
「コカコーラ大好き」と彼は何回言ったのか?WebスクレイピングとDuckDBで集計してみた
コンバンハ、千葉(幸)です。
このブログサイト(DevelopersIO)ではさまざまな著者がブログを投稿しています。
著者によっては、ブログの書き出しにお決まりの挨拶を持っています。(コンバンハ、千葉(幸)です。もそうです。)
同僚にコカコーラが大好きな人物がいます。
「コカコーラ大好きカジです。」が彼のお決まりの挨拶です。「〇〇大好き△△です。」のフォーマットは汎用性が高くていいなと思います。
彼の文体を真似しようと思った時に、冒頭の書き出しにいくつかパターンがあることに気づきました。
- こんにちは、コカコーラ大好きカジです。
- こんにちはコカコーラ大好き、カジです。
- こんにちは、コカコーラが大好きなカジです。
- こんにちはコカコーラ大好きカジです。
- ……
こうなってくると全パターンを網羅したくなります。2025年6月現在、彼は154個の記事を書いています。それぞれの冒頭の挨拶を確認する必要が出てきました。
一個一個のブログを目で見て確認するのはギリ無理なので、前々から興味があったWebスクレイピングとDuckDBを用いて集計してみることにしました。きっかけが無いと人は動きませんからね。
果たして彼はどのようなパターンで冒頭の挨拶をしているのか?そして何回「コカコーラ大好き」と言ってきたのか。早速確認していきましょう。私はドクターペッパーが好きです。
今回やりたいこと
- Webスクレイピングをして必要な情報をまとめたCSVファイルを作成する
- 作成したCSVファイルに対してDuckDBを用いてクエリを実行する
動作確認環境
以下の両方で動作確認しました。
- macOS
- Python 3.13.2
- beautifulsoup4 4.13.4
- duckdb 1.3.1
- AWS CloudShell
- Python 3.9.21
- beautifulsoup4 4.13.4
- duckdb 1.3.1
Webスクレイピングでブログから冒頭の挨拶を取得する
今回はPythonライブラリのBeautiful Soupを用いてスクレイピングしてみます。(スクレイピングと言えば、というレベルでよく聞くため。)
対象サイトのrobots.txtを確認する
Webスクレイピングを実施するにあたって、対象サイトのrobots.txtを確認しておきましょう。
% curl https://dev.classmethod.jp/robots.txt
## https://dev.classmethod.jp/robots.txt
User-agent: *
Disallow: /pages/
Disallow: /error/
Disallow: /tag/
Disallow: /category/
Allow: /
# sitemap
Allow: /sitemap.xml
Allow: /sitemaps/*
Sitemap: https://dev.classmethod.jp/sitemap.xml
# RSS Feed
Allow: /feed/
# Option
Crawl-delay: 1
特定のパスへのクロールが禁止されていること、1秒の間隔を開けるべきであることが読み取れました。(2025/06現在)
今回取得したいサイトのページの構成
以下の構成です。(2025年6月現在)
- 著者ページに最大60個の記事が表示されている
- 記事が多い場合、以下のようにページ分割される
ブラウザの検証ツールでHTML要素を確認する
スクレイピングするために、どのようなHTML構造になっているかを理解しておきます。Webブラウザによって細かい部分は変わるかもしれませんが、該当箇所を右クリック→「検証」で、開発者ツールでHTMLの構造を確認できます。
著者ページにおける記事一覧
著者ページではこのように記事がカード形式で並んでいます。
