
【アップデート】Amazon SageMaker CanvasのEDA用可視化機能を使ってみました
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データアナリティクス事業本部機械学習チームの中村です。
今回はAmazon SageMaker Canvasの新機能であるEDA(探索的データ分析)用の可視化機能ついてご紹介します。
AWS公式アナウンスでは1か月ほど前に以下で発表されています。
Amazon SageMaker Canvas アップデート概要
Amazon SageMaker Canvasは、コーディングすることなく機械学習を使用した予測を生成するサービスです。
使用できるユースケースとしては以下のようなものが挙げられます。
- 離職率の低減
- 不正行為の検出
- 売上予測
- 在庫の最適化
今回はこちらのサービスで、予測モデルなどを学習する前に実行するEDA(探索的データ分析)用の可視化機能が追加されました。
これによりモデル学習などコストが掛かるプロセスを実行する前に、ある程度簡単な分析を行うことができます。
Amazon SageMaker Canvas の料金
料金は以下の2つの部分で発生します。試される場合はご留意ください。
- Session Charges
- Canvasを起動して、Logoutするまでのセッションに対して発生します。
- そのためLogoutは忘れずに実施されてください。
- Training Charges
- データのセル数に応じて費用が発生します。
詳しい料金については下記URLを参照ください。
EDA用の可視化機能の概要
可視化の機能として以下の3種類に対応しています。
- Scatter plot(散布図):
- データの異なるカラムの関係性を可視化するために使用します。
- Bar plot(棒グラフ):
- データをあるカラムについて集約し、別カラムによるカテゴリ間で集約値を比較するために使用します。
- Box plot(箱ひげ図):
- データの分布を把握するために四分位数で表現します。
また、上記は色分けやプロットをあるカラム毎に分けて表示することも可能となっています。
実際に使用してみた
データセット
以下にあるForest Cover Typeデータセットを使用します。
