
SageMaker HyperPod recipesを使ってfine-tuningを試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
こんちには。
データ事業本部 インテグレーション部 機械学習チームの中村( @nokomoro3 )です。
本記事ではre:Invent 2024で発表されたSageMaker Hyperpod recipesをご紹介し、実際に動かしてみたいと思います。
SageMaker HyperPod recipesとは
Amazon SageMaker HyperPod recipesは、一般公開されている基盤モデル (FM) のトレーニングやファインチューニングをすぐに開始するためのレシピです。
実際にはGitHub上でレシピが公開される形となっています。
レシピとなる設定ファイルや実行するためのスクリプトが、モデル毎に公開されています。
これにより、トレーニングデータセットのロード、分散トレーニング技術の適用、障害からの迅速な復旧のためのチェックポイントの自動化、エンドツーエンドのトレーニングループの管理など、いくつかの重要なステップをテンプレートに沿った形で実行することが可能です。
今回の記事ではこちらを動かしてみます。
事前準備
SageMaker HyperPodのワークショップを参考に実施していきます。
スタック作成
以下に自身のアカウントでワークショップを実施する際の、スタック作成のテンプレートがあります。
- ワークショップのページ
- テンプレートのURL
AWSアカウントにログインした状態で、上記のテンプレートにアクセスすると、以下のようにCloudFormationのページを開くことができます。
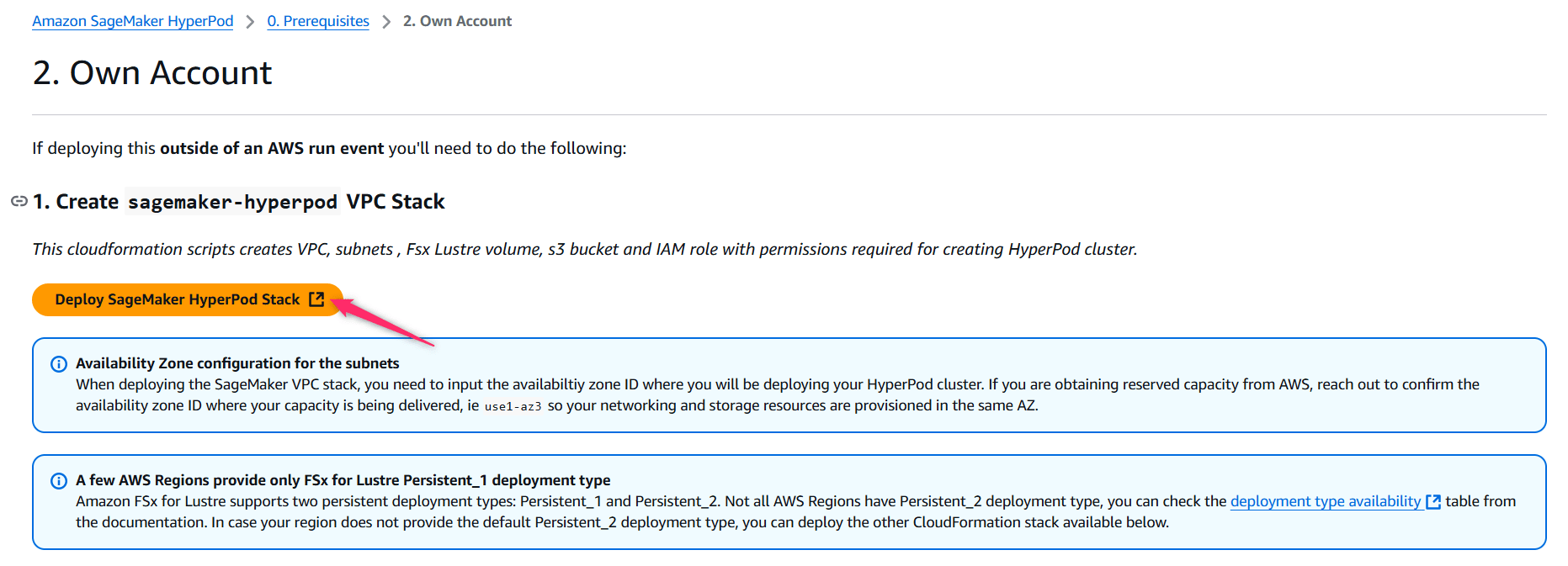
スタック名は cm-nakamura-hyperpod に修正しておきます。

AZはデフォルトが usw2-az4 (us-west-2d)となっていたため、使用できるインスタンスファミリが比較的多い usw2-az1 (us-west-2a)に変更しておきます。

AZごとの利用可能なインスタンスは以下をご参照ください。
他はデフォルトで作成します。
作成されるリソースは以下のようになっていました。
| 論理 ID | タイプ |
|---|---|
| AmazonSagemakerClusterExecutionRole | AWS::IAM::Role |
| EFASecurityGroupEgress | AWS::EC2::SecurityGroupEgress |
| EFASecurityGroupEgressECS | AWS::EC2::SecurityGroupEgress |
| EFASecurityGroupIngress | AWS::EC2::SecurityGroupIngress |
| ElasticIP | AWS::EC2::EIP |
| FlowLogsGroup | AWS::Logs::LogGroup |
| FlowLogsRole | AWS::IAM::Role |
| FlowLogVPC | AWS::EC2::FlowLog |
| FSxLFilesystem | AWS::FSx::FileSystem |
| GatewayToInternet | AWS::EC2::VPCGatewayAttachment |
| InternetGateway | AWS::EC2::InternetGateway |
| LCScriptsBucket | AWS::S3::Bucket |
| NATGateway | AWS::EC2::NatGateway |
| PrimaryPrivateSubnet | AWS::EC2::Subnet |
| PrimaryPrivateSubnetRTAssociation | AWS::EC2::SubnetRouteTableAssociation |
| PrivateRouteTable | AWS::EC2::RouteTable |
| PrivateRouteToInternet | AWS::EC2::Route |
| PublicRoute | AWS::EC2::Route |
| PublicRouteTable | AWS::EC2::RouteTable |
| PublicSubnet | AWS::EC2::Subnet |
| PublicSubnetRouteTableAssociation | AWS::EC2::SubnetRouteTableAssociation |
| S3Endpoint | AWS::EC2::VPCEndpoint |
| SecurityGroup | AWS::EC2::SecurityGroup |
| SSMSessionManagerRunShellAsUbuntu | AWS::SSM::Document |
| VPC | AWS::EC2::VPC |
| VpcCidrBlock | AWS::EC2::VPCCidrBlock |
