
AWS re:Invent 2024のAmazon SageMaker AIのアップデートをまとめてみた #AWSreInvent
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データ事業本部 インテグレーション部 機械学習チームの中村( @nokomoro3 )です。
みなさま、re:Invent 2024はいかがでしたか?
本記事では、Amazon SageMaker AI(従来のSageMaker)のアップデートを機能別にご紹介します。
次世代SageMakerについては本記事では含んでいませんのでご注意ください。
その他のアップデートまとめについては以下を参照ください。
- 日付別
- AWS re:Invent 2024の0日目(現地日付12/1)のアップデートまとめてみた #AWSreInvent | DevelopersIO
- AWS re:Invent 2024の1日目(現地日付12/2)のアップデートまとめてみた #AWSreInvent | DevelopersIO
- AWS re:Invent 2024の2日目(現地日付12/3)のアップデートまとめてみた #AWSreInvent | DevelopersIO
- AWS re:Invent 2024の3日目(現地日付12/4)のアップデートまとめてみた #AWSreInvent | DevelopersIO
- AWS re:Invent 2024の4日目以降(現地日付12/5以降)のアップデートまとめてみた #AWSreInvent | DevelopersIO
- サービス別
Amazon SageMaker AI
冒頭に少し触れましたが、次世代SageMakerの発表に伴い、従来のAmazon SageMakerはAmazon SageMaker AIと名前を変えています。
次世代のSageMakerはマネジメントコンソール上はAmazon SageMaker Platformというサービスになっています。
SageMaker Studio
Amazon SageMaker Partner AI Appsを発表、プロバイダーのアプリがStudioで使用可能に
従来SageMaker内のアプリケーションというと、JupyterLabやCodeEditor、MLflowなどOSSベースのものをAWSが提供してくれていましたが、今回その幅が拡がり以下のアプリケーションがStudio内で使用可能となっています。
- Comet: AIモデル開発のための実験を追跡、視覚化、管理
- Deepchecks: AIモデルの品質とコンプライアンスを評価
- Fiddler: 生産中のAIモデルを検証、監視、分析、改善
- Lakera: プロンプト攻撃、データ損失、不適切なコンテンツなどのセキュリティ脅威からAIアプリケーションを保護

これらのアプリケーションは、SageMaker AIおよびSageMaker Unified Studioから使用することができます。
- 参考記事
推論の高速化・最適化
re:Invent 2024では、推論時にモデルやコンテナの読み込みを高速化したり、より推論時の処理を最適化する機能が多数発表がありました。
またこれらの後押しもあってか、SageMakerの推論エンドポイントがゼロスケール(最小インスタンス数0)に対応しており、個人的には待望のアップデートでした。
