Snowflake Cortex Search で PDF チャットボットを作ってみた
はじめに
こんにちは、データ事業本部のまっきーです。
前回の記事「Snowflake入門 - AWSメインでやってきた自分から見たZero to Snowflake」では、Snowflakeの無料トライアルを使ってZero to Snowflakeチュートリアルに取り組みました。UNDROPやデータシェアリングといった機能に驚いたのが印象的でした。
今回はその続きとして、Cortex Searchチュートリアル(全3回) を実践しました。最終的にはPDFファイルに対して自然言語で質問できるRAGチャットボットを作るところまでやります。
そもそも Cortex Search って何?
チュートリアルに入る前に、Cortex Searchが何をするものなのかを整理しておきます。
通常のSQLでデータを検索するときは、WHERE name = '東京' のように条件を正確に指定して探します。一方、Cortex Searchを使うと「東京で人気の観光スポットは?」のように自然言語で意味を汲み取った検索ができます。
作り方もシンプルで、SQL一発でサービスが立ち上がります。
CREATE CORTEX SEARCH SERVICE my_search -- 検索サービスの名前
ON text_column -- どのカラムを検索対象にするか
WAREHOUSE = my_wh -- 処理に使うコンピュートリソース
AS (SELECT text_column FROM my_table);-- 検索対象のデータを返すクエリ
これだけで、裏側の検索エンジンの構築やインデックスの管理はSnowflakeが全部やってくれます。利用者が意識する必要はありません。
AWSでの経験がある身として驚いたのは、検索基盤を自分で構築しなくていいという点です。AWSで同じようなことをやろうとすると、検索サービスを立てて、LLM連携を設定して、Lambdaでつなぎこんで...とかなりの構築作業が必要になります。それがSQLの1行で済んでしまう。
そもそも RAG って何?
もう一つ、チュートリアルを進める上で理解しておきたい概念がRAG(Retrieval-Augmented Generation)です。
RAGを一言でいうと、「まず検索で関連情報を引っ張ってきて、それをLLMに渡して回答を生成させる」 パターンです。
ユーザーの質問
↓
Cortex Search で関連テキストを検索(= Retrieval)
↓
検索結果 + 質問を LLM に渡す
↓
LLM が回答を生成(= Generation)
Snowflakeでは、検索パートをCortex Searchが、回答生成パートをCOMPLETE関数が担います。
COMPLETE関数は、SnowflakeのSQL内から直接LLMを呼び出せる関数です。
SELECT SNOWFLAKE.CORTEX.COMPLETE('snowflake-arctic', 'RAGって何?');
これだけでLLMが回答を返してくれます。APIキーの取得も外部接続の設定も不要で、Snowflakeの中で全部完結します。
そもそも Streamlit in Snowflake って何?
3つのチュートリアル全てでUI構築に使うので、こちらも軽く触れておきます。
Streamlit はPythonだけでWebアプリが作れるフレームワークで、それをSnowflake上でそのまま動かせるのが Streamlit in Snowflake(SiS)です。
- Snowsight上でPythonコードを書くだけでアプリが起動する
- ホスティングサーバーやフロントエンド基盤を用意する必要がない
- アプリからSnowflakeのデータ・関数(Cortex含む)に直接アクセスできる
AWSでチャットボットUIを作るなら、AmplifyやS3 + CloudFrontでフロントをホスティングして、APIGateway + Lambdaでバックエンド連携して...と構築作業が結構発生します。それがPythonファイル1つで済んでしまうのは衝撃でした。
Tutorial 1: テキストデータで検索サービスを作る
概要
最初のチュートリアルでは、Airbnbのリスティングデータ(テキスト)をCortex Searchに取り込んで、自然言語で検索できるようにします。
やったこと
- データベースとウェアハウスを作成
- JSONデータ(Airbnbのリスティング情報)をSnowsightからロード
- テキストデータをチャンク分割(
