
複数のAmazon Bedrock Knowledge Baseで同じOpenSearch Serverless Collectionを共有する
はじめに
Amazon Bedrock Knowledge Base(以下 KB)でベクトルストアに Amazon OpenSearch Serverless(以下 OSS)を選ぶと、Collection 1つあたり月額 $700+ の固定費が発生します。
OpenSearch Serverless の最低課金: 4 OCU(Indexing 2 OCU + Search 2 OCU)× 約 $0.24/hour ≒ 月 $700+
KB を 1 つしか作らない場合は仕方ないとして、同じプロジェクトの中で 2 つ目、3 つ目の KB を追加するたびに新しい Collection を立てると、そのたびに月額 $700+ がスタックしていきます。
実は、1 つの OSS Collection を複数の KB で共有することで、固定費の二重・三重発生を回避できます。本記事では、既存 KB が稼働中の環境に新しい KB を追加するケースで、Collection を共有する手順をやってみました。
用語整理(最重要)
OSS の構造を最初に確認しておきます。ここの理解が曖昧だと後の手順で混乱します。
OpenSearch Serverless
└── Collection(コレクション) ← 課金単位・トップレベルリソース
├── Index A(ベクトルインデックス) ← Knowledge Base A 用
├── Index B(ベクトルインデックス) ← Knowledge Base B 用
└── Index C(ベクトルインデックス) ← Knowledge Base C 用
- Collection: OSS の物理リソース。作成すると月額 $700+ の固定費が発生
- Index: Collection 内の論理的なデータストア。1 KB あたり 1 Index が必要
- Bedrock KB 1 つにつき紐づくのは Index 1 つ(Collection ではない)
