![[レポート] Deep dive on AWS Glue Elastic Views #reinvent #emb019](https://devio2023-media.developers.io/wp-content/uploads/2020/11/eyecatch_reinvent-2020-session-report.jpg)
[レポート] Deep dive on AWS Glue Elastic Views #reinvent #emb019
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは。サービスグループの武田です。
開催中のre:Invent 2020でDeep dive on AWS Glue Elastic Viewsのセッションを視聴しましたのでレポートします。
何度か配信がありますので視聴したい方はスケジュールを確認してみてください。

セッション概要
- スピーカー
- Akshat Vig(AWS Speaker)
- Almann Goo(AWS Speaker)
- タイトル
- Deep dive on AWS Glue Elastic Views
- EMB019
AWS Glue Elastic ViewsはAWS Glueの新しい機能で、カスタムコードを書くことなく、複数のデータストア間でデータを結合して複製するためのマテリアライズド・ビューを簡単に構築することができます。このセッションでは、AWS Glue Elastic Viewsを使ってSQLを使ってマテリアライズドビューを作成する方法を学びます。また、ソースデータストアからターゲットデータストアにデータをコピーし、ソースデータストアのデータの変更を継続的に監視し、ターゲットデータストアに自動更新を提供する方法を学びます。
アジェンダ

- なぜAWS Glue Elastic Viewsなのか
- AWS Glue Elastic Viewsが解決する問題は何か
- 主要な機能
- スケーラビリティ、正しさ、コントロール
アプリケーション開発について

アプリケーション開発には2つのコンポーネントがあり、ひとつはビジネスロジックであり、もうひとつはデータベースです。オンラインショッピングポータルを例にすると、ショッピングサービスは複数のサブアプリケーションから構成されるため、DBは複数の役割を担います。注文処理、注文や出荷状況の追跡、分析などです。従来はこれらを単一のDBで行ってきましたが、今日ではアプリケーションをより小さな単位に分割して、各部分ごとに構築をしています。

開発するアプリケーションの機能要件から、使用しようとしているDBに期待するパフォーマンスや特性、スケーリングなどを分析します。AWSは目的に応じたDBを提供しています。そのため、開発者はニーズに合わせて特定のDBを選択できます。たとえば分析であればAmazon Redshiftを選択できますし、出荷追跡であればDynamoDBでイベントを処理できます。
なぜAWS Glue Elastic Viewsなのか

ショッピングポータルの例に当てはめて、先ほどのDBの特性について再考してみましょう。具体的な要件はなんでしょうか?約100万ユーザーの利用者と100万 RPSのリクエストレートを達成する必要があります。これらのリクエストは一桁ミリ秒で処理されることを期待しますが、DynamoDBはこれらの条件を満たしています。そのため、アプリケーションローンチ時はDynamoDBを使用することになるでしょう。

運用開始後にフリーテキスト検索の機能追加が必要となりました。繰り返しになりますが、適切なデータストアを選択することが重要です。ここではElasticsearchを選択しましょう。アプリケーションは図のようになります。クライアントはマイクロサービスと通信をし、そのマイクロサービスがDynamoDBとElasticsearchを利用します。製品カタログはDynamoDBで管理されているため、Elasticsearchにデータを取り込む必要がありますが、そこには課題があります。
AWS Glue Elastic Viewsが解決する問題は何か

データの取り込みには次のような課題があります。
- 複雑なコードを書かなければいけない
- すべての障害ケースについて適切に処理しなければいけない
- パイプラインの管理をしなければいけない

Glue Elastic Views(以下、Glue EVと表記)はこれらの課題を解決するものです。つまりカスタムコードを書くことなく、複数のデータストアからデータをコピー・結合して、マテリアライズドビューを簡単に作成できるサービスです。パイプラインの管理は簡素化されスケールもしますし、データを読み込んで書き込むという退屈なコードを書く必要もなくなります。
主要な機能
Glue EVは次のような特徴を持ちます。
- データの変換と結合
- 複数のデータソースから取り込みが可能
- マネジメントコンソールから簡単に使用できる
- 直感的な操作が可能
- PartiQLによる制御
- PartiQLを利用したビューの定義
- 正しさ
- トランザクション的な正しさ
- 多様なデータ型を変換する正しさ
- ニアリアルタイム
- ソースの変更を継続的に監視し、実際に同期しているかを確認する
- セキュア
- データの暗号化
- IAMによるアクセス制御
- サーバーレス
- 高可用性
- スケーラブル
続いてGlue EVを利用するステップをマネジメントコンソールの画面で説明します。先ほどのDynamoDBからElasticsearchへの製品カタログコピーをユースケースとして見ていきます。