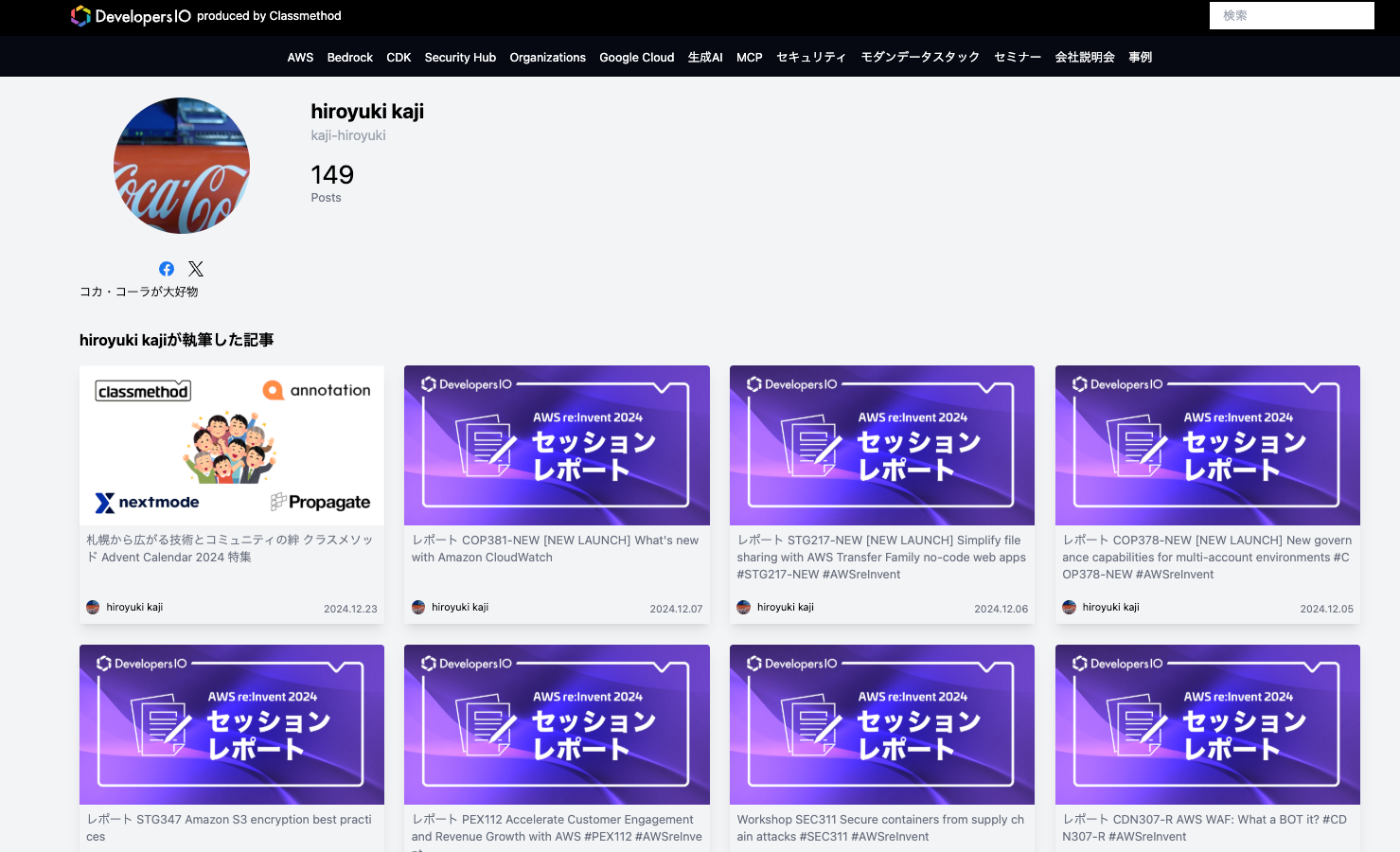
一つの記事のHTMLの例は以下です。(2025年6月現在)
<div class="flex flex-col rounded">
<div class="shadow-lg flex flex-col group grow justify-between">
<a href="/articles/advent-calendar-2024-sapporo-technology-and-community/">
<div class="aspect-[1200/630] overflow-hidden">
<img src="https://images.ctfassets.net/ct0aopd36mqt/26xITVwg0bbVYYjahaAkSu/59eed019d9c0b421786a8033660a52e6/classmethod-group-community-activities-advent-calendar-2024_1200x630.png" alt="札幌から広がる技術とコミュニティの絆 クラスメソッド Advent Calendar 2024 特集">
</div>
<div class="p-2 break-all">
<p class="text-sm text-gray-500">札幌から広がる技術とコミュニティの絆 クラスメソッド Advent Calendar 2024 特集</p>
</div>
</a>
<div class="flex justify-between px-2 py-2 items-center">
<a href="/author/kaji-hiroyuki/">
<div class="flex items-center">
<div class="h-4 w-4 flex-shrink-0 mr-2">
<img src="https://devio2023-media.developers.io/wp-content/uploads/devio_thumbnail/2024-06/kaji-hiroyuki.jpeg" alt="User avatar">
</div>
<span class="text-xs text-black">hiroyuki kaji</span>
</div>
</a>
<div class="items-center">
<span class="text-xs text-gray-500">2024.12.23</span>
</div>
</div>
</div>
</div>
もう少しツリー構造的に表現すると以下の通り。今回は「記事URL」「記事タイトル」「記事日付」を取得したいです。
<div class="grid ..."> ← 記事一覧のグリッドレイアウト(複数記事の親)
├── <div class="flex flex-col rounded"> ← カード外枠(記事1個分)
│ └── <div class="shadow-lg ..."> ← 記事カード本体(データの起点)
│ ├── <a href="/articles/~"> ← ★記事URL
│ │ ├── <div> <img ...> ← アイキャッチ画像
│ │ └── <div> <p class="text-sm"> ← ★記事タイトル
│ └── <div class="flex justify-between px-2 py-2">
│ ├── <a href="/author/..."> ← 著者名リンク
│ │ └── <span>hiroyuki kaji</span>
│ └── <span class="text-xs text-gray-500">2024.12.23</span> ← ★記事日付
│
├── <div class="flex flex-col rounded"> ← (以下、次の記事)
...