つまり「KB ごとに Collection を立てる」のではなく、「Collection を 1 つ立てて、KB ごとに Index を別に持つ」構成にすれば、固定費は Collection 1 つ分で済みます。
構成のイメージ
before(KB を増やすたびに Collection を立てる構成):
KB A → Collection A(月 $700+)
KB B → Collection B(月 $700+) ← 追加で発生
KB C → Collection C(月 $700+) ← さらに追加で発生
after(Collection を共有する構成):
KB A ┐
KB B ┼→ Collection(月 $700+)
KB C ┘
KB が増えても固定費は Collection 1 つ分のまま。Index 単位で OCU 使用量に比例した従量課金は微増しますが、固定費の二重発生に比べれば誤差レベルです。
やってみた
既存 KB が稼働している環境に、2 つ目の KB を追加するケースで実施しました。流れは以下の通りです。
[1] 事前確認(既存 Collection の情報収集)
↓
[2] KB ウィザード起動 → ロール ARN 取得 → Data Access Policy 更新(2 タブ並行)
↓
[3] OpenSearch Dashboards で新 Index 作成(タブ 2 で継続)
↓
[4] タブ 1 のウィザードに戻り KB 作成を完了
↓
[5] データソース同期 + 動作確認
所要時間は合計 30 分程度(データインジェスト量による)でした。
Step 1: 既存 Collection の情報収集
以下の 2 箇所からそれぞれ情報を収集します。
OSS コンソールで確認する情報
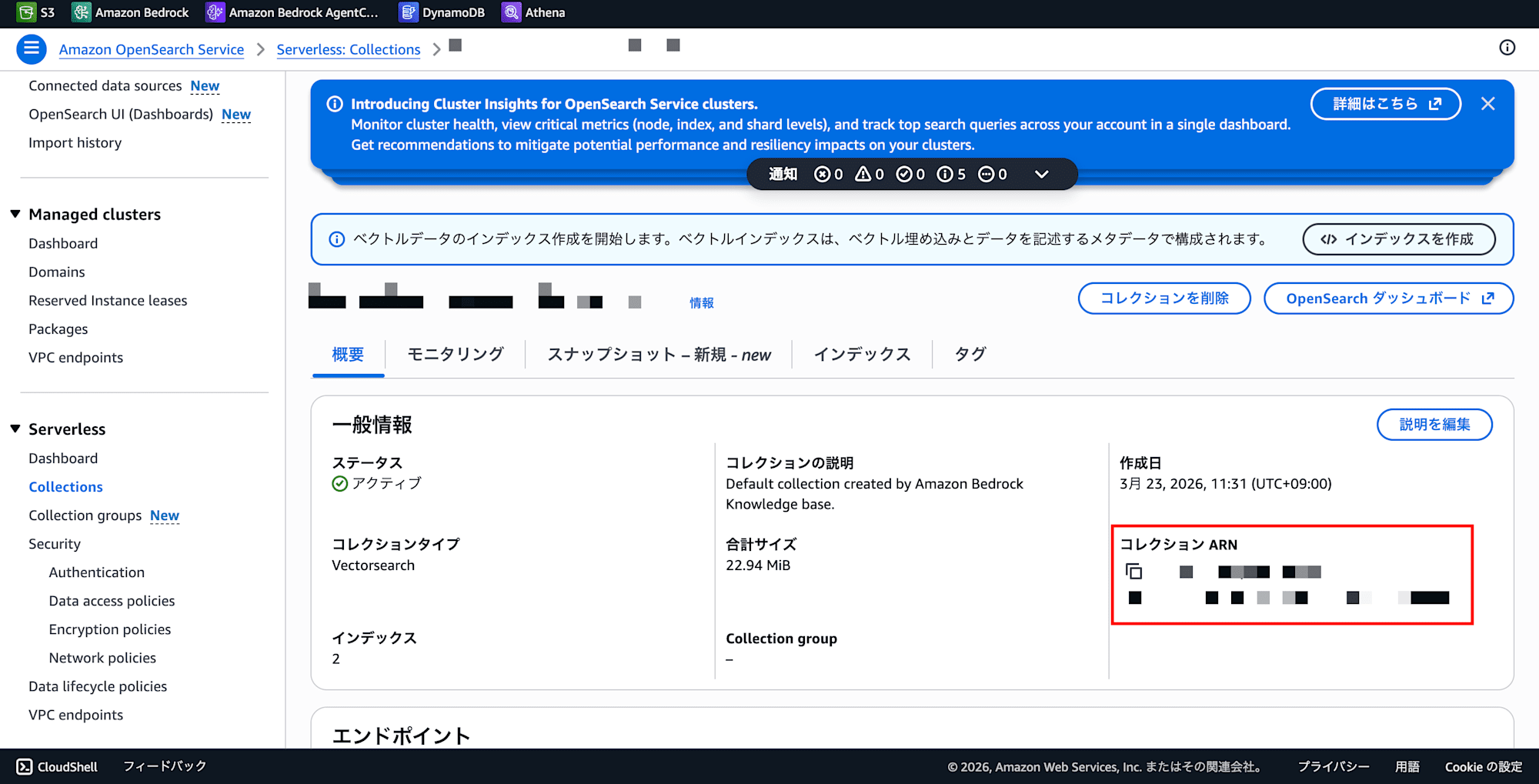
Collection ARN と Index 名:
- OpenSearch Service コンソール → サーバーレス → コレクション
- 対象の Collection をクリック → 詳細画面で Collection ARN をコピー
- 「インデックス」タブを開き、既存の Index 名 をメモ(新規 Index はこれと別名にする)