料金に関わってくるのは、FSxやNATGatewayのリソースかと思います。
その他はVPC、サブネットがパブリックとプライベートの一つずつ、クラスタの実行ロール、EFA関連のSecurityGroupの設定、SSMなどとなります。S3バケットもLifecycleScript用に準備されています。
またワークショップのページにはこのほかに「Deploy Cluster Observability Stack」というクラスタ監視のためのスタックもあるのですが、今回は作成せずに進めてみます。
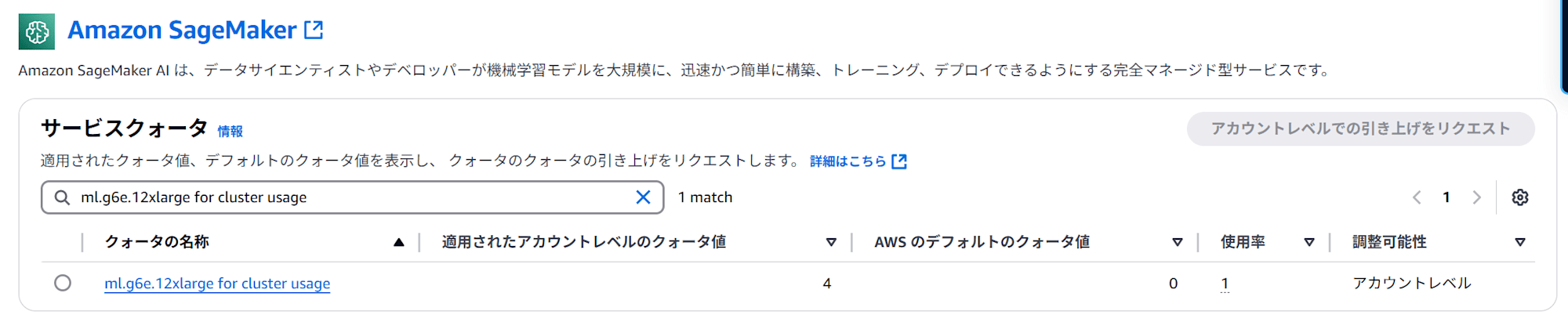
サービスクォータの確認
SageMaker HyperPodはSageMakerと同様に ml. が付いたインスタンスを指定して起動します。この ml. は通常のEC2インスタンスとは別にサービスクォータがあり、細かく制御できるようになっているため、利用予定のインスタンスのサービスクォータを確認しておきましょう。
本記事では、 g6e.12xlarge をクラスタのワーカーとして利用予定のため、以下を確認しておきます。
クラスタのセットアップ
ワークショップの以下に沿って進めます。
「Easy cluster setup」と「Manual cluster setup」がありますが、前者はスクリプトで自動化されているので、今回は理解を深めるため後者でやってみます。
AWS CLIのインストール
以下に沿って進めます。
まずはAWS CLIを使えるようにしておきます。私はWindows 11マシンのWSL(Ubuntu-24.04)から実行しています。
$ aws --version
# aws-cli/2.17.56 Python/3.12.6 Linux/5.15.167.4-microsoft-standard-WSL2 exe/x86_64.ubuntu.24
ライフライクルスクリプトの設定
以下に沿って進めます。
まずは公開されている create_config.sh を取得します。
$ curl 'https://static.us-east-1.prod.workshops.aws/public/97f372ae-83fb-43a1-9da2-0393b81dc89d/static/scripts/create_config.sh' --output create_config.sh
このスクリプトには先ほど作成したスタックから値を取得します。そのため先ほど変更したスタック名に書き換える必要があります。
- : "${STACK_ID_VPC:=sagemaker-hyperpod}"
+ : "${STACK_ID_VPC:=cm-nakamura-hyperpod}"
これ以降は、AWSプロファイルが有効となった状態で実行されてください。(aws-vault経由などでもOKです)
あとはワーカーに使用するインスタンスを環境変数で指定した後、 create_config.sh を実行します。
$ export INSTANCES=g6e.12xlarge
$ bash create_config.sh
実行後は以下のような env_var ファイルが作成されます。(伏字の xxxx の部分はそれぞれ異なります)
export AWS_REGION=us-west-2
export INSTANCES=g6e.12xlarge
export VPC_ID=vpc-xxxx
export SUBNET_ID=subnet-xxxx
export PUBLIC_SUBNET_ID=subnet-xxxx
export FSX_ID=fs-xxxx
export FSX_MOUNTNAME=xxxx
export SECURITY_GROUP=sg-xxxx
export ROLE=arn:aws:iam::xxxx:role/cm-nakamura-hyperpod-AmazonSagemakerClusterExecutio-xxxx
export ROLENAME=cm-nakamura-hyperpod-AmazonSagemakerClusterExecutio-xxxx
export BUCKET=sagemaker-lifecycle-xxxx
環境変数を読み込みます。
$ source env_vars
ライフサイクルスクリプトがGitHubで公開されているので、取得してそれをS3バケットにアップロードします。
$ git clone --depth=1 https://github.com/aws-samples/awsome-distributed-training/
$ cd awsome-distributed-training/1.architectures/5.sagemaker-hyperpod/LifecycleScripts/
# upload data
$ aws s3 cp --recursive base-config/ s3://${BUCKET}/src
# move back to env_var directory
$ cd ../../../..
