![[AWS Glue]ジョブブックマークのリセットの動作を確認してみた](https://devio2023-media.developers.io/wp-content/uploads/2019/04/aws-glue.png)
[AWS Glue]ジョブブックマークのリセットの動作を確認してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんにちは、CX事業本部の若槻です。
AWS Glueでは、ジョブブックマークのリセットをすることにより、すでにジョブで処理済みのデータを再度処理させることができます。
If you intend to reprocess all the data using the same job, reset the job bookmark. To reset the job bookmark state, use the AWS Glue console, the ResetJobBookmark Action (Python: reset_job_bookmark) API operation, or the AWS CLI.
今回は、AWS Glueでジョブブックマークのリセットの動作を確認してみました。
やってみた
まず最初に以降のコマンド実行で使用する変数を定義しておきます。
% AWS_REGION=ap-northeast-1
% ACCOUNT_ID=$(aws sts get-caller-identity | jq -r ".Account")
% RAW_DATA_BUCKET=s3://devices-raw-data-${ACCOUNT_ID}-${AWS_REGION}
% DATA_ANALYTICS_BUCKET=s3://devices-data-analytics-${ACCOUNT_ID}-${AWS_REGION}
% ETL_GLUE_JOB_NAME=devices-data-etl
環境構築
動作確認環境を作成します。
CloudFormationテンプレート
CloudFormationスタックのテンプレートです。(長いため折りたたんでいます。)
クリックで展開
<div>
AWSTemplateFormatVersion: '2010-09-09'
Resources:
DevicesRawDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-raw-data-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub devices-data-analytics-${AWS::AccountId}-${AWS::Region}
DevicesDataAnalyticsGlueDatabase:
Type: AWS::Glue::Database
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseInput:
Name: devices_data_analystics
DevicesRawDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_raw_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesRawDataBucket}/raw-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