以下のアプローチで取得します。
- 著者ページ内で
<a href>の/articlesで始まるものを全て取得 - それぞれに対して、
<a>内の<p class="text-sm">から記事タイトルを取得- 親要素の
<div class="shadow-lg">内にある<span class="text-xs text-gray-500">から記事日付を取得
記事内の冒頭の挨拶
個別の記事ではこのようにheaderがあり、そこから下の一文目が取得したい部分です。
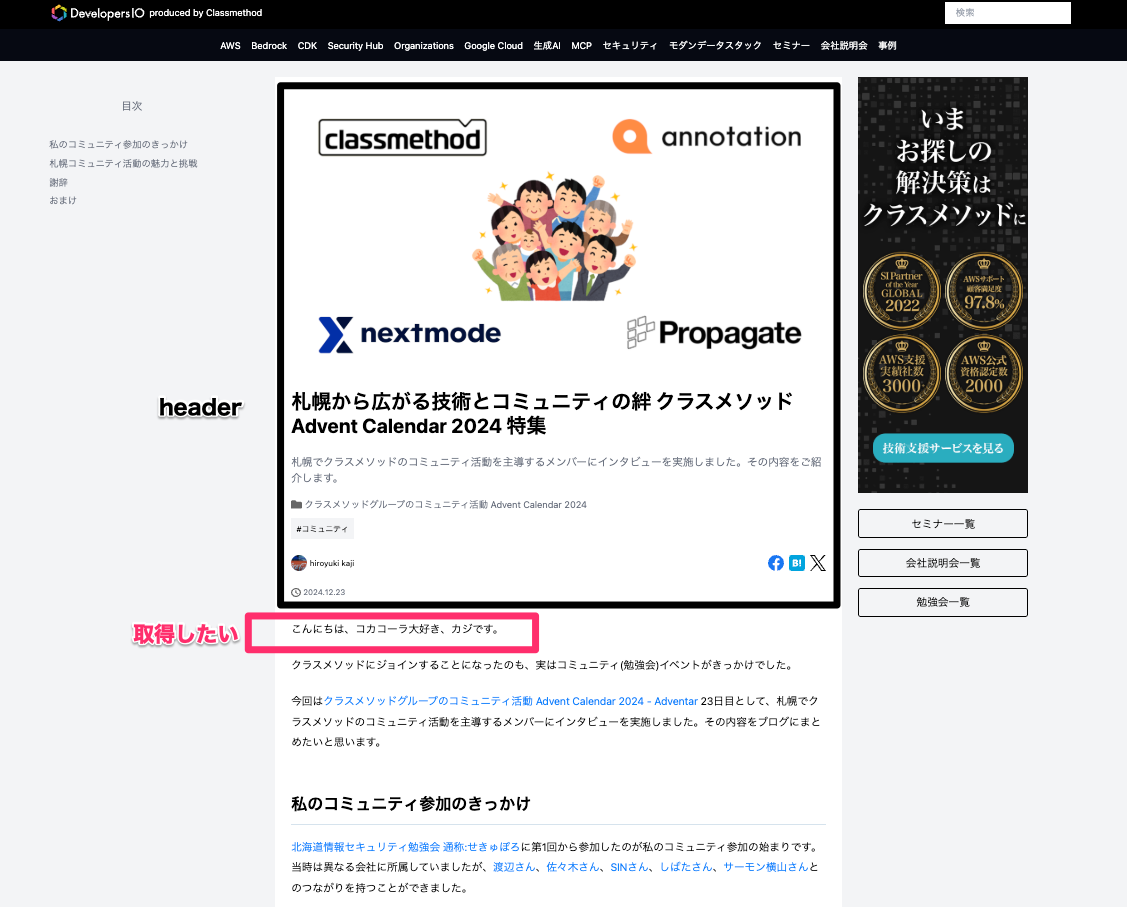
HTMLではこのような構成イメージです。(2025年6月現在)
<div class="...">
<article class="">
<header>...</header>
<div class="znc mt-8">
<p>こんにちは、コカコーラ大好き、カジです。</p>
<p>クラスメソッドにジョインすることになっ...</p>
<p>今回は Advent Calendar の23日目として、札幌の...</p>
<h2>私のコミュニティ参加のきっかけ</h2>
<p>最初は「せきゅぽろ」という勉強会への...</p>
<p>その後、札幌でAWSを使う会社としてクラ...</p>
<p>...(以下、札幌コミュニティの魅力や今後の展望について)</p>
</div>
</article>
</div>
<div class="znc mt-8">内の初めの<p>を取得します。ただ、この<p>に長い文章が含まれる場合もあるため、「です。」で終わる文章を抜き出すようなアプローチを取ります。
DevelopersIOの特定の著者ページから記事一覧と冒頭の挨拶をスクレイピングするスクリプト
以下のスクリプトを作成しました。
折りたたみ
import sys
import requests
from bs4 import BeautifulSoup
import time
import csv
from datetime import datetime
from concurrent.futures import ThreadPoolExecutor, as_completed
import re
def validate_url(url, base_url):
if not url.startswith(base_url):
print(f"The URL '{url}' is invalid or not under {base_url}")
sys.exit(1)
def extract_author_name(author_url):
return author_url.rstrip('/').split('/')[-1]
def fetch_page(session, url):
try:
response = session.get(url, timeout=10)
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Failed to fetch URL {url}: {e}")
return None
def fetch_articles(author_url):
"""
Fetch all article URLs, titles, and dates from the author's page.
Handles pagination until no more articles are found.
