Snowflake Intelligence で統合 AI エージェントを組んでみた
はじめに
こんにちは、データ事業本部のまっきーです。
前々回のZero to Snowflake入門、前回のCortex Searchチュートリアル実践記に続いて、今回は Snowflake Intelligence を実践しました。
Intelligence は一言でいうと Snowflake の中で AI エージェントを組むためのプラットフォーム です。Cortex Search(意味検索)と Cortex Analyst(自然言語 → SQL)、さらに自作のストアドプロシージャを「Tool」として束ねて、自然言語で使えるエージェントアプリを構築できます。
実践してみた結果、最初はトライアルアカウントの壁にぶつかり、社内検証アカウントに切り替えてようやく動作確認まで到達という流れになりました。権限周りの学びも含めてレポートします。
Snowflake Intelligence とは
まず Intelligence が Snowflake の AI プラットフォームのどこに位置するのか、公式の全体図で確認しておきます。
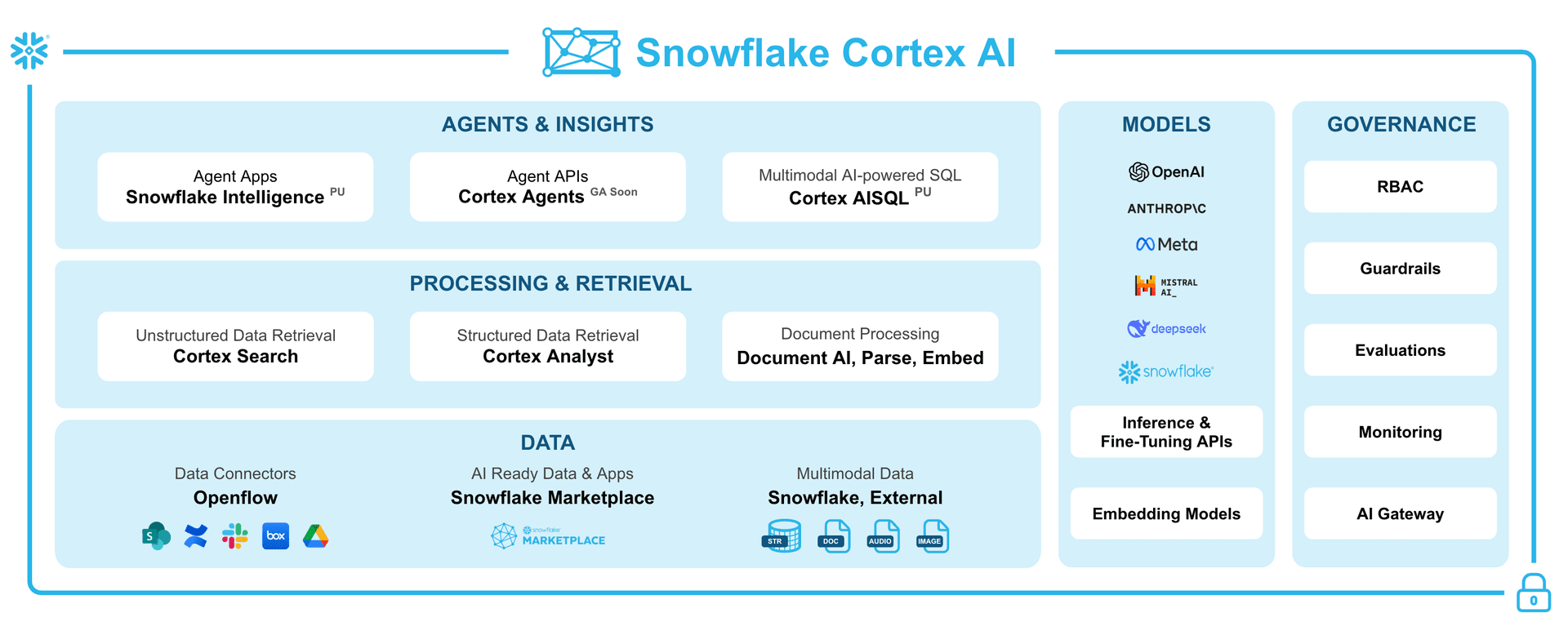
出典: Snowflake Cortex AI|Snowflake
この図の一番上の AGENTS & INSIGHTS 層にある Snowflake Intelligence が、今回実践する対象です。Intelligence の一つ下の層(PROCESSING & RETRIEVAL)には、Cortex Analyst(構造化データを自然言語で分析)、Cortex Search(非構造化データの意味検索)、Document AI(PDF等の解析)があり、Intelligence はこれらを「Tool」として束ねて動きます。
さらに下の DATA 層には Openflow(データの取り込み)、そして全体を横断して MODELS(OpenAI / Anthropic / Meta / Snowflake 等)と GOVERNANCE(RBAC / Guardrails / AI Gateway)が支える構成です。
Intelligence は、エージェント本体(Agent Apps)から Tool 実行・外部 API 連携・権限制御まで、AI エージェントに必要な要素を Snowflake の中に一通りまとめた プラットフォームです。データが既に Snowflake にあるなら、エージェント側もそのまま同居させやすい、という設計思想が特徴です。
構成
Snowflake 公式ドキュメントにも、Agent と Tool の関係を示す図があります。
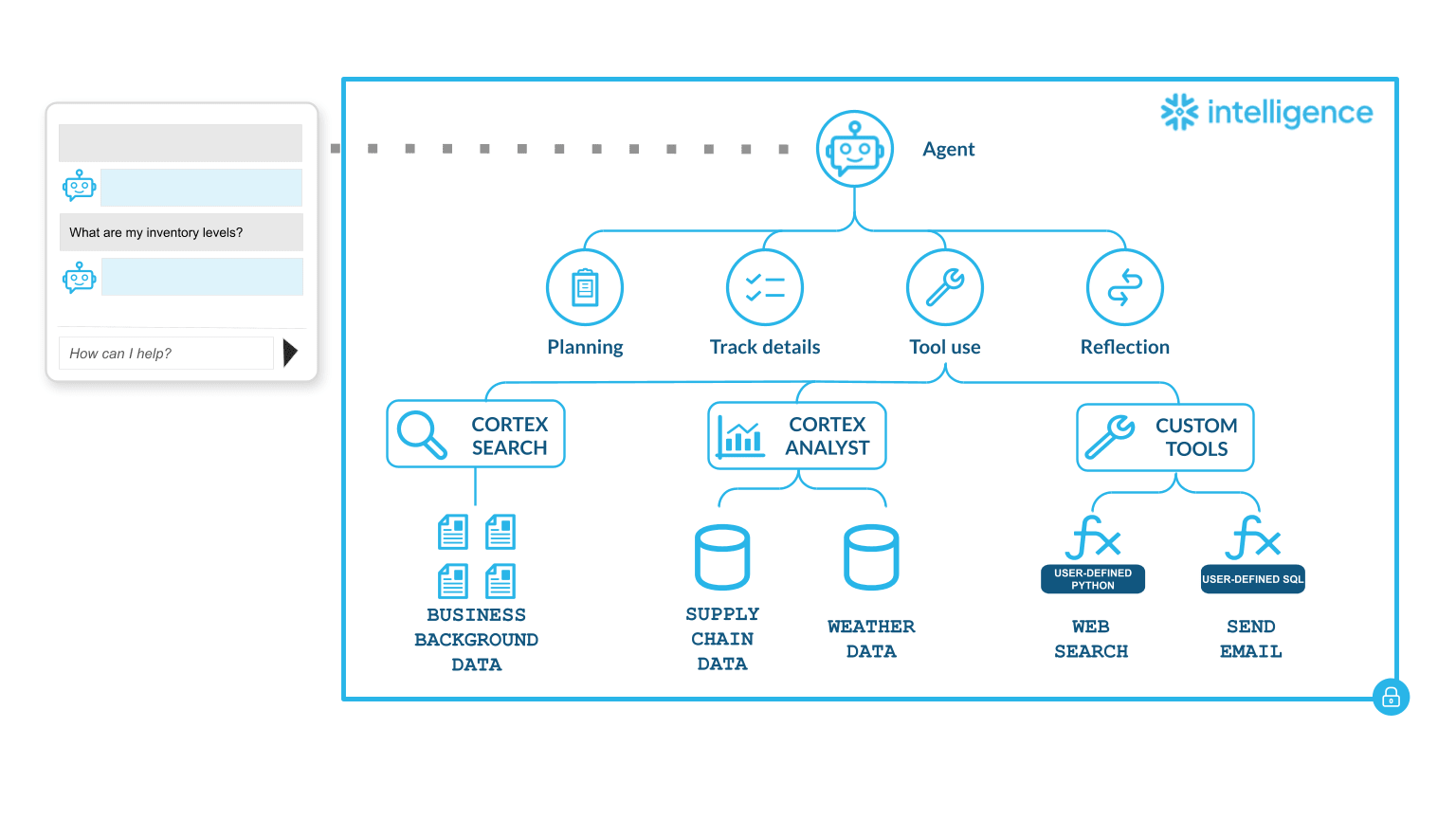
出典: Snowflake Intelligence|Snowflake Docs
ユーザーの自然言語質問が入ると、Agent は Planning(計画)→ Track details(詳細追跡)→ Tool use(Tool 実行)→ Reflection(振り返り) の4フェーズを回しながら、適切な Tool を呼び分けて回答を組み立てます。Tool は以下の3種類:
- Cortex Analyst: 構造化データ(例: Supply Chain、Weather などのテーブル)への自然言語質問