DevicesIntegratedDataGlueTable:
Type: AWS::Glue::Table
Properties:
CatalogId: !Ref AWS::AccountId
DatabaseName: !Ref DevicesDataAnalyticsGlueDatabase
TableInput:
Name: devices_integrated_data
TableType: EXTERNAL_TABLE
Parameters:
has_encrypted_data: false
serialization.encoding: utf-8
EXTERNAL: true
StorageDescriptor:
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Columns:
- Name: device_id
Type: string
- Name: timestamp
Type: bigint
- Name: state
Type: boolean
InputFormat: org.apache.hadoop.mapred.TextInputFormat
Location: !Sub s3://${DevicesDataAnalyticsBucket}/integrated-data
SerdeInfo:
Parameters:
paths: "device_id, timestamp, state"
SerializationLibrary: org.apache.hive.hcatalog.data.JsonSerDe
ExecuteDevicesDataETLGlueJobRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Principal:
Service:
- glue.amazonaws.com
Action:
- sts:AssumeRole
Policies:
- PolicyName: devices-data-etl-glue-job-policy
PolicyDocument:
Version: 2012-10-17
Statement:
-
Effect: Allow
Action:
- glue:StartJobRun
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:job/devices-data-etl
-
Effect: Allow
Action:
- glue:GetPartition
- glue:GetPartitions
- glue:GetTable
Resource:
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:catalog
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:database/${DevicesDataAnalyticsGlueDatabase}
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesDataAnalyticsGlueDatabase}/${DevicesRawDataGlueTable}