これにより以下のスクリプトが s3://${BUCKET}/src に配置されます。
$ aws s3 ls s3://${BUCKET}/src/
# 2025-01-12 23:11:26 1655 add_users.sh
# 2025-01-12 23:11:26 723 apply_hotfix.sh
# 2025-01-12 23:11:26 3119 config.py
# 2025-01-12 23:11:26 8948 lifecycle_script.py
# 2025-01-12 23:11:26 3226 mount_fsx.sh
# 2025-01-12 23:11:26 1337 on_create.sh
# 2025-01-12 23:11:26 3577 setup_mariadb_accounting.sh
# 2025-01-12 23:11:26 2843 setup_rds_accounting.sh
# 2025-01-12 23:11:27 8262 setup_sssd.py
# 2025-01-12 23:11:27 88 shared_users_sample.txt
# 2025-01-12 23:11:27 1355 start_slurm.sh
クラスタの作成
以下に沿って進めます。
次にクラスタを作成していきます。以下のようにいくつかのインスタンスの設定ファイルが例示されています。
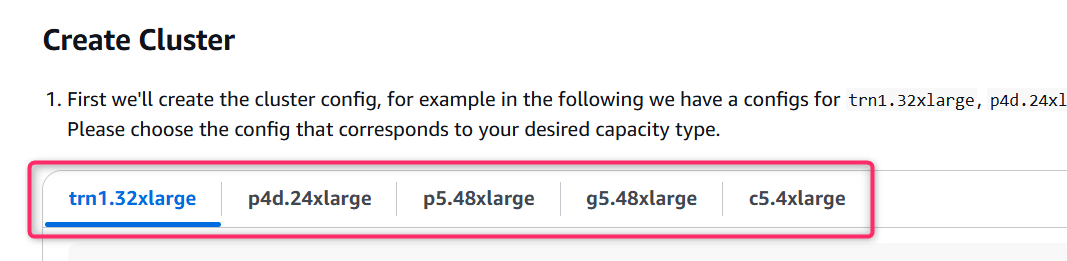
c5.4xlargeなどの場合を参考にしつつ、以下の点を変更します。
- ClusterNameは
cm-nakamura-clusterに変更 login-groupは任意のため削除controller-machineのInstanceTypeをml.c5.xlargeに変更(これはml.m5.xlargeのままで良かったかも)worker-group-1のInstanceTypeをml.g6e.12xlargeに変更
最終的には、以下を実行して cluster-config.json を作成します。
$ source env_vars
$ cat > cluster-config.json << EOL
{
"ClusterName": "cm-nakamura-cluster",
"InstanceGroups": [
{
"InstanceGroupName": "controller-machine",
"InstanceType": "ml.c5.xlarge",
"InstanceStorageConfigs": [
{
"EbsVolumeConfig": {
"VolumeSizeInGB": 500
}
}
],
"InstanceCount": 1,
"LifeCycleConfig": {
"SourceS3Uri": "s3://${BUCKET}/src",
"OnCreate": "on_create.sh"
},
"ExecutionRole": "${ROLE}",
"ThreadsPerCore": 2
},
{
"InstanceGroupName": "worker-group-1",
"InstanceType": "ml.g6e.12xlarge",
"InstanceCount": 1,
"InstanceStorageConfigs": [
{
"EbsVolumeConfig": {
"VolumeSizeInGB": 500
}
}
],
"LifeCycleConfig": {
"SourceS3Uri": "s3://${BUCKET}/src",
"OnCreate": "on_create.sh"
},
"ExecutionRole": "${ROLE}",
"ThreadsPerCore": 1
}
],
"VpcConfig": {
"SecurityGroupIds": ["$SECURITY_GROUP"],
"Subnets":["$SUBNET_ID"]
}
}
EOL
また、このクラスタ設定に一致した provisioning_parameters.json を以下で作成します。
$ instance_type=$(jq '.InstanceGroups[] | select(.InstanceGroupName == "worker-group-1").InstanceType' cluster-config.json)
$ cat > provisioning_parameters.json << EOL
{
"version": "1.0.0",
"workload_manager": "slurm",
"controller_group": "controller-machine",
"worker_groups": [
{
"instance_group_name": "worker-group-1",
"partition_name": ${instance_type}
}
],
"fsx_dns_name": "${FSX_ID}.fsx.${AWS_REGION}.amazonaws.com",
"fsx_mountname": "${FSX_MOUNTNAME}"
}
EOL
こちらはS3バケットに追加で格納します。
# copy to the S3 Bucket
$ aws s3 cp provisioning_parameters.json s3://${BUCKET}/src/
最後にクラスタ作成コマンドを実行します。
$ aws sagemaker create-cluster \
--cli-input-json file://cluster-config.json \
--region $AWS_REGION
作成中の状況はマネコンまたは以下のコマンドで確認できます。
$ aws sagemaker list-clusters --output table
# ---------------------------------------------------------------------------------------------------------------------------------------------------------
# | ListClusters |
# +-------------------------------------------------------------------------------------------------------------------------------------------------------+
# || ClusterSummaries ||
# |+----------------------------------------------------------------+------------------------------+----------------+------------------------------------+|
# || ClusterArn | ClusterName | ClusterStatus | CreationTime ||
# |+----------------------------------------------------------------+------------------------------+----------------+------------------------------------+|
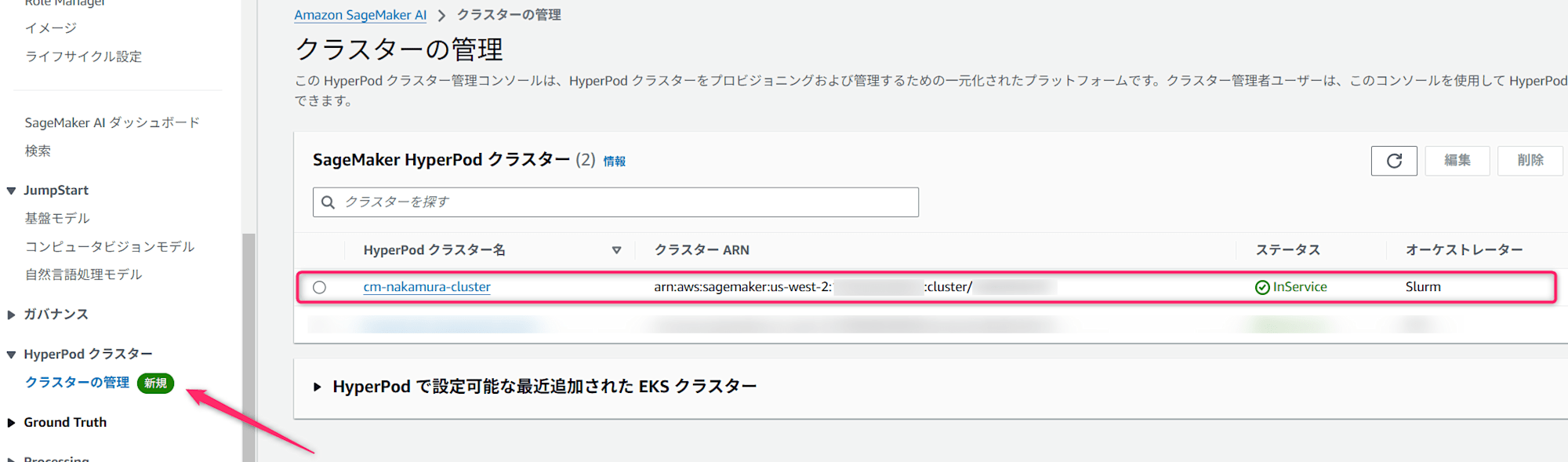
