データエンジニア未経験だったインフラエンジニアが Snowflake に入門してみて気づいたこと ― Zero to Snowflake をやってみた感想
データエンジニア未経験のインフラエンジニアが Snowflake に入門して気づいたこと
はじめに
Snowflakeの公式入門チュートリアル「Zero to Snowflake」を一通りやってみました。
データエンジニアとしての経験はなく、これまではAWSのインフラ寄りの仕事をしてきた人間です。チュートリアルの手順をなぞる記事ではなく、そんな自分が実際に触ってみて「おっ」と思ったポイントを中心に書きます。
やったこと
Snowflakeの公式入門コンテンツ「Zero to Snowflake」のStep 1〜9を実施しました。業務の合間に1日1時間ずつ進めて、約1週間で完走しました。
- Step 1-3: 基本操作(ウェアハウス作成、データロード、クエリ実行)
- Step 4-6: 半構造化データ、キャッシュ、クローン
- Step 7: タイムトラベル
- Step 8-9: データシェアリング、マーケットプレイス
全体を通して感じたのは、Snowflakeは「データを守る」「データを共有する」ということにすごく力を入れているということ。ただのDWHではなく、データを中心にした協業のプラットフォームという印象を受けました。
印象に残ったポイント
1. UNDROP —— 「消したら終わり」じゃない安心感
基幹システムの運用保守をやっていた身からすると、本番環境で何かを消すのは本当に怖いことです。
オンプレのOracleで運用していたときは、バックアップからの復元となると手順確認して、影響範囲を洗い出して、関係者に連絡して……という一連の流れが頭をよぎる。
Snowflakeのタイムトラベルは違いました。
まず、テーブルをDROPします。
DROP TABLE json_weather_data;
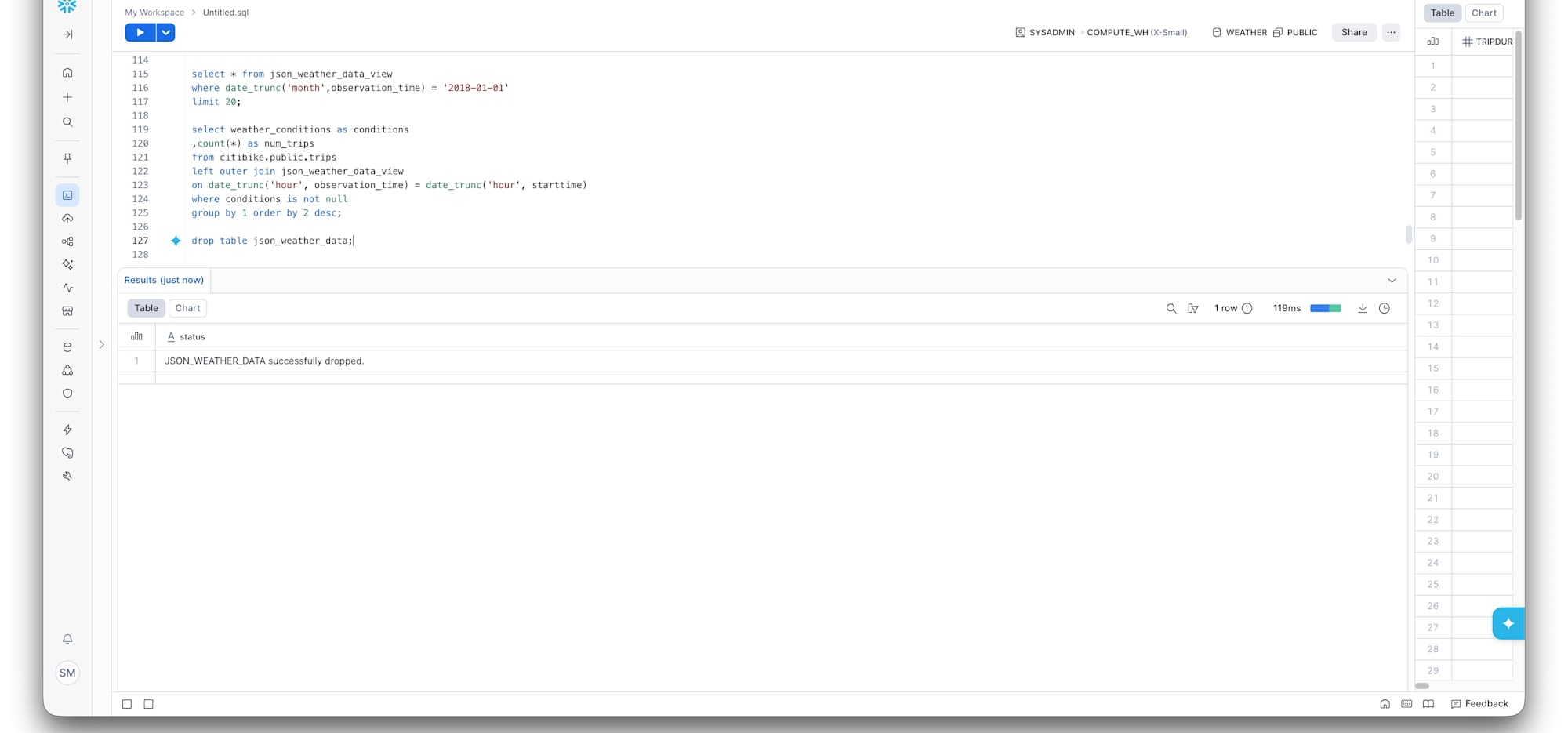
