![[レポート] Aurora を使用した費用対効果の高い RAG ベース生成 AI アプリ構築について議論するチョークトーク「Build a cost-effective RAG-based gen AI application with Amazon Aurora [REPEAT]」 #DAT313-R1 #AWSreInvent](https://images.ctfassets.net/ct0aopd36mqt/3IQLlbdUkRvu7Q2LupRW2o/edff8982184ea7cc2d5efa2ddd2915f5/reinvent-2024-sessionreport-jp.jpg?w=3840&fm=webp)
[レポート] Aurora を使用した費用対効果の高い RAG ベース生成 AI アプリ構築について議論するチョークトーク「Build a cost-effective RAG-based gen AI application with Amazon Aurora [REPEAT]」 #DAT313-R1 #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
コーヒーが好きな emi です。
AWS re:Invent 2024 で chalk talk 「Build a cost-effective RAG-based gen AI application with Amazon Aurora [REPEAT] (Amazon Aurora を使用した費用対効果の高い RAG ベースの生成 AI アプリケーションの構築)」に参加しました。
[REPEAT] がついているのは re:Invent 期間中何回か開催されるセッションです。
このチョークトークでは主に RAG を使ったシステムにおけるコスト削減手法が紹介され、議論が飛び交いました。
概要
タイトル:DAT313-R1 | Build a cost-effective RAG-based gen AI application with Amazon Aurora [REPEAT]
このチョークトークでは、費用対効果の高い生成AIアプリケーションを構築するための主な設計上の考慮事項について説明します。 Retrieval Augmented Generation(RAG)アーキテクチャの最適化戦略に焦点を当て、モデルの選択と最適化手法について学びます。 また、Amazon Auroraを使用した効率的なデータストレージと検索方法の実装についても学びます。 生成AIソリューションの全体的な費用対効果を確保するために役立つ、迅速なエンジニアリングのベストプラクティスと効果的な監視およびコスト追跡アプローチについても紹介します。
スピーカー
Shayon Sanyal(Principal WW SSA PostgreSQL, Amazon Web Services, Inc.)
Jim Mlodgenski(Senior Principal Engineer, Amazon Web Services)
Wednesday, December 4
1:00 PM - 2:00 PM PST
Caesars Forum | Level 1 | Summit 220
Session types: Chalk talk
Topic: Databases
Area of interest: Generative AI, Cost Optimization
Level: 300 – Advanced
Role: Data Scientist, Developer / Engineer, Solution / Systems Architect
Services: Amazon Aurora
レポート
チョークトークおなじみのホワイトボードがあります。

セッション概要
- モデル選択とプロンプトデザイン
- Retrieval Augmented Generation (RAG) の最適化
- キャッシュとメモリ管理
- アーキテクチャとインフラ最適化
- RAG の効果測定
上から順番に、コストへの影響が大きいものです。

AnyCompany の課題をもとにコストについて検討していく
AnyCompany という架空の企業が運用しているとても人気のカスタマーチャットボットについて考えます。
予測不可能なコストをユーザー体験を損なわずに最適化する方法を考えます。
- 1 日あたり 10 万件の質問がある
- 1 つの質問あたり平均1,900トークン(入力)、250トークン(出力)
- 初期 DB ストレージは 1TB で 1 日 17GB の増加
- インスタンスタイプは db.r7i.xlarge 2台

月額コスト全体の約 95% が LLM にかかっている状況です。
- 入力トークン:$17,100、出力トークン:$11,200、合計:$28,350
- Aurora
- インスタンス:$1,080
- ストレージ:$315。
- Titan Text v2 Embedding:$114

モデル選択とデザイン
- 「Bigger isn’t always better」(大きい方がいつも良いわけではない)
- 小規模モデルでも十分な場合は小規模モデルを選択
- モデルごとのコスト比較で、Claude 3 Haiku が最も低コスト(約 11 倍安い)

プロンプトダイエット
「太ったトークンの手入れ」と表現されていました。
- クリアで簡潔に書く
- コンテキスト(背景情報や前提条件)を含める
- 明確な指示を含める
- 期待されるアウトプットを記載
- 質問の目的を明確にする
- 具体例を示す
- サブタスクを分ける(複雑なタスクは小分けに)
- 実験しながら対応する