DynamoDBのテーブルはすでにあると仮定し、Glue EVで実際に行うのは次の3ステップです。
- Glue EVのテーブル作成および有効化
- 有効化するとソースからデータが流れ始める
- ビューの作成
- PartiQLで定義
- ビューの実体化
- ターゲットにデータが流れ始める

コンソールにログインして、ソースとしてDynamoDBを選択すると、DynamoDBに存在するテーブルのリストが表示されます。その中に製品カタログが見つかります。今回この製品カタログを実体化しようとしているので、それをクリックしてテーブルを作成します。

作成したテーブルはデフォルトでは無効化されています。

有効化ボタンをクリックするとデータはGlue EVに流れ始めます。また、DynamoDBに存在するデータのスキーマも自動的に発見されていることに気付くでしょう。

スキーマができたらビューを作成できます。PartiQLでクエリを書いて、マテリアライズしたい属性を選択できます。この例では、製品カタログを持っているすべての属性の中から、フリーテキスト検索をするための属性を選択しています。

ビュー定義のプレビューもできます。PartiQLで指定した5つの属性が投影され、最終的に実体化されることがわかります。ビューの定義が正しいことを確認したら次に進みます。

ターゲットを追加するため、[Materialize view]をクリックします。

ターゲットとなるデータストアを選択します。今回はAmazon Elasticsearch Serviceを選択し、実体化するドメインおよびインデックス名を入力し、[Add target]をクリックします。

[Materialize view]をクリックすれば完了です。

重要なのは、DynamoDBとElasticsearchはそれぞれが独自のデータ型を持っていますが、Glue EVは自動的に型のマッピングを提案してくれます。誤りがあるなら個別に指定もできます。
プログラム可能性と正しさ
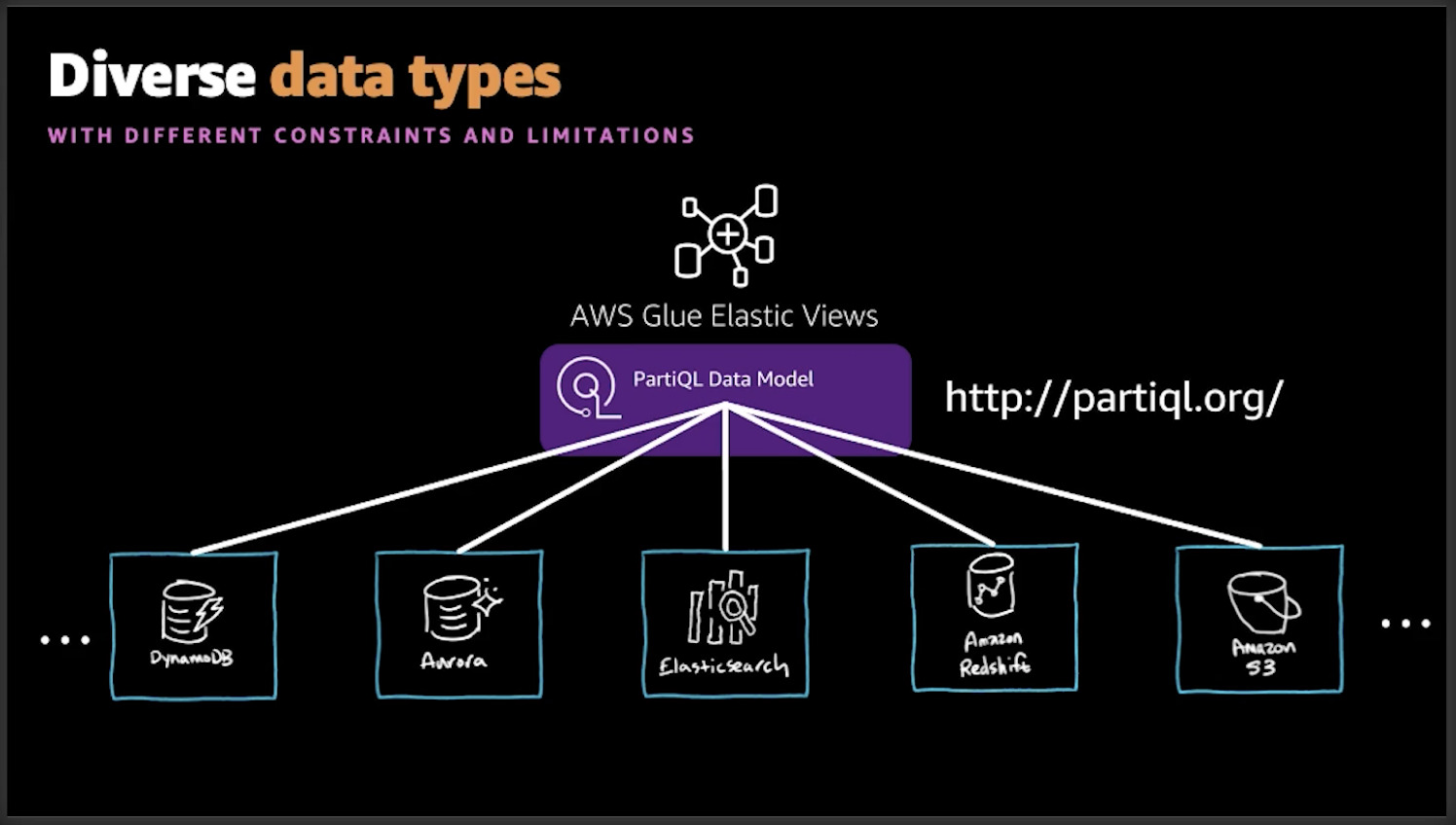
Glue EVはSQLの拡張機能をもったクエリ言語であるPartiQLを使用しており、データ損失のないデータ変換を開発者が定義できます。さまざまなソースをサポートするために、Glue EVは一種のハブとしてPartiQLのデータモデルとクエリ言語を導入しています。