こちらのtrain.csv.zipを解凍して使用します。
特徴量は以下のようになっています。
- Elevation: 標高
- Aspect: 方角
- Slope: 地面の傾斜
- Horizontal_Distance_To_Hydrology: 水場からの距離
- Vertical_Distance_To_Hydrology: 水場との標高差
- Horizontal_Distance_To_Roadways: 最も近い道路からの距離
- Hillshade_9am: 陰影起伏指数(夏至の午前9時)
- Hillshade_Noon: 陰影起伏指数(夏至の正午)
- Hillshade_3pm: 陰影起伏指数(夏至の午後3時)
- Horizontal_Distance_To_Fire_Points: 山火事の発火地点に最も近いところまでの距離
- Wilderness_Area: 原生地域指定
- 4個のバイナリ値で表現
- Soil_Type
- 40個のバイナリ値で表現
また目的変数は以下です。
- Cover_type: 森林被覆タイプ
データセットのアップロード
SageMaker Canvasから使用するためにS3にcsvデータをアップロードしておきます。
今回は以下に配置しました。
- s3://sample-nakamura-2022-09-22-canvas/dataset/train.csv
Canvas起動
以下からCanvasのメニューに移動し、
以下のボタンを押下します。
ユーザー一覧が表示されるので、ユーザーを追加します。

名前を入力します。今回実行ロールは新しく作成します。
特定のS3バケットに、データセットを置いたバケットを指定して、ロールを作成します。
作成が終わったら次へを押下します。
Studio設定はデフォルトで次へを押下します。
RStudioの設定もそのままとして、送信を押下します。
作成を終えたら、アプリケーションを起動を押下して、Canvasを選択します。

起動中の画面となります。

インポート
いくつかサンプルがデータセット一覧に表示されていますが、Importを押下してデータセットを追加します。
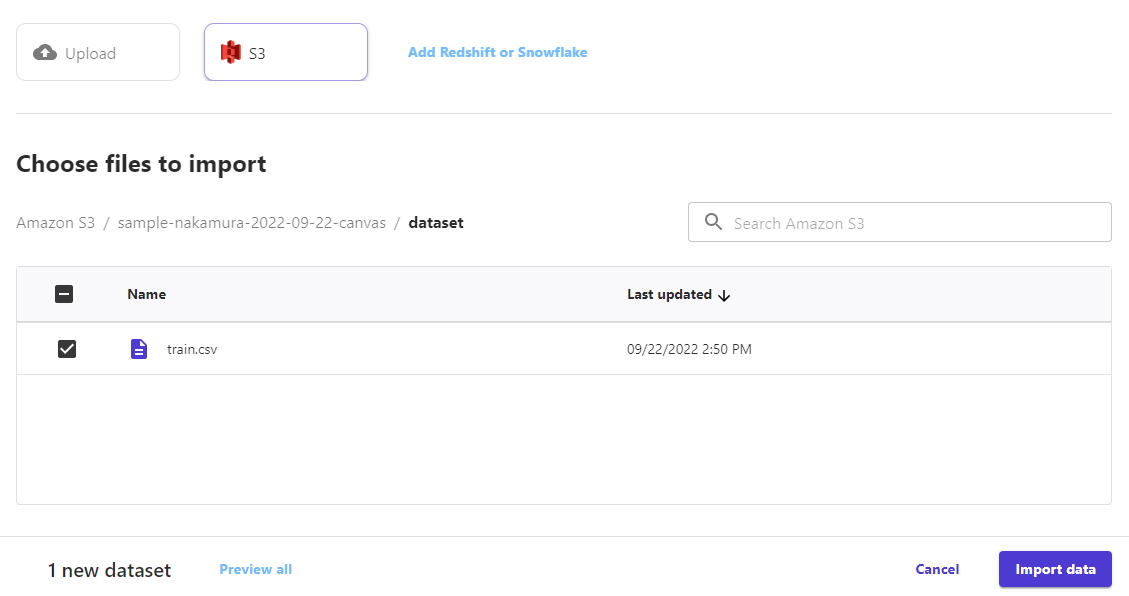