- Cortex Search: 非構造化データ(例: Business Background Data の文書群)の意味検索
- Custom Tools: 自作の User-Defined Python / SQL(例: Web Search、Send Email)
テキストで整理するとこうなります。
ユーザーの自然言語質問
↓
Agent(オーケストレーター LLM)が質問を理解
↓
必要な Tool を選んで呼ぶ:
- Cortex Analyst(構造化データ → SQL を自動生成して実行)
- Cortex Search(非構造化データの意味検索)
- Custom Tool(自作のストアドプロシージャ・UDF・外部 API)
↓
結果をまとめて回答(グラフ自動生成・引用元表示も対応)
主な機能
- 自然言語 Q&A(構造化・非構造化データを横断)
- 引用元(References)の自動表示
- グラフ自動生成(bar / line / pie / scatter)
- Extended Thinking(複雑な質問で深く考えるモード)
- Artifacts(グラフや表を保存・再利用)
- Snowflake 既存のロール/権限をそのまま使う(Seamless Governance)
モデルは Claude Opus 4.6 / Sonnet 4.6 / Haiku 4.5 など Claude 系を中心に選べます。下記画像では一番下の Gemini 3.1 Pro だけグレーアウトしていて、自分の環境では選択できませんでした(条件は不明)。
Cortex Analyst とは(構造化データの自然言語分析)
先ほどの全体図でいうと、PROCESSING & RETRIEVAL 層の Structured Data Retrieval にあたる位置です。
Cortex Analyst は 自然言語で投げた質問を SQL に変換して実行し、結果を返す サービスです。前回扱った Cortex Search が「検索」の仕組みだったのに対して、こちらは「構造化データ分析」の仕組みです。
イメージとしては 「SQL を書ける AI アナリストを雇った」 感じです。人間のデータアナリストが DB スキーマを理解してクエリを書くのと同じことを、自然言語で頼めるようにしたサービス、と考えると腑に落ちやすいと思います。
ついでに Cortex Search との違いも整理しておきます。
| Cortex Search | Cortex Analyst | |
|---|---|---|
| 相手にするデータ | 文章・テキスト(非構造化) | テーブル(構造化) |
| やりたいこと | 探して読む | 計算・集計する |
| 出力 | テキストの抜粋リスト | 数値・表・グラフ |
| 内部の動き | 意味的に似てるチャンクを検索 | SQL を生成して実行 |
| 誰に頼むイメージ | 図書館の司書 | 社内のデータアナリスト |
たとえば「商品カテゴリ別の売上トレンドを見せて」と質問すると、Cortex Analyst が以下のような SQL を生成して実行してくれます。
WITH monthly_sales AS (
SELECT p.category,
DATE_TRUNC('MONTH', s.date) AS month,
