
การรัน SQL ไปยังไฟล์ใน S3 ด้วย Glue กับ Athena บน Amazon Linux 2023
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
ครั้งนี้ผมจะมาแนะนำเกี่ยวกับการรัน SQL ไปยังไฟล์ใน S3 ด้วย Glue กับ Athena บน Amazon Linux 2023
ภาพรวมของขั้นตอนการทำทั้งหมด
- ตั้งค่าการสร้างและอัปโหลดไฟล์ JSON ไปยัง S3 ทุกๆ 1 นาทีโดยอัตโนมัติ: นี่คือการเตรียม EC2 สำหรับการอัปโหลดไฟล์ไปยัง S3 และเรียกใช้ python 1 ครั้งโดยใช้ cron ทุกๆ 1 นาทีเช่นกัน ซึ่ง python จะทำการสร้างไฟล์ JSON แบบสุ่มโดยอัตโนมัติ
- เตรียมพร้อมการเรียกใช้ SQL ไปยังไฟล์ที่มีอยู่ใน S3 (AWS Glue): เรียกใช้ Glue สำหรับไฟล์ที่มีอยู่ใน S3 และสร้าง Database กับ Table เพื่อให้สามารถ Call ด้วย SQL ได้
- รัน SQL สำหรับ Table (Amazon Athena): เตรียมพร้อมที่จะเริ่มใช้ Athena หลังจากนั้นให้รัน SQL ด้วย Query Editor ของ Athena
- ทำวิธีการลบ AWS Resource ที่สร้างขึ้นในบทความนี้
Service ที่ใช้ในบทความนี้
- Amazon S3
- Buckets (2)
- AWS Identity and Access Management (IAM)
- Roles (2)
- Amazon EC2
- Key Pairs
- Instance
- Security Groups
- AWS Glue
- Databases
- Tables
- Crawlers
- Databases
- Amazon Athena
- Workgroups
สิ่งที่ต้องมี
ขั้นตอนอาจจะซับซ้อนนิดนึง แนะนำให้เพื่อนๆ ลองอ่านรายละเอียดให้ดีก่อนลงมือทำในแต่ละขั้นตอน เพื่อป้องกันความผิดพลาดนะครับ
ขั้นแรกให้สร้าง S3 ขึ้นมา จากนั้นสร้าง EC2 ที่เชื่อมต่อกับ Role และสามารถเข้าถึง S3 ได้เตรียมไว้ โดยผมจะระบุรายละเอียดขั้นตอนการสร้างและแปะลิงก์ที่ด้านล่างนี้ครับ
S3 Buckets ที่สร้างเสร็จแล้ว
- การสร้าง Buckets ใน Amazon S3 (S3 สำหรับบันทึกไฟล์ JSON จากโปรแกรม Python)
EC2 ที่เชื่อมต่อกับ Role และสามารถเข้าถึง S3 ได้
- การสร้าง Role ใน IAM (Permissions policies [
AmazonS3FullAccess,AmazonSSMManagedInstanceCore])- การ Launch Instance
- การเชื่อมต่อ Instance โดยใช้ SSM (สามารถใช้ตัวเลือกอื่นได้ เช่น PuTTY)
ครั้งนี้จะไม่ใช้ Key pair เนื่องจากเป็นการสาธิต หากต้องการใช้ Key pair ให้ดูที่ลิงก์ การ Create Key Pair
เมื่อติดตั้ง S3 และ EC2 เสร็จเรียบร้อยแล้ว ให้ทดสอบการเข้าถึง S3 จาก EC2 โดยดูข้อมูลใน S3 ผ่านคำสั่ง AWS CLI และเปลี่ยน Time Zone EC2 ดังนี้
ทดสอบเข้าถึง S3 ผ่าน EC2
ก่อนอื่นเชื่อมต่อ Instance ผ่าน SSM และรันคำสั่งใช้สิทธิ์ root
sudo su -
แล้วรันคำสั่งของ AWS CLI S3 เพื่อดูข้อมูลใน S3 โดยใช้คำสั่ง aws s3 ls s3:// + bucket_name ของคุณ
aws s3 ls s3://tinnakorn-test-s3
ถ้าไม่ขึ้น Error และแสดงหน้าจอเหมือนด้านล่างนี้ก็ทำขั้นตอนถัดไปได้เลยครับ
Output
[root@ip-xx-xx-xx-xx ~]# aws s3 ls s3://tinnakorn-test-s3
[root@ip-xx-xx-xx-xx ~]#
ดูข้อมูลเพิ่มเติมได้ที่: การ Upload ไฟล์ไปยัง S3 ผ่าน Console
เปลี่ยน Time Zone EC2
รันคำสั่งนี้เพื่อเปลี่ยนเวลาจาก UTC ให้เป็น +07
ln -sf /usr/share/zoneinfo/Asia/Bangkok /etc/localtime
date
จะเห็นว่าเวลาปัจจุบันเป็น +07 เรียบร้อยแล้ว (หากตรวจสอบเวลาปัจจุบันด้วย date ในตอนแรกจะแสดงเป็นเขตเวลา UTC)
Output
[root@ip-xx-xx-xx-xx ~]# ln -sf /usr/share/zoneinfo/Asia/Bangkok /etc/localtime
[root@ip-xx-xx-xx-xx ~]# date
Fri Sep 6 16:05:18 +07 2024
[root@ip-xx-xx-xx-xx ~]#
ดูข้อมูลเพิ่มเติมได้ที่: วิธีตั้งค่า Time Zone ใน Amazon Linux 2 ของ EC2
เพียงเท่านี้การเตรียม S3 และ EC2 ก็เสร็จเรียบร้อย
1. ตั้งค่าการสร้างและอัปโหลดไฟล์ JSON ไปยัง S3 ทุกๆ 1 นาทีโดยอัตโนมัติ
สร้างไฟล์ Python
ขั้นตอนนี้เป็นการสร้าง Python โดยให้ไฟล์ที่จะสร้างนี้อัปโหลดไปยัง S3 ตามเวลาที่เรากำหนดโดยอัตโนมัติ ! เมื่อพร้อมแล้วมาเริ่มกันเลยครับ
รันคำสั่งนี้เพื่อตรวจสอบเวอร์ชัน Python ที่อยู่ใน EC2
python3 --version
โดยปกติแล้ว python จะมีอยู่ใน EC2 ให้อยู่แล้วครับ
Output
[root@ip-xx-xx-xx-xx ~]# python3 --version
Python 3.9.16
[root@ip-xx-xx-xx-xx ~]#
สำหรับผู้ใช้งานที่ตรวจสอบเวอร์ชันแล้ว กรณีที่ไม่มี python ตามที่กล่าวไว้ ให้รันคำสั่งด้านล่างนี้เพื่อติดตั้งได้เลยครับ (โดยปกติจะรวม python มาให้อยู่แล้ว)
หมายเหตุ: หากมีอยู่แล้วให้ข้ามขั้นตอนนี้ไปได้เลย
yum install python3 -y
รันคำสั่งนี้เพื่อดาวน์โหลดไฟล์ Python
wget https://raw.githubusercontent.com/classmethod-thailand/cmth_seminar/develop/s3_athena_material/create_sample_json_upload_s3.py
Output
[root@ip-xx-xx-xx-xx ~]# wget https://raw.githubusercontent.com/classmethod-thailand/cmth_seminar/develop/s3_athena_material/create_sample_json_upload_s3.py
--2024-09-06 16:07:07-- https://raw.githubusercontent.com/classmethod-thailand/cmth_seminar/develop/s3_athena_material/create_sample_json_upload_s3.py
Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.109.133, 185.199.110.133, 185.199.111.133, ...
Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.109.133|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 678 [text/plain]
Saving to: ‘create_sample_json_upload_s3.py’
create_sample_json_upload_s3.py 100%[=======================================================================================>] 678 --.-KB/s in 0s
2024-09-06 16:07:08 (15.3 MB/s) - ‘create_sample_json_upload_s3.py’ saved [678/678]
[root@ip-xx-xx-xx-xx ~]#
รันคำสั่งนี้เพื่อเข้ามาที่ไฟล์ create_sample_json_upload_s3.py และเปลี่ยนชื่อ s3_bucket_name ในขั้นตอนถัดไป
vi create_sample_json_upload_s3.py
แล้วเปลี่ยนชื่อ s3_bucket_name ให้เป็นชื่อ Bucket ของเรา
ดูตัวอย่าง Code ที่นี่: create_sample_json_upload_s3.py
วิธีเปลี่ยนชื่อ s3_bucket_name
- กดปุ่ม
iที่แป้นพิมพ์ ให้"create_sample_json_upload_s3.py" 27L, 678Bที่อยู่ด้านล่างซ้ายเปลี่ยนเป็น--INSERT--- หาคำว่า
s3_bucket_nameแล้วคัดลอก Bucket ของเราที่สร้างไว้ก่อนหน้านี้มาใส่แทนชื่อเก่า เช่น ในบทความนี้คือชื่อtinnakorn-test-s3เป็นต้นเมื่อเปลี่ยนชื่อ s3_bucket_name เสร็จแล้วทำการ Save ตามนี้
- กดปุ่ม
Escให้--INSERT--หายไป- จากนั้นพิมพ์
:xหรือ:wq+ Enter
รันคำสั่งนี้เพื่ออัปโหลดไฟล์ JSON ไปยัง S3
python3 create_sample_json_upload_s3.py
เมื่อรันคำสั่งนี้ไปแล้ว ตัวไฟล์ JSON จะถูกอัปโหลดขึ้นไปที่ S3 ครับ
Output
[root@ip-xx-xx-xx-xx ~]# python3 create_sample_json_upload_s3.py
upload: ./20240906_161020.json to s3://tinnakorn-test-s3/20240906/20240906_161020.json
[root@ip-xx-xx-xx-xx ~]#
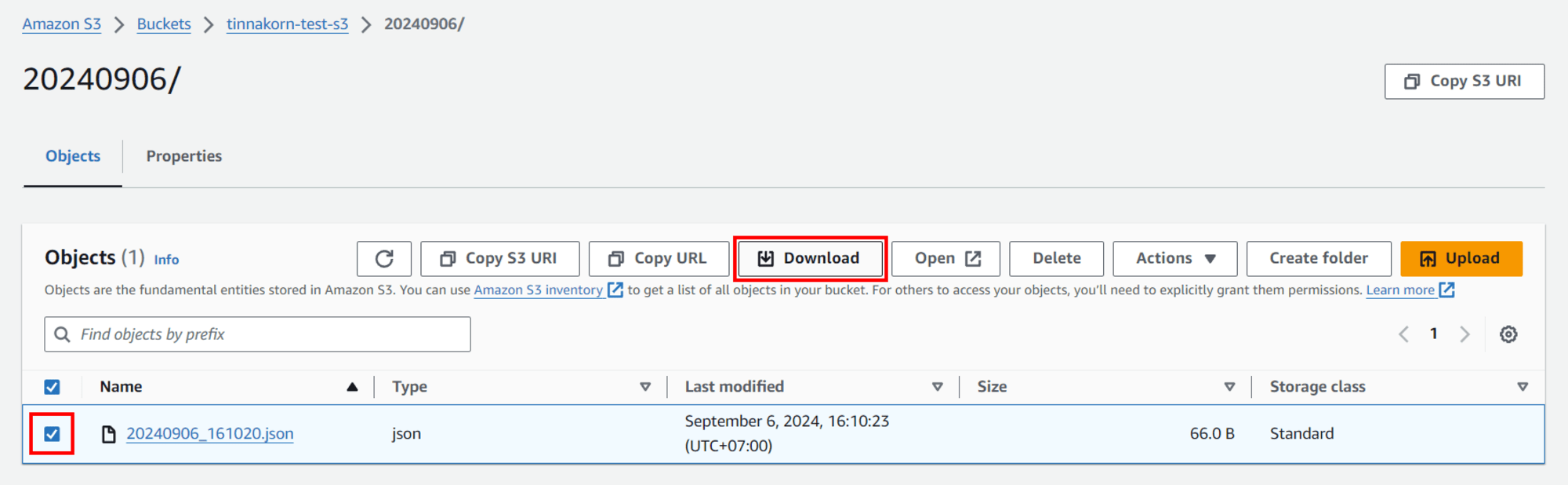
เข้ามาที่ S3 Bucket ของเรา แล้วทำการ Reload จะเห็นว่ามีไฟล์เพิ่มขึ้นมา คลิกเข้ามาที่โฟลเดอร์ตามวันที่ปัจจุบัน
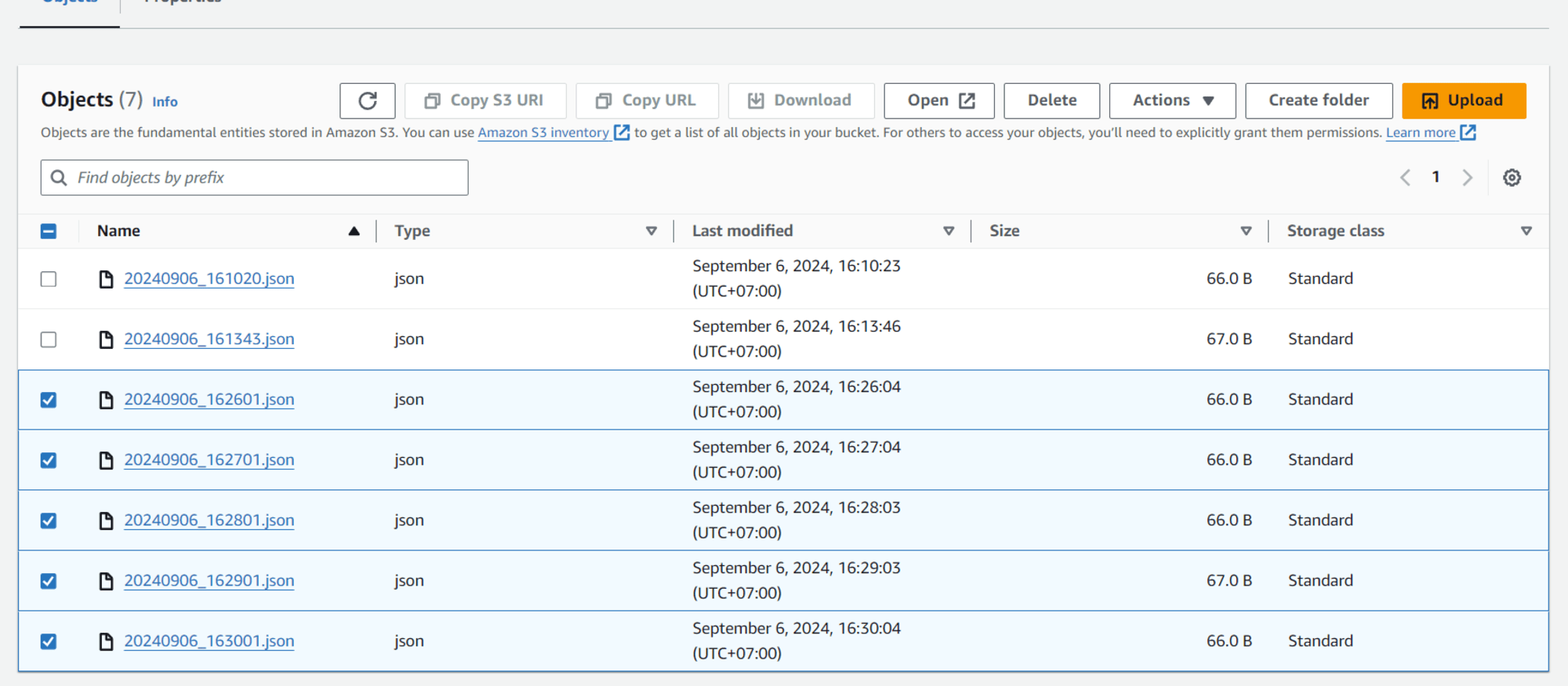
ทีนี้ให้ทำการดาวน์โหลดไฟล์ JSON โดยติ๊ก ✅ ไฟล์ที่ต้องการดาวน์โหลด แล้วกดปุ่ม Download ได้เลยครับ
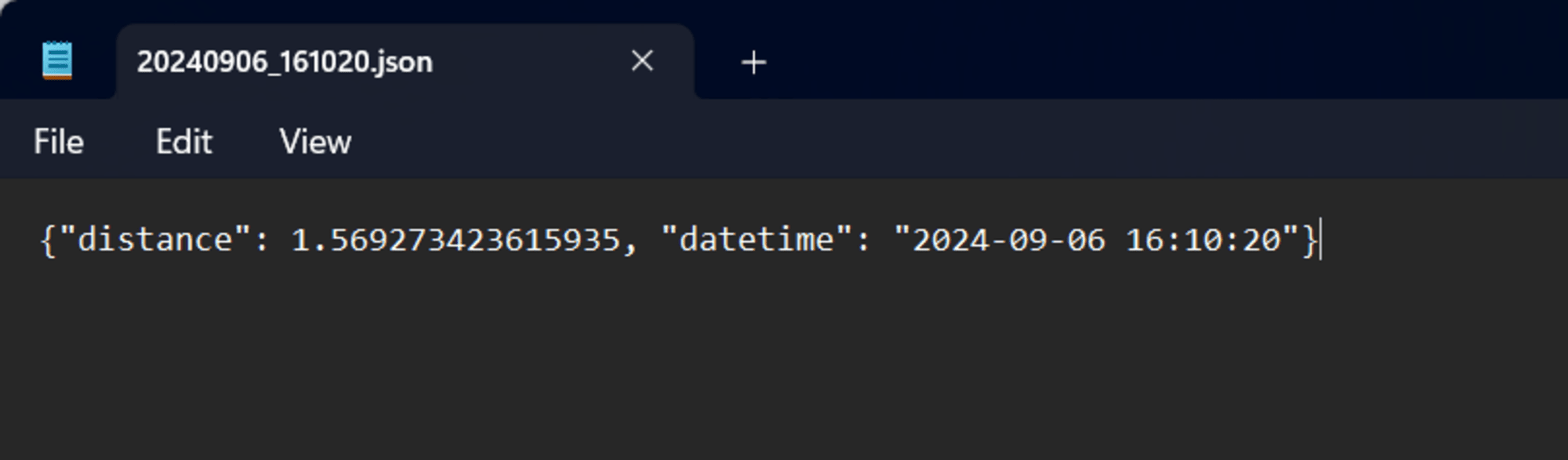
เปิดดูไฟล์ด้วยโปรแกรม Notepad ของ Windows ได้เลย ซึ่งข้อมูลจะแสดงตามรูปภาพด้านล่างครับ
รันคำสั่งนี้เพื่ออัปโหลดไฟล์ JSON ไปยัง S3 อีกครั้ง
python3 create_sample_json_upload_s3.py
เมื่อรันคำสั่งนี้ไปแล้ว ตัวไฟล์ Python จะสร้างและอัปโหลดไฟล์ JSON ขึ้นไปที่ S3
Output
[root@ip-xx-xx-xx-xx ~]# python3 create_sample_json_upload_s3.py
upload: ./20240906_161343.json to s3://tinnakorn-test-s3/20240906/20240906_161343.json
[root@ip-xx-xx-xx-xx ~]#
เข้ามาที่ S3 Bucket ของเราอีกครั้ง แล้วท Reload จะเห็นว่ามีไฟล์ JSON อันที่ 2 เพิ่มขึ้นมา แล้วดาวน์โหลดไฟล์ JSON อีกครั้ง
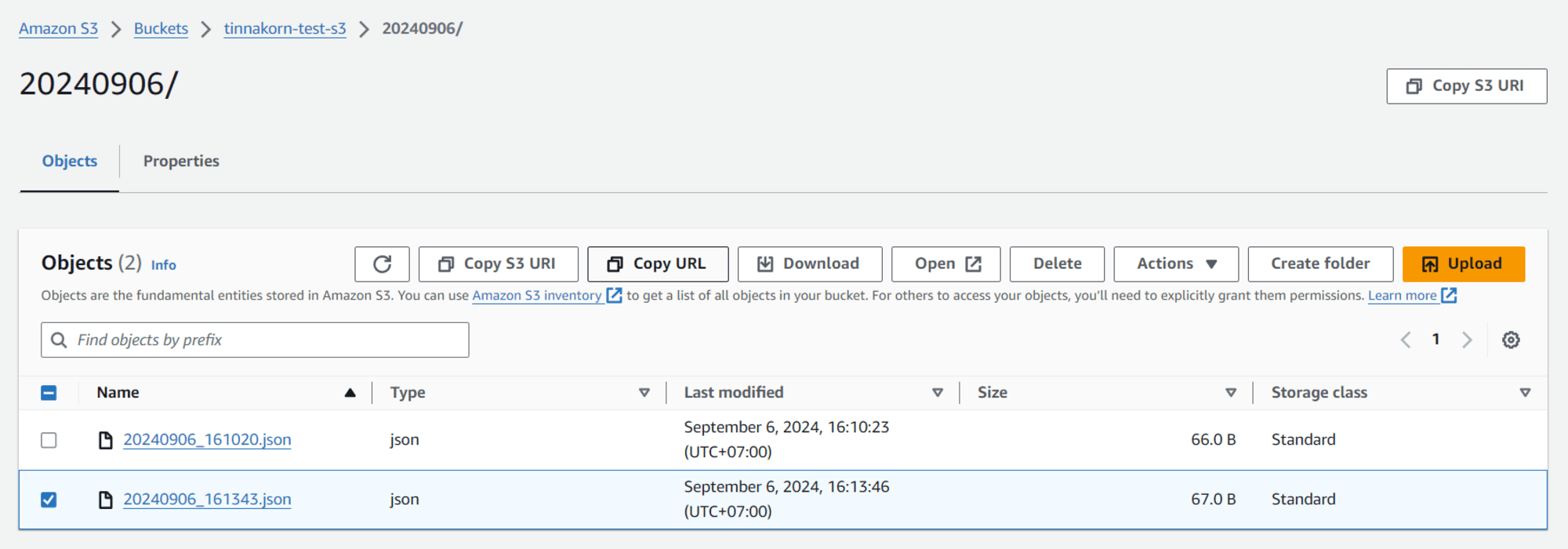
เปิดดูไฟล์ด้วยโปรแกรม Notepad ของ Windows อีกครั้ง (สามารถใช้โปรแกรมอื่นได้)
ทีนี้ลองเปิดเทียบกันดู จะเห็นว่าเวลาจะต่างกันตามระยะเวลาที่เราทำการอัปโหลดไป และ distance ก็จะได้ตัวเลขที่สุ่มออกมาแบบนี้ครับ

การใช้งาน cron สำหรับ Amazon Linux 2023
ติดตั้ง cron สำหรับ Amazon Linux 2023
ก่อนอื่นให้ติดตั้ง cronie ก่อน เนื่องจากใน Amazon Linux 2023 ต้องติดตั้งเอง
*หากไม่ติดตั้ง cronie สำหรับ Amazon Linux 2023 ก็จะไม่สามารถใช้งาน cron ให้ทำงานในรูปแบบอัตโนมัติได้
รันคำสั่งติดตั้ง cronie
yum install -y cronie
systemctl enable --now crond
ดูข้อมูลเพิ่มเติมได้ที่ลิงก์ด้านล่างนี้
・systemd timers replace cron - Amazon Linux 2023
・Automate letsEncrypt SSL cert for Lightsail AL2023 | AWS re:Post
แล้วจะรันคำสั่งตรวจสอบการทำงานของไฟล์ crontab ในขั้นตอนถัดไป ดังนั้นตอนนี้จะยังไม่รันคำสั่งนี้
journalctl -efu crond
ตั้งค่า crontab ใน Amazon Linux 2023
ขั้นตอนต่อไปจะเป็นการแก้ไขไฟล์ crontab เพื่อที่จะทำให้สามารถอัปโหลดไฟล์ JSON ไปยัง S3 ได้โดยอัตโนมัติ
รันคำสั่งนี้เพื่อเข้ามาที่ไฟล์ crontab และทำการเพิ่ม Code ในขั้นตอนถัดไป
vi /etc/crontab
ทีนี้เรามาแก้ไขไฟล์ crontab โดยการเพิ่ม Code ตามนี้
» กดปุ่ม i ให้คำว่า "/etc/crontab" 15L, 451B ที่อยู่ด้านล่างซ้ายเปลี่ยนเป็น -- INSERT --
» Copy Code ด้านล่างนี้ และนำไปวางที่บรรทัดถัดไปของ # * * * * * user-name command to be executed
* * * * * root /usr/bin/python3 /root/create_sample_json_upload_s3.py
Output
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
~
~
~
~
~
-- INSERT -- 15,1 All
เมื่อเพิ่ม Code เสร็จแล้วทำการ Save ตามนี้
» กดปุ่ม Esc ให้คำว่า -- INSERT -- ที่อยู่ด้านล่างซ้ายหายไป
» พิมพ์ :x หรือ :wq + Enter
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
* * * * * root /usr/bin/python3 /root/create_sample_json_upload_s3.py
~
~
~
~
~
:x
เมื่อเสร็จสิ้นจากการเพิ่ม Code แล้ว หลังจากนี้ตัวไฟล์ Python จะทำการสร้างและอัปโหลดไฟล์ JSON ขึ้นไปที่ S3 โดยอัตโนมัติทุกๆ 1 นาที
ตรวจสอบการทำงานของไฟล์ crontab
หลังจากตั้งค่า cron เสร็จแล้ว ให้รันคำสั่งตรวจสอบการทำงานของไฟล์ crontab (หากยังไม่ติดตั้ง ติดตั้ง cron สำหรับ Amazon Linux 2023 จะไม่สามารถรันคำสั่งนี้ได้)
journalctl -efu crond
เมื่อได้หน้าจอแบบนี้แล้วรอ 1 นาที
Output
[root@ip-172-31-16-27 ~]# journalctl -efu crond
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal systemd[1]: Started crond.service - Command Scheduler.
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) STARTUP (1.5.7)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (Syslog will be used instead of sendmail.)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (RANDOM_DELAY will be scaled with factor 92% if used.)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (running with inotify support)
Sep 06 16:26:01 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26184]: (root) CMD (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
เมื่อครบ 1 นาทีแล้ว จะเปลี่ยนเป็นแบบนี้โดยให้สังเกตเวลาปัจจุบัน เช่น Sep 06 16:26:01
[root@ip-172-31-16-27 ~]# journalctl -efu crond
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal systemd[1]: Started crond.service - Command Scheduler.
