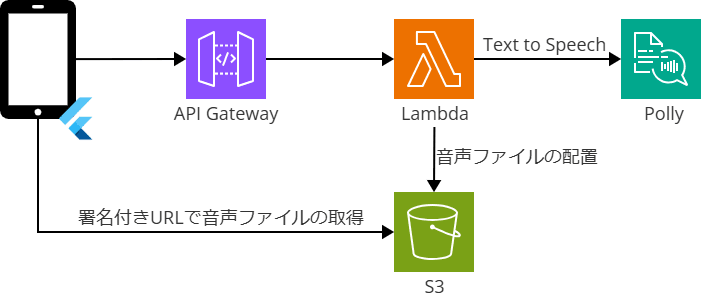
構成は簡単なものですが以下です。
Flutterからテキストを送って、Lambda経由でPollyに渡して音声に変換して、S3に配置します。
S3に配置したファイルを署名付きURLを使って、Flutterで取得して再生します。
今回はフロント部分にFlutterを使用しましたが、API実行しているだけのためcurlでも実行可能です。
環境
- Lambdaランタイム:Python 3.13
- Flutter:3.22.3
AWSインフラの作成
AWSインフラはTerraformで作成しました。
API Gateway + Lambdaのよくある構成のため、説明は割愛します。
音声ファイル配置用のS3のみ事前に作成してあるものを使用します。
managed_policy_arnsの部分は、Warningが出て書き方が古いみたいなので、修正した方が良いかもしれません。
main.tf
# account idの取得
data aws_caller_identity current {}
### IAM start ###
# Lambda
## ロールの作成
data aws_iam_policy_document tts_lambda_assume {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["lambda.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
## ポリシーの作成
resource aws_iam_policy tts_lambda_policy {
name = "TTSLambdaBackendLambdaPolicy"
description = "TTSLambdaBackendLambdaPolicy"
policy = templatefile("./iam_policy/backend_lambda_iam.json",{
account_id : "${data.aws_caller_identity.current.account_id}",
})
}
resource aws_iam_role tts_lambda_role {
name = "TTS_Lambda_Backend_Lambda_Role"
assume_role_policy = data.aws_iam_policy_document.tts_lambda_assume.json
managed_policy_arns = [
"arn:aws:iam::aws:policy/AmazonPollyFullAccess",
"arn:aws:iam::aws:policy/AmazonS3FullAccess",
aws_iam_policy.tts_lambda_policy.arn
]
}
# API Gateway
## 統合リクエスト用
## ロールの作成
data aws_iam_policy_document api_gateway_assume {
statement {
effect = "Allow"
principals {
type = "Service"
identifiers = ["apigateway.amazonaws.com"]
}
actions = ["sts:AssumeRole"]
}
}
## ポリシーの作成
resource aws_iam_policy api_gateway_policy {
name = "APIGatewayPolicy"
description = "API Gateway Policy"
policy = templatefile("./iam_policy/apigateway_iam.json",{
lambda_backend_arn : "${aws_lambda_function.lambda_tts.arn}"
})
}
resource aws_iam_role api_gateway_role {
name = "API_Gateway_Role"
assume_role_policy = data.aws_iam_policy_document.api_gateway_assume.json
managed_policy_arns = [aws_iam_policy.api_gateway_policy.arn]
}
## アカウント別のログ記録用
## ロールの作成
resource aws_iam_role api_gateway_log_role {
name = "API_Gateway_Log_Role"
assume_role_policy = data.aws_iam_policy_document.api_gateway_assume.json
managed_policy_arns = ["arn:aws:iam::aws:policy/service-role/AmazonAPIGatewayPushToCloudWatchLogs"]
}
## ロールの設定
resource aws_api_gateway_account api_gateway_log_role {
cloudwatch_role_arn = aws_iam_role.api_gateway_log_role.arn
}
### IAM end ###
### Backend start ###
### AWS Resource start ###
# Lambda
data archive_file lambda_tts {
type = "zip"
source_dir = "tts/dist"
