
Snowflakeのタスクだけで重複削除・差分更新を行うデータパイプラインを構築してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
さがらです。
Snowflakeのタスクだけで重複削除・差分更新を行うデータパイプラインを構築してみたので、その内容をまとめてみます。
Snowflakeのタスクとは
まず簡単に、Snowflakeのタスクについて説明しておきます。
- 概要
- COPY INTO、CREATE TABLE、INSERT、MERGE等任意のSQL文を定期実行できる機能
- 設定方法
create taskコマンドで作成alter task ~~ resumeコマンドあるいはsystem$task_dependents_enableシステム関数でタスクを有効化
- 使用するコンピュートリソース
- タスク:ユーザー側で作成したウェアハウス
- 一度起動すると60秒必ず起動するため、60秒分のコストが発生する
- サーバーレスタスク:Snowflake管理のリソース
- 実行時間の分だけ、コストが発生する。60秒未満の場合でもその所要時間だけコストが発生
- ただ、実行時間が60秒以上で同じ&コンピュートリソースのスペックも同じ場合は、タスクよりもサーバーレスタスクの方が単価が高い
- タスク:ユーザー側で作成したウェアハウス
- エラー通知
- ERROR_INTEGRATIONパラメータでAmazon SNSと連携した通知が可能
タスク利用時の注意点
タスクを利用する際は、下記の内容に注意する必要があります。
- タスクに親子関係を持たせてタスクグラフを作成するには、すべてのタスクが同一データベース・スキーマ内にないといけない
- そのため、全ての処理をタスクで実行する場合には、
TASK_DBみたいなデータベースを1つ作成することを推奨 - 参考Docs
- そのため、全ての処理をタスクで実行する場合には、
- タスクグラフ上には、ルートタスクは1つだけ設定できる(複数のルートタスクがあるタスクグラフは作れない)
- タスクグラフは最大1000個のタスクに制限される
- 1つのタスクには、最大100個の親タスクと100個の子タスクを含めることが可能
alter taskでタスクのSQL定義等を変更する際は、ルートタスクがsuspendになっていないといけない
タスクによるパイプラインの構築
では早速、タスクによるパイプライン構築をしていきます。
今回はあくまで検証のため、全てACCOUNTADMINロールで実行します。
前提条件
以下の3層構成でパイプラインを作成します。
- RAW層:ステージからロードしたデータをそのままの形で保持するレイヤー
- STG層:RAW層でロードしたデータでは主キーごとに重複が発生するため、その重複を削除するレイヤー
- MART層:STG層で重複削除を行ったデータを元に、エンドユーザーが利用するデータを管理するレイヤー
必要なデータベース・スキーマ・ウェアハウスの作成
「Snowflakeのタスク利用時の注意点」章でも述べたように、タスクの依存関係を持たせるためには1つのデータベース・スキーマに全てのタスクが作成されている必要があります。以下ではsagara_task_db.task_schemaをタスク用のデータベース・スキーマとして作成しています。
-- データベースの作成
create database sagara_test_db;
create database sagara_task_db; -- タスク専用のデータベースを追加
-- スキーマの作成
use database sagara_test_db;
create schema raw;
create schema stg;
create schema mart;
-- タスク用スキーマの作成
use database sagara_task_db;
create schema task_schema;
-- ウェアハウスの作成
create warehouse if not exists compute_wh
with
warehouse_size = 'xs'
auto_suspend = 60
auto_resume = true;
内部ステージとファイルフォーマットの作成
メタデータをつけてロードするために、ファイルフォーマットのオプションは少し変更しています。(参考ブログ)
-- 名前付き内部ステージの作成
create or replace stage sagara_test_db.raw.raw_stage;
-- 日本語データ用のCSVファイルフォーマットの作成(メタデータ対応)
create or replace file format sagara_test_db.raw.csv_format_with_metadata
type = 'csv'
parse_header = true
error_on_column_count_mismatch = false
field_delimiter = ','
encoding = 'UTF8';
RAW層のテーブル定義
-- RAW層のテーブル作成
create or replace table sagara_test_db.raw.raw_customer (
"顧客ID" int,
"氏名" varchar(100),
"年齢" int,
"住所" varchar(200),
"登録日" date,
"メールアドレス" varchar(100),
"メタデータ_ファイル名" varchar(255),
"メタデータ_ファイル更新日時" timestamp_ntz,
"メタデータ_ファイルロード日時" timestamp_ntz
);
create or replace table sagara_test_db.raw.raw_product (
"商品ID" int,
"商品名" varchar(100),
"カテゴリ" varchar(50),
"単価" decimal(10,2),
"在庫数" int,
"メーカー" varchar(100),
"メタデータ_ファイル名" varchar(255),
"メタデータ_ファイル更新日時" timestamp_ntz,
"メタデータ_ファイルロード日時" timestamp_ntz
);
create or replace table sagara_test_db.raw.raw_purchase (
"購入明細ID" int,
"顧客ID" int,
"商品ID" int,
"購入日" date,
"数量" int,
