
【レポート】S3 Tablesの最新動向と導入事例・ベストプラクティス #AWSreInvent #STG334
はじめに
こんにちは。データ事業本部の渡部です。
AWS re:Invent2025のセッション「Amazon S3 Tables architecture, use cases, and best practices」を視聴したので、自分なりにこれはと思ったところをまとめます。
2025年のS3 Tablesのアップデート
2025年のS3 Tablesにあったアップデート一覧です。
私が参加していた去年のre:Invent 2024で発表となったS3 Tables。はじめになかった機能群がどんどん追加されていき、ますます実用的になっていっています。
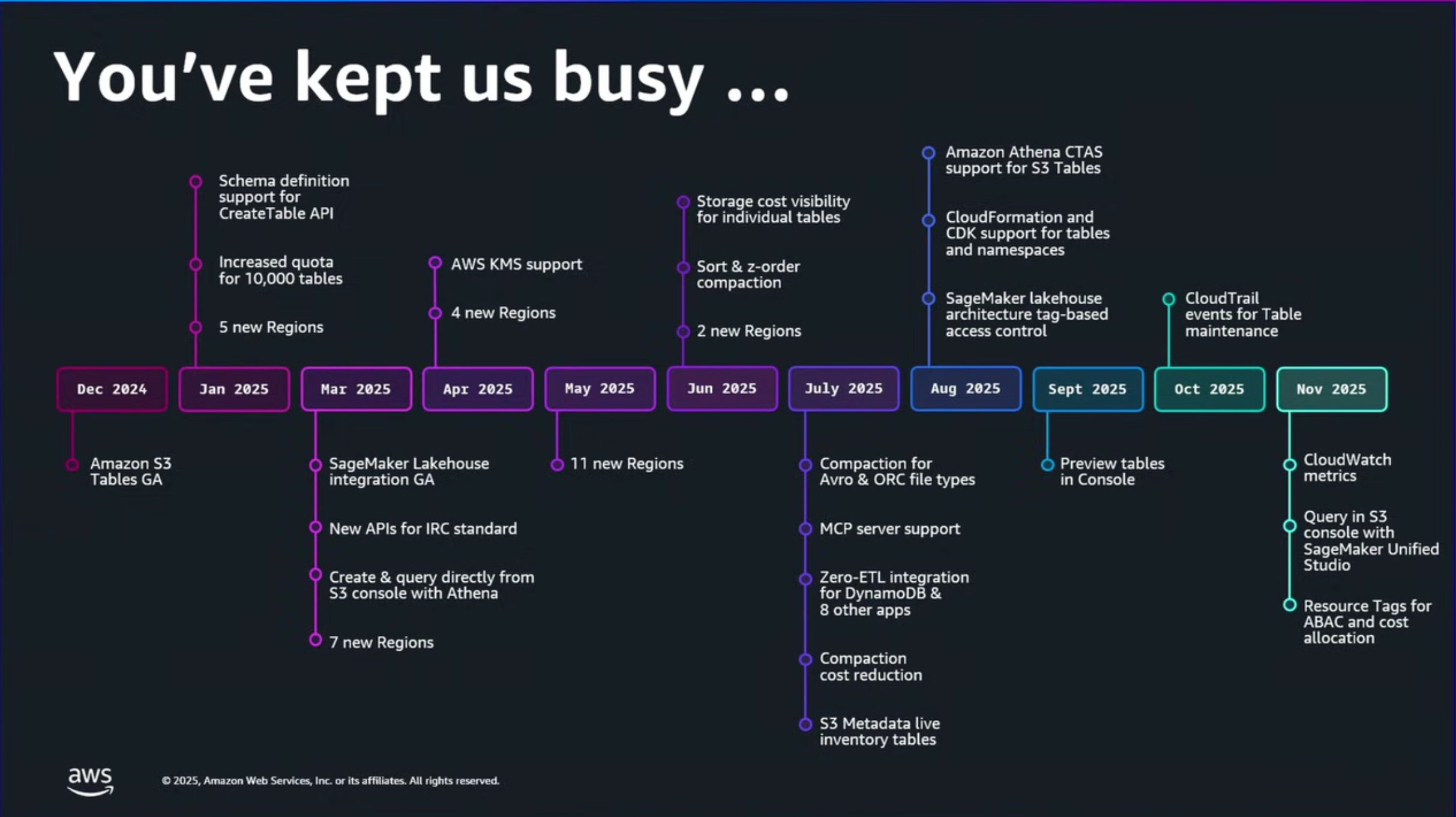
CTASがサポートされたり、
タグを使用したTBACがサポートされたり(ABACも今年4月にサポート)。
今年のre:Invent2025まわりではS3 Tablesに主に3つのアップデートがありました。
Iceberg v3でDeletion VectorsとRow Lineageのサポート。パフォーマンスやコンプライアンス、データ保護の要件に対応するレプリケーション。ストレージコストの最適化に使用できるIntelligent-Tierlingストレージクラスです。
特にRow Lineageがサポートされたことで、CDCをはじめとした増分処理など今後のAWSサービスアップデートがあったりするのではないかと思っています(GlueでMatelialized Viewが最近サポートされたのがこの一環ですかね)。
