
Splunkで外れ値検出をやってみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
データ分析において、通常と異なるパターンのデータに対してしきい値をかけて検出したり、時系列グラフなどでどれぐらい異常なのかを可視化しておきたい場面は多いかと思います。
Splunkのユースケースの一つとしてセキュリティ分析がありますが、認証のスパイクを検出したり、普段実行していない特殊なオペレーションの検出など、外れ値として注目したい場面が多いかと思います。
今回は、外れ値の検出を題材にどんな分析ができるかやってみたいと思います。
統計手法で基本的なものから順に理解しながら外れ値の設定方法を試してみます。
Splunkの基本的な統計コマンドについては、本記事ではご紹介しておりませんのでご承知おきください。
尚、サンプルデータは下記のデータをもとに検証しております。
平均値と移動平均からデータの移り変わりを分析する
平均値をもとに時系列の中でデータがどのように移り変わっているかを分析します。
移動平均を使ってさらにスケールを広げて大まかなデータの移り変わりを同時に分析します。
例えば、ECサイトの購入履歴のログの場合、日々の購入回数の平均値を集計してグラフ化し、月単位での購入回数を移動平均で算出することで季節性的なデータの移り変わりを見たい場合などに利用できます。
外れ値というよりかは傾向分析になるかもしれませんが、このグラフ上で大きな値があった場合などに可視化しておくことで外れ値に気づく可能性が高くなります。
以下、サンプルクエリです。
sourcetype=access_combined_wcookie
| timechart avg(bytes) as avg span=1h
| trendline sma12(avg) as moving_avg
移動平均は、trendline sma12(avg) as moving_avg のコマンドで分析していて、分析対象としているデータの個数やどれくらいの期間を対象に平均化するかをもとに設定値の調整が可能です。
sma12は過去12個のデータ(この場合だと12時間分)をもとに平均値を算出し、時系列が進むごとにスライドして計算されます。


trendlineの利用方法だけ覚えておけが応用が可能です。
標準偏差から外れ値を検出
データが正規分布している時に外れ値を見つけるのに特に効果を発揮します。
データの分布が安定していて、ブレの少ないデータを対象にすると良いです。
また、一般的にデータ数が少ないとデータの偏りが起きやすくなりますし、サンプル数が十分に多い場合に正規分布しやすくなる特徴があります。
以下、サンプルクエリです。
sourcetype=access_combined_wcookie
| timechart sum(bytes) as total span=1h
| eventstats avg(total) as avg stdev(total) as stdev
| eval upper_bound = avg + 2*stdev, lower_bound = avg - 2*stdev
| fields - avg - stdev
| eval outlier = if(total > upper_bound OR total < lower_bound , 1000000, 0)
※メインの統計をバイトの合計値にしています。
しきい値については、eval upper_bound = avg + 2*stdev, lower_bound = avg - 2*stdev のように平均から2標準偏差外れた値を検出するようにしています。
目安として、2標準偏差にした場合、正規分布したデータを前提に4.6%程度の出現率の外れ値を検出します。
3標準偏差にすれば、0.3%程度のデータが外れ値となるようです。
外れ値と異常値 | ブログ | 統計WEB
しきい値判定として、eval outlier = if(total > upper_bound OR total < lower_bound , 1000000, 0) しきい値を超えた場合にフラグを立てます。グラフ上で見やすいように「1000000」を指定していますが、アラート用のクエリであれば「1」などにするなどどちらでも問題ないです。


eventstatsを使った平均と標準偏差の出し方| eventstats avg(total) as avg stdev(total) as stdevと、上限・下限を求める時の計算式| eval upper_bound = avg + 2*stdev, lower_bound = avg - 2*stdevさえ覚えておけば応用が可能です。
しきい値が緩い場合は、3*stdev、3.5*stdevといったように調整していく感じになります。
移動平均をもとにした標準偏差から外れ値を検出
計算する範囲を時系列でスライドさせながら標準偏差と平均を求めて、外れ値を算出することも可能です。
時系列タイミングに従った動的なしきい値を求めることができますが、データのサンプル数が限定的になってしまうデメリットもあります。
以下、サンプルクエリです。
sourcetype=access_combined_wcookie
| timechart sum(bytes) as total span=1h
| streamstats window=12 avg(total) as avg stdev(total) as stdev
| eval upper_bound = avg + 2*stdev, lower_bound = avg - 2*stdev
| fields - avg - stdev
| eval outlier = if(total > upper_bound OR total < lower_bound , 1000000, 0)
streamstats window=12 avg(total) as avg stdev(total) as stdev ウィンドウを12個=12時間ごとに計算するデータをスライドさせています。


