
【S3 Tables】ローカルのVSCodeからS3 Tables上のIcebergテーブルを触りたい
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ事業本部の川中子(かわなご)です。
まだまだGAされてから日が浅いS3 Tablesですが、皆さんもう触ってみたでしょうか。
自動メンテナンス機能が使えたり、メタデータファイルの管理の手間が減らせるのでとても便利です。
色々検証を進める中で、もう少し手軽にテーブル操作ができたら楽だなぁと思っていたのですが、
ちょうど良いタイミングで笠原さんがこんな記事を上げてくれていました。
今回はこの記事の内容をもとに、VSCodeのノートブックから操作してみました。
かなり手軽にS3 Tablesの検証ができるようになるので、参考になれば幸いです。
はじめに
今回の内容は、AWSの方から出ていたPyIcebergを使ったテーブル操作のブログが元になっています。
私はPyIcebergを触ったことがなかったのですが、今回軽く触ってみただけでも、
直感的にカタログの読み込みやテーブルの操作ができたので敷居は低いと思います。
PyIcebergの導入については以下の記事を参照下さい。
やってみる
以下は私が実際にノートブック上で実行していたコードを順にあげていきます。
細かいところについてはご自身の環境に合わせて修正して下さい。
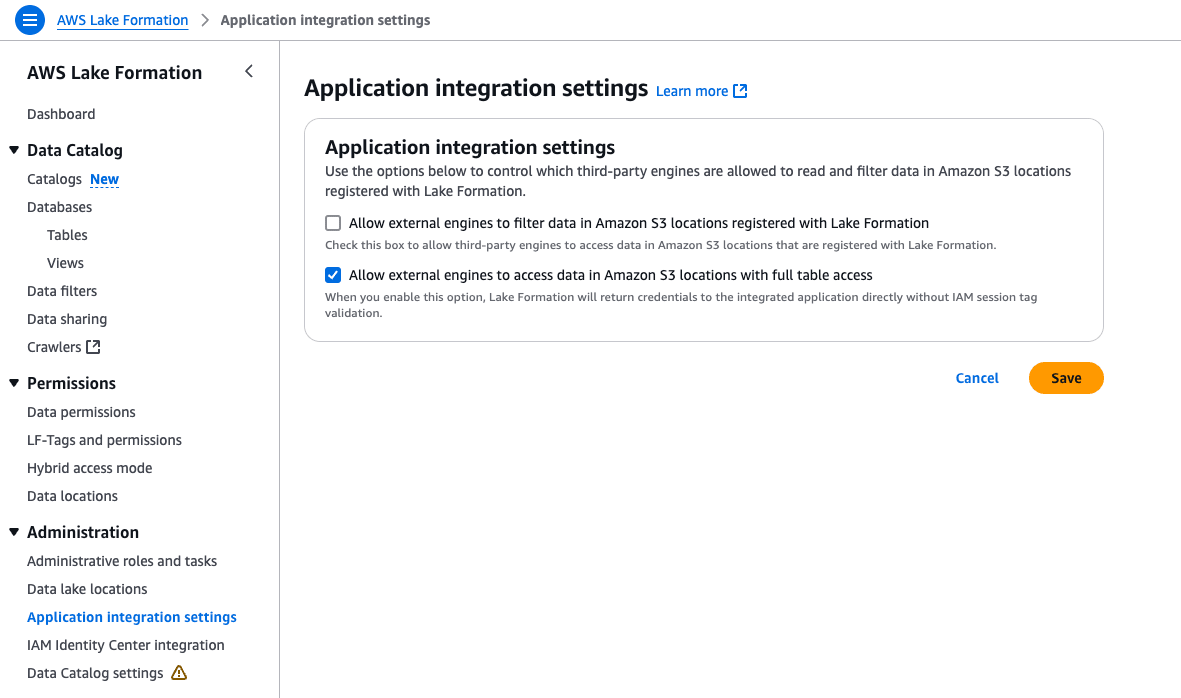
LakeFormationの設定
前提としてLakeFormation周りの設定が完了している必要があります。
AWS分析サービスとの統合や権限の設定についてはこちらの記事を参照して下さい。
そして今回のように外部アプリから接続する際にはApplication integration settingsの
Allow external engines to access data in Amazon S3 Locations with full table accessに
チェックを入れないと、アクセス拒否されてしまうので必ず設定して下さい。
(私はこの設定を見落としていて数時間を無駄にしました)
assume role
ここからノートブック上の操作ですが、最初にテーブル操作のためのロールに切り替えておきましょう。
私の環境では1passwordを使っているのでTokenCodeを渡してます。
また何時まで認証が有効だったか分からなくなるので、有効期限を出力していました。
import os
import boto3
import datetime
# assume role
sts_client = boto3.client("sts")
temp_creds = sts_client.assume_role(
RoleArn = "{スイッチロール先のarn}",
RoleSessionName = "{任意のセッション名}",
DurationSeconds = 3200,
SerialNumber = "{MFAのarn}",
TokenCode = "{ワンタイムパスワード}"
)
# 認証情報を環境変数として定義
os.environ["AWS_ACCESS_KEY_ID"] = temp_creds["Credentials"]["AccessKeyId"]
os.environ["AWS_SECRET_ACCESS_KEY"] = temp_creds["Credentials"]["SecretAccessKey"]
os.environ["AWS_SESSION_TOKEN"] = temp_creds["Credentials"]["SessionToken"]
# 有効期限の日時を日本時間で出力
td = datetime.timedelta(hours=9)
Expiration = temp_creds["Credentials"]["Expiration"]
print(f"Expiration: {datetime.datetime.strftime(Expiration + td, '%H:%M:%S')}")
カタログを読み込む
ブログの内容ほとんどそのままでカタログの読み込みができます。
from pyiceberg.catalog import load_catalog
# S3 Tablesカタログの読み込み関数
def init_rest_catalog(s3table_bucket_name, account_id, region, catalog_name="S3TablesCatalog"):
return load_catalog(
catalog_name,
**{
"type": "rest",
"warehouse": f"{account_id}:s3tablescatalog/{s3table_bucket_name}",
"uri": f"https://glue.{region}.amazonaws.com/iceberg",
"rest.sigv4-enabled": "true",