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) STARTUP (1.5.7)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (Syslog will be used instead of sendmail.)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (RANDOM_DELAY will be scaled with factor 92% if used.)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (running with inotify support)
Sep 06 16:26:01 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26184]: (root) CMD (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:26:03 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26183]: (root) CMDOUT (Completed 66 Bytes/66 Bytes (566 Bytes/s) with 1 file(s) remainingupload: ./20240906_162601.json to s3://tinnakorn-test-s3/20240906/20240906_162601.json)
Sep 06 16:26:04 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26183]: (root) CMDEND (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
เข้ามาที่ S3 Bucket จะเห็นว่ามีไฟล์ JSON อันที่ 3 เพิ่มขึ้นมาโดยอัตโนมัติ
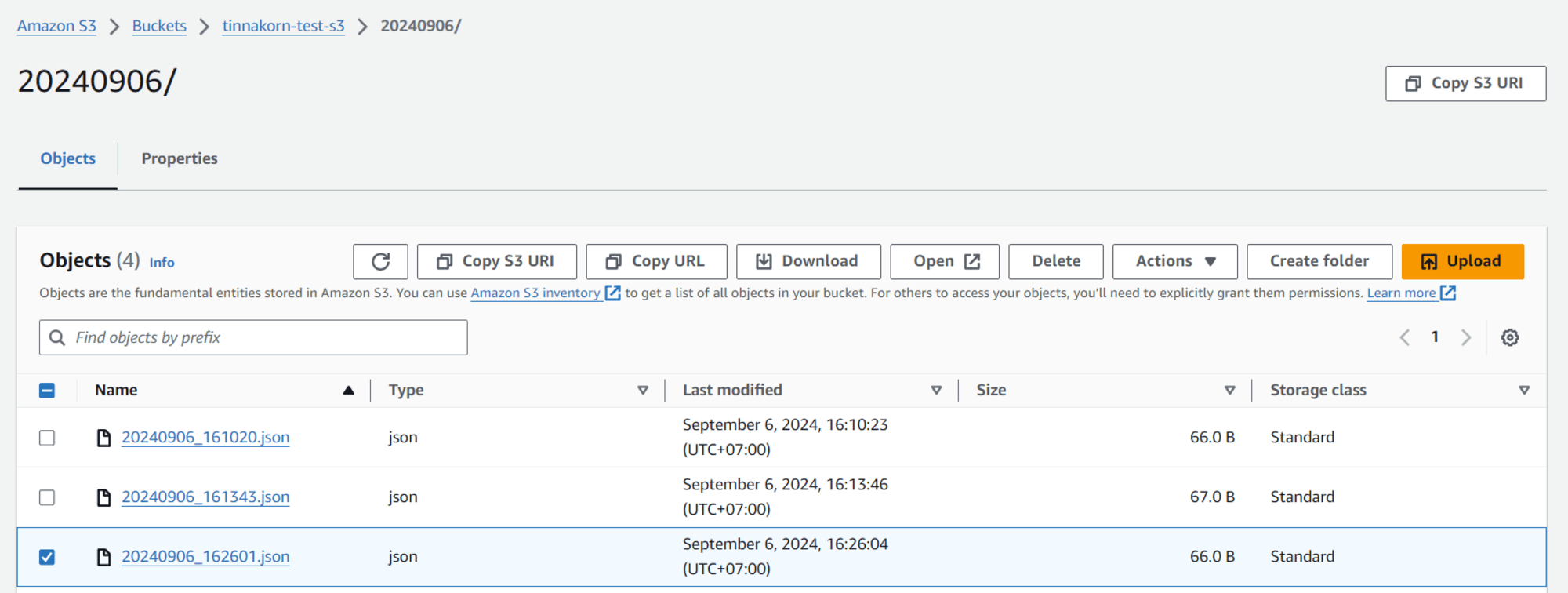
หลังจากนี้ไฟล์ JSON ก็จะถูกสร้างและอัปโหลดไปที่ S3 เรื่อยๆ ทุกๆ 1 นาที สมมุติเวลาผ่านไปแล้ว 5 นาที ไฟล์ก็จะถูกอัปโหลดไป 5 ไฟล์ตามเวลาตัวอย่างด้านล่างนี้ครับ
Sep 06 16:26:01
Sep 06 16:27:01
Sep 06 16:28:01
Sep 06 16:29:01
Sep 06 16:30:01
สามารถตรวจสอบได้โดยรันคำสั่งนี้
journalctl -efu crond
Output
[root@ip-172-31-16-27 ~]# journalctl -efu crond
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal systemd[1]: Started crond.service - Command Scheduler.
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) STARTUP (1.5.7)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (Syslog will be used instead of sendmail.)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (RANDOM_DELAY will be scaled with factor 92% if used.)
Sep 06 16:25:03 ip-172-31-16-27.ap-southeast-1.compute.internal crond[6235]: (CRON) INFO (running with inotify support)
Sep 06 16:26:01 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26184]: (root) CMD (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:26:03 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26183]: (root) CMDOUT (Completed 66 Bytes/66 Bytes (566 Bytes/s) with 1 file(s) remainingupload: ./20240906_162601.json to s3://tinnakorn-test-s3/20240906/20240906_162601.json)
Sep 06 16:26:04 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26183]: (root) CMDEND (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:27:01 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26195]: (root) CMD (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:27:03 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26194]: (root) CMDOUT (Completed 66 Bytes/66 Bytes (365 Bytes/s) with 1 file(s) remainingupload: ./20240906_162701.json to s3://tinnakorn-test-s3/20240906/20240906_162701.json)