"購入金額" decimal(10,2),
"支払方法" varchar(50),
"配送状況" varchar(50),
"メタデータ_ファイル名" varchar(255),
"メタデータ_ファイル更新日時" timestamp_ntz,
"メタデータ_ファイルロード日時" timestamp_ntz
);
RAW層へのデータロード用タスク
RAW層へのデータロード用のタスクの前に、1つroot_taskを設けています。各データロード用のタスクそれぞれをルートタスクにしようとするとエラーになるため、関係するデータロードのタスクは全て1つのルートタスクの子タスクにするのがオススメです。
-- ルートタスクを作成(スケジュール付き)
create or replace task sagara_task_db.task_schema.root_task
warehouse = compute_wh
schedule = 'USING CRON 0 9 1 1 * Asia/Tokyo' -- 毎年1月1日9時(日本時間)に実行
as
select 1 as dummy;
-- RAW層へのデータロードタスク(ルートタスクの後に実行)
create or replace task sagara_task_db.task_schema.load_raw_customer
warehouse = compute_wh
after sagara_task_db.task_schema.root_task
as
copy into sagara_test_db.raw.raw_customer
from @sagara_test_db.raw.raw_stage/customer
file_format = sagara_test_db.raw.csv_format_with_metadata
match_by_column_name = case_insensitive
include_metadata = (
"メタデータ_ファイル名" = metadata$filename,
"メタデータ_ファイル更新日時" = metadata$file_last_modified,
"メタデータ_ファイルロード日時" = metadata$start_scan_time
);
create or replace task sagara_task_db.task_schema.load_raw_product
warehouse = compute_wh
after sagara_task_db.task_schema.root_task
as
copy into sagara_test_db.raw.raw_product
from @sagara_test_db.raw.raw_stage/product
file_format = sagara_test_db.raw.csv_format_with_metadata
match_by_column_name = case_insensitive
include_metadata = (
"メタデータ_ファイル名" = metadata$filename,
"メタデータ_ファイル更新日時" = metadata$file_last_modified,
"メタデータ_ファイルロード日時" = metadata$start_scan_time
);
create or replace task sagara_task_db.task_schema.load_raw_purchase
warehouse = compute_wh
after sagara_task_db.task_schema.root_task
as
copy into sagara_test_db.raw.raw_purchase
from @sagara_test_db.raw.raw_stage/purchase
file_format = sagara_test_db.raw.csv_format_with_metadata
match_by_column_name = case_insensitive
include_metadata = (
"メタデータ_ファイル名" = metadata$filename,
"メタデータ_ファイル更新日時" = metadata$file_last_modified,
"メタデータ_ファイルロード日時" = metadata$start_scan_time
);
STG層のテーブル定義
-- STG層のテーブル作成
create table if not exists sagara_test_db.stg.stg_customer (
"顧客ID" int,
"氏名" varchar(100),
"年齢" int,
"住所" varchar(200),
"登録日" date,
"メールアドレス" varchar(100),
"メタデータ_ファイル名" varchar(255),
"メタデータ_ファイル更新日時" timestamp_ntz,
"メタデータ_ファイルロード日時" timestamp_ntz,
"メタデータ_レコード更新日時" timestamp_ntz default current_timestamp()
);
create table if not exists sagara_test_db.stg.stg_product (
"商品ID" int,
"商品名" varchar(100),
"カテゴリ" varchar(50),
"単価" decimal(10,2),
"在庫数" int,
"メーカー" varchar(100),
"メタデータ_ファイル名" varchar(255),
"メタデータ_ファイル更新日時" timestamp_ntz,
"メタデータ_ファイルロード日時" timestamp_ntz,
"メタデータ_レコード更新日時" timestamp_ntz default current_timestamp()
);
create table if not exists sagara_test_db.stg.stg_purchase (
"購入明細ID" int,
"顧客ID" int,
"商品ID" int,
"購入日" date,
"数量" int,
"購入金額" decimal(10,2),
"支払方法" varchar(50),
"配送状況" varchar(50),
"メタデータ_ファイル名" varchar(255),
"メタデータ_ファイル更新日時" timestamp_ntz,