output_path = "tts.zip"
}
resource aws_lambda_function lambda_tts {
filename = "tts.zip"
function_name = "tts-api-execution"
role = aws_iam_role.tts_lambda_role.arn
handler = "tts-api.lambda_handler"
source_code_hash = data.archive_file.lambda_tts.output_base64sha256
runtime = "python3.13"
timeout = 300
environment {
variables = {
S3_BUCKET_NAME = "{BUCKET_NAME}"
S3_PREFIX = "{PREFIX}"
}
}
}
resource aws_lambda_permission lambda_tts_permission {
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.lambda_tts.function_name
principal = "apigateway.amazonaws.com"
source_arn = aws_api_gateway_rest_api.apigateway.arn
}
# Cloudwatch
## Cloudwatch LogGroupの作成
resource aws_cloudwatch_log_group lambda_log_group {
name = "/aws/lambda/${aws_lambda_function.lambda_tts.function_name}"
retention_in_days = 7
}
# API Gateway
## API Gatewayの作成
resource aws_api_gateway_rest_api apigateway {
name = "tts-apigateway"
endpoint_configuration {
types = ["REGIONAL"]
}
}
### リソースの作成
resource aws_api_gateway_resource tts_resource {
rest_api_id = aws_api_gateway_rest_api.apigateway.id
parent_id = aws_api_gateway_rest_api.apigateway.root_resource_id
path_part = "tts"
}
### メソッドの作成
resource aws_api_gateway_method tts_post_method {
rest_api_id = aws_api_gateway_rest_api.apigateway.id
resource_id = aws_api_gateway_resource.tts_resource.id
http_method = "POST"
authorization = "NONE"
}
### 統合リクエストの作成
resource aws_api_gateway_integration tts_integration {
rest_api_id = aws_api_gateway_rest_api.apigateway.id
resource_id = aws_api_gateway_resource.tts_resource.id
http_method = aws_api_gateway_method.tts_post_method.http_method
integration_http_method = "POST"
type = "AWS_PROXY"
uri = aws_lambda_function.lambda_tts.invoke_arn
credentials = aws_iam_role.api_gateway_role.arn
}
# OPTIONSメソッドの追加
resource aws_api_gateway_method tts_options_method {
rest_api_id = aws_api_gateway_rest_api.apigateway.id
resource_id = aws_api_gateway_resource.tts_resource.id
http_method = "OPTIONS"
authorization = "NONE"
}
# OPTIONSメソッドのモックインテグレーション
resource aws_api_gateway_integration tts_options_integration {
rest_api_id = aws_api_gateway_rest_api.apigateway.id
resource_id = aws_api_gateway_resource.tts_resource.id
http_method = aws_api_gateway_method.tts_options_method.http_method
type = "MOCK"
request_templates = {
"application/json" = "{\"statusCode\": 200}"
}
}
# OPTIONSメソッドのレスポンス
resource aws_api_gateway_method_response tts_options_method_response {
rest_api_id = aws_api_gateway_rest_api.apigateway.id