streamstatsによる移動平均と標準偏差の出し方| streamstats window=12 avg(total) as avg stdev(total) as stdev、上限・下限を求める時の計算式| eval upper_bound = avg + 2*stdev, lower_bound = avg - 2*stdevさえ覚えておけば応用が可能です。
しきい値が緩い場合は、3*stdev、3.5*stdevといったように調整していく感じになります。(先程のパターンと同じですね。)
中央絶対偏差を使って外れ値を検出
先程の「標準偏差」を利用した外れ値判定では、ばらつきが多い(正規分布していない)データが弱点でした。
ばらつきが多いデータや、サンプル数がそれほど多くとれない時には中央値を利用した外れ値検出が効果的です。
以下、サンプルクエリです。
sourcetype=access_combined_wcookie
| timechart sum(bytes) as total span=1h
| streamstats window=12 median(total) as median
| eval absDev=(abs(total - median))
| streamstats window=12 median(absDev) as medianAbsDev
| eval upper_bound = median + 2*medianAbsDev, lower_bound = median - 2*medianAbsDev
| fields - median - absDev - medianAbsDev
| eval outlier = if(total > upper_bound OR total < lower_bound , 1000000, 0)


中央値の出し方| streamstats window=12 median(total) as median、絶対値の求め方| eval absDev=(abs(total - median))、絶対中央値の求め方| streamstats window=12 median(absDev) as medianAbsDevを順番に知っていれば問題なくクエリを応用できます。
しきい値の求め方や調整については、これまでのものと同様なので割愛します。
もちろん検索レンジの全データを対象にしきい値を設定することもできます。
以下、サンプルクエリです。
sourcetype=access_combined_wcookie
| timechart sum(bytes) as total span=1h
| eventstats median(total) as median
| eval absDev=(abs(total - median))
| eventstats median(absDev) as medianAbsDev
| eval upper_bound = median + 2*medianAbsDev, lower_bound = median - 2*medianAbsDev
| fields - median - absDev - medianAbsDev
| eval outlier = if(total > upper_bound OR total < lower_bound , 1000000, 0)


四分位範囲(IQR)を使って外れ値を検出
四分位範囲(IQR)では、箱ひげ図というデータの分布を把握するための図で有名ですが、外れ値の検出でも利用できます。
先程の例と同じで、中央値をもとに外れ値を検出するため、正規分布していないデータの場合でも効果があります。
正直、「中央絶対偏差」と「四分位範囲(IQR)」のどんなときに特に良いかについては分かっていませんが、どちらも外れ値分析で強いようです。
一般的に、75パーセンタイル値から IQR(第3四分位数と第一四分位数の差異) の 1.5倍大きい、25パーセンタイル値から IQR の 1.5倍小さい値を外れ値としてみなすようです。正規分布している場合にはおおよそ0.7%のデータが該当するようです。
sourcetype=access_combined_wcookie
| timechart sum(bytes) as total span=1h
| streamstats window=12 median(total) as median, p25(total) as p25, p75(total) as p75
| eval IQR = (p75-p25)
| eval upper_bound = p75 + 1.5*IQR, lower_bound = p25 - 1.5*IQR
| fields - IQR median p25 p75
| eval outlier = if(total > upper_bound OR total < lower_bound , 1000000, 0)

中央値・25パーセンタイル・75パーセンタイルの求め方| streamstats window=12 median(total) as median, p25(total) as p25, p75(total) as p75、IQRの求め方| eval IQR = (p75-p25)、IQRを利用したしきい値の求め方| eval upper_bound = p75 + 1.5*IQR, lower_bound = p25 - 1.5*IQRが分かれば応用可能です。
また、こちらも同様ですが全期間を対象にしきい値を設定することもできます。
sourcetype=access_combined_wcookie
| timechart sum(bytes) as total span=1h
| eventstats median(total) as median, p25(total) as p25, p75(total) as p75
| eval IQR = (p75-p25)
| eval upper_bound = p75 + 1.5*IQR, lower_bound = p25 - 1.5*IQR
| fields - IQR median p25 p75
| eval outlier = if(total > upper_bound OR total < lower_bound , 1000000, 0)