当然、この状態でクエリを投げるとエラーになります。
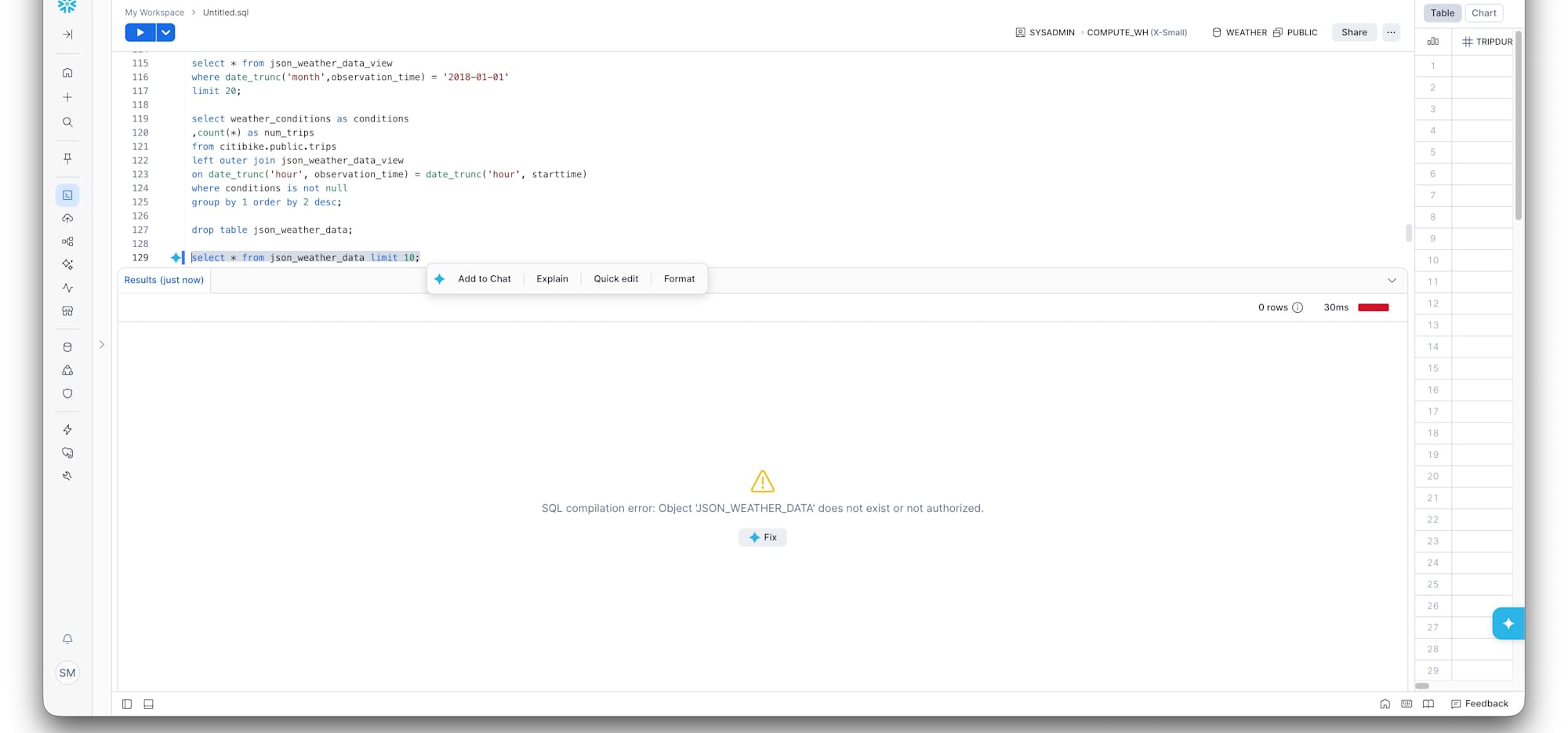
ここで UNDROP です。
UNDROP TABLE json_weather_data;
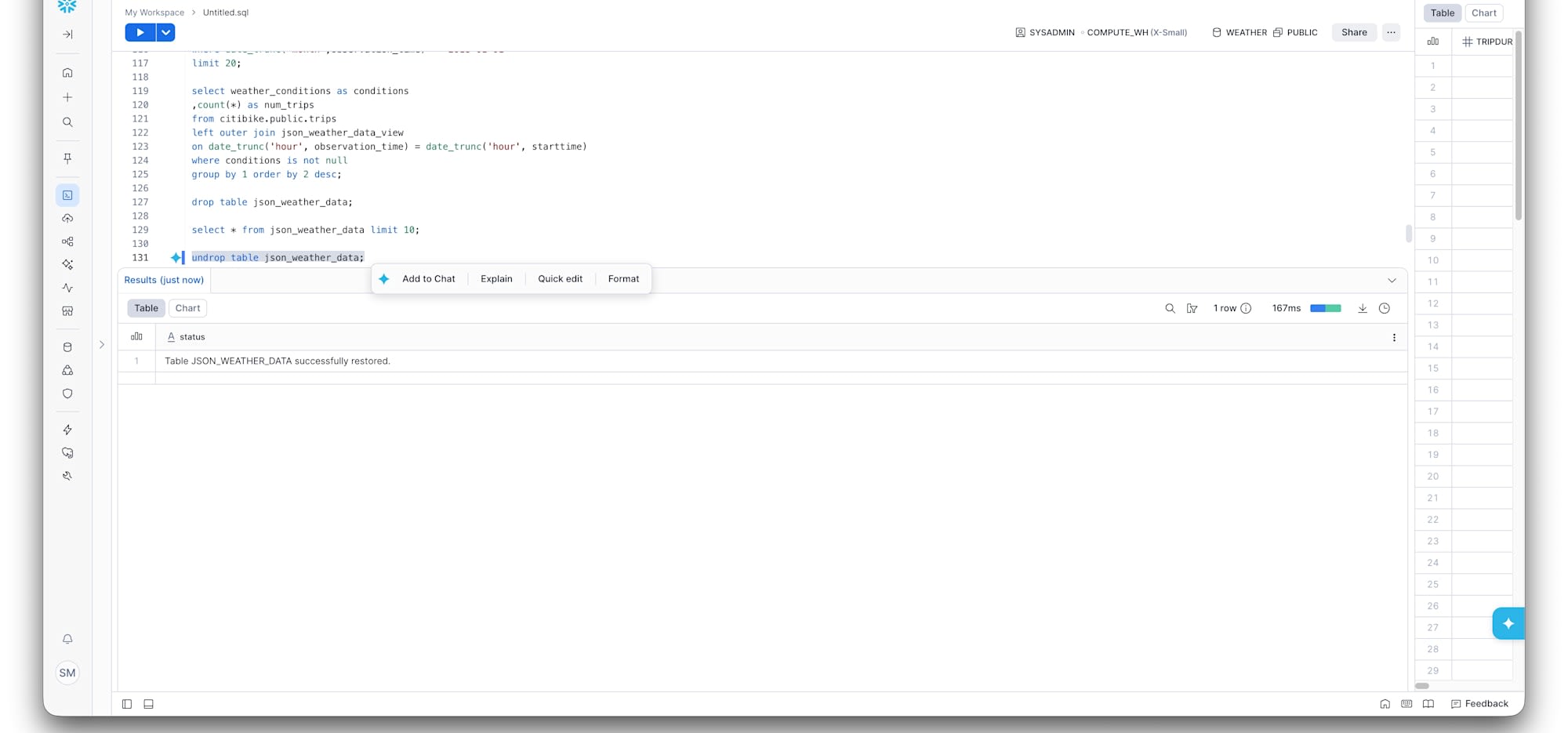
もう一度SELECTすると、データがそのまま戻っています。
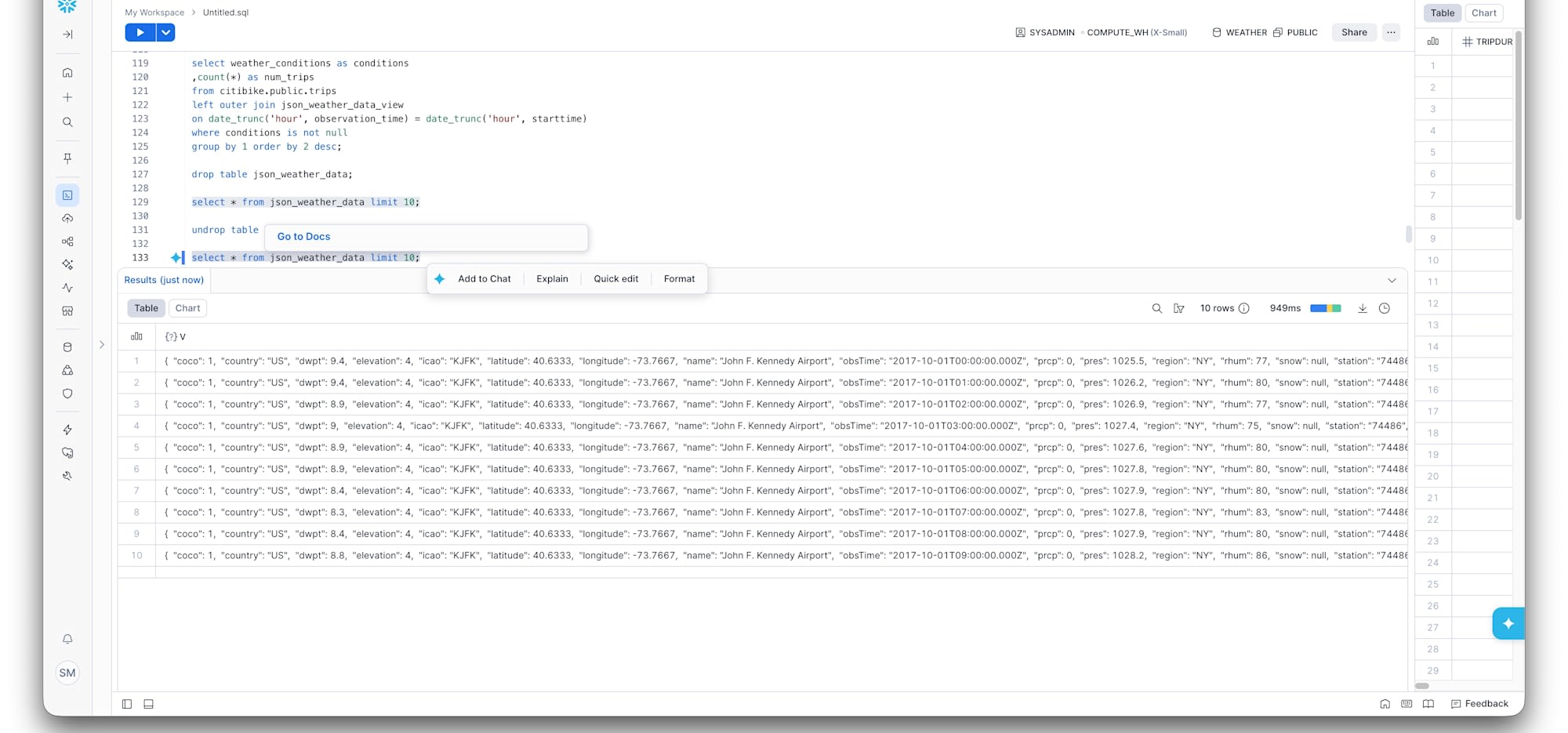
これだけで戻る。テーブル単位で。デフォルトで有効。
オンプレ環境で夜間バッチの障害対応やマスタ調査をやっていた経験があるので、「DROP直後にワンコマンドで戻せる」ことのありがたみは結構リアルに感じました。
もちろんタイムトラベルの保持期間(デフォルト1日、最大90日)はあるので万能ではないですが、「うっかり」レベルのミスに対するセーフティネットが最初から組み込まれているのは、触っていて安心感がありました。