"メタデータ_ファイルロード日時" timestamp_ntz,
"メタデータ_レコード更新日時" timestamp_ntz default current_timestamp()
);
STG層の差分更新実装
MERGE文を用いてSTG層の実装を行います。
dbtのIncremental Modelのクエリを参考に、メタデータ_ファイルロード日時のMAX値より大きい値を持つレコードだけをMERGE文の対象としています。
STG層はRAW層と1:1で紐づくため、各タスクの親は該当するRAW層のテーブルへのデータロードタスクに設定しています。
-- 顧客データのMERGE処理(増分更新)
create or replace task sagara_task_db.task_schema.merge_stg_customer
warehouse = compute_wh
after sagara_task_db.task_schema.load_raw_customer
as
merge into sagara_test_db.stg.stg_customer target
using (
select
"顧客ID",
"氏名",
"年齢",
"住所",
"登録日",
"メールアドレス",
"メタデータ_ファイル名",
"メタデータ_ファイル更新日時",
"メタデータ_ファイルロード日時"
from (
select
"顧客ID",
"氏名",
"年齢",
"住所",
"登録日",
"メールアドレス",
"メタデータ_ファイル名",
"メタデータ_ファイル更新日時",
"メタデータ_ファイルロード日時",
row_number() over (partition by "顧客ID" order by "メタデータ_ファイルロード日時" desc) as rn
from sagara_test_db.raw.raw_customer
-- 増分更新: 最後に処理したロード日時以降のデータのみを取得
where "メタデータ_ファイルロード日時" > (
select coalesce(max("メタデータ_ファイルロード日時"), '1900-01-01'::timestamp_ntz)
from sagara_test_db.stg.stg_customer
)
)
where rn = 1
) source
on target."顧客ID" = source."顧客ID"
when matched then update set
target."氏名" = source."氏名",
target."年齢" = source."年齢",
target."住所" = source."住所",
target."登録日" = source."登録日",
target."メールアドレス" = source."メールアドレス",
target."メタデータ_ファイル名" = source."メタデータ_ファイル名",
target."メタデータ_ファイル更新日時" = source."メタデータ_ファイル更新日時",
target."メタデータ_ファイルロード日時" = source."メタデータ_ファイルロード日時",
target."メタデータ_レコード更新日時" = current_timestamp()
when not matched then insert (
"顧客ID", "氏名", "年齢", "住所", "登録日", "メールアドレス",
"メタデータ_ファイル名", "メタデータ_ファイル更新日時", "メタデータ_ファイルロード日時", "メタデータ_レコード更新日時"
) values (
source."顧客ID",
source."氏名",
source."年齢",
source."住所",
source."登録日",
source."メールアドレス",
source."メタデータ_ファイル名",
source."メタデータ_ファイル更新日時",
source."メタデータ_ファイルロード日時",
current_timestamp()
);
-- 商品データのMERGE処理(増分更新)
create or replace task sagara_task_db.task_schema.merge_stg_product
warehouse = compute_wh
after sagara_task_db.task_schema.load_raw_product
as
merge into sagara_test_db.stg.stg_product target
using (
select
"商品ID",
"商品名",
"カテゴリ",
"単価",
"在庫数",
"メーカー",
"メタデータ_ファイル名",
"メタデータ_ファイル更新日時",
"メタデータ_ファイルロード日時"
from (
select
"商品ID",
"商品名",
"カテゴリ",
"単価",
"在庫数",
"メーカー",
"メタデータ_ファイル名",
"メタデータ_ファイル更新日時",
"メタデータ_ファイルロード日時",
row_number() over (partition by "商品ID" order by "メタデータ_ファイルロード日時" desc) as rn
from sagara_test_db.raw.raw_product
-- 増分更新: 最後に処理したロード日時以降のデータのみを取得
where "メタデータ_ファイルロード日時" > (
select coalesce(max("メタデータ_ファイルロード日時"), '1900-01-01'::timestamp_ntz)
from sagara_test_db.stg.stg_product
)
)
where rn = 1
) source
on target."商品ID" = source."商品ID"
when matched then update set
target."商品名" = source."商品名",
target."カテゴリ" = source."カテゴリ",
target."単価" = source."単価",
target."在庫数" = source."在庫数",
target."メーカー" = source."メーカー",
target."メタデータ_ファイル名" = source."メタデータ_ファイル名",
target."メタデータ_ファイル更新日時" = source."メタデータ_ファイル更新日時",
target."メタデータ_ファイルロード日時" = source."メタデータ_ファイルロード日時",