- !Sub arn:aws:glue:${AWS::Region}:${AWS::AccountId}:table/${DevicesDataAnalyticsGlueDatabase}/${DevicesIntegratedDataGlueTable}
-
Effect: Allow
Action:
- s3:ListBucket
- s3:GetBucketLocation
Resource:
- arn:aws:s3:::*
-
Effect: Allow
Action:
- logs:CreateLogStream
- logs:CreateLogGroup
- logs:PutLogEvents
Resource: !Sub arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws-glue/jobs/*
-
Effect: Allow
Action:
- s3:GetObject
Resource:
- !Sub arn:aws:s3:::${DevicesRawDataBucket}/raw-data/*
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-script/devices-data-etl.py
-
Effect: Allow
Action:
- s3:GetObject
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/glue-job-temp-dir/*
-
Effect: Allow
Action:
- s3:PutObject
Resource:
- !Sub arn:aws:s3:::${DevicesDataAnalyticsBucket}/integrated-data/*
DevicesDataETLGlueJob:
Type: AWS::Glue::Job
Properties:
Name: devices-data-etl
Command:
Name: glueetl
PythonVersion: 3
ScriptLocation: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-script/devices-data-etl.py
DefaultArguments:
--job-language: python
--job-bookmark-option: job-bookmark-enable
--TempDir: !Sub s3://${DevicesDataAnalyticsBucket}/glue-job-temp-dir
--GLUE_DATABASE_NAME: !Sub ${DevicesDataAnalyticsGlueDatabase}
--SRC_GLUE_TABLE_NAME: !Sub ${DevicesRawDataGlueTable}
--DEST_GLUE_TABLE_NAME: !Sub ${DevicesIntegratedDataGlueTable}
GlueVersion: 2.0
ExecutionProperty:
MaxConcurrentRuns: 1
MaxRetries: 0
Role: !Ref ExecuteDevicesDataETLGlueJobRole
</div>
CloudFormationスタックをデプロイします。
% aws cloudformation deploy \
--template-file template.yaml \