確かに入出力トークンが小さくスマートになればコスト削減になりますね。Bedrock のオンデマンドタイプの課金単位はトークンごとなので。
最適化の方法として以下があげられていました。
- 効率的な取得によりトークンの消費量を削減
- LLM 呼び出しの削減
- 必要最低限のデータを統合
- ナレッジベースの最適化
- 最小限のコストで繰り返し問い合わせを処理
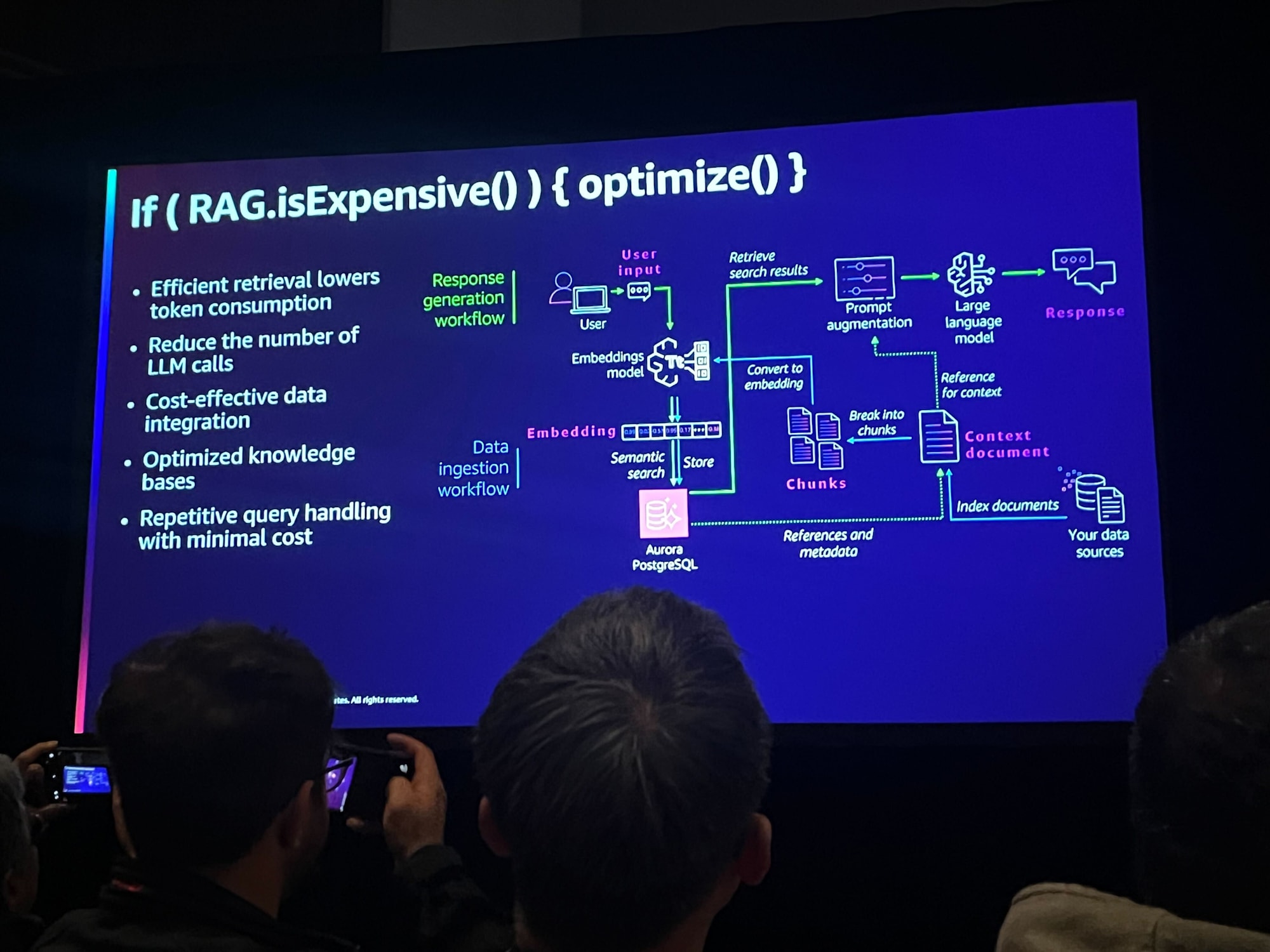
ちなみに if ( RAG.isExpensive() ) { optimize() } というのは実在する関数ではなく、プログラミング的な表現を使った比ゆ的なタイトルです。
チャンクサイズのバランス
目的によって小さいチャンクサイズが良いか大きいチャンクサイズが良いか調整します。
- 小さいチャンク(200トークン以下)
- 質問応答タスクに有利
- インデックスサイズが増大し、検索コストが高くなる可能性がある
- 大きいチャンク(2000トークン以上)
- テキスト要約や構造化データに有利
- コストが増加し、モデルの文脈長を超える可能性