またS3 Tablesのレプリケーションは別アカウント・別リージョンへのリードレプリカを作成することができ、例えばデータ保護で使用する場合はIntelligent-Tieringストレージクラスをレプリカ側で使うことによって、より低コストにレプリカを保持することが可能です。
レプリケーションで面白かったのは、データソース側で侵害や開発者の誤った変更によって空のメタデータがコミットされても、レプリケーション側では破壊的な変更を検知して、破壊的なメタデータを上書きとして適用するのではなく、整合性を保つ形でIcebergの仕様に則ってマージを試みるということでした。
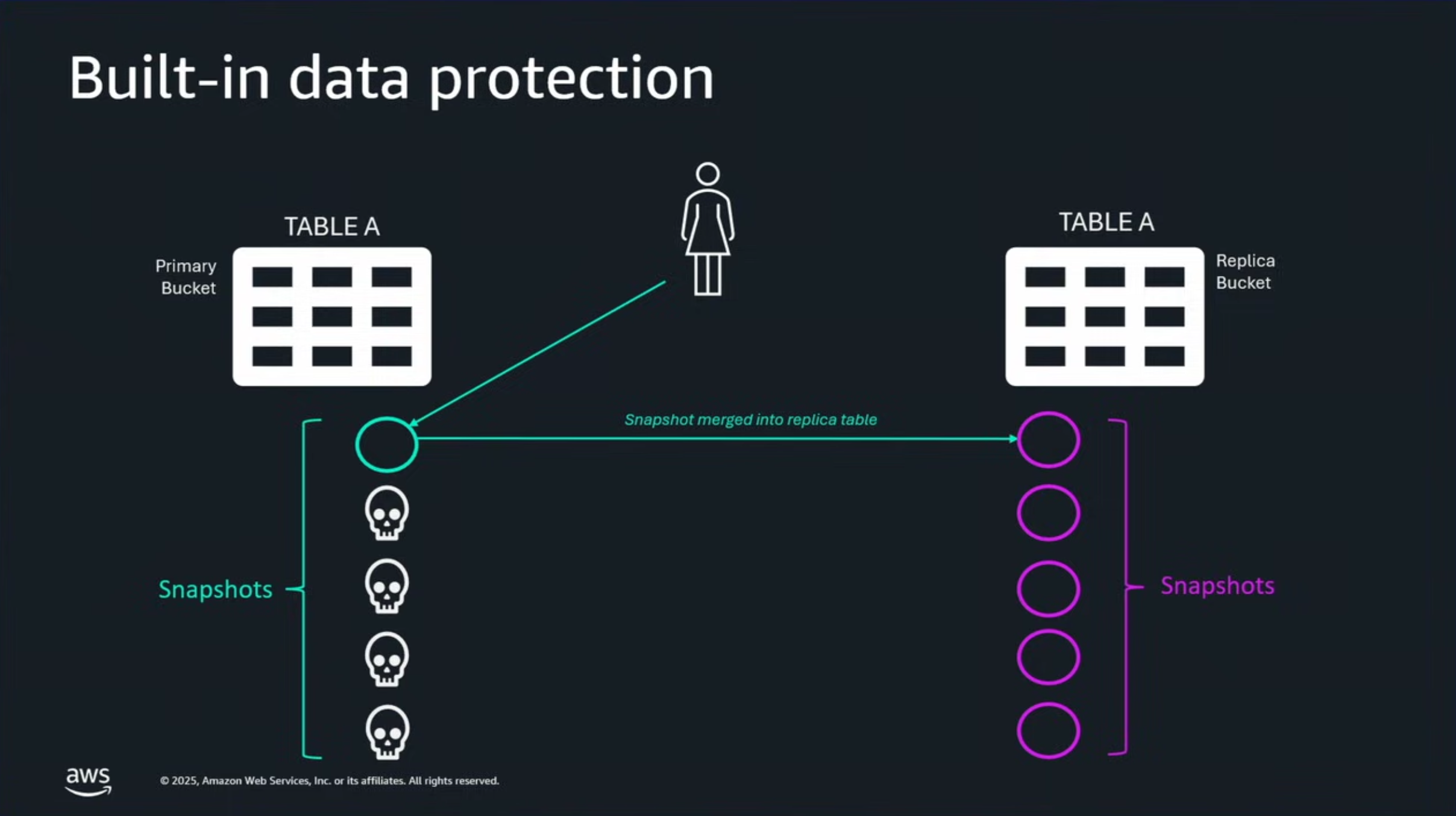
結果として、レプリカは過去の完全な履歴を保持し続けます。
空のメタデータがコミットされるという状況が何を指すのかわからなかったのですが、メタデータロケーションの変更やスナップショット保持ポリシーの誤った適用を指すのでしょうか。とにもかくにもレプリカ側はデータ履歴を優先するということですね。
単なるレプリケーションではなく、こういった機構が含まれているのはデータ保護の観点でありがたいですね。
S3 Tablesのおすすめメンテナンス設定
S3 Tablesのメンテナンスではスナップショット保持ポリシーや孤立ファイルの削除ポリシーを設定することができます。
セッションではこちらの推奨設定について解説されていました。
まずスナップショット保持ポリシーについては、最大スナップショット保持期間を3日、最大スナップショット数を120(デフォルト)にするのがよいとのことです。
これはバッチETLを想定していて、バッチ処理はコミット頻度が比較的低いため、デフォルト設定で十分なタイムトラベルによる履歴を確保できるからということでした。