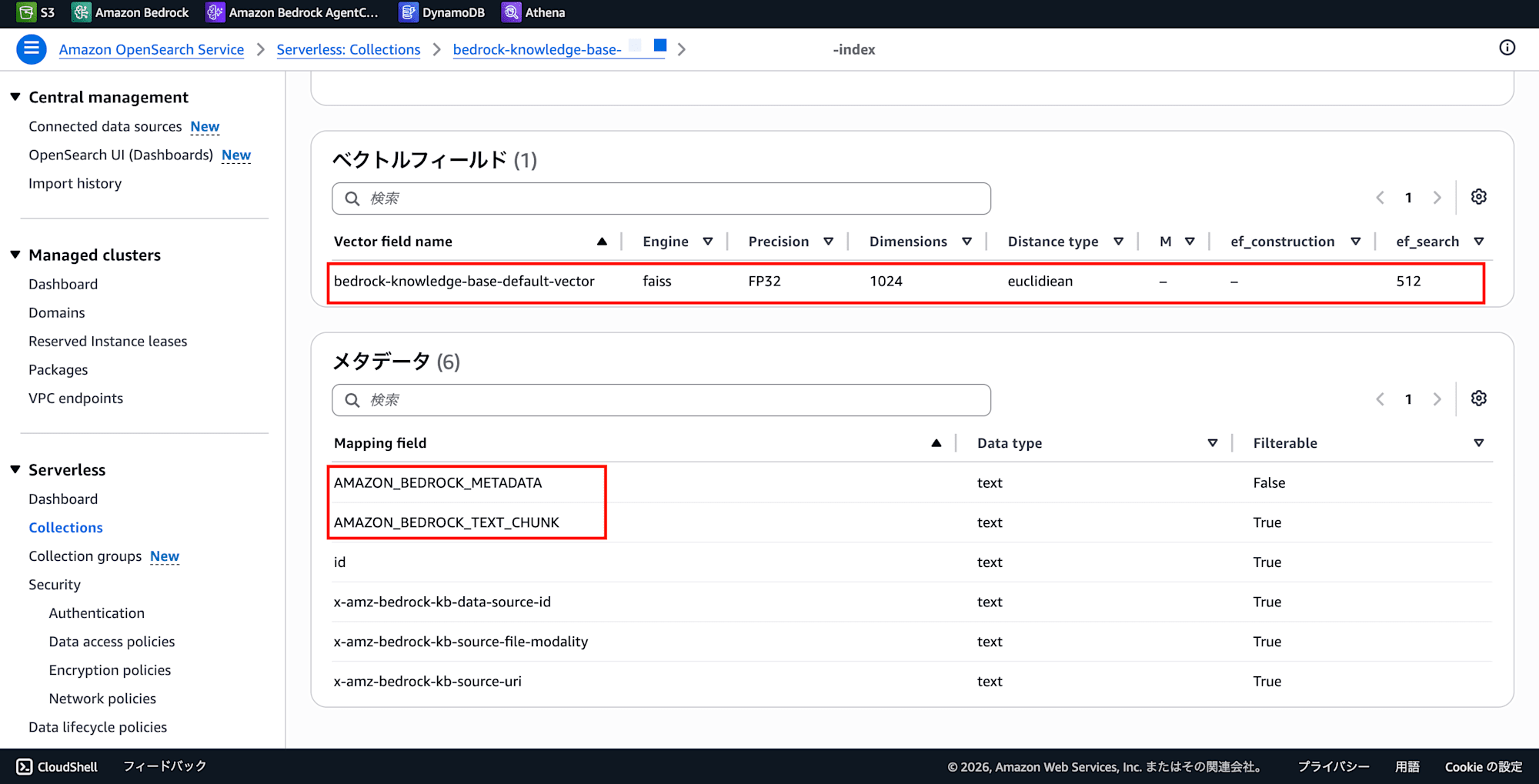
フィールドマッピング:
- 「インデックス」タブで既存 Index 名をクリック
- Index 詳細画面に「ベクトルフィールド」と「メタデータ」セクションが表示される
- 以下をメモ(Bedrock のデフォルト命名の場合)
- ベクトルフィールド:
bedrock-knowledge-base-default-vector(dimension も確認) - テキストフィールド:
AMAZON_BEDROCK_TEXT_CHUNK - メタデータフィールド:
AMAZON_BEDROCK_METADATA
- ベクトルフィールド:
Bedrock コンソールで確認する情報
埋め込みモデル:
- Bedrock コンソール → ナレッジベース → 既存 KB をクリック
- 「設定」タブで埋め込みモデル(例: Titan Text Embeddings v2、dimension: 1024)を確認
新規 KB でも同じフィールド命名を使うと手順書を使い回せるので、既存 KB の設定に揃えるのがおすすめです。
Step 2: ロール ARN 取得と Data Access Policy 更新
OSS の Data Access Policy は「どの IAM ロールが、どの Collection / Index に、どんな権限でアクセスできるか」を定義するポリシーです。新しく作る KB のサービスロールも、ここに登録されていないと Index にアクセスできません。
ところが、Bedrock KB のサービスロールはウィザードで KB を作成するときに自動生成されるため、KB 作成前にロール ARN がわかりません。鶏と卵の問題です。
これを解決するには、KB 作成ウィザードを途中まで進めてロール ARN を先取りする方法があります。ウィザードはステップ 1(KB 名と IAM 許可)で「新しいサービスロールを作成」を選択した時点で、作成予定のロール名を画面に表示します。
ブラウザで 2 つのタブを並べて作業します。
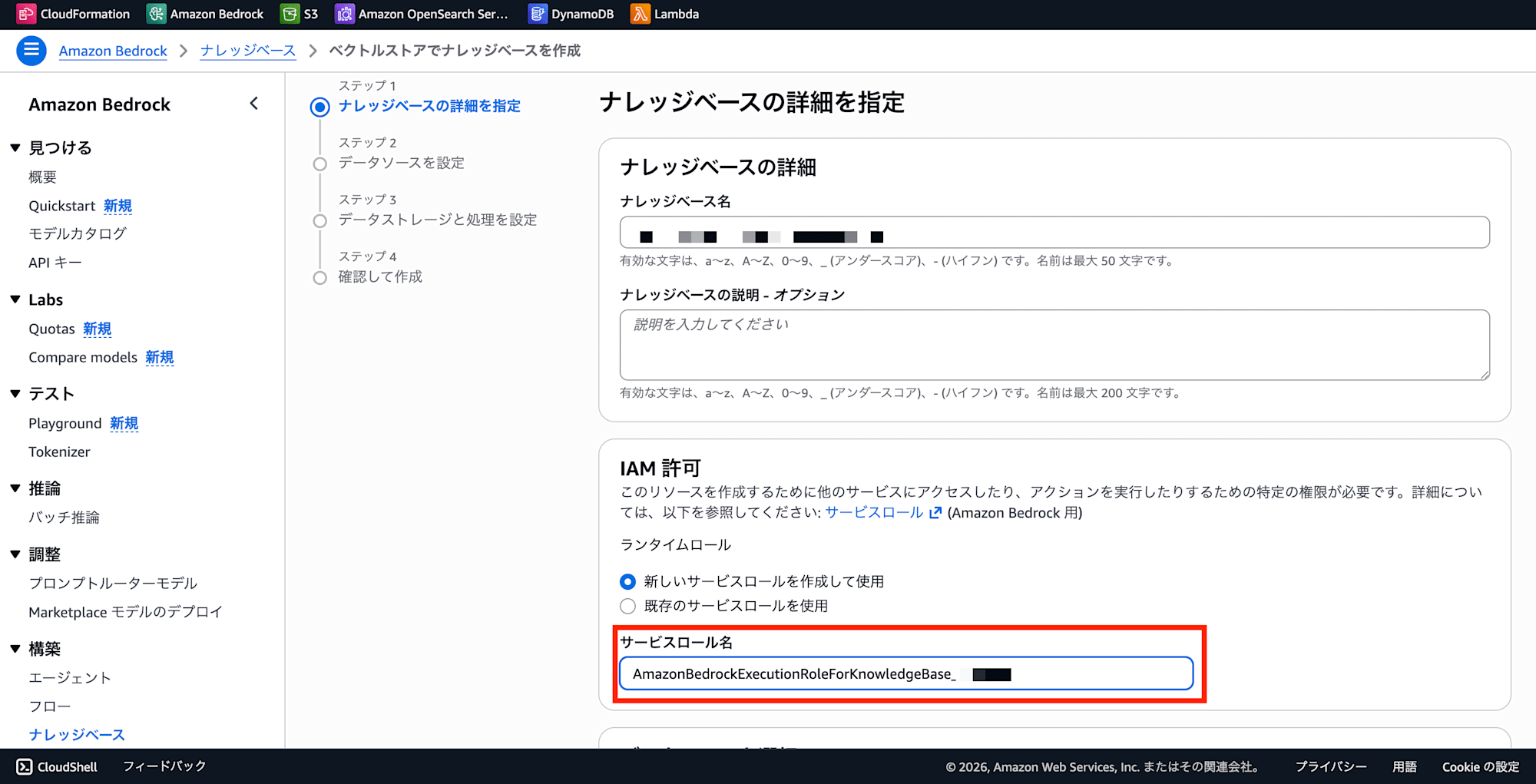
【タブ 1】Bedrock コンソール