SPLIT_TEXT_RECURSIVE_CHARACTER) - Cortex Search Serviceを作成
- Streamlit in Snowflakeで検索UIを構築
ポイント
チャンク分割がここで初めて出てきます。チャンクとは「テキストを適度なサイズに切った断片」のことです。長いテキストをそのまま検索対象にすると、どこに欲しい情報があるか分からず精度が落ちるため、検索しやすいサイズに分割しておきます。
SNOWFLAKE.CORTEX.SPLIT_TEXT_RECURSIVE_CHARACTER(
text_column, -- 分割対象のテキスト
1500, -- 1チャンクの最大文字数
300 -- チャンク間のオーバーラップ(重なり)
)
SNOWFLAKE.CORTEX. という接頭辞がついた関数は、Snowflake の AI 機能(Cortex)が提供する専用関数です。通常の SQL 関数と同じ感覚で使えます。
オーバーラップ(重なり)は、前のチャンクの末尾300文字を次のチャンクの先頭にも含める仕組みです。これにより、チャンクの境目で文脈が途切れるのを防ぎます。
Cortex Search Serviceの作成は本当にSQL一発です。
CREATE CORTEX SEARCH SERVICE my_search_service
ON search_column -- 検索対象のカラム
WAREHOUSE = my_wh -- 使用するウェアハウス
TARGET_LAG = '1 hour' -- インデックス更新の最大遅延
AS (
SELECT
search_column, -- 検索対象(必須)
other_column -- 検索結果に含めたい追加情報
FROM my_table
);
TARGET_LAG = '1 hour' は「元テーブルが更新されたら最大1時間以内にインデックスも更新する」という設定です。リアルタイム性と処理コストのバランスを取る仕組みで、値を小さくすれば鮮度は上がりますが、その分コンピュートリソースを消費します。
Tutorial 2: RAG チャットボットを作る
概要
Tutorial 1では「検索して結果を返す」だけでしたが、Tutorial 2では検索結果をLLMに渡して人間が読める回答を生成するところまでやります。これがRAGチャットボットの基本形です。
Tutorial 1との違い
| Tutorial 1 | Tutorial 2 | |
|---|---|---|
| 入力 | テキストデータ | テキストデータ(同じ) |
| 検索 | Cortex Search | Cortex Search(同じ) |
| 出力 | 検索結果の一覧 | LLMが生成した回答文 |
| UI | 検索ボックス | チャットUI(会話履歴付き) |
新しく登場するのがCOMPLETE関数です。前述の通り、SQL内からLLMを呼び出せる関数で、Cortex Searchで引っ張ってきた検索結果とユーザーの質問を合わせてプロンプトを組み立て、LLMに回答を生成させます。
ポイント
チャット履歴の考慮が地味に重要です。「2023年のGDP成長率は?」→「同じ四半期の失業率は?」と続けて聞いたとき、2問目の「同じ四半期」が何を指すかは会話の流れを見ないと分かりません。
Tutorial 2のコードでは、過去の会話履歴をLLMに渡して「この文脈で、ユーザーの質問を補完したクエリを作って」と指示する仕組みが入っています。RAGを実用的にするには、こういった工夫が必要になるんですね。
Tutorial 3: PDF からチャットボットを作る
概要
ここが一番の見せ場です。Tutorial 1・2はテキストデータが既にある状態からスタートしましたが、Tutorial 3はPDFファイルという非構造化データから始めます。
使用するデータはFOMC(米国連邦公開市場委員会)の議事録PDF、12ファイル(各約10ページ)です。
全体の流れ
PDF をステージにアップロード
↓ 「生のPDF、まだ中身は読めない」
PARSE_DOCUMENT でテキスト抽出
↓ 「テキストになったが長すぎて検索に使えない」
SPLIT_TEXT_MARKDOWN_HEADER でチャンク分割
↓ 「検索しやすいサイズの断片になった」
Cortex Search Service 作成
↓ 「自然言語で検索できるようになった」
Streamlit でチャットボット UI
↓ 「質問 → 検索 → LLM回答 のRAGが完成」
Step 1-2: PDFのアップロード
ステージ(Stage)って何?