MLTKを使った外れ値分析
Splunkでは機械学習の機能拡張とサポートツールとしてMLTK(Machine Learning Tool Kit)というものが用意されています。
こちらを使うことで、ユースケース別のガイドに従った機械学習分析クエリを作っていくことができます。
特に、Smart Assistant機能を利用することで、SPL文を記述することなくGUIベースで設定することが可能となっています。
また、ユースケースごとにおすすめの機械学習アルゴリズムを選択してくれるなど、機械学習に馴染みのないユーザーでも設定しやすくなっているのでこちらでの設定も試してみます。
以下のマニュアルを参考に必要なAdd-on等をインストールしておく必要があります。
Install the Splunk Machine Learning Toolkit - Splunk Documentationバージョンによる依存関係などもあるので、事前に確認しておくことがおすすめです。
Outlier(外れ値)の検出では、Smart Outlier Detection が利用できます。
こちらでは、Density Funtion が採用されています。
Splunk Machine Learning Toolkit を開き、Experiments の Create New Experiment を選択します。

Smart Outlier Detection を選んで、名前をつけます。

対象とするデータを選択します。前回に続き時系列データを対象にしたいので、以下のクエリを書いて検索を実行します。
(ルックアップファイルや、Metricsも指定が可能です。)
sourcetype=access_combined_wcookie
| timechart span=1h sum(bytes)

検索結果が出たら Next を選択すると次に進めます。
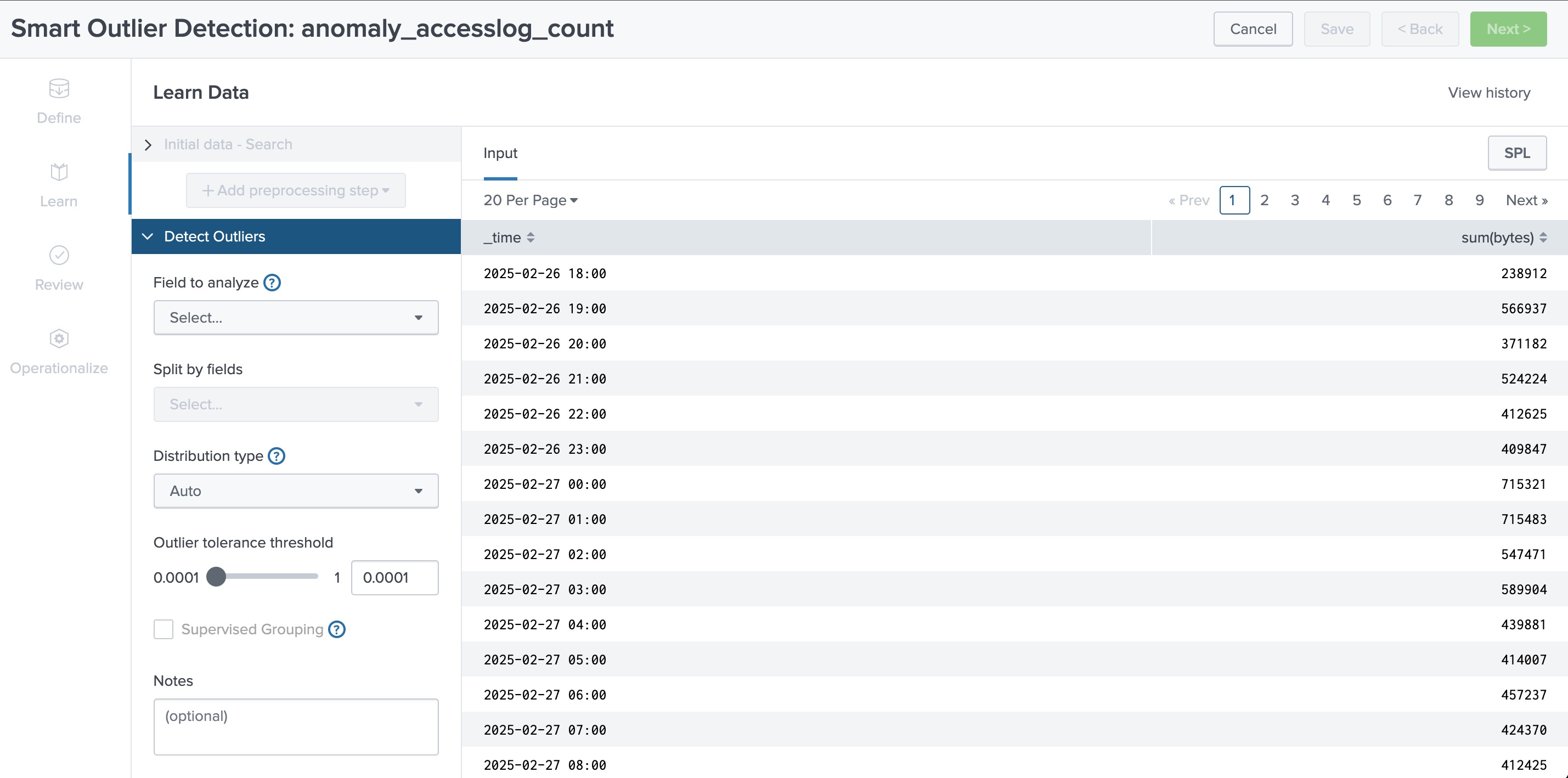
Field to analyze では、分析の対象とする「sum(bytes)」を選択します。
Outlier tolerance threshold はしきい値の調整になります。数値がどういった意味になるのかの説明はドキュメントから見つけられなかったのですが、「0.007」とかにすると 0.7% に分布するような外れ値を検出という意味になるのでしょうか。。
IQRのときに設定していたしきい値と近いようなこちらの数値で試してみます。
そのほかはデフォルトで検知してみます。