target."メタデータ_レコード更新日時" = current_timestamp()
when not matched then insert (
"商品ID", "商品名", "カテゴリ", "単価", "在庫数", "メーカー",
"メタデータ_ファイル名", "メタデータ_ファイル更新日時", "メタデータ_ファイルロード日時", "メタデータ_レコード更新日時"
) values (
source."商品ID",
source."商品名",
source."カテゴリ",
source."単価",
source."在庫数",
source."メーカー",
source."メタデータ_ファイル名",
source."メタデータ_ファイル更新日時",
source."メタデータ_ファイルロード日時",
current_timestamp()
);
-- 購入データのMERGE処理(増分更新)
create or replace task sagara_task_db.task_schema.merge_stg_purchase
warehouse = compute_wh
after sagara_task_db.task_schema.load_raw_purchase
as
merge into sagara_test_db.stg.stg_purchase target
using (
select
"購入明細ID",
"顧客ID",
"商品ID",
"購入日",
"数量",
"購入金額",
"支払方法",
"配送状況",
"メタデータ_ファイル名",
"メタデータ_ファイル更新日時",
"メタデータ_ファイルロード日時"
from (
select
"購入明細ID",
"顧客ID",
"商品ID",
"購入日",
"数量",
"購入金額",
"支払方法",
"配送状況",
"メタデータ_ファイル名",
"メタデータ_ファイル更新日時",
"メタデータ_ファイルロード日時",
row_number() over (partition by "購入明細ID" order by "メタデータ_ファイルロード日時" desc) as rn
from sagara_test_db.raw.raw_purchase
-- 増分更新: 最後に処理したロード日時以降のデータのみを取得
where "メタデータ_ファイルロード日時" > (
select coalesce(max("メタデータ_ファイルロード日時"), '1900-01-01'::timestamp_ntz)
from sagara_test_db.stg.stg_purchase
)
)
where rn = 1
) source
on target."購入明細ID" = source."購入明細ID"
when matched then update set
target."顧客ID" = source."顧客ID",
target."商品ID" = source."商品ID",
target."購入日" = source."購入日",
target."数量" = source."数量",
target."購入金額" = source."購入金額",
target."支払方法" = source."支払方法",
target."配送状況" = source."配送状況",
target."メタデータ_ファイル名" = source."メタデータ_ファイル名",
target."メタデータ_ファイル更新日時" = source."メタデータ_ファイル更新日時",
target."メタデータ_ファイルロード日時" = source."メタデータ_ファイルロード日時",
target."メタデータ_レコード更新日時" = current_timestamp()
when not matched then insert (
"購入明細ID", "顧客ID", "商品ID", "購入日", "数量", "購入金額", "支払方法", "配送状況",
"メタデータ_ファイル名", "メタデータ_ファイル更新日時", "メタデータ_ファイルロード日時", "メタデータ_レコード更新日時"
) values (
source."購入明細ID",
source."顧客ID",
source."商品ID",
source."購入日",
source."数量",
source."購入金額",
source."支払方法",
source."配送状況",
source."メタデータ_ファイル名",
source."メタデータ_ファイル更新日時",
source."メタデータ_ファイルロード日時",
current_timestamp()
);
MART層のテーブル定義
-- MART層のテーブル作成(初回のみ)
create table if not exists sagara_test_db.mart.mart_customer_purchase (
"顧客ID" int,
"氏名" varchar(100),
"年齢" int,
"住所" varchar(200),
"購入回数" int,
"合計購入金額" decimal(15,2),
"最終購入日" date,
"最頻購入カテゴリ" varchar(50),
"最頻支払方法" varchar(50),
"メタデータ_レコード更新日時" timestamp_ntz default current_timestamp()
);
create table if not exists sagara_test_db.mart.mart_product_sales (
"商品ID" int,
"商品名" varchar(100),
"カテゴリ" varchar(50),
"メーカー" varchar(100),
"販売数量" int,
"販売金額" decimal(15,2),
"購入顧客数" int,
"平均購入年齢" float,
"メタデータ_レコード更新日時" timestamp_ntz default current_timestamp()
);
create table if not exists sagara_test_db.mart.mart_sales_summary (
"集計日" date,
"カテゴリ" varchar(50),
"販売数量" int,
"販売金額" decimal(15,2),
"購入顧客数" int,
"前月比" float,
"メタデータ_レコード更新日時" timestamp_ntz default current_timestamp()
);
MART層の差分更新実装