Sep 06 16:27:03 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26194]: (root) CMDEND (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:28:01 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26265]: (root) CMD (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:28:02 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26264]: (root) CMDOUT (Completed 66 Bytes/66 Bytes (542 Bytes/s) with 1 file(s) remainingupload: ./20240906_162801.json to s3://tinnakorn-test-s3/20240906/20240906_162801.json)
Sep 06 16:28:03 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26264]: (root) CMDEND (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:29:01 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26277]: (root) CMD (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:29:02 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26276]: (root) CMDOUT (Completed 67 Bytes/67 Bytes (687 Bytes/s) with 1 file(s) remainingupload: ./20240906_162901.json to s3://tinnakorn-test-s3/20240906/20240906_162901.json)
Sep 06 16:29:02 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26276]: (root) CMDEND (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:30:01 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26347]: (root) CMD (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
Sep 06 16:30:03 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26346]: (root) CMDOUT (Completed 66 Bytes/66 Bytes (437 Bytes/s) with 1 file(s) remainingupload: ./20240906_163001.json to s3://tinnakorn-test-s3/20240906/20240906_163001.json)
Sep 06 16:30:04 ip-172-31-16-27.ap-southeast-1.compute.internal CROND[26346]: (root) CMDEND (/usr/bin/python3 /root/create_sample_json_upload_s3.py)
เข้ามาที่ S3 Bucket อีกครั้ง จะเห็นว่ามีไฟล์ JSON เพิ่มขึ้นมาใหม่ 5 ไฟล์โดยอัตโนมัติ
ในส่วนของขั้นตอน 1 นี้ก็เสร็จเรียบร้อยแล้ว ผมจะทบทวนสิ่งที่ได้ทำมาจนถึงตอนนี้อีกครั้ง
- สิ่งที่ได้ทำไปแล้วในหัวข้อ 1. ตั้งค่าการสร้างและอัปโหลดไฟล์ JSON ไปยัง S3 ทุกๆ 1 นาทีโดยอัตโนมัติ
- ดาวน์โหลดไฟล์ Python
- เปลี่ยนชื่อ s3_bucket_name ในไฟล์ Python:create_sample_json_upload_s3.py
- รันคำสั่ง Python3 โดยใช้ไฟล์ Python เพื่อสร้างและอัปโหลดไฟล์ JSON ไปยัง S3
- แก้ไขไฟล์ crontab โดยการเพิ่ม Code ที่สามารถทำให้สร้างและอัปโหลดไฟล์ JSON ไปยัง S3 ทุกๆ 1 นาทีได้โดยอัตโนมัติ
เมื่อเข้าใจวิธีการจัดการไฟล์ Python เพื่อสร้างและอัปโหลดไฟล์ JSON ไปยัง S3 โดยอัตโนมัติแล้ว ให้เริ่มทำหัวข้อถัดไปได้เลยครับ