- ナレッジベース → 「ベクトルストアを含むナレッジベース」を作成
- ステップ 1 で「新しいサービスロールを作成」を選択 → 表示されるロール名(
AmazonBedrockExecutionRoleForKnowledgeBase_xxxx)をコピー - ウィザードはここで一時停止(タブを閉じない)
【タブ 2】OpenSearch Service コンソール
- サーバーレス → データアクセスポリシー → 既存 Collection に紐づくポリシーを選択 → 編集
- プリンシパル欄にタブ 1 でコピーしたロール ARN を追加して保存
arn:aws:iam::{アカウントID}:role/service-role/AmazonBedrockExecutionRoleForKnowledgeBase_xxxx
なお、Index 作成のために自分自身のロール(IAM ユーザー or 作業用 Admin ロール)も一時的に追加しておくと、後の Step 3 で OpenSearch Dashboards にアクセスできるようになります。
arn:aws:iam::{アカウントID}:role/{自分のロール名}
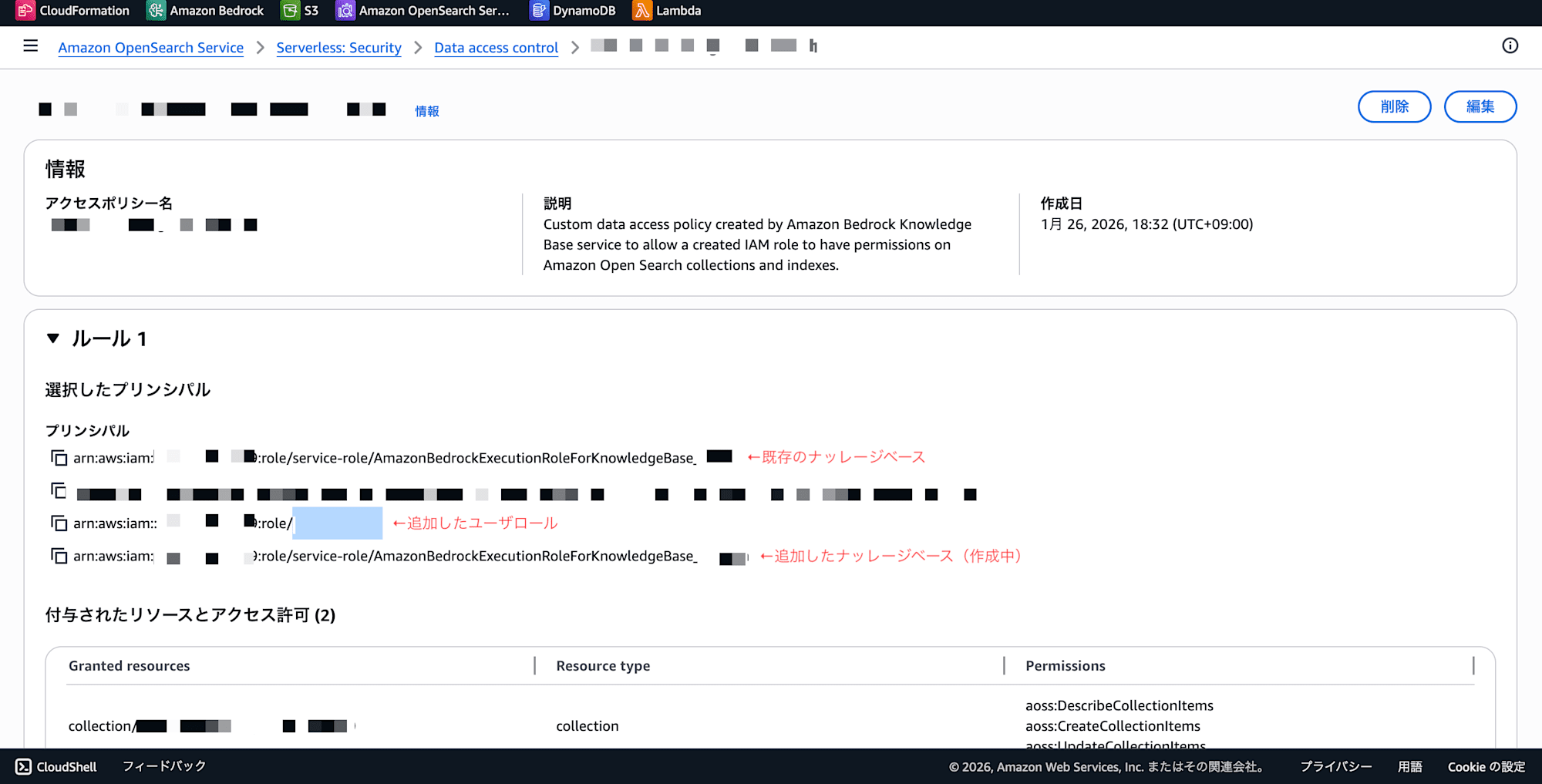
作業完了後、自分のロールはポリシーから削除しておくと最小権限の原則に沿います。
タブ 2 で Step 3(Index 作成)まで完了させてから、タブ 1 のウィザードに戻って残りのステップを進めます。
Step 3: OpenSearch Dashboards で新 Index 作成
【タブ 2 の作業】 Step 2 でタブ 1 を一時停止している間に、引き続きタブ 2 で Index を作成します。
Bedrock の「既存のベクトルストアを使用」オプションは、Index が事前に作成されていることを前提としています。Bedrock 側では Index は作ってくれないので、自分で作る必要があります。

- タブ 2(OSS コンソール)で対象の Collection をクリック → 「OpenSearch Dashboards URL」をクリック
- 以下の API リクエストを実行