PartiQLはSQLの拡張機能であり、一般的なスカラ値はもちろん、ドキュメントデータベースのような構造化された値を属性にもつレコードの操作も問題ありません。これによりDynamoDBのドキュメントなどもシームレスに扱うことができます。
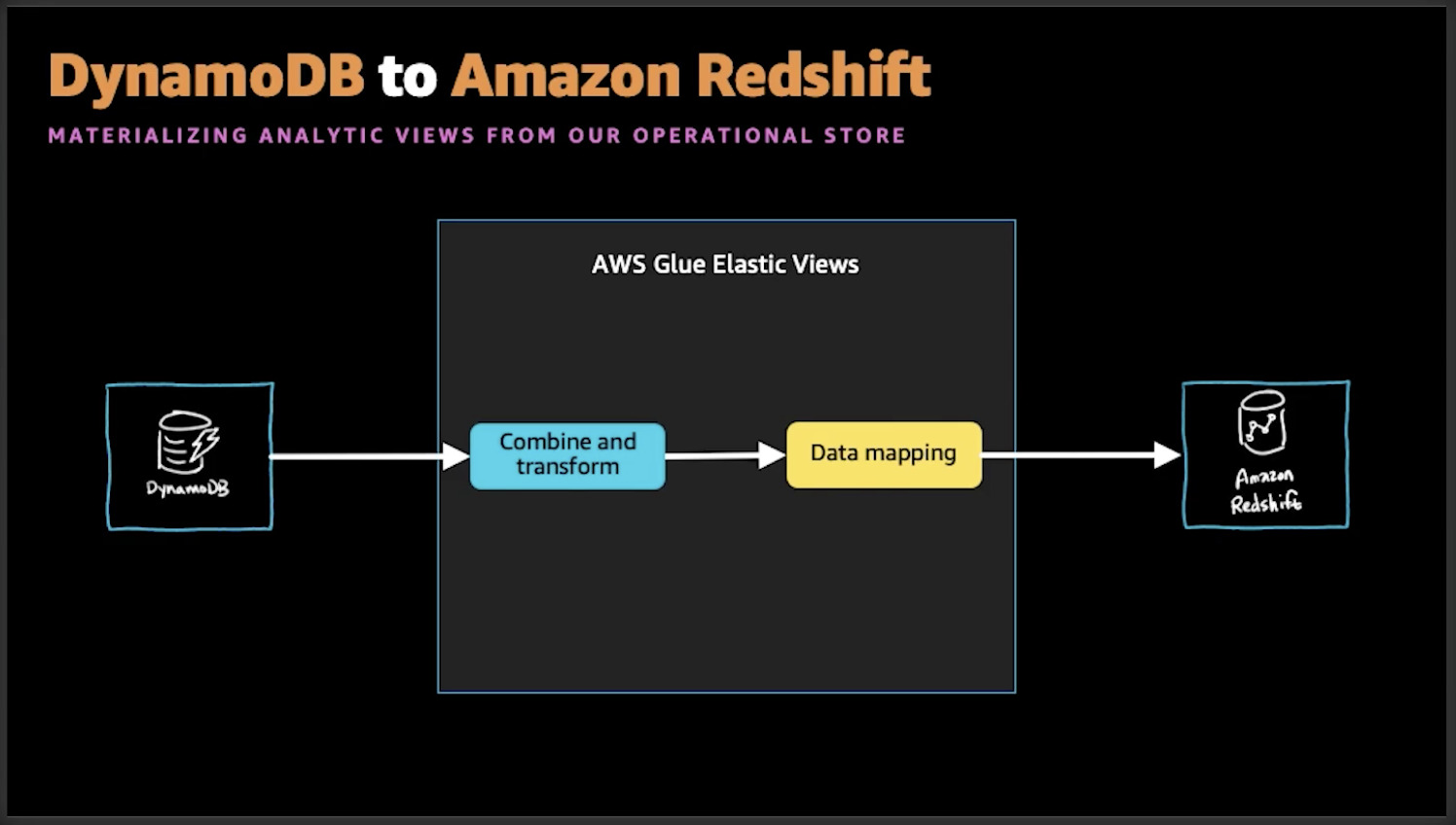
先ほどのショッピングポータルの例に戻って、ユーザーの注文に関するデータから分析をしたいユースケースを考えてみます。DynamoDBに注文情報があるためこれをソースとし、Glue EVに取り込みます。分析するのに必要な正規化やデータ変換のステップを追加しRedshiftに流せば完了です。