SUM(s.sales_amount) AS monthly_sales
FROM sales AS s
INNER JOIN products AS p ON s.product_id = p.product_id
WHERE s.date >= '2025-06-01' AND s.date < '2025-09-01'
GROUP BY p.category, DATE_TRUNC('MONTH', s.date)
)
SELECT category, month, monthly_sales
FROM monthly_sales
ORDER BY category, month;
ここでポイントになるのが、Cortex Analyst はデータベーススキーマだけ見ても適切な SQL を生成できない ということです。ユーザーが「エリア」と言ったとき、それが region カラムなのか area カラムなのか、AI には判断がつきません。
そこで登場するのが Semantic Model(YAML ファイル) です。
Semantic Model とは(Cortex Analyst の「意味地図」)
先ほどの「AI アナリストを雇った」の例えで言うと、Semantic Model は「そのアナリストへの引き継ぎ資料」 です。YAML で書きます。
- 「このテーブルのこの列は何を意味するか」
- 「ユーザーが『エリア』って言ったら
region列のことだよ」 - 「
SALESとPRODUCTSはPRODUCT_IDで JOIN するよ」
こういう「人間のアナリストなら当然知っているけど、AI は知らない文脈」を YAML に書き出しておく。すると Analyst が人間の質問を受け取ったとき、「あ、これは SALES と PRODUCTS を JOIN してカテゴリ別に集計すればいいのね」と判断できるようになります。
今回のチュートリアルで使った YAML の一部です。
- name: CAMPAIGN_NAME
synonyms:
- ad_campaign
- marketing_campaign
- promo_name
- advertisement_name
- campaign_title
description: The name of the marketing campaign, which can be used to identify and analyze the performance of specific promotional initiatives.
expr: CAMPAIGN_NAME
data_type: VARCHAR(16777216)
sample_values:
- Summer Fitness Campaign
synonyms: 「広告名」「プロモ名」のような表記ゆれを吸収description: そのカラムが何を意味するかの自然言語定義sample_values: 実際にどんな値が入っているかの例
さらに、テーブル間の関係も定義します。
relationships:
- name: SALES_TO_PRODUCT
left_table: SALES
right_table: PRODUCTS
relationship_columns:
- left_column: PRODUCT_ID