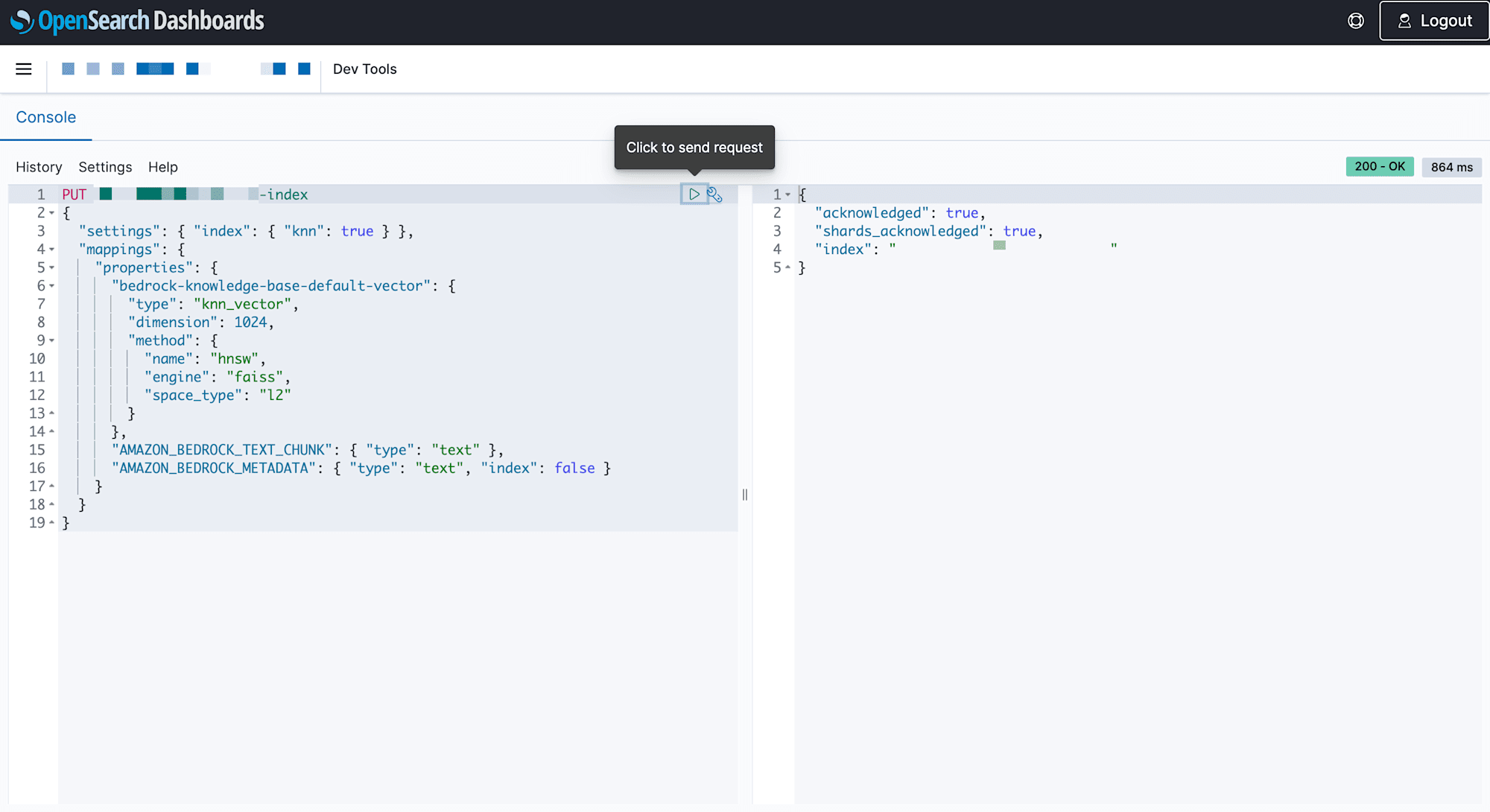
PUT new-rag-index
{
"settings": {
"index": {
"knn": true,
"knn.algo_param.ef_search": 512
}
},
"mappings": {
"properties": {
"bedrock-knowledge-base-default-vector": {
"type": "knn_vector",
"dimension": 1024,
"method": {
"name": "hnsw",
"engine": "faiss",
"space_type": "l2"
}
},
"AMAZON_BEDROCK_TEXT_CHUNK": {
"type": "text"
},
"AMAZON_BEDROCK_METADATA": {
"type": "text",
"index": false
}
}
}
}
ポイント:
dimension: 1024は Titan Text Embeddings v2 の次元数。使う埋め込みモデルに合わせて変更- フィールド名は Bedrock のデフォルト命名に揃える(後で KB 作成時に同じ名前を指定)
- Index 名は既存 Index と重複しないこと
成功すると acknowledged: true が返ってきます。
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "new-rag-index"
}
Step 4: Bedrock KB 作成(タブ 1 のウィザードに戻る)
【タブ 1 に戻る】 Step 2 で一時停止していた Bedrock KB 作成ウィザードの続きから進めます。ステップ 1(KB 名と IAM 許可)はすでに完了しているので、ステップ 2 から再開します。
- ステップ 2: データソース(S3 バケット等)を設定
- ステップ 3: 埋め込みモデルとベクトルストア
- 埋め込みモデル: 既存 KB と同じものを選択
- ベクトルストア: 「既存のベクトルストアを使用」
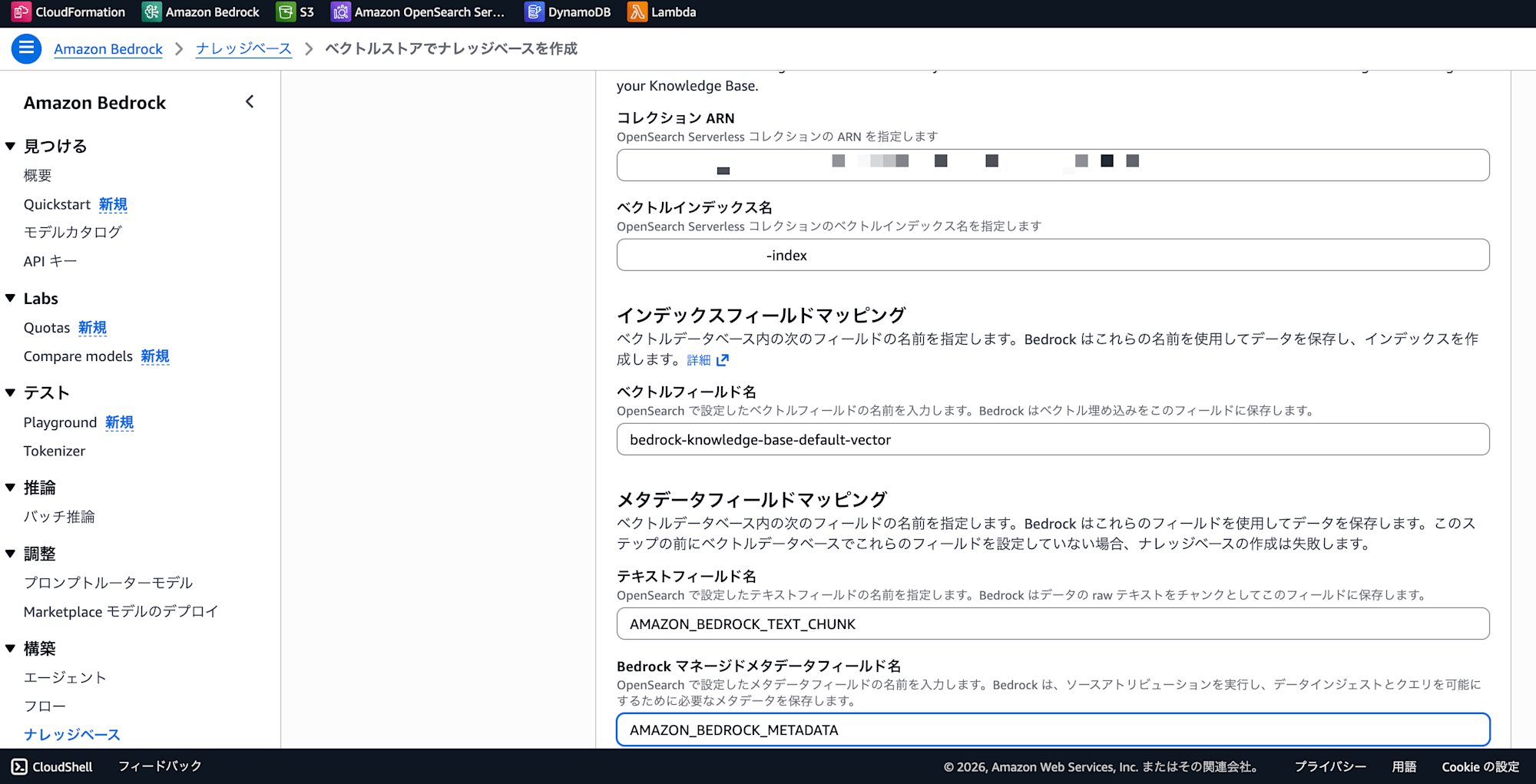
