
【S3 Tables】メンテナンスジョブのファイル圧縮について調べてみよう
データ事業本部の川中子(かわなご)です。
以前S3 Tablesにおけるメンテナンスジョブのスナップショット削除の挙動について調べたのですが、
今回は追加でファイルコンパクションや非参照ファイルの削除の挙動について調べてみました。
以前の記事はこちらをご覧ください。
結論
最初に今回の検証で分かった内容についてまとめておきます。
icebergcompactionはデータファイル数が5つ以上のときに実行されるicebergcompaction実行の閾値を変更する方法は確認できなかった
unreferencedfileremovalの詳細な挙動については確認できなかった
検証準備
検証用のテーブル
今回の検証用に、S3 Tables上に2つのテーブルを作成しました。
tbl_physcl_dlttbl_physcl_dlt_mtdt
tbl_physcl_dltには定期的に1,000行のデータを格納し、その後約半分のデータを削除します。
スナップショットやデータファイルは、INSERTとDELETEの操作ごとに生成されます。
tbl_physcl_dlt_mtdtには tbl_physcl_dltのメタデータ関連の情報や、
メンテナンスジョブの実行履歴を定期的に格納します。
検証用のLambda
次に検証に使用するLambdaを作成しました。
処理は大まかに2点で、4時間ごとにテーブルにINSERTとDELETEを実行し、
その直後にメタデータを別テーブルに格納しています。
- 以下を4時間ごとに実行
tbl_physcl_dltに1,000行のデータをINSERTcol_2列の値が400以下の行であることを条件にDELETEを実行get-table-maintenance-configurationを実行し、結果をtbl_physcl_dlt_mtdtに格納
具体的なソースコードは以下に置いておきます。
Lambdaでpyicebergなどのライブラリを使用する方法については以下ブログを参考にしています。
lambda_function.py
import time
import boto3
import random
import string
import pyarrow as pa
import datetime as dt
from pyiceberg.catalog import load_catalog
# S3 Tablesカタログの読み込み関数
def init_rest_catalog(
s3table_bucket_name, account_id, region, catalog_name="S3TablesCatalog"
):
return load_catalog(
catalog_name,
**{
"type": "rest",
"warehouse": f"{account_id}:s3tablescatalog/{s3table_bucket_name}",
"uri": f"https://glue.{region}.amazonaws.com/iceberg",
"rest.sigv4-enabled": "true",
"rest.signing-name": "glue",
"rest.signing-region": region,
},
)
# ランダムな文字列を生成
def randstr(n):
randlst = [random.choice(string.ascii_letters) for i in range(n)]
return "".join(randlst)
def lambda_handler(event, context):
# 現在の日本時刻を取得
td = dt.timedelta(hours=9)
now_jst = dt.datetime.now() + td
# ================================================
# カタログ読み込み用の変数
region = "ap-northeast-1"
account_id = "123456789012"
s3table_bucket_name = "table-bucket-name"
# テーブル作成先のネームスペースとテーブル名
database_name = "name_space_name"
table_name = "tbl_physcl_dlt"
mttable_name = "tbl_physcl_dlt_mtdt"
# ================================================
# カタログを読み込み
catalog = init_rest_catalog(s3table_bucket_name, account_id, region)