MERGE文を用いてMART層の実装を行います。
MART層についてもSTG層と同様に差分のレコードだけを処理したいですが、今回定義するMART層のクエリは対象テーブルの全レコードを集計する仕様のために、差分のレコードだけの処理が出来ません。MART層の差分レコード処理は、可能な場合だけ行うようにしましょう。
STG層の更新タスクが全て完了しないとMART層のテーブル更新に着手できないため、1つ中間タスクとしてstg_completeというタスクも用意しています。
-- STG層のすべてのテーブルが準備できた後に実行するため、新しい中間タスクを作成
create or replace task sagara_task_db.task_schema.stg_complete
warehouse = compute_wh
after sagara_task_db.task_schema.merge_stg_customer, sagara_task_db.task_schema.merge_stg_product, sagara_task_db.task_schema.merge_stg_purchase
as
select 1 as dummy;
-- 顧客購入情報のMERGE処理
create or replace task sagara_task_db.task_schema.merge_mart_customer_purchase
warehouse = compute_wh
after sagara_task_db.task_schema.stg_complete
as
merge into sagara_test_db.mart.mart_customer_purchase target
using (
with customer_purchase_summary as (
select
c."顧客ID",
c."氏名",
c."年齢",
c."住所",
count(p."購入明細ID") as "購入回数",
sum(p."購入金額") as "合計購入金額",
max(p."購入日") as "最終購入日"
from sagara_test_db.stg.stg_customer c
left join sagara_test_db.stg.stg_purchase p on c."顧客ID" = p."顧客ID"
group by c."顧客ID", c."氏名", c."年齢", c."住所"
),
category_frequency as (
select
p."顧客ID",
prod."カテゴリ",
count(*) as category_count,
row_number() over (partition by p."顧客ID" order by count(*) desc) as rn
from sagara_test_db.stg.stg_purchase p
join sagara_test_db.stg.stg_product prod on p."商品ID" = prod."商品ID"
group by p."顧客ID", prod."カテゴリ"
),
payment_frequency as (
select
p."顧客ID",
p."支払方法",
count(*) as payment_count,
row_number() over (partition by p."顧客ID" order by count(*) desc) as rn
from sagara_test_db.stg.stg_purchase p
group by p."顧客ID", p."支払方法"
)
select
cps."顧客ID",
cps."氏名",
cps."年齢",
cps."住所",
cps."購入回数",
cps."合計購入金額",
cps."最終購入日",
cf."カテゴリ" as "最頻購入カテゴリ",
pf."支払方法" as "最頻支払方法"
from customer_purchase_summary cps
left join category_frequency cf on cps."顧客ID" = cf."顧客ID" and cf.rn = 1
left join payment_frequency pf on cps."顧客ID" = pf."顧客ID" and pf.rn = 1
) source
on target."顧客ID" = source."顧客ID"
when matched then update set
target."氏名" = source."氏名",
target."年齢" = source."年齢",
target."住所" = source."住所",
target."購入回数" = source."購入回数",
target."合計購入金額" = source."合計購入金額",
target."最終購入日" = source."最終購入日",
target."最頻購入カテゴリ" = source."最頻購入カテゴリ",
target."最頻支払方法" = source."最頻支払方法",
target."メタデータ_レコード更新日時" = current_timestamp()
when not matched then insert (
"顧客ID", "氏名", "年齢", "住所", "購入回数", "合計購入金額", "最終購入日",
"最頻購入カテゴリ", "最頻支払方法", "メタデータ_レコード更新日時"
) values (
source."顧客ID",
source."氏名",
source."年齢",
source."住所",
source."購入回数",
source."合計購入金額",
source."最終購入日",
source."最頻購入カテゴリ",
source."最頻支払方法",
current_timestamp()
);
-- 商品販売情報のMERGE処理
create or replace task sagara_task_db.task_schema.merge_mart_product_sales
warehouse = compute_wh
after sagara_task_db.task_schema.stg_complete
as
merge into sagara_test_db.mart.mart_product_sales target
using (
select
p."商品ID",
p."商品名",
p."カテゴリ",
p."メーカー",
sum(pur."数量") as "販売数量",