--stack-name devices-data-analytics-stack \
--capabilities CAPABILITY_NAMED_IAM \
--no-fail-on-empty-changeset
Glueジョブスクリプト
データソースから取得したデータを変更を加えずデータターゲットに書き込むだけのPySparkスクリプトとなっています。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.dynamicframe import DynamicFrame
args = getResolvedOptions(
sys.argv,
[
'JOB_NAME',
'GLUE_DATABASE_NAME',
'SRC_GLUE_TABLE_NAME',
'DEST_GLUE_TABLE_NAME'
]
)
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
df = glueContext.create_dynamic_frame.from_catalog(
database = args['GLUE_DATABASE_NAME'],
table_name = args['SRC_GLUE_TABLE_NAME'],
transformation_ctx = 'datasource'
).toDF()
df.show()
dyf = DynamicFrame.fromDF(df,
glueContext,
'integrated_data'
)
glueContext.write_dynamic_frame.from_catalog(
frame = dyf,
database = args['GLUE_DATABASE_NAME'],
table_name = args['DEST_GLUE_TABLE_NAME'],
transformation_ctx = 'datasink'
)
job.commit()
スクリプトをS3バケットにアップロードします。
% aws s3 cp devices-data-etl.py \
${DATA_ANALYTICS_BUCKET}/glue-job-script/devices-data-etl.py
データソースとなるデータ
{"device_id": "3ff9c44a", "timestamp": 1609348014, "state": true}
{"device_id": "e36b7dfa", "timestamp": 1609375822, "state": true}
ジョブブックマークをリセットする
データソースへのデータ作成およびジョブ実行を2回ずつ行い、ジョブブックマークを2回分作成します。
% aws s3 cp raw-data-1.json \
${RAW_DATA_BUCKET}/raw-data/raw-data-1.json
% aws glue start-job-run --job-name ${ETL_GLUE_JOB_NAME}
% aws s3 cp raw-data-2.json \
${RAW_DATA_BUCKET}/raw-data/raw-data-2.json
% aws glue start-job-run --job-name ${ETL_GLUE_JOB_NAME}
Athenaでデータターゲットに対してSelectクエリを実行すると、ジョブで処理されたデータがロードされていることが確認できます。