2. データシェアリング —— UIがわからなくてSQLに逃げたら、逆にスッキリした話
Step 8のデータシェアリングで、チュートリアルの指示通りUIから共有を作成しようとしたんですが、正直どこを押せばいいのかわからなかった。
「共有名を入れて『共有の作成』をクリック」と書いてあるのに、該当する画面がどうしても見つからない。
数分迷った末に、SQLで直接実行することにしました。
CREATE SHARE ZERO_TO_SNOWFLAKE_SHARED_DATA;
GRANT USAGE ON DATABASE CITIBIKE TO SHARE ZERO_TO_SNOWFLAKE_SHARED_DATA;
GRANT USAGE ON SCHEMA CITIBIKE.PUBLIC TO SHARE ZERO_TO_SNOWFLAKE_SHARED_DATA;
GRANT SELECT ON ALL TABLES IN SCHEMA CITIBIKE.PUBLIC TO SHARE ZERO_TO_SNOWFLAKE_SHARED_DATA;
SHOW SHARES;
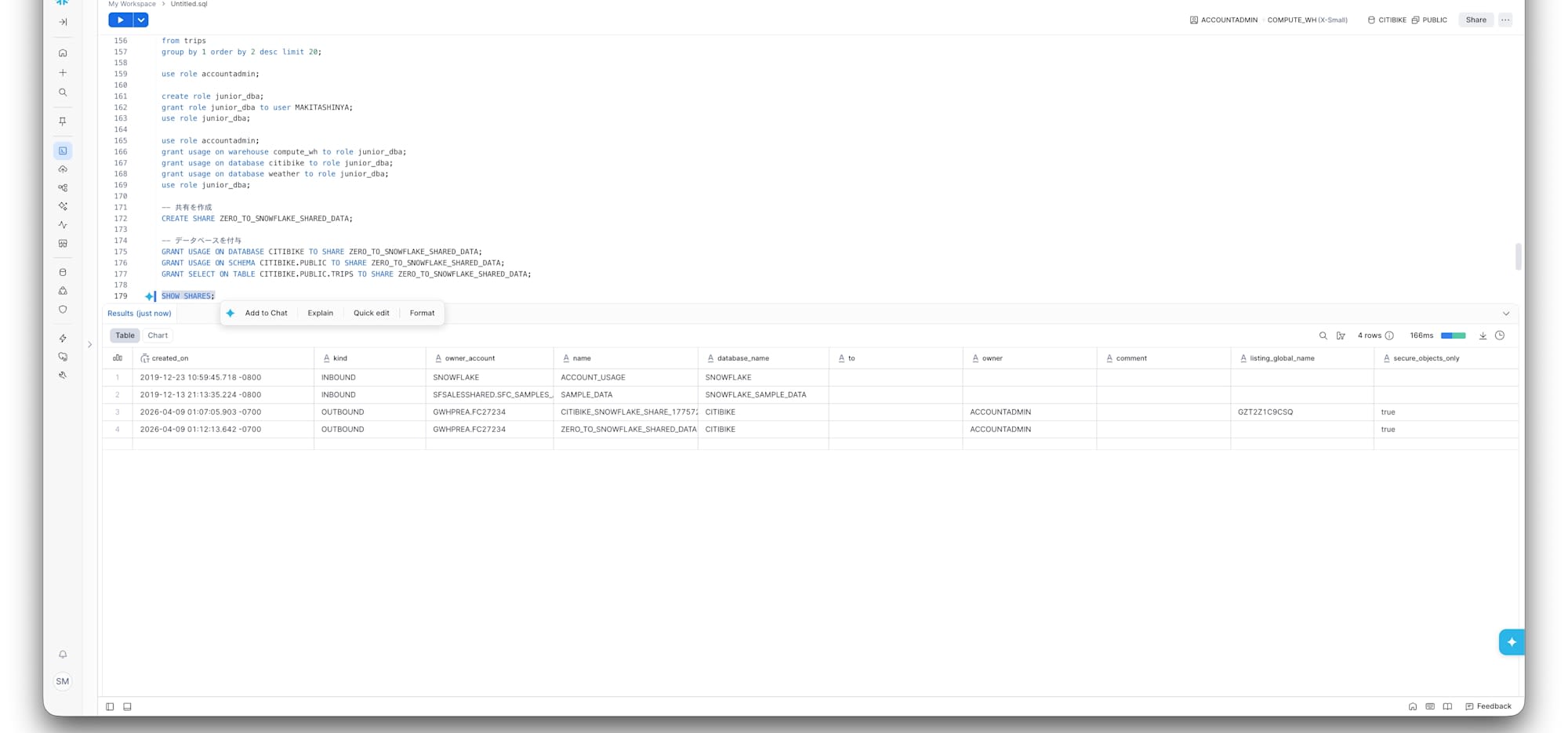
結果に ZERO_TO_SNOWFLAKE_SHARED_DATA が OUTBOUND で表示されて、「あ、できてる」と。
この体験で気づいたのは、Snowflakeは「SQLですべてが完結する」設計になっているということ。昔、CloudFormationでインフラをコードとして管理していたという経験もあり、「宣言的に書いて、実行して、状態を確認する」という流れ自体は馴染みがあります。Snowflakeの場合、それがSQLという共通言語で統一されているのが良い。
GUIに迷ったらSQLに逃げる、というのは入門者にとって意外と有効な戦略かもしれません。
DE未経験だからこそ感じたこと
Step 1で CREATE WAREHOUSE を実行したとき、最初は「これEC2みたいなものか」と思いました。でも触っていくうちに、だいぶ違うなと。
使わなければ自動で停止するし、必要になれば自動で再開する。サイズ変更もSQLひとつ。前職でCloudFormationのテンプレートを整備して「EC2のリソース払い出しフロー」を標準化する、みたいな仕事をやっていたので、計算資源の管理がここまで抽象化されているのは正直うらやましかった。
インフラエンジニアの仕事の多くは「リソースの面倒を見る」ことですが、Snowflakeはそこを徹底的に隠してくれている。インフラじゃなくてデータの作業に集中できるように作られてるんだな、というのが一番の感想です。
おわりに
データエンジニア未経験でも、Snowflakeの入門は問題なくできました。SQLの経験があれば取っ掛かりやすいし、インフラの経験があるからこそ「ここが違う」と気づけたポイントもあった気がします。
次はCortex Searchのチュートリアルに進みます。Snowflakeの上でAI/検索がどう動くのか、引き続き未経験者目線でレポートする予定です。