right_column: PRODUCT_ID
relationship_type: many_to_one
join_type: inner
これで「商品カテゴリ別の売上」という質問に対して、SALES と PRODUCTS を PRODUCT_ID で JOIN した SQL を生成できるようになります。
Snowflake はこの「自然言語 → カラム解決」を YAML 一枚で宣言的に書ける形に標準化 しています。スキーマに対するメタデータ層を組織の資産として持てる、というアプローチは自分にとって馴染みやすく感じました。
Custom Tool とは(AIに自作処理を渡す仕組み)
Agent に「自作の処理を実行させる」ための仕組みです。Snowflake のストアドプロシージャや UDF を登録すると、AI がそれを呼び出せるようになります。
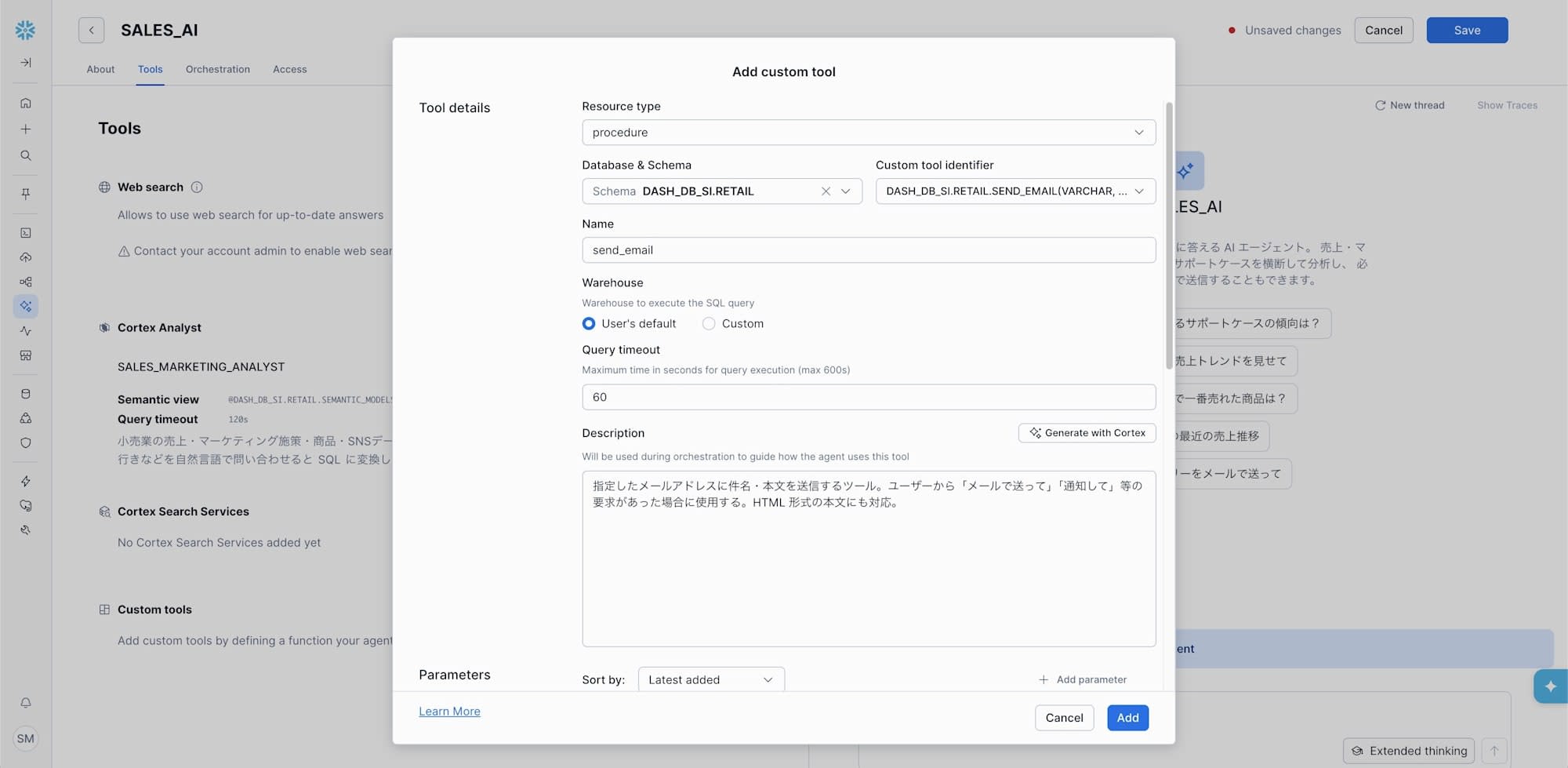
チュートリアルでは send_email というストアドプロシージャを Custom Tool として登録しました。
CREATE OR REPLACE PROCEDURE send_email(
recipient_email VARCHAR,
subject VARCHAR,
body VARCHAR
)
...
これを Agent に紐づけると、「先月の売上サマリーを xxx@example.com に送って」と自然言語で指示するだけで、Agent が適切な引数を組み立てて send_email を呼び出します。
外部 API(Salesforce、Prezent.ai など)も External Access Integration を使えば呼び出し可能で、AI エージェントを自社業務に組み込む汎用的な仕組み が Snowflake の中で完結する、という設計です。
Tool の実体(ストアドプロシージャや UDF)そのものを Snowflake の中に持てる のが特徴です。データと Tool のコードが同じ場所にあるので、権限設計も Snowflake のロールで一貫して扱えます。
やったこと
公式チュートリアル「Getting Started with Snowflake Intelligence」を実施しました。
setup.sql実行(ロール・ウェアハウス・DB・テーブル5件・Git Integration・Email Integration・send_emailプロシージャを作成)- Cortex Search Service(
support_case_search)を別途作成 - Semantic Model(
marketing_campaigns.yaml)をステージにアップロード - Snowsight の AI & ML → Agents から Agent を作成
- About タブに名前・説明・例示質問を入力
- Tools タブに Cortex Analyst / Cortex Search / Custom Tool を追加
- チャットで動作確認
トライアルの壁と社内検証アカウントへの切り替え
最初はトライアルアカウントで Agent まで作って、いざチャットを実行したところエラーが出ました。
Error: Access denied for trial accounts.