sum(pur."購入金額") as "販売金額",
count(distinct pur."顧客ID") as "購入顧客数",
avg(c."年齢") as "平均購入年齢"
from sagara_test_db.stg.stg_product p
left join sagara_test_db.stg.stg_purchase pur on p."商品ID" = pur."商品ID"
left join sagara_test_db.stg.stg_customer c on pur."顧客ID" = c."顧客ID"
group by p."商品ID", p."商品名", p."カテゴリ", p."メーカー"
) source
on target."商品ID" = source."商品ID"
when matched then update set
target."商品名" = source."商品名",
target."カテゴリ" = source."カテゴリ",
target."メーカー" = source."メーカー",
target."販売数量" = source."販売数量",
target."販売金額" = source."販売金額",
target."購入顧客数" = source."購入顧客数",
target."平均購入年齢" = source."平均購入年齢",
target."メタデータ_レコード更新日時" = current_timestamp()
when not matched then insert (
"商品ID", "商品名", "カテゴリ", "メーカー", "販売数量", "販売金額",
"購入顧客数", "平均購入年齢", "メタデータ_レコード更新日時"
) values (
source."商品ID",
source."商品名",
source."カテゴリ",
source."メーカー",
source."販売数量",
source."販売金額",
source."購入顧客数",
source."平均購入年齢",
current_timestamp()
);
-- 売上サマリーのMERGE処理
create or replace task sagara_task_db.task_schema.merge_mart_sales_summary
warehouse = compute_wh
after sagara_task_db.task_schema.stg_complete
as
merge into sagara_test_db.mart.mart_sales_summary target
using (
with current_month_sales as (
select
date_trunc('month', p."購入日") as month_date,
prod."カテゴリ",
sum(p."数量") as total_quantity,
sum(p."購入金額") as total_amount,
count(distinct p."顧客ID") as customer_count
from sagara_test_db.stg.stg_purchase p
join sagara_test_db.stg.stg_product prod on p."商品ID" = prod."商品ID"
group by month_date, prod."カテゴリ"
),
previous_month_sales as (
select
dateadd('month', 1, month_date) as next_month,
"カテゴリ",
total_amount as prev_amount
from current_month_sales
)
select
cms.month_date as "集計日",
cms."カテゴリ",
cms.total_quantity as "販売数量",
cms.total_amount as "販売金額",
cms.customer_count as "購入顧客数",
case
when pms.prev_amount is null or pms.prev_amount = 0 then null
else (cms.total_amount - pms.prev_amount) / pms.prev_amount * 100
end as "前月比"
from current_month_sales cms
left join previous_month_sales pms on cms.month_date = pms.next_month and cms."カテゴリ" = pms."カテゴリ"
) source
on target."集計日" = source."集計日" and target."カテゴリ" = source."カテゴリ"
when matched then update set
target."販売数量" = source."販売数量",
target."販売金額" = source."販売金額",
target."購入顧客数" = source."購入顧客数",
target."前月比" = source."前月比",
target."メタデータ_レコード更新日時" = current_timestamp()
when not matched then insert (
"集計日", "カテゴリ", "販売数量", "販売金額", "購入顧客数", "前月比", "メタデータ_レコード更新日時"
) values (
source."集計日",
source."カテゴリ",
source."販売数量",
source."販売金額",
source."購入顧客数",
source."前月比",
current_timestamp()
);
タスクの有効化
タスクは作成しただけでは実行されないため、有効化する必要があります。有効化の際はsystem$task_dependents_enableというシステム関数が便利です。
-- 最上位のルートタスクを指定して、子タスクをまとめて有効化
call system$task_dependents_enable('sagara_task_db.task_schema.root_task');
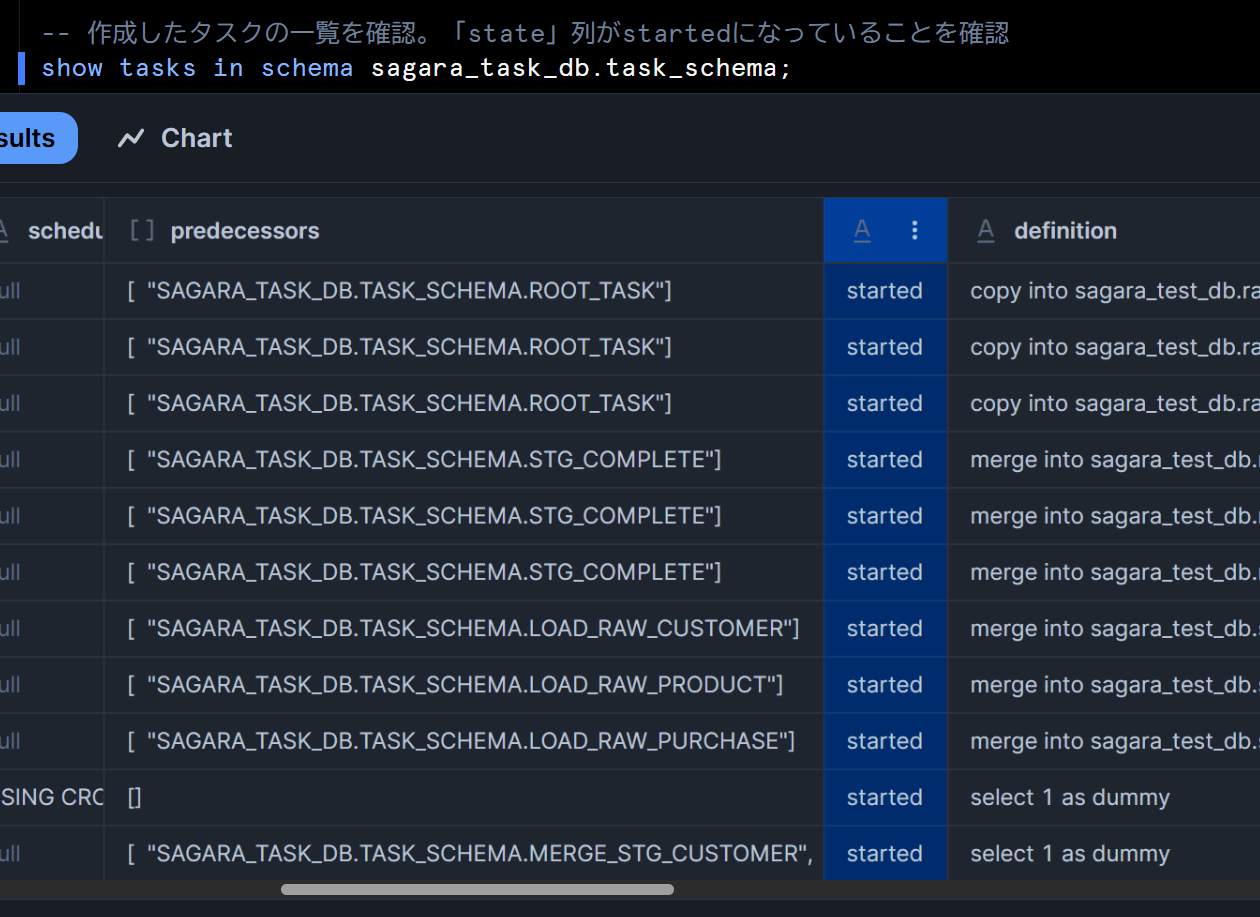
-- 作成したタスクの一覧を確認。「state」列がstartedになっていることを確認
show tasks in schema sagara_task_db.task_schema;