SageMaker Inferenceの新しいゼロスケール機能を発表
これまでは、SageMaker推論エンドポイントは、トラフィックが少ない、または全くない期間であっても、インスタンス数を0にはできませんでした。
このアップデートにより、使用されていない期間中にインスタンスをゼロにスケールできるようにエンドポイントを構成することが可能となります。
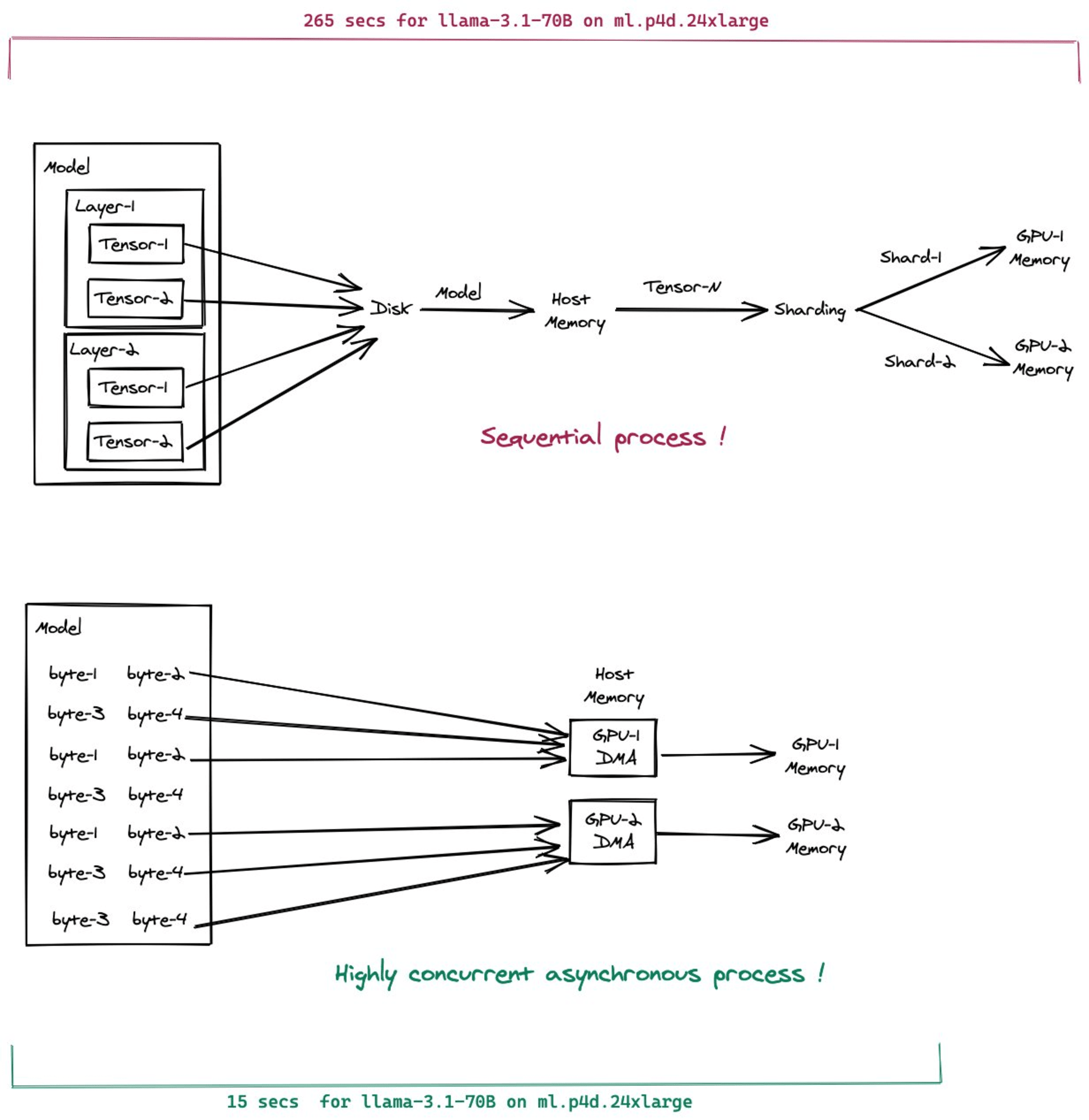
Amazon SageMakerでモデルの重みをAmazon S3からアクセラレータに直接ストリーミングするFast Model Loaderを発表
Fast Model Loaderは、S3からGPUに直接重みなどのモデルパラメータをストリーミングします。
従来、機械学習モデルの重みなどのパラメータは、S3からディスクに取得して、ホストPCメモリに展開した後にGPUなどのアクセラレータのメモリに転送が必要でした。
これをディスクを経由せずに、直接S3からホストPCメモリに転送することを実現したのがFast Model Loaderとなります。
またS3からホストPCメモリへの転送を待たずに、GPU側のメモリにストリーミングで転送することで、より待ち時間を短くしています。
使用するためには、SageMaker SDKからModelBuilderクラスを用いて、モデルを最適化、デプロイします。
- Introducing Fast Model Loader in SageMaker Inference: Accelerate autoscaling for your Large Language Models (LLMs) – part 1 | AWS Machine Learning Blog
- Introducing Fast Model Loader in SageMaker Inference: Accelerate autoscaling for your Large Language Models (LLMs) – Part 2 | AWS Machine Learning Blog
Amazon SageMakerの新しいコンテナキャッシング機能を発表
コンテナキャッシングは、コンテナイメージを事前にキャッシュし、スケールする際にダウンロードする必要性を排除することで、このスケーリングの課題に対処します。
本機能は以下のDeep Learning Containerで利用可能となっています。
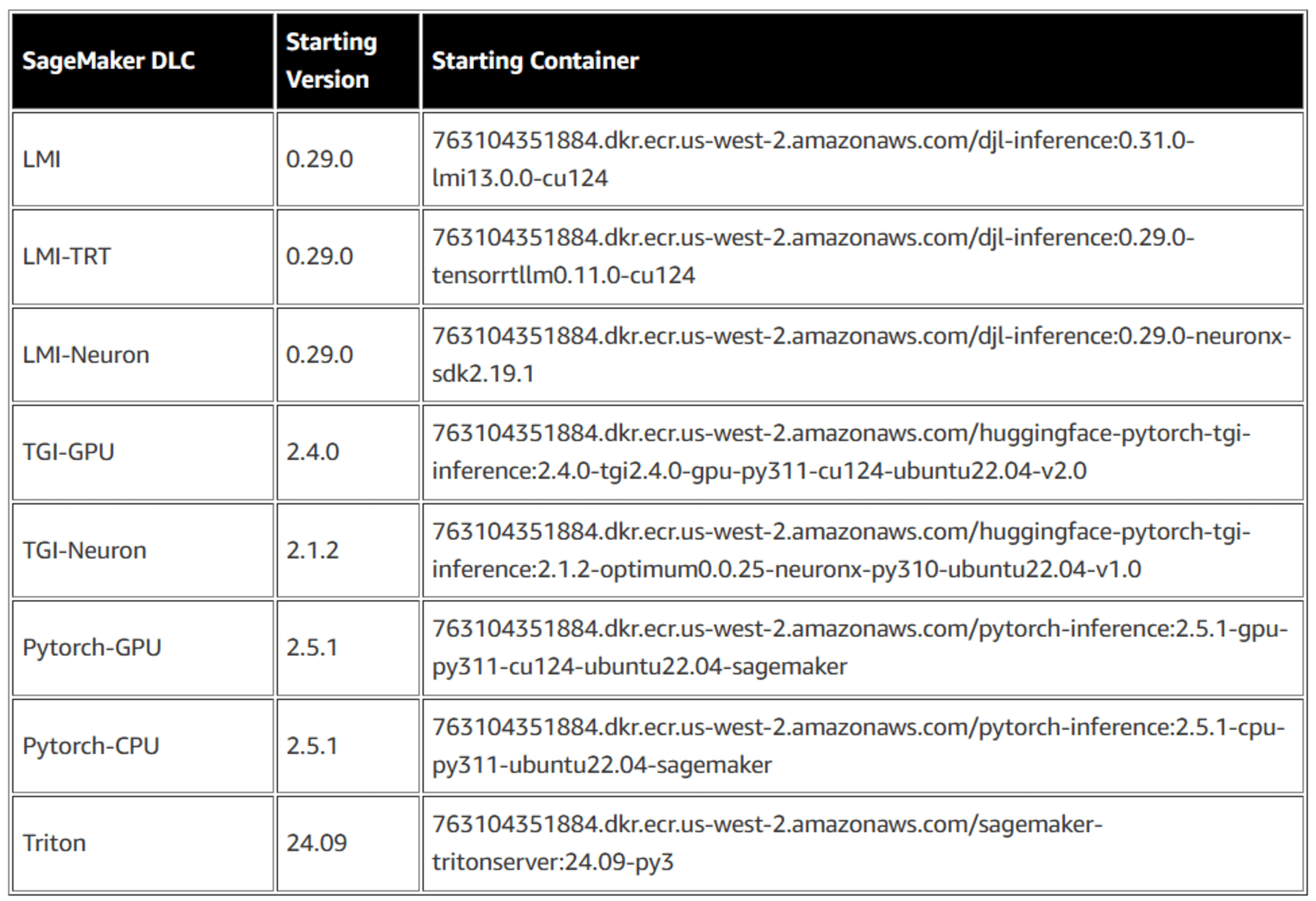
これらのコンテナを使用して、CreateInferenceComponentを作成することで、コンテナキャッシングは自動的に機能します。
Amazon SageMakerが推論最適化ツールキットのアップデートを発表
推論最適化ツールキットのアップデートを発表し、生成AIモデルをより速く最適化するための新機能と機能強化を提供します。
具体的には投機的(Speculative)デコード処理のサポート、FP8量子化のサポート、TensorRT-LLMのコンパイルなどの機能を新たに提供しています。
これらの機能もModelBuilderを使用することによって利用可能です。
- 参考記事
- Amazon SageMaker launches the updated inference optimization toolkit for generative AI | AWS Machine Learning Blog