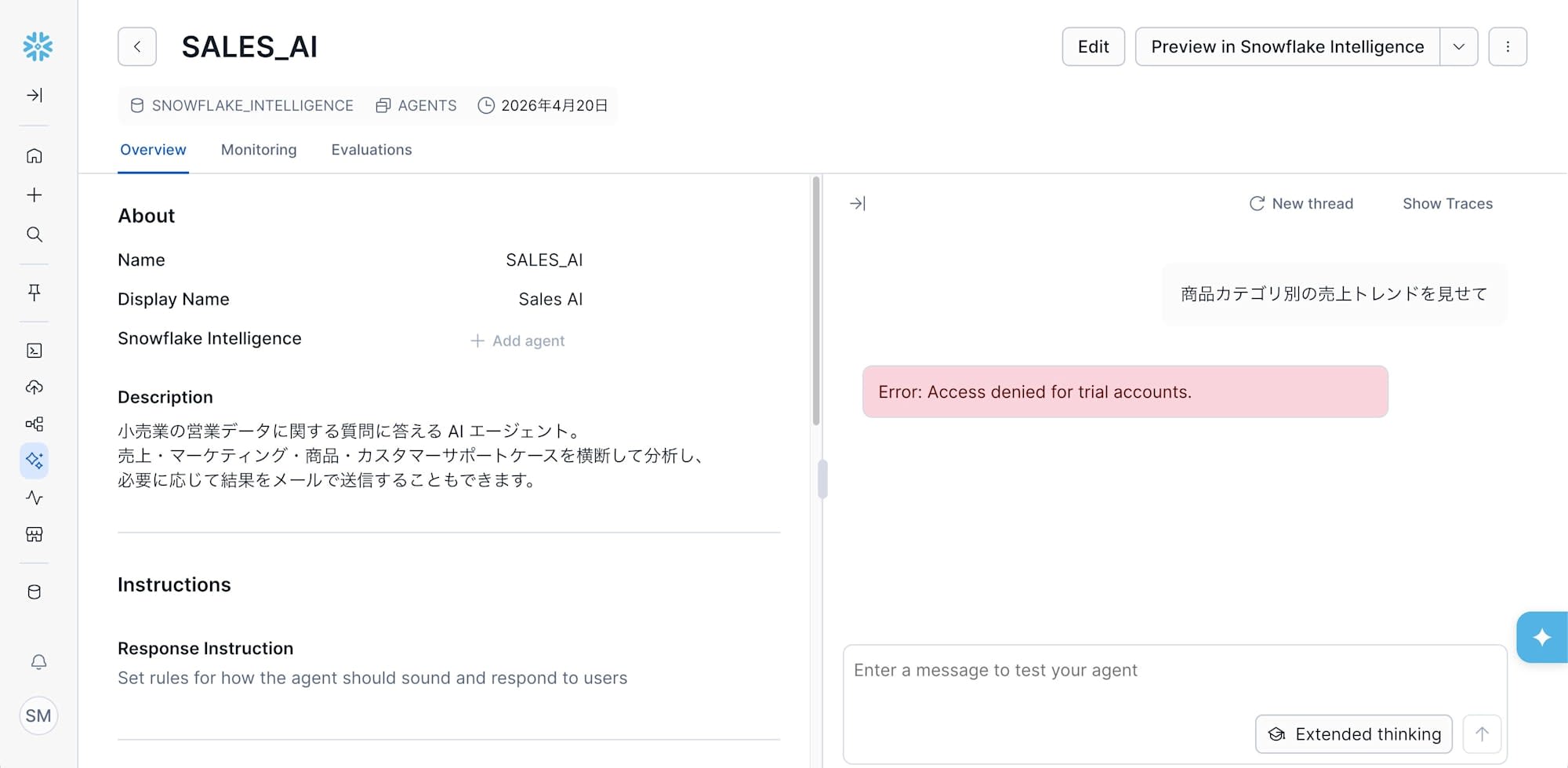
このエラー文言のとおり、Snowflake Intelligence のチャット実行(質問を投げる操作)はトライアルアカウントでは弾かれました。Agent の作成や Tool の追加まではできるのですが、実際に質問を投げるとここで止まります。なお、公式のトライアルアカウント制約一覧に「Intelligence チャット不可」と明示されているわけではなく、これは実際に動かしてエラーで判明したものです。
さらに、Intelligence を動かすには SNOWFLAKE_INTELLIGENCE という固定名のデータベース が必要で、ここに Agent オブジェクトが保存されます。社内検証アカウントで再試行したのですが、今度は 既存の SNOWFLAKE_INTELLIGENCE DB に自分のロールから権限がない という壁にぶつかりました。
- Intelligence は固定名 DB を前提とする仕様
- 既存 DB の権限は上位ロール(ACCOUNTADMIN)しか付与できない
- 別名 DB では回避できない
最終的に、社内検証アカウントの管理者に権限付与を依頼して、無事突破できました。
学び:Snowflake の AI 機能は「権限設計」が最初の山
Snowflake は ロールベースのアクセス制御(RBAC)が中心 で、上位ロールから明示的に付与されない限り、下位ロールで権限を取りにいくことができない設計です。
これは企業運用上はむしろ安全で、
- 誰が何を作れるか
- 誰が何を参照できるか
を組織ポリシーとして一元管理できるのは強みです。ただ、「とりあえず試したい」段階だとここで詰まる ことがあると知っておくと、PoC の準備が楽になります。特に Intelligence は固定名 DB を使う仕様なので、使い始めるには必ず管理者との擦り合わせが必要 になると認識しておくとよさそうです。
動作確認1:Cortex Analyst で売上トレンドを聞く
権限の壁を突破した後、実際に Agent に質問を投げてみました。
質問: 「商品カテゴリ別の売上トレンドを見せて」