変換のステップを見てみましょう。元のデータはDynamoDBのドキュメントとして保存されています。Redshiftで扱うためには入れ子になったレコードをフラットにする必要があります。

変換クエリは従来のビューを作成するSQLと同じように書けます。PartiQLではクロスJOINの文法で入れ子データをフラットにできます。

具体的なデータで見てみます。元の注文データからフラット化され、また税金も計算されています。

次のステップはデータの互換性の問題です。分析用に論理的なビューを用意しましたが、DynamoDBとRedshiftは異なるデータ型をもっています。DynamoDBが保持している数値や文字列データをどのようにRedshiftにマッピングするかを検討し、明示的にいくつかの選択をしなければいけません。そしてRedshiftの型に対応するPartiQLの型を検討します。

検討した結果をマッピングビューとしてコードにします。選択した型に変換するため、クエリにCASTを追加しています。データのソースがどこかは関係なく、PartiQLがデータ変換をカバーしています。ただし、使用するデータベースによっては異なる制約がある可能性もありますので、そこは注意しましょう。

作成したマッピングビューで実行してみると、期待どおり変換が行われていることがわかります。

もし予期せぬデータがあった場合はどうなるでしょうか。たとえばUnicode文字列ではなくバイナリデータがレコードに入ってしまう可能性もあります。

そのようなケースでも、PartiQLを活用することで例外ケースを補足して別ファイルに出力し、運用分析に役立てることができます。

完成したパイプラインを振り返ってみると、データを結合する論理的な変換ビューがあります。そこに違反ビューを追加して、予期せぬケースや例外的なケースを捕捉しS3に実体化しています。またデータマッピングビューでは、DynamoDBからRedshiftへ、どのようにモデル化されるかを正確にコントロールしています。これらはすべて、ビュー構成の一例にすぎません。複雑なアプリケーションの要件に応じて、さまざまなことを行うことができます。

私たちの目標は、PartiQLをサポートし、結合やアグリゲートなどのお客様のニーズを満たすために強化することです。ここで重要なことは、お客様からのフィードバックに耳を傾け、お客様にもっとも価値のある機能や統合を優先して提供したいと考えています。ぜひプレビューに参加してください。
感想
re:Invent 2020で発表された新サービス、AWS Glue Elastic Viewsの背景や具体的なユースケースが理解できました。re:Inventの直前にDynamoDBがPartiQLのサポートを発表していましたが、Glue EVにつながっていたんですね。GAはもう少し先になるでしょうが、今からどう活用できそうか考えるのも楽しそうです。
AWS re:Invent 2020は現在絶賛開催中です!
参加がまだの方は、この機会にぜひこちらのリンクからレジストレーションして豊富なコンテンツを楽しみましょう!
AWS re:Invent | Amazon Web Services
またクラスメソッドではポータルサイトで最新情報を発信中です!