- Achieve up to ~2x higher throughput while reducing costs by ~50% for generative AI inference on Amazon SageMaker with the new inference optimization toolkit – Part 1 | AWS Machine Learning Blog
- Achieve up to ~2x higher throughput while reducing costs by up to ~50% for generative AI inference on Amazon SageMaker with the new inference optimization toolkit – Part 2 | AWS Machine Learning Blog
NVIDIAアクセラレーテッド・コンピューティングとソフトウェア提供により、AI推論ワークロードを高速化する新機能を発表
NVIDIA NIMは、生成AIモデルをデプロイ・管理するためのマイクロサービスフレームワークで、こちらがAWS Marketplaceで利用可能となりました。
それに加え、NVIDIAが開発したLLM、Nemotron-4がSageMaker JumpStartで利用可能となっています。
またNVIDIA製のGPUが搭載されているP5e(H200)およびG6e(L40S)インスタンスがSageMakerで利用できるようになりました。
- 参考記事
- [セッションレポート]【AIM241-S】Build, customize, and deploy generative AI with NVIDIA on AWS | DevelopersIO
- Speed up your AI inference workloads with new NVIDIA-powered capabilities in Amazon SageMaker | AWS Machine Learning Blog
- Amazon Bedrock Marketplace now includes NVIDIA models: Introducing NVIDIA Nemotron-4 NIM microservices | AWS Machine Learning Blog
Amazon SageMaker HyperPod
SageMaker HyperPodはre:Invent 2023で発表された、生成AIなどの大規模なモデルを並列分散トレーニングするためのサービスです。
re:Invent 2024ではこのHyperPodに関するアップデートも多くありました。
Amazon SageMaker HyperPod flexible training plansがGAし、大規模なMLモデルの柔軟なトレーニングが可能に
HyperPodでflexible training plansというものが使用可能になりました。
使用には、特定の期間または複数の期間であらかじめクラスタを使用する計画を作成し、前払いでインスタンスの料金を支払います。
作成されたプランにあらかじめジョブを割り当てて処理をさせることが可能で、複数の期間がある場合はSageMaker AIのManaged Spot Training同様に、自動で中断して再開するなども可能です。