チャンクについては チャンキング戦略 の解説が分かりやすいので参照ください。
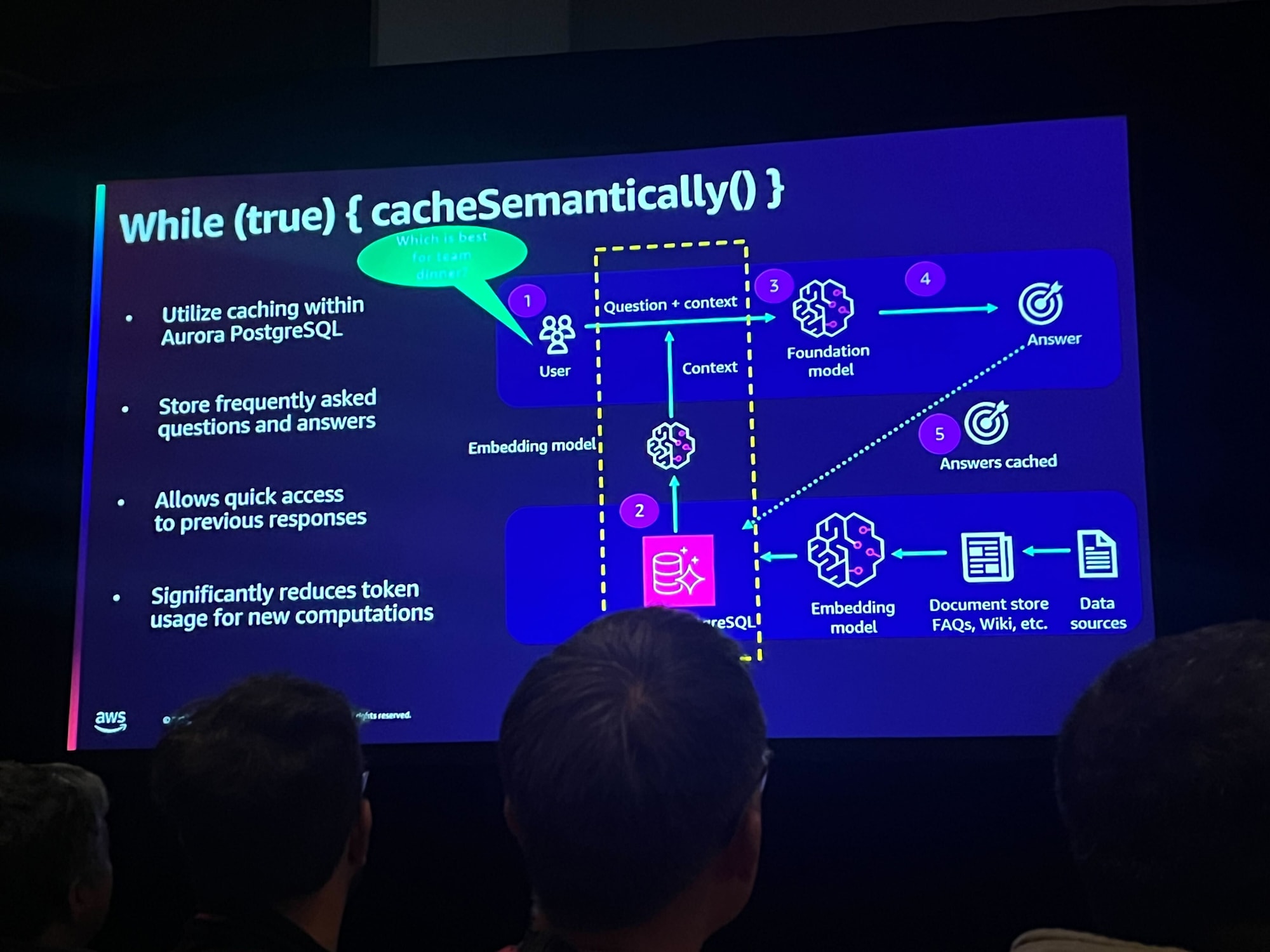
キャッシュとメモリ管理
キャッシュを活用して再利用可能なデータを保持してトークン消費を削減する手法が語られました。
- チャット履歴の効率化
- 必要な情報だけを保持
- Amazon Bedrock、LangChain、LlamaIndex を活用したメモリ管理
意味的キャッシング
(Aurora)PostgreSQL の組み込みキャッシュ機能を利用してよくある質問と回答を格納しトークン消費を削減すると良いそうです。
静的最適化
- インスタンスタイプの最適化
- リザーブドインスタンスの活用
バッチ推論の利用 (The bulk discount API)
- リアルタイム処理(オンデマンド)ではなく、バッチ処理を活用することで大幅なコスト削減が可能
- PostgreSQL のバルクローディング機能が利用できる

感想
コスト最適化と関連して、RAG の評価フレームワークとして以下の評価軸があることも紹介されました。
- 回答の関連性(質問に対して適切な回答か)
- 文脈の関連性(質問に関連するコンテキストを取得できたか)
- 根拠の妥当性(回答がコンテキストに基づいているか)
RAG に関してはとにかく「PoC!」 「やってみよう!」という流れを強く感じていて、コストへの影響についてそこまで考えたことが無かったので勉強になりました。便利でも莫大なコストがかかったら大変ですよね。
モデルの選択を見直すのが最もコストに影響があるというのは「まあそうだな」と思いつつ、以前 Claude 3 Haiku を使ったときは返ってくる応答がイマイチだなぁ…と思ったことがありました。ですが、さっき再度色々質問してみたら思ったより精度が高くなっていてちょっとびっくりしました。最近は徐々にモデルの精度が上がってきているのかもしれません。これなら本番運用でもハルシネーション少なくかつ低コスト高速で運用できるかもしれないと思いました。モデルの選択を変えるのは簡単ですしね。
トークンの削減手法なども勉強になりました。
データベース部分に関してはキャッシュの利用やインスタンスサイズの最適化というところが紹介され、通常のシステムと大差なかったように感じます。
チョークトークで後半は質疑応答が飛び交ったのですが、英語が難しく議論についていけなかったのが残念です。
余談
このセッションの後に以下のインタビューを受けました。