先ほどアップロードしたcsvファイルを選択して、Import dataを押下します。
トレーニング用にデータセットをロード
インポートしたcsvファイルを選択し、Create a modelを押下します。
Model nameを入力して、Createを押下します。
ロード画面となりますが、まだモデルをトレーニングしているわけではありません。
しばらく待つとBuildタブで読み込んだデータの一覧を確認できます。
この画面にある、Data visualizerというものが今回リリースされた機能となります。
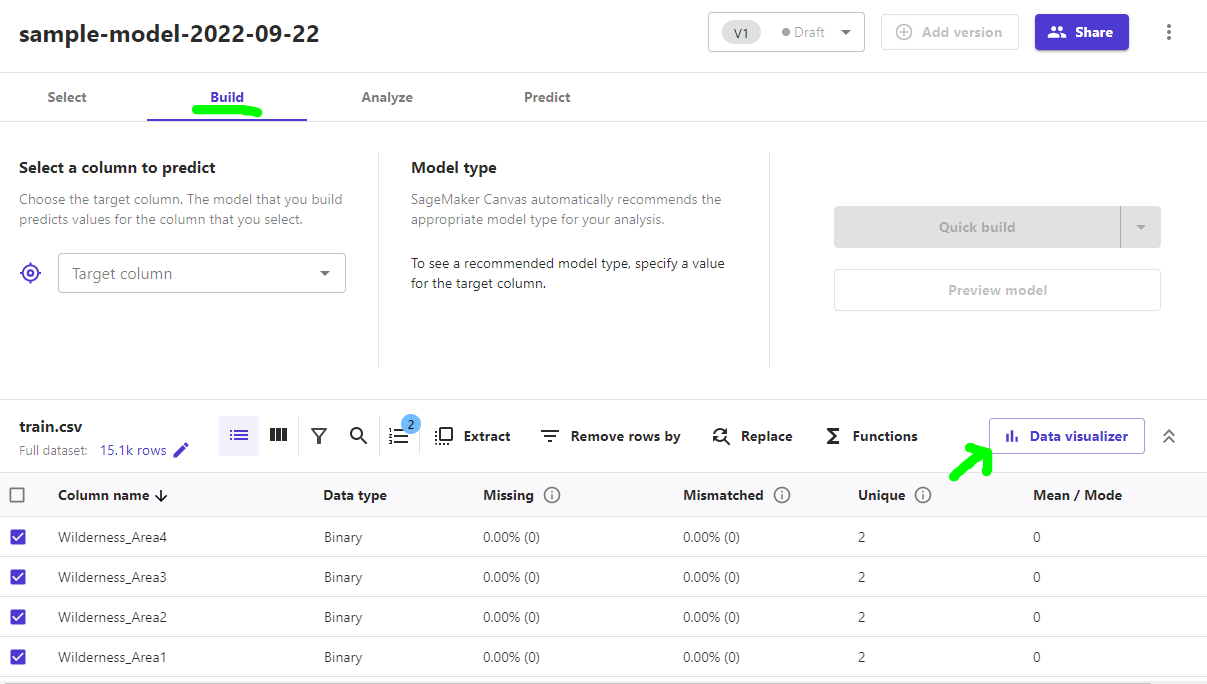
Data visualizerによるEDA
Data visualizerを起動すると以下のような画面となります。
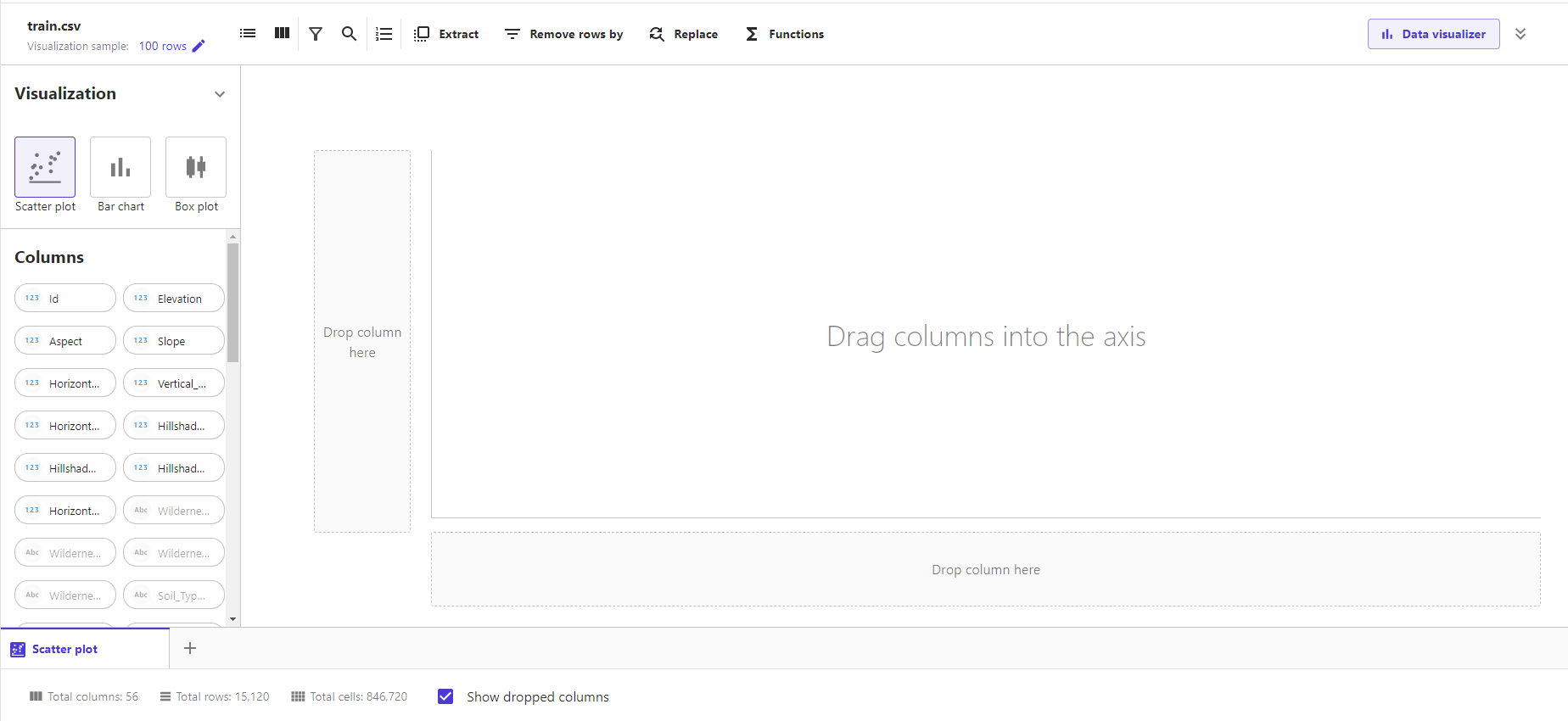
Visualizationから3つのグラフの種類を選択し、各値は左にあるColumnsからドラッグ&ドロップで配置するような形となります。
Scatter plot
まずは、Scatter plotの例として横軸にElevation、縦軸にHillshade_9amをプロットします。
