
AWS再入門ブログリレー2022 AWS Glue編
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
当エントリは弊社コンサルティング部による『AWS再入門ブログリレー2022』の39日目のエントリです。
このブログリレーの企画は、普段AWSサービスについて最新のネタ・深い/細かいテーマを主に書き連ねてきたメンバーの手によって、 今一度初心に返って、基本的な部分を見つめ直してみよう、解説してみようというコンセプトが含まれています。
AWSをこれから学ぼう!という方にとっては文字通りの入門記事として、またすでにAWSを活用されている方にとっても AWSサービスの再発見や 2022年のサービスアップデートのキャッチアップの場となればと考えておりますので、ぜひ最後までお付合い頂ければ幸いです。
では、さっそくいってみましょう。今日のテーマは『AWS Glue』です。
AWS Glueとは
AWS Glueは様々なデータソースのメタデータを管理し、分析、機械学習、アプリケーション開発のためのデータ検出、準備、結合をシンプルでスケーラブルに行うためのサーバーレスデータ統合サービスです。
以前まで「フルマネージドでサーバーレスなETLサービス」と紹介されていたと思いますが、最近では「サーバーレスデータ統合サービス」と称されるあたりにAWS Glueの発展を感じますね。
AWS Glueの全体像
(引用元:【AWS Black Belt Online Seminar】AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-)
- ETLジョブ
- データソースから必要なデータを抽出
- 必要に応じてサーバーレスの実行エンジンにてデータ変換ジョブを実行
- クローラ
- データレイクをクローリングし、どのようなデータが入っているかという情報(メタデータ)をデータカタログに登録・更新
- データカタログ
- ターゲット側のシステムはデータカタログからデータレイク内にあるデータを理解する
- データカタログをもとに必要なデータをロードし分析等を実行する
- ワークフロー
- これらのETLジョブ、クローラ、データカタログ出力までの一連の処理を自動化する
従来のこれらの機能に加え、「Glue Studio」「Glue DataBrew」「Glue Elastic Views」といった強力な追加機能が「サーバーレスETLサービス」という位置づけから「サーバーレスデータ統合サービス」へと押し上げたと思います。これらの機能紹介は後ほど。

(引用元:【AWS Black Belt Online Seminar】AWS Glue -Glue Studioを使ったデータ変換のベストプラクティス-)
それでは再入門ブログらしく、まずは標準の各コンポーネントについてあらためて紹介します。
データカタログ
データカタログにはGlueでの抽出、変換、ロード(ETL)ジョブのソースおよびターゲットとして使用するデータへのリファレンスが含まれています。データカタログにはデータの場所、スキーマなどの情報がメタテーブルとして保存されます。
以下の図はクローラーがデータストアやその他の要素とどのようにやり取りしてデータカタログを生成するかを示しています。

(引用元:AWS Glue Data Catalog の入力)
- クローラが任意のカスタム分類子(Classifier)を実行し、データ形式とスキーマを推論する
- カスタム分類子がデータのスキーマにマッチしない場合、組み込みの分類子がデータのスキーマを認識しようとする
- クローラがデータストアに接続する
- 推論されたスキーマが作成される
- クローラはデータカタログにメタデータを書き込みます。テーブル定義にはデータストア内のデータに関するメタデータが含まれます。テーブルは、データカタログ内でテーブルの箱となるデータベースに書き込まれる
データカタログはテーブル定義のみを保存しますので、オリジナルデータはデータソースにのみ存在しています。
データカタログは以下のオブジェクトによって構成されます。