SELECT * FROM "devices_data_analystics"."devices_integrated_data"
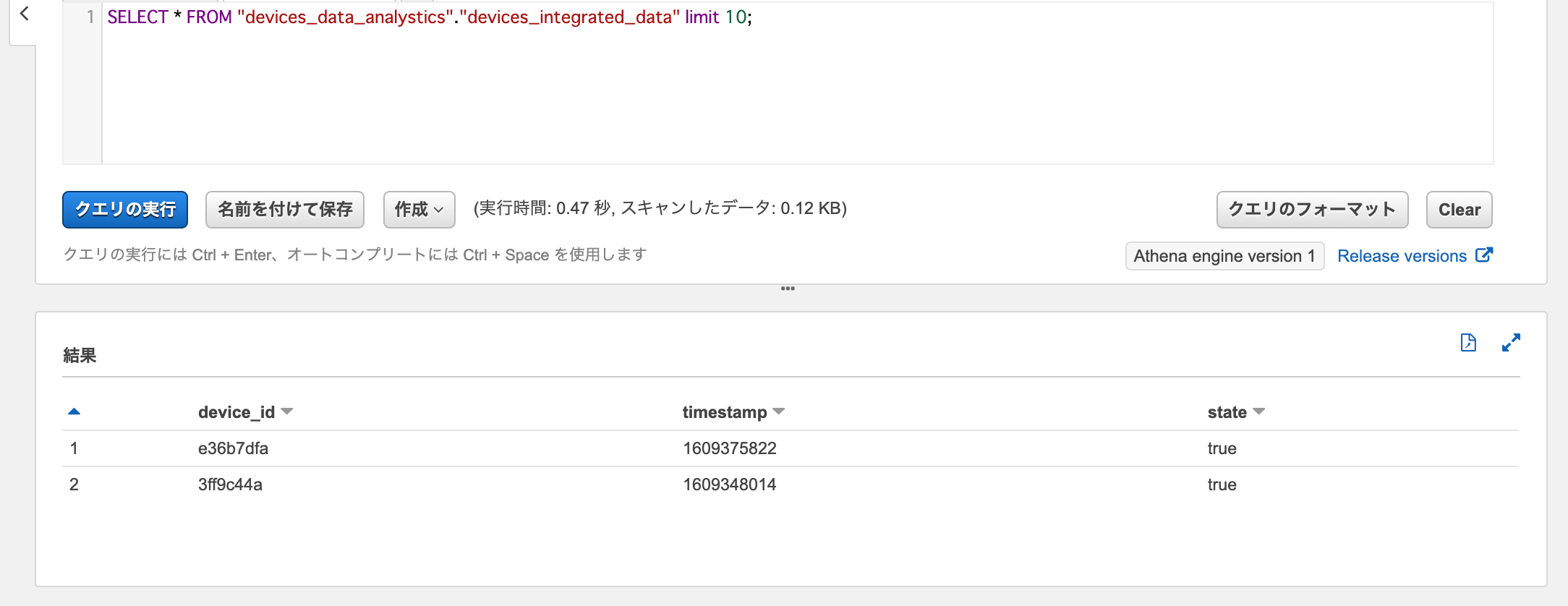
ジョブブックマークを取得してみます。JobBookmarkEntry.JobBookmarkにデータソース(datasource)に対するジョブブックマークが記録されているのが確認できます。
% aws glue get-job-bookmark --job-name ${ETL_GLUE_JOB_NAME}
{
"JobBookmarkEntry": {
"JobName": "devices-data-etl",
"Version": 4,
"Run": 3,
"Attempt": 0,
"PreviousRunId": "jr_1a6a256c601967ecf3780e61d5126542296cace4e8e191ca38ceb9d0f8d97437",
"RunId": "jr_6ffb11286196edbb2f72a99b5a11ef3dce0b536a48787d3410f1abc3b37598bb",
"JobBookmark": "{\"datasource\":{\"jsonClass\":\"HadoopDataSourceJobBookmarkState\",\"timestamps\":{\"RUN\":\"2\",\"HIGH_BAND\":\"900000\",\"CURR_LATEST_PARTITION\":\"0\",\"CURR_LATEST_PARTITIONS\":\"\",\"CURR_RUN_START_TIME\":\"2021-01-07T08:53:15.319Z\",\"INCLUDE_LIST\":\"92910e7237af0bba96ca1654c095edd9,d5e87ccadbec54b4338a5b93f9ff426e,4ea843998d3c98234a5a69c8d128e254,f6309d74b950c0c1bae67f2dfc2f065d\"}}}"
}
}
CLIによるジョブブックマークのリセットはreset-job-bookmarkコマンドで行えます。
下記のようにコマンドを実行することにより、job-nameで指定したジョブのすべてのジョブブックマークを削除できます。JobBookmarkEntry.JobBookmarkが空となり、すべてのジョブブックマークが削除されました。
% aws glue reset-job-bookmark --job-name ${ETL_GLUE_JOB_NAME}
{
"JobBookmarkEntry": {
"JobName": "devices-data-etl",
"Version": 5,
"Run": 4,
"Attempt": 0,
"JobBookmark": ""
}
}
再度ジョブを実行します。
% aws glue start-job-run --job-name ${ETL_GLUE_JOB_NAME}
Athenaでデータターゲットに対してSelectクエリを実行すると、リセットによりジョブブックマークが削除されたデータが重複してロードされていることが確認できます。
SELECT * FROM "devices_data_analystics"."devices_integrated_data"
