
re:Invent 2025のExpoでGrafana Labsブースにお邪魔し最新機能を聞いてきました! #AWSreInvent
「re:Invent 2025のExpoにGrafanaブースがある!」
先日まで開催されていたre:Invent 2025。私も7回目のre:Inventをしっかり楽しんできたわけですが、re:Inventの巨大なExpoにおいて、去年に引き続き今年もGrafana Labsが出展していたので、そちらの様子をご紹介します。
おそらくre:Inventで初めてGrafanaブースが登場したのは、2024年だったと思うのですが、去年よりも大きめの展示になっており、今Grafanaが推している機能を、Grafana Labsの方に説明いただいたので、その様子をお届けします。

"Higher-value telemetry, lower costs"
良いメッセージやで…
以下、Grafana Labsの社員の方に説明いただいた内容をもとに構成しています。
Adaptive Telemetryの機能について
Adaptive Telemetryは、一言で言うと、データの利用状況を自動分析し、使われていないデータの削減や集約を推奨・実行することで、可観測性を損なわずにコストとノイズを削減する機能群。
メトリクスやログなどのデータは「とりあえず全部送る」とコストが膨れ上がりがちですが、この機能を使うことで、価値のあるデータは残し、不要なデータは賢く減らすことができます。
Adaptive Telemetryの主な機能を紹介していきますね。
Adaptive Metrics(メトリクスの最適化)
これはメトリクスの管理とカーディナリティ最適化の機能ですね。ダッシュボードやアラート、レコーディングルール、クエリで実際にどのメトリクスが使われているかを分析して、「このラベル、30日間誰も見てないですよ」というのを教えてくれます。で、使っていないラベルは集約して低カーディナリティ版にすることで、時系列のメトリクスの数を大幅に減らせます。
Adaptive Logs(ログの最適化)
こちらはログのパターンを自動で認識して、「このパターンのログ、過去15日間でほとんどクエリされてないですよ」と教えてくれます。で、そういう低価値なログは一定割合でドロップしていい、というレコメンデーションを出してくれるんです。インシデント対応に必要なログはちゃんと残しつつ、デバッグログみたいな普段見ないものを削減できます。
Adaptive Traces(トレースの最適化)
分散トレーシングって、正常なリクエストも全部保存するとすごいデータ量になりますよね?Adaptive Tracesは「tail sampling」という技術を使って、トレース全体を見てからサンプリングを判断します。エラーがあるトレースや、レイテンシが高いトレースは確実に残して、正常なものは一部だけサンプリングする、といった柔軟なポリシーが設定できます。
Adaptive Profiles(プライベートプレビュー)
継続的プロファイリングのデータ収集を、ワークロードの状況に応じて動的に調整してくれます。問題が起きているときは高解像度でデータを取って、平常時はベースラインに抑える。これで、インフラ全体にプロファイリングを展開しても、コストが爆発しません。
具体的なAdaptive Telemetryの使い方のイメージ(デモ)
というわけで、その推し機能、Adaptive Telemetryについて説明していただいたデモの内容を、その流れとともにお伝えします!
不要なメトリクスを特定する (Adaptive Metrics)