これにより、設定したタスクのstate列がstartedとなります。
参考情報:タスクの無効化
今回はタスクの無効化は不要なのですが、運用する中でタスクの定義を更新する際はルートタスク無効化が必要です。
以下では参考までに全てのタスクを無効化する例を載せておきます。無効化はシステム関数がないため、ルートタスクから順に無効化する必要があります。
-- ルートタスク(最初に一時停止)
alter task sagara_task_db.task_schema.root_task suspend;
-- RAW層のタスク
alter task sagara_task_db.task_schema.load_raw_customer suspend;
alter task sagara_task_db.task_schema.load_raw_product suspend;
alter task sagara_task_db.task_schema.load_raw_purchase suspend;
-- STG層のタスク
alter task sagara_task_db.task_schema.merge_stg_customer suspend;
alter task sagara_task_db.task_schema.merge_stg_product suspend;
alter task sagara_task_db.task_schema.merge_stg_purchase suspend;
-- 中間タスク
alter task sagara_task_db.task_schema.stg_complete suspend;
-- MART層のタスク(最も末端)
alter task sagara_task_db.task_schema.merge_mart_customer_purchase suspend;
alter task sagara_task_db.task_schema.merge_mart_product_sales suspend;
alter task sagara_task_db.task_schema.merge_mart_sales_summary suspend;
-- 作成したタスクの一覧を確認。「state」列がsuspendedになっていることを確認
show tasks in schema sagara_task_db.task_schema;
構築したタスクグラフ
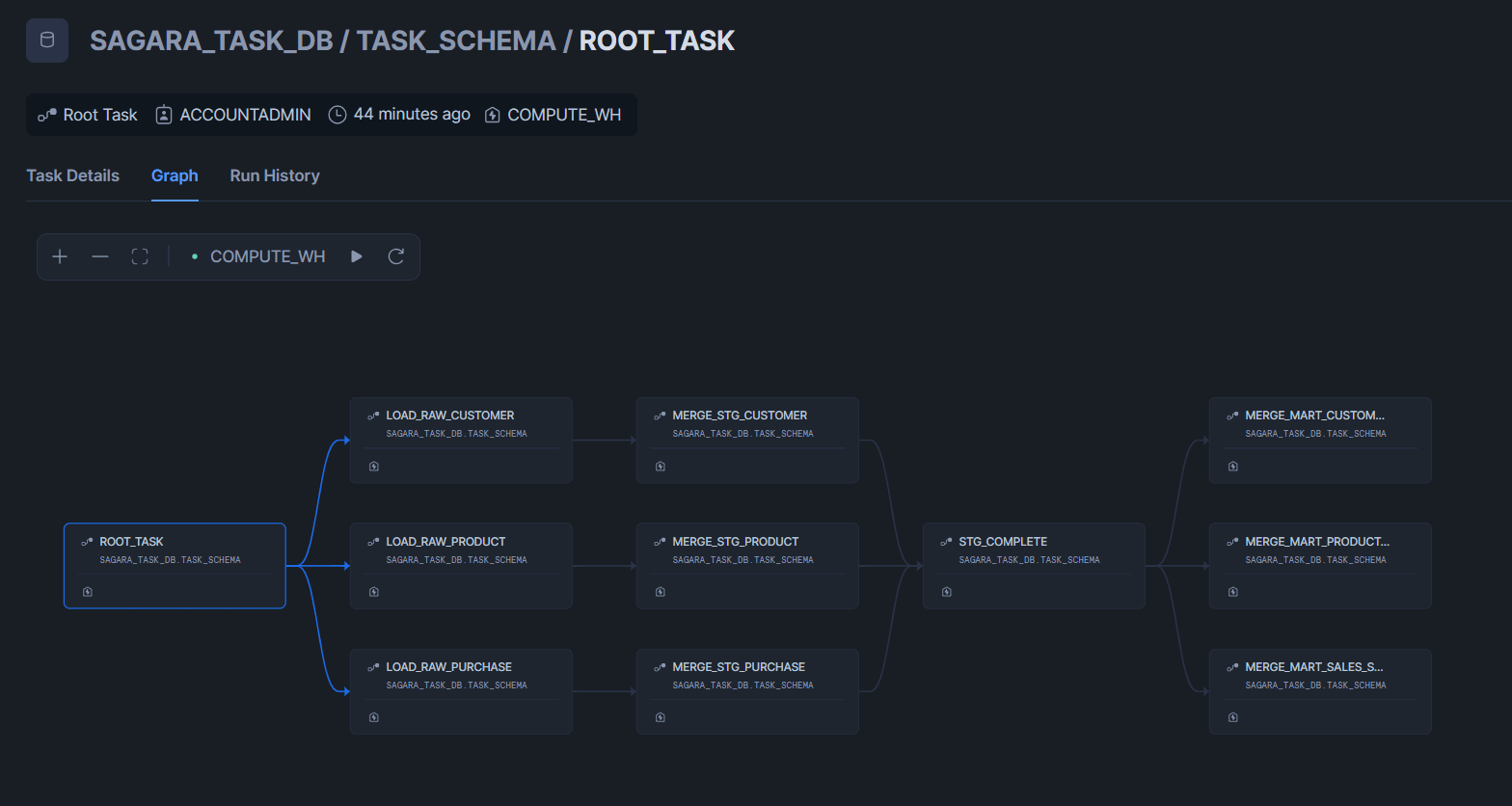
CSVファイルを1つずつ格納しパイプラインの動作確認
投入するデータ
まずは作成した内部ステージに対して、CSVファイルを各テーブルごとに1つずつ格納します。
- customer_data_20230601.csv(raw_customerへロード)
顧客ID,氏名,年齢,住所,登録日,メールアドレス
1,田中太郎,35,東京都新宿区,2023-01-01,tanaka@example.com
2,佐藤花子,28,大阪府大阪市,2023-01-15,sato@example.com
3,鈴木一郎,42,北海道札幌市,2023-01-20,suzuki@example.com
4,高橋みどり,31,福岡県福岡市,2023-02-01,takahashi@example.com
5,伊藤健太,39,愛知県名古屋市,2023-02-10,ito@example.com
- product_data_20230601.csv(raw_productへロード)
商品ID,商品名,カテゴリ,単価,在庫数,メーカー
101,高級腕時計,アクセサリー,85000.00,12,スイス時計
102,スマートフォン,電子機器,65000.00,35,テックコーポ
103,ノートパソコン,電子機器,120000.00,8,コンピュータ社
104,ダイニングテーブル,家具,45000.00,5,木工房
105,ゴルフセット,スポーツ,78000.00,15,スポーツギア
- purchase_data_20230601.csv(raw_purchaseへロード)
購入明細ID,顧客ID,商品ID,購入日,数量,購入金額,支払方法,配送状況
1001,1,102,2023-01-15,1,65000.00,クレジットカード,配送済み
1002,2,107,2023-02-20,1,25000.00,銀行振込,配送済み
1003,3,101,2023-01-30,1,85000.00,クレジットカード,配送済み
1004,4,106,2023-03-05,1,55000.00,電子マネー,配送中
1005,5,104,2023-02-10,1,45000.00,クレジットカード,配送済み
※下図は内部ステージへのアップロードの際の一例です。
タスク実行とデータの確認
実際に以下のクエリでタスクを手動実行してデータを確認してみます。
-- ルートタスクの手動実行
execute task sagara_task_db.task_schema.root_task;
以下、RAWとSTGレイヤーでテーブルを1つ、MARTレイヤーでは3つ全て、テーブルの中身を確認してみます。※生成AIで作ったデータファイルのため、まだ商品IDが登録されていないデータも存在しますが、2回目のタスク実行時に更新されます。
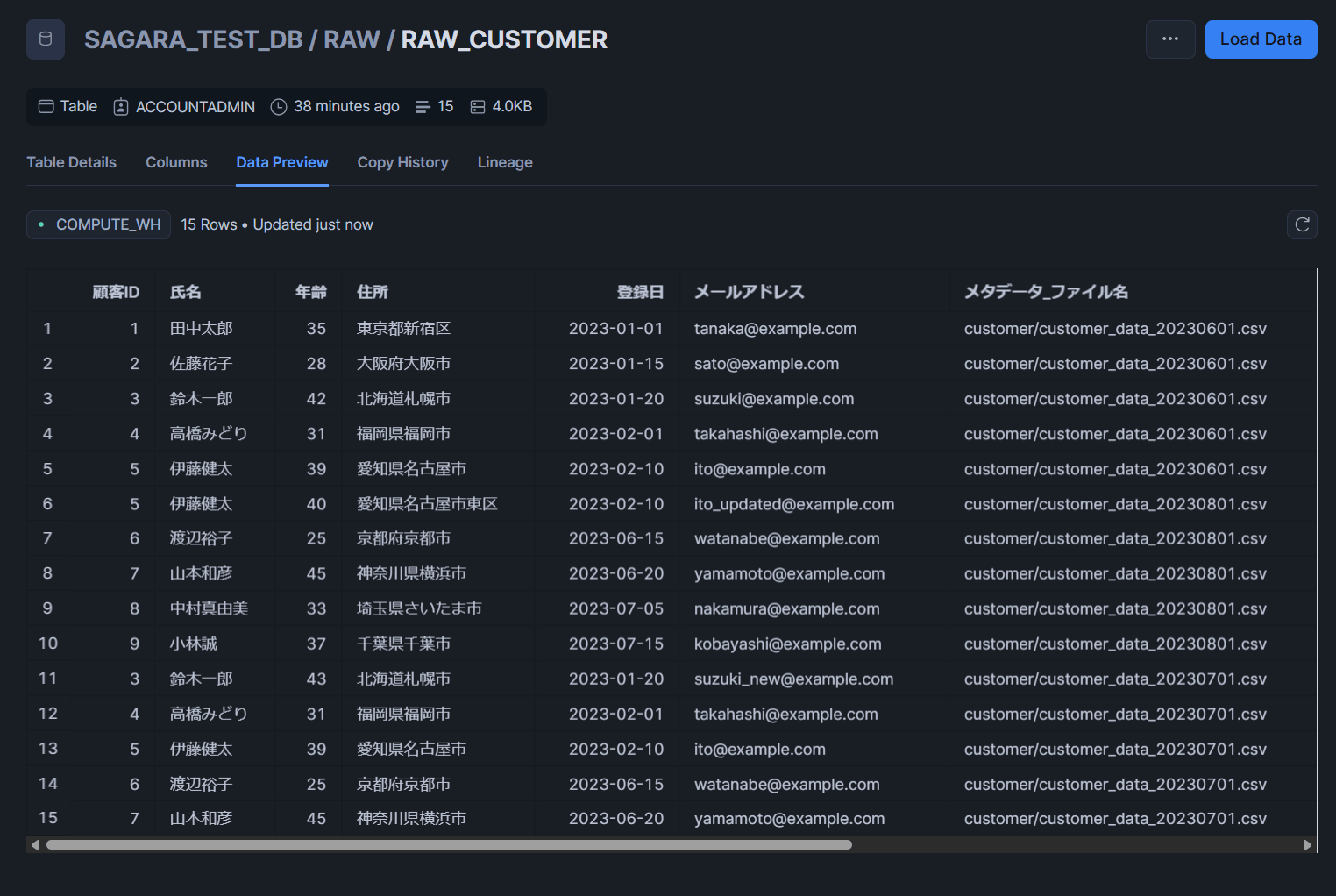
RAW_CUSTOMERテーブル
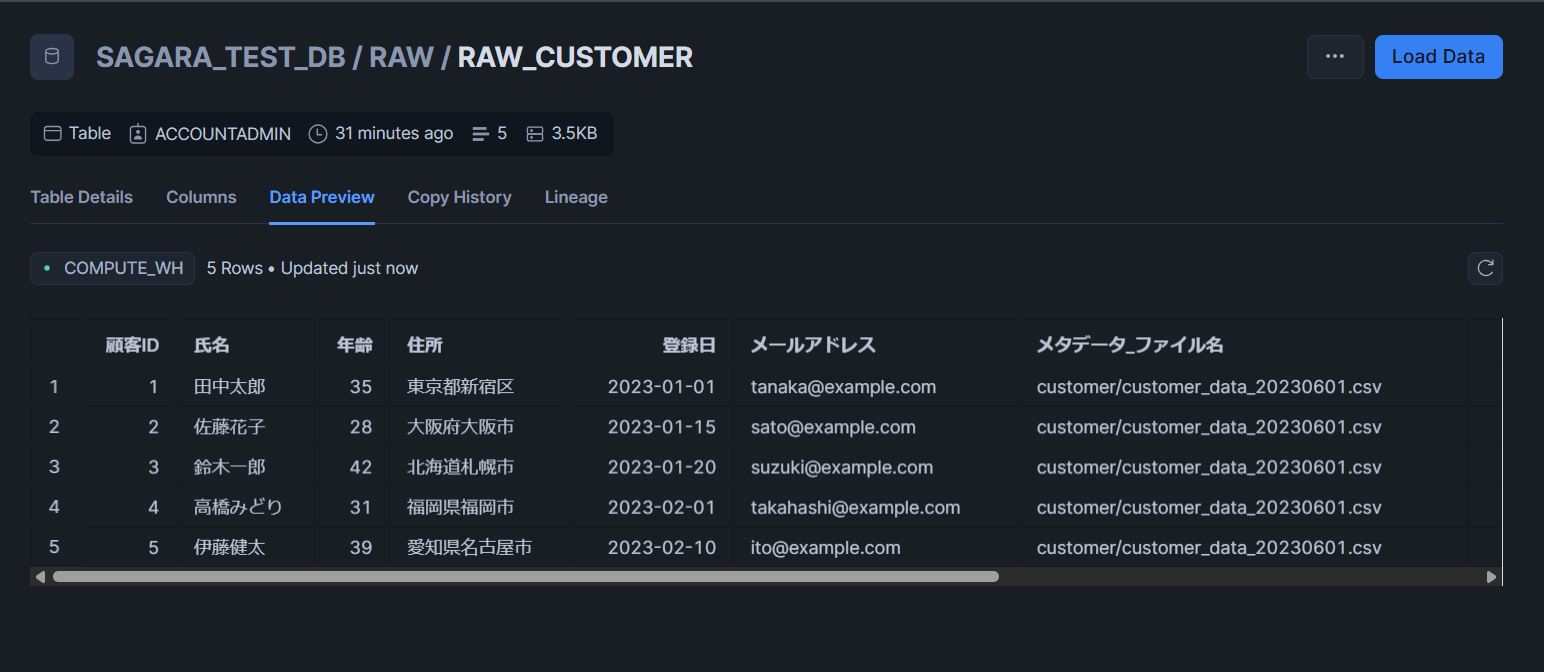
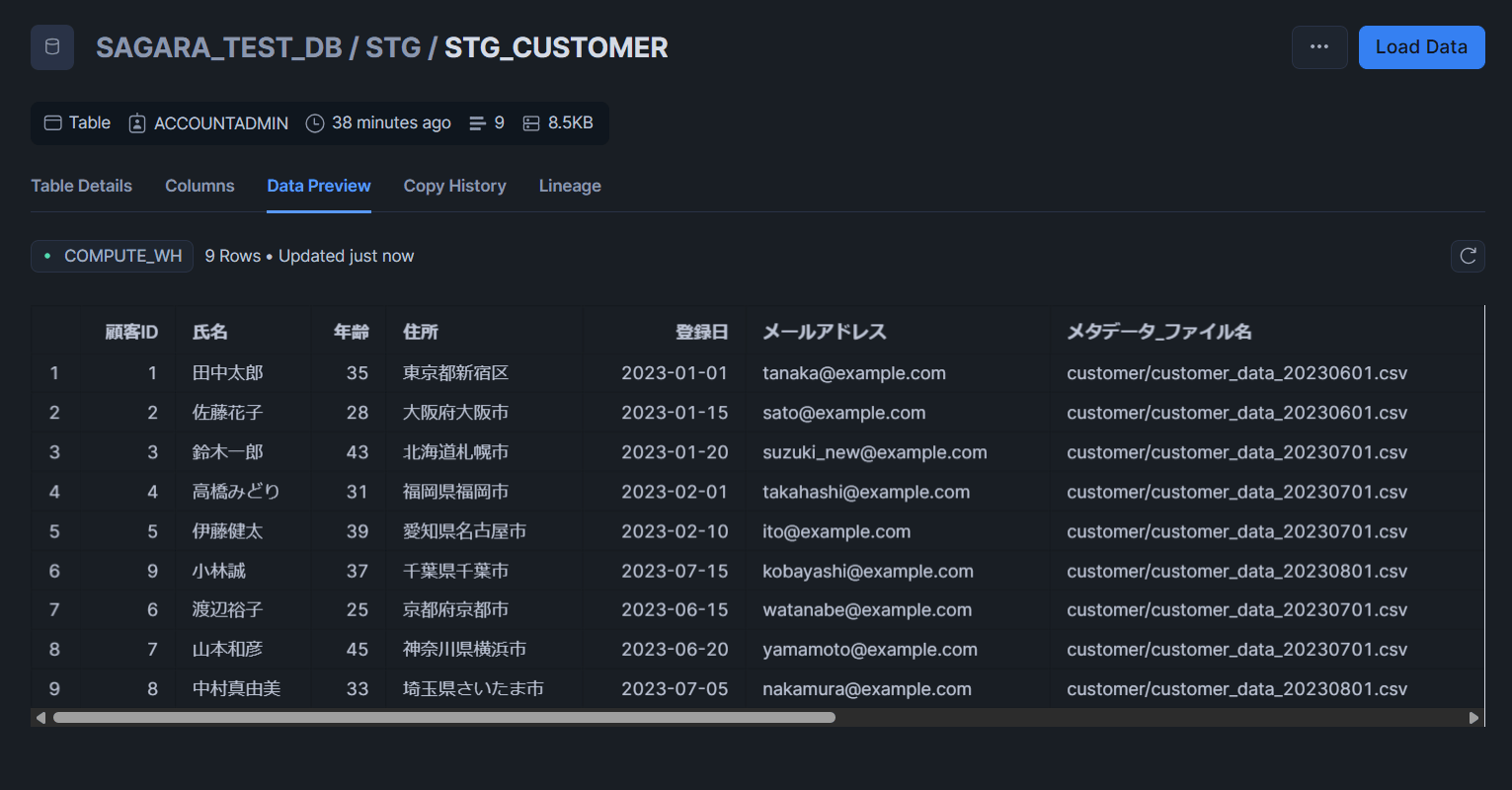
STG_CUSTOMERテーブル
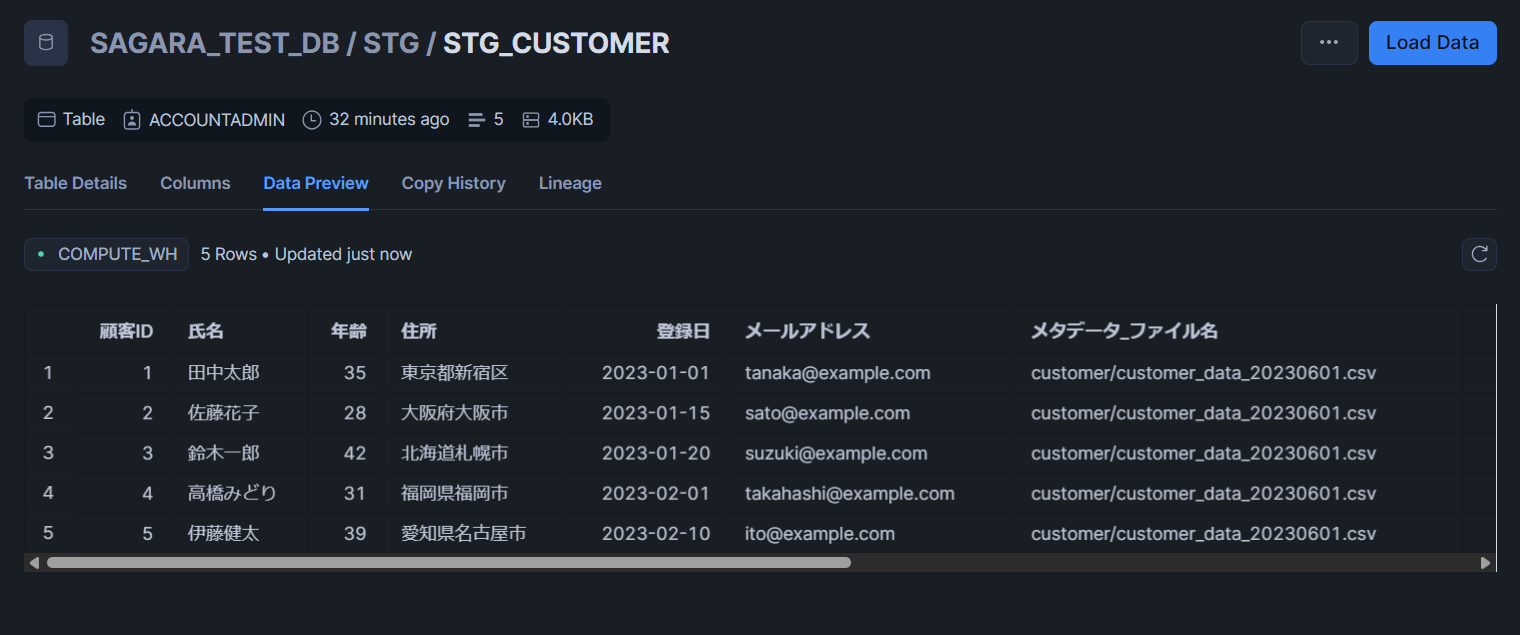
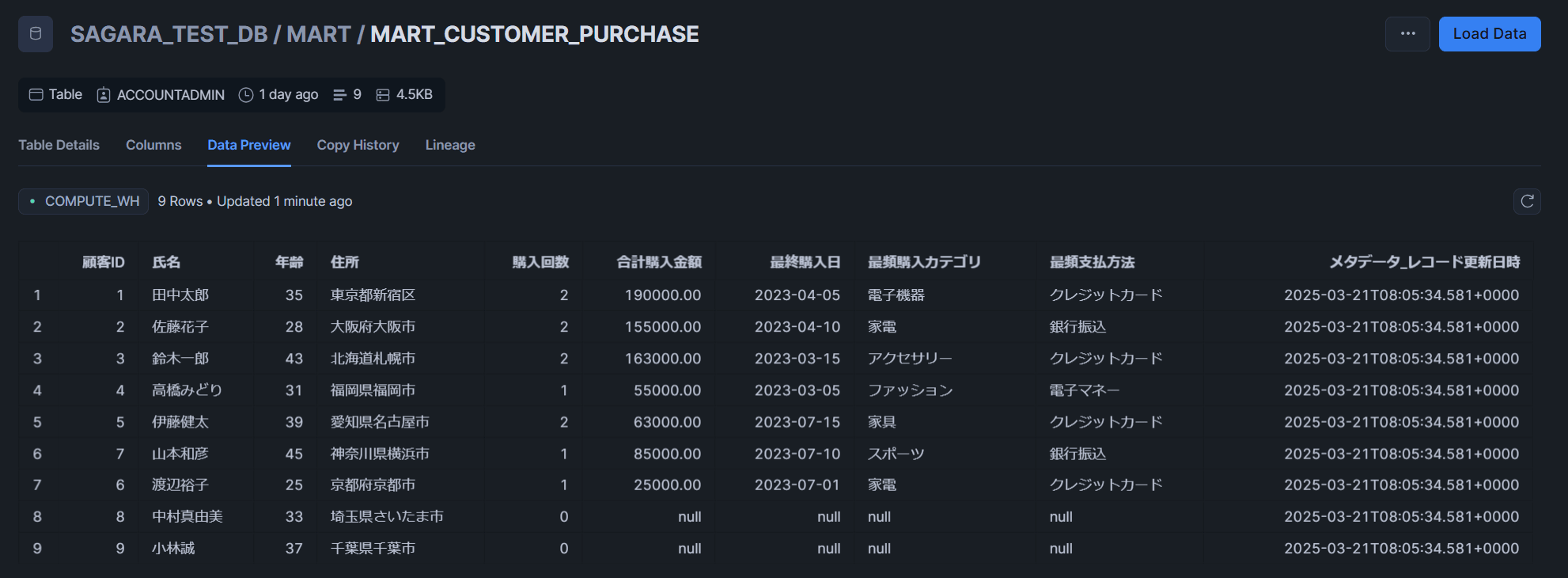
MART_CUSTOMER_PURCHASEテーブル
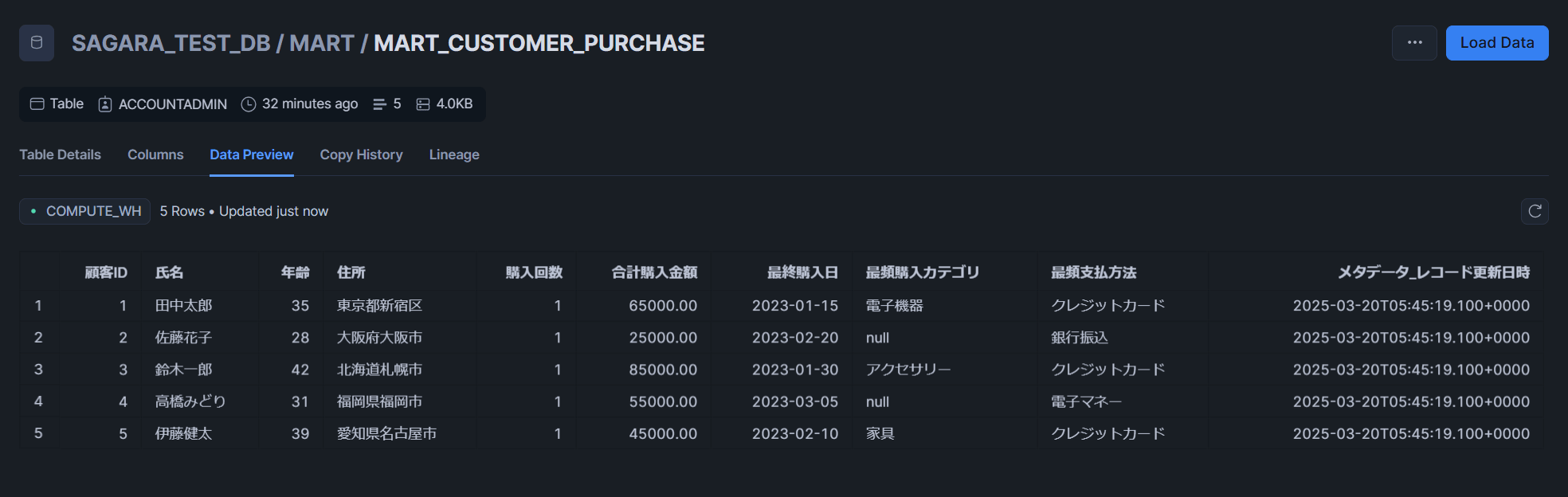
MART_PRODUCT_SALESテーブル
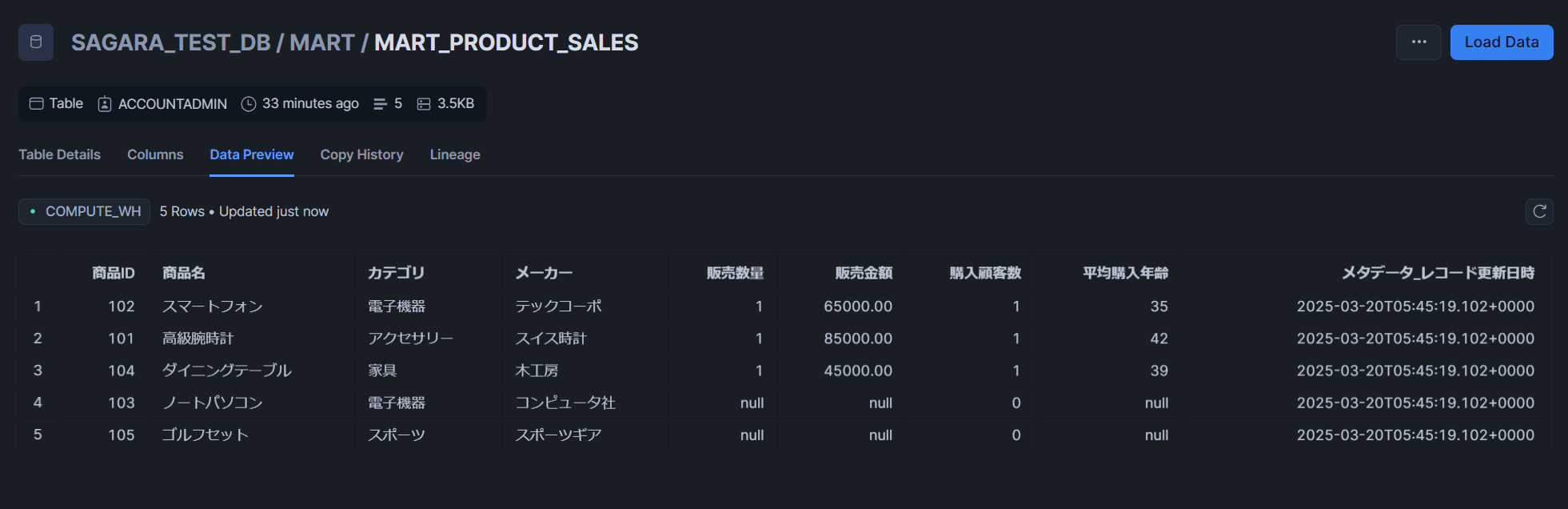
MART_SALES_SUMMARYテーブル
CSVファイルを2つずつ格納しパイプラインの動作確認
投入するデータ
まずは作成した内部ステージに対して、CSVファイルを各テーブルごとに2つずつ格納します。
これらのCSVファイルでは、以下のように各IDごとにデータのアップデートが行われています。
-