Agent は Cortex Analyst を呼び出し、Semantic Model を参照して SQL を自動生成・実行。結果をサマリーテキストと折れ線グラフでまとめてくれました。
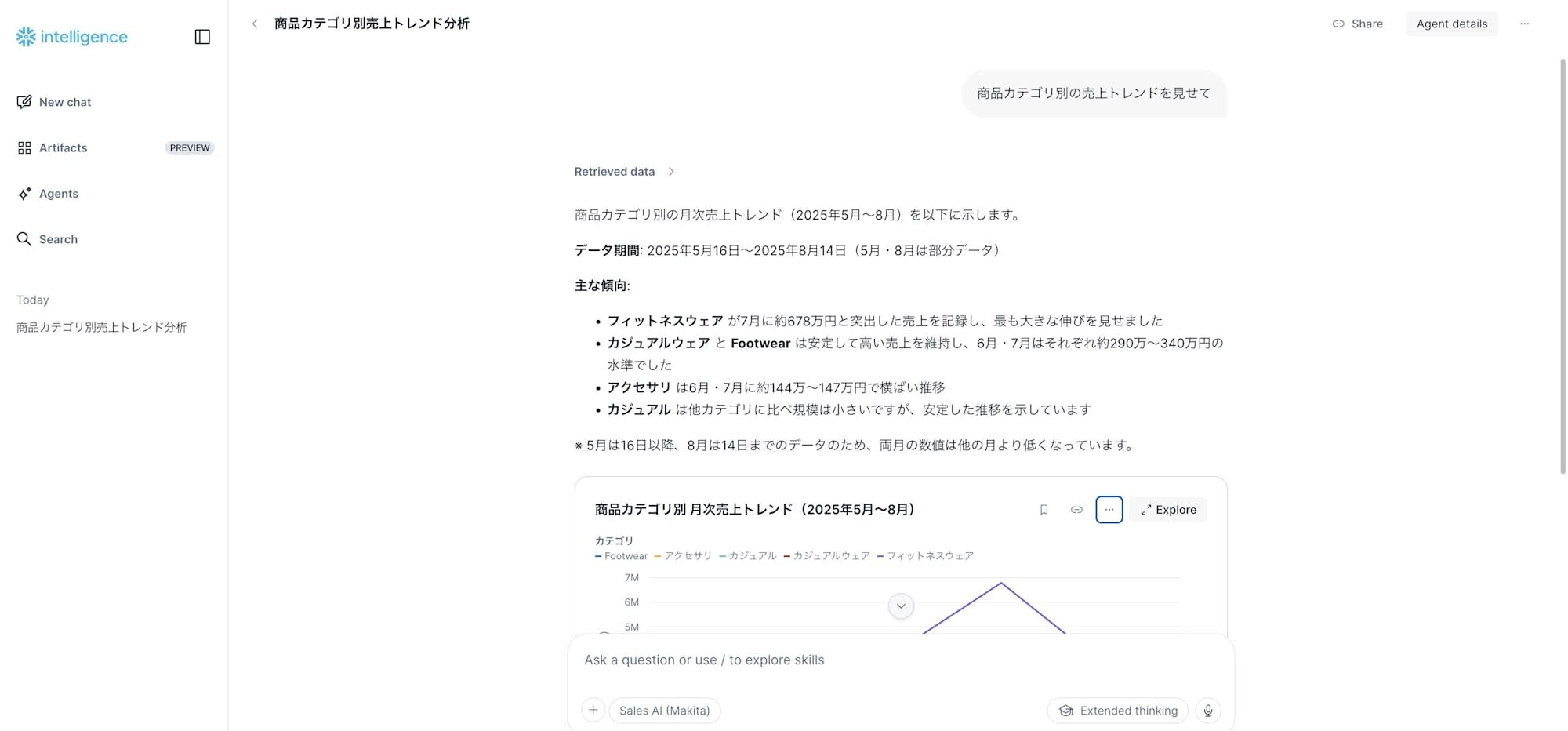
- フィットネスウェアが 7 月に他カテゴリを引き離して伸びている
- カジュアルウェアと Footwear は 6〜7 月に安定
- アクセサリ・カジュアルは小規模だが安定推移
面白かったのは、「5月は16日以降、8月は14日までのデータのため、両月は他の月より低くなっています」 という注釈まで自動で付けてくれたこと。Semantic Model に sample_values や description を書いておくだけで、ここまで気の利いた回答が返ってきたのは、自分が想像していたよりも踏み込んだ挙動でした。
動作確認2:Cortex Search でサポートケースを検索
続いて、非構造化データ(サポートケースのチャット記録)への自然言語検索です。
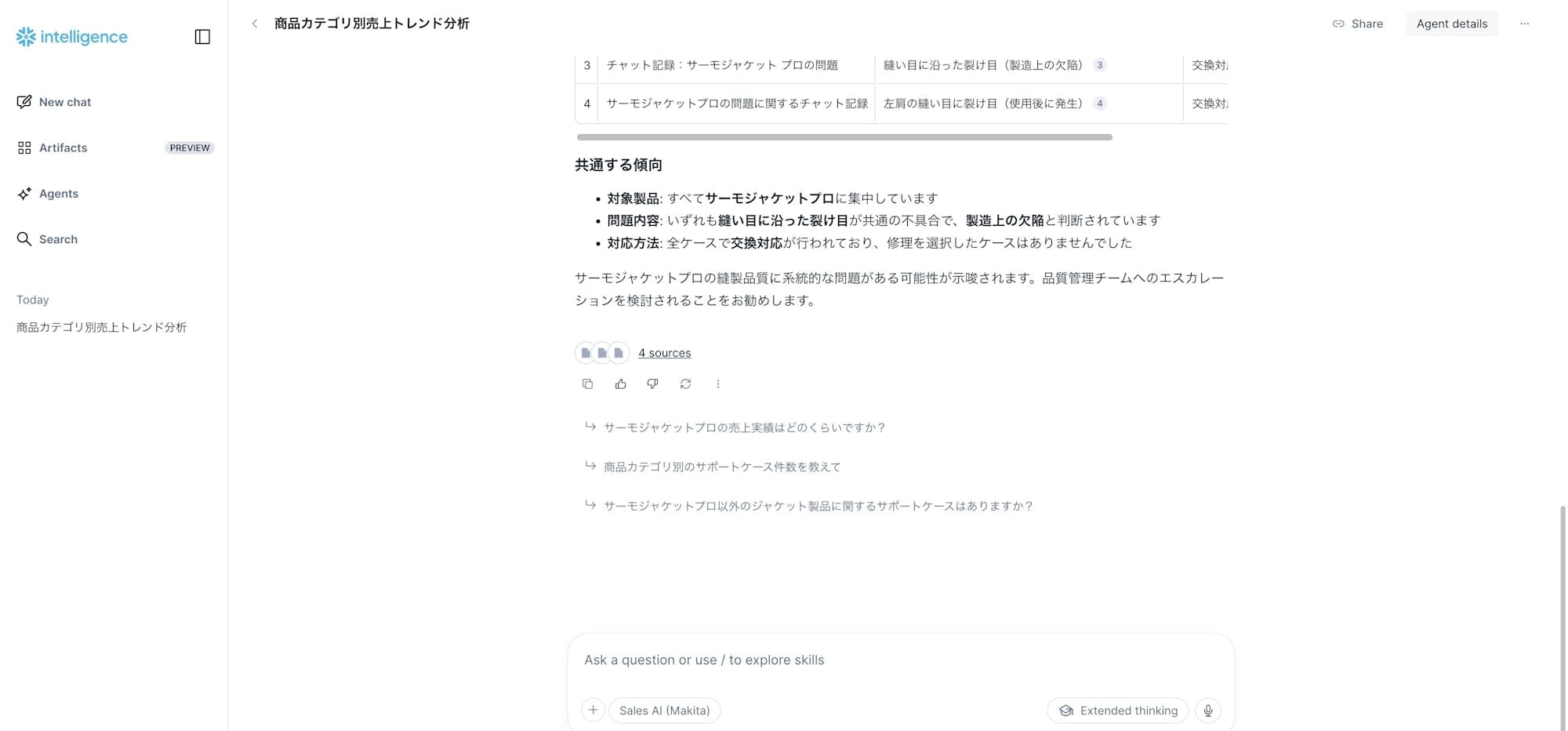
質問: 「最近のジャケットに関するサポートケース」
Agent は今度は Cortex Search Service(support_case_search)を呼び出し、サポートケース4件をピックアップ+共通する傾向を要約してくれました。
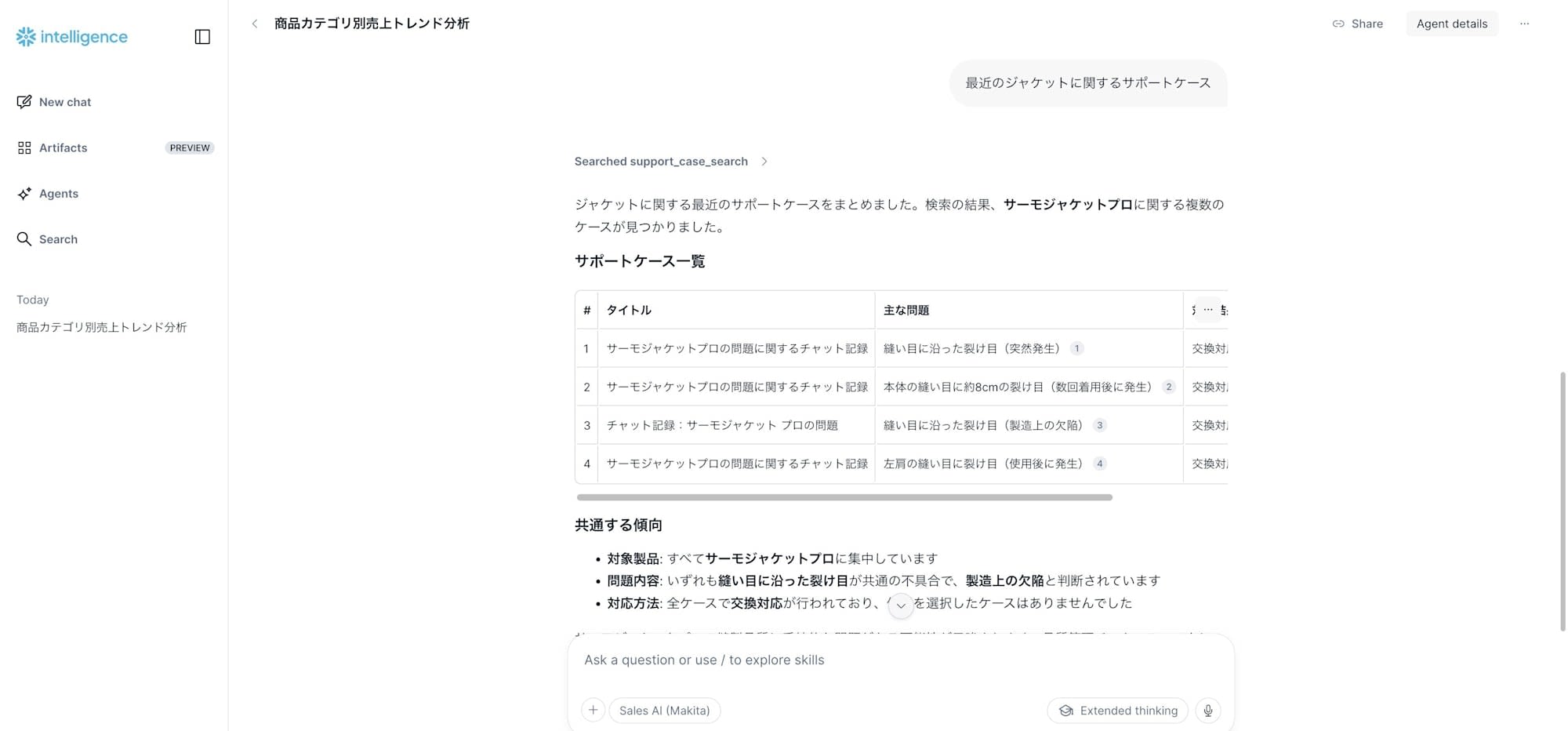
- 対象製品: すべてサーモジャケットプロに集中
- 問題内容: いずれも縫い目に沿った裂け目が共通の不具合で、製造上の欠陥と判断
- 対応方法: 全ケースで交換対応が行われている
回答の下には 4 sources として引用元のチャット記録へのリンクも表示されました。RAG で「この回答の根拠はどこか」を追跡できるのは、実用に耐える仕組みとして重要です。
同じ Agent に対して、1問目は Cortex Analyst、2問目は Cortex Search が自動で選ばれた のがポイント。質問の性質に応じて Agent が使う Tool を切り替えてくれるのが、Intelligence の本質だと感じました。