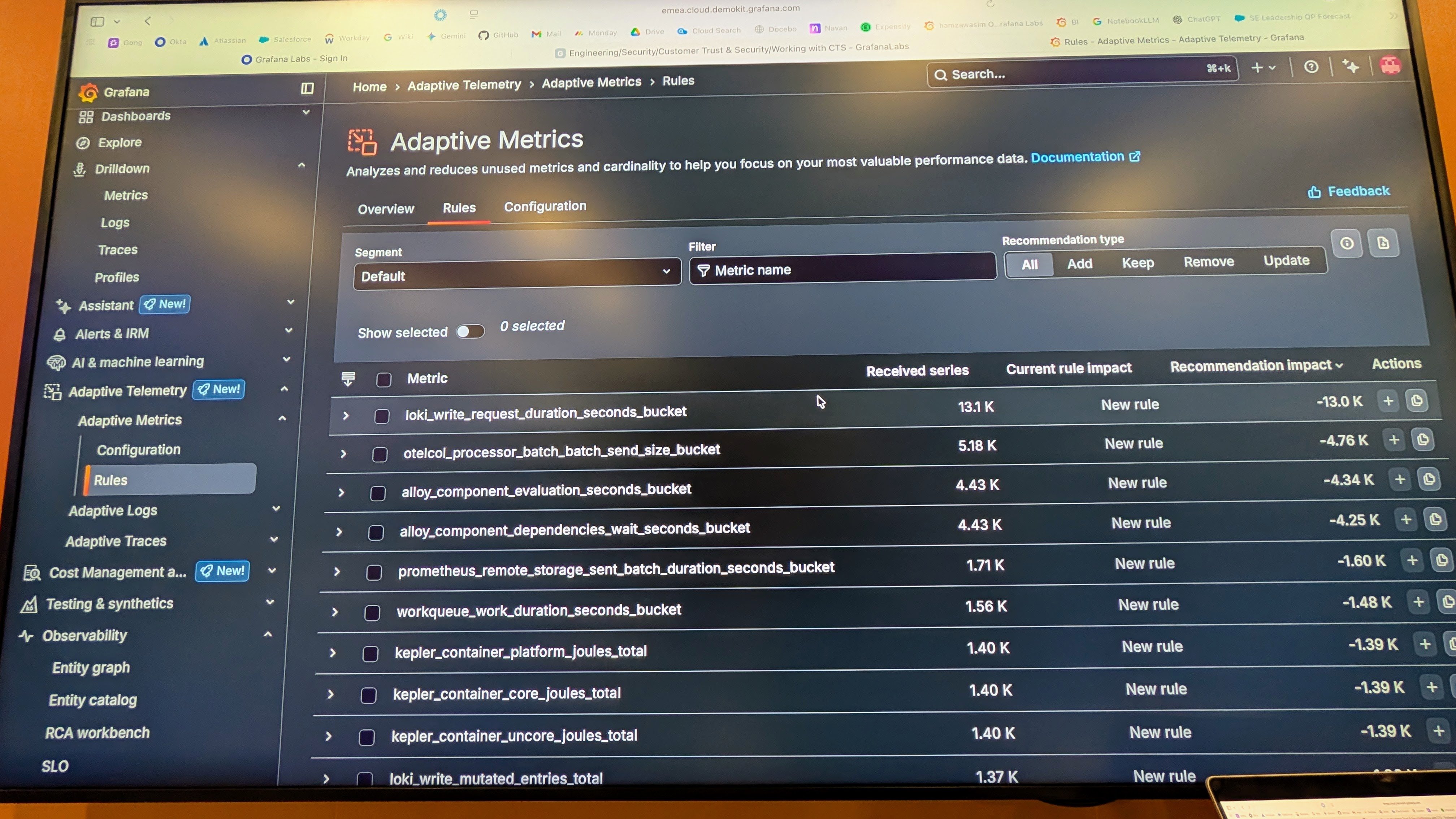
非常によく話題にあがる『メトリクスのコスト』について見ていただきます。これが Adaptive Metrics の実際の管理画面です。
ここにリストアップされているのは、Grafana CloudのAIが『過去30日間、誰もクエリで使っていない』と判断したメトリクスの一覧です。
- 例えば、一番上の
loki_write_request_...というメトリクスを見てください。 - これだけで 13,000 (13.0K) シリーズ データが発生していますが、実際はほとんど使われていません。
- 右側の『Recommendation impact』にある通り、ワンクリックで13,000シリーズ分のコストを削減できます。
右端の『+(Add)』ボタンを押すだけ。これで、必要な可観測性を維持したまま、無駄な課金を自動的にカットできます。
障害の主要原因をタイムラインで追う (RCA Workbench)