2. เตรียมพร้อมการเรียกใช้ SQL ไปยังไฟล์ที่มีอยู่ใน S3 ใน AWS Glue
ขั้นตอนนี้จะมาสร้าง Database กับ Table เพื่อรันคำสั่ง SQL จาก Athena โดยใช้ฟังก์ชัน Crawler ของ AWS Glue ครับ
ค้นหาและเลือก AWS Glue
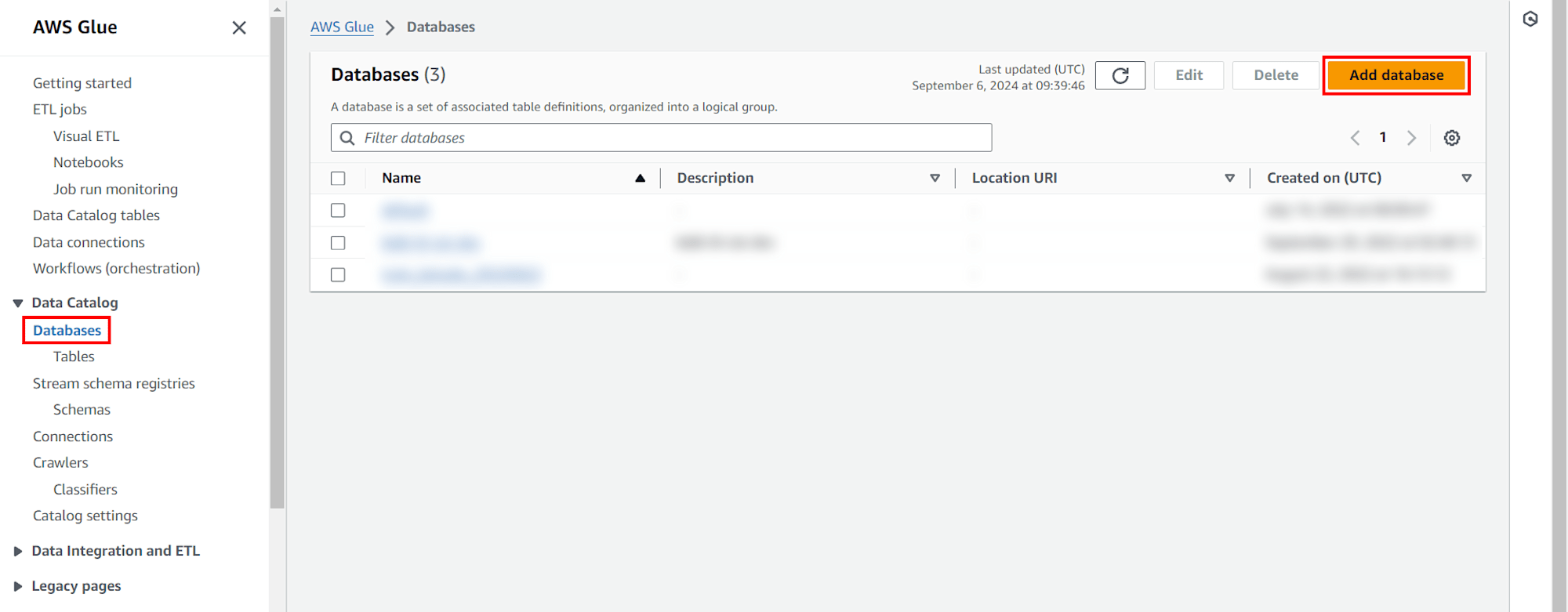
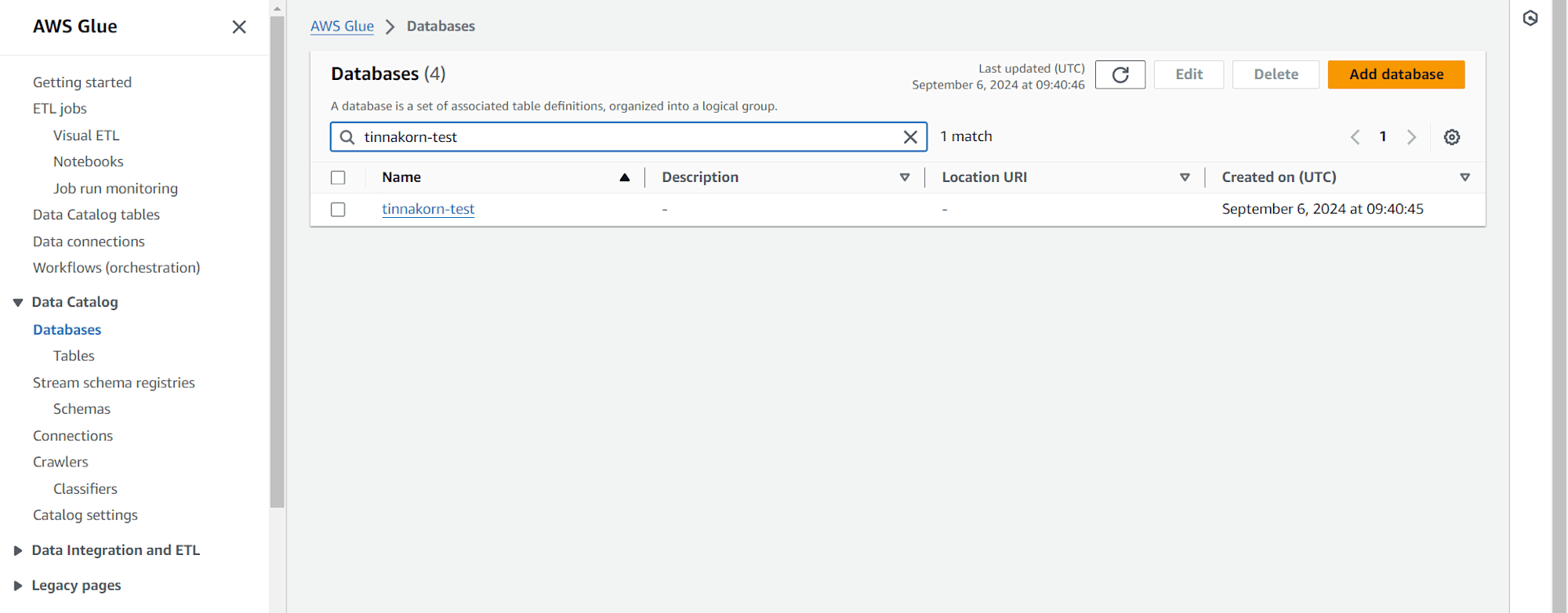
สร้าง Databases
เลือก Databases จากเมนูด้านซ้าย และคลิก Add database
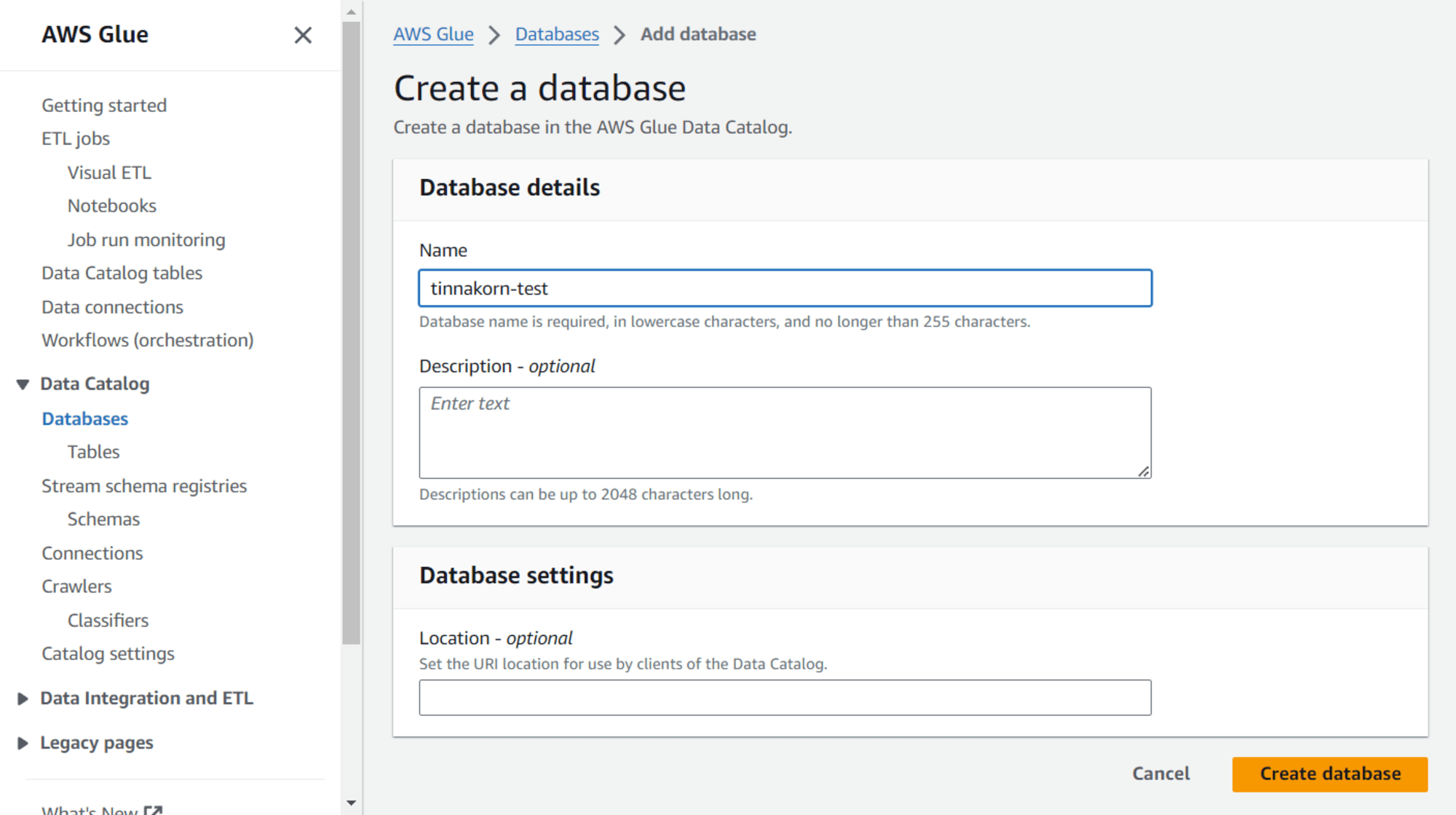
Database name: tinnakorn-test คลิก Create database
เมื่อสร้างเสร็จจะได้ Database ตามชื่อของเรา
สร้าง Crawlers
เลือก Crawlers จากเมนูด้านซ้าย และคลิก Create crawler
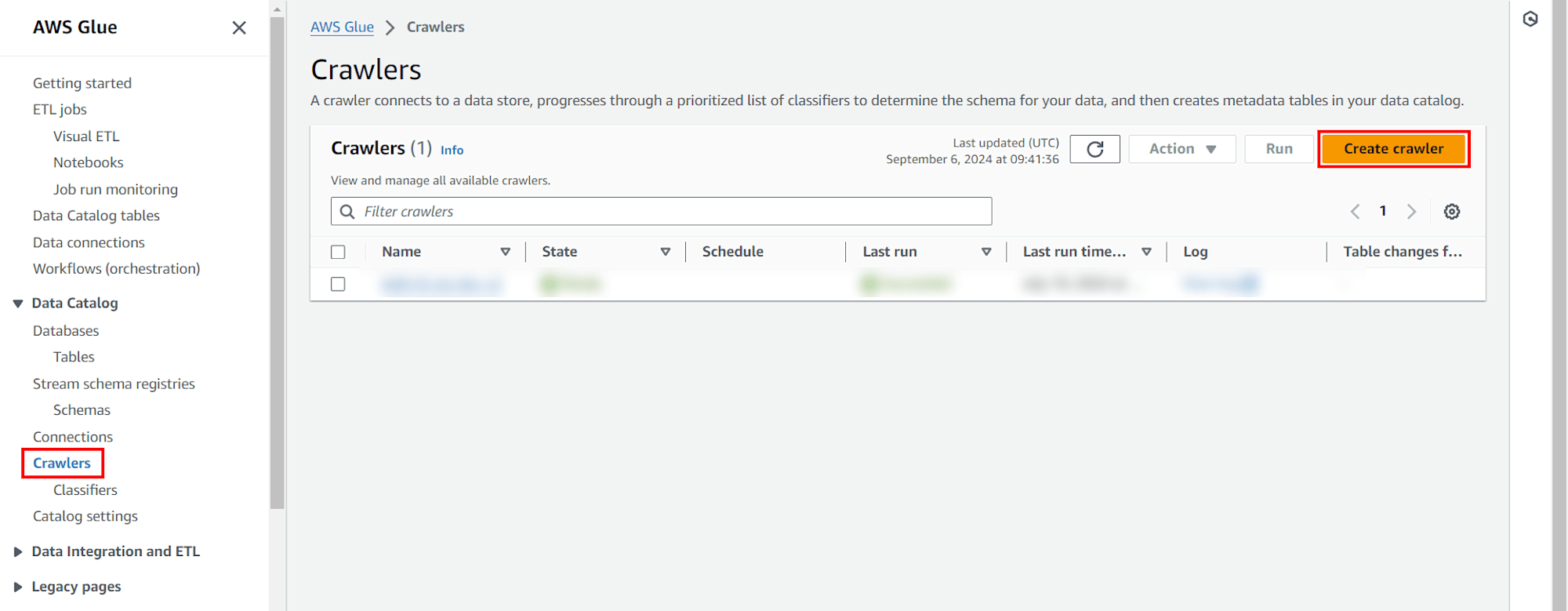
Step 1: Set crawler properties
Crawler details
Name: tinnakorn-test (ชื่ออะไรก็ได้) คลิก Next
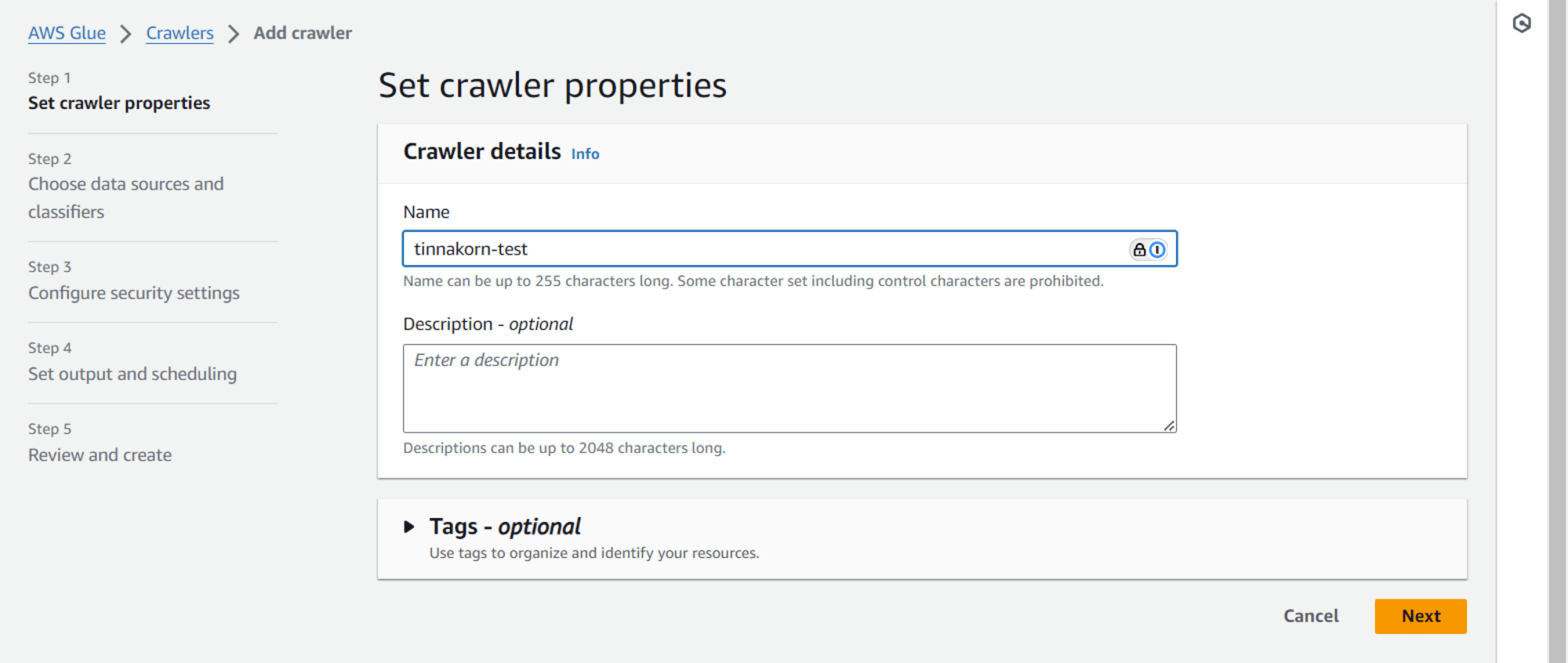
Step 2: Choose data sources and classifiers
Data source configuration
◉ Not yet (Default)
Data sources
คลิก Add a data source (จะมี 2 ปุ่ม คลิกปุ่มไหนก็ได้)
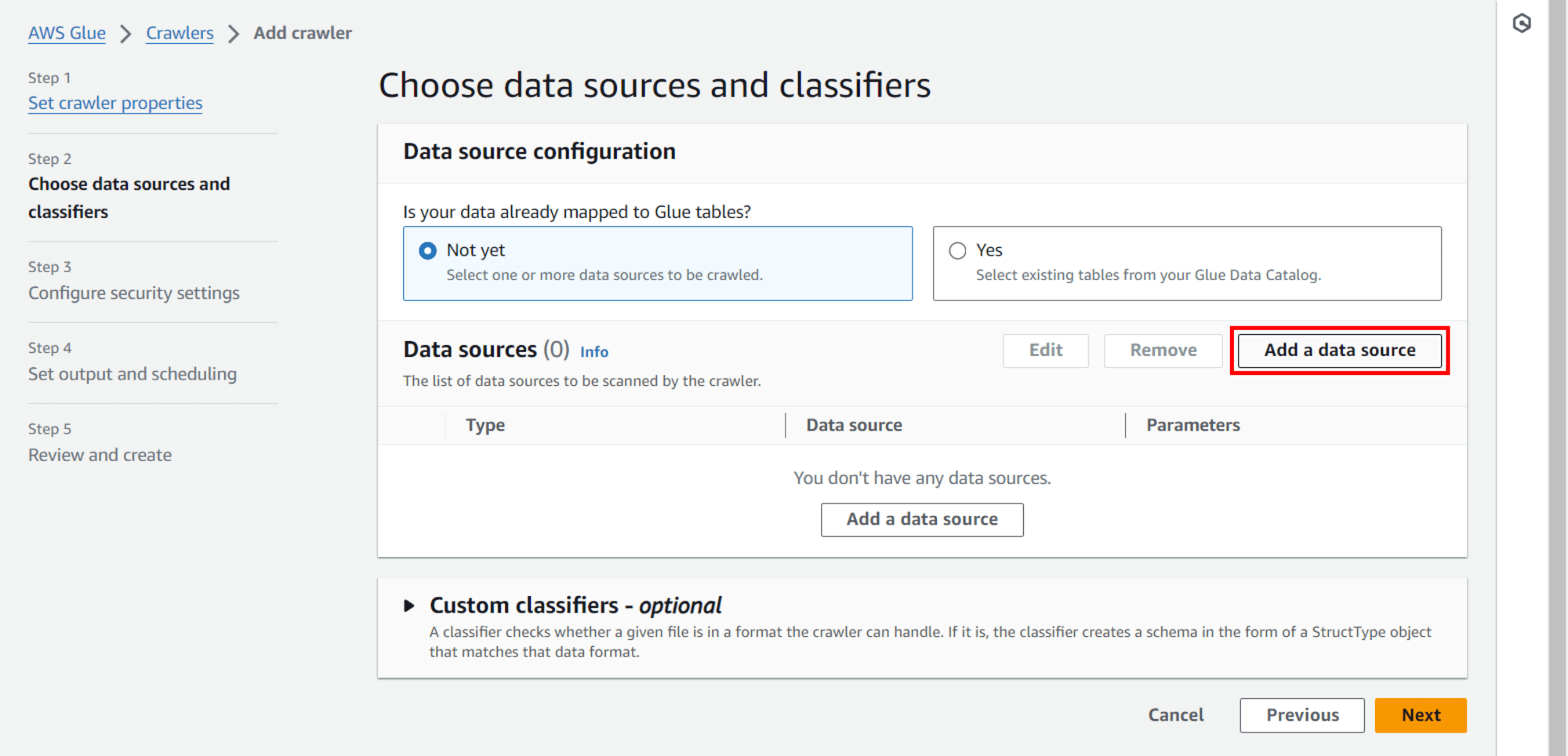
หน้าจอ POPUP
Add data source
Data source: S3 (Default)
S3 path: คลิก Browse S3
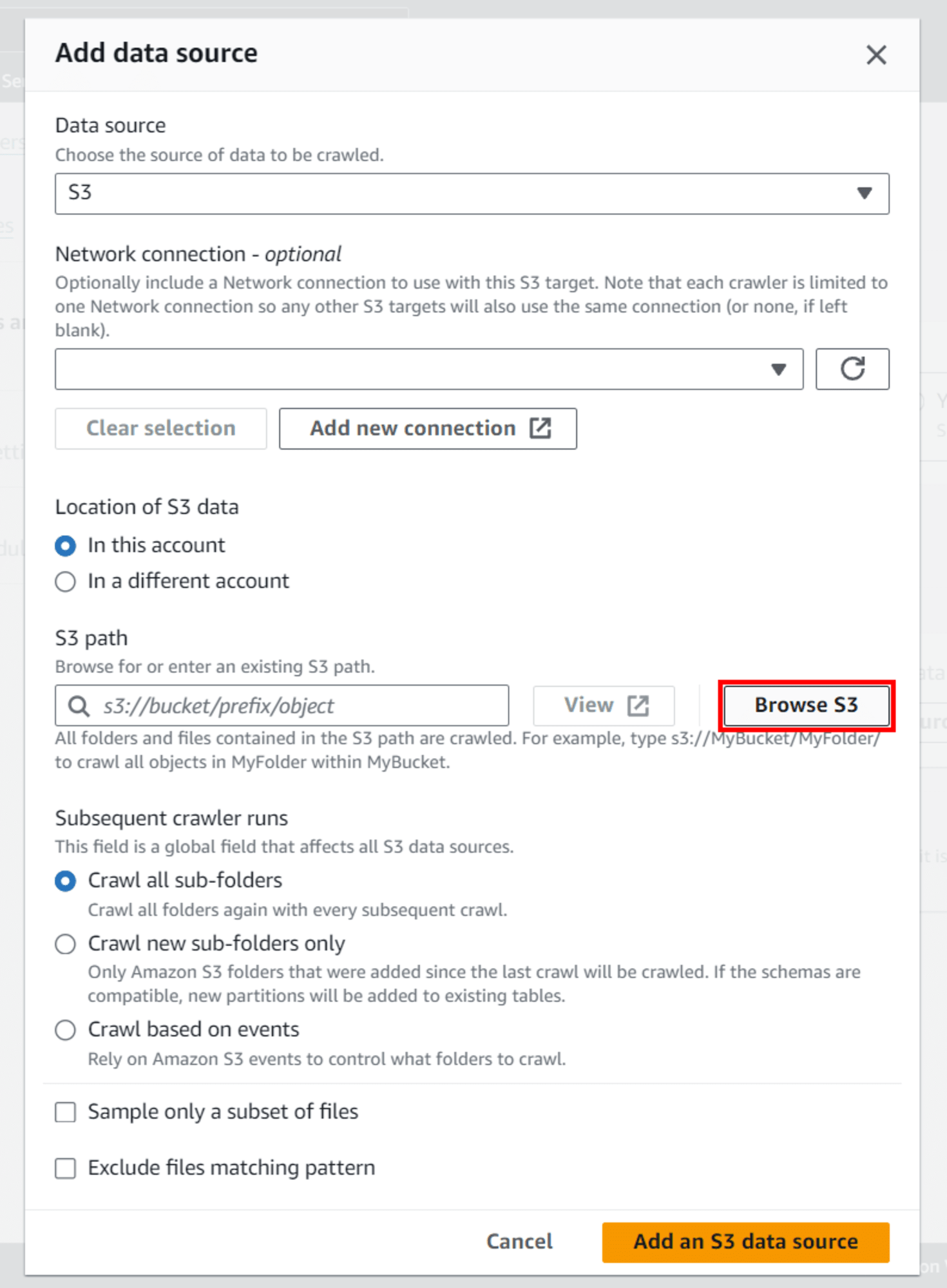
ค้นหาและเลือก Bucket ของเรา เช่น tinnakorn-test-s3 แล้วคลิก Choose
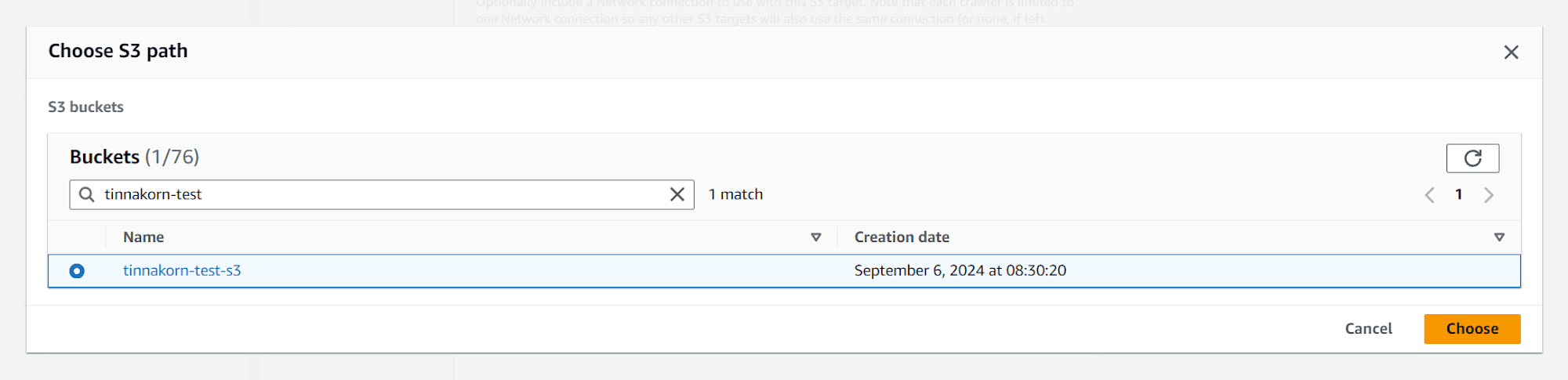
แล้วคลิก Add an S3 data source ด้านล่างสุด (หากในช่อง S3 path แสดงเป็นสีแดงก็ไม่เป็นไร)
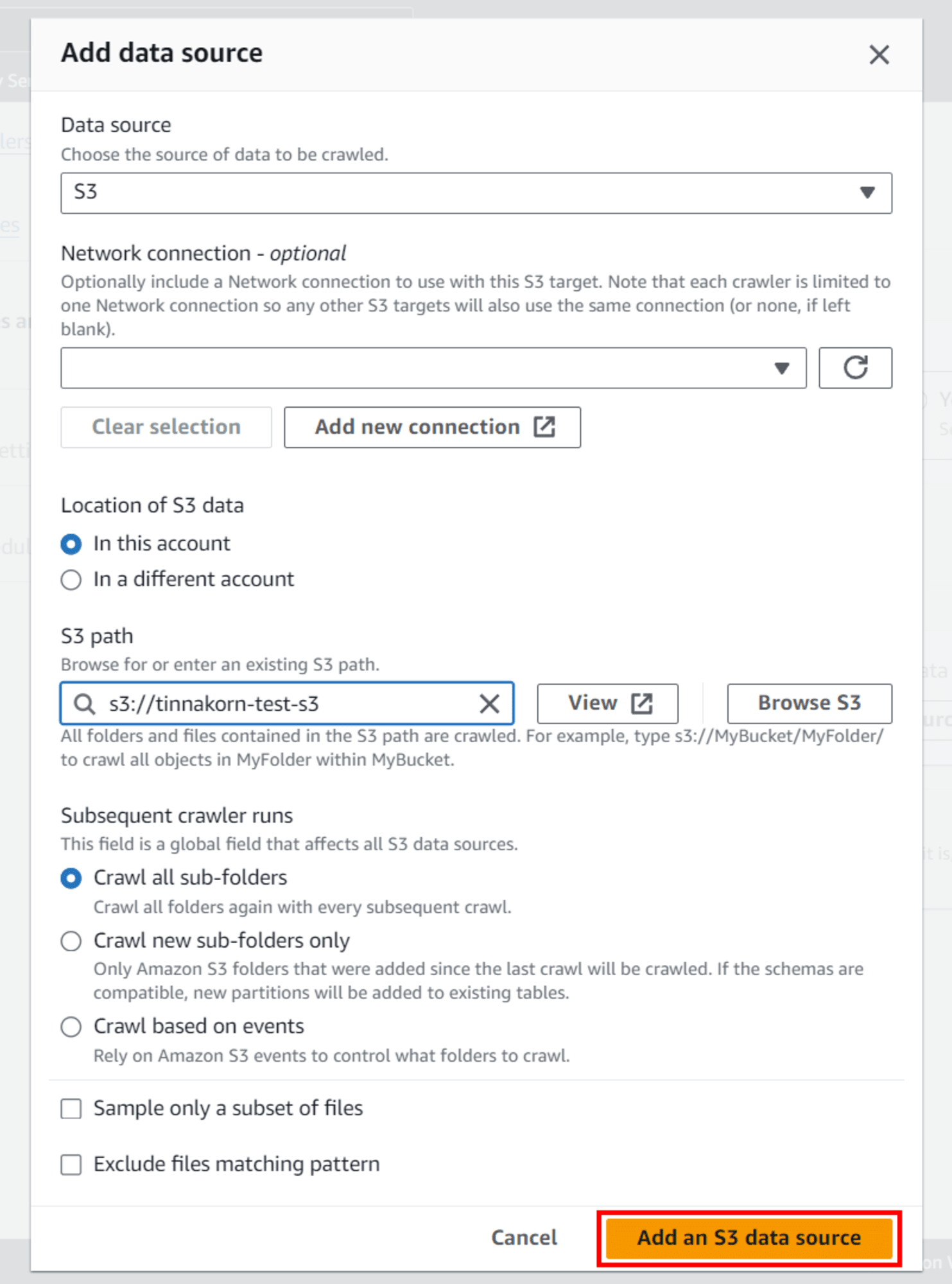
ออกจากหน้าจอ POPUP
แล้วจะเห็น Data source แสดงเป็น path S3 Bucket ของเราแบบนี้ แล้วคลิก Next
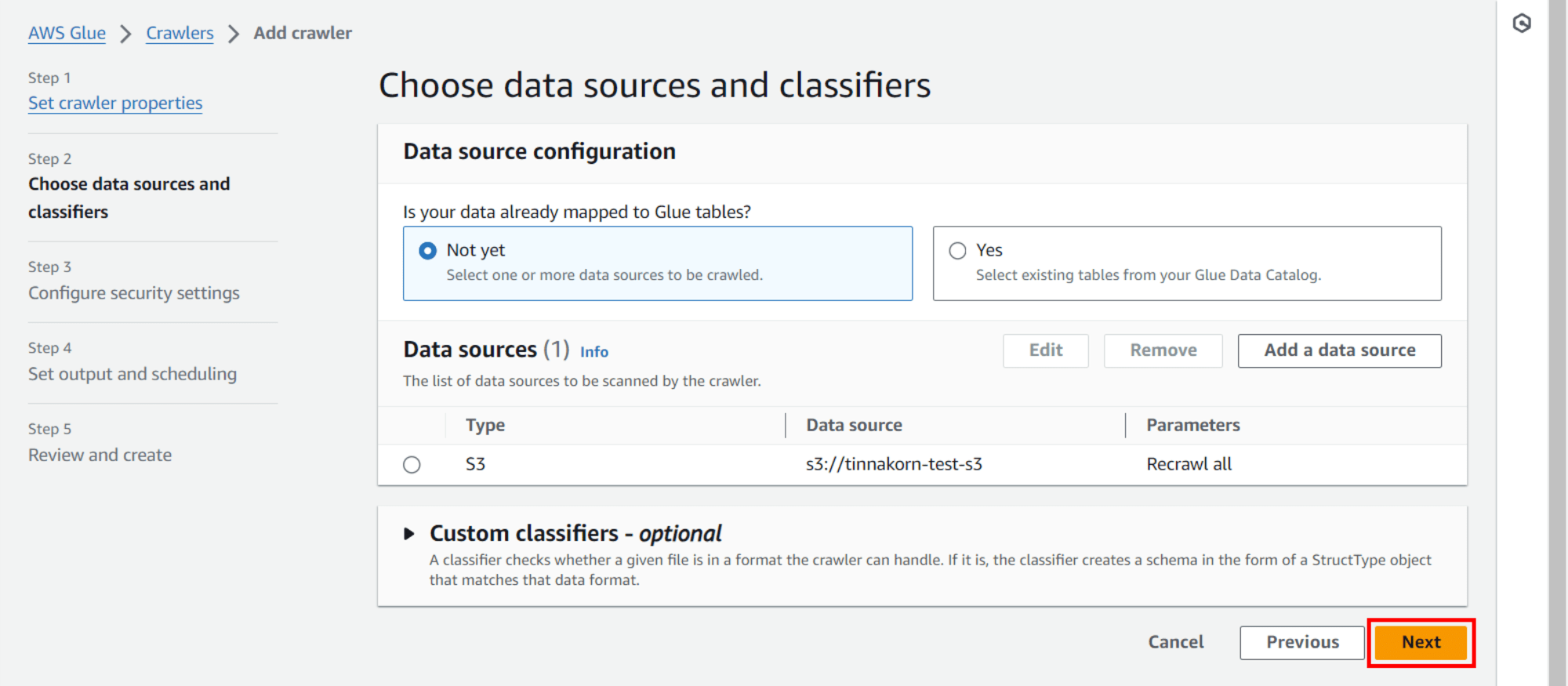
Step 3: Configure security settings
IAM role
Existing IAM role: คลิก Create new IAM role
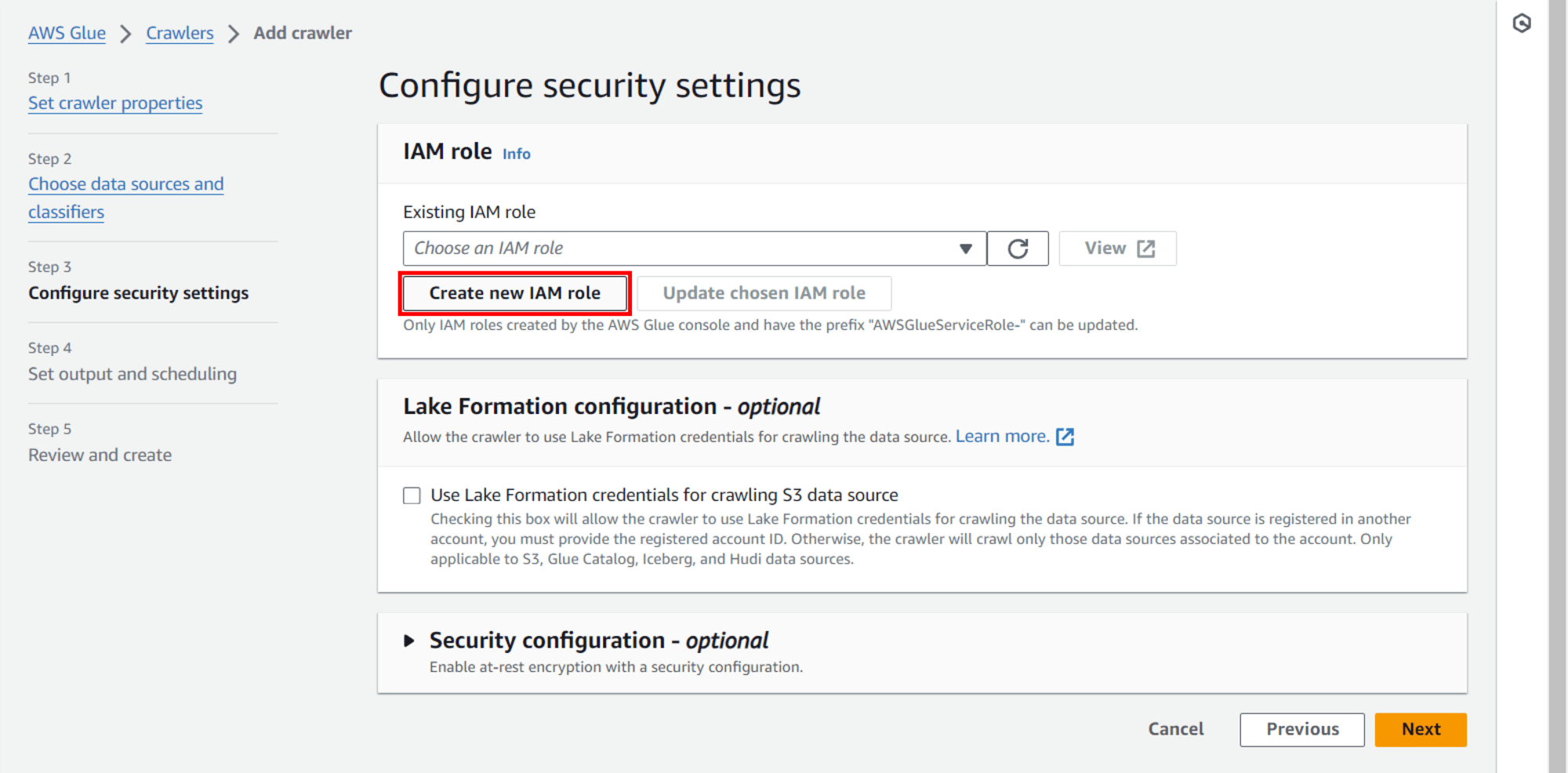
หน้าจอ POPUP
Create new IAM role
Enter new IAM role: AWSGlueServiceRole-tinnakorn-test (แนะนำให้ป้อนขื่อที่ต้องการต่อจากชื่อที่ระบบแนะนำเพื่อให้ง่ายต่อการค้นหา เช่น AWSGlueServiceRole-your_name) แล้วคลิก Create
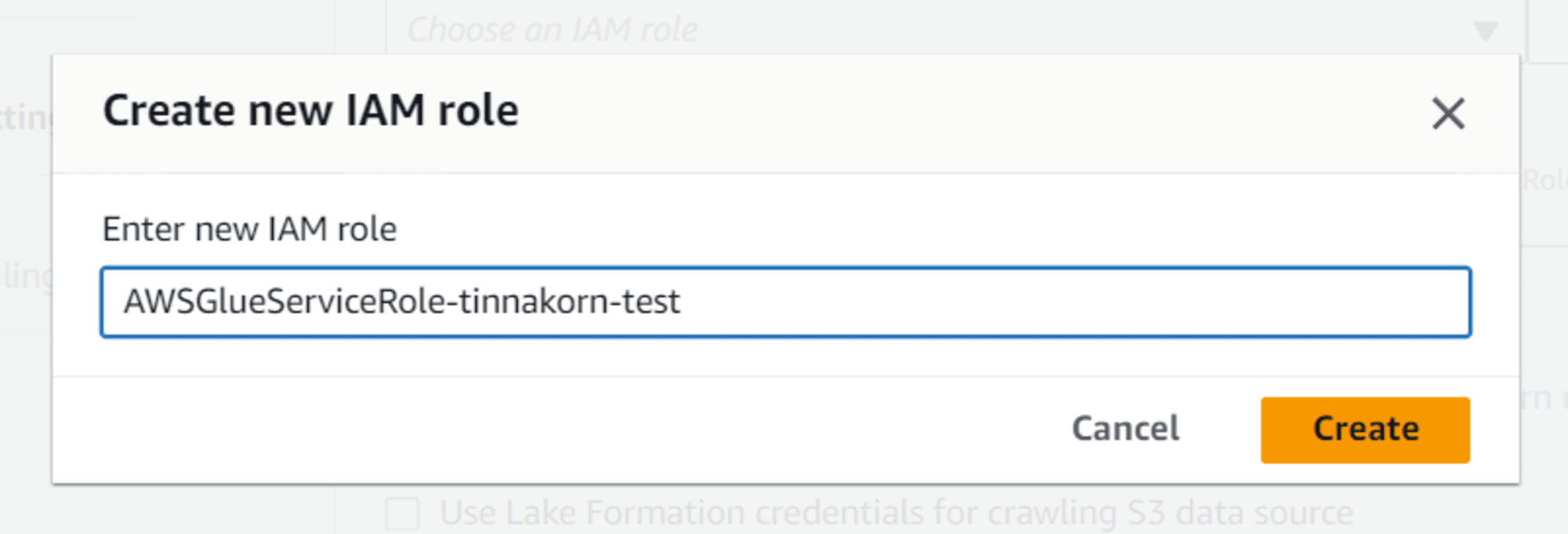
ออกจากหน้าจอ POPUP
แล้วจะแสดง Role ที่สร้างใหม่ของเราใน Existing IAM role แบบนี้ แล้วคลิก Next
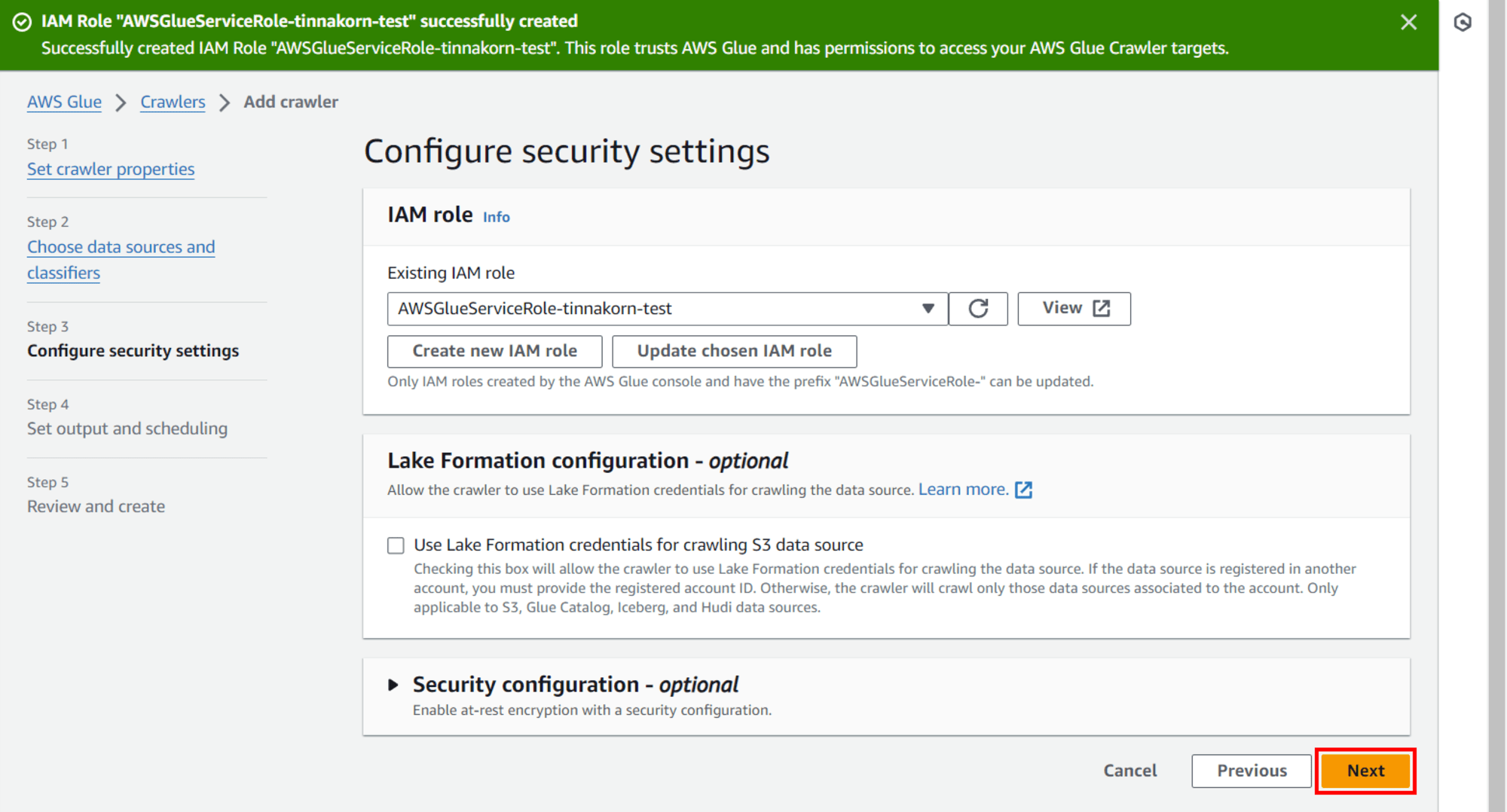
Step 4: Set output and scheduling
Output configuration
Target database: เลือก Database ที่ต้องการบันทึกข้อมูล เช่น tinnakorn-test
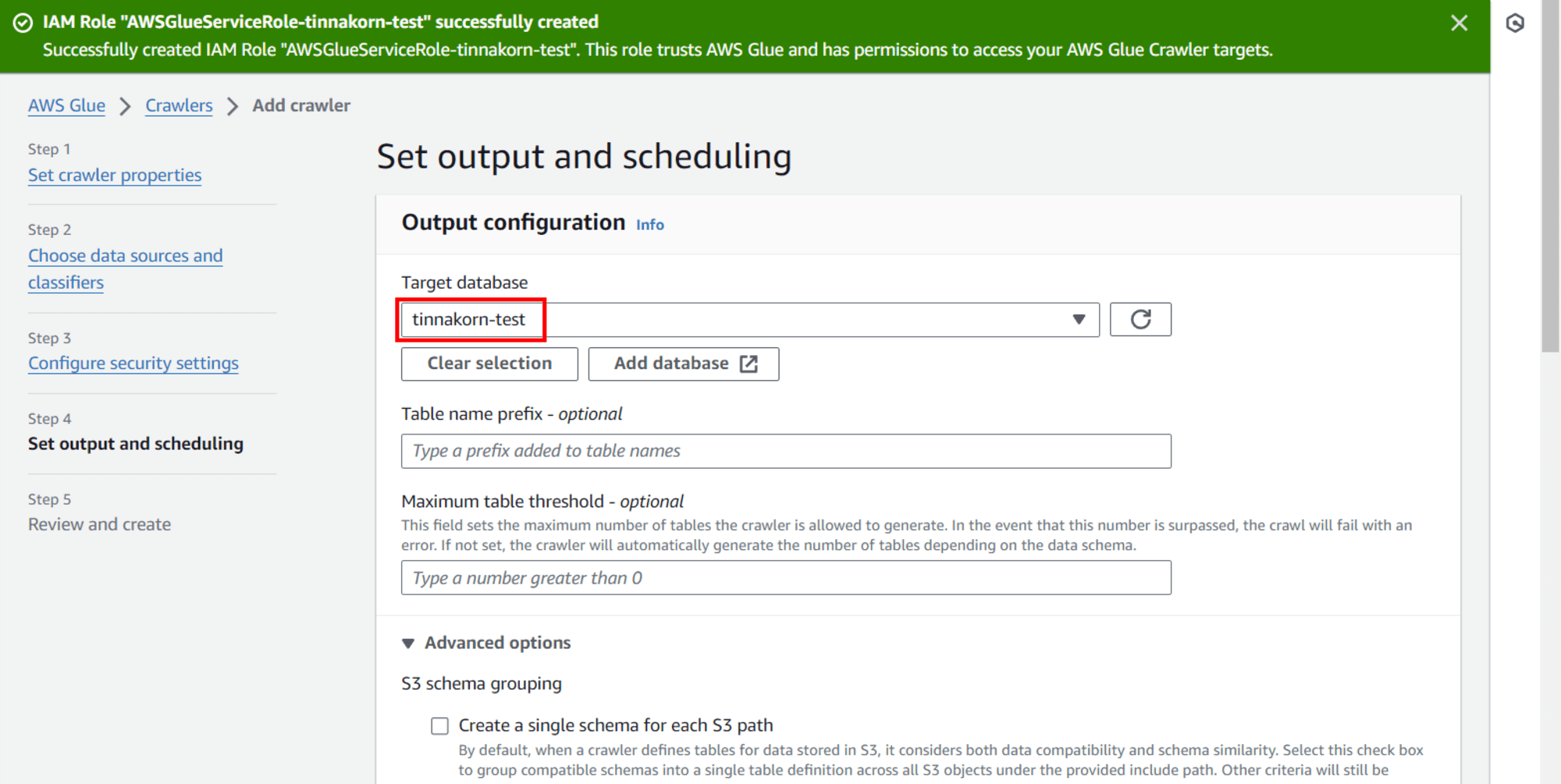
คลิก Advanced options ขยายลงมา แล้วเลื่อนลงมาด้านล่างและเอาเครื่องหมายถูกตรง ▢ Create partition indexes automatically ออกไป (ค่าเริ่มต้นจะติ๊ก ✅️ มาให้)
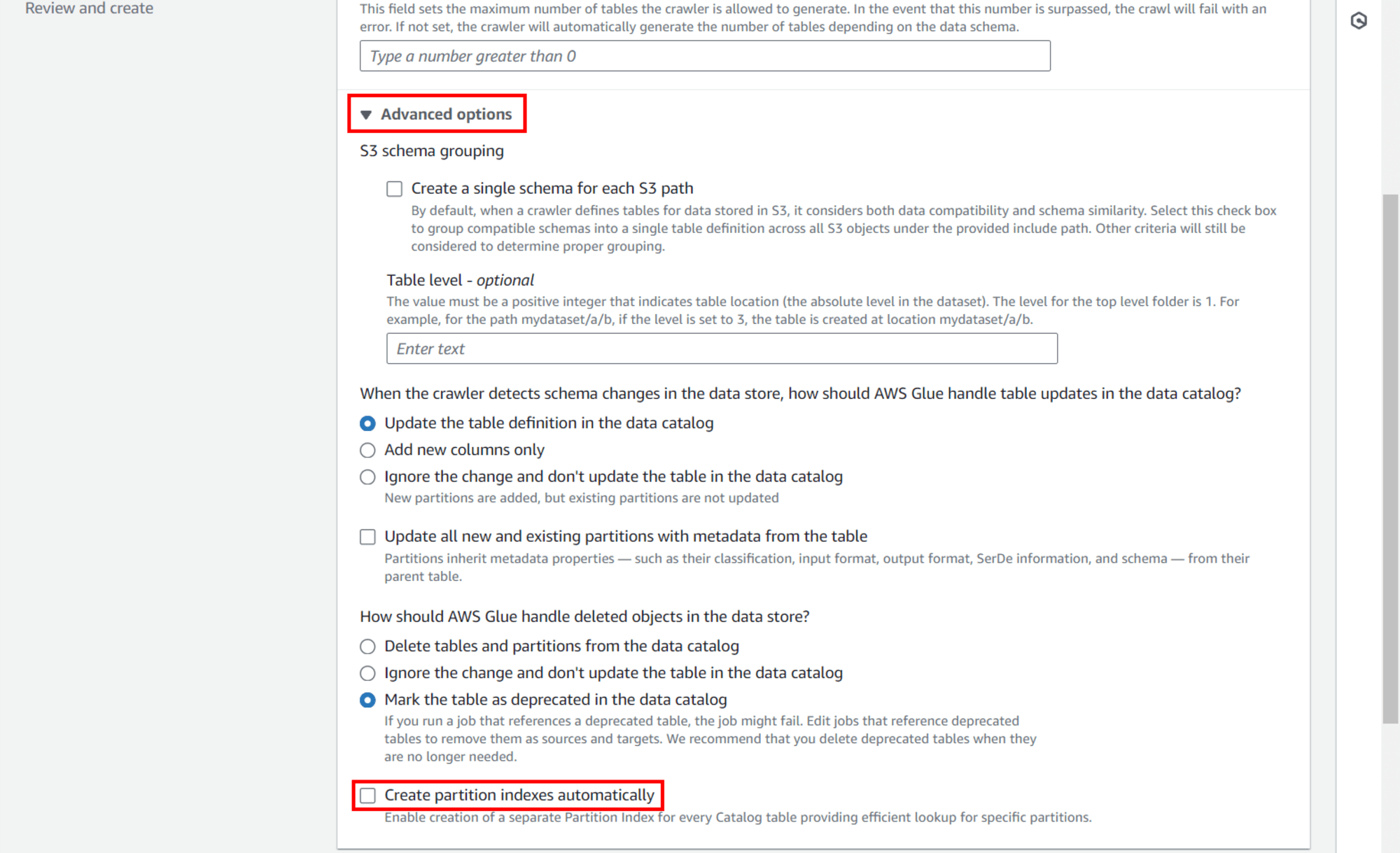
แล้วคลิก Next ที่ด้านล่างขวาสุด
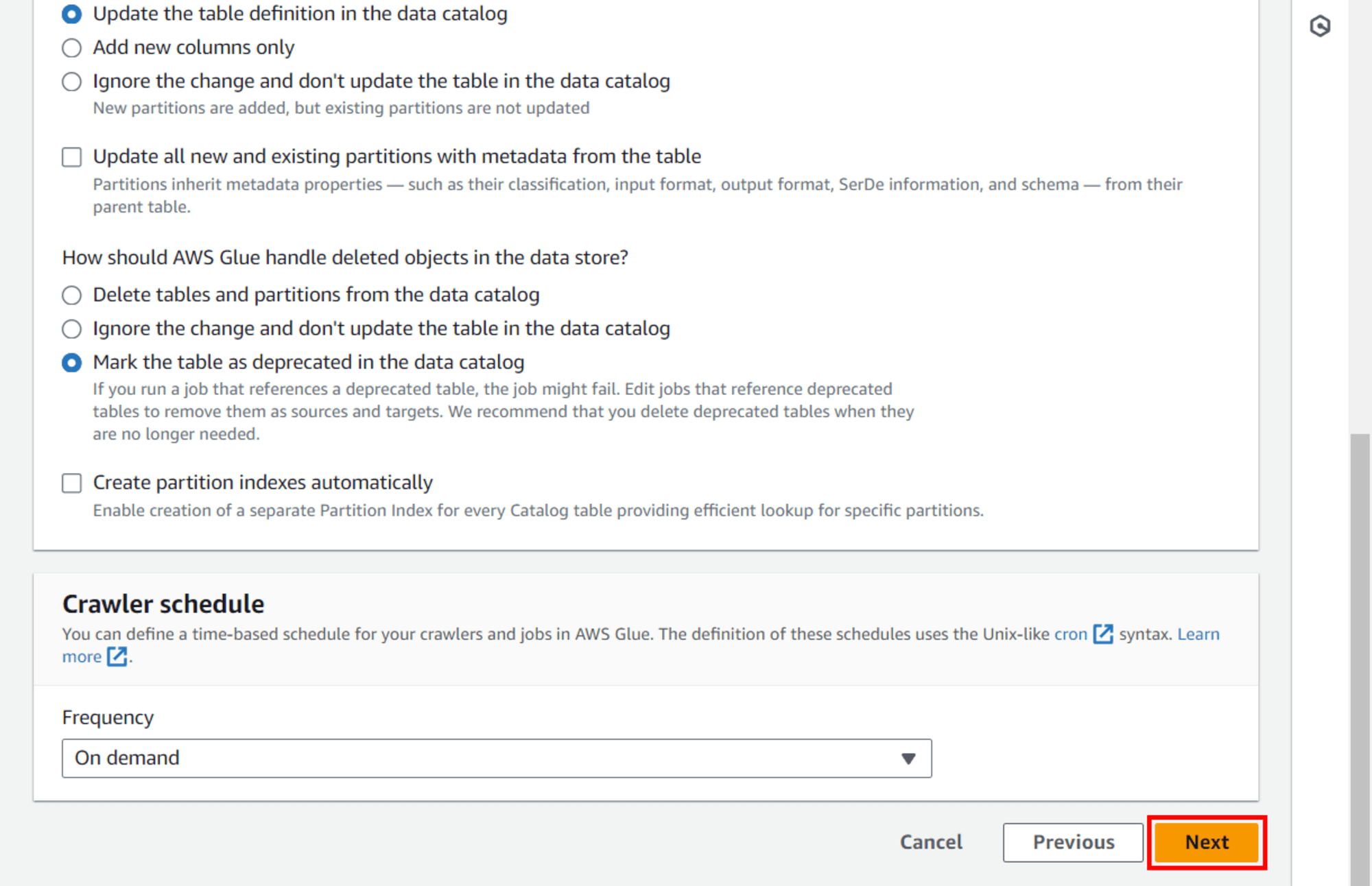
Step 5: Review and create
ตรวจสอบข้อมูลที่ป้อนตั้งแต่ Step 1 - Step 4 ให้ถูกต้อง แล้วคลิก Create crawler ด้านล่างขวาสุด