Snowflake内に用意されているファイル置き場のことです。CSV/JSON/PDFなどのファイルをここにアップロードしておき、SQLから参照してロードや解析を行います。AWSでいうS3バケットに近い位置付けですが、Snowflake内のロール/権限で直接アクセス制御できるのが特徴です。
Snowflake内に「ステージ」というファイルの置き場を作り、そこにPDFをアップロードします。
CREATE OR REPLACE STAGE fomc
DIRECTORY = (ENABLE = TRUE)
ENCRYPTION = (TYPE = 'SNOWFLAKE_SSE');
DIRECTORY = (ENABLE = TRUE) を付けるとステージ内のファイル一覧をSQLで取得できるようになります。後でPDFを一括処理するのに必要な設定です。
SnowsightのUIからドラッグ&ドロップでPDFをアップロードできます。
Step 3: PDFからテキスト抽出 → チャンク分割
ここがTutorial 3で新しく登場する部分です。
まずPARSE_DOCUMENTでPDFの中身をテキストに変換します。
CREATE OR REPLACE TABLE raw_text AS
SELECT
RELATIVE_PATH, -- ステージ内のファイルパス(例: fomcminutes20230201.pdf)
TO_VARCHAR(
SNOWFLAKE.CORTEX.PARSE_DOCUMENT( -- PDF → テキスト変換する Cortex 関数
'@fomc', -- ステージ名(@をつけて参照)
RELATIVE_PATH, -- 対象ファイル
{'mode': 'LAYOUT'} -- 見出し構造を保持するモード
):content -- 抽出結果の JSON から content 部分を取り出す
) AS EXTRACTED_LAYOUT
FROM DIRECTORY('@fomc') -- ステージ内のファイル一覧を取得する関数
WHERE RELATIVE_PATH LIKE '%.pdf'; -- PDF ファイルだけに絞る
いくつか Snowflake 特有の構文があるので補足します。
DIRECTORY('@fomc'): ステージ内のファイル一覧をテーブルのように返す関数です。RELATIVE_PATHというカラムでファイル名が取れます。PARSE_DOCUMENT(...): Cortex が提供する PDF 解析関数です。'LAYOUT'モードを指定すると、PDFの見出し構造がMarkdown形式(#、##等)で保持されます。:content: Snowflake の半構造化データ(JSON)アクセス構文です。PARSE_DOCUMENTの戻り値は JSON なので、そこからcontentキーの値を取り出しています。前回の記事でやったv:tempと同じ書き方です。