# || arn:aws:sagemaker:us-west-2:001234567899:cluster/{CLUSTER_ID} | cm-nakamura-cluster | Creating | 2025-01-13T11:21:53.178000+09:00 ||
# |+----------------------------------------------------------------+------------------------------+----------------+------------------------------------+|
マネジメントコンソールでも起動を確認できました。
SSH接続設定
以下に沿って進めます。
まずはSession Managerのプラグインをインストールします。
$ sudo curl "https://s3.amazonaws.com/session-manager-downloads/plugin/latest/ubuntu_64bit/session-manager-plugin.deb" -o "/tmp/session-manager-plugin.deb"
$ sudo dpkg -i /tmp/session-manager-plugin.deb
~/.ssh/config が壊れる可能性があるので、バックアップを取得しておいてください。
$ cp ~/.ssh/config ~/.ssh/config.bak
SSHキーを作成します。
$ ssh-keygen -t rsa -q -f "$HOME/.ssh/hyperpod" -N ""
$ ls -l $HOME/.ssh/ | grep "hyperpod"
# -rw------- 1 nakamura nakamura 2602 Jan 13 11:59 hyperpod
# -rw-r--r-- 1 nakamura nakamura 570 Jan 13 11:59 hyperpod.pub
接続用の easy-ssh.sh を取得します。
$ curl -O https://raw.githubusercontent.com/aws-samples/awsome-distributed-training/main/1.architectures/5.sagemaker-hyperpod/easy-ssh.sh
いくつかデフォルトの id_rsa という名前でSSHキーが作成されているという前提となっているため、修正をします。
# Function to add the user's SSH public key to the cluster
add_keypair_to_cluster() {
- PUBLIC_KEY=$(cat ~/.ssh/id_rsa.pub)
+ PUBLIC_KEY=$(cat ~/.ssh/hyperpod.pub)
# Check if the fingerprint already exists in the cluster's authorized_keys
EXISTING_KEYS=$(aws ssm start-session --target sagemaker-cluster:${cluster_id}_${node_group}-${instance_id} --document-name AmazonEKS-ExecuteNonInteractiveCommand --parameters command="cat /fsx/ubuntu/.ssh/authorized_keys")
if echo "$EXISTING_KEYS" | grep -q "$PUBLIC_KEY"; then
- echo -e "${BLUE}2. Detected SSH public key ${GREEN}~/.ssh/id_rsa.pub${BLUE} on the cluster. Skipping adding...${NC}"
+ echo -e "${BLUE}2. Detected SSH public key ${GREEN}~/.ssh/hyperpod.pub${BLUE} on the cluster. Skipping adding...${NC}"
return
else
- echo -e "${BLUE}2. Do you want to add your SSH public key ${GREEN}~/.ssh/id_rsa.pub${BLUE} to the cluster (yes/no)?${NC}"
+ echo -e "${BLUE}2. Do you want to add your SSH public key ${GREEN}~/.ssh/hyperpod.pub${BLUE} to the cluster (yes/no)?${NC}"
read -p "> " ADD_KEYPAIR
if [[ $ADD_KEYPAIR == "yes" ]]; then
echo "Adding ... ${PUBLIC_KEY}"
command="sed -i \$a$(escape_spaces "$PUBLIC_KEY") /fsx/ubuntu/.ssh/authorized_keys"
aws ssm start-session --target sagemaker-cluster:${cluster_id}_${node_group}-${instance_id} --document-name AmazonEKS-ExecuteNonInteractiveCommand --parameters command="$command"
- echo "✅ Your SSH public key ~/.ssh/id_rsa.pub has been added to the cluster."
+ echo "✅ Your SSH public key ~/.ssh/hyperpod.pub has been added to the cluster."
else
echo "❌ Skipping adding SSH public key to the cluster."