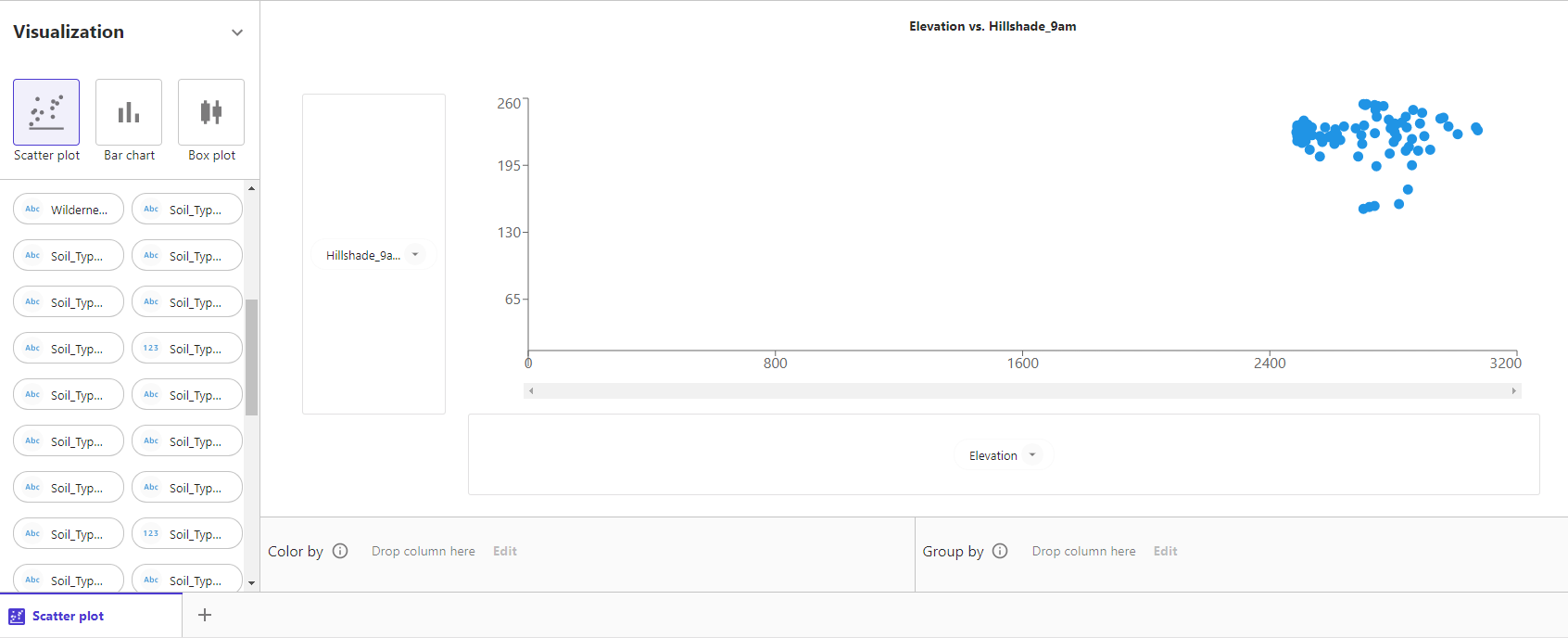
これに加えて、下部のColor byにカテゴリ変数などを設定し、カテゴリごとにColorを変えることができます。
また、Group byにカテゴリ変数などを設定し、カテゴリごとにプロットを分けることが可能です。
実際に、Color byにSoil_Type12を指定すると以下のように0が紺色、1が桃色に色分けされプロットされます。
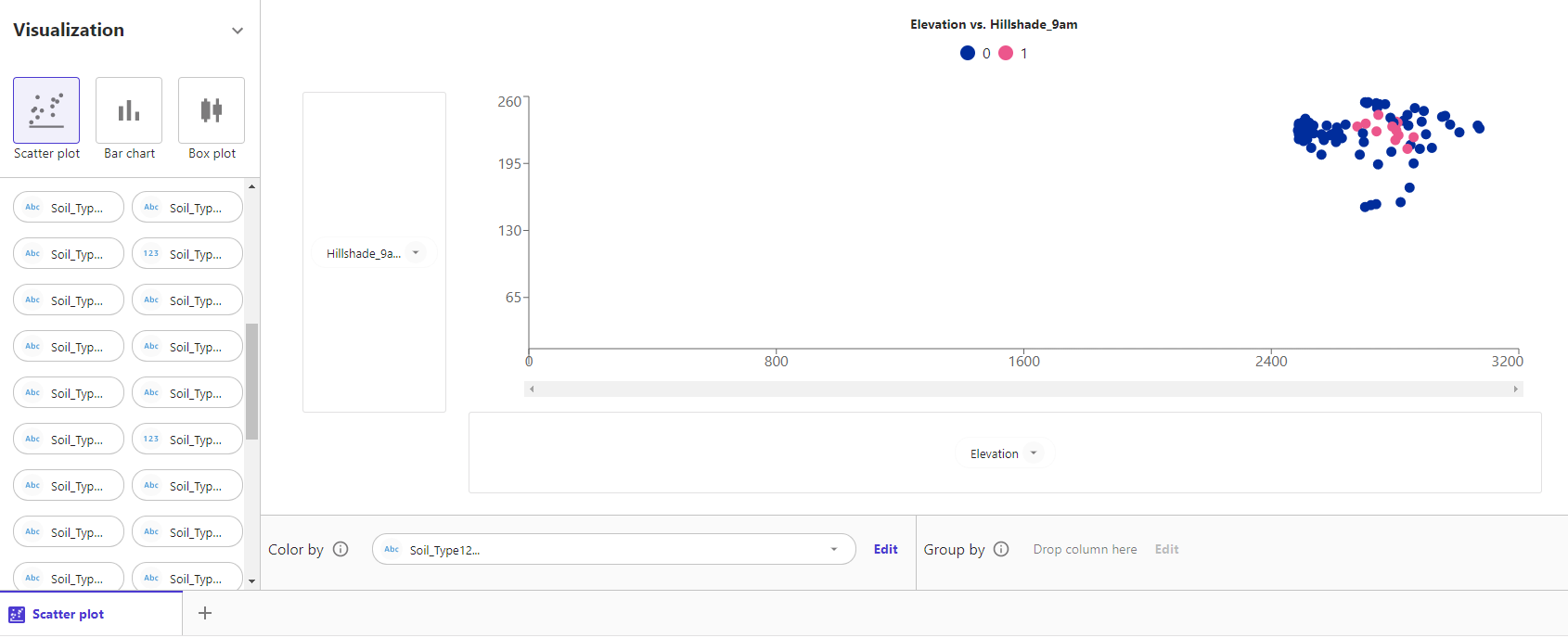
これに加え、Group byにSoil_Type18を指定すると以下のようにプロットが複数となります。
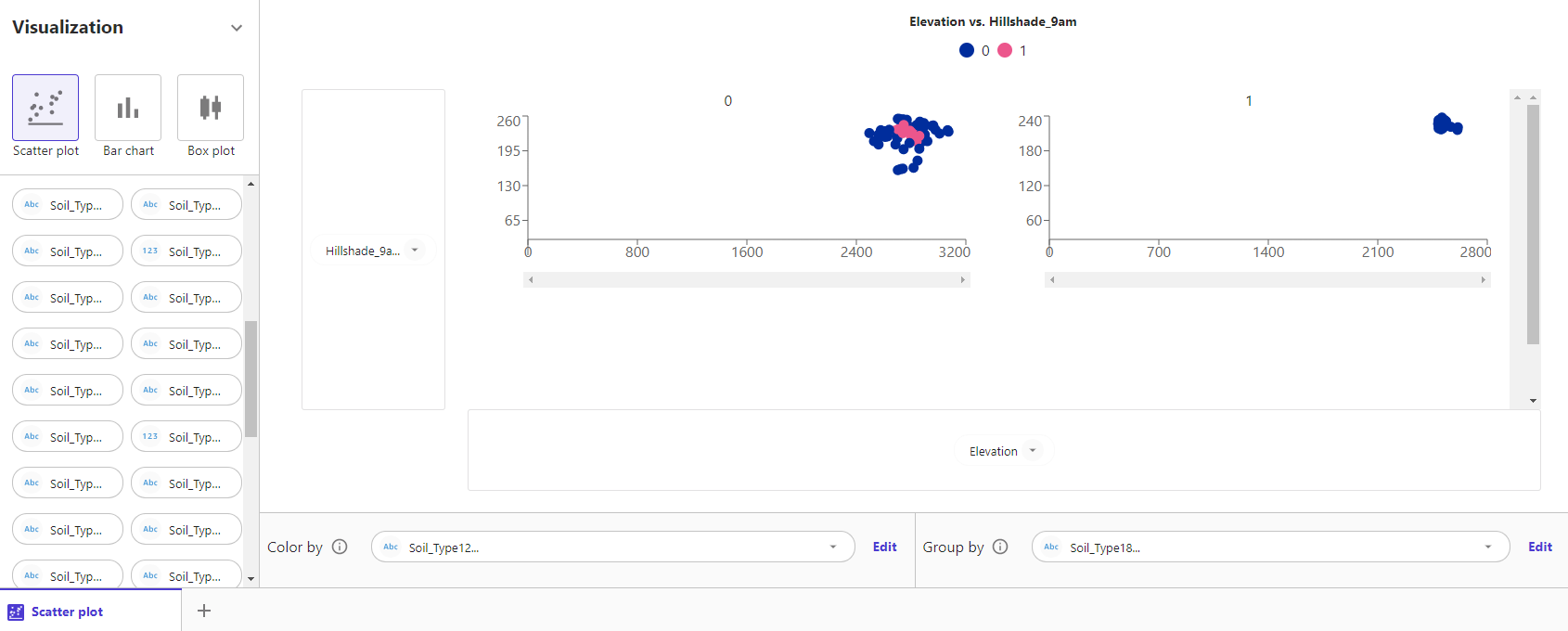
留意点としては、プロットはすべての点を描画しているわけではないため、サンプリングによっては、0もしくは1しか表示されないケースがあるようです。プロットが想定と異なった場合は、データ順を確認したりサンプリング数を調整してみてください。
サンプリング数の調整は左上のVisualization sampleの部分から実施可能です。