*เสร็จขั้นตอน Step 1 - Step 5*
การ Run crawler
ขั้นตอนนี้ผมจะทำการ Run crawler เพื่อสร้าง Table ไปยัง Database
เมื่อสร้าง Crawler เสร็จแล้วจะแสดงหน้าจอแบบนี้
แล้วคลิกปุ่ม Run crawler (ปุ่มจะอยู่ด้านบนขวาและด้านล่างในแท็บ Crawler runs โดยจะคลิกปุ่มไหนก็ได้)
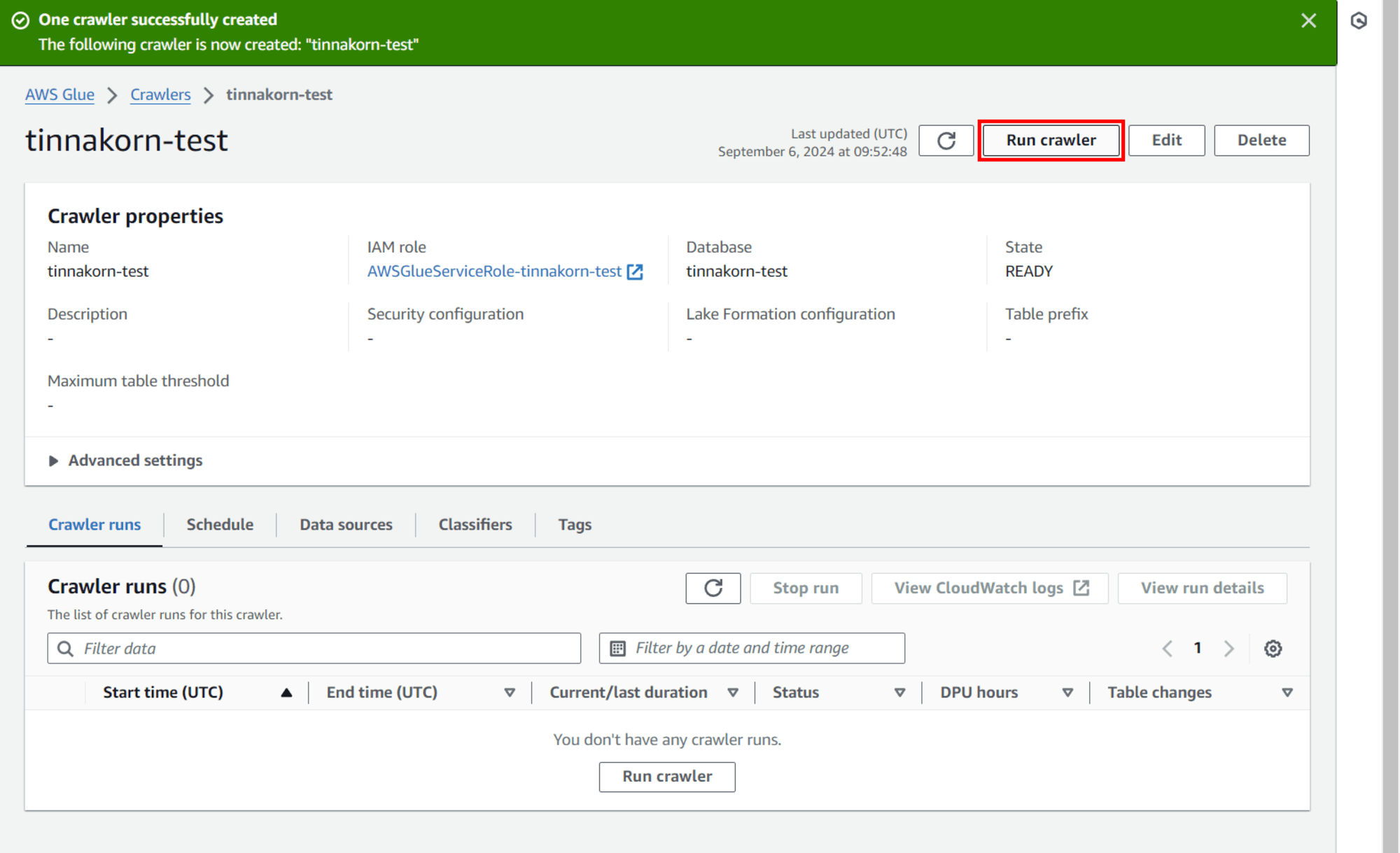
แล้วดูที่แท็บ Crawler runs ด้านล่าง จะเห็นว่า Crawler กำลังสร้าง Table ไปยัง Database ที่เราสร้างไว้ในตอนแรก โดยแสดง Status เป็น Running
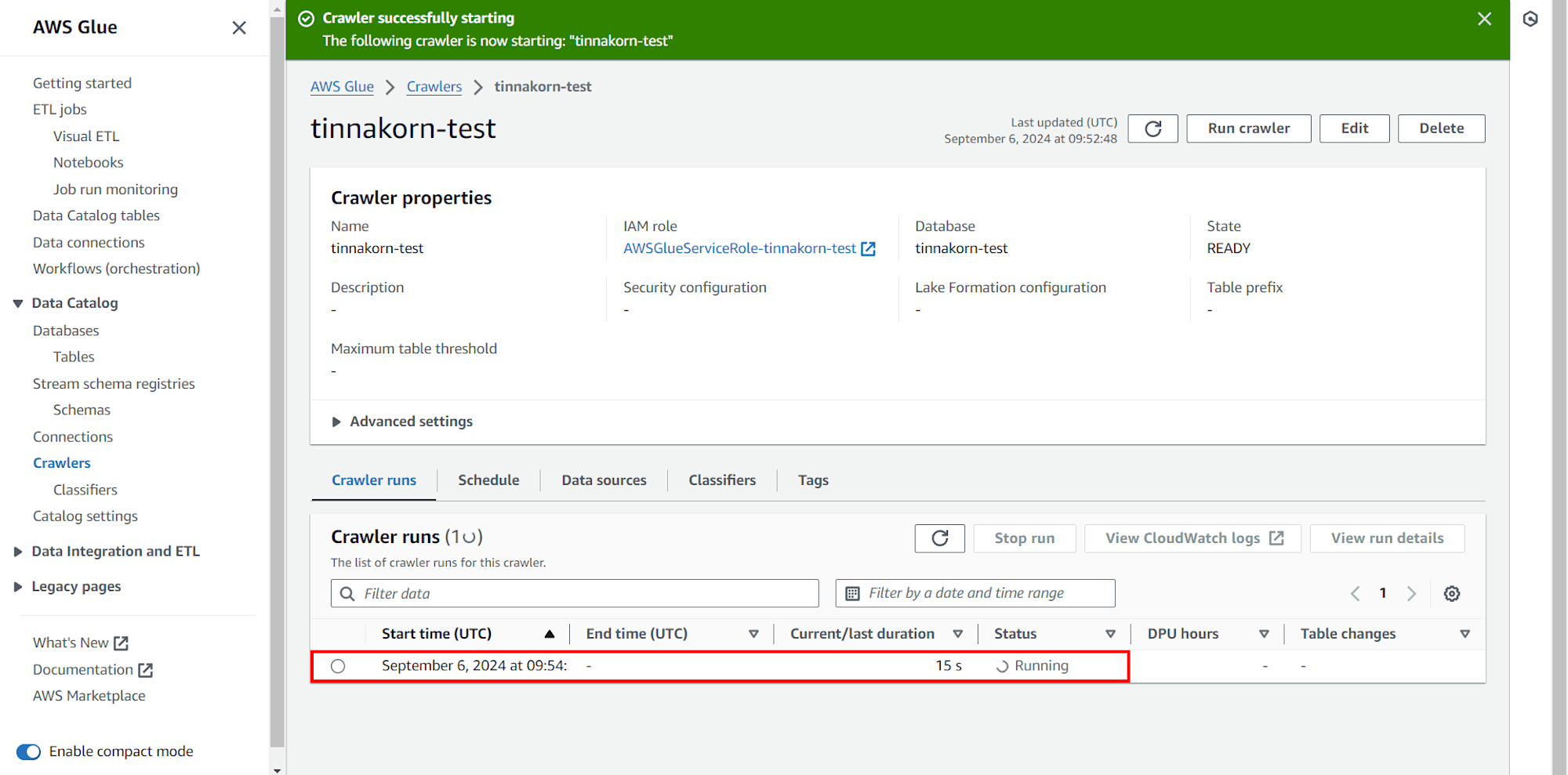
เมื่อสร้าง Table ไปยัง Database ของเราแล้ว จะแสดง Status เป็น Completed
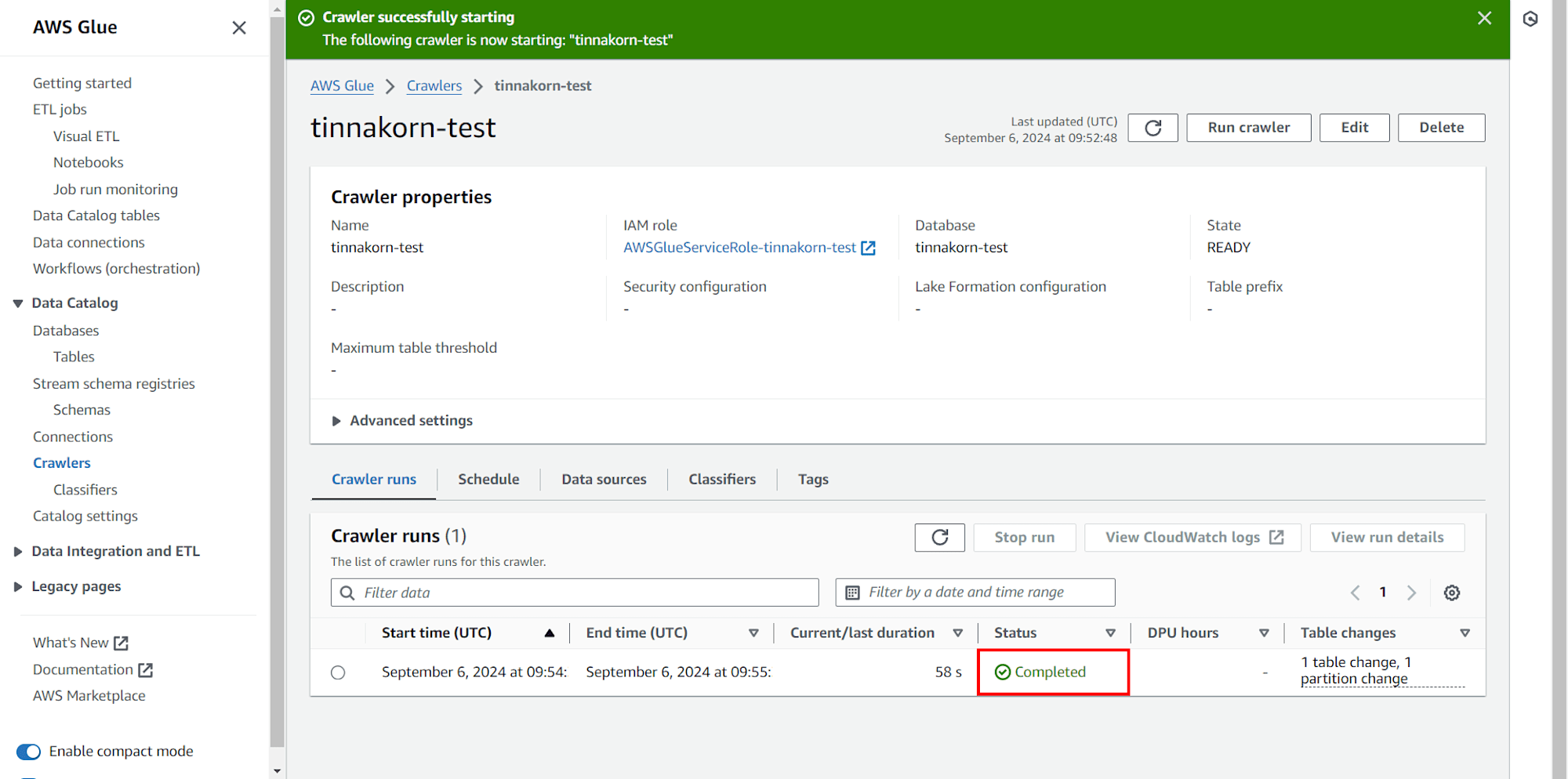
ตั้งค่า Schema ใน Table
ขั้นตอนนี้ผมจะเปลี่ยน datetime: string ให้เป็น datetime: timestamp
ต่อไปคลิกเมนู Tables จากด้านซ้าย แล้วค้นหาและคลิกเข้าไปที่ชื่อของเราในช่อง Name เช่น tinnakorn_test_s3 (ชื่อ Table จะถูกสร้างตามชื่อ Bucket หรือชื่อโฟลเดอร์ใน Objects ตามที่เราเลือก)
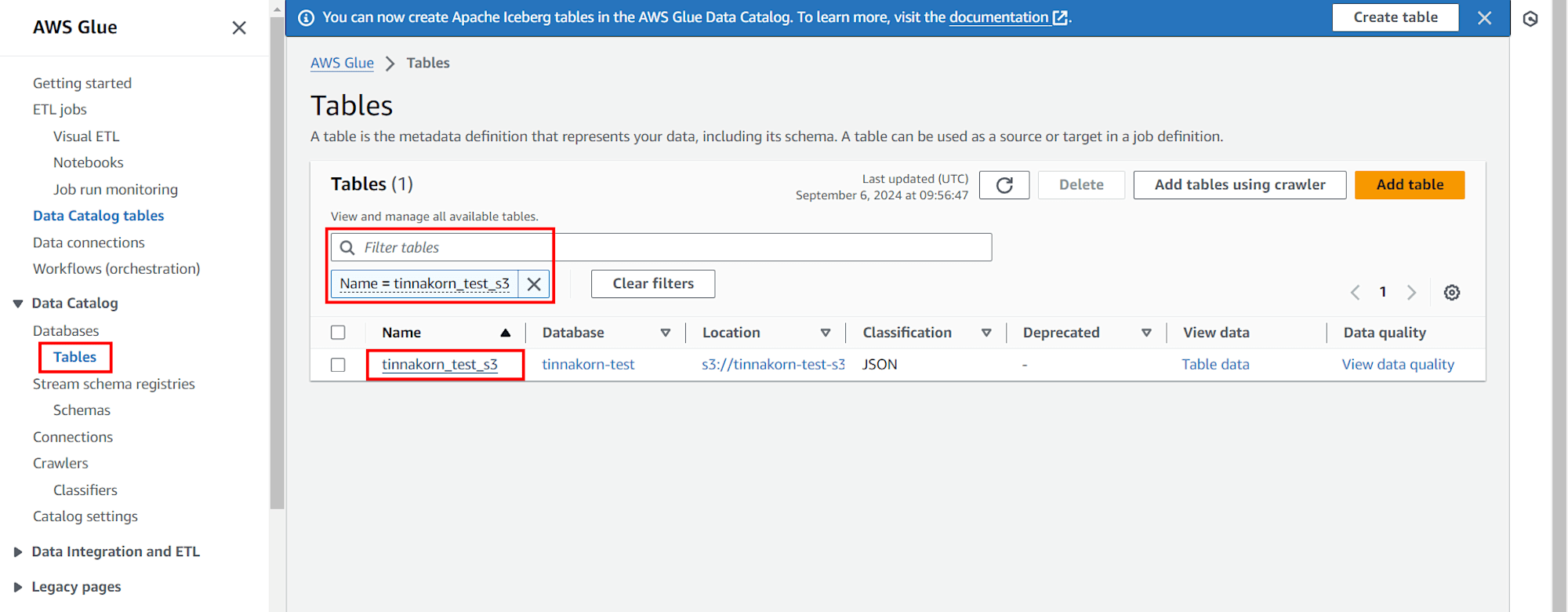
แล้วเลื่อนลงมาที่แท็บ Schema ด้านล่างสุด แล้วดูที่ Column name: datetime จะเห็นว่าแสดงเป็น Data type: string ซึ่งเราจะมาแก้ไขในส่วนนี้โดยคลิก Edit schema ด้านบนขวาในแท็บ Schema
หมายเหตุ: หากเข้ามาแล้วแสดง Error "this table no longer exists." ให้รีสตาร์ทเบราว์เซอร์ที่เรากำลังใช้งาน แล้วตรวจสอบอีกครั้ง
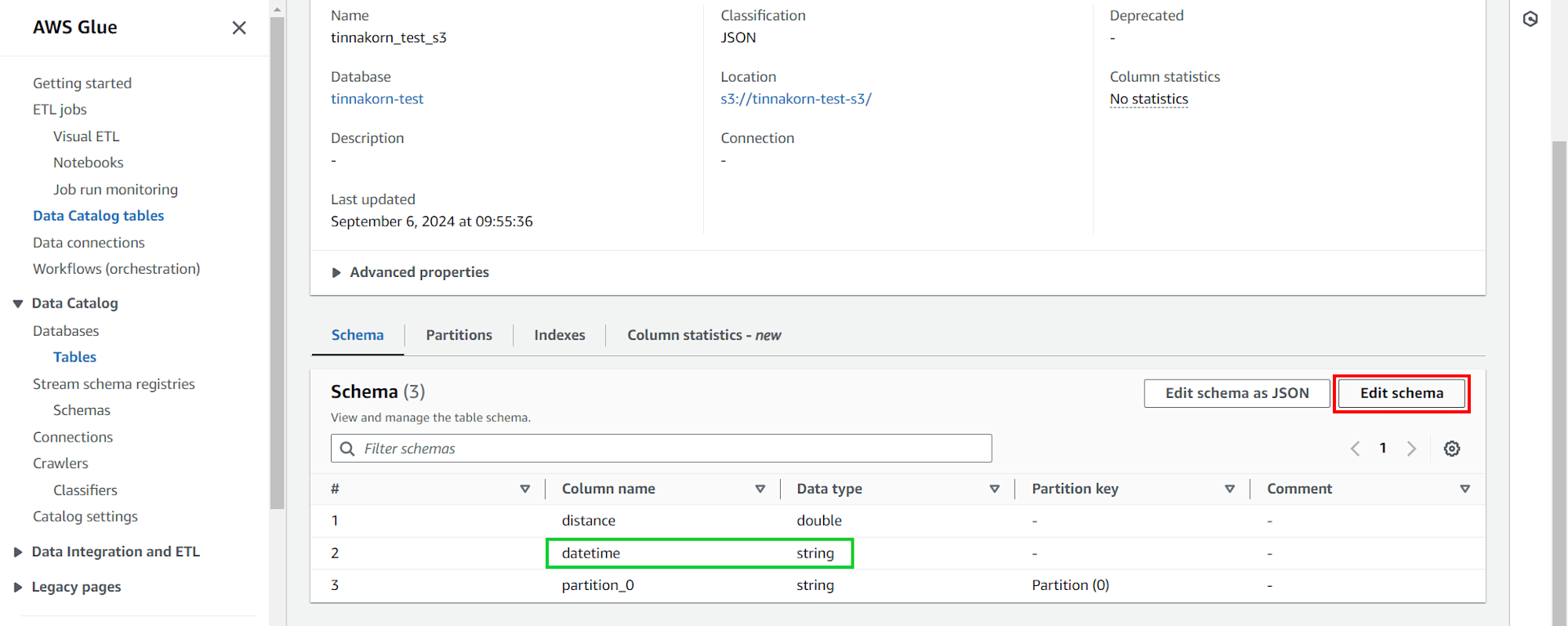
แล้วติ๊ก ✅️ แถว [#: 2, Column name: datetime, Data type: string] แล้วคลิก Edit
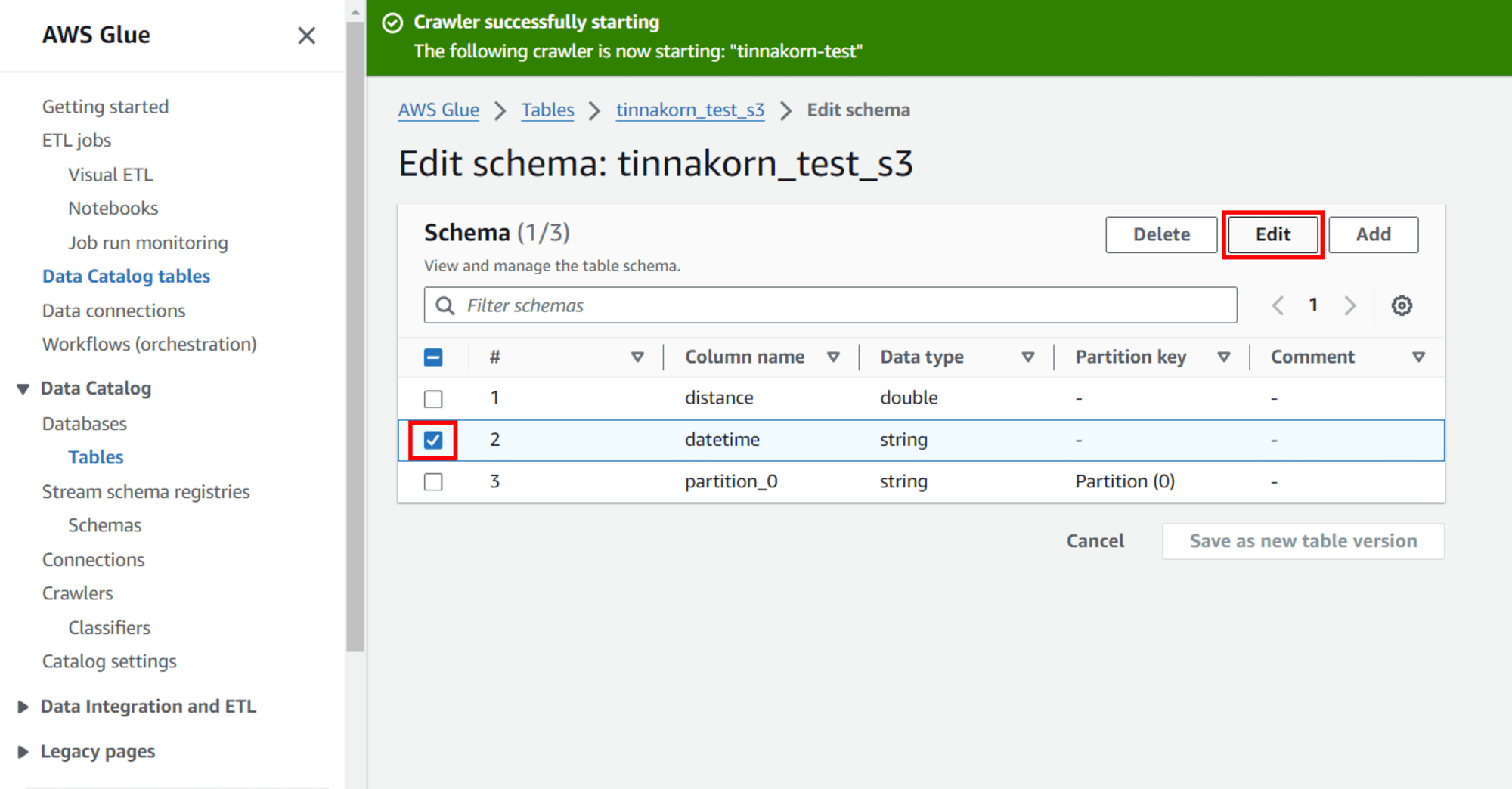
*หน้าจอ POPUP*
แล้วเปลี่ยนตรง Data type ให้เป็น timestamp แล้วคลิก Save
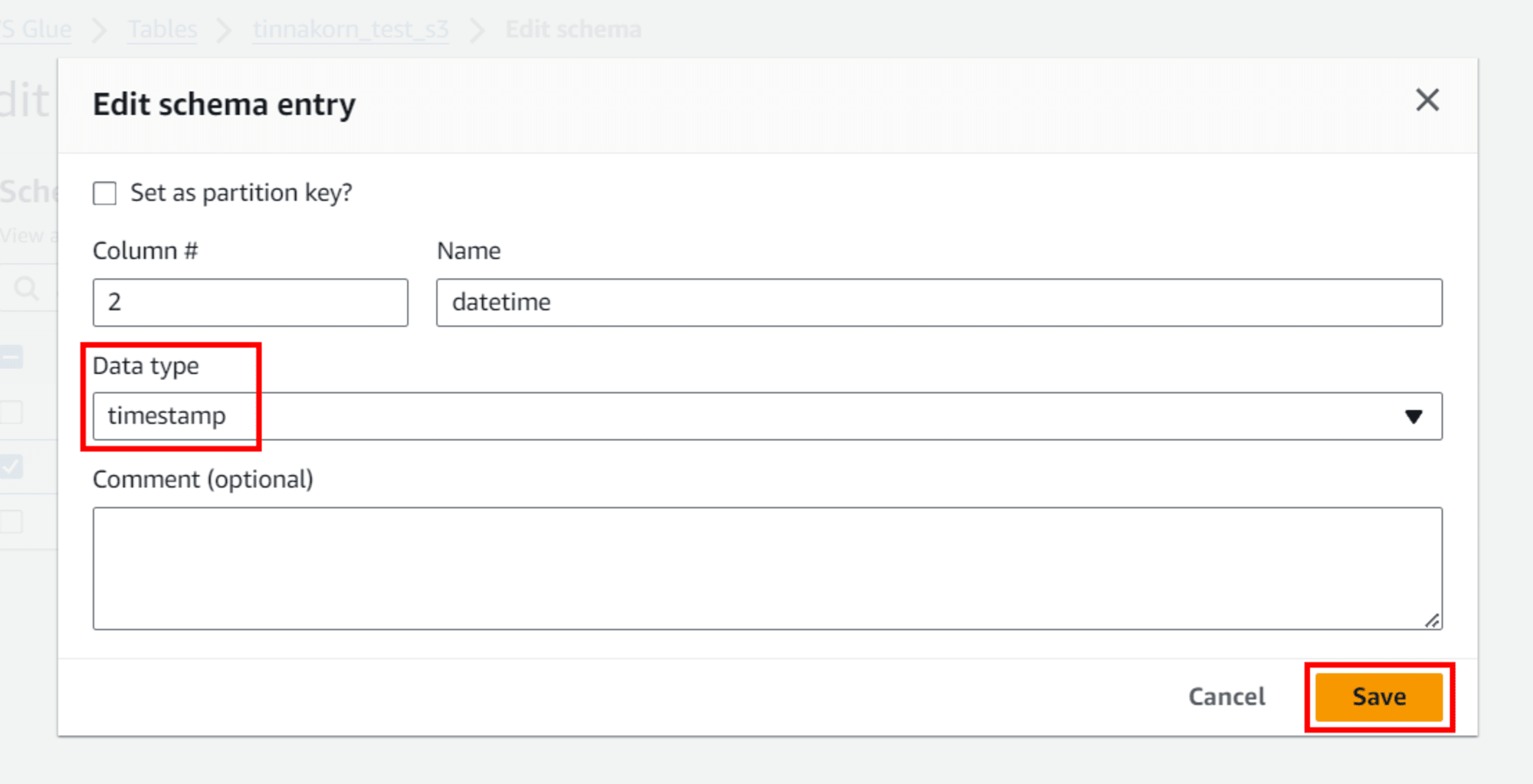
*ออกจากหน้าจอ POPUP*
แล้วติ๊ก ✅️ แถว [#: 3, Column name: partition_0, Data type: string] แล้วคลิก Delete
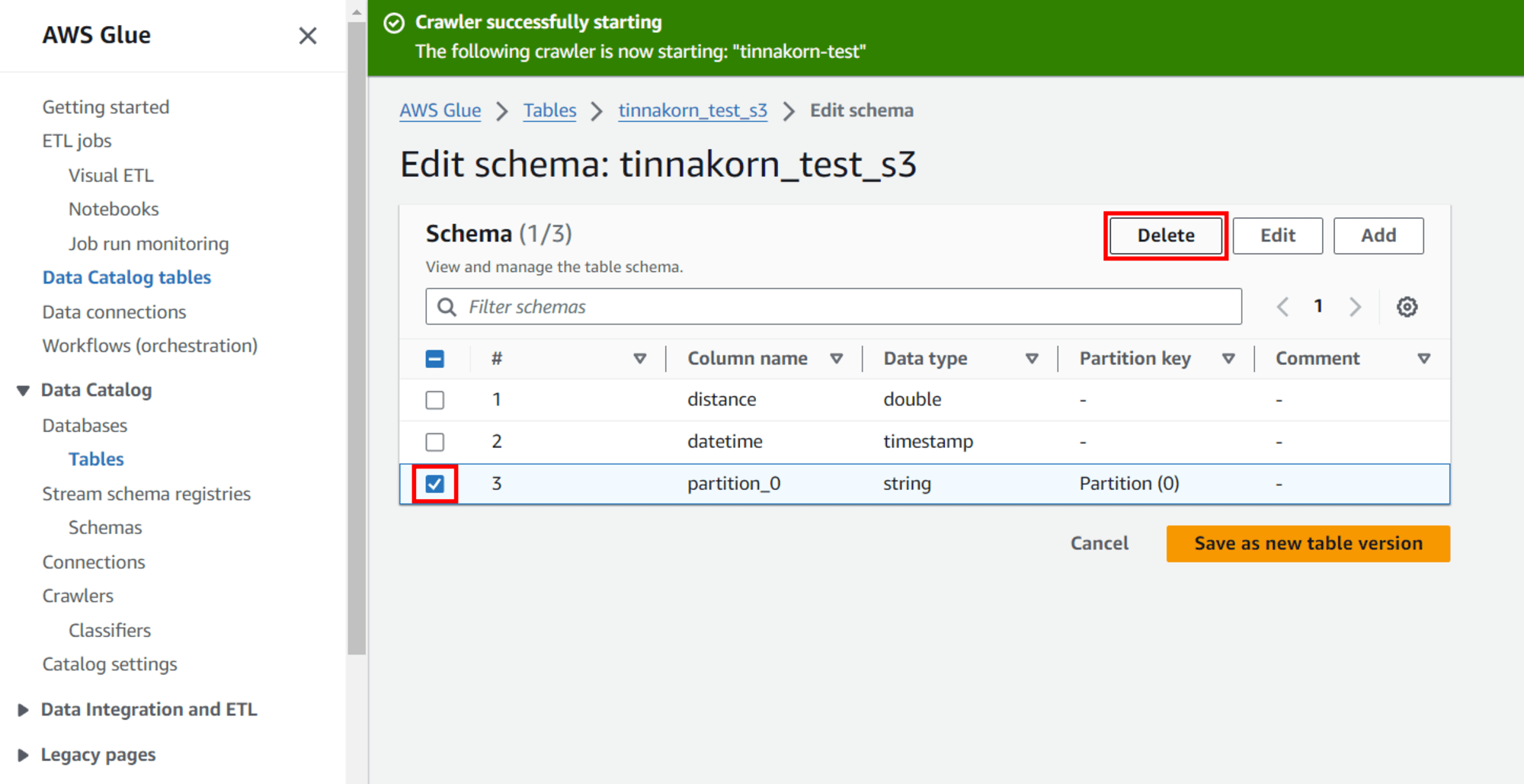
แล้วคลิก Save as new table version
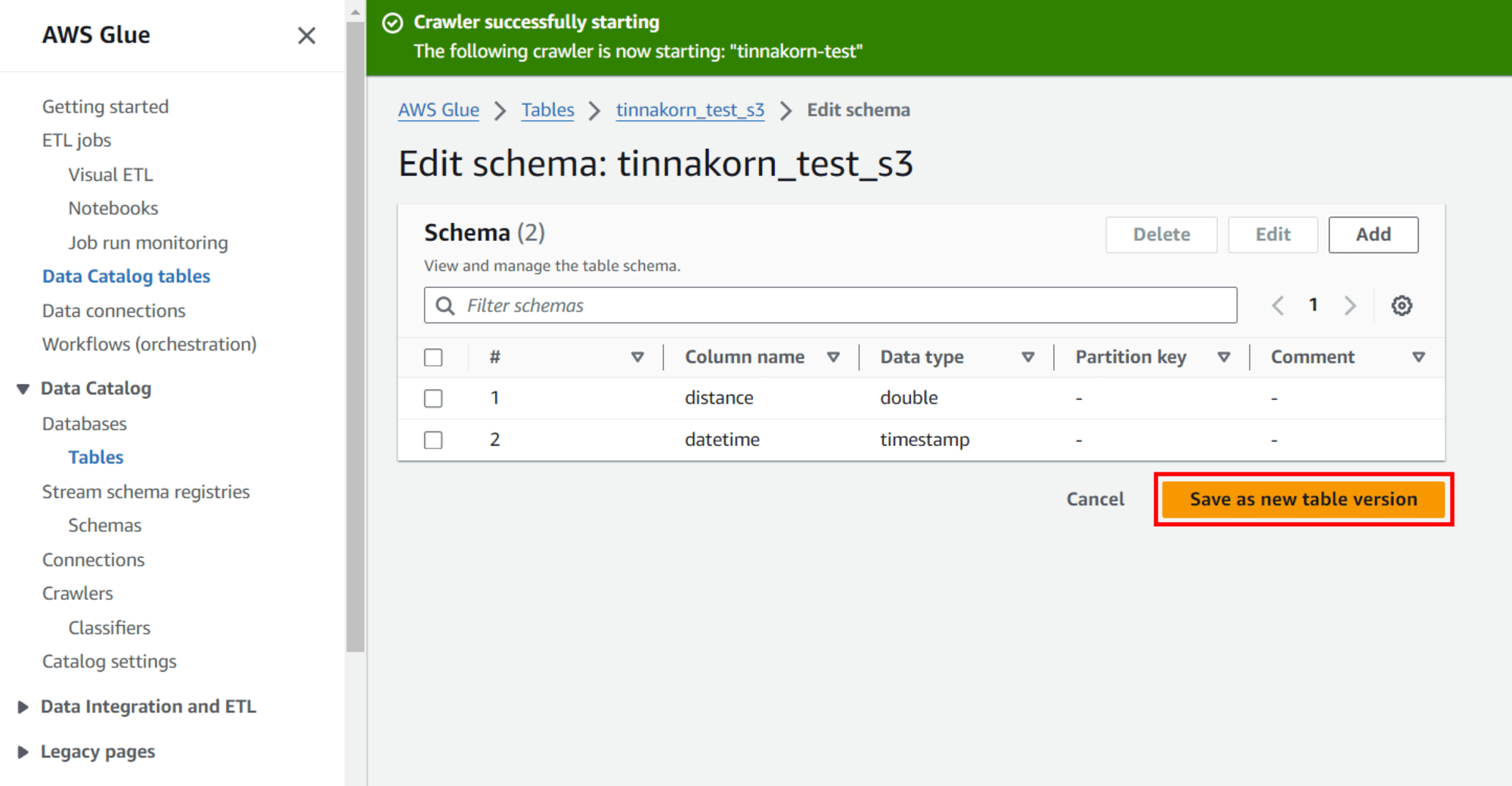
ตรวจสอบที่ Column name: datetime อีกครั้ง จะเห็นว่าเปลี่ยนเป็น Data type: timestamp เรียบร้อยแล้ว
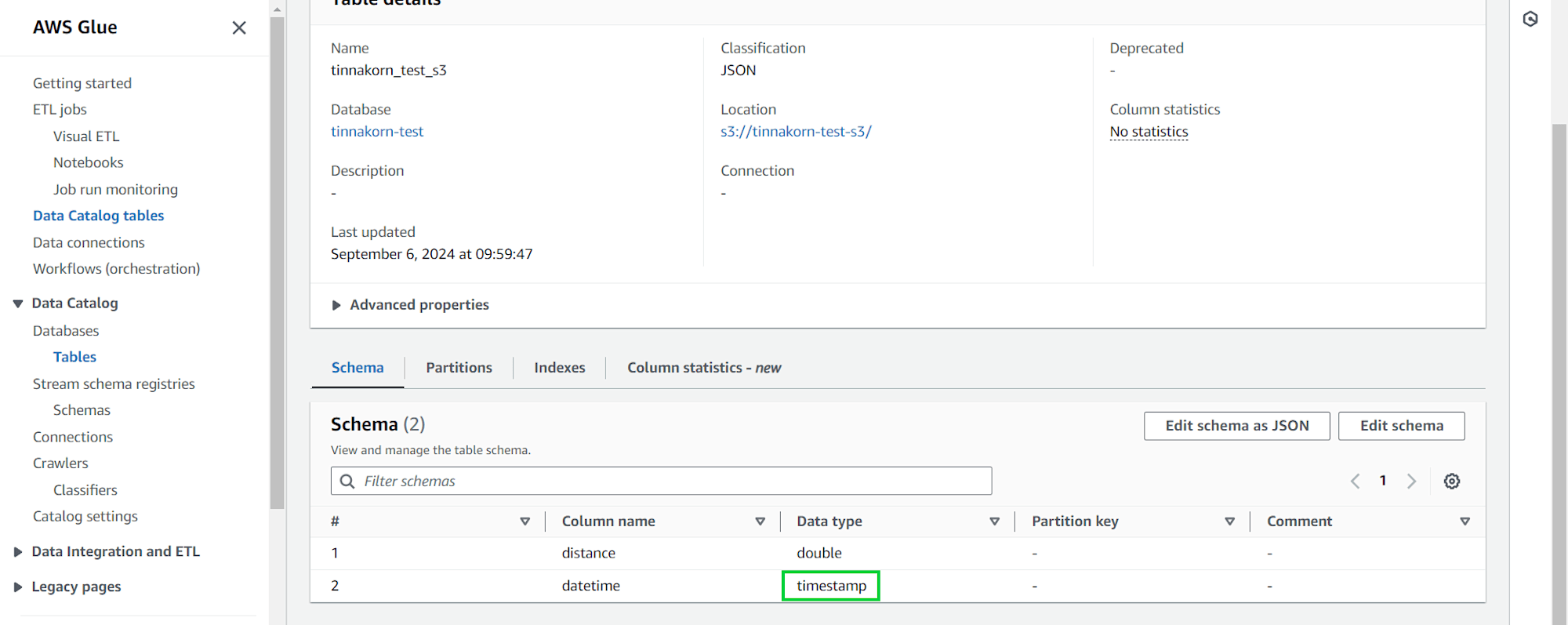
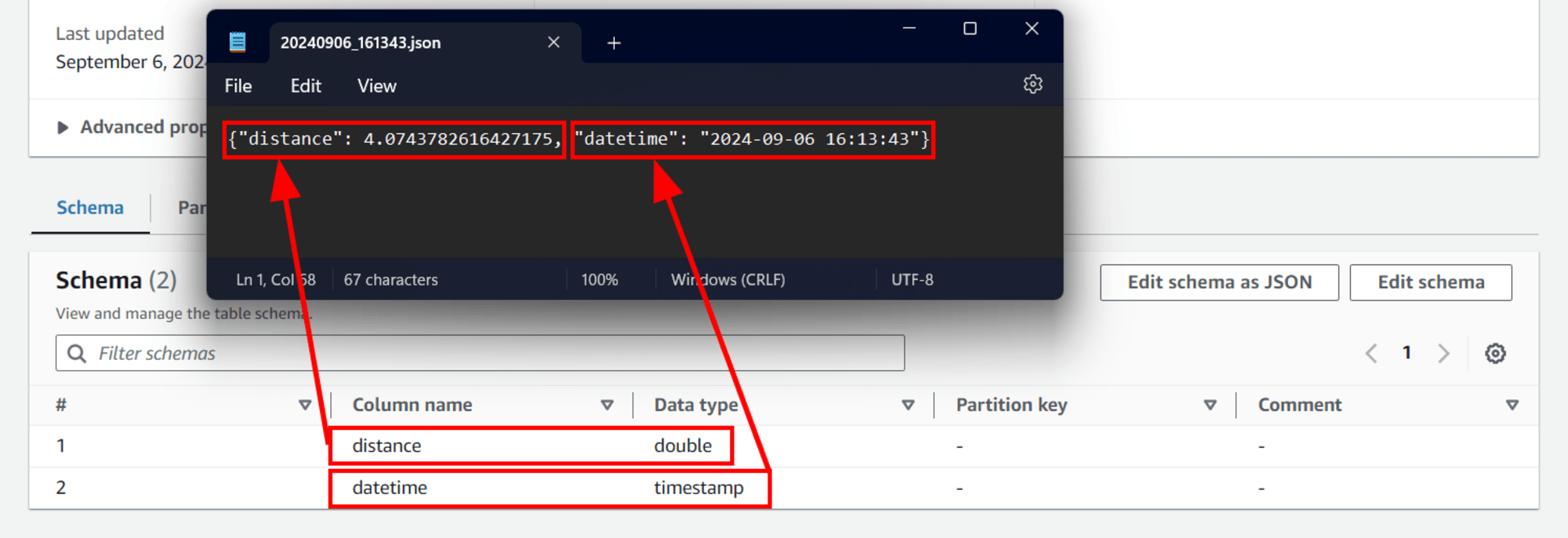
ในส่วนของ Schema นี้คือ เวลาที่ไฟล์ JSON ถูกอัปโหลดไปที่ S3
ไฟล์ JSON จะถูกอ่านข้อมูลดังนี้
| Column name | Data type | JSON | Description |
|---|---|---|---|
| distance | double | 4.0743782616427175 | ข้อมูลประเภทตัวเลขทศนิยม |
| datetime | timestamp | 2024-09-06 16:13:43 | ข้อมูลวันที่และเวลา |
เวลาที่ไฟล์ JSON ถูกอัปโหลดไปที่ S3 ตัวฟังก์ชัน Crawlers จะทำการตรวจสอบไฟล์ที่มีอยู่ใน S3 ว่าเป็นไฟล์แบบไหน จะต้องสร้าง Table ยังไง จากนั้น Crawlers จะทำการรวบรวมข้อมูลเพื่อตัดสินใจและสร้าง Table มาให้โดยอัตโนมัติ ซึ่งฟังก์ชัน Crawlers นี้คือการทำงานของ AWS Glue
ทีนี้ผมจะเทียบ Schema กับไฟล์ JSON ให้เห็นตำแหน่งของข้อมูลได้ชัดเจนมากขึ้นโดยดูจากรูปด้านล่างได้เลย