- データベース
- テーブル
- パーティション
- 接続
データベース
データベースはAWS Glueのメタデータテーブルを整理するために使用されます。データカタログでテーブルを定義すると、データベースに追加されます。データベースには様々なデータストアからのデータ定義テーブルを含めることができます。
データベースをデータカタログから削除すると、データベース内のすべてのテーブルも削除されます。
テーブル
テーブルは、スキーマを含むデータを表すメタデータ定義です。テーブルをジョブ定義のソースまたはターゲットとして使用できます。
以下はメタデータ定義の例です。

(引用元:[AWS Black Belt Online Seminar] AWS Glue)
テーブルのスキーマおよびスキーマを一覧、比較することが可能です。また手動でスキーマ項目を追加、削除、型の変更が可能です。
パーティション
先のメタデータ定義の例にもあるように、Glueではテーブル定義にパーティションキーが含まれています。S3フォルダのデータを評価しテーブルのカタログを作成する際に、個別のテーブルまたはパーティション化されたテーブルのどちらを追加するか決定します。
S3フォルダーのパーティションテーブルを作成するには以下の条件をすべて満たしていいる必要があります。
- Glue が判断したファイルのスキーマが同様である
- ファイルのデータ形式が同じである
- ファイルの圧縮形式が同じである
例えば以下の例でiOSとAndroidの売上データファイルは、同じスキーマ、データ形式、および圧縮形式を持っているとします。この場合、データカタログではクローラーが、年、月、日のパーティショニングキーを持つ1つのテーブル定義を作成します。
my-app-bucket/Sales/year=2010/month=feb/day=1/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=1/Android.csv my-app-bucket/Sales/year=2010/month=feb/day=2/iOS.csv my-app-bucket/Sales/year=2010/month=feb/day=2/Android.csv ... my-app-bucket/Sales/year=2017/month=feb/day=4/iOS.csv my-app-bucket/Sales/year=2017/month=feb/day=4/Android.csv
パーティションキーの値を割り当てるためにフォルダ名に=記号が使用されています。
パーティションインデックス
経年とともにパーティション数があまりに増えるとGetPartitionsAPIの呼び出しがクエリパフォーマンスのボトルネックになる場合があります。そのような場合はパーティションインデックスを検討します。
クローラ
クローラはデータカタログにメタデータを作成するプログラムです。クローラを実行すると以下のアクションを使用してデータストアを調査します。
- 生データの形式、スキーマ、および関連プロパティを確認するためにデータを分類する
- データをテーブルまたはパーティションにグループ化する
- メタデータをデータカタログに書き込む
クローラは、以下のファイルベースおよびテーブルベースのデータストアをクロールすることができます。
| クローラが使用するアクセスタイプ | データストア |
|---|---|
| ネイティブクライアント | Amazon S3 Amazon DynamoDB Delta Lake |
| JDBC | Amazon Redshift Amazon RDS内、または Amazon RDS の外部: ・Amazon Aurora ・MariaDB ・Microsoft SQL Server ・MySQL ・Oracle PostgreSQL |
| MongoDB クライアント | MongoDB Amazon DocumentDB |
- 執筆時点ではデータストリーム(KinesisやKafkaなど)のクローラがサポートされていません