resource_id = aws_api_gateway_resource.tts_resource.id
http_method = aws_api_gateway_method.tts_options_method.http_method
status_code = "200"
response_parameters = {
"method.response.header.Access-Control-Allow-Headers" = true
"method.response.header.Access-Control-Allow-Methods" = true
"method.response.header.Access-Control-Allow-Origin" = true
}
}
# OPTIONSメソッドのインテグレーションレスポンス
resource aws_api_gateway_integration_response tts_options_integration_response {
rest_api_id = aws_api_gateway_rest_api.apigateway.id
resource_id = aws_api_gateway_resource.tts_resource.id
http_method = aws_api_gateway_method.tts_options_method.http_method
status_code = aws_api_gateway_method_response.tts_options_method_response.status_code
response_parameters = {
"method.response.header.Access-Control-Allow-Headers" = "'Content-Type,X-Amz-Date,Authorization,X-Api-Key,X-Amz-Security-Token'"
"method.response.header.Access-Control-Allow-Methods" = "'GET,OPTIONS,POST,PUT'"
"method.response.header.Access-Control-Allow-Origin" = "'*'"
}
}
## ステージの作成
### デプロイ設定
resource aws_api_gateway_deployment stage_deploy {
rest_api_id = aws_api_gateway_rest_api.apigateway.id
stage_name = "v1"
depends_on = [
aws_api_gateway_rest_api.apigateway,
aws_api_gateway_method.tts_post_method,
aws_api_gateway_integration.tts_integration,
aws_api_gateway_method.tts_options_method,
aws_api_gateway_integration.tts_options_integration
]
lifecycle {
create_before_destroy = true
}
}
### メソッドの設定
resource aws_api_gateway_method_settings method_settings {
depends_on = [
aws_api_gateway_account.api_gateway_log_role,
]
rest_api_id = aws_api_gateway_rest_api.apigateway.id
stage_name = aws_api_gateway_deployment.stage_deploy.stage_name
method_path = "*/*"
settings {
metrics_enabled = true
logging_level = "INFO"
data_trace_enabled = false
}
}
### AWS Resource end ###
### Backend end ###
provider.tf
# provider
terraform {
required_providers {
aws = {
source = "hashicorp/aws"
version = "~> 5.81.0"
}
}
backend s3 {
bucket = "{BUCKET_NAME}"
region = "ap-northeast-1"
key = "tts.tfstate"
}
}
# AWSプロバイダーの定義
provider aws {
region = "ap-northeast-1"
}
Lambdaのソースコードは以下です。
受け取ったテキストをPollyにて音声ファイルに変換してS3に配置した後、署名付きURLを作成して返却しています。
S3に配置する音声ファイル名には、ランダムなUUIDを付与しており、ファイル名が重複しないようにしています。
import json
import boto3
import os
import uuid
def lambda_handler(event, context):
# リクエストボディからテキストを取得
try:
request_body = json.loads(event['body'])
text = request_body.get('text', '')
if not text:
return {
'statusCode': 400,
'body': json.dumps({'error': 'テキストが入力されていません'})