ในส่วนของขั้นตอน 2 นี้ก็เสร็จเรียบร้อยแล้ว ผมจะทบทวนสิ่งที่ได้ทำมาจนถึงตอนนี้อีกครั้ง
- สิ่งที่ได้ทำไปแล้วในหัวข้อ 2. เตรียมพร้อมการเรียกใช้ SQL ไปยังไฟล์ที่มีอยู่ใน S3 ใน AWS Glue
- สร้าง Crawlers
- Run crawler เพื่อสร้าง Table ไปยัง Database โดยอัตโนมัติ
- เปลี่ยน datetime ให้เป็น timestamp ใน Schema
เมื่อสร้างทุกอย่างตามที่ระบุไว้แล้ว ให้เริ่มทำหัวข้อถัดไปได้เลยครับ
3. รัน SQL จาก Table ใน Amazon Athena
Amazon Athena คืออะไร
Amazon Athena เป็นบริการการสืบค้นแบบโต้ตอบที่ช่วยให้ง่ายต่อการวิเคราะห์ข้อมูลใน Amazon S3 โดยใช้ SQL มาตรฐาน Athena ไร้เซิร์ฟเวอร์ จึงไม่มีโครงสร้างพื้นฐานในการจัดการ และคุณจ่ายเฉพาะการสืบค้นที่คุณใช้งานเท่านั้น
สร้าง S3 Bucket เพื่อบันทึกข้อมูลการรันคำสั่งของ Athena
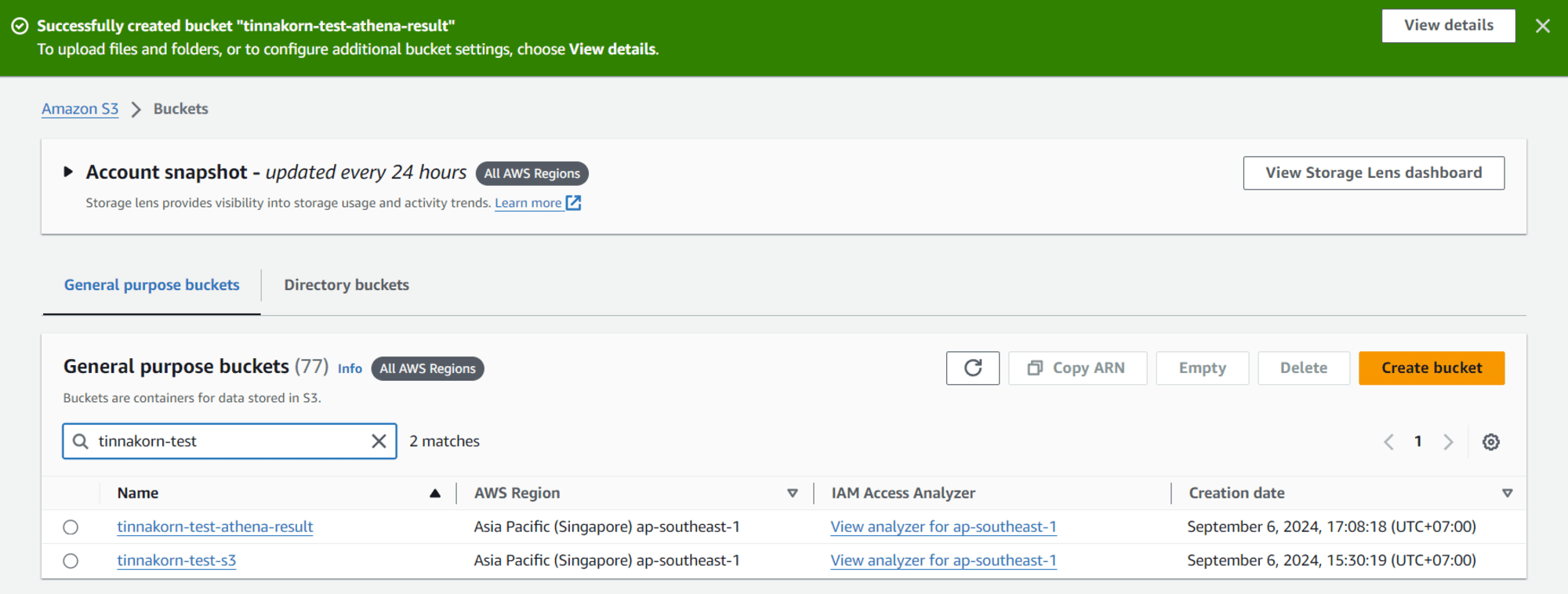
ผมจะสร้าง S3 Bucket อันที่ 2 ขึ้นมาเพื่อบันทึกข้อมูลการรันคำสั่งของ Athena
ดูตัวอย่างที่นี่: การสร้าง Buckets ใน Amazon S3
รายละเอียดการสร้าง S3 Bucket อันที่ 2 ในบทความนี้คือ:
Bucket name:tinnakorn-test-athena-resultเมื่อสร้างเสร็จแล้วผมก็จะมี S3 Bucket ทั้งหมด 2 อัน ซึ่ง S3 Bucket ที่ใช้สำหรับ Athena จะอธิบายในภายหลังครับ
สร้าง Workgroups
ขั้นตอนนี้ผมจะทำการสร้าง Workgroups ขึ้นมาเชื่อมต่อกับ S3 Bucket ที่ใช้สำหรับ Athena และตั้งค่า Query editor เพื่อใช้ในการรันคำสั่ง SQL ครับ
ค้นหาและเลือก Athena
เลือก Workgroups จากเมนูด้านซ้าย แล้วคลิก Create workgroup
Workgroup name: tinnakorn-test (ชื่ออะไรก็ได้)
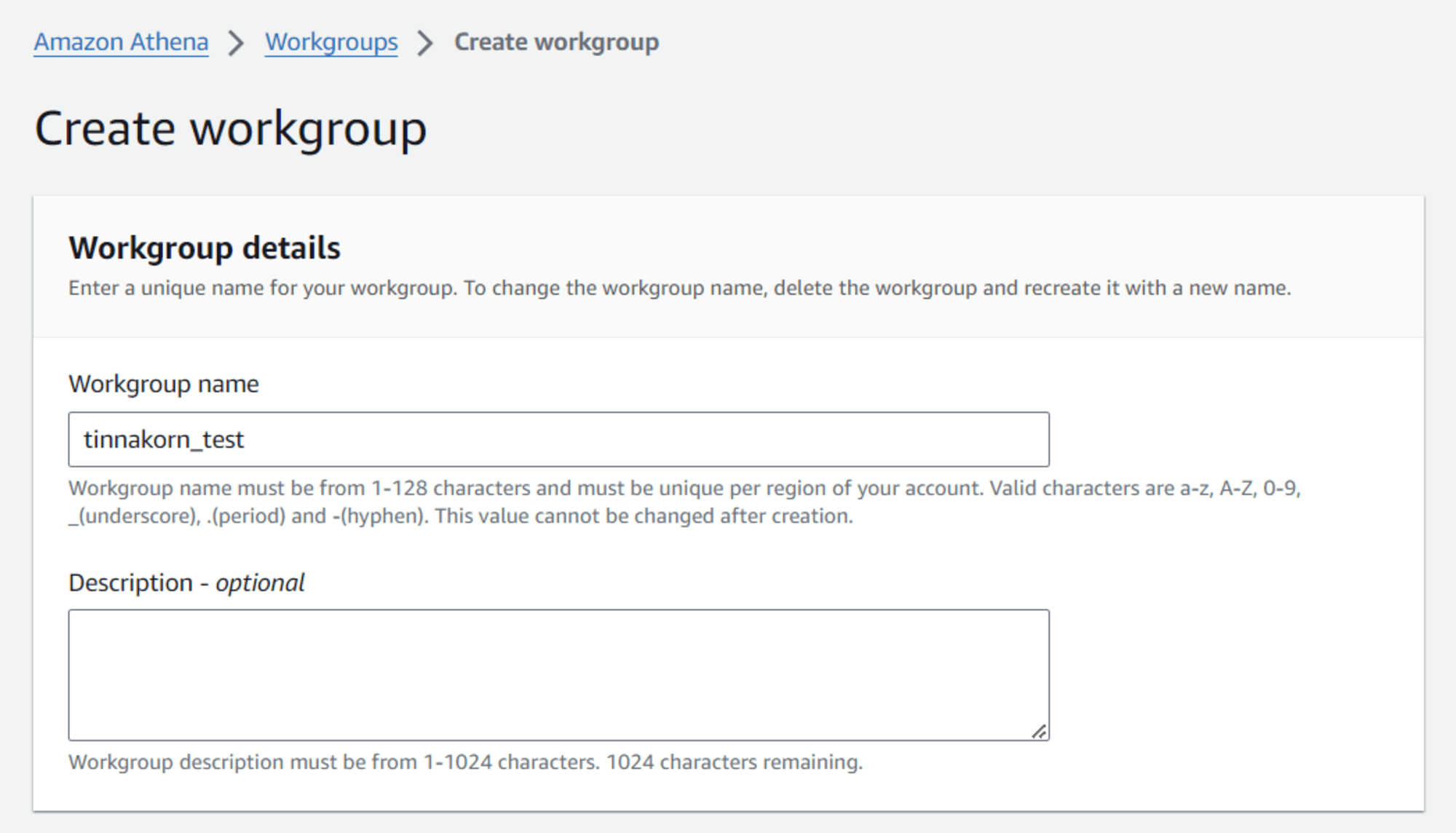
มาที่หัวข้อ Query result configuration คลิก Browse S3
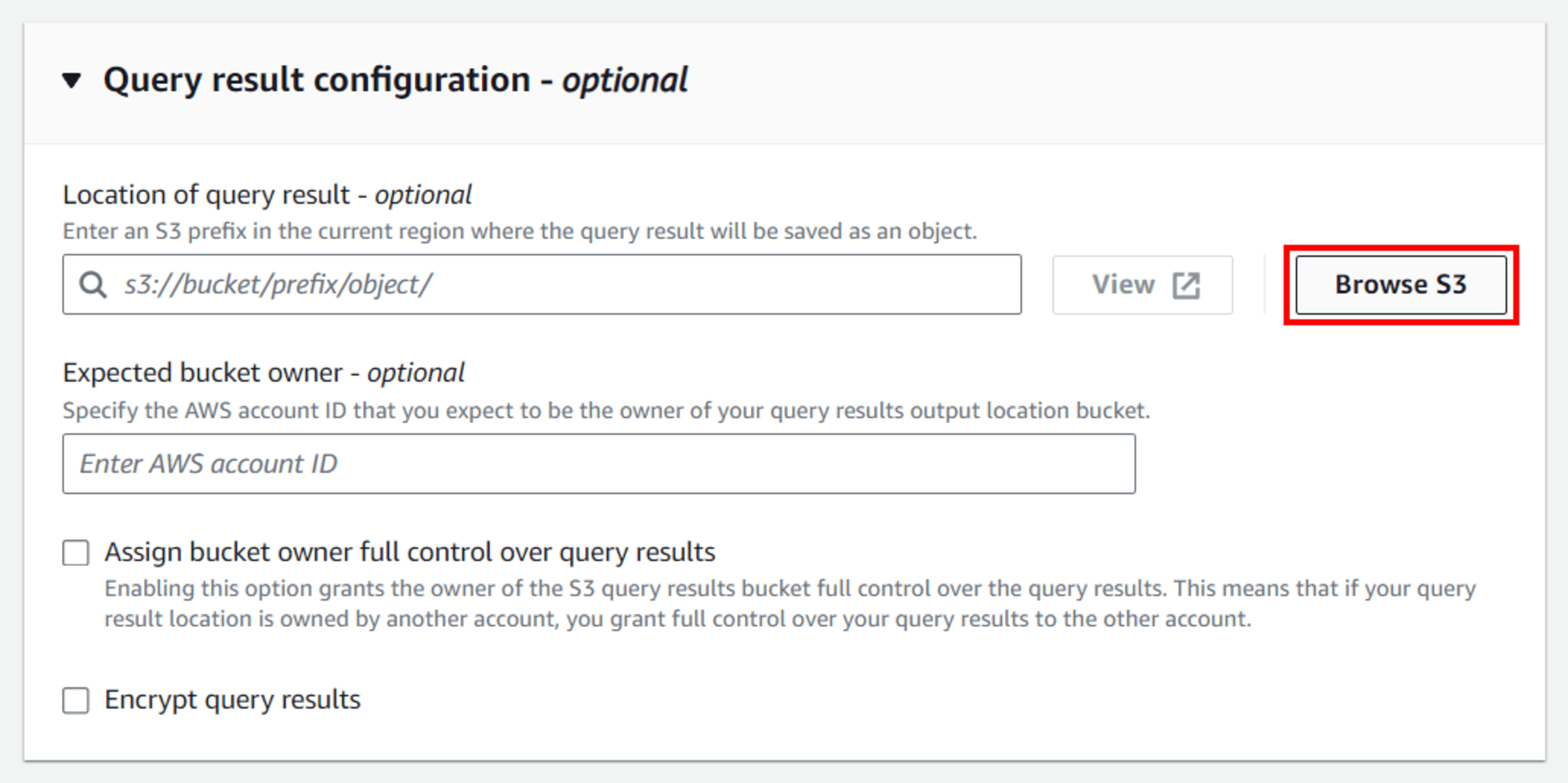
เลือก Bucket ของ Athena ที่สร้างไปเมื่อสักครู่นี้ ในบทความนี้คือ tinnakorn-test-athena-result และคลิก Choose
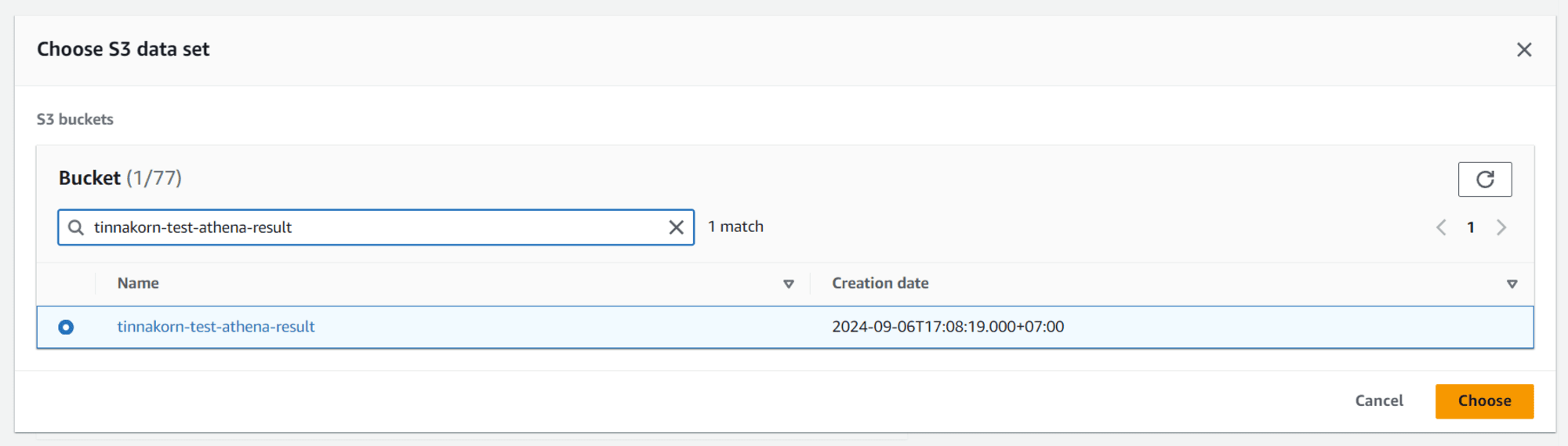
แล้วจะแสดง Location of query result แบบนี้ แล้วเลื่อนลงมาด้านล่างสุด คลิก Create workgroup
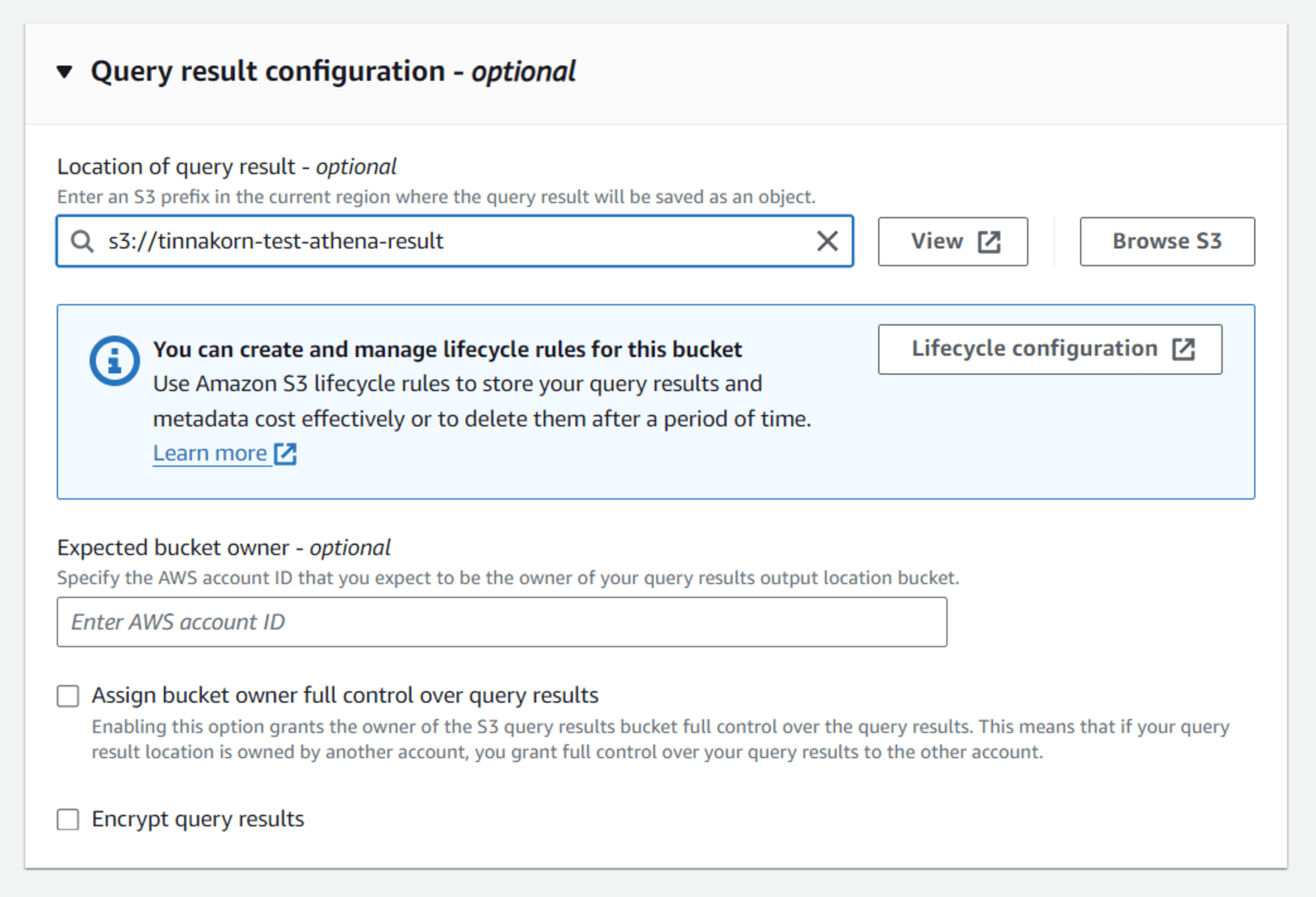
ตั้งค่า Query editor
เลือก Query editor จากเมนูด้านซ้าย แล้วมาที่มุมขวาบน เลือก Workgroup: tinnakorn-test
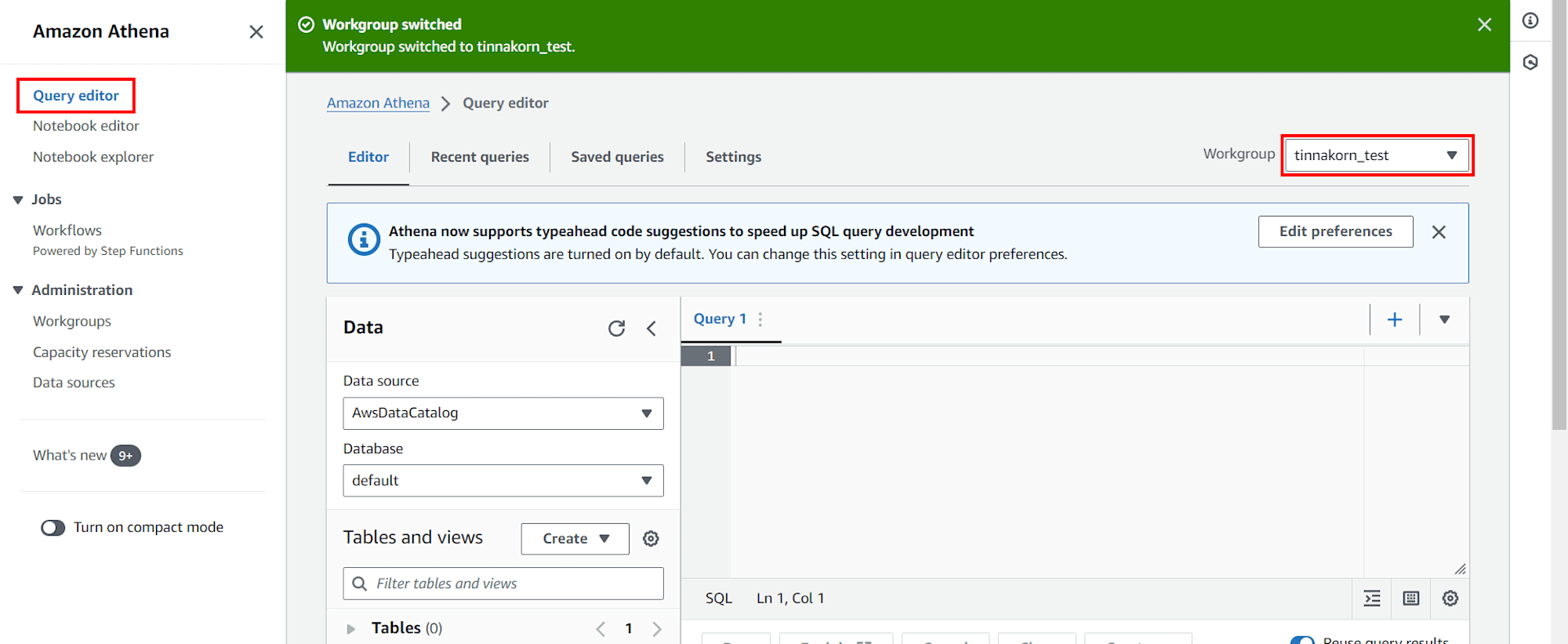
มาที่แท็บ Editor ดูที่ช่อง Data ด้านซ้าย แล้วตั้งค่าพื้นฐานดังนี้
・Data source: AwsDataCatalog (ค่าเริ่มต้น)
・Database: tinnakorn-test
・ดูที่ Table แล้วคลิก + ที่ชื่อของเรา คือต้องมี distance และ datatime แสดงอยู่ที่นี่แบบนี้
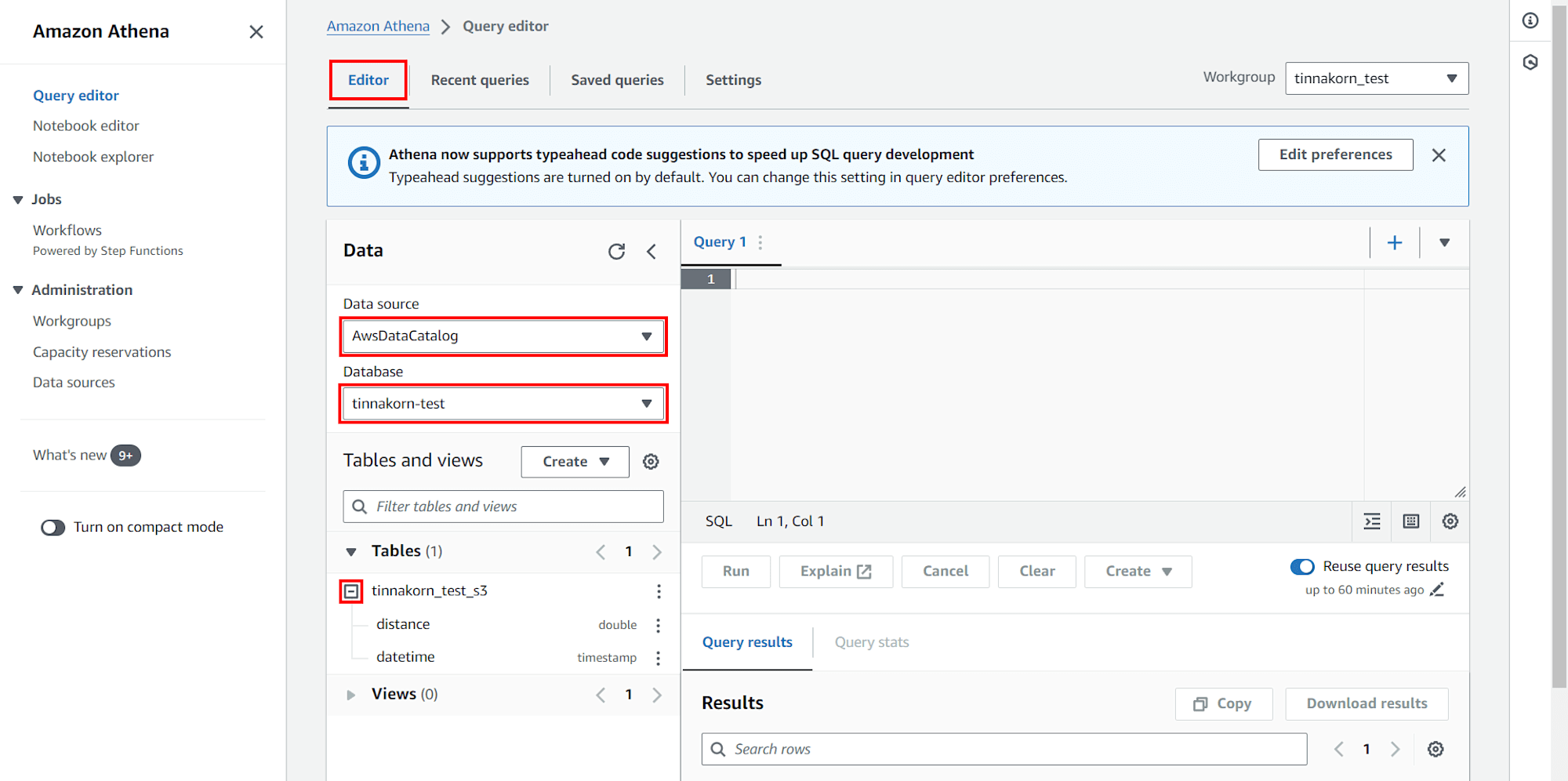
การใช้งาน SQL ใน Query editor
ขั้นตอนนี้ผมลองใช้งาน Query editor ในการรันคำสั่ง SQL เพื่อจัดการ Database ที่รวบรวมข้อมูลมาจาก S3 Bucket ที่เชื่อมต่อกับ EC2 ครับ
มาที่ช่อง Query1 ด้านขวา
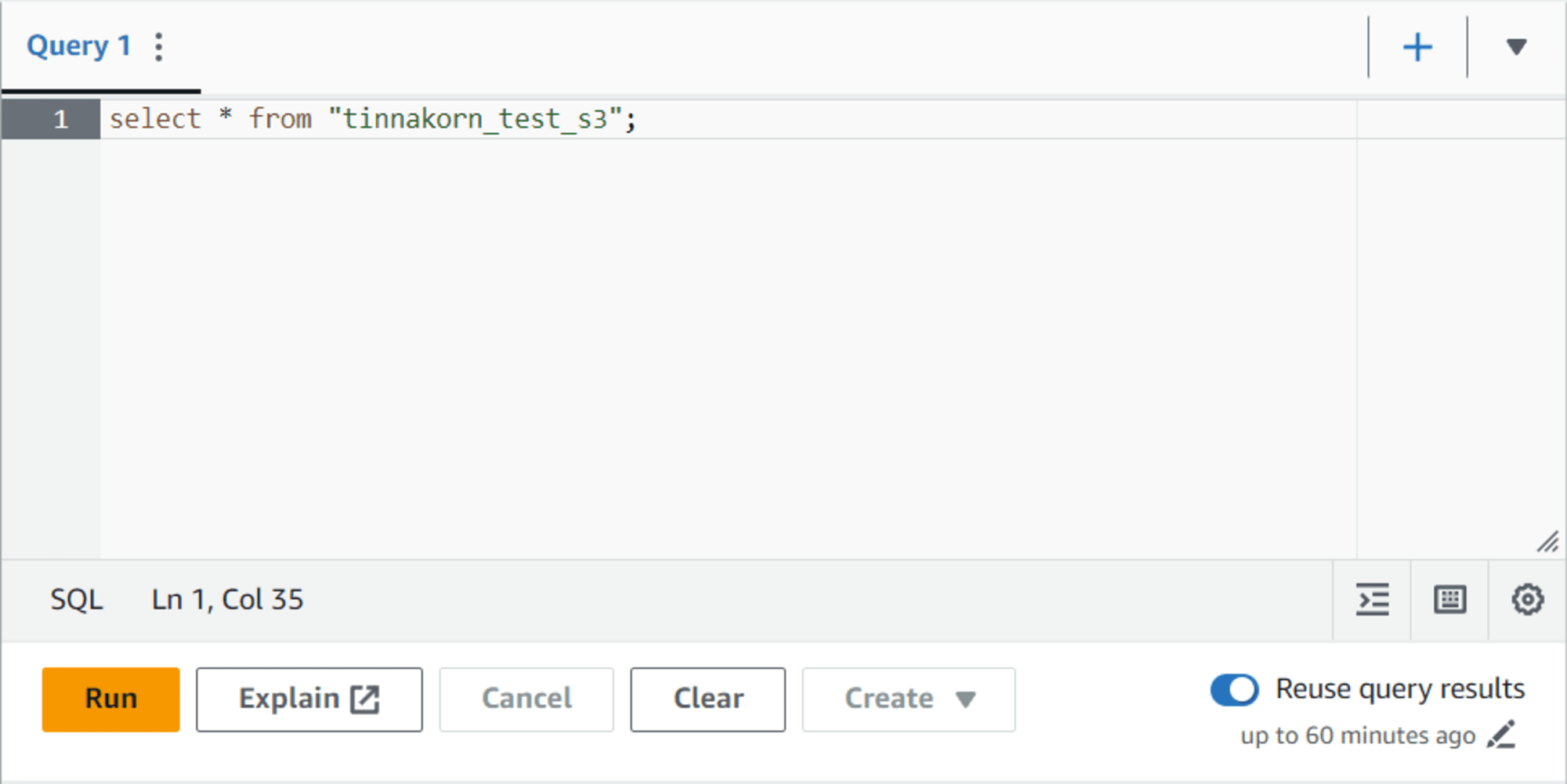
รันคำสั่งด้านล่างนี้และคลิกปุ่ม Run เพื่อเรียกดูข้อมูลใน S3
select * from "tinnakorn_test_s3";