fi
fi
}
以下を実行すると、クラスタのインスタンス(この場合は controller-machine というヘッドノードのようなもの)に接続できます。
$ ./easy-ssh.sh -c controller-machine cm-nakamura-cluster
# =================================================
#
# ==== 🚀 HyperPod Cluster Easy SSH Script! 🚀 ====
#
#
# =================================================
# Cluster id: xxxx
# Instance id: xxxx
# Node Group: controller-machine
# Would you like to add cm-nakamura-cluster to ~/.ssh/config (yes/no)?
# > yes
# ✅ adding ml-cluster to ~/.ssh/config:
# 2. Do you want to add your SSH public key ~/.ssh/hyperpod.pub to the cluster (yes/no)?
# > yes
# Adding ... ssh-rsa xxxx
#
# Starting session with SessionId: cm-nakamura.shogo-xxxx
#
#
# Exiting session with sessionId: cm-nakamura.shogo-xxxx.
#
# ✅ Your SSH public key ~/.ssh/hyperpod.pub has been added to the cluster.
#
# Now you can run:
#
# $ ssh cm-nakamura-cluster
#
# Starting session with SessionId: cm-nakamura.shogo-xxxx
# /bin/bash -c 'cd ~ && exec bash'
ubuntu@ip-xxxx:~$
一旦、再接続するため exit で抜けます。
先ほどの easy-ssh.sh 実行後は設定が ~/.ssh/config に自動的に追記されます。
(単なる文字列置換を行うため、元の設定ファイルが壊れてないかは注意が必要です)
こちらに更に手動でIdentityFileに公開鍵を追記すると、以降は ssh cm-nakamura-cluster で接続可能になります。
Host cm-nakamura-cluster
User ubuntu
+ IdentityFile ~/.ssh/hyperpod
ProxyCommand sh -c "aws ssm start-session --target sagemaker-cluster:xxxx_controller-machine-xxxx --document-name AWS-StartSSHSession --parameters 'portNumber=%p'"
再度接続を試してみます。
$ ssh cm-nakamura-cluster
# ========================================================================================
# ____ __ ___ __ __ __ ___ __
# / __/__ ____ ____ / |/ /__ _/ /_____ ____ / // /_ _____ ___ ____/ _ \___ ___/ /
# _\ \/ _ `/ _ `/ -_) /|_/ / _ `/ '_/ -_) __/ / _ / // / _ \/ -_) __/ ___/ _ \/ _ /
# /___/\_,_/\_, /\__/_/ /_/\_,_/_/\_\\__/_/ /_//_/\_, / .__/\__/_/ /_/ \___/\_,_/
# /___/ /___/_/
# HyperPod Instance AMI (Ubuntu 20.04)
# ========================================================================================
# Welcome to Ubuntu 20.04.6 LTS (GNU/Linux 5.15.0-1072-aws x86_64v)
# Utility libraries are installed in /usr/bin/python3.9.
# To access them, use /usr/bin/python3.9.
# AWS Deep Learning AMI Homepage: https://aws.amazon.com/machine-learning/amis/
# Release Notes: https://docs.aws.amazon.com/dlami/latest/devguide/appendix-ami-release-notes.html
# Support: https://forums.aws.amazon.com/forum.jspa?forumID=263
# For a fully managed experience, check out Amazon SageMaker at https://aws.amazon.com/sagemaker
# =============================================================================
# * Documentation: https://help.ubuntu.com
# * Management: https://landscape.canonical.com
# * Support: https://ubuntu.com/pro
# System information as of Mon Jan 13 03:11:39 UTC 2025
# System load: 0.0 Processes: 245
# Usage of /: 52.2% of 96.73GB Users logged in: 0
# Memory usage: 14% IPv4 address for ens6: xxxx
# Swap usage: 0%
# * Ubuntu Pro delivers the most comprehensive open source security and
# compliance features.
# https://ubuntu.com/aws/pro
# Expanded Security Maintenance for Applications is not enabled.
# 19 updates can be applied immediately.
# 11 of these updates are standard security updates.
# To see these additional updates run: apt list --upgradable
# 41 additional security updates can be applied with ESM Apps.
# Learn more about enabling ESM Apps service at https://ubuntu.com/esm
# New release '22.04.5 LTS' available.
# Run 'do-release-upgrade' to upgrade to it.
# To replace an instance run:
# sudo scontrol update node=<hostname> state=fail reason="Action:Replace"
# To automatically resume jobs, please add the following in your job submission script:
# srun --auto-resume=1
# Instance Type: c5.xlarge
# =============================================================================
# AMI Name: Deep Learning Base OSS Nvidia Driver GPU AMI (Ubuntu 20.04)
# Supported EC2 instances: G4dn, G5, G6, Gr6, G6e, P4d, P4de, P5, P5e, P5en, Trn1, Trn1n
# NVIDIA driver version: 550.127.05
# CUDA versions available: cuda-12.1 cuda-12.2 cuda-12.3 cuda-12.4
# Default CUDA version is 12.1
# Release notes: https://docs.aws.amazon.com/dlami/latest/devguide/appendix-ami-release-notes.html
# AWS Deep Learning AMI Homepage: https://aws.amazon.com/machine-learning/amis/
# Developer Guide and Release Notes: https://docs.aws.amazon.com/dlami/latest/devguide/what-is-dlami.html
# Support: https://forums.aws.amazon.com/forum.jspa?forumID=263
# For a fully managed experience, check out Amazon SageMaker at https://aws.amazon.com/sagemaker
# =============================================================================
# ____ __ ___ __ __ __ ___ __
# / __/__ ____ ____ / |/ /__ _/ /_____ ____ / // /_ _____ ___ ____/ _ \___ ___/ /
# _\ \/ _ `/ _ `/ -_) /|_/ / _ `/ '_/ -_) __/ / _ / // / _ \/ -_) __/ ___/ _ \/ _ /
# /___/\_,_/\_, /\__/_/ /_/\_,_/_/\_\\__/_/ /_//_/\_, / .__/\__/_/ /_/ \___/\_,_/
# /___/ /___/_/
# To replace an instance run:
# sudo scontrol update node=<hostname> state=fail reason="Action:Replace"
# To automatically resume jobs, please add the following in your job submission script:
# srun --auto-resume=1
# You're on the login
# Controller Node IP: xxxx
# Login Node IP: xxxx
# Instance Type: ml.c5.xlarge
# Last login: Mon Jan 13 03:
ubuntu@ip-xxxx:~$
以降はこの controller-machine に接続した状態をメインで作業をします。
デバッグ等で worker-group-1 に接続したい場合も、同様に実行されてください。
$ ./easy-ssh.sh -c worker-group-1 cm-nakamura-cluster
データセットの準備
データセット作成
データセットの作成は以下の記事に沿って準備済みとします。
なお、使用したいモデルが変わる場合はトークナイザから変わるため、データセットの作成からやり直す必要があります。
今回の記事は上記と同じく、以下のモデルを学習する前提で記載します。
ここまでで、 tokenized_dataset.tar が作成されている前提で以降を進めます。
S3の準備とFSxとの関連付け
ここはローカルマシン等で実行します。
SSH等で配置するにはデータサイズが大きすぎるため、S3経由でFSxに配置します。
まずはデータセット用のバケットを作成します。
$ export DATASET_BUCKET_NAME="cm-nakamura-dataset"
$ aws s3api create-bucket --bucket ${DATASET_BUCKET_NAME} --region ${AWS_REGION} \
--create-bucket-configuration LocationConstraint=${AWS_REGION}
最初のスタックで作成した、FSxに関連付けをします。
$ aws fsx create-data-repository-association \
--region ${AWS_REGION} \
--file-system-id ${FSX_ID} \
--file-system-path /dataset \
--data-repository-path s3://${DATASET_BUCKET_NAME} \
--s3 "AutoImportPolicy={Events=[NEW,CHANGED,DELETED]},AutoExportPolicy={Events=[NEW,CHANGED,DELETED]}" \