"rest.signing-name": "glue",
"rest.signing-region": region,
},
)
# カタログを読み込みに必要なパラメータ
s3table_bucket_name = "{テーブルバケット名}"
account_id = "{スイッチロール先のアカウントID}"
region = "{対象のリージョン}"
# カタログを読み込み
catalog = init_rest_catalog(s3table_bucket_name, account_id, region)
カタログが問題なく読み込めれば、簡単にネームスペースやテーブルを確認できます。
今回は作成済みのネームスペースで作業していますが、もちろん新規でネームスペースの作成も可能です。
# ネームスペースを出力
catalog.list_namespaces()
# 出力
[('20250218_namespace',)]
# ネームスペース内のテーブルを出力
catalog.list_tables("20250218_namespace")
# 出力
[('20250218_namespace', 'maintenance_test'),
('20250218_namespace', 'migration_test'),
('20250218_namespace', 'table_kawanago_test')]
テーブルを作成する
pyarrowを使えば簡単にスキーマ情報を定義できます。
あとはネームスペース&テーブル名を指定して、create_tableでテーブルが作成されます。
import pyarrow as pa
# スキーマを定義
schema = pa.schema(
[
pa.field("col_1", pa.string(), nullable=True),
pa.field("col_2", pa.int32(), nullable=True),
pa.field("col_3", pa.bool_(), nullable=True),
]
)
# テーブルを作成してオブジェクトを取得
database_name = "20250218_namespace"
new_table_name = "table_20250307"
tbl = catalog.create_table(
identifier=f"{database_name}.{new_table_name}",
schema=schema
)
上ではcreate_tableから直接オブジェクトを受け取っていますが、
以下のようにload_tableでテーブルを直接読み込むことももちろん可能です。
tbl = catalog.load_table(f"{database_name}.{new_table_name}")
list_tablesで確認すると、新しくテーブルが追加されたことが確認できます。
# テーブルが追加されている
catalog.list_tables(database_name)
# 出力
[('20250218_namespace', 'maintenance_test'),
('20250218_namespace', 'migration_test'),
('20250218_namespace', 'table_20250307'),
('20250218_namespace', 'table_kawanago_test')]
データを投入してみる
今回はサンプルデータとしてに2つのcsvを用意しました。
sample_1.csv
| col_1 | col_2 | col_3 |
|---|---|---|
| string1 | 100 | True |
| string2 | 200 | False |
| string3 | 300 |
sample_2.csv
| col_1 | col_2 | col_3 |
|---|---|---|
| string4 | 400 | True |
| string5 | 500 | False |
| string6 | 600 |
サンプル用に作成したcsvをpandasで読み込んで、pyarrowのオブジェクトに変換しておきます。
import pandas as pd
# 格納するデータを読み込み
source_1 = pd.read_csv("sample_1.csv", dtype={"col_1": "str", "col_2": "int32", "col_3": "boolean"})
df_1 = pa.Table.from_pandas(source_1)
ではデータをINSERTしてみます。
データの投入も確認も本当に簡単で驚きました。
# データをINSERT
tbl.append(df_1)
# データの格納を確認
tbl.scan().to_arrow()
出力:
pyarrow.Table
col_1: large_string
col_2: int32
col_3: bool
----
col_1: [["string1","string2","string3"]]