- クローラにはIAMロールを作成してアタッチすることができます
- S3およびDynamoDBをクロールするにはIAMで許可を与えます
- KMSで暗号化されているデータを読み取る場合、クローラの使用するIAMロールに復号のアクセス許可が必要です
増分クロール
Amazon S3データソースの場合、増分クロールは前回のクローラ実行後に追加されたフォルダーのみをクロールします。このオプションがない場合、クローラはデータセット全体をクロールします。増分クロールは時間とコストの削減に効果的です。
接続管理
クローラ、ジョブ、開発エンドポイントは特定の種類のデータストアにアクセスするためにGlueの接続を使用します。
「接続」は特定のデータストアの接続情報を保存するデータカタログのオブジェクトです。接続には、ログイン認証情報、URI文字列、VPC情報などが含まれソースとターゲットの両方に使用できます。
次の接続の種類を使用できます。
- JDBC
- Amazon Redshift
- Amazon Relational Database Service (Amazon RDS)
- Amazon DocumentDB
- DynamoDB
- Kafka
- Amazon managed streaming for Apache Kafka (MSK)
- Customer managed Apache Kafka
- Amazon Kinesis
- MongoDB
- Network (VPC内のデータソースへの接続を指定)
- Amazon S3
通常、パブリックインターネット上にあるAmazon S3ソースまたはターゲットには接続は必要ありません。しかしVPC内からアクセスする場合にはゲートウェイタイプのAmazon S3 VPCエンドポイントおよび、Networkタイプの接続が必要になります。
AWS Glue カスタムコネクタ
2020年8月にリリースされたカスタムコネクタによって、SaaSなどサードパーティとの接続をAWS MarketPlaceからサブスクライブするだけで追加したり、独自にコネクタを開発して利用できるようになりました。
サーバーレスエンジン
ここからはGlueのサーバーレスエンジンの構成要素について紹介していきます。
ジョブ
ジョブはGlueで抽出、変換、ロード(ETL)作業を実行するビジネスロジックで構成されます。以下は基本的なワークフローとステップを示したものです。

(引用元:AWS Glue でジョブを作成する)
- ジョブ用のデータソースを選択します。ソーステーブルは、データカタログで既に定義されている必要があります
- ジョブ用のデータターゲットを選択します。ターゲットテーブルは、データカタログで定義することも、ジョブを実行するときに作成することもできます
- ジョブと生成されたスクリプトの引数を提供することで、ジョブ処理環境をカスタマイズできます
- 初期状態ではGlueはスクリプトを生成しますが、このスクリプトを編集してソース、ターゲット、トランスフォームを追加することも可能です
- ジョブが呼び出す方法としてオンデマンド、スケジュール、イベントのいずれかを指定します
- 入力された情報により、GlueはPySparkまたはScalaスクリプトを生成します
Glueのジョブには以下の3タイプがあります
- Apache Spark
- Apache Spark ストリーミング
- Python shell
ストリーミングETL
2020年4月にストリーミングETLがリリースされたことで、従来はEMR(Spark Streaming)で行っていたようなKinesisやKafkaといったストリーミングデータのETL処理においてもGlueができるようになりました。
Glueバージョン
Glueバージョンによってジョブで使用できるApach SparkおよびPythonのバージョンが決まります。各バージョンごとの詳細は「AWS Glue リリースノート」を参照ください。
| Glueバージョン | サポートされるSparkおよびPythonバージョン |