# テーブルを読み込み
tbl = catalog.load_table(f"{database_name}.{table_name}")
mttbl = catalog.load_table(f"{database_name}.{mttable_name}")
# ================================================
# ダミーデータの投入と削除
# ================================================
# ランダム文字列と乱数で1000行分のデータを作成
dm_dict = {"col_1": [], "col_2": [], "col_3": []}
for i in range(1000):
dm_dict["col_1"].append(randstr(12))
dm_dict["col_2"].append(random.randint(1, 999))
dm_dict["col_3"].append(random.choice([True, False]))
# データをテーブルに変換してINSERT
schema = pa.schema(
[
pa.field("col_1", pa.string(), nullable=True),
pa.field("col_2", pa.int32(), nullable=True),
pa.field("col_3", pa.bool_(), nullable=True),
]
)
padf = pa.Table.from_pydict(dm_dict, schema=schema)
tbl.append(padf)
# col_2が400以下の行を削除する
# tbl.delete(delete_filter="col_2 <= 400")
# pyicebergから実行するとMoRは対応してなかったため、Athenaで実行
athena_client = boto3.client("athena")
athena_client.start_query_execution(
QueryString=f"delete from tbl_physcl_dlt where col_2 <= 400;",
QueryExecutionContext={
"Catalog": f"s3tablescatalog/{s3table_bucket_name}",
"Database": database_name,
},
ResultConfiguration={"OutputLocation": "s3://bucket_name"},
WorkGroup="workgroup_name",
)
# Athenaのクエリ実行に時間がかかる可能性があるのでスリープ
# 本当はポーリングした方がいい
time.sleep(60)
# テーブルの最新の状態を取得
tbl = catalog.load_table(f"{database_name}.{table_name}")
# ================================================
# メタデータを取得と格納
# ================================================
# メタデータ用の辞書
mt_dict = {}
# 全ファイルのファイルサイズ合計を取得
files = tbl.inspect.files().to_pydict()
mt_dict["files_size"] = [sum(files["file_size_in_bytes"])]
# データファイルのファイル数とファイルサイズ合計を取得
data_files = tbl.inspect.data_files().to_pydict()
mt_dict["data_files_count"] = [len(data_files["content"])]
mt_dict["data_files_size"] = [sum(data_files["file_size_in_bytes"])]
# 削除ファイルのファイル数とファイルサイズ合計を取得
delete_files = tbl.inspect.delete_files().to_pydict()
mt_dict["delete_files_count"] = [len(delete_files["content"])]
mt_dict["delete_files_size"] = [sum(delete_files["file_size_in_bytes"])]
# スナップショット数を取得
mt_dict["snapshots_count"] = [len(tbl.snapshots())]
# メンテンスジョブの履歴を取得
s3tbl_client = boto3.client("s3tables")