col_2: [[100,200,300]]
col_3: [[true,false,null]]
テーブルの情報はtbl.scan().to_pandas()でも出力可能です。
直接ノートブック上でデータを分析する際には嬉しいですね。

スナップショットはhistoryまたはsnapshotsで確認ができます。
簡単に確認したい時はhistoryの方が見やすいかも知れません。
# スナップショットが生成されている
tbl.history()
# 出力
[SnapshotLogEntry(snapshot_id=288629301491538650, timestamp_ms=1741336245591)]
スナップショットのtimestampがUNIX表記だったので変換していました。
import datetime
# スナップショットの生成時刻を取得
ts_ms = tbl.snapshots()[-1].timestamp_ms
# unix時刻表記から変換
time_format = "%Y-%m-%d %H:%M:%S"
datetime.datetime.fromtimestamp(ts_ms/1000).strftime(time_format)
# 出力
'2025-03-07 17:30:45'
データを追加してタイムトラベルしてみる
タイムトラベルを確認するために、データを追加してみます。
各カラムのデータはトランザクションごとにリストになっているみたいです。
# 格納するデータを読み込み
source_2 = pd.read_csv("sample_2.csv", dtype={"col_1": "str", "col_2": "int32", "col_3": "boolean"})
df_2 = pa.Table.from_pandas(source_2)
# データをINSERT
tbl.append(df_2)
# データの格納を確認
tbl.scan().to_arrow()
# 出力
pyarrow.Table
col_1: large_string
col_2: int32
col_3: bool
----
col_1: [["string4","string5","string6"],["string1","string2","string3"]]
col_2: [[400,500,600],[100,200,300]]
col_3: [[true,false,null],[true,false,null]]
新しいスナップショットが追加されています。
# スナップショットが生成されている
tbl.history()
# 出力
[SnapshotLogEntry(snapshot_id=288629301491538650, timestamp_ms=1741336245591),
SnapshotLogEntry(snapshot_id=2269627949680666147, timestamp_ms=1741336494884)]
snapshotsで取得した1つ前のスナップショットIDにタイムトラベルしてみました。
想定通り1つ前の状態のデータが表示されています。
#1つ前のスナップショットIDを取得して、タイムトラベル
previous_id = tbl.snapshots()[-2].snapshot_id
tbl.scan(snapshot_id=previous_id).to_arrow()
# 出力
pyarrow.Table
col_1: large_string
col_2: int32
col_3: bool
----
col_1: [["string1","string2","string3"]]
col_2: [[100,200,300]]
col_3: [[true,false,null]]
テーブル削除
最後に、不要になったテーブルを削除しておきました。
リストからも消えてますね。
# テーブルを削除
catalog.drop_table(f"{database_name}.{new_table_name}", purge_requested=True)
catalog.list_tables(database_name)
# 出力
[('20250218_namespace', 'maintenance_test'),
('20250218_namespace', 'migration_test'),
('20250218_namespace', 'table_kawanago_test')]
さいごに
簡単になりますが、PyIcebergを使ってローカル環境からS3 Tablesのテーブルを操作してみました。
LakeFormationの設定と、assume role、カタログの読み込みが正しくできていれば、
特に複雑な環境設定などは必要なく、手軽にローカルからS3 Tablesにアクセスできました。
基本的なテーブル操作は今回紹介していますが、各APIの詳細は以下のドキュメントをご参照下さい。
簡単な内容でしたが、少しでも参考になれば幸いです。
最後まで記事を閲覧頂きありがとうございました。