この機能は、ml.p4d.48xlarge, ml.p5.48xlarge, ml.p5e.48xlarge, ml.p5en.48xlarge, ml.trn2.48xlargeと大きなインスタンスをサポートしています。
- 参考記事
- [アップデート] Amazon SageMaker HyperPod flexible training plans が発表されました #AWSreInvent | DevelopersIO
- Amazon SageMaker HyperPod now provides flexible training plans - AWS
- Meet your training timelines and budgets with new Amazon SageMaker HyperPod flexible training plans | AWS News Blog
- Speed up your cluster procurement time with Amazon SageMaker HyperPod training plans | AWS Machine Learning Blog
Amazon SageMaker HyperPod task governanceがGAし、リソースの割り当てにガバナンスを効かせることが可能に
HyperPodでtask governanceという機能が使えるようになりました。
こちらは、コンピュートリソースの割り当てを完全に可視化および制御を実現するもので、最も重要なタスクに優先順位を付け、コンピュートリソースの利用率を最大化し、モデル開発コストを最大40%削減することができます。
監視機能として従来はGrafana等の準備が必要でしたが、主要なメトリクスがコンソールで確認できるようになっています。また、必要に応じてAmazon CloudWatch Container InsightsまたはAmazon Managed Grafanaとも統合できます。
加えてクラスターポリシーを使って、リソースの割り当てにガバナンスを持たせることができます。
- 参考記事
Amazon SageMaker HyperPod recipesの発表し、トレーニングスタックによる学習の迅速な開始が可能に
Amazon SageMaker HyperPod recipesを使用すると、最先端のパフォーマンスで、一般公開されている基盤モデル (FM) のトレーニングやファインチューニングをすぐに開始できます。
こちらはキーノートでは紹介されませんでしたが、同日にアップデートとしてアナウンスされています。
実際にはGitHub上でレシピが公開される形となっています。
レシピにはAWSによってテストされたトレーニングスタックが含まれているため、さまざまなモデル構成を試す退屈な作業がなくなり、評価とテストを何週間も繰り返す必要がなくなります。
レシピは、トレーニングデータセットのロード、分散トレーニング技術の適用、障害からの迅速な復旧のためのチェックポイントの自動化、エンドツーエンドのトレーニングループの管理など、いくつかの重要なステップを自動化します。
- 参考記事
まとめ
いかがでしたでしょうか。こちらで一通りAmazon SageMaker AIのアップデートはおさらいできるかと思います。
本記事がみなさまのご参考になれば幸いです。