response = s3tbl_client.get_table_maintenance_job_status(
tableBucketARN=f"arn:aws:s3tables:{region}:{account_id}:bucket/{s3table_bucket_name}",
namespace=database_name,
name=table_name,
)
# メンテナンスジョブのレスポンスからタイムスタンプを取得
for k, v in response["status"].items():
try:
# 最終実行時日時を日本時間に変換
ts_jst = v["lastRunTimestamp"] + td
ts_jst_str = dt.datetime.strftime(ts_jst, "%Y-%m-%d %H:%M:%S")
except:
# 取得できなかった場合
ts_jst_str = "Not_Yet_Run"
# カラムと日時の値を格納
mt_dict[k.lower()] = [ts_jst_str]
# 実行時刻を格納
mt_dict["timestamp"] = [now_jst.strftime("%Y-%m-%d %H:%M:%S")]
# メタデータ情報を格納
mt_schema = pa.schema(
[
pa.field("files_size", pa.int32(), nullable=True),
pa.field("data_files_count", pa.int32(), nullable=True),
pa.field("data_files_size", pa.int32(), nullable=True),
pa.field("delete_files_count", pa.int32(), nullable=True),
pa.field("delete_files_size", pa.int32(), nullable=True),
pa.field("snapshots_count", pa.int32(), nullable=True),
pa.field("icebergcompaction", pa.string(), nullable=True),
pa.field("icebergunreferencedfileremoval", pa.string(), nullable=True),
pa.field("icebergsnapshotmanagement", pa.string(), nullable=True),
pa.field("timestamp", pa.string(), nullable=True),
]
)
mt_padf = pa.Table.from_pydict(mt_dict, schema=mt_schema)
mttbl.append(mt_padf)
return {"status_code": 200, "results": mt_dict}
メンテナンスジョブの設定を変更する
メンテナンスジョブは以下の要件を満たすように設定しておきます。
- スナップショットの最低保持数は3つ(
minSnapshotsToKeep) - 生成から1時間以上経過しているスナップショットは削除対象(
maxSnapshotAgeHours) - テーブルから参照されない状態で2日経ったら非最新ファイルとしてマーク(
unreferencedDays) - 非最新ファイルになってから1日経過したらファイルを削除(
nonCurrentDays)
aws s3tables put-table-maintenance-configuration \
--table-bucket-arn arn:aws:s3tables:{region}:{acountID}:bucket/{tablebucketname} \
--namespace kawanago_namespace \
--name tbl_physcl_dlt \
--type icebergSnapshotManagement \
--value '{"status":"enabled","settings":{"icebergSnapshotManagement":{"minSnapshotsToKeep":3,"maxSnapshotAgeHours":1}}}'
aws s3tables put-table-bucket-maintenance-configuration\
--table-bucket-arn arn:aws:s3tables:{region}:{accountID}:bucket/{tablebucketname} \
--type icebergUnreferencedFileRemoval \
