
QuickSightのSPICEと直接クエリ、結局どっちを使えばいいの?
こんにちは。
私は機械学習チームに所属していて、普段はモデル開発がメインなんですが、分析結果や予測データをステークホルダーに共有する機会が増えてきました。
Jupyter NotebookやMatplotlibで作ったグラフをスクショして共有するのも限界があるし、非エンジニアの方でも自由に見られるダッシュボードが欲しいなと思ってQuickSightを触り始めました。
そこで最初にQuickSight内でデータセットを作ろうとしたら「SPICE」と「直接クエリ」という選択肢が出てきて、「え、どっち...?」となりました。
実際に両方試してみて、それぞれの特徴や使い分けのポイントが分かってきたので共有します。
結論
- 最初は「直接クエリ」で作る
- ちゃんと動いたら「SPICE」に切り替える(切り替えは後からでもできるので心配無用)
SPICEと直接クエリの違い
直接クエリとは
ダッシュボード開くたびにRDSとかRedshiftに毎回クエリ飛ばす方式。

メリット
- 常に最新データが見れる
デメリット
- 応答速度が遅い
- データベースに負荷かかる
SPICEとは
データをQuickSight内のメモリにコピーして保存する方式。
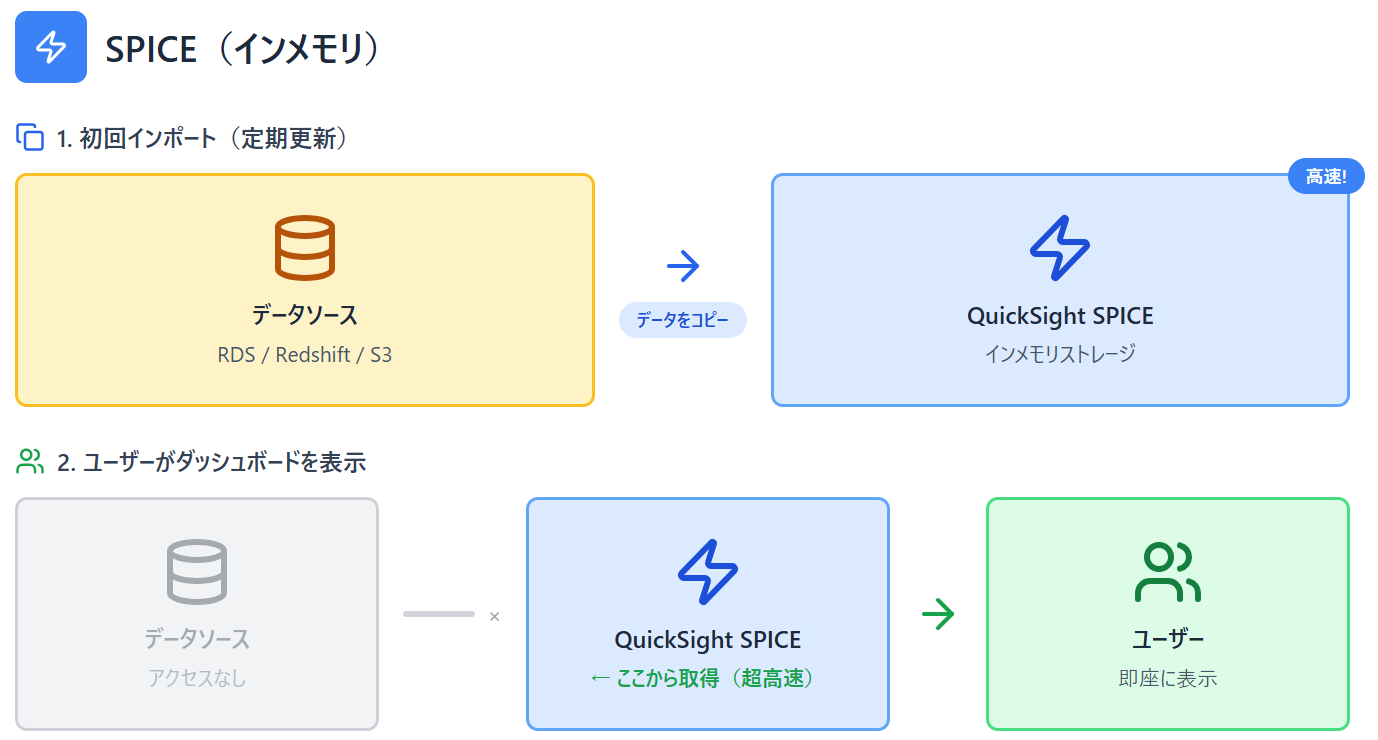
メリット
- 応答速度がめちゃくちゃ速い
- データベースに負荷かからない
デメリット
- リアルタイム性の欠如(15分間隔が最短)
- 更新スケジュールの管理が必要
どっちを選べばいい?
基本的にSPICEになりますが、以下の場合は直接クエリの方がいいと思います。
-
リアルタイムじゃないとダメな場合
株価モニタリングとか、IoTセンサーの監視とか。SPICEは最短でも15分間隔でしか更新できないので。 -
アクセス頻度が極端に低い場合
月に数回しか見ないダッシュボードや、特定の調査目的でたまにしか使わないダッシュボード。SPICE容量を消費し続けるより、必要な時だけクエリする方がコスト効率が良い。
SPICEの定期実行設定について
SPICEの更新には「フル更新」と「増分更新」があります。
増分更新を使うと、前回更新以降に追加・変更されたデータだけを取り込むので更新が速いです。
ただし条件があって、updated_atとかcreated_atみたいな日付型のカラムが必要になります。
-- ユーザーが書くクエリ(普通のSELECT文)
SELECT
order_id,
customer_id,
amount,
updated_at
FROM orders
増分更新を設定すると、QuickSightが以下のように自動でフィルター条件を追加してくれる。
-- QuickSightが内部的に実行するクエリ
SELECT
order_id,
customer_id,
amount,
updated_at
FROM orders
WHERE updated_at > '2025-11-01 10:00:00' -- 自動で追加される
データソース側で特別な設定は不要です。QuickSightが前回更新時刻を記憶していて、それ以降のデータだけを取得する仕組みになっています。
※但し、日付型のカラムがない場合は、完全更新(フルリフレッシュ)しか選択できないので注意して下さい。
まとめ
QuickSight実装するなら、
- 直接クエリでサクッと作る
- 動いたらSPICEに切り替え
- 更新スケジュール設定して完了
直接クエリから始めた方が開発しやすいし、SPICEへの切り替えも簡単。本番運用はSPICEの方が速いし安定するので、最終的にはSPICEにするのがおすすめです。
リアルタイムが絶対必要とか、アクセス頻度が極端に低いとかじゃなければ、基本SPICEで問題ないと思います。
最後に
データ事業本部では現在、データ分析業務経験の浅い方や、
キャリアチェンジを検討している方向けのポジションも募集しています。
「データ分析に興味があるけれど、実務経験が少ない」
「機械学習エンジニアを目指しているが、何から始めればいいか分からない」
「技術力を伸ばせる環境で働きたい」
そんな方も、まずは会社説明会でお話を聞いてみませんか。
普段の働き方や、実際に業務内容についてお話しします。
ぜひお気軽にご参加ください。
▼ 会社説明会情報
▼ よくある質問
▼ 募集職種の詳細