また、Color byやGroup byは10種類までしか同時に分けて表示することができないため、ここも留意が必要です。
Bar plot
次にBar plotで描画します。Bar plotでは様々な集約値を確認できます。
まずは、横軸にSoil_Type12を、縦軸にElevationを指定します。
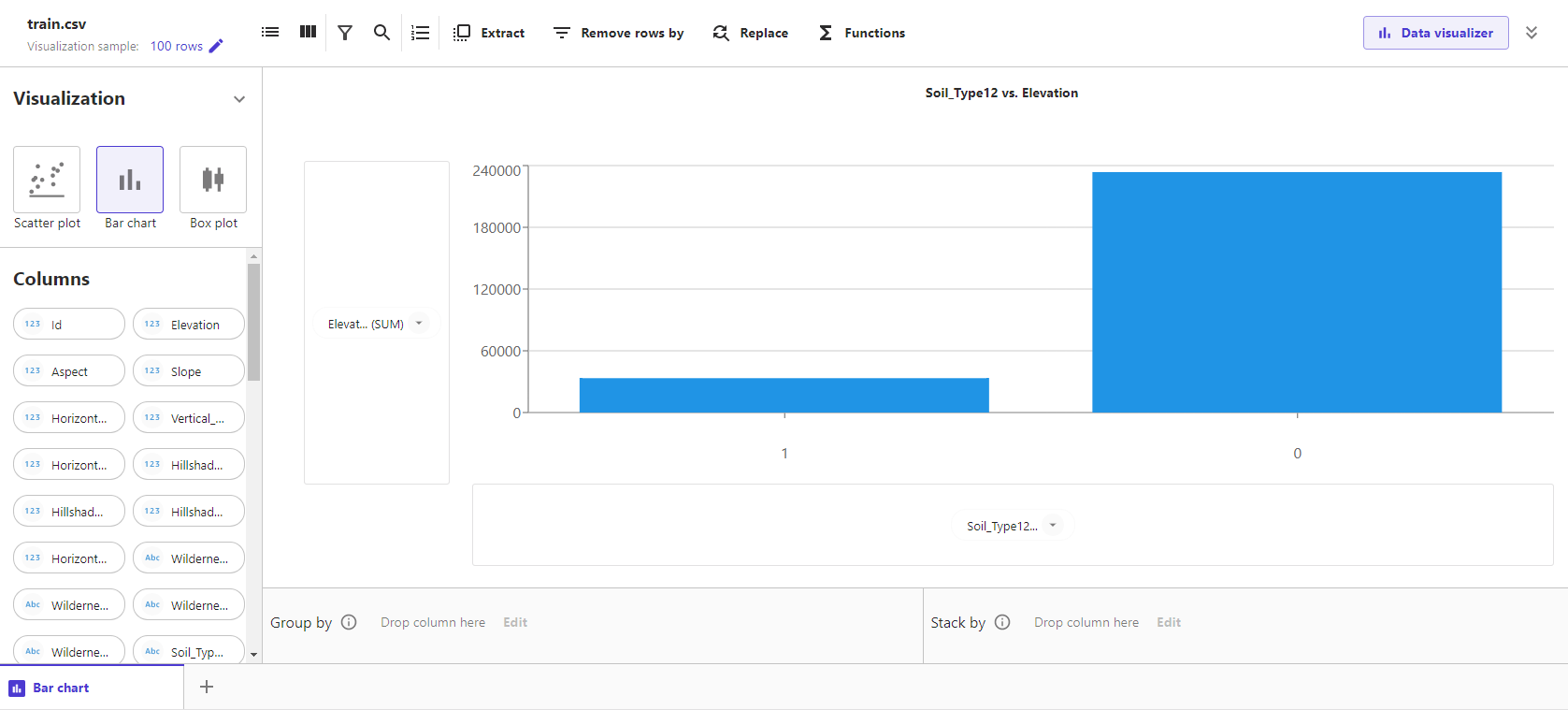
縦軸はデフォルトでSUMとなっていることが分かりますので、別の統計量をドロップメニューから選択することも可能です。
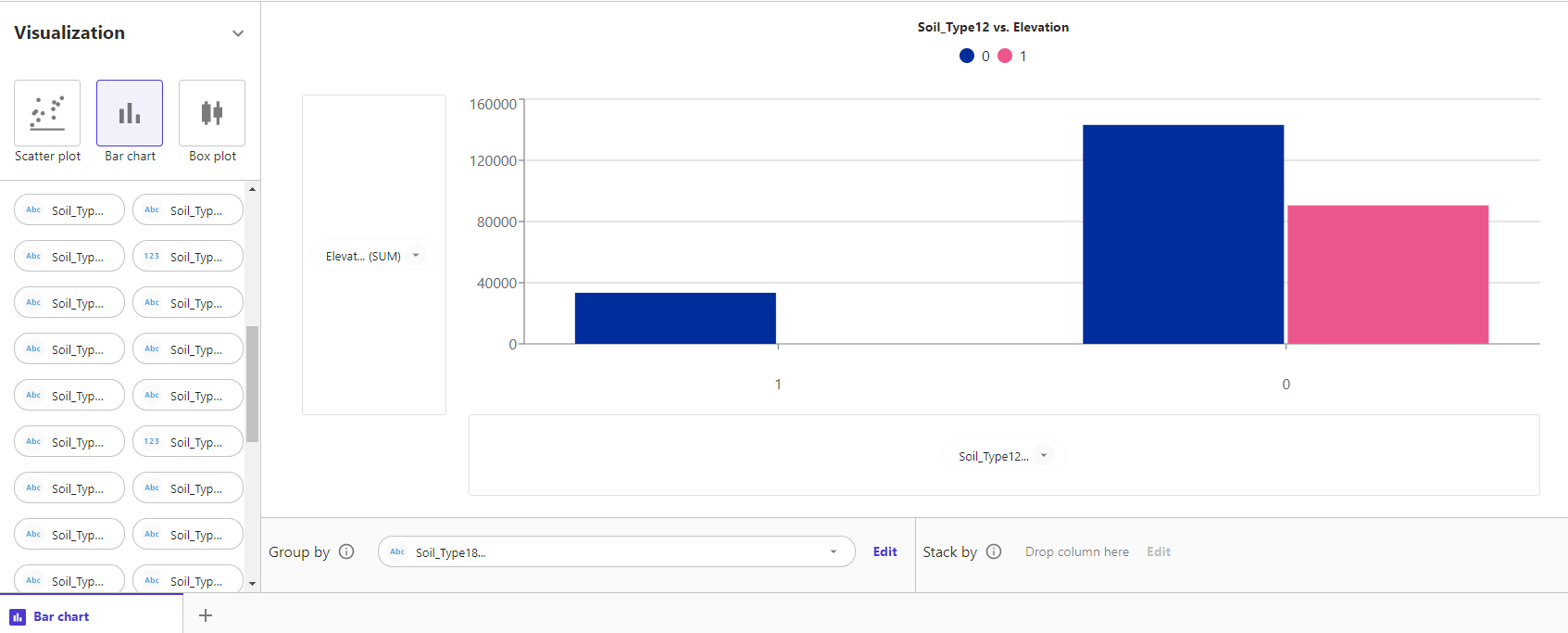
また棒グラフもカテゴリ毎に表現する方法として、Group byとStack byを使用することができます。
Group byに、Soil_Type18を指定すると以下のようになります。
また追加でStack byにSoil_Type29を指定すると以下のようになります。
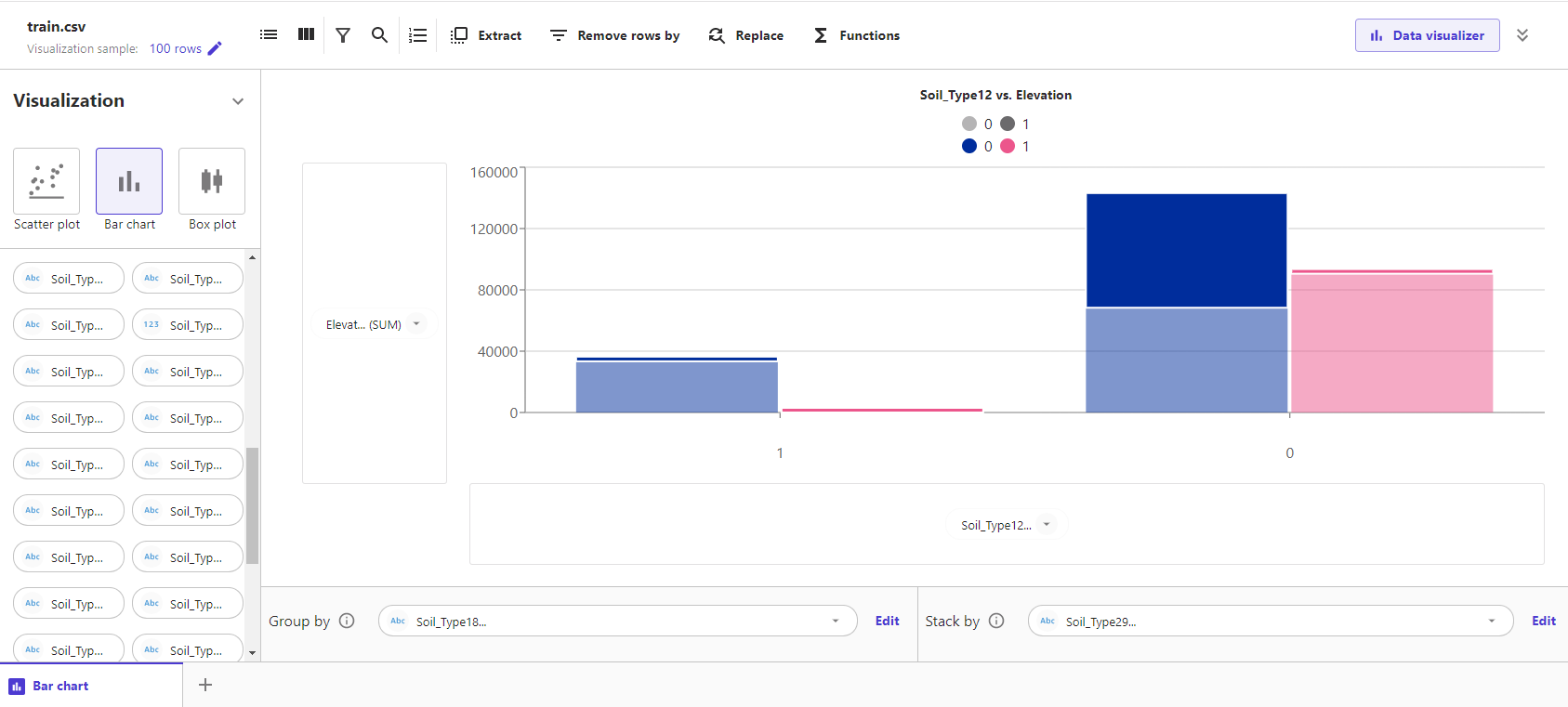