}
except Exception as e:
return {
'statusCode': 400,
'body': json.dumps({'error': 'リクエストボディが不正です'})
}
# クライアントの初期化
polly_client = boto3.client('polly')
s3_client = boto3.client('s3')
try:
# Pollyで音声合成を実行
response = polly_client.synthesize_speech(
Text=text,
OutputFormat='mp3',
VoiceId='Kazuha',
Engine='neural' # ニューラル音声を使用
)
# S3バケット名(環境変数から取得)
bucket_name = os.environ['S3_BUCKET_NAME']
prefix = os.environ['S3_PREFIX']
# ランダムなファイル名を生成
file_name = f"{prefix}{str(uuid.uuid4())}.mp3"
# S3に音声ファイルをアップロード
s3_client.put_object(
Bucket=bucket_name,
Key=file_name,
Body=response['AudioStream'].read(),
ContentType='audio/mpeg'
)
# 署名付きURLを生成(有効期限10分)
presigned_url = s3_client.generate_presigned_url(
'get_object',
Params={
'Bucket': bucket_name,
'Key': file_name
},
ExpiresIn=600 # 10分
)
# レスポンスの作成
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'POST',
'Access-Control-Allow-Headers': 'Content-Type'
},
'body': json.dumps({
'url': presigned_url,
'message': '音声ファイルの生成とアップロードに成功しました'
})
}
except Exception as e:
return {
'statusCode': 500,
'body': json.dumps({
'error': f'音声の生成に失敗しました: {str(e)}'
})
}
Flutterの実装
Flutterでは、テキストを入力して、API GatewayにPOSTリクエストを送信します。
その後、API Gateway経由でLambdaから返却された署名付きURLを使って、S3に配置された音声ファイルを取得して再生します。
main.dart
import 'package:flutter/material.dart';
import 'package:flutter_riverpod/flutter_riverpod.dart';
import 'contents.dart';
void main() {
runApp(
const ProviderScope(
child: MyApp()
)
);
}
class MyApp extends StatelessWidget {
const MyApp({super.key});
@override
Widget build(BuildContext context) {
return MaterialApp(
debugShowCheckedModeBanner: false,
theme: ThemeData(
colorScheme: ColorScheme.fromSeed(seedColor: Colors.lightBlueAccent),
useMaterial3: true,
fontFamily: 'Noto Sans JP'
),
home: ContentsPage(),
);
}
}
import 'dart:convert';
import 'package:flutter/material.dart';
import 'package:flutter_riverpod/flutter_riverpod.dart';
import 'package:http/http.dart' as http;
import 'package:audioplayers/audioplayers.dart';
import 'dart:developer' as developer;
// 音声ファイル管理用のNotifier
class AudioUrlNotifier extends Notifier<String?> {
@override
String? build() => null;
void setUrl(String url) {
state = url;
}
}
final audioUrlProvider = NotifierProvider<AudioUrlNotifier, String?>(AudioUrlNotifier.new);
// メイン画面
class ContentsPage extends ConsumerWidget {
ContentsPage({super.key});
final TextToSpeechService tts = TextToSpeechService();
final TextEditingController _textController = TextEditingController();
@override