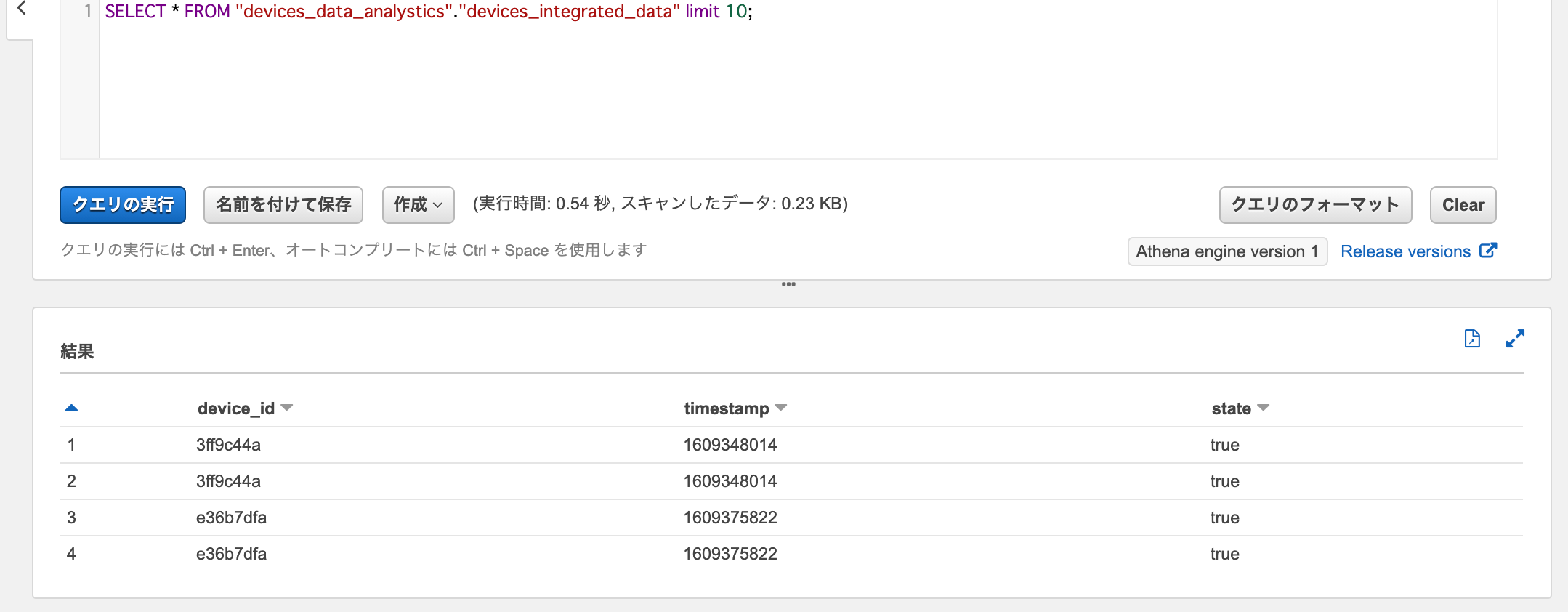
これで、ジョブブックマークのリセットにより、データソースとデータターゲットの両方に対するジョブブックマークがすべて削除されることが確認できました。
ジョブブックマークの「巻き戻し」というのもある
ジョブブックマークの「リセット」はそのジョブのすべてのジョブブックマークをリセット対象とするのに対して、「巻き戻し」は個別のジョブ実行をリセット対象とします。
データソースおよびデータターゲットのデータ、およびジョブブックマークをすべて削除して、一度環境をきれいにします。
% aws s3 rm ${RAW_DATA_BUCKET}/raw-data --recursive
% aws s3 rm ${DATA_ANALYTICS_BUCKET}/integrated-data --recursive
% aws glue reset-job-bookmark --job-name ${ETL_GLUE_JOB_NAME}
再度データソースへのデータ作成およびジョブ実行を2回ずつ行いますが、今度は確認のためジョブ実行ごとにジョブブックマークを取得してみます。
1回目のジョブ実行IDはjr_b7db8f88f1ed27cacf04f5ba69073f355004fc36e5c56a8bf3cb6944e02526d0です。
% aws s3 cp raw-data-1.json \
${RAW_DATA_BUCKET}/raw-data/raw-data-1.json
% aws glue start-job-run --job-name ${ETL_GLUE_JOB_NAME}
% aws glue get-job-bookmark --job-name ${ETL_GLUE_JOB_NAME}
{
"JobBookmarkEntry": {
"JobName": "devices-data-etl",
"Version": 10,
"Run": 7,
"Attempt": 0,
"RunId": "jr_b7db8f88f1ed27cacf04f5ba69073f355004fc36e5c56a8bf3cb6944e02526d0",
"JobBookmark": "{\"datasource\":{\"jsonClass\":\"HadoopDataSourceJobBookmarkState\",\"timestamps\":{\"RUN\":\"6\",\"HIGH_BAND\":\"900000\",\"CURR_LATEST_PARTITION\":\"0\",\"CURR_LATEST_PARTITIONS\":\"\",\"CURR_RUN_START_TIME\":\"2021-01-07T09:11:40.236Z\",\"INCLUDE_LIST\":\"52a7e1419be1a3397a6fbf36fc06109c,d5e87ccadbec54b4338a5b93f9ff426e\"}}}"
}
}
2回目のジョブ実行IDはjr_b47a7309a45b2cb4f6bcd889d1b3b1e96e0e2b3327438b48ef4a2edf04aa9830です。また、JobBookmarkEntry.JobBookmarkの値が増え、ジョブブックマークが追加されていることが分かります。
% aws s3 cp raw-data-2.json \