--batch-import-meta-data-on-create
アップロードと展開
S3にデータセットをアップロードします。
$ aws s3 cp ./tokenized_dataset.tar s3://${DATASET_BUCKET_NAME}
クラスターの controller-machine 上で作業を進めます。
関連付けされたディレクトリ /fsx/dataset が確認できると思うので、移動して展開します。
$ cd /fsx/dataset
$ sudo tar xvf tokenized_dataset.tar
展開後は以下のように確認できると思います。
$ tree
# .
# ├── tokenized_dataset
# │ ├── test
# │ │ ├── data-00000-of-00001.arrow
# │ │ ├── dataset_info.json
# │ │ └── state.json
# │ ├── train
# │ │ ├── data-00000-of-00008.arrow
# │ │ ├── data-00001-of-00008.arrow
# │ │ ├── data-00002-of-00008.arrow
# │ │ ├── data-00003-of-00008.arrow
# │ │ ├── data-00004-of-00008.arrow
# │ │ ├── data-00005-of-00008.arrow
# │ │ ├── data-00006-of-00008.arrow
# │ │ ├── data-00007-of-00008.arrow
# │ │ ├── dataset_info.json
# │ │ └── state.json
# │ └── validation
# │ ├── data-00000-of-00001.arrow
# │ ├── dataset_info.json
# │ └── state.json
# └── tokenized_dataset.tar
HyperPod recipesの使用
おおむね以下に沿って進めます。
ただしワークショップの通りにやるだけだと一部権限不足や、記載の誤り、がありましたのでご注意ください。
(本記事では実際に実施できた手順で記載しています)
Python環境準備
controller-machine 上で作業を進めます。
まずはPython関連のパッケージをインストールします。
$ sudo apt install python3.9-venv
$ sudo apt install python3.9-dev
仮想環境を作成し、activateします。
$ python3.9 -m venv ${PWD}/venv
$ source venv/bin/activate
SageMaker HyperPod recipesをGitHubから取得し、必要なパッケージを仮想環境上にインストールします。
(venv) $ git clone --recursive https://github.com/aws/sagemaker-hyperpod-recipes.git
(venv) $ cd sagemaker-hyperpod-recipes
(venv) $ pip3 install --upgrade setuptools wheel
(venv) $ pip3 install -r requirements.txt
コンテナイメージの取得
ワークショップの通りに作成したスタックでは、クラスタの実行ロールにECRへのアクセス権限が不足していました。
そのため、スタックで作成されたIAMロールに以下のように AmazonEC2ContainerRegistryReadOnly というマネージドルールを追加します。
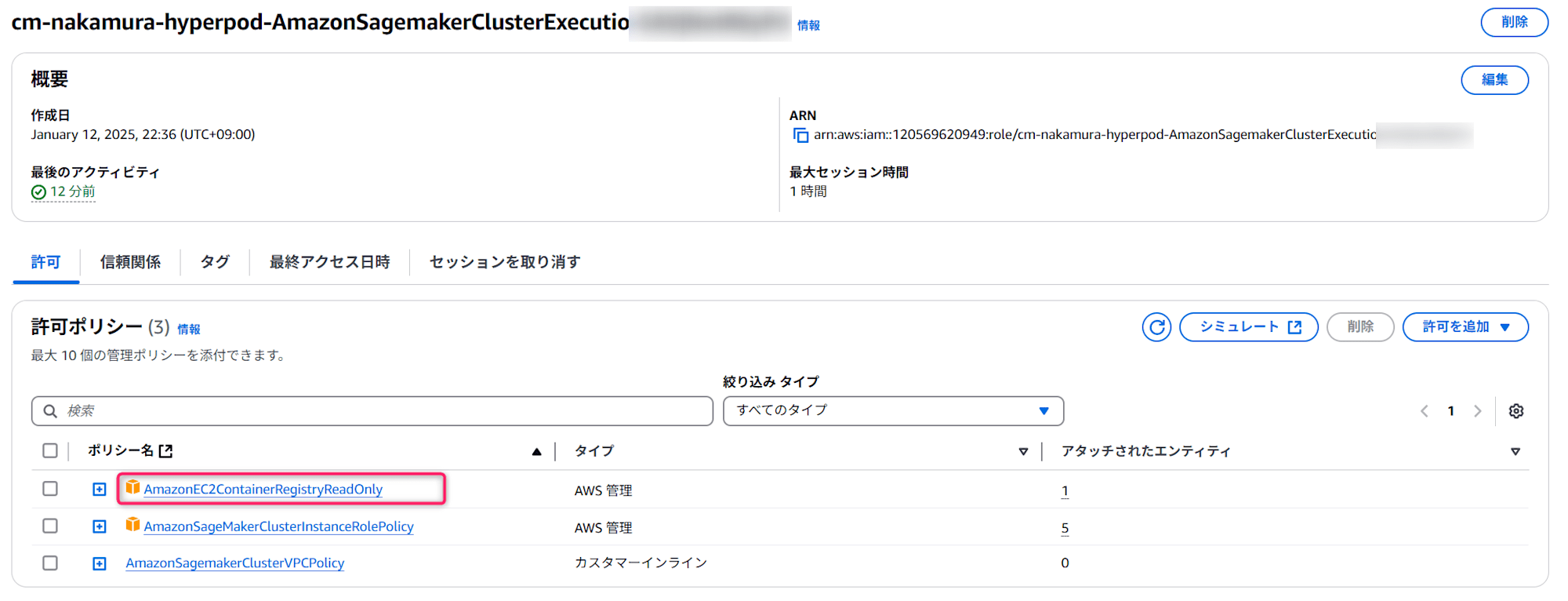
その後、以下を実行して公開されているリポジトリにログインします。
(ワークショップに記載されているコマンドはアカウントIDが誤っていたのでご注意ください)
$ export AWS_REGION="us-west-2"
$ REGION=$AWS_REGION
$ IMAGE="658645717510.dkr.ecr.${REGION}.amazonaws.com/smdistributed-modelparallel:2.4.1-gpu-py311-cu121"
$ aws ecr get-login-password --region "${REGION}" | docker login --username AWS --password-stdin 658645717510.dkr.ecr.${REGION}.amazonaws.com
# Login Succeeded
イメージをファイルとして取得します。
(クラスタでのジョブ実行時にはこのファイルを指定して実行します)
$ enroot import -o $PWD/smdistributed-modelparallel.sqsh dockerd://${IMAGE}
# [INFO] Fetching image
#
# Unable to find image '658645717510.dkr.ecr.us-west-2.amazonaws.com/smdistributed-modelparallel:2.4.1-gpu-py311-cu121' locally