データを減らすと、いざという時に調査できないのでは?と心配になりますが、そこで見ていただきたいのが、こちらの RCA (Root Cause Analysis) Workbench。
これは、システム全体で何が起きているかを時系列で可視化したものです。
画面中央のタイムラインを見てください。赤いブロックが表示されています。これは frontend サービスで大きな障害(Failure/Error)が起きていることを示しています。その下にある productcatalogservice など、依存関係にあるサービスの状態も一目でわかります。
通常なら、各サービスのログを個別に検索して突き合わせる作業が必要ですが、ここでは全てのサービスの異常検知(Anomaly)やエラーが1つのタイムラインに統合されていて便利ですね。
AIを利用した原因究明 (Detailed RCA)
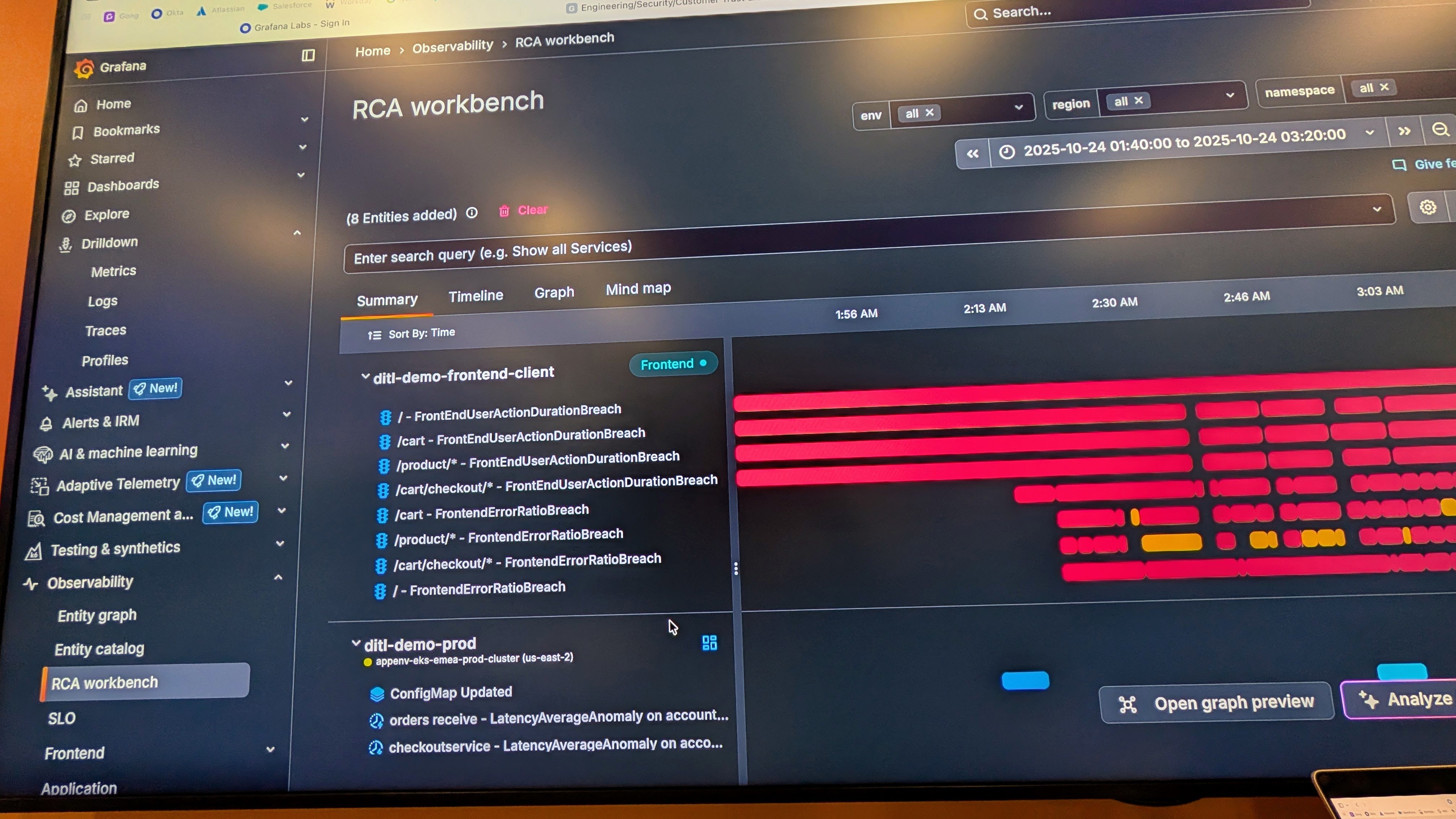
では、先ほどの frontend の赤いエラー部分をクリックすることで、さらに深掘りしてみます。
詳細画面を開くと、具体的に何が閾値を超えているのか(Breach)がリストアップされます。ここでは FrontEndUserActionDurationBreach(ユーザー操作の遅延)や FrontendErrorRatioBreach(エラー率の悪化)が検知されているのがわかります。右側の赤いバーが続いている時間帯が、まさに障害が継続している期間です。
Adaptive Telemetry で無駄なノイズデータは削減しつつも、このように障害対応に必要な重要なシグナルはしっかり残っています。だからこそ、AI(SiftやAsserts)がこのように正確に原因箇所を特定できます。
このあたりの障害原因の追求あたりは、Grafana Labsとしても非常に推している機能で、是非いろんな方にご活用いただきたいですね!
とりあえずやってみると良さそうなこと
今日からすぐにできるアクションとして、まずは『現状の分析(Analysis)』です。
Adaptive Metricsの良いところは、設定を有効化しても、実際に『Apply(適用)』ボタンを押すまではデータには一切変更を加えない点です。つまり、リスクゼロで『もし導入したらいくら安くなるか』という見積もりだけでも出すことができるので、使い勝手が良いですね。Grafana Cloud使っている方は、まずはここのダッシュボードだけでも見てみて、削減余地がないかどうか確認してもらえればと思います。
re:Invent 2025でみる、GrafanaとAWSとの親和性

(ブースでもらった日本版Grot君とともに)
ざっとですが、re:Invent 2025のExpoのGrafanaブースで聞いた内容を、ブログにまとめさせていただきました。最近は、AIアシスタントが提供されていたり、Grafana Cloudのアプデの勢いが止まりません。ブース全体も人がよく集まっておりAWSユーザーへの関心の高さが伺えます。
AWSのマネージドサービスとしてGrafanaが提供開始されたのが2020年12月。もう5年経っているなかでExpoにGrafanaがブース出しているのは、よりAWSのワークロードにおける拡大をGrafanaが狙っているというメッセージを感じました。自分も先日Grafana Championを拝命したので、これからもGrafanaを様々なシチュエーションで活用していきたいと思ってます。

今回、ブースを案内していただいたMiyatake sanと共に!これからもよろしくお願いします m(_ _)m

それでは今日はこのへんで。濱田孝治(ハマコー)でした。