customerデータの重複と変更点
- 顧客ID 3: 年齢が42から43に更新され、メールアドレスも変更
- 顧客ID 5: 年齢が39から40に更新され、住所が詳細化され、メールアドレスも変更
- 顧客ID 4, 6, 7: 複数のファイルに同じデータが存在
-
productデータの重複と変更点
- 商品ID 103: 単価が120,000円から125,000円に値上げされ、在庫数が減少
- 商品ID 105: 商品名が「ゴルフセット」から「ゴルフセット プロモデル」に変更され、単価も上昇
- 商品ID 104, 106, 107: 在庫数のみ変更
-
purchaseデータの重複と変更点
- 購入明細ID 1004, 1005: 同じデータが複数ファイルに存在
- 購入明細ID 1006: 配送状況が「準備中」から「配送済み」に更新
- 購入明細ID 1008: 数量が1から2に変更され、購入金額も倍増
-
customer_data_20230701.csv(raw_customerへロード)
顧客ID,氏名,年齢,住所,登録日,メールアドレス
3,鈴木一郎,43,北海道札幌市,2023-01-20,suzuki_new@example.com
4,高橋みどり,31,福岡県福岡市,2023-02-01,takahashi@example.com
5,伊藤健太,39,愛知県名古屋市,2023-02-10,ito@example.com
6,渡辺裕子,25,京都府京都市,2023-06-15,watanabe@example.com
7,山本和彦,45,神奈川県横浜市,2023-06-20,yamamoto@example.com
- customer_data_20230801.csv(raw_customerへロード)
顧客ID,氏名,年齢,住所,登録日,メールアドレス
5,伊藤健太,40,愛知県名古屋市東区,2023-02-10,ito_updated@example.com
6,渡辺裕子,25,京都府京都市,2023-06-15,watanabe@example.com
7,山本和彦,45,神奈川県横浜市,2023-06-20,yamamoto@example.com
8,中村真由美,33,埼玉県さいたま市,2023-07-05,nakamura@example.com
9,小林誠,37,千葉県千葉市,2023-07-15,kobayashi@example.com
- product_data_20230701.csv(raw_productへロード)
商品ID,商品名,カテゴリ,単価,在庫数,メーカー
103,ノートパソコン,電子機器,125000.00,5,コンピュータ社
104,ダイニングテーブル,家具,45000.00,3,木工房
105,ゴルフセット,スポーツ,78000.00,15,スポーツギア
106,高級バッグ,ファッション,55000.00,20,ラグジュアリーブランド
107,電子レンジ,家電,25000.00,40,家電メーカー
- product_data_20230801.csv(raw_productへロード)
商品ID,商品名,カテゴリ,単価,在庫数,メーカー
105,ゴルフセット プロモデル,スポーツ,85000.00,10,スポーツギア
106,高級バッグ,ファッション,55000.00,15,ラグジュアリーブランド
107,電子レンジ,家電,25000.00,35,家電メーカー
108,コーヒーメーカー,家電,18000.00,25,キッチン工房
109,ヨガマット,スポーツ,5000.00,50,フィットネス社
- purchase_data_20230701.csv(raw_purchaseへロード)
購入明細ID,顧客ID,商品ID,購入日,数量,購入金額,支払方法,配送状況
1004,4,106,2023-03-05,1,55000.00,電子マネー,配送済み
1005,5,104,2023-02-10,1,45000.00,クレジットカード,配送済み
1006,1,103,2023-04-05,1,125000.00,ローン,準備中
1007,3,105,2023-03-15,1,78000.00,クレジットカード,配送済み
1008,2,102,2023-04-10,1,65000.00,クレジットカード,配送中
- purchase_data_20230801.csv(raw_purchaseへロード)
購入明細ID,顧客ID,商品ID,購入日,数量,購入金額,支払方法,配送状況
1006,1,103,2023-04-05,1,125000.00,ローン,配送済み
1008,2,102,2023-04-10,2,130000.00,クレジットカード,配送済み
1009,6,107,2023-07-01,1,25000.00,クレジットカード,配送済み
1010,7,105,2023-07-10,1,85000.00,銀行振込,配送中
1011,5,108,2023-07-15,1,18000.00,電子マネー,配送済み
※下図は内部ステージへのアップロードの際の一例です。
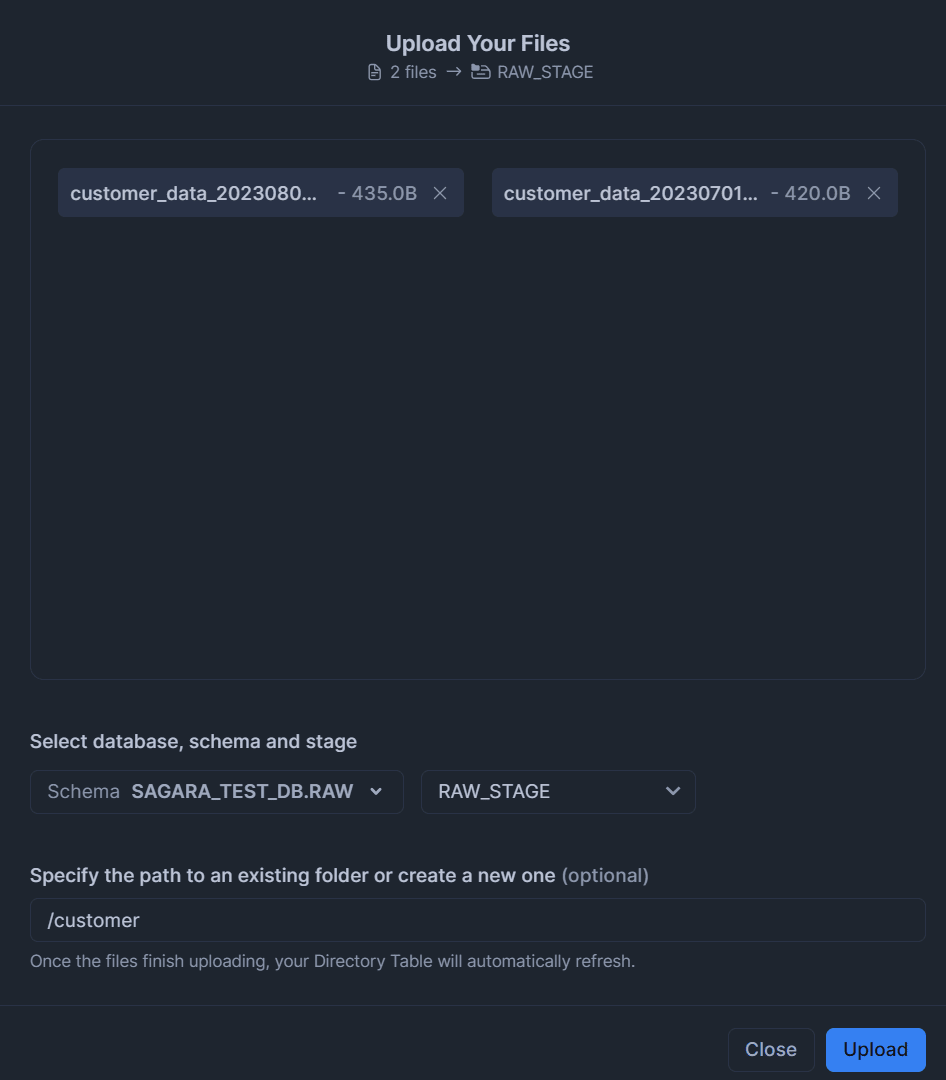
タスク実行とデータの確認
実際に以下のクエリでタスクを手動実行してデータを確認してみます。
-- ルートタスクの手動実行
execute task sagara_task_db.task_schema.root_task;
以下、RAWとSTGレイヤーでテーブルを1つ、MARTレイヤーでは3つ全て、テーブルの中身を確認してみます。(3/22追記:一部のタスクの定義を修正して再実行したため、メタデータレコード更新日時が各テーブルでズレていますがご了承ください。)
RAW_CUSTOMERテーブル
STG_CUSTOMERテーブル顧客IDごとに最新のデータだけが登録されていることがわかります。
MART_CUSTOMER_PURCHASEテーブル
MART_PRODUCT_SALESテーブル
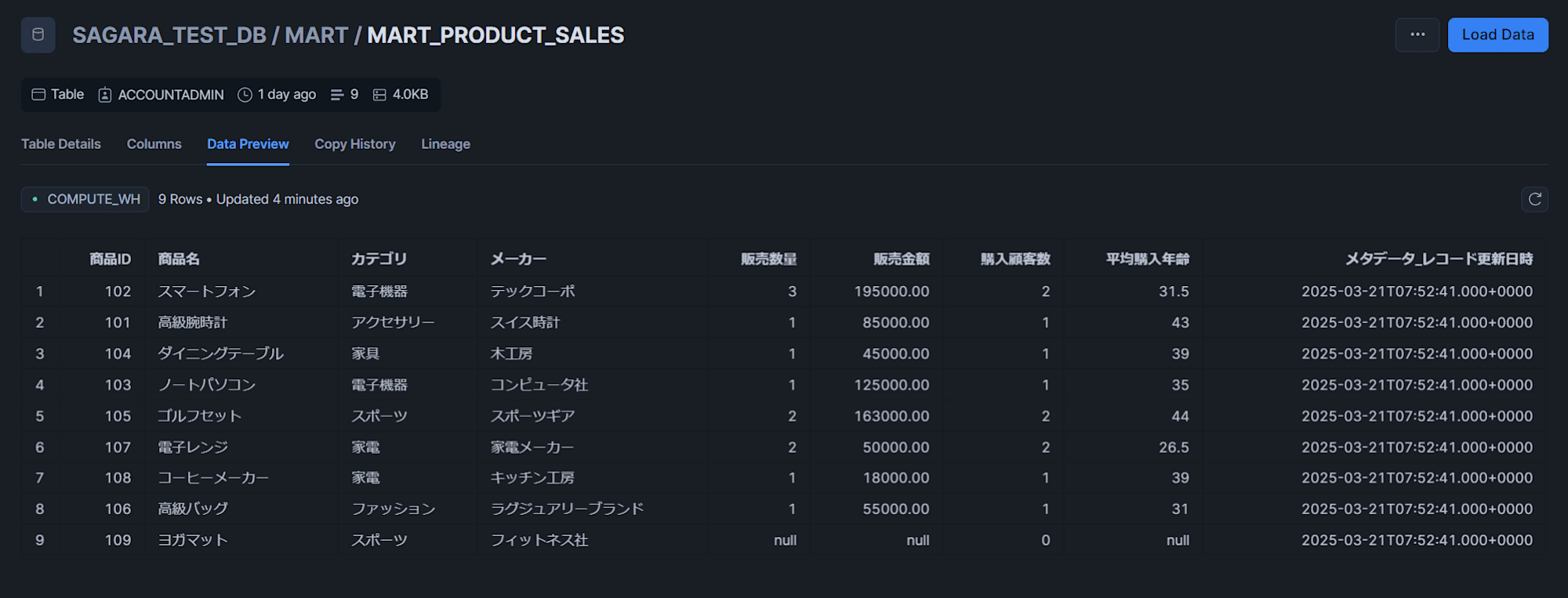
MART_SALES_SUMMARYテーブル
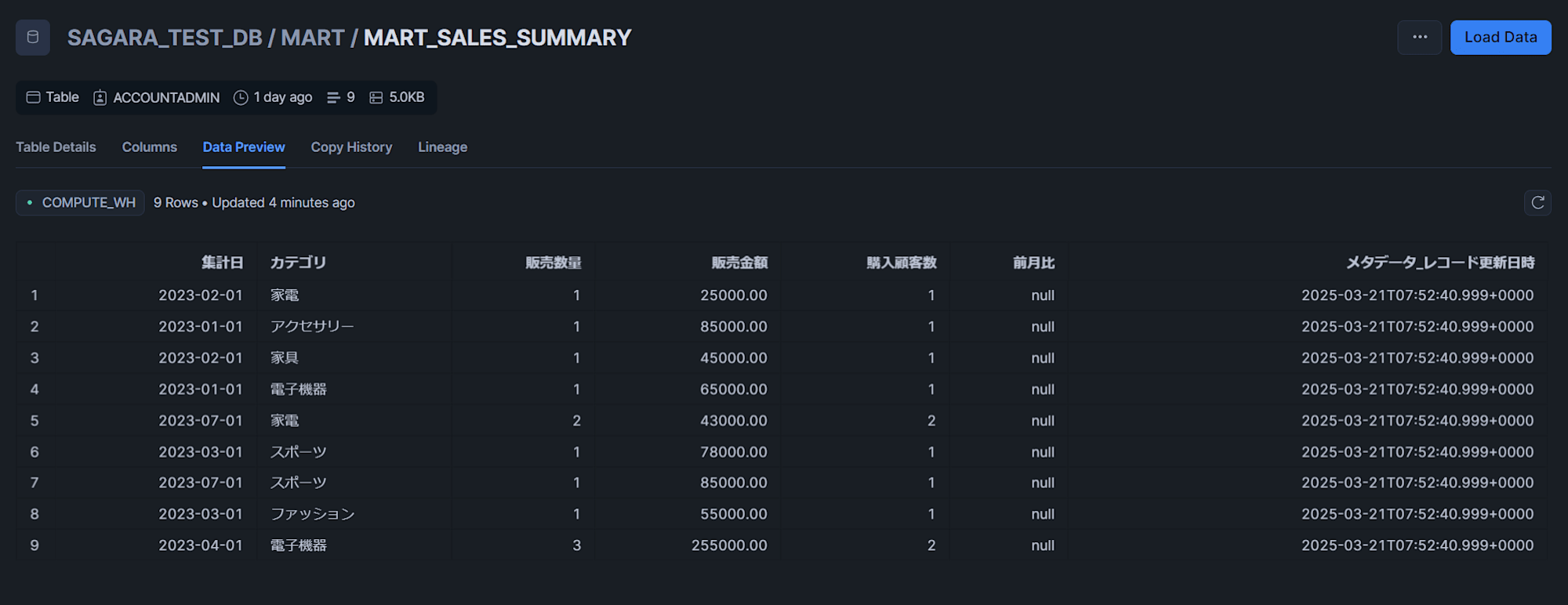
最後に
Snowflakeのタスクだけで重複削除・差分更新を行うデータパイプラインを構築してみたので、その内容をまとめてみました。
タスクを使う際の注意点含め、どのようにルートタスクや中間タスクなどを設定すればよいのかなど実運用上で使えそうなポイントも入れてみたので、参考になると嬉しいです!