# 2.4.1-gpu-py311-cu121: Pulling from smdistributed-modelparallel
# 7a2c55901189: Pulling fs layer
# 755e535b54a3: Pulling fs layer
#
# ...(中略)...
#
# Digest: sha256:a0e2cefb276671c79728b7f236ec50570535400843a4db5e9715930e3ae1c007
# Status: Downloaded newer image for 658645717510.dkr.ecr.us-west-2.amazonaws.com/smdistributed-modelparallel:2.4.1-gpu-py311-cu121
# 95037b48fcd3d6e025cb6a44a22c0afb3518d6c4b496e6688a2c1baeedfaf585
#
# [INFO] Extracting image content...
# [INFO] Creating squashfs filesystem...
#
# Parallel mksquashfs: Using 4 processors
# Creating 4.0 filesystem on /fsx/ubuntu/sagemaker-hyperpod-recipes/smdistributed-modelparallel.sqsh, block size 131072.
# [===================================================================================================\] 346971/346971 100%
#
# Exportable Squashfs 4.0 filesystem, lzo compressed, data block size 131072
# uncompressed data, uncompressed metadata, uncompressed fragments,
# uncompressed xattrs, uncompressed ids
# duplicates are not removed
# Filesystem size 19724778.70 Kbytes (19262.48 Mbytes)
# 99.87% of uncompressed filesystem size (19750283.71 Kbytes)
# Inode table size 8522800 bytes (8323.05 Kbytes)
# 100.00% of uncompressed inode table size (8522800 bytes)
# Directory table size 6499860 bytes (6347.52 Kbytes)
# 100.00% of uncompressed directory table size (6499860 bytes)
# No duplicate files removed
# Number of inodes 242167
# Number of files 207963
# Number of fragments 14355
# Number of symbolic links 10322
# Number of device nodes 0
# Number of fifo nodes 0
# Number of socket nodes 0
# Number of directories 23882
# Number of ids (unique uids + gids) 1
# Number of uids 1
# root (0)
# Number of gids 1
# root (0)
参考:VSCodeで作業するための準備
こちらは必要があれば任意の設定になります。
以降の編集作業をVSCodeを使って実施したい場合は、参考にされてください。
スクリプトの概要
先ほどGitHubから取得したSageMaker HyperPod recipesから、関連しそうなファイルを抜粋して確認します。
ユースケースとしてはLlama 3 8BモデルをLoRaで学習する例を使用します。
・launcher_scripts/llama/p4_run_hf_llama3_8b_seq8k_gpu_lora.sh
こちらがジョブ投入時に叩くスクリプトです。このスクリプトで後述の設定ファイルを基本的には上書きできます(例外あり)。
#!/bin/bash
# Original Copyright (c), NVIDIA CORPORATION. Modifications © Amazon.com
#Users should setup their cluster type in /recipes_collection/config.yaml
SAGEMAKER_TRAINING_LAUNCHER_DIR=${SAGEMAKER_TRAINING_LAUNCHER_DIR:-"$(pwd)"}
- HF_MODEL_NAME_OR_PATH="${HF_MODEL_NAME_OR_PATH}" # HuggingFace pretrained model name or path
- HF_ACCESS_TOKEN="${HF_ACCESS_TOKEN}" # Optional HuggingFace access token
+ HF_MODEL_NAME_OR_PATH="meta-llama/Meta-Llama-3-8B" # HuggingFace pretrained model name or path
+ HF_ACCESS_TOKEN="{ここにHugging Faceのトークンを記載}" # Optional HuggingFace access token
- TRAIN_DIR="${TRAIN_DIR}" # Location of training dataset
- VAL_DIR="${VAL_DIR}" # Location of validation dataset
+ TRAIN_DIR="/fsx/dataset/tokenized_dataset/train" # Location of training dataset
+ VAL_DIR="/fsx/dataset/tokenized_dataset/validation" # Location of validation dataset
- EXP_DIR="${EXP_DIR}" # Location to save experiment info including logging, checkpoints, etc.
+ EXP_DIR="/fsx/ubuntu/exp" # Location to save experiment info including logging, checkpoints, etc.
HYDRA_FULL_ERROR=1 python3 "${SAGEMAKER_TRAINING_LAUNCHER_DIR}/main.py" \
base_results_dir="${SAGEMAKER_TRAINING_LAUNCHER_DIR}/results" \
+ instance_type=ml.g6e.12xlarge \
+ container=/fsx/ubuntu/smdistributed-modelparallel.sqsh \
recipes=fine-tuning/llama/p4_hf_llama3_8b_seq8k_gpu_lora \
recipes.run.name="hf-llama3-8b-lora" \
recipes.exp_manager.exp_dir="$EXP_DIR" \
recipes.trainer.num_nodes=1 \
recipes.model.train_batch_size=1 \
recipes.model.data.train_dir="$TRAIN_DIR" \
recipes.model.data.val_dir="$VAL_DIR" \
recipes.model.hf_model_name_or_path="$HF_MODEL_NAME_OR_PATH" \
recipes.model.hf_access_token="$HF_ACCESS_TOKEN" \
+ recipes.model.shard_degree=4 \
+ recipes.trainer.devices=4 \
以降、変更点の概要を説明します。
以下は、モデル名の指定とトークンを指定する箇所です。トークンの詳細については、さきほどのデータセット準備の記事、またはこちらでご確認されてください。
- HF_MODEL_NAME_OR_PATH="${HF_MODEL_NAME_OR_PATH}" # HuggingFace pretrained model name or path
- HF_ACCESS_TOKEN="${HF_ACCESS_TOKEN}" # Optional HuggingFace access token
+ HF_MODEL_NAME_OR_PATH="meta-llama/Meta-Llama-3-8B" # HuggingFace pretrained model name or path
+ HF_ACCESS_TOKEN="{ここにHugging Faceのトークンを記載}" # Optional HuggingFace access token
以下は入力するデータセットと、モデル学習結果を格納するディレクトリを指定します。
- TRAIN_DIR="${TRAIN_DIR}" # Location of training dataset
- VAL_DIR="${VAL_DIR}" # Location of validation dataset
+ TRAIN_DIR="/fsx/dataset/tokenized_dataset/train" # Location of training dataset
+ VAL_DIR="/fsx/dataset/tokenized_dataset/validation" # Location of validation dataset
- EXP_DIR="${EXP_DIR}" # Location to save experiment info including logging, checkpoints, etc.