|---|---|
| Glue 0.9 | Spark 2.2.1 Python 2.7 |
| Glue 1.0 | Spark 2.4.3 Python2.7/3.6 |
| Glue 2.0 | Spark 2.4.3 Python3.7 |
| Glue 3.0 | Spark 3.1.1 Python3.7 |
- Glue 3.0(2021年8月にリリース)
- Apache Spark 3.1.1をベースにパフォーマンスを最適化したランタイムを採用
- ベクトル化されたリーダーとS3に最適化された出力コミッターが利用可能になり読み書きが最適化
- パーティションインデックスにより不要なパーティションへのアクセスを削減することでパーティション数が膨大なデータで実行速度を向上
- Glue 0.9、Glue 1.0は2022年6月1日でサポート終了が発表されています
Worker Type
ジョブ実行時に割り当てる処理能力をDPU(Data Processing Unit)といい、Glueの料金はDPUに対する処理時間で決まります。
- 1DPU = 4vCPU、16GBメモリ
選べるWorkerTypeと必要となるDPU数は以下のとおりです。
| Worker Type | DPU数/1Worker | Executor数/1Worker | メモリ数/1Executor |
|---|---|---|---|
| 標準 | 1 | 2 | 5.5GB |
| G.1X | 1 | 1 | 12GB |
| G.2X | 2 | 1 | 24GB |
DynamicFrame
DynamicFrameはGlue独自のデータ表現であり、Sparkのデータ表現であるDataFrameと相互に変換可能です。Spark DataFrameがテーブル操作のために設計されたものに対し、Glue DynamicFrameはETLのために設計されています。
DynamicFrameでは最初にスキーマを必要とせず、読み込んだデータの要件とユースケースにあわせて後から自由にスキーマを決定できます。この型をChoice型といいます。

(引用元:[AWS Black Belt Online Seminar] AWS Glue)
DynamicFrameについてより理解を深めたいという方はこちらの記事をおススメします。
Choice型
複数の型を発見した場合に両方の型を持つことで処理を中断することなく進めることができます。Choice型はResolveChoiceメソッドで型を解決します。(ResolveChoice クラス)

(引用元:[AWS Black Belt Online Seminar] AWS Glue)
parquetとglueparquet
DynamicFrameをParquetフォーマットに変換して出力したい場合、parquetとglueparquetの2種類を設定できます。glueparquetはDynamicFrameの書き出しにパフォーマンス面で最適化されているため、通常はgluparquetでの出力がおススメです。
サーバレスETL処理の使い分け
AWS LambdaやAmazon EMRも含めた多様な選択肢から、必要とされる規模や処理によって選択します。

(引用元:統合データインテグレーションサービス AWS Glue 及び AWS Lake Formation 最新アップデート)
オーケストレーション
ここからはGlueで提供されるオーケストレーション機能について紹介していきます。
独自ライブラリの利用
AWS Glue 2.0 を使用して、ジョブレベルで追加のPythonモジュールまたは異なるバージョンをインストールできます。新しいモジュールを追加したり、既存のモジュールのバージョンを変更したりするには、--additional-python-modulesジョブパラメータキーを使用して、カンマで区切られたPythonモジュールのリストを含む値を指定します。これにより、AWS Glue 2.0 ETLジョブがpip3を使用して追加のモジュールをインストールできるようになります。