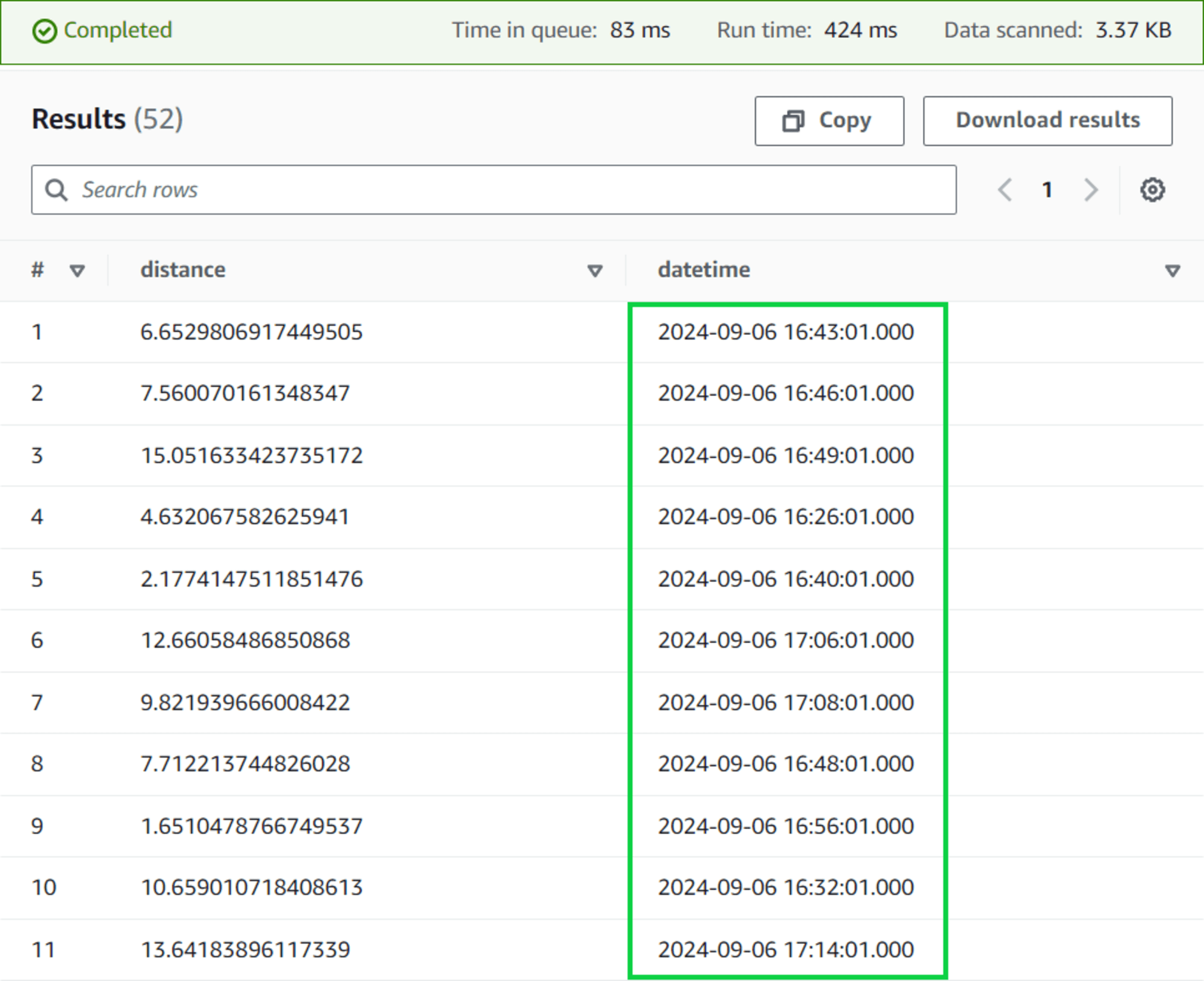
เลื่อนลงมาด้านล่างที่หัวข้อ Results จะเห็นข้อมูล JSON แสดงขึ้นมา
ให้สังเกตที่ datetime ซึ่งเวลาจะไม่เรียงให้
รันคำสั่งด้านล่างนี้และคลิกปุ่ม Run เพื่อเรียกดูข้อมูลใน S3 โดยเรียง datetime จากมากไปน้อย
select * from "tinnakorn_test_s3" order by datetime desc;
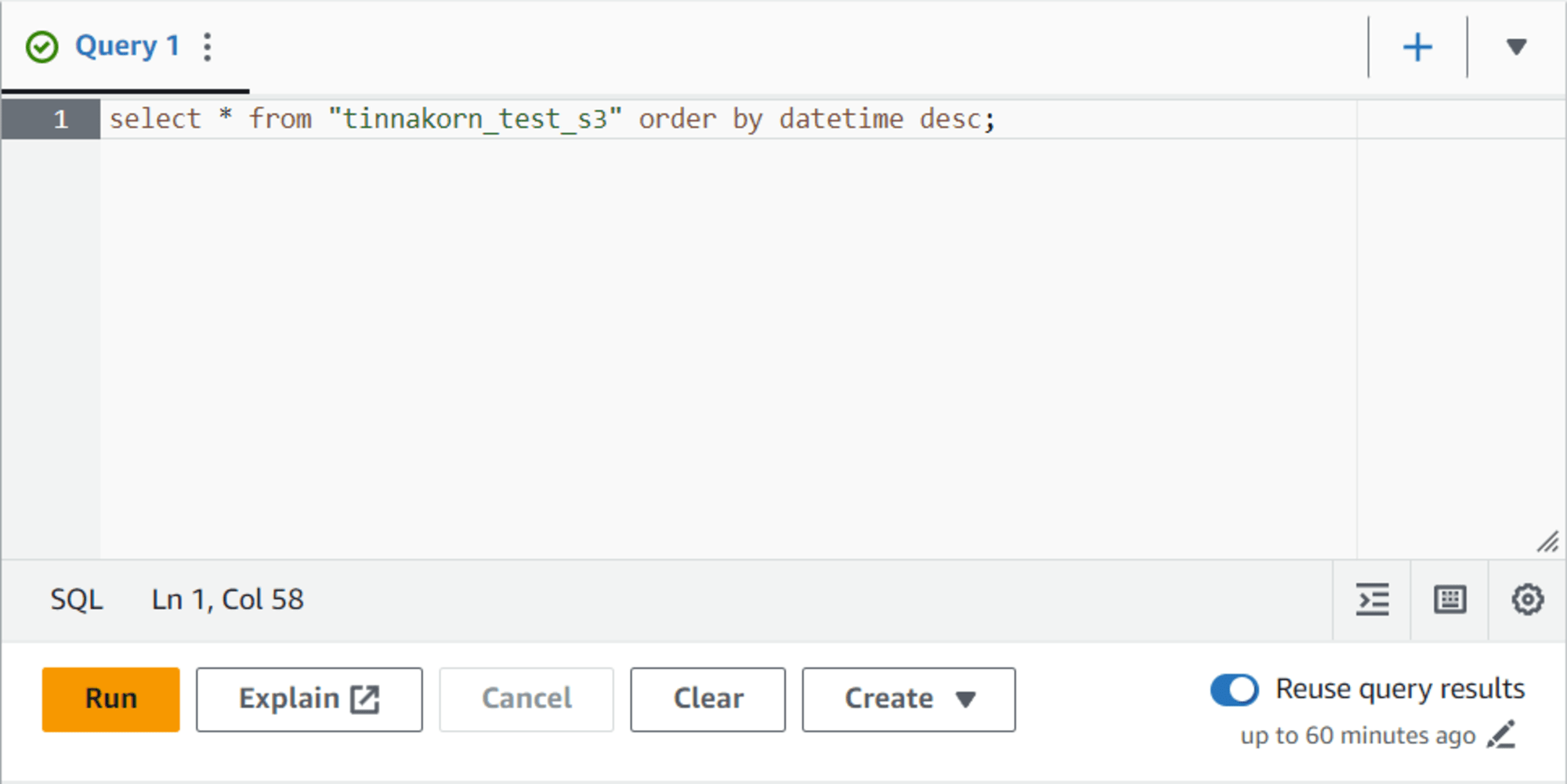
เลื่อนลงมาด้านล่างที่หัวข้อ Results จะเห็นข้อมูล JSON แสดงขึ้นมา
ให้สังเกตที่ datetime ซึ่งเวลาจะเรียงให้จากมากไปน้อย
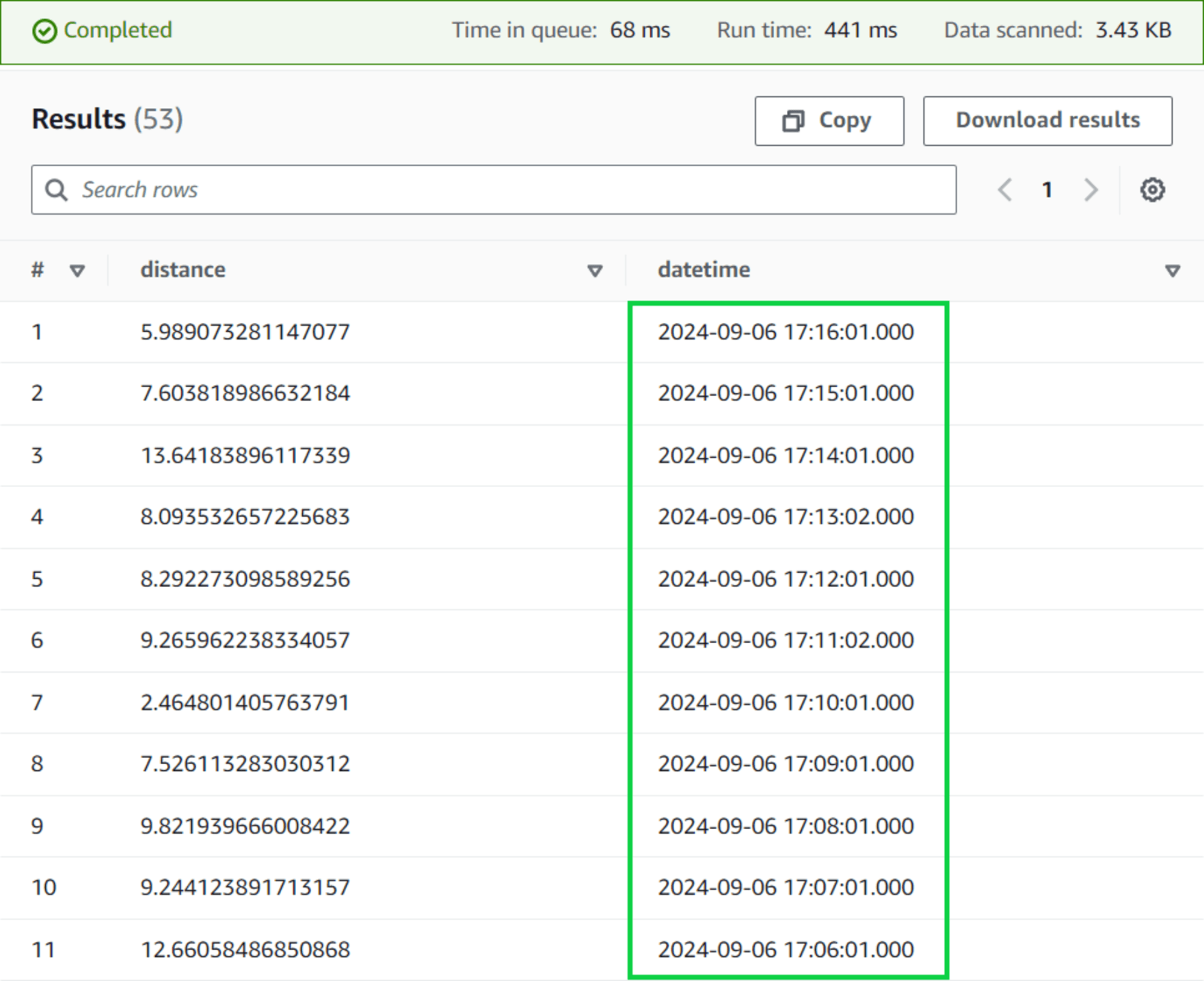
รันคำสั่งด้านล่างนี้และคลิกปุ่ม Run เพื่อตรวจสอบข้อมูล distance ที่ใหญ่ที่สุด
select max(distance) from "tinnakorn_test_s3";
แล้วเลื่อนลงมาด้านล่างที่หัวข้อ Results จะเห็นข้อมูล JSON แสดงขึ้นมา
ซึ่งจะแสดงข้อมูลที่ใหญ่ที่สุดของ distance
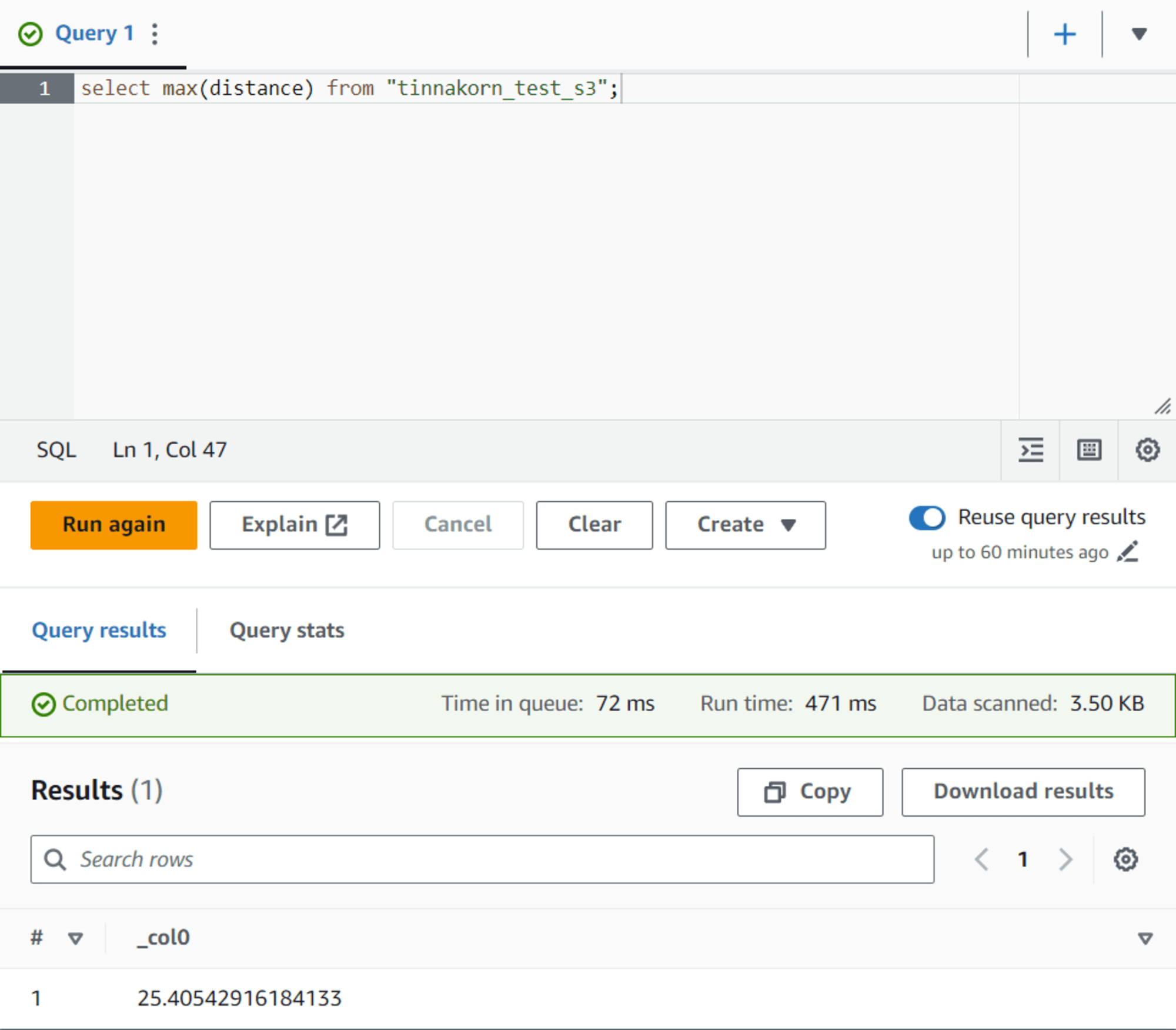
รันคำสั่งด้านล่างนี้และคลิกปุ่ม Run เพื่อดูข้อมูลของ S3 ทั้งหมดโดยการนับออกมาเป็นตัวเลข
select count(*) from "tinnakorn_test_s3";
แล้วเลื่อนลงมาด้านล่างที่หัวข้อ Results จะเห็นข้อมูล JSON แสดงขึ้นมา
ซึ่งเลข 56 นี้คือจำนวนไฟล์ที่นับได้ทั้งหมดในขณะที่ทำการตรวจสอบ
การทำงาน S3 Bucket สำหรับ Athena
เข้ามาที่ S3 Bucket ที่ใช้สำหรับ Athena ในตัวอย่างนี้คือ tinnakorn-test-athena-result
จะเห็นว่ามีไฟล์ .csv และ .csv.metadata อยู่
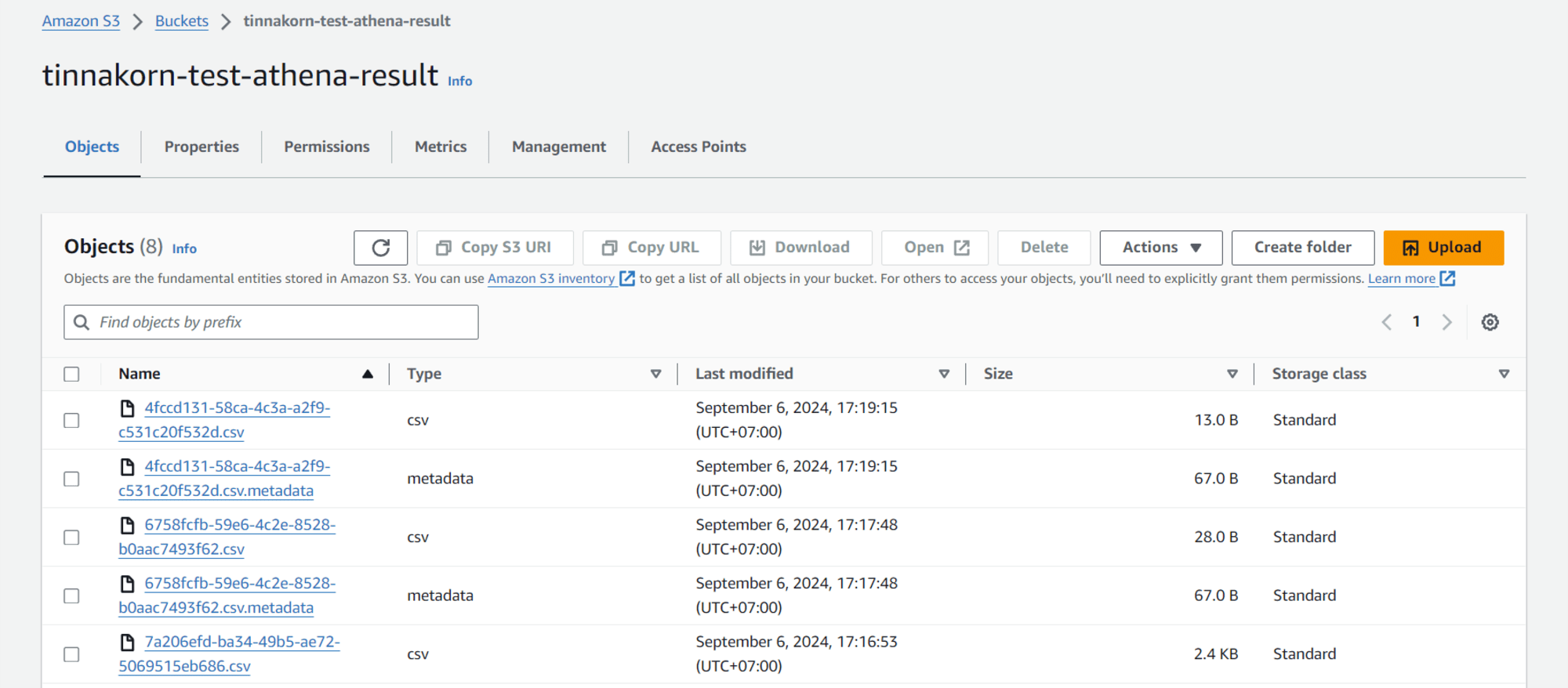
ขั้นตอนนี้จะดาวน์โหลดไฟล์ .csv มาดูข้อมูลข้างในโดยให้เลือกดาวน์โหลดในเวลาล่าสุดที่มีการรันคำสั่ง "count" ใน Athena ไปเมื่อสักครู่นี้
วิธีการดาวโหลดง่ายๆ เลย ให้ติ๊ก ✅ ไฟล์ที่ต้องการดาวน์โหลด และคลิกปุ่ม Download
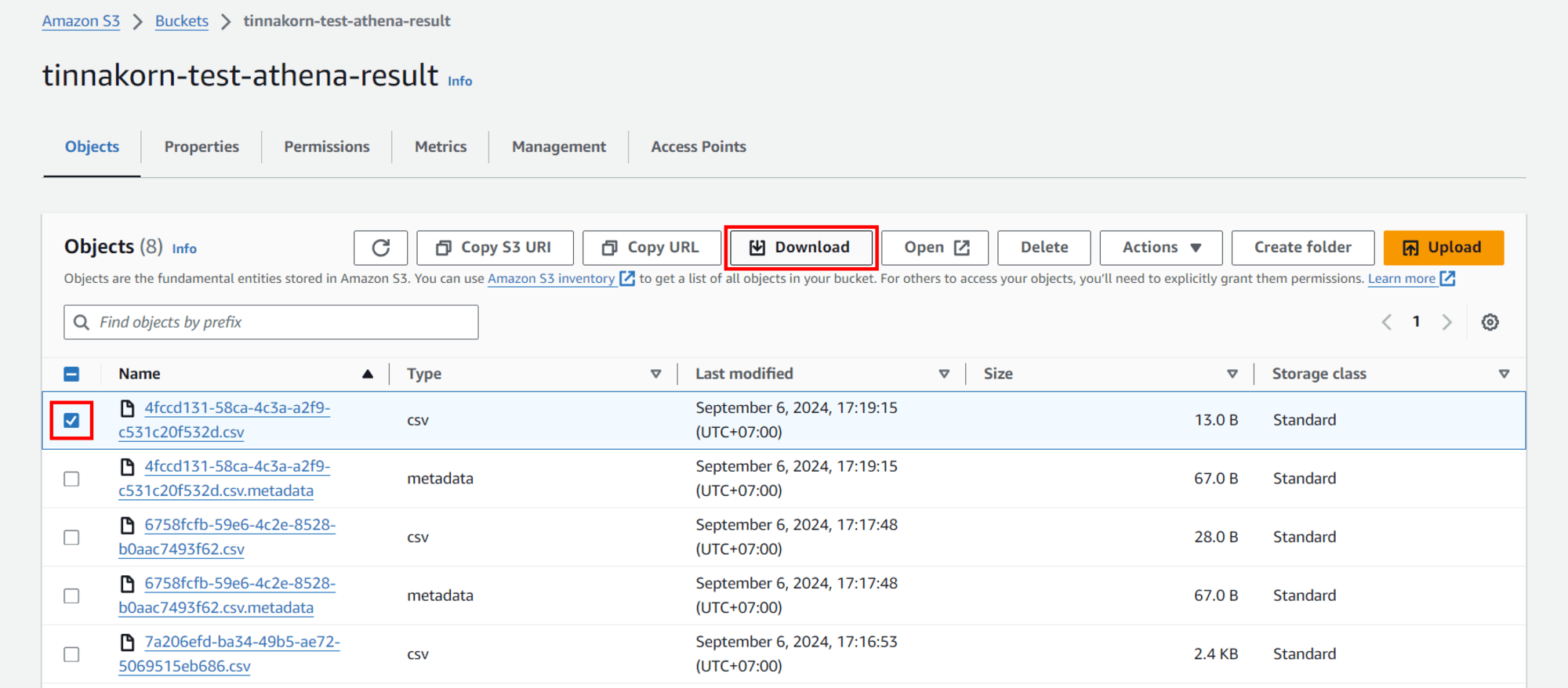
ลองเปิดไฟล์ .csv ขึ้นมา จะเห็นว่าเป็นผลลัพธ์ของการรันคำสั่ง count ไปเมื่อสักครู่นี้
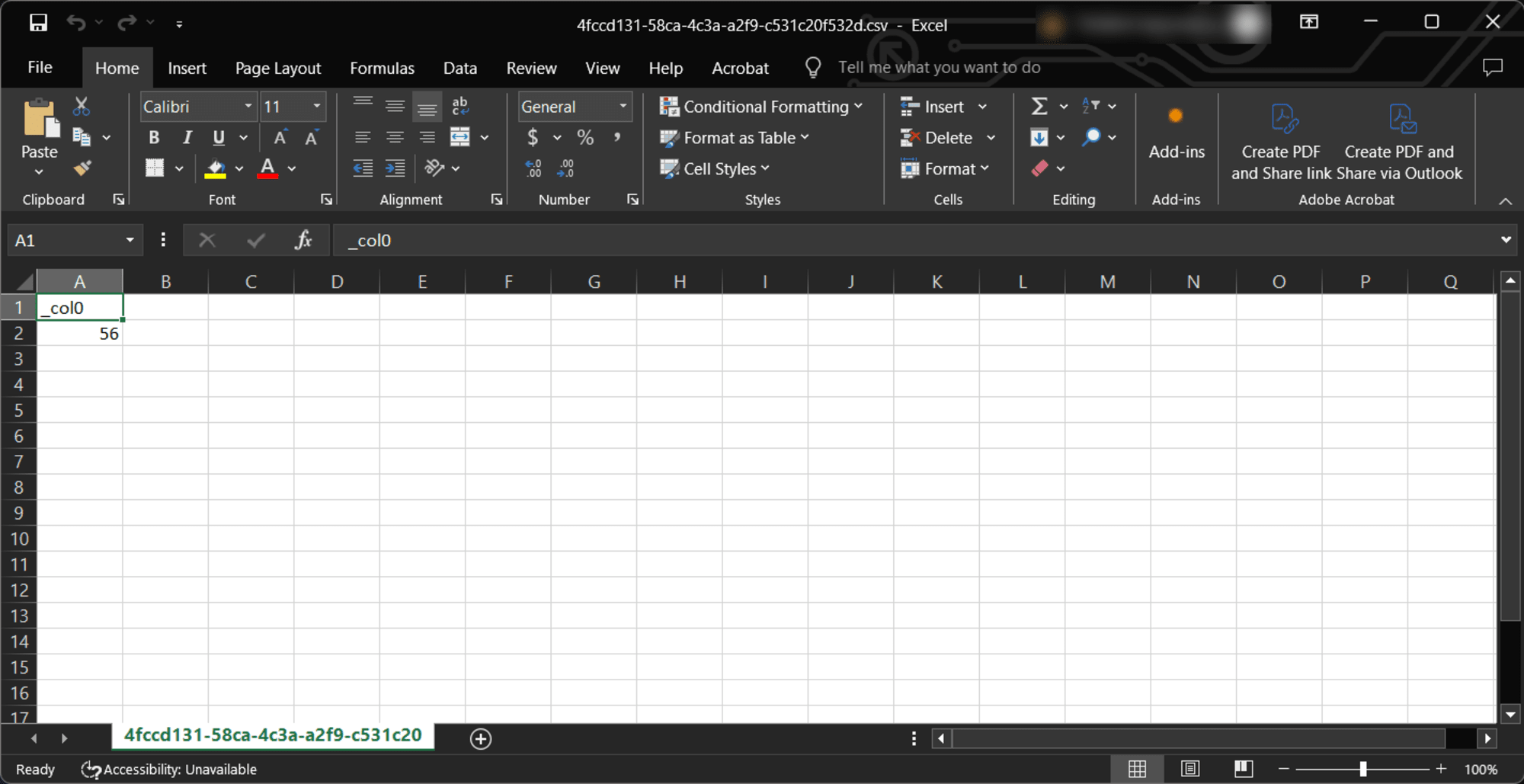
ไฟล์ต่อไปที่จะดาวน์โหลดคือไฟล์ .csv.metadata ให้ดาวน์โหลดเหมือนขั้นตอนที่แล้วโดยติ๊ก ✅ ไฟล์ที่ต้องการดาวน์โหลด และคลิกปุ่ม Download ได้เลย
ลองเปิดไฟล์ .csv.metadata ขึ้นมา จะเห็นว่าเป็น Log ที่เก็บข้อมูลของการรันคำสั่ง count ไปเมื่อสักครู่นี้
หมายเหตุ: ถ้าเปิดไฟล์ .csv.metadata ใน Notepad ของ Windows ตัวหนังสืออาจเป็นภาษาต่างดาว แนะนำให้โหลดโปรแกรม Downloads | Notepad++ นี้มาเปิดดู
ในส่วนของขั้นตอน 3 นี้ก็เสร็จเรียบร้อยแล้ว ผมจะทบทวนสิ่งที่ได้ทำมาจนถึงตอนนี้อีกครั้ง
- สิ่งที่ได้ทำไปแล้วในหัวข้อ 3. รัน SQL จาก Table ใน Amazon Athena
- สร้าง S3 Bucket เพื่อบันทึกข้อมูลการรันคำสั่งของ Athena
- สร้าง Workgroups ขึ้นมาเชื่อมต่อกับ S3 Bucket ที่ใช้สำหรับ Athena
- ตั้งค่า Query editor เพื่อเตรียมการรัน SQL สำหรับ Table
- ทดสอบการใช้งาน SQL ใน Query editor
ขั้นตอนการทำทั้งหมดของบทความนี้คือ การรัน SQL ไปยังไฟล์ใน S3 ด้วย Glue กับ Athena บน Amazon Linux 2023 ก็ได้สิ้นสุดลงที่หัวข้อนี้ครับ