${RAW_DATA_BUCKET}/raw-data/raw-data-2.json
% aws glue start-job-run --job-name ${ETL_GLUE_JOB_NAME}
% aws glue get-job-bookmark --job-name ${ETL_GLUE_JOB_NAME}
{
"JobBookmarkEntry": {
"JobName": "devices-data-etl",
"Version": 12,
"Run": 8,
"Attempt": 0,
"PreviousRunId": "jr_b7db8f88f1ed27cacf04f5ba69073f355004fc36e5c56a8bf3cb6944e02526d0",
"RunId": "jr_b47a7309a45b2cb4f6bcd889d1b3b1e96e0e2b3327438b48ef4a2edf04aa9830",
"JobBookmark": "{\"datasource\":{\"jsonClass\":\"HadoopDataSourceJobBookmarkState\",\"timestamps\":{\"RUN\":\"7\",\"HIGH_BAND\":\"900000\",\"CURR_LATEST_PARTITION\":\"0\",\"CURR_LATEST_PARTITIONS\":\"\",\"CURR_RUN_START_TIME\":\"2021-01-07T09:15:15.178Z\",\"INCLUDE_LIST\":\"52a7e1419be1a3397a6fbf36fc06109c,d5e87ccadbec54b4338a5b93f9ff426e,24d21120e27253f94f5d1938067b9ecf,f6309d74b950c0c1bae67f2dfc2f065d\"}}}"
}
}
Athenaでデータターゲットに対してSelectクエリを実行すると、ジョブで処理されたデータがロードされていることが確認できます。
SELECT * FROM "devices_data_analystics"."devices_integrated_data"
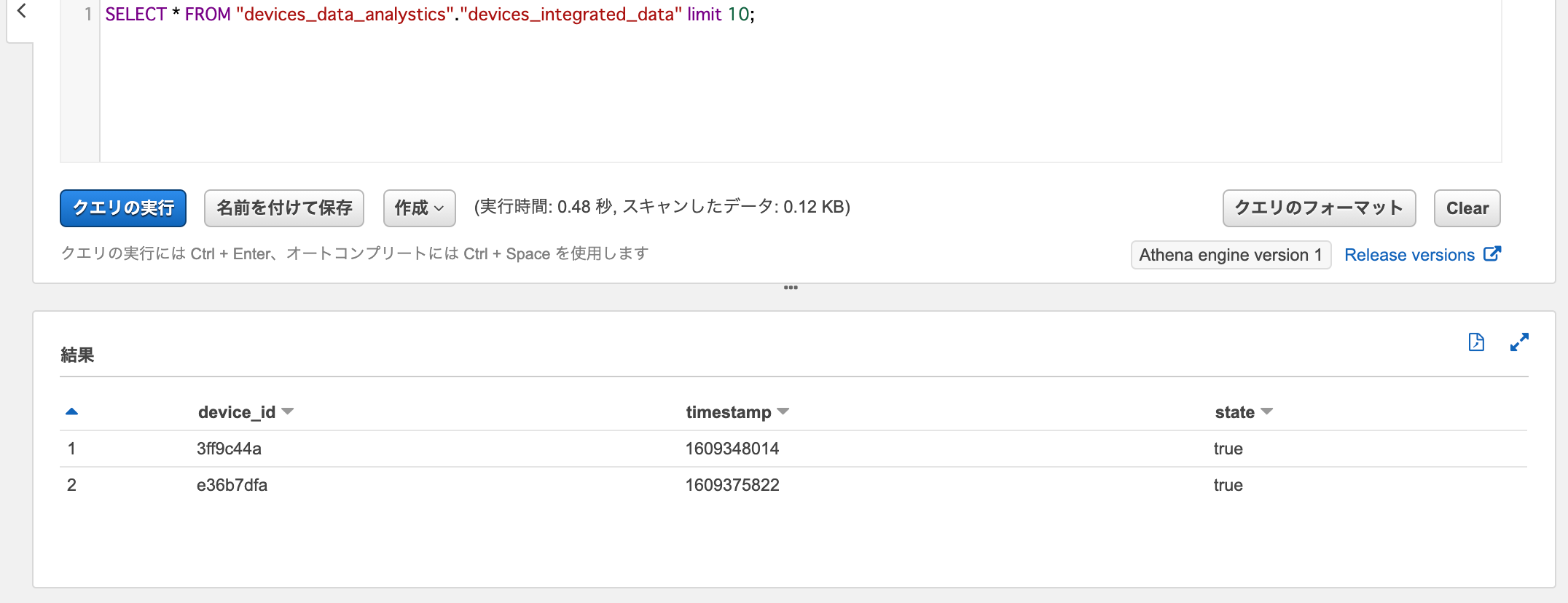
ジョブブックマークの巻き戻しは、リセットと同じglue reset-job-bookmarkコマンドでrun-idオプションにジョブ実行IDを指定することにより行えます。1回目のジョブ実行IDを指定して、ジョブブックマークを巻き戻ししてみます。するとJobBookmarkEntry.JobBookmarkからジョブブックマークが一部削除されていることが確認できます。
% aws glue reset-job-bookmark --job-name ${ETL_GLUE_JOB_NAME} \
--run-id jr_b7db8f88f1ed27cacf04f5ba69073f355004fc36e5c56a8bf3cb6944e02526d0
{
"JobBookmarkEntry": {
"JobName": "devices-data-etl",
"Version": 13,
"Run": 7,
"Attempt": 0,
"RunId": "jr_b7db8f88f1ed27cacf04f5ba69073f355004fc36e5c56a8bf3cb6944e02526d0",