印象に残ったポイント
1. 「エージェント」を宣言的に組める
Intelligence は Snowflake 上に作ったストアドプロシージャや関数を、間に仲介コードや別のスキーマ定義を挟むことなく、そのまま Agent の Tool に登録できます。Snowsight の UI 上で「Cortex Analyst / Cortex Search / Custom Tool」を選んで設定するだけで Agent ができたので、自分のユースケースでは構築までの手数が少なく感じました。
2. Semantic Model が「意味の API」になっている
Cortex Analyst のために YAML を書く体験は、DB スキーマに対するメタデータ層を標準化する作業 に近いものでした。AI のためだけではなく、「このテーブルは何を意味するのか」「カラムの同義語は何か」を組織としてドキュメント化する仕組みになっていて、設計資産として残るのが自分にとっては嬉しいポイントでした。
3. 権限設計が最初にクリアすべき課題
Snowflake Intelligence は 固定名 DB(SNOWFLAKE_INTELLIGENCE)への権限付与が最初の関門 になります。PoC や検証を始める前に、ACCOUNTADMIN ロールを持つ管理者と連携して権限設計を通しておくと、自分の経験からするとスムーズに進められそうです。
まとめ
Intelligence を動かしてみて、AI エージェント基盤を Snowflake の中で宣言的に組み立てられる 体験は、自分にとって新鮮でした。
Snowflake Intelligence が提供する機能を、自分が普段触っている AWS のサービスと対応づけて整理するとこうなります(どちらが優れているかではなく、設計思想の違いを掴むための対比)。
| 役割 | Snowflake Intelligence | AWS で同じ役割を担うサービス(例) |
|---|---|---|
| AIエージェント本体 | Agent(Snowsight UI で作成) | Bedrock Agents |