Returns a list of tuples: (article_url, title, date_str)
"""
BASE_URL = "https://dev.classmethod.jp"
HEADERS = {"User-Agent": "Mozilla/5.0 (compatible; ArticleScraper/1.0)"}
validate_url(author_url, BASE_URL)
articles = []
seen_urls = set()
page = 1
session = requests.Session()
session.headers.update(HEADERS)
while True:
page_url = author_url if page == 1 else f"{author_url}{page}/"
html = fetch_page(session, page_url)
if not html:
break
soup = BeautifulSoup(html, "html.parser")
anchors = soup.select('a[href^="/articles/"]')
if not anchors:
break
page_articles = []
for a in anchors:
href = a.get("href")
if not href:
continue
full_url = BASE_URL + href
if full_url in seen_urls:
continue
seen_urls.add(full_url)
title_tag = a.select_one('p.text-sm')
title = title_tag.get_text(strip=True) if title_tag else "タイトル不明"
grandparent = a.find_parent("div", class_="shadow-lg")
date_str = "日付不明"
if grandparent:
date_tag = grandparent.find("span", class_="text-xs text-gray-500")
if date_tag:
date_text = date_tag.get_text(strip=True)
m = re.search(r"(\d{4})\.(\d{2})\.(\d{2})", date_text)
if m:
# Format date as YYYY-MM-DD
date_str = f"{m.group(1)}-{m.group(2)}-{m.group(3)}"
page_articles.append((full_url, title, date_str))
if not page_articles:
break
articles.extend(page_articles)
page += 1
time.sleep(1.0)
return articles
def extract_greeting(article_info):
"""
Given a tuple of (url, title, date), fetch the article page and extract
the first greeting paragraph ending with 'です。' if possible.
Returns a tuple: (date_str, title, url, greeting)
"""
url, title, date_str = article_info
HEADERS = {"User-Agent": "Mozilla/5.0 (compatible; ArticleScraper/1.0)"}
session = requests.Session()
session.headers.update(HEADERS)
try:
response = session.get(url, timeout=10)
response.raise_for_status()
except requests.RequestException as e:
greeting = "(本文の取得に失敗しました)"
print(f"Failed to fetch article '{title}': {e}")
return date_str, title, url, greeting
soup = BeautifulSoup(response.text, "html.parser")
time.sleep(1.0)
content = soup.select_one("div.znc.mt-8 p")
full_text = content.get_text(strip=True) if content else ""
m = re.search(r"(.*?です。)", full_text)
greeting = m.group(1) if m else (full_text or "(本文が見つかりませんでした)")
return date_str, title, url, greeting
def main():
if len(sys.argv) < 2:
print("Usage: python devio_greeting_scraper.py <author_url>")
sys.exit(1)
author_url = sys.argv[1].rstrip('/') + '/'
article_infos = fetch_articles(author_url)
print(f"Fetched {len(article_infos)} articles.")
if not article_infos:
sys.exit(0)
results = []
total = len(article_infos)
done = 0
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(extract_greeting, info) for info in article_infos]
for future in as_completed(futures):
try:
result = future.result()
results.append(result)
done += 1
if done % 20 == 0 or done == total:
print(f"{done}/{total} articles processed...")
except Exception as e:
print(f"Exception during article processing: {e}")
# Sort results by date descending; unknown dates go to bottom
def sort_key(item):
date_str = item[0]
if re.match(r"\d{4}-\d{2}-\d{2}", date_str):
return datetime.strptime(date_str, "%Y-%m-%d")
return datetime.min
results.sort(key=sort_key, reverse=True)
author_name = extract_author_name(author_url)
timestamp = datetime.now().strftime("%y%m%d-%H%M%S")
filename = f"greeting-list-{author_name}-{timestamp}.csv"
try:
with open(filename, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["日付", "タイトル", "URL", "挨拶"])
for date, title, url, intro in results:
writer.writerow([date, title, url, intro])
print(f"Saved to {filename}")
except IOError as e:
print(f"Failed to write CSV file: {e}")
if __name__ == "__main__":
main()
スクリプトの概要は以下です。
-
著者URLの検証と初期化
- コマンドライン引数から DevIO 著者ページのURLを受け取る
- https://dev.classmethod.jp ドメイン下かどうかをチェック(不正なら即終了)
- HTTPセッションを作成し、User-Agent を明示的に設定して以降の通信に使う
-
著者ページをクロールして記事一覧を取得
- 著者ページを1ページ目から順に巡回(/1/, /2/, …)し、ページネーションを処理
- 各ページで記事リンク(/articles/...)と記事タイトル、日付(例: 2024.03.10)を抽出
- すでに収集済みのURLを seen_urls セットで管理し、重複を排除
- 記事情報を (URL, タイトル, 日付) の形式でリストに追加
-
各記事の本文から「〜です。」で終わる挨拶文を抽出
- 記事URLをひとつずつ HTTP GET で取得し、HTMLをパース
- 最初の
<p>要素から、正規表現で〜です。という文を探す - 該当文が見つからなければ段落全体またはスタブテキストを挿入
- エラー時(タイムアウト・404等)は「本文の取得に失敗しました」と記録
-
並列実行で本文処理を高速化
ThreadPoolExecutorを使って、複数の記事本文の抽出を並列実行- 各タスクの実行完了を
as_completedで待機し、順次リストに結果を追加 - スレッド数は最大5(
max_workers=5)に制限し過負荷を防止
-
抽出結果をCSVで保存
- 挨拶文付き記事リストを日付降順でソート(不明な日付は末尾に)
- 著者名とタイムスタンプを含んだファイル名(例:
blog-list-tanaka-250620-143012.csv)で保存 - CSVの1行目はヘッダー、以降は
[日付, タイトル, URL, 挨拶文]の形式で出力
DevelopersIOの特定の著者ページから記事一覧と冒頭の挨拶をスクレイピングしてみた
スクリプトを実行してみます。
macOSでの場合。
# 事前の準備
% python3 -m venv venv
% source venv/bin/activate
(venv) % pip install requests beautifulsoup4
#実行
(venv) % python devio_greeting_scraper.py https://dev.classmethod.jp/author/kaji-hiroyuki/
AWS CloudShellでの場合。
# 事前の準備
$ pip install requests beautifulsoup4
# 実行
$ python devio_greeting_scraper.py https://dev.classmethod.jp/author/kaji-hiroyuki/
以下のようにメッセージが表示され、最終的にCSVに結果が出力されます。
Fetched 154 articles.