"JobBookmark": "{\"datasource\":{\"jsonClass\":\"HadoopDataSourceJobBookmarkState\",\"timestamps\":{\"RUN\":\"6\",\"HIGH_BAND\":\"900000\",\"CURR_LATEST_PARTITION\":\"0\",\"CURR_LATEST_PARTITIONS\":\"\",\"CURR_RUN_START_TIME\":\"2021-01-07T09:11:40.236Z\",\"INCLUDE_LIST\":\"52a7e1419be1a3397a6fbf36fc06109c,d5e87ccadbec54b4338a5b93f9ff426e\"}}}"
}
}
再度ジョブを実行します。
% aws glue start-job-run --job-name ${ETL_GLUE_JOB_NAME}
スクリプト内でのdf.show()の出力を見ると、巻き戻したジョブ実行で処理したデータが再度データソースから取得されていることが分かります。
>>> df.show()
+---------+----------+-----+
|device_id| timestamp|state|
+---------+----------+-----+
| e36b7dfa|1609375822| true|
+---------+----------+-----+
しかし、データターゲットへはデータのロードは行われておらず、データの重複は発生していません。
SELECT * FROM "devices_data_analystics"."devices_integrated_data"
ジョブブックマークの巻き戻しは、データソース側のジョブブックマークは削除されるが、データターゲット側は削除されていないと思われる動作となりました。
AWSマネジメントコンソールからの操作の場合
- ジョブブックマークのリセット
対象のジョブを選択して、[アクション] - [ジョブブックマークのリセット]をクリックすることにより行えます。
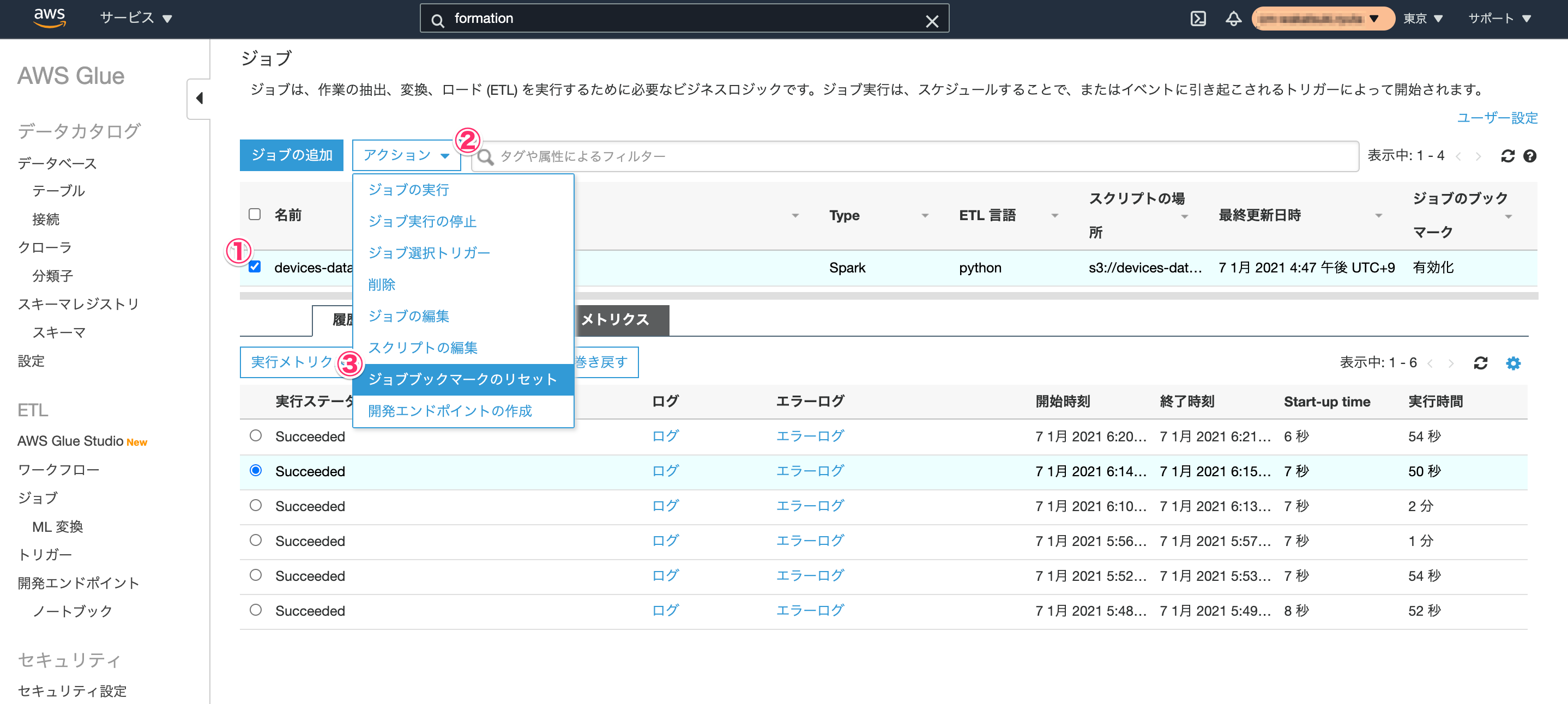
- ジョブブックマークの巻き戻し
対象のジョブのジョブ実行を選択して、[ジョブブックマークの巻き戻し]をクリックすることにより行えます。
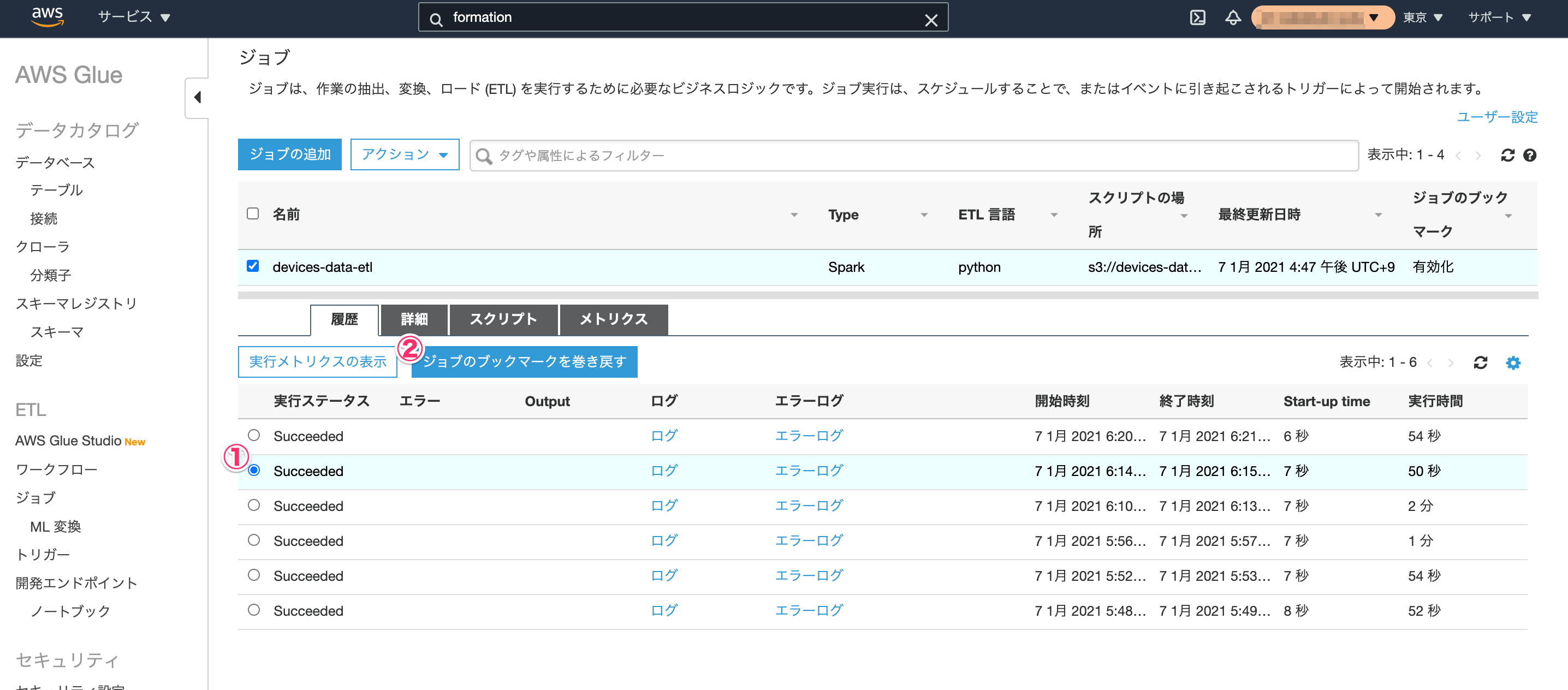
まとめ
「ジョブブックマークのリセット」には、「リセット」と「巻き戻し」の2種類がある
- リセット
データソースとデータターゲットの両方に対するジョブブックマークがすべて削除される動作となる。
よって、ジョブに不具合がありデータターゲットに不備のあるデータが作成されてしまった場合に、データターゲットのデータの全削除とジョブブックマークのリセットを行い、不具合を修正したジョブを実行することにより、データソースに対するフルスキャンを行って正常なデータターゲットのデータを一括作成する、なんていう不具合対応への使い方が期待できる。
- 巻き戻し
データソース側のジョブブックマークは削除されるが、データターゲット側は削除されない動作となると思われる。公開情報も少なく正直言って仕様や使い所がよく分からなかった。
おわりに
AWS Glueでジョブブックマークのリセットの動作を確認してみました。
ジョブブックマークの仕様はなかなか奥が深そうですが、リセット機能はとても便利なので覚えておきたいですね。
参考
以上