| 構造化データへの自然言語質問 | Cortex Analyst + Semantic Model | Bedrock / Athena + 自作の RAG |
| 非構造化データの意味検索 | Cortex Search | Kendra / OpenSearch + Bedrock |
| 自作処理の Tool 化 | Custom Tool(ストアドプロシージャ直接登録) | Lambda + Action Group |
| 外部 API 連携 | External Access Integration | API Gateway + Lambda + Secrets Manager |
| 権限管理 | Snowflake ロール(固定名 DB 前提) | IAM + リソースポリシー |
Snowflake 側は データ基盤と同じ枠の中に AI 機能が配置されている ので、「データがすでに Snowflake にあって、その上に AI 機能を載せたい」というユースケースでは、連携設計を Snowflake のロールに寄せやすいのが特徴です。一方で AWS はサービス単位で個別に選べる柔軟性があり、用途やすでに動いている基盤によってどちらに寄せるかが決まる、と理解しました。
一方で、Intelligence を動かすには 固定名 DB への権限 が必要で、PoC の初手でここに引っかかることがあります。本番環境で使う際は、管理者(ACCOUNTADMIN)との権限設計を最初にクリアしておくのが重要だと学びました。
おわりに
これで Snowflake の AI 機能について、データ取り込み → 意味検索 → 自然言語分析 → エージェント化 の一連の流れを一通り触りました。
次は OpenFlow(非構造化データの取り込み基盤)のチュートリアルに進む予定です。冒頭の全体図でいうと、一番下の DATA 層 にあたる部分。ここまで触ってきた機能の手前にある「データをどう Snowflake に入れるか」を押さえれば、「AI Data Cloud」と呼ばれる所以の全体像が掴めるはずです。引き続き触りながら整理していきます。