20/154 articles processed...
40/154 articles processed...
60/154 articles processed...
80/154 articles processed...
100/154 articles processed...
120/154 articles processed...
140/154 articles processed...
154/154 articles processed...
Saved to greeting-list-kaji-hiroyuki-250623-161632.csv
できあがったCSVの内訳は以下のようになっています。
日付,タイトル,URL,挨拶
2025-06-18,[アップデート] Amazon Certificate Managerで証明書がエクスポートできるようになりました,https://dev.classmethod.jp/articles/amazon-certificate-manager-export-certificate-file/,こんにちはコカコーラ大好きカジです。
2025-06-18,[プレビュー] AWS Shield Network Security Director(Preview)が発表されました,https://dev.classmethod.jp/articles/aws-shield-network-security-director-preview/,コカコーラ大好き、カジです。
2025-06-18,AWS re:Inforce 2025 EXPOを写真で紹介 #AWSreInforce,https://dev.classmethod.jp/articles/aws-reinforce-2025-expo/,こんにちはコカコーラ大好きカジです。
2025-06-18,[アップデート] AWS Network Firewallにてアクティブ脅威防御のサポート,https://dev.classmethod.jp/articles/aws-network-firewall-active-threat-defense/,こんにちはコカコーラ大好きカジです。
2025-06-17,[レポート] Scaling security with Sportsbet's Security Guardians program #APS204 #AWSreInforce,https://dev.classmethod.jp/articles/aws-reinforce-2025-Sportsbets-Security-Guardians-program-aps204/,こんにちは、コカコーラ大好きカジです。
...
ちょっともう面白いですね。
CSVファイルを対象にDuckDBでクエリする
出力されたCSVファイルに対してDuckDBでクエリしていきます。
DuckDBのインストールとテーブルの作成
お使いの環境に合わせてインストールします。
macOSの場合はbrewでインストールできます。
% brew install duckdb
AWS CloudShellの場合は、インストールスクリプトを実行します。
$ curl https://install.duckdb.org | sh
スクリプトの実行イメージ
$ curl https://install.duckdb.org | sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 3268 100 3268 0 0 12048 0 --:--:-- --:--:-- --:--:-- 12014
*** DuckDB Linux/MacOS installation script, version 1.3.1 ***
.;odxdl,
.xXXXXXXXXKc
0XXXXXXXXXXXd cooo:
,XXXXXXXXXXXXK OXXXXd
0XXXXXXXXXXXo cooo:
.xXXXXXXXXKc
.;odxdl,
######################################################################## 100.0%
Successfully installed DuckDB binary to /home/cloudshell-user/.duckdb/cli/1.3.1/duckdb
with a link from /home/cloudshell-user/.duckdb/cli/latest/duckdb
Hint: Append the following line to your shell profile:
export PATH='/home/cloudshell-user/.duckdb/cli/latest':$PATH
To launch DuckDB now, type
/home/cloudshell-user/.duckdb/cli/latest/duckdb
duckdbと打ってDというプロンプトが表示されたらクエリ実行可能な状態です。
$ duckdb
DuckDB v1.3.1 (Ossivalis) 2063dda3e6
Enter ".help" for usage hints.
Connected to a transient in-memory database.
Use ".open FILENAME" to reopen on a persistent database.