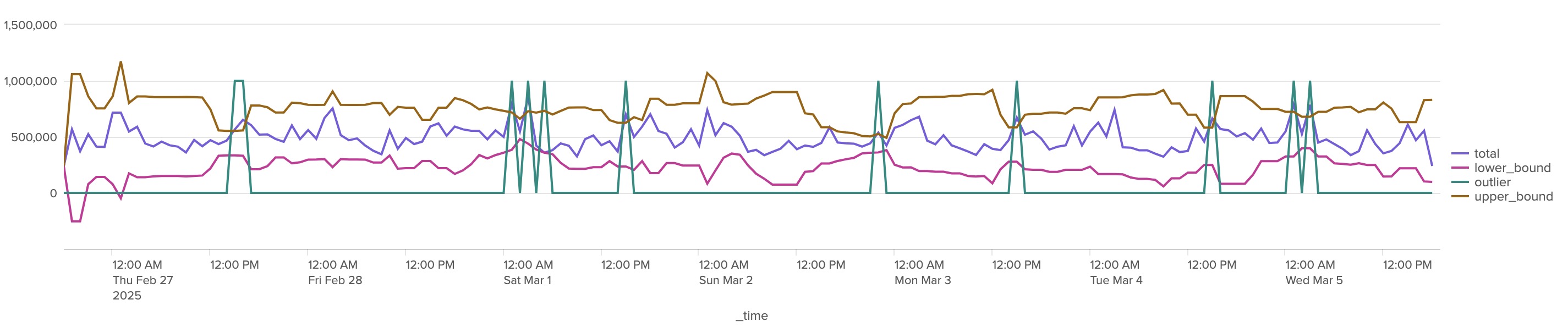
正規分布図が表示され、外れ値が一つ見つけられました。

Timeにすると、時系列データとしきい値の範囲、検出された外れ値も確認できます。

Nextで次に進むと、分析結果のプレビューを見ることができます。
Model Summary、Cardinality Histogram、Distribution Properties、Outlier Analysis でそれぞれの結果を確認できます。
Model Summary では、最小値、最大値、平均、標準偏差、カーディナリティー(統計対象となったグループ数、今回だと1hごとの時系列分割数)、計算に利用されたオプションや統計情報が確認できます。

Cardinality Histogramはフィールド分割を指定している場合に表示されます。

Distribution propertiesも同じくフィールド分割を指定している場合に表示されます。

Outlier analysisも同様でした。。

Save & Next で次に進みます。

さらに継続的なトレーニング、アラートの設定がこの画面で出来ます。
今回は一旦このまま終了します。
非常に簡単にでき、視覚的にも確認しながら機械学習検知ができるのでいい感じです。
まとめ
以上、Splunkで外れ値検出をする方法についてご紹介しました。
MLTKのSmart Assistant機能は簡単で精度の高い外れ値検出が可能なので積極的に使っていきたいと思いました。
一方、平均/中央値と標準偏差を使った手法についても、パターンを覚えておくだけで様々応用が効きますし、ビルトインのAppでも使われていることが多いので、どういった外れ値を検出しようとしているのか理解するのに役立ちそうです。
本記事がどなたかの一助になれば幸いです。