+ EXP_DIR="/fsx/ubuntu/exp" # Location to save experiment info including logging, checkpoints, etc.
入力は先ほどデータセットを展開したディレクトリを指定しています。出力先は任意に指定できます。
いずれのディレクトリも後述の設定でコンテナ内にマウントしないと、データの入出力ができないのでご注意ください。
以下は今回使用するワーカーのインスタンスを指定します。
+ instance_type=ml.g6e.12xlarge \
以下は学習に取得するコンテナイメージのパスを指定します。(先ほどenrootのimportで出力したものです)
+ container=/fsx/ubuntu/smdistributed-modelparallel.sqsh \
以下はGPUデバイス数と、並列数に関する設定です。
+ recipes.trainer.num_nodes=1 \
+ recipes.model.shard_degree=4 \
+ recipes.trainer.devices=4 \
num_nodes は単純にインスタンス数です。 devices は各インスタンスあたりのGPUボード数となります。 shard_degree は並列数を表しています。
今回は、 ml.g6e.12xlarge なので、 devices は4となります。
並列数の設定としてはこの他に、 tensor_model_parallel_degree や expert_model_parallel_degree もあり、今回の設定ファイルでは1となっています。
ここへんはエラーメッセージをみながら、ノード・デバイス数と並列数が矛盾しないように指定しましょう。
・main.py
先ほどのスクリプトが実行するPythonファイルです。設定値の解読などはこちらが行いますが、変更は不要となります。
・recipes_collection/config.yaml
基本となる設定ファイルです。コンテナイメージの指定やレシピとして使う詳細設定ファイルを指定したりします。
こちらの設定内容は基本的に、最初のシェルで上書きすることができます。先頭に recipes. と記載がないパラメータがこちらの設定ファイルに該当しています。
今回はシェル側で設定を実施し、このファイルは変更せずに実行しました。
・recipes_collection/recipes/fine-tuning/llama/p4_hf_llama3_8b_seq8k_gpu_lora.yaml
レシピとなる詳細設定ファイルです。分散方式や量子化設定、モデルの構造、学習時のハイパーパラメータなど、モデル学習関連の設定を行うことができます。
こちらの設定内容も基本的に、最初のシェルで上書きすることができます。先頭に recipes. と記載があったパラメータがこちらの設定ファイルに該当しています。
今回はシェル側で設定を実施し、このファイルは変更せずに実行しました。
・recipes_collection/cluster/slurm.yaml
こちらはslurmをジョブスケジューラとして使う際の設定となっているようです。
こちらのパラメータは最初のシェルで上書きができないため、containerにマウントするディレクトリの設定を記載しています。
# Original Copyright (c), NVIDIA CORPORATION. Modifications © Amazon.com
exclusive: True
mem: 0
job_name_prefix: 'sagemaker-'
slurm_create_submission_file_only: False # Setting to True if just want to create submission file
stderr_to_stdout: True # Setting to False to split the stderr and stdout logs
srun_args:
# - "--no-container-mount-home"
slurm_docker_cfg:
docker_args:
# - "--runtime=nvidia" # this is required if the docker runtime version is low
post_launch_commands: # commands will run after launching the docker container using bash
- container_mounts: # List of additional paths to mount to container. They will be mounted to same path.
- - null
+ container_mounts:
+ - /fsx/dataset:/fsx/dataset
+ - /fsx/ubuntu/exp:/fsx/ubuntu/exp
ジョブ実行
変更が終わったら、以下を実行してジョブを投入します。
$ bash ./launcher_scripts/llama/p4_run_hf_llama3_8b_seq8k_gpu_lora.sh
投入されたジョブは squeue で確認できます。
$ squeue
# JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
# 3 dev sagemake ubuntu R 4:06 1 ip-10-1-57-144
使用可能なクラスタは以下で確認できます。
$ sinfo
# PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
# dev* up infinite 1 alloc ip-10-1-57-144
# ml.g6e.12xlarge up infinite 1 alloc ip-10-1-57-144
ログが以下のファイルに吐かれるため、エラーが出ていないか確認します。
./results/hf-llama3-8b-lora/log-sagemaker-hf-llama3-8b-lora_{ジョブID}.out
結果
学習が成功すると、実行時に指定した EXP_DIR の場所に以下のように結果が出力されます。
$ tree
# /fsx/ubuntu/exp
# ├── checkpoints
# │ └── peft_full
# │ └── steps_50
# │ ├── README.md
# │ ├── adapter_config.json
# │ ├── adapter_model.safetensors
# │ └── final-model
# │ ├── config.json
# │ ├── generation_config.json
# │ ├── model-00001-of-00004.safetensors
# │ ├── model-00002-of-00004.safetensors
# │ ├── model-00003-of-00004.safetensors
# │ ├── model-00004-of-00004.safetensors
# │ └── model.safetensors.index.json
# └── experiment
# ├── 2025-01-22_04-32-34
# │ ├── cmd-args.log
# │ ├── events.out.tfevents.1737520360.ip-10-1-78-125.41029.0
# │ ├── git-info.log
# │ ├── hparams.yaml
# │ ├── lightning_logs.txt
# │ ├── nemo_error_log.txt
# │ └── sagemaker_log_globalrank-0_localrank-0.txt
# ├── sagemaker_log_globalrank-1_localrank-1.txt
# ├── sagemaker_log_globalrank-2_localrank-2.txt
# └── sagemaker_log_globalrank-3_localrank-3.txt
まとめ
いかがでしたでしょうか。
SageMaker HyperPod recipesには様々なモデルのレシピが公開されており、モデルの比較検証等はできてないので、機会があれば試してみたいと思います。
本記事がSageMaker HyperPod recipesを使われる方のご参考になれば幸いです。