- OpenSearch Serverless を選択し、以下を入力
- Collection ARN: Step 1 でメモしたもの
- ベクトルインデックス名:
new-rag-index(Step 3 で作成した名前) - ベクトルフィールド名:
bedrock-knowledge-base-default-vector - テキストフィールド名:
AMAZON_BEDROCK_TEXT_CHUNK - メタデータフィールド名:
AMAZON_BEDROCK_METADATA
- ステップ 4: 確認して作成
KB 作成と同時に、Bedrock が AmazonBedrockExecutionRoleForKnowledgeBase_xxxx という名前のサービスロールを自動生成します。Step 2 で Data Access Policy に登録した ARN と一致するため、許可が自動で有効になります。
Step 5: データソース同期 + 動作確認
KB 作成後、データソースタブから「同期」を実行します。同期完了後、テストクエリを投げて、新 KB が期待通りに動作するか確認します。
そして重要なのが、既存 KB への影響確認です。
- 既存 KB のテストクエリも投げて、変わらず動作することを確認
- レスポンスタイムに極端な遅延がないかチェック
私が試したケースでは、新規 KB と既存 KB の両方が問題なく動作しました。Index 単位でデータと検索が完全に分離されているため、お互いの検索結果が混ざることはありません。
検証で確認できたこと
実際にやってみて確認できたポイントです。
Index 単位でデータが完全分離される
新しい Index に投入したデータは、既存 Index の検索クエリには一切ヒットしません。例えば、既存 KB が「経営数値データ」を持ち、新規 KB が「技術資料」を持っている場合、それぞれの KB が自分の Index にだけクエリを投げるため、検索結果が混ざることはありません。
これは Bedrock KB の検索 API が vectorStoreConfiguration.opensearchServerlessConfiguration.vectorIndexName で指定された Index にのみクエリを投げる仕様だからです。