Glue0.9, Glue1.0ではC言語で記述されたライブラリ(pandasなど)はサポートされていませんでしたが、Glue2.0では--additional-python-modulesオプションを使用した追加がサポートされるようになりました。ただし、spacyやgrpcなどのPythonモジュールのサブセットをインストールするにはroot許可が必要です。root許可がない場合、モジュールのコンパイルが失敗します。
トリガー
トリガーによって指定されたジョブとクローラを開始できます。トリガーは以下の3つの組み合わせに基づいて起動します。
- スケジュール(cron)
- イベント
- オンデマンド
1つのトリガーで起動できるのは2つのクローラのみです。複数のデータストアをクロールする場合は、複数のクローラを同時に実行するのではなく、各クローラに複数のデータソースを使用します。
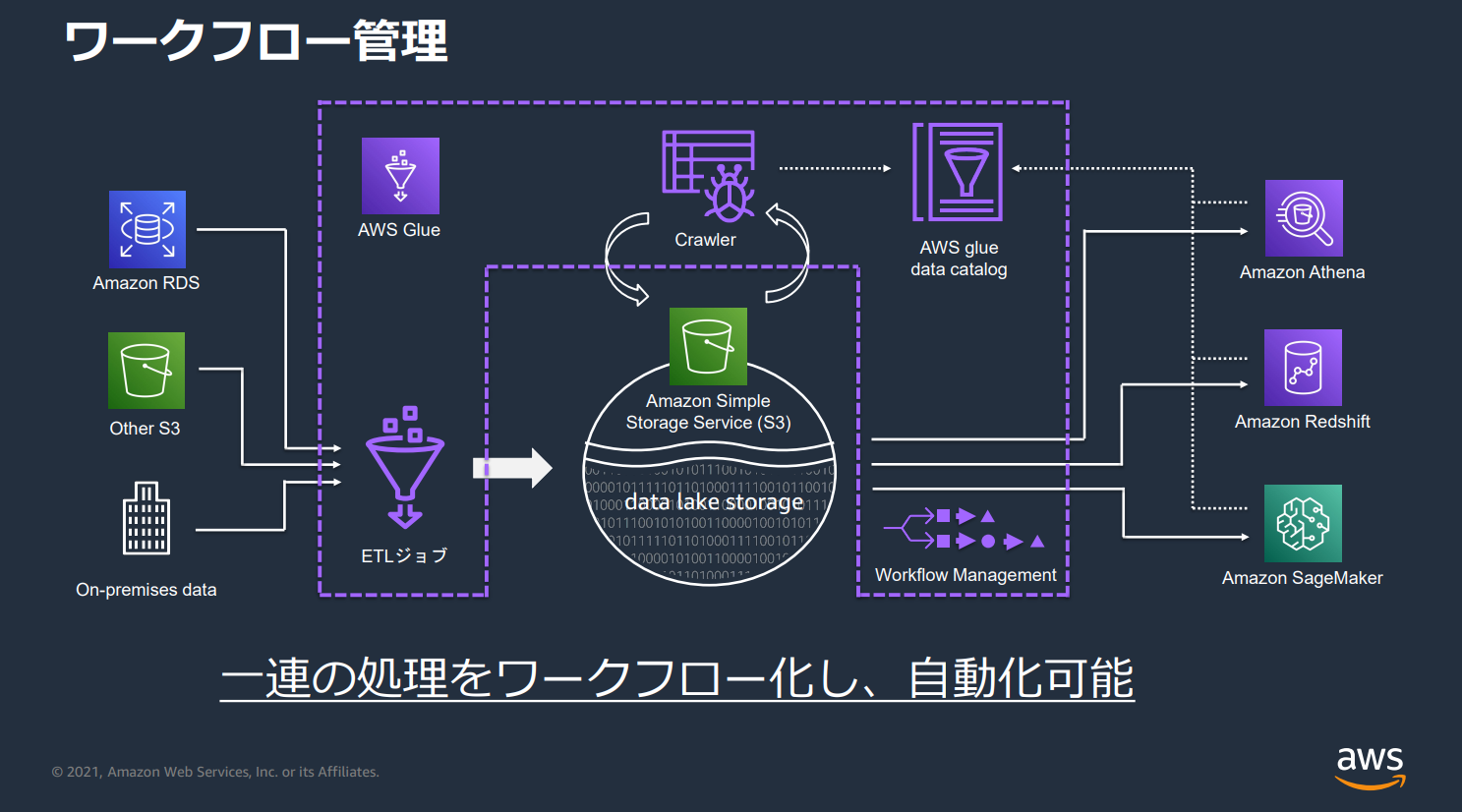
ワークフロー
複数のクローラ、ジョブ、およびトリガーを使う複雑なETLアクティビティを作成して可視化できます。

(引用元:[AWS Black Belt Online Seminar] AWS Glue)
ブループリント
2021年8月にリリースされたブループリント(設計図)からワークフローの作成が可能になりました。パラメータを使用することで単一のブループリントから類似した様々なユースケースのワークフローを展開することが可能です。
- サンプルブループリントも提供されています
開発環境
開発エンドポイントとNotebookサーバ
開発エンドポイントはジョブ実行環境に直接アクセスするためのアクセスポイントです。Amazon SageMaker(Jupyter)やZeppelinなどのノートブック環境から接続しETLスクリプトを作成およびテストできます。
開発エンドポイントは最低2個のDPUが必要、デフォルトでは5個のDPUが割り当てられます。
DPU時間あたり$0.44が1秒単位で課金されます。ジョブの実行有無にかかわらず開発エンドポイントを立ち上げている期間で課金が発生しますので利用時には気を付けたいところ。
AWS Glue Studio
2020年9月にリリースされた新しいビジュアルインターフェースのジョブ作成ツール。データ変換ワークフローを視覚的に構成し、AWS GlueのApache SparkベースのサーバーレスETLエンジンでシームレスに実行できます。
これまでジョブ作成にはApache Sparkのコードを記述するスキルが必要でしたが、不慣れなユーザでもボックスと矢印をつなげ、プルダウンメニューやチェックボックスなどを選択するだけでサーバーレスなApache SparkベースのETL処理が可能になりました。
AWS Glue DataBrew
2020年11月にリリースされたビジュアルデータ準備ツール。データアナリストやデータサイエンティストがデータのクリーニングや正規化を行い、分析や機械学習のためのデータ準備をコードを書くことなく実施できるようになりました。
Glue DataBrewとGlue Studioの違い
いずれもノーコードでデータ変換できる部分など似ているように思いますが、Glue StudioはどちらかといえばETL処理に特化しており、場合によってコードに手を加えるなどのカスタマイズに優れています。
一方でGlue DataBrewはデータアナリスト、データサイエンティストがデータの特性を理解したり、クリーニングしてデータを整えたり、データソースの変換を視覚的にトラッキングするなど、モデル作成するにあたってのデータ準備向けのツールとなっています。

(引用元:【AWS Black Belt Online Seminar】AWS Glue DataBrew)
インフラやアプリケーション関連のログから障害調査等のログ分析をするために、不要なフィールドを落としたい、Parquet形式に変換したい、といった用途であればGlue Studioのほうがシンプルで使いやすいと思います。(個人の感想です)