หมายเหตุ: สำหรับคนที่ต้องการนำวิธีนี้ไปใช้งานต่อในบทความอื่นก็ไม่ต้องทำการลบ AWS Resource !
แต่ถ้าไม่ต้องการใช้งานแล้วให้ทำการลบโดยทำตามหัวข้อถัดไปได้เลยครับ
4. ลบ AWS Resource ที่สร้างขึ้นในบทความนี้
ลบ Resource ที่ได้สร้างขึ้นใน Service ต่างๆ
ลบตามลำดับดังนี้:
- Amazon EC2
- Key Pairs
- Instance
- Security Groups
- Amazon Athena
- Workgroups
- AWS Glue
- Databases
- Tables (หากลบ Databases ไปแล้ว Tables จะถูกลบไปด้วยโดยอัตโนมัติ)
- Crawlers
- Databases
- Amazon S3
- Buckets (2)
- AWS Identity and Access Management (IAM)
- Roles (2)
การลบฟังก์ชันใน Service ต่างๆ ถ้าเราไม่รู้ลำดับของการลบฟังก์ชันก็จะทำให้เกิด Error ในขณะลบ หรือไม่สามารถลบได้ เช่น ถ้าทำการลบ Security Group ที่กำลังเชื่อมต่ออยู่กับ EC2 โดยที่ไม่ Terminate Instance ก่อน ก็จะไม่สามารถลบ Security Group ได้เป็นต้น ดังนั้นแนะนำให้ลบตามลำดับที่ผมเรียงไว้ได้เลย
การ Terminate Instance, ลบ Key Pair และลบ Security Group ใน EC2
ดูตัวอย่างการลบที่นี่: การ Terminate Instance, ลบ Key Pair และลบ Security Group ใน EC2
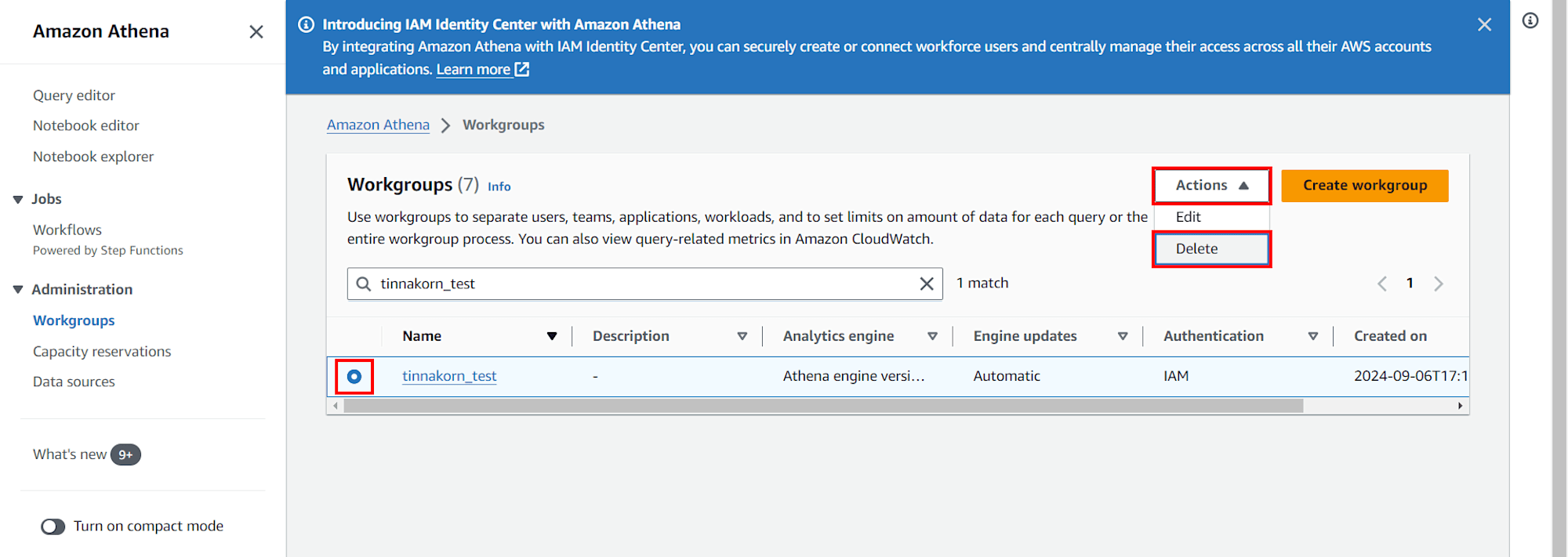
การลบ Workgroups ใน Amazon Athena
เข้ามาที่ 「 Service Athena » Workgroups 」 แล้วทำการลบ
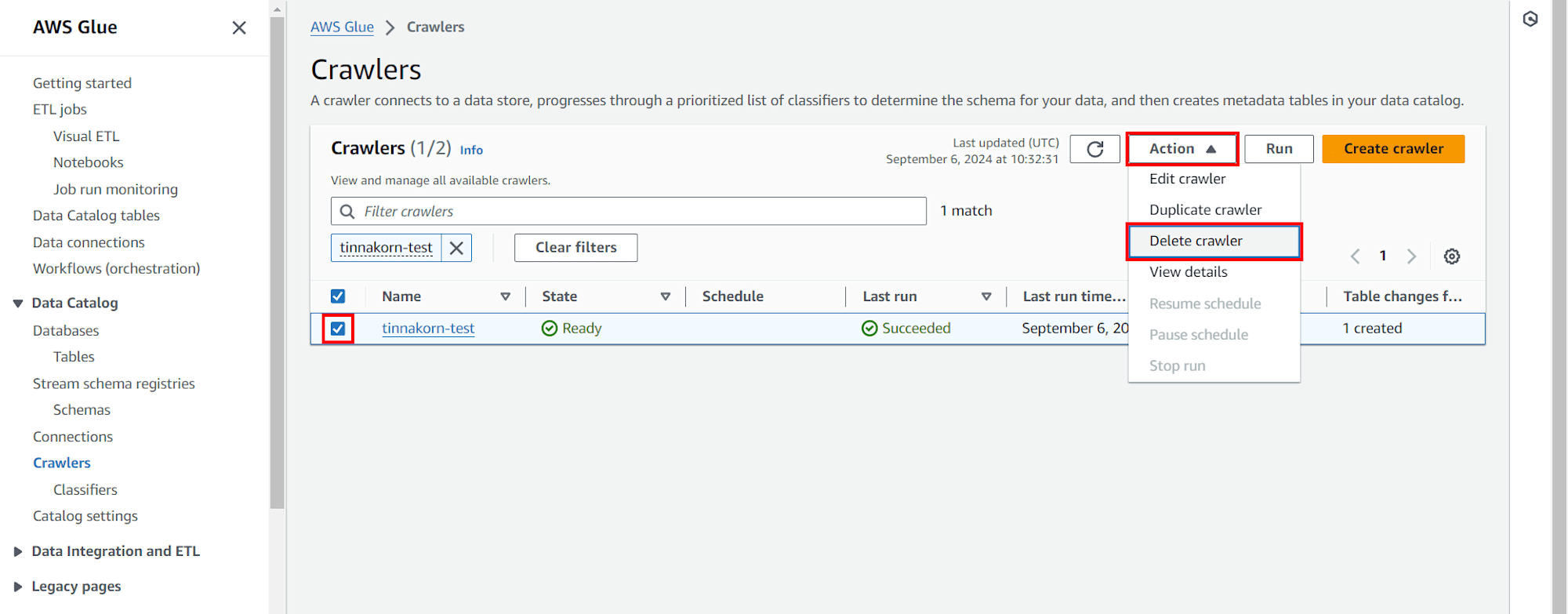
การลบ Crawlers และ Databases ใน AWS Glue
※Crawlers
เข้ามาที่ 「 Service AWS Glue » Crawlers 」 แล้วทำการลบ
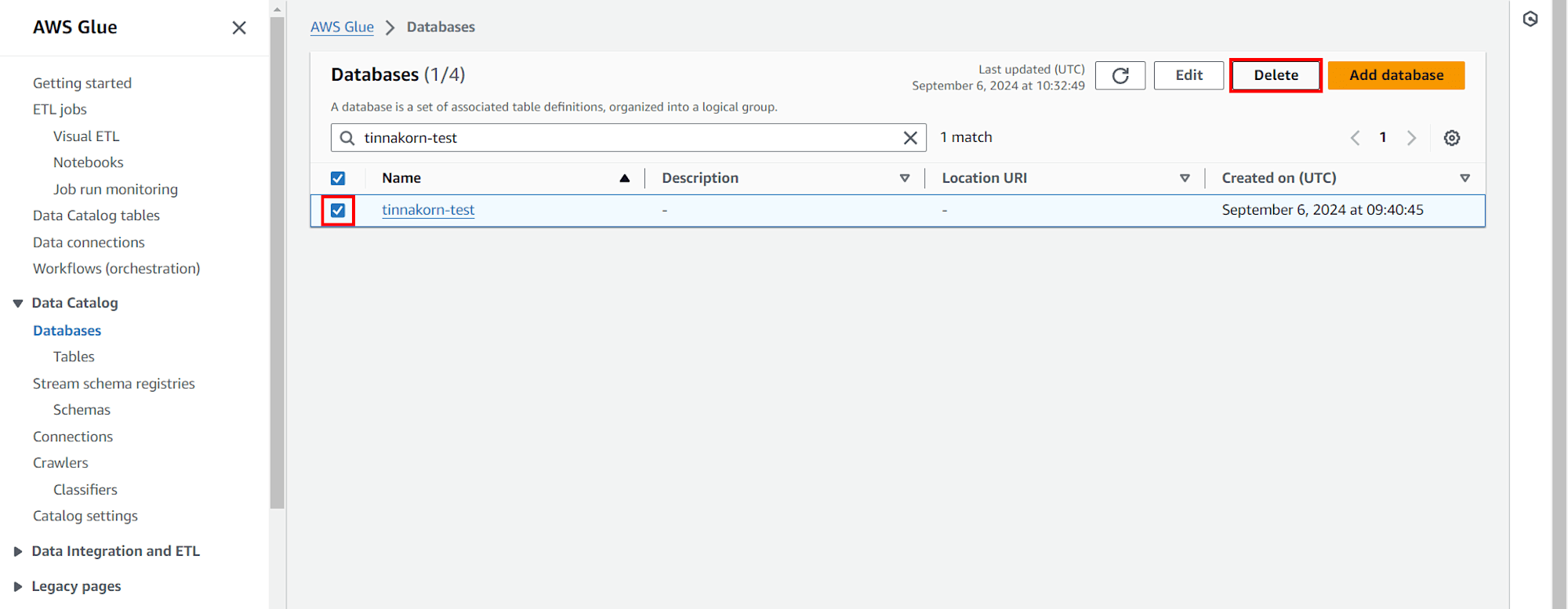
※Databases
เข้ามาที่ 「 Service AWS Glue » Databases 」 แล้วทำการลบ (เมื่อลบเสร็จแล้ว Tables ก็จะถูกลบไปด้วยโดยอัตโนมัติ)
การลบ Buckets ใน Amazon S3
การลบ Buckets นี้ต้องลบออกทั้งหมด 2 อัน ซึ่งจะมี Bucket ที่ใช้กับ EC2 และ Athena ครับ
ดูตัวอย่างการลบที่นี่: การลบ Buckets ใน Amazon S3
การลบ Role และ Policies ใน IAM
การลบ Role นี้ต้องลบออกทั้งหมด 2 อัน ซึ่งจะมี Role ที่ใช้กับ EC2 และ AWS Glue ครับ
ดูตัวอย่างการลบที่นี่: การลบ Role และ Policies ใน IAM
สรุป
การสาธิตครั้งนี้เป็นการอธิบายโดยจะเน้นมาที่การใช้งาน Service AWS Glue และ Athena เป็นหลัก
AWS Glue มีหน้าที่ในการค้นหา จัดเตรียม และรวมข้อมูลสำหรับการวิเคราะห์ โดยการผสานรวมข้อมูลที่เรียบง่าย ปรับขนาดได้ และไร้เซิร์ฟเวอร์ ซึ่งผมได้นำมาใช้กับ Service Athena และ S3 ในครั้งนี้ครับ
Amazon Athena มีหน้าที่ในการสืบค้นแบบโต้ตอบที่ช่วยให้ง่ายต่อการวิเคราะห์ข้อมูลใน Amazon S3 โดยใช้ SQL มาตรฐาน Athena ไร้เซิร์ฟเวอร์ ซึ่งผมได้นำมาใช้งานกับ Service AWS Glue และ S3 โดยการรันคำสั่ง SQL เพื่อเรียกดูข้อมูลใน S3 ครับ
การใช้งานโดยรวมคือ AWS Glue สามารถค้นหา วิเคราะห์ข้อมูลใน S3 เพื่อตัดสินใจในการผสานรวมข้อมูลหรือสร้างตารางออกมาตามรูปแบบของฐานข้อมูลของ S3 อย่างรวดเร็ว และ Athena ก็สามารถจัดการฐานข้อมูลโดยการรันคำสั่ง SQL ที่ได้รับการผสานรวมข้อมูลมาจาก AWS Glue ได้อย่างรวดเร็วเช่นเดียวกันครับ