D
出力されたCSVを対象にテーブルを作成します。
D CREATE TABLE blogs AS SELECT * FROM read_csv_auto('greeting-list-kaji-hiroyuki-250623-162728.csv');
テーブルの内訳はこのようになっています。
D DESCRIBE blogs;
┌─────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├─────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ 日付 │ DATE │ YES │ NULL │ NULL │ NULL │
│ タイトル │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ URL │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ 挨拶 │ VARCHAR │ YES │ NULL │ NULL │ NULL │
└─────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘
以降はblogsというテーブルがある前提で記します。
DuckDBでさまざまなクエリを実行する
挨拶ごとの件数をクエリしてみます。挨拶文中に「梶」か「カジ」を含まないものは「その他」に分類します。
D SELECT
CASE
WHEN 挨拶 LIKE '%梶%' OR 挨拶 LIKE '%カジ%' THEN 挨拶
ELSE 'その他'
END AS 挨拶分類,
COUNT(*) AS 件数
FROM blogs
GROUP BY 挨拶分類
ORDER BY 件数 DESC;
┌───────────────────────────────────────────────────────────────────────────────┬───────┐
│ 挨拶分類 │ 件数 │
│ varchar │ int64 │
├───────────────────────────────────────────────────────────────────────────────┼───────┤
│ こんにちは、コカコーラ大好きカジです。 │ 43 │
│ こんにちはコカコーラ大好きカジです。 │ 15 │
│ こんにちは、コカコーラが大好きなカジです。 │ 14 │
│ その他 │ 10 │
│ こんにちは、コカコーラ好きのカジです。 │ 8 │
│ こんにちは、梶です。 │ 8 │
│ こんにちはコカコーラ大好き、カジです。 │ 8 │
│ こんにちは、コカコーラ好きなカジです。 │ 7 │
│ こんにちは、コカコーラ大好き、カジです。 │ 6 │
│ こんにちは、コカコーラ好きの梶です。 │ 4 │
│ コカコーラ大好き、カジです。 │ 4 │
│ コカコーラが大好きな梶です。 │ 3 │
│ コカコーラが大好きなカジです。 │ 3 │
│ こんにちはコカコーラ好きな梶です。 │ 2 │
│ こんにちは、コカ・コーラが大好きなカジです。 │ 2 │
│ こんにちはコカコーラ好きのカジです。 │ 2 │
│ こんにちは梶です。 │ 1 │
│ こんにちは。コカコーラ好きのカジです。 │ 1 │
│ コカコーラが大好きな、カジです。 │ 1 │
│ こんにちは。コカコーラが大好きなカジです。 │ 1 │
│ こんにちは。コカコーラ大好き、カジです。 │ 1 │
│ コカコーラ好きのカジです。 │ 1 │
│ こんにちは。コカコーラ大好きカジです。 │ 1 │
│ こんにちは。コーラ好きの梶です。 │ 1 │
│ 2014年8月1日付けで入社しました、梶 浩幸と申します。よろしくお願いいたします。 │ 1 │
│ こんにちは、コカコーラをこよなく愛するカジです。 │ 1 │
│ こんばんわ、コカコーラ大好き カジです。 │ 1 │
│ コカコーラ大好きカジです。 │ 1 │
│ こんにちは、コカコーラ大好き カジです。 │ 1 │
│ こんにちは。コカコーラ好きの梶です。 │ 1 │
│ こんにちは。コカコーラを大好きなカジです。 │ 1 │
├───────────────────────────────────────────────────────────────────────────────┴───────┤
│ 31 rows 2 columns │
└───────────────────────────────────────────────────────────────────────────────────────┘
「コカコーラ」と何回言ったのかをカウントします。
D SELECT COUNT(*) AS 件数
FROM blogs
WHERE 挨拶 LIKE '%コカコーラ%';
┌───────┐
│ 件数 │
│ int64 │
├───────┤
│ 131 │
└───────┘
「大好き」と「好き」がそれぞれ何回登場したのかをカウントします。
D SELECT
COUNT(*) FILTER (WHERE 挨拶 LIKE '%大好き%') AS 大好き件数,
COUNT(*) FILTER (WHERE 挨拶 LIKE '%好き%' AND 挨拶 NOT LIKE '%大好き%') AS 好き件数
FROM blogs;
┌────────────┬──────────┐
│ 大好き件数 │ 好き件数 │
│ int64 │ int64 │
├────────────┼──────────┤
│ 106 │ 27 │
└────────────┴──────────┘
「コカコーラ大好き」と何回言ったのかをカウントします。
D SELECT COUNT(*) AS コカコーラ大好き件数
FROM blogs
WHERE 挨拶 LIKE '%コカコーラ大好き%';
┌──────────────────────┐
│ コカコーラ大好き件数 │
│ int64 │
├──────────────────────┤
│ 81 │
└──────────────────────┘
81回でした!!(2025/06/24現在)
年ごとの「コカコーラ大好き」件数を表示します。
D SELECT
strftime('%Y', 日付) AS 年,
COUNT(*) AS コカコーラ大好き件数
FROM blogs
WHERE 挨拶 LIKE '%コカコーラ大好き%'
GROUP BY 年
ORDER BY 年;
┌─────────┬──────────────────────┐
│ 年 │ コカコーラ大好き件数 │
│ varchar │ int64 │
├─────────┼──────────────────────┤
│ 2016 │ 5 │
│ 2017 │ 7 │
│ 2018 │ 8 │
│ 2019 │ 14 │
│ 2020 │ 15 │
│ 2021 │ 9 │
│ 2022 │ 1 │
│ 2023 │ 7 │
│ 2024 │ 10 │
│ 2025 │ 5 │
├─────────┴──────────────────────┤
│ 10 rows 2 columns │
└────────────────────────────────┘
年ごとの「コカコーラ大好き」「コカコーラ好き」件数を集計します。
D SELECT
strftime('%Y', 日付) AS 年,
COUNT(*) FILTER (WHERE 挨拶 LIKE '%コカコーラ大好き%') AS コカコーラ大好き件数,
COUNT(*) FILTER (WHERE 挨拶 LIKE '%コカコーラ好き%' AND 挨拶 NOT LIKE '%大好き%') AS コカコーラ好き件数
FROM blogs
GROUP BY 年
ORDER BY 年;