Glue Elastic Views(プレビュー)
AWS re:Invent 2020のキーノートセッションで発表されたマテリアライズドビュー機能です。
- カスタムコードを記述することなく、使い慣れたSQLを使用して複数のデータストア間でデータ結合および複製するマテリアライズドビュー(仮想テーブル)の作成が可能
- ソースデータストア内のデータに対する変更を継続的に監視し、ターゲットデータストア内のマテリアライズドビューに自動的に更新を反映し、常に最新であることを保証
AWS Glue 最近のアップデート
オートスケーリング(プレビュー)
2022年1月に発表されたオートスケーリング機能です。ジョブ実行の各ステージやマイクロバッチでの並列度合いに応じて、クラスターへのワーカー追加、削除を自動的に行います。スケーリング範囲は最大ワーカー数を指定することで制御可能です。
- Glue 3.0環境で利用可能
- 発表当時はオハイオのみでしたが、現在では東京リージョンでも利用可能
Interactive SessionとJob Notebooks(プレビュー)
2022年1月に発表されたデータ統合ジョブの開発プロセスを簡素化するのに役立つ新しいサーバーレス機能です。Glue Studioを介してノートブックを開始すると、数秒後に開発環境を手に入れることができます。
- Interactive Session
- クラスターの設定やプロビジョニング無しにセッションを開始
- 複数セッションを起動した場合、それぞれ独立した環境として提供されるので異なるプログラムやラインタイムを利用することも可能
- Job Notebooks
- インストール不要でJupyter Notebook環境にアクセス
- このプレビューは東京リージョンでも利用可能
Personal Identifiable Informationの検出と修復(プレビュー)
2022年1月に発表された個人情報の識別機能です。AWS Glueジョブの実行中に列レベルとセルレベルの両方で個人情報を自動的に検出し、必要に応じて是正措置を講じるオプションが含まれます。
- 東京、大阪リージョンでは未だ利用できません
- マイナンバーカードなど日本国内向けの個人情報には対応していません
LakeFormationへの拡張
GlueのデータカタログにLakeFormationの拡張されたセキュリティモデルを利用することで、より細やかなアクセスコントロール(行列単位やセル単位など)をシンプルに集中管理することが可能となります。
データカタログを中心としたデータ連携を行うことで、最新バージョンのデータ利用やセキュリティといったデータ共有の課題解決や、データ複製をもたないことでのコストメリットが得られます。

(引用元:統合データインテグレーションサービス AWS Glue 及び AWS Lake Formation 最新アップデート)
さいごに、AWS Glueを学ぶためのワークショップ紹介
そろそろAWS Glueを触ってみたくなってきたのではないでしょうか?
これまでAWS GlueはSparkやPythonといったETL処理のコードを書く必要がありましたが、Glue Studio、Glue DataBrewの登場によって圧倒的に簡単にETL処理を実装できるようになりました。
「なんだかよくわからないな、、」と思っている方もワークショップでETL処理の実装までを体験していただくと、その簡単さに感動すると思いますので是非一度お試しください。
- AWS Glue Hands-On Labs
- AWS Glue DataBrew Immersion Day
- AWS Glue Studio Workshop
- Introduction to AWS Glue and Glue Databrew
- Amazon Personalize with Glue DataBrew
以上、『AWS再入門ブログリレー2022』の39日目のエントリ『AWS Glue』編でした。
3/30(月)は青柳の「AWS Directory Service」の予定です。お楽しみに!!