既存 KB の性能・データに影響なし
新規 Index を追加しても、既存 Index の検索性能には体感できる劣化はありませんでした。OSS は OCU(OpenSearch Compute Unit)を自動スケーリングするため、Collection に Index が増えてもリソースが自動で確保されます。
ただし、データ量や検索頻度が増えれば OCU 使用量も増え、従量課金分は微増します。とはいえ、新規 Collection 作成による月額 $700+ の固定費に比べれば誤差レベルです。
ワイルドカードプリンシパルという選択肢
今回は 2 タブ操作でロール ARN を先取りして特定 ARN を登録しましたが、KB を頻繁に追加する運用では ワイルドカードプリンシパルを使う方法もあります。
Data Access Policy のプリンシパルに以下を追加しておくと、AmazonBedrockExecutionRoleForKnowledgeBase_ で始まるロールはすべて自動で許可されるため、KB を増やすたびに Data Access Policy を編集する必要がなくなります。
arn:aws:iam::{アカウントID}:role/service-role/AmazonBedrockExecutionRoleForKnowledgeBase_*
セキュリティ的には「特定のロール ARN だけ許可」のほうが厳格です。開発・検証フェーズはワイルドカード、本番環境は特定 ARN と使い分けるのが現実的です。
ハマりポイント
実際にやってみて引っかかったところをメモしておきます。
「既存のベクトルストアを使用」は Index を作ってくれない
Bedrock のウィザードに「新しいベクトルストアをクイック作成」と「既存のベクトルストアを使用」の 2 択がありますが、後者は Index が既に存在する前提で動きます。Bedrock 側が Index を作ってくれるわけではないので、Step 3 を飛ばして Step 4 に進むと「Index が見つかりません」エラーで詰まります。