┌─────────┬──────────────────────┬────────────────────┐
│ 年 │ コカコーラ大好き件数 │ コカコーラ好き件数 │
│ varchar │ int64 │ int64 │
├─────────┼──────────────────────┼────────────────────┤
│ 2014 │ 0 │ 0 │
│ 2015 │ 0 │ 19 │
│ 2016 │ 5 │ 0 │
│ 2017 │ 7 │ 6 │
│ 2018 │ 8 │ 1 │
│ 2019 │ 14 │ 0 │
│ 2020 │ 15 │ 0 │
│ 2021 │ 9 │ 0 │
│ 2022 │ 1 │ 0 │
│ 2023 │ 7 │ 0 │
│ 2024 │ 10 │ 0 │
│ 2025 │ 5 │ 0 │
├─────────┴──────────────────────┴────────────────────┤
│ 12 rows 3 columns │
└─────────────────────────────────────────────────────┘
年ごとの「カジ」「梶」件数をあらわにします。
D SELECT
strftime('%Y', 日付) AS 年,
COUNT(*) FILTER (WHERE 挨拶 LIKE '%カジ%') AS カジ件数,
COUNT(*) FILTER (WHERE 挨拶 LIKE '%梶%') AS 梶件数
FROM blogs
GROUP BY 年
ORDER BY 年;
┌─────────┬──────────┬────────┐
│ 年 │ カジ件数 │ 梶件数 │
│ varchar │ int64 │ int64 │
├─────────┼──────────┼────────┤
│ 2014 │ 0 │ 11 │
│ 2015 │ 23 │ 10 │
│ 2016 │ 11 │ 0 │
│ 2017 │ 13 │ 0 │
│ 2018 │ 9 │ 0 │
│ 2019 │ 14 │ 0 │
│ 2020 │ 17 │ 0 │
│ 2021 │ 11 │ 0 │
│ 2022 │ 3 │ 0 │
│ 2023 │ 7 │ 0 │
│ 2024 │ 10 │ 0 │
│ 2025 │ 5 │ 0 │
├─────────┴──────────┴────────┤
│ 12 rows 3 columns │
└─────────────────────────────┘
満足しました。
副産物:DevelopersIOの特定の著者ページから記事一覧をスクレイピングするスクリプト
「ページ一覧を取得しページごとに冒頭の挨拶を取得する」というスクリプトを作る中で、単に「ページ一覧を取得する」スクリプトもできました。
わざわざ挨拶を取得したい人はそうそういないと思うので、こちらのスクリプトの方が使い所は多いかもしれません。
折りたたみ
# Script to scrape article metadata (date, title, URL) from a given author's page on dev.classmethod.jp and save it to a CSV file.
import requests
from bs4 import BeautifulSoup
import csv
import sys
import re
from datetime import datetime
import time
from urllib.parse import urlparse
def validate_url(url):
"""URLが有効なdev.classmethod.jpのURLかを検証"""
parsed = urlparse(url)
return parsed.netloc == "dev.classmethod.jp" and parsed.scheme in ["http", "https"]
def extract_author_name(author_url):
"""URLから著者名を抽出"""
author_match = re.search(r'/author/([^/]+)/?', author_url)
if not author_match:
raise ValueError("Invalid author URL format")
return author_match.group(1)
def fetch_page(session, url):
"""指定されたURLからページを取得"""
try:
headers = {
"User-Agent": "Mozilla/5.0 (compatible; ArticleMetadataScraper/1.0)"
}
response = session.get(url, headers=headers, timeout=10)
response.raise_for_status()
return response.text
except requests.exceptions.RequestException as e:
print(f"Error fetching {url}: {e}")
return None
def parse_article_data(block):
"""記事ブロックからメタデータを抽出"""
a_tag = block.find("a", href=True)
if not a_tag:
return None
href = a_tag.get("href", "").strip()
article_url = "https://dev.classmethod.jp" + href
title_tag = block.select_one("p.text-sm")
title = title_tag.get_text(strip=True) if title_tag else ""
date_tag = block.select_one("span.text-xs.text-gray-500")
pub_date_raw = date_tag.get_text(strip=True) if date_tag else ""
try:
pub_date_cleaned = pub_date_raw.replace(".", "/")
pub_date = datetime.strptime(pub_date_cleaned, "%Y/%m/%d").strftime("%Y-%m-%d")
except ValueError:
pub_date = pub_date_raw
return {
"date": pub_date,
"title": title,
"url": article_url
}
def fetch_article_urls(author_url, max_pages=100):
"""著者ページから記事URLを取得"""
if not validate_url(author_url):
raise ValueError("Invalid URL provided")
http = requests.Session()
articles = []
page_num = 1
try:
author_name = extract_author_name(author_url)
except ValueError as e:
print(f"Error: {e}")
return [], "unknown_author"
seen_urls = set()
while page_num <= max_pages:
url = author_url if page_num == 1 else f"{author_url.rstrip('/')}/{page_num}/"
print(f"Scraping page {page_num}...")