少しわかりずらいですが、透けている方がSoil_Type29=0、濃い方がSoil_Type29=1に割り当たっています。
Box plot
最後にBox plotで描画します。Box plotでは値の大まかな分布を確認することができます。
Bar plotと同様に、横軸にSoil_Type12を、縦軸にElevationを指定します。
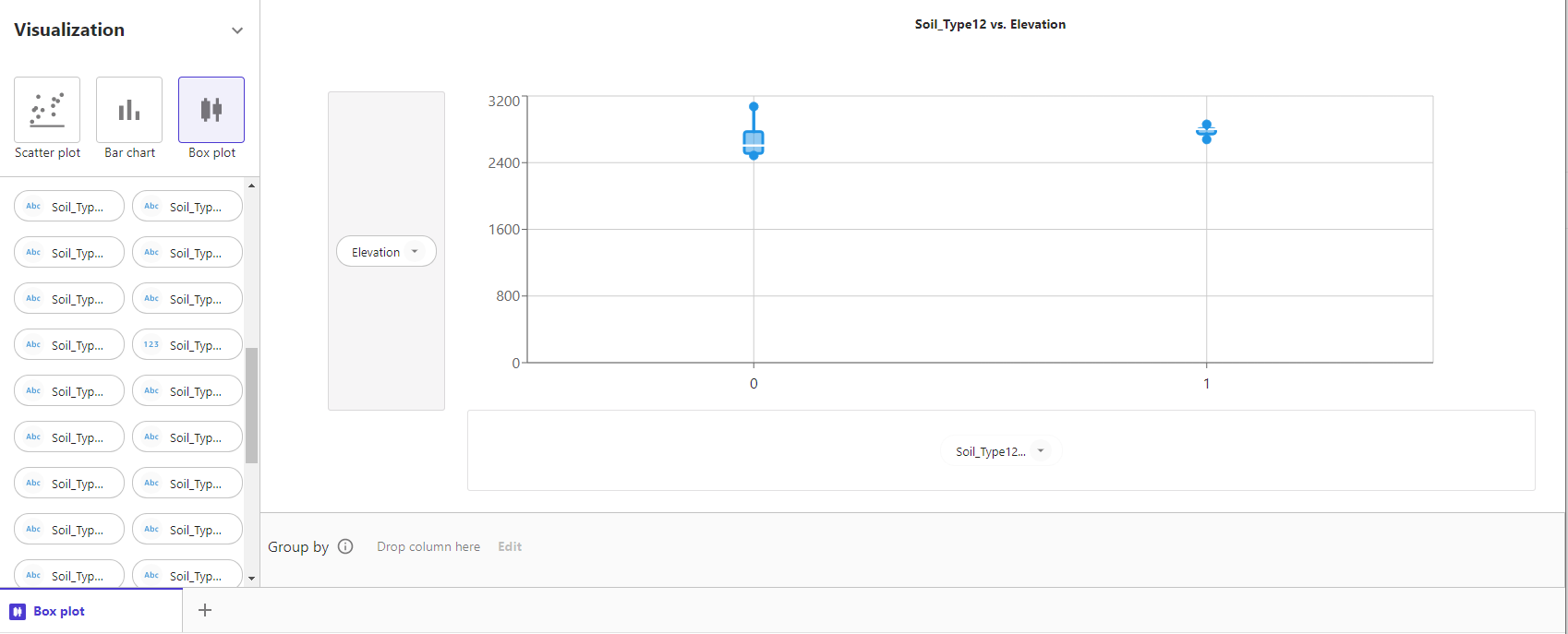
白線が中央値の線となっているようです。箱の端は上下25%分の境界を表します。
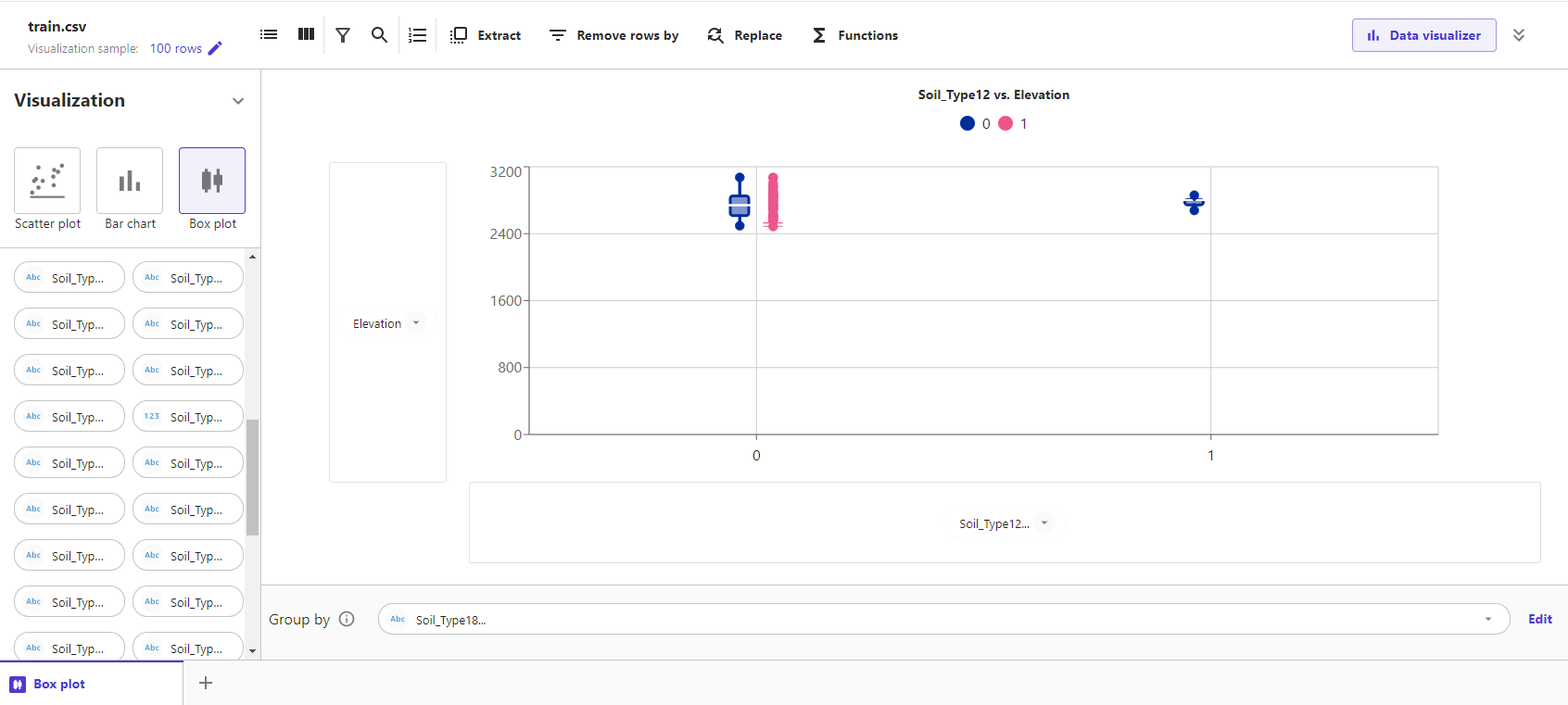
こちらは、追加でGroup byのみ可能となっています。Group byに、Soil_Type18を指定すると以下のようになります。
最後に
使用後は忘れずに、左下のメニューからLogoutを行ってください。
まとめ
いかがでしたでしょうか?
トレーニング前の作業として、手軽に簡易的なグラフで確認したい時は使えそうな機能ですね。
Amazon SageMaker Canvasをご利用の方は是非お試しください。
こちらの記事が活用する際の参考になれば幸いです。