Dashboards にアクセスできない
最初に Dashboards にアクセスしようとすると「You don't have authorization」と表示されることがあります。これは OSS の認可モデル上、Data Access Policy で明示的に許可されたプリンシパルしか Dashboards にアクセスできないためです。
普段使っている IAM ロールが Admin 権限を持っていても、OSS は IAM 権限とは別に Data Access Policy で認可します。自分のロールを Data Access Policy のプリンシパルに追加することで解決します。
フィールドマッピングのミス
ベクトルフィールド名・テキストフィールド名・メタデータフィールド名は、Index 作成時の mappings と KB 作成時の指定が完全に一致している必要があります。1 文字でも違うと同期が失敗するか、ベクトル検索が空を返します。
既存 KB と同じ命名(Bedrock のデフォルト)に揃えておくのが、ミスを防ぐ最も簡単な方法です。
まとめ
複数の Bedrock KB で 1 つの OpenSearch Serverless Collection を共有することで、月額固定費の二重発生を回避できることを確認しました。
ポイントは以下の通りです。
- Collection ではなく Index 単位で KB を分けることで、固定費を抑える
- KB ウィザードを 2 タブで並行操作してロール ARN を先取りし、Data Access Policy に登録してから KB 作成を完了する
- OpenSearch Dashboards で Index を事前作成してから、Bedrock の「既存のベクトルストアを使用」オプションで紐づける
- Index 単位でデータ・検索が分離されるため、既存 KB への影響なしで新規 KB を追加できる
「Bedrock KB を増やしたいけどコストが気になる」というケースに有効な構成です。RAG を本格運用するフェーズで、複数のユースケースに対応する複数 KB を運用する場合は特に効果が大きくなります。
参考になれば幸いです。