html_content = fetch_page(http, url)
if not html_content:
break
soup = BeautifulSoup(html_content, "html.parser")
article_blocks = soup.select('div.shadow-lg')
new_articles = []
for block in article_blocks:
article_data = parse_article_data(block)
if article_data and article_data["url"] not in seen_urls:
seen_urls.add(article_data["url"])
new_articles.append(article_data)
if not new_articles:
print(f"Found {len(articles)} articles in total. Finishing.")
break
articles.extend(new_articles)
page_num += 1
time.sleep(1)
return articles, author_name
def save_to_csv(articles, author_name):
"""記事メタデータをCSVに保存"""
if not articles:
print("No articles found.")
return
timestamp = datetime.now().strftime("%y%m%d-%H%M%S")
filename = f"blog-list-{author_name}-{timestamp}.csv"
try:
with open(filename, "w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["date", "title", "url"])
writer.writeheader()
for article in articles:
writer.writerow(article)
print(f"Scraping completed. Metadata saved to {filename}")
except IOError as e:
print(f"Error writing to CSV file: {e}")
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python scrape_metadata.py <author_url>")
sys.exit(1)
author_url = sys.argv[1]
try:
articles, author_name = fetch_article_urls(author_url)
save_to_csv(articles, author_name)
except Exception as e:
print(f"An error occurred: {e}")
sys.exit(1)
必要とするライブラリは先述のものと同様です。このような実行イメージです。
% python devio_bloglist_by_author.py https://dev.classmethod.jp/author/kaji-hiroyuki/
Scraping page 1...
Scraping page 2...
Scraping page 3...
Scraping page 4...
Found 154 articles in total. Finishing.
Scraping completed. Metadata saved to blog-list-kaji-hiroyuki-250623-161814.csv
日付、タイトル、URLの一覧が取得されます。
date,title,url
2025-06-18,AWS re:Inforce 2025 EXPOを写真で紹介 #AWSreInforce,https://dev.classmethod.jp/articles/aws-reinforce-2025-expo/
2025-06-18,[プレビュー] AWS Shield Network Security Director(Preview)が発表されました,https://dev.classmethod.jp/articles/aws-shield-network-security-director-preview/
2025-06-18,[アップデート] AWS Network Firewallにてアクティブ脅威防御のサポート,https://dev.classmethod.jp/articles/aws-network-firewall-active-threat-defense/
2025-06-18,[アップデート] Amazon Certificate Managerで証明書がエクスポートできるようになりました,https://dev.classmethod.jp/articles/amazon-certificate-manager-export-certificate-file/
2025-06-17,[レポート] Scaling security with Sportsbet's Security Guardians program #APS204 #AWSreInforce,https://dev.classmethod.jp/articles/aws-reinforce-2025-Sportsbets-Security-Guardians-program-aps204/
2024-12-23,札幌から広がる技術とコミュニティの絆 クラスメソッド Advent Calendar 2024 特集,https://dev.classmethod.jp/articles/advent-calendar-2024-sapporo-technology-and-community/
2024-12-07,レポート COP381-NEW [NEW LAUNCH] What's new with Amazon CloudWatch,https://dev.classmethod.jp/articles/reinvent2024-report-COP381-NEW/
2024-12-06,レポート STG217-NEW [NEW LAUNCH] Simplify file sharing with AWS Transfer Family no-code web apps #STG217-NEW #AWSreInvent,https://dev.classmethod.jp/articles/reinvent2024-report-stg217-new/
...
まとめ
- 梶さんは「コカコーラ大好き」と過去に81回言及した
- 2019年〜2020年にかけて「大好き」の成長フェーズを迎えた
- 梶さんの最もスタンダードな挨拶は「こんにちは、コカコーラ大好きカジです。」
- 2016年を境に梶さんは「梶」ではなく「カジ」を名乗るようになった
- 一度だけコカコーラに対しての愛を述べたことがある
終わりに
BeautifulSoupを用いたWebスクレイピングとDuckDBによるクエリで同僚の挨拶を分析してみました。
特に、気になっていたDuckDBを初めて触ってみたので楽しかったです。インストールから実行まで簡単で、便利さを感じました。触ってみるきっかけがあってよかったです。
梶さん、コーラの飲み過ぎには気をつけてくださいね。
以上、チバユキ (@batchicchi)がお送りしました。