--value '{"status":"enabled","settings":{"icebergUnreferencedFileRemoval":{"unreferencedDays":2,"nonCurrentDays":1}}}'
メンテナンスジョブの詳細については以下のドキュメントを参照してください。
結果を見てみる
icebergcompactionの挙動
数日後に結果のテーブルを見てみると、ファイル数が一定のタイミングで減少していることが分かります。
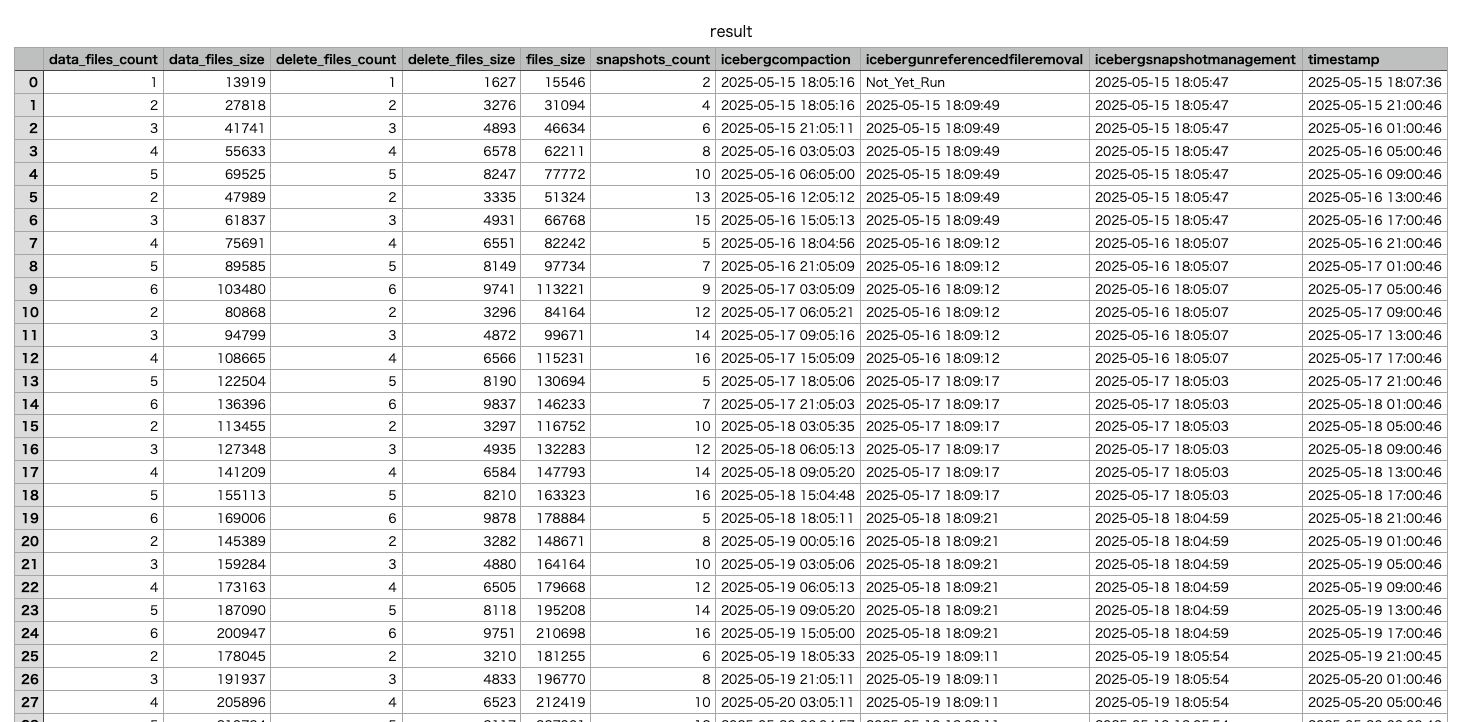
テーブルだと全体が把握しづらいので、今回もグラフで描画してみました。
x軸にデータ連携やメンテナンスが発生した時刻、y軸はその時点でテーブルが持っているデータファイル数を描画してます。
x軸下部にある点はそれぞれメンテナンスジョブの実行時点を示しています。
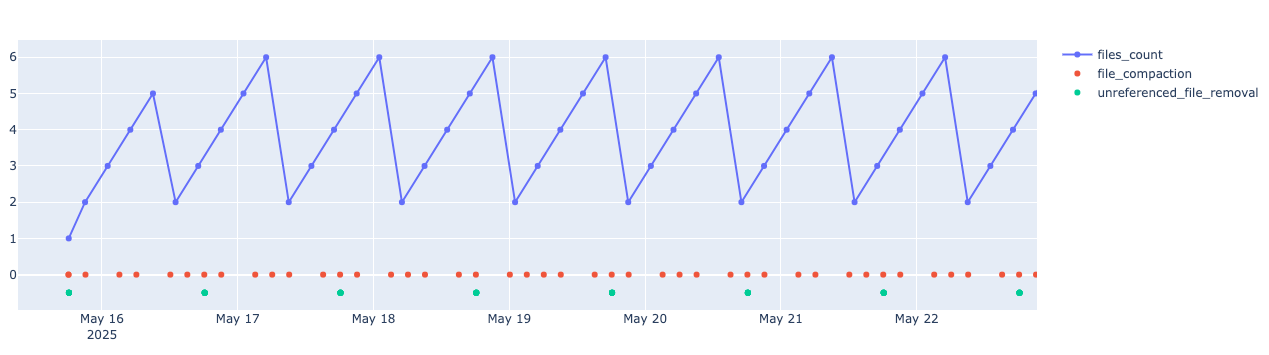
icebergcompactionは以前調べたときと同様に3時間ごとに実施されていて、
データファイル数が5つを超えているときにファイルの圧縮が実行されているようでした。
画像には削除ファイルの数は表示していませんが、削除ファイルについても全く同じグラフになっていました。
icebergcompactionのタイミングを制御できるか検証
今のままだとトランザクションが5回発生しない限り削除データがマージされないため、
icebergcompactionが実行される条件のファイル数を制御できないか確認してみました。
Icebergテーブルのプロパティの設定を参考に、以下の2つを設定してみました。
- optimize_rewrite_data_file_threshold:データファイル用の設定値
- optimize_rewrite_delete_file_threshold:データ削除ファイル用の設定値
Athenaから以下を実行して、テーブルプロパティに設定されていることを確認しました。
ALTER TABLE tbl_physcl_dlt SET TBLPROPERTIES (
'optimize_rewrite_data_file_threshold'='3',
'optimize_rewrite_delete_file_threshold'='3'
);
SHOW TBLPROPERTIES `tbl_physcl_dlt`;
-- 以下出力
write_compression zstd
optimize_rewrite_delete_file_threshold 3
optimize_rewrite_data_file_threshold 3
上記の設定は23日の日中に実行したのですが、結果的にicebergcompactionの頻度は変わりませんでした。
どうやらS3 Tablesではどちらもデフォルトで5に設定されていて、変更はできないようです。
unreferencedfileremovalの挙動について
また今回の検証ではunreferencedfileremovalの挙動についても調べるつもりだったのですが、
S3Tablesでは管理されているメタデータファイルがユーザーの触れないところで管理されるため、
詳細な非参照ファイル削除のタイミングを追うことができませんでした。
S3 Tablesでは、削除されたスナップショットに紐づいているメタデータはその時点でマーキングされ、
マーキングされたオブジェクトを復旧する場合はAWSサポートに依頼する必要があります。
最新でないとマークされたオブジェクトを表示または復旧するには、AWS サポート に連絡する必要があります。
AWS サポート へのお問い合わせの詳細については、AWS サポート ドキュメントの「AWS へのお問い合わせ」を参照してください。
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/userguide/s3-table-buckets-maintenance.html
あくまでもS3 Tablesにおいてはメタデータファイルの管理はマネージドのため、
unreferencedfileremovalはコスト管理を目的とした機能ということになりそうです。
さいごに
今回はS3 Tablesにおけるicebergcompactionの仕様について検証してみました。
結果的にicebergcompactionは3時間ごと、ファイル数が5つ以上の場合に実行 され、
その 閾値については変更ができない 仕様であることが分かりました。
ただあくまでも私の検証範囲内であり、公式ドキュメントに記載のある内容ではない点にご留意ください。
以上、S3 Tablesのメンテナンスジョブの仕様検証でした。
少しでも参考になれば幸いです、最後まで閲覧頂きありがとうございました。