高頻度なストリーミング(1分1回など)であれば最大スナップショット保持期間を24時間以下にして、クエリが読み取るメタデータの量を抑えてパフォーマンス低下を防ごうということでした。
孤立ファイルの削除ポリシーについてはデフォルトの3日を推奨としていて、ETLが頻繁に失敗するなどの状況がなければ基本はこれでよいということです。
このあたりの設定は企業のセキュリティポリシーなどに従って決めつつ、上記のような考えに従って設定をしていきたいです。
Indeed社の事例
S3 Tablesにデータ基盤を移行したIndeed社の話がありました。
なおIndeed社の移行のセッションについては以下で詳しく語られているので、ご参考ください。
S3 Tables移行前の状況と課題
Indeed社は求職者の就職支援をする企業であり、データレイクはその事業規模を反映して極めて大規模となっていました。
• データ量: 85ペタバイト(PB)以上のデータがデータレイクに格納
• テーブル数: 15,000を超えるデータセット(テーブル)が存在
• 処理量: 毎日550テラバイト(TB)を超える新規データがインジェストされ、1日あたり170,000件以上のクエリが実行されていました。
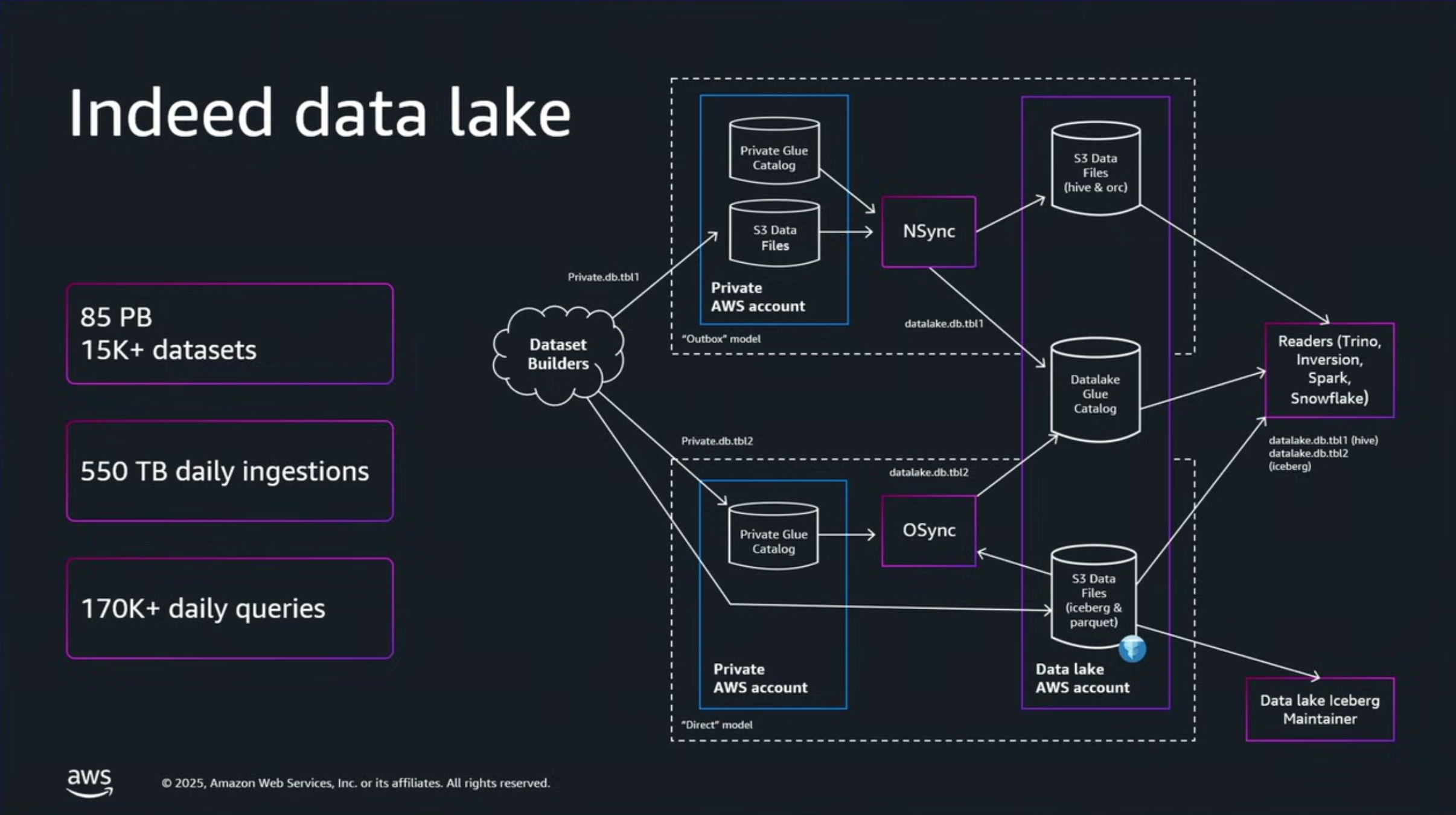
S3 Tables導入前は、S3汎用バケットでIcebergを管理していてメンテナンスを自前で管理していたとのことです。
従来の課題として4点挙げられていました。

- 持続不可能な運用負荷: Icebergテーブルのメンテナンス(コンパクション、スナップショット管理、孤立ファイルの削除など)のために、年間2,000開発時間以上を費やしていました。これは、Kubernetes上で独自のSparkジョブを実行して管理していたため、膨大なエンジニアリングリソースの浪費となっていました。