次にSPLIT_TEXT_MARKDOWN_HEADERでチャンク分割します。
SNOWFLAKE.CORTEX.SPLIT_TEXT_MARKDOWN_HEADER(
EXTRACTED_LAYOUT, -- 分割対象のテキスト
OBJECT_CONSTRUCT('#', 'header_1', '##', 'header_2'), -- どのヘッダーレベルを区切りに使うか
2000, -- チャンクの最大文字数
300 -- オーバーラップ
)
Tutorial 1ではSPLIT_TEXT_RECURSIVE_CHARACTER(文字数ベースの分割)を使いましたが、今回はMarkdownのヘッダーを区切りとして「意味のあるまとまり」で分割します。PDFからLAYOUTモードでテキスト抽出したのは、このヘッダー情報を使うためでした。
OBJECT_CONSTRUCT('#', 'header_1', '##', 'header_2') は Snowflake でキーと値のペアからJSONオブジェクトを作る関数です。ここでは「# を header_1、## を header_2 として扱う」という定義を渡しています。分割された各チャンクに「どのセクションのテキストか」のヘッダー情報が付与されるため、後の検索精度が上がります。
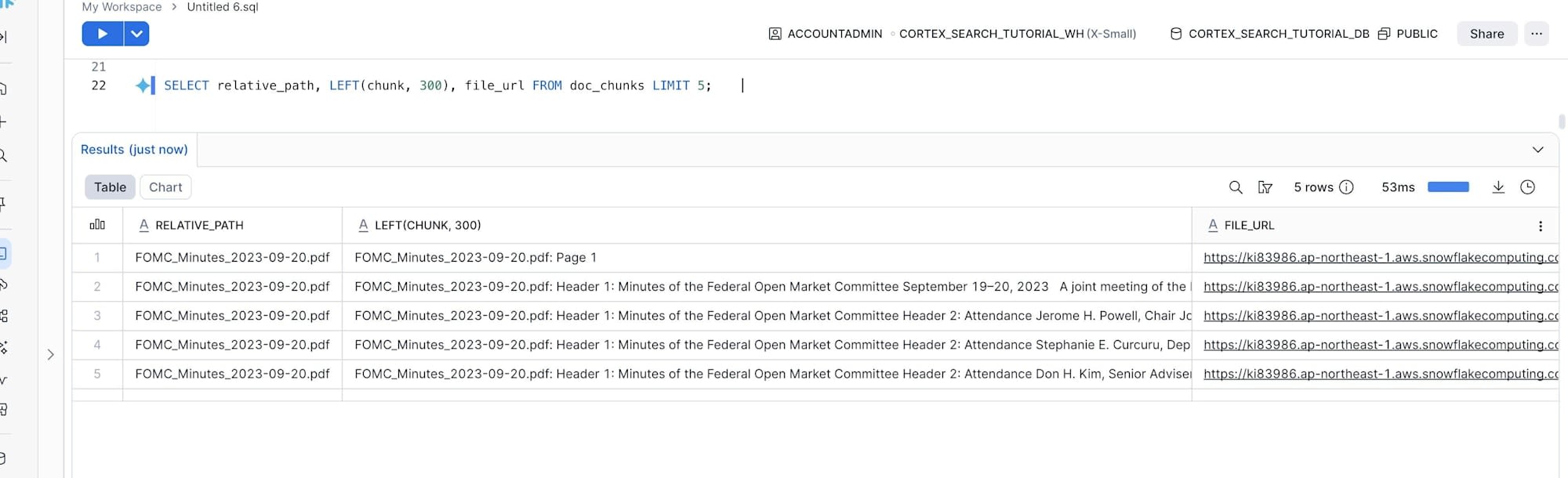
12本のPDFから422個のチャンクが生成されました。中身を LIMIT 5 で5件だけプレビューしたのが以下です。各チャンクに Header 1: Minutes of the Federal Open Market Committee のようなヘッダー情報が付いているのが確認できます。
Step 4-5: 検索サービスとチャットボット
ここからはTutorial 2とほぼ同じ流れです。Cortex Search Serviceを作成し、Streamlitでチャットボットを構築します。
Tutorial 3で追加された機能として、回答の下にReferences(参照元PDF)のリンクテーブルが表示されます。「この回答はどのPDFの情報に基づいているか」が一目で分かるようになっており、RAGの実用性として重要な要素です。
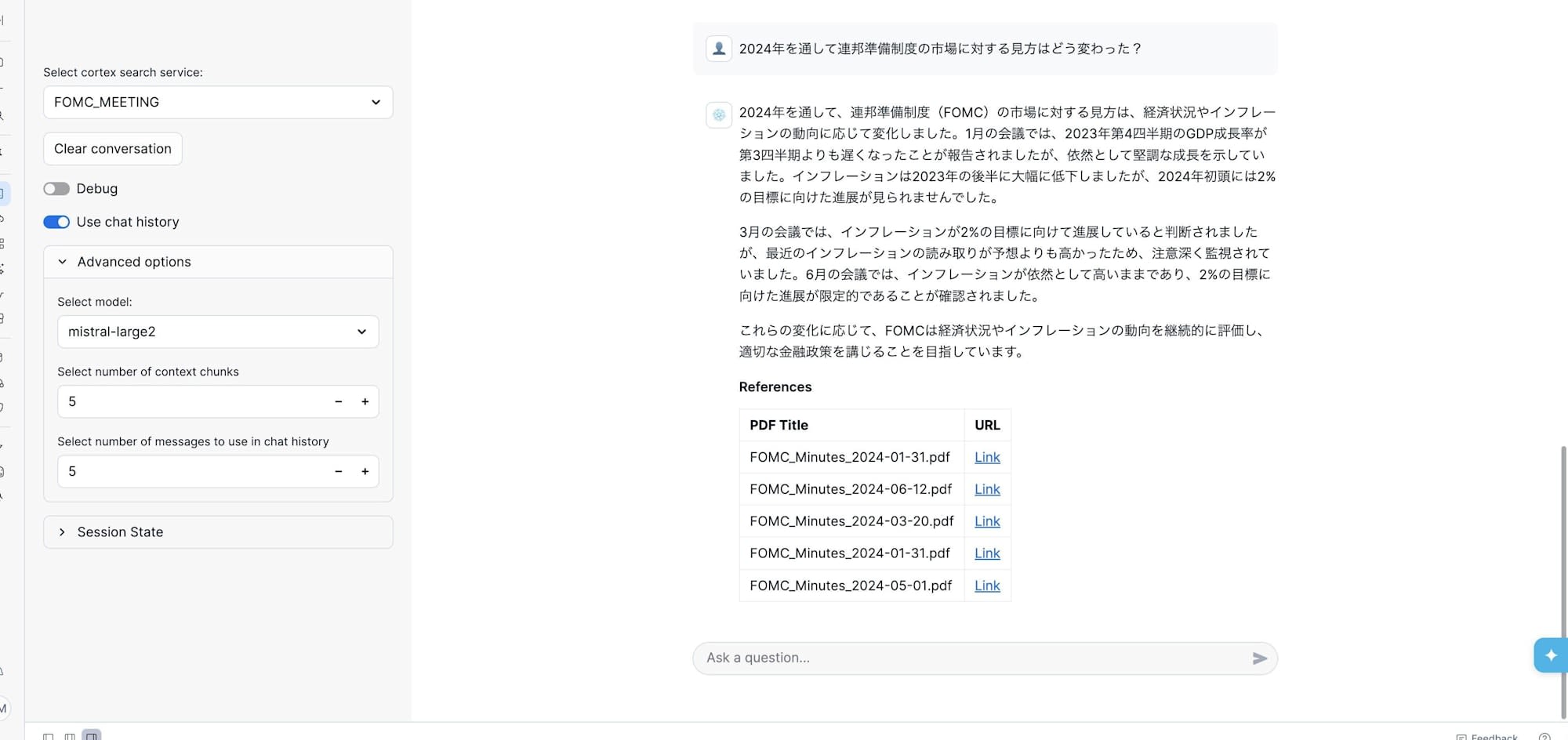
日本語で質問しても、LLMが英語のPDFから情報を取得して日本語で回答してくれました。
ハマったところ
StreamlitアプリでCOMPLETE関数を呼ぶ際、Python SDKのComplete()関数(REST API経由)がアカウントの制限でブロックされました。
# ❌ これがブロックされた
from snowflake.cortex import Complete