Widget build(BuildContext context, WidgetRef ref) {
final audioUrl = ref.watch(audioUrlProvider);
return Scaffold(
appBar: AppBar(
backgroundColor: Theme.of(context).colorScheme.inversePrimary,
title: const Text('音声変換テスト'),
),
body: Padding(
padding: const EdgeInsets.all(16.0),
child: Column(
children: [
TextField(
controller: _textController,
decoration: const InputDecoration(
labelText: '変換するテキスト',
),
),
const SizedBox(height: 16),
ElevatedButton(
onPressed: () async {
if (_textController.text.isNotEmpty) {
try {
final url = await tts.convertText(_textController.text);
ref.read(audioUrlProvider.notifier).setUrl(url);
} catch (e) {
ScaffoldMessenger.of(context).showSnackBar(
SnackBar(content: Text('エラーが発生しました: $e')),
);
}
}
},
child: const Text('変換する'),
),
const SizedBox(height: 32),
if (audioUrl != null) ...[
Column(
children: [
const Text(
'変換後の音声操作',
style: TextStyle(fontSize: 20),
),
const SizedBox(height: 16),
Row(
mainAxisAlignment: MainAxisAlignment.center,
children: [
IconButton(
icon: const Icon(Icons.play_arrow),
onPressed: () => tts.playAudio(audioUrl),
),
IconButton(
icon: const Icon(Icons.stop),
onPressed: () => tts.stop(),
),
],
),
],
)
],
],
),
),
);
}
}
class TextToSpeechService {
// ★API GatewayのURLを入れる
final String apiUrl = '{API_GATEWAY_URL}/{STAGE_NAME}/{PATH}';
final AudioPlayer audioPlayer = AudioPlayer();
Future<String> convertText(String text) async {
try {
final response = await http.post(
Uri.parse(apiUrl),
headers: {
'Content-Type': 'application/json',
},
body: json.encode({'text': text}),
);
if (response.statusCode == 200) {
final data = json.decode(response.body);
return data['url'];
} else {
throw Exception('音声の生成に失敗しました');
}
} catch (e) {
developer.log('エラーが発生しました: $e');
rethrow;
}
}
Future<void> playAudio(String url) async {
try {
await audioPlayer.play(UrlSource(url));
} catch (e) {
developer.log('音声の再生に失敗しました: $e');
rethrow;
}
}
Future<void> stop() async {
await audioPlayer.stop();
}
}
実行
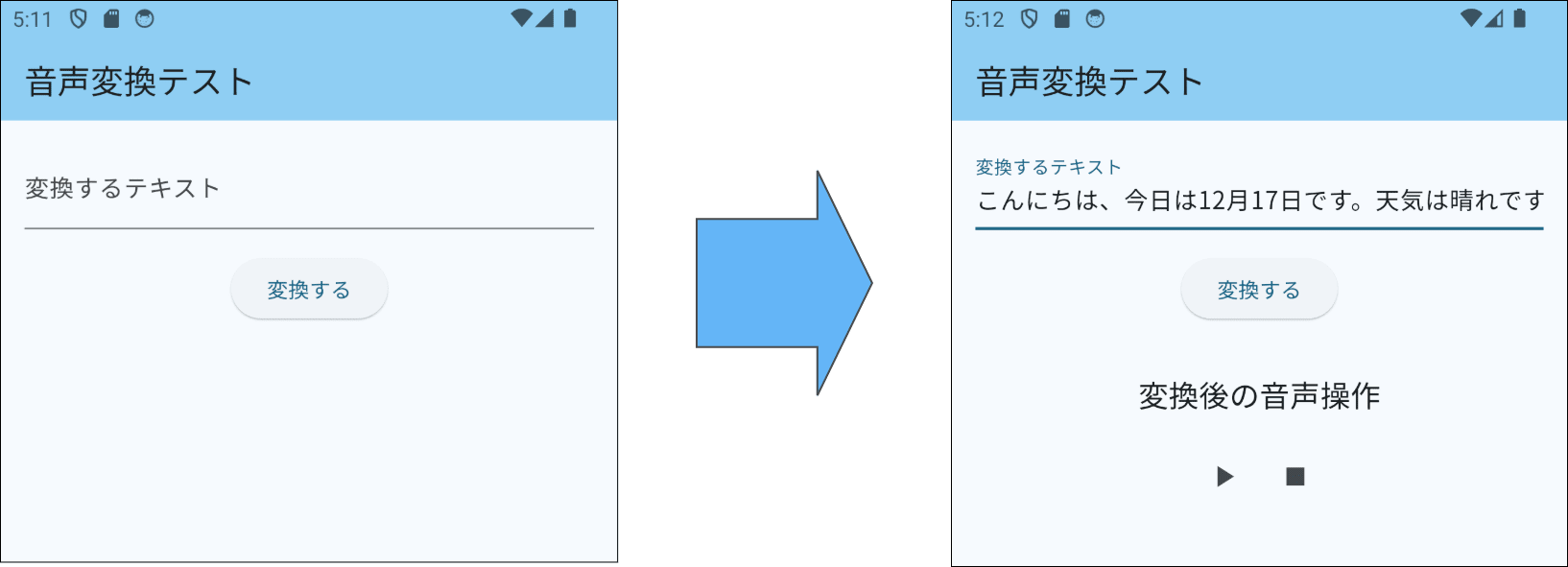
準備ができたため、適当なテキストを入力してテストします。
今回は「こんにちは、今日は12月17日です。天気は晴れです。」としました。
その後に「変換する」ボタンを押すと、音声ファイルを再生することができます。
改善点として、音量が小さかったので、audioplayersを使って音量を変更できるようにすると、より良いかもしれません。
ちなみにFlutterで画面を作ったものの、API実行しているだけのためコマンドでも実行可能です。
以下コマンドを実行すると、署名付きURLが返却されるため、そのURLにアクセスすると音声ファイルを取得できます。
curl -X POST \
-H "Content-Type: application/json" \
-d '{"text": "こんにちは、今日は12月17日です。天気は晴れです。"}' \
{API_GATEWAY_URL}/{STAGE_NAME}/{PATH}
最後に
今回は、API Gateway + Lambda + Pollyでテキストを音声に変換して、Flutterから再生してみたことを記事にしました。
どなたかの参考になると幸いです。