- オンボーディングの遅延: 新しいデータサイエンスチームやプロダクトチームをデータレイクにオンボーディングし、Icebergテーブルを利用可能にするまでに、1チームあたり丸1日以上を要していました。350以上のチームが存在するIndeed社にとって、これはイノベーションの大きなボトルネックでした。
- パフォーマンスと信頼性の問題: ピーク時のワークロード中にS3の読み取り制限(レートリミット)に遭遇することがあり、これが重大なインシデント(Severity 1/2)を引き起こし、データの可用性に影響を与えていました。
- 複雑で非効率なガバナンス: アクセス制御にS3のオブジェクトごとのタグ付けを使用していましたが、データレイク内の6億個のS3オブジェクトそれぞれにタグを管理・監査することは、セキュリティリスクとデータアクセスボトルネックを生じさせていました。
4はLake Formationを使用せずにIcebergを構成するファイルにタグ付けをしていたとのことで、大変な労力であることが伺えますね。。
S3 Tablesへ移行してこうなった

- データガバナンスを10,000倍簡素化:
6億超のS3オブジェクトに対するタグベースのアクセス管理を、AWS Lake Formation連携のテーブルリソースポリシーに刷新。データ分類の変更にかかる期間が数週間から1分未満に短縮されました。- 年間AWSコストを10%以上削減し、信頼性を向上:
マネージドメンテナンスへの移行で年間AWSコストを10%以上削減。さらに、S3の読み取り制限による深刻なサービス障害の発生リスクを解消しました。- 新規チームのオンボーディングを144倍高速化:
新チームがIcebergテーブルを利用開始するまでの時間が1日以上から10分未満へ短縮され、組織のイノベーションが加速しました。- プラットフォームチームに4ヶ月分の開発期間を創出:
年間2,000時間以上を要したIcebergテーブルのメンテナンスが不要になり、プラットフォームチームは4ヶ月分の開発リソースを他の優先事項に振り向けられるようになりました。
特にS3 Tablesに移行することで、マネージドでメンテナンスを実施してくれことがコスト的にも開発リソース的にもメリットがあったとのことです。
S3 Tablesのここが難しかった
S3 Tablesで運用コストを落としましたが、移行にあたって難しかったと語られていたことがありました。
それはアクセス制御がLake Formationを使用することです。
S3 TablesはLake Formationと密接に統合されており、アクセス制御はLake Formationを使用します。そのため別の方法で権限制御をしている場合は、Lake Formationで権限制御ができるように更新作業が必要となり困難だったということです。
上記を聞いたとき私は「ですよね〜」と思わず頷いてしまいました。
Lake Formation自体も理解するのに時間がかかるので、ここは移行の1つのハードルとなりますね。
とはいえ権限が一覧で見れたり設定ができるUIが用意されているのは非エンジニアの使用にとって大きな長所のため、ここは触りつつチーム内で知見をためていくのが良いかと思います。
さいごに
2025年のS3 Tablesについて振り返ることができてよかったです。
どんどん機能拡張を続けるS3 Tablesの2026年もアップデートも楽しみです。