Complete(model, prompt)
ワークシートのSQL関数(SNOWFLAKE.CORTEX.COMPLETE())は動いたので、Python SDK経由からSQL経由に切り替えて解決しました。
# ✅ SQL経由に変更
result = session.sql(
f"SELECT SNOWFLAKE.CORTEX.COMPLETE('{model}', '{prompt}') AS response"
).collect()
やっていることは同じ(LLMにプロンプトを投げて回答を得る)ですが、裏の通信経路が違います。トライアルアカウントや特定のリージョンでこの制限に当たることがあるようです。同じエラーが出た方はこの方法を試してみてください。
まとめ:AWSメインでやってきた自分から見た Cortex Search
3つのチュートリアルを通して、Snowflake上でRAGチャットボットを構築するまでの一連の流れを体験しました。
改めて驚いたのは、必要なものが全部Snowflakeの中に揃っているという点です。
| やりたいこと | AWSでの構成例 | Snowflakeでは |
|---|---|---|
| テキストの意味検索 | OpenSearch Serverless + 埋め込みモデル + インデックス管理 | CREATE CORTEX SEARCH SERVICE |
| LLM呼び出し | Bedrock + IAM + Lambda | SNOWFLAKE.CORTEX.COMPLETE() |
| PDF解析 | Textract + S3 + Lambda | PARSE_DOCUMENT() |
| フロントエンドUI | Amplify or S3 + CloudFront | Streamlit in Snowflake |
| 認証・権限管理 | IAM + Cognito | Snowflakeのロール |
AWSだと複数のサービスを組み合わせて構築する必要があるものが、SnowflakeではSQLとPythonスクリプトだけで完結します。AWSでの構築・運用に慣れている身としては、「この部分を全部Snowflakeが吸収してくれるのか」という感覚でした。
もちろん、細かいカスタマイズ性や既存AWSリソースとの統合ではAWSに分がある場面もあると思います。ただ「とにかく早くRAGを試したい」「基盤の面倒を見たくない」という場面では、Snowflakeの統合的なアプローチは非常に魅力的でした。
次はCortex Analyst(自然言語からSQL生成)とSnowflake Intelligence(AIエージェント)の実践編を書く予定です。Cortex Searchで作った検索機能が、Intelligenceの中でどう「ツール」として呼び出されるのか、そのあたりも含めて深掘りしていきます。









