[新機能]モデルの実行情報を収集し比較できる「Snowflake ML Experiments」がパブリックプレビューとなったので試してみた
かわばたです。
2025年11月4日にSnowflake ML Experimentsがプレビュー版として利用可能になりました。
今回はSnowflake ML Experimentsを実際に試していきます。
【公式ドキュメント】
対象読者
- Snowflake ML Experimentsについて確認したい方
検証環境
- SnowflakeトライアルアカウントEnterprise版
使用するデータ
Titanic - Machine Learning from Disasterのデータを活用しています。
概要
Snowflake ML Experimentsは機械学習モデルのトレーニングプロセスを追跡・管理・評価するための機能となります。
この機能を使用することで、「どのパラメータ設定で、どのような精度のモデルができたか」 を記録し、SnowflakeのUI上で簡単に比較・分析できるようになります。いわゆるMLflowのような実験管理機能をSnowflake環境内で利用できるものです。
実際に試してみた。
事前準備
Snowflake ML Experimentsを保存するデータベース・スキーマ等を作成しました。
-- 自分のデータベース・スキーマを作成
CREATE DATABASE IF NOT EXISTS SNOWFLAKE_ML;
CREATE SCHEMA IF NOT EXISTS SNOWFLAKE_ML.EXPERIMENTS;
CREATE SCHEMA IF NOT EXISTS SNOWFLAKE_ML.titanic;
-- タイタニックのデータを格納する内部ステージを作成
CREATE STAGE titanic_stage
DIRECTORY = ( ENABLE = true )
ENCRYPTION = ( TYPE = 'SNOWFLAKE_SSE' );
作成したステージにTitanic - Machine Learning from Disasterのデータをアップロードします。
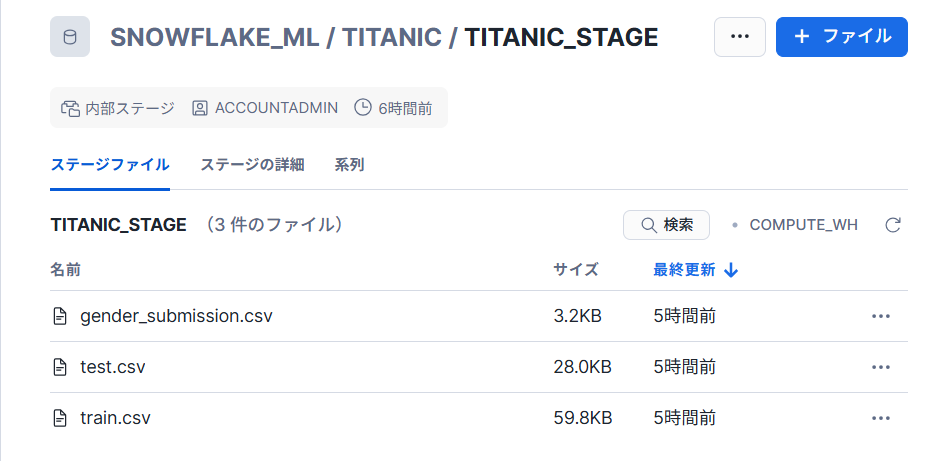
Snowflake ML Experimentsの作成
AI&ML→Experimentsを選択します。
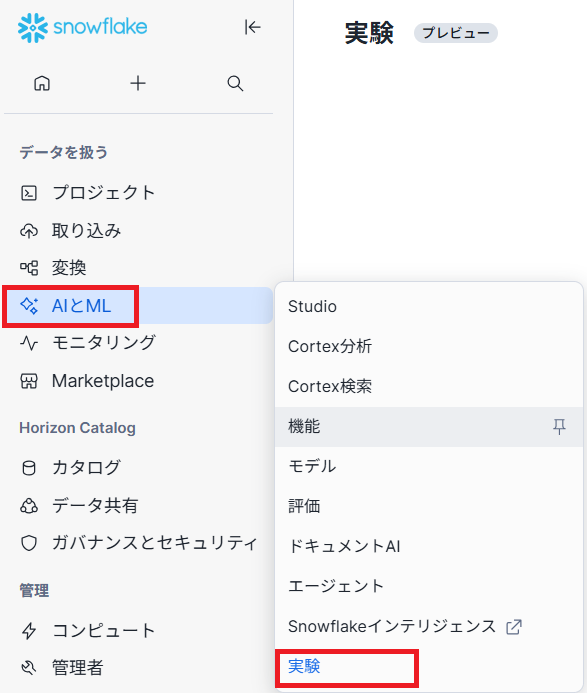
下記画面でCreate experimentを押下します。
Experimentsの名称と、保存先のデータベース・スキーマを指定します。

下記のように作成されました。
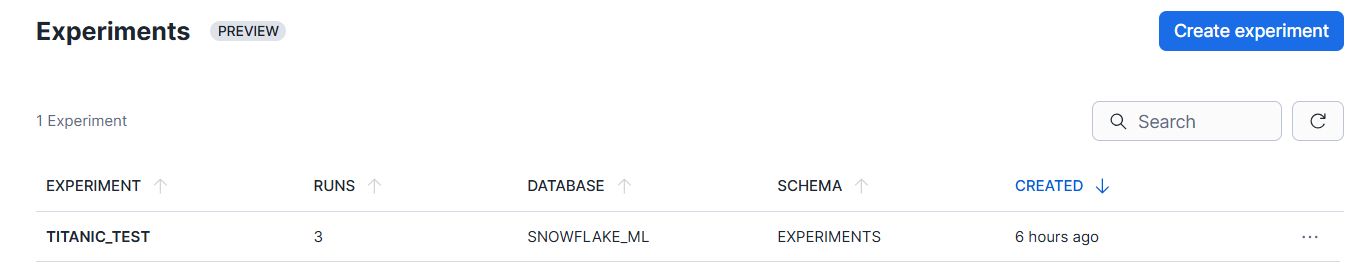
Notebooksでモデルの作成
下記に必要な設定を記載し、Notebooksを作成しました。

ステージから、データを読み込みを下記のように処理しました。
import pandas as pd
from snowflake.snowpark.files import SnowflakeFile
from snowflake.snowpark import Session
# 1. train.csv の読み込み
# SnowflakeFile.open() を使ってファイルストリームを開き、pandasに渡します
with SnowflakeFile.open("@titanic_stage/train.csv") as f:
train_df = pd.read_csv(f)
# 2. test.csv の読み込み
with SnowflakeFile.open("@titanic_stage/test.csv") as f:
test_df = pd.read_csv(f)
# 確認
print("Train shape:", train_df.shape)
print("Test shape:", test_df.shape)
print(train_df.head(3))
実際にモデルを作成しながら、Experimentsの設定も行います。
今回はlightgbmでモデルを作成しました。
トレーニング情報を自動的に記録する方法
XGBoost、LightGBM、またはKerasモデルのトレーニング情報を、モデルのトレーニング中に自動ログに記録でき、その方法を試しました。
## 必要なライブラリのインポート
import pandas as pd
from lightgbm import LGBMClassifier
from snowflake.snowpark import Session
from snowflake.ml.experiment import ExperimentTracking
from snowflake.ml.experiment.callback.lightgbm import SnowflakeLightgbmCallback
from snowflake.ml.model.model_signature import infer_signature
from sklearn.model_selection import train_test_split
# 1. セッションの取得 (Notebook環境)
session = get_active_session()
# 2. データ準備
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_df[features])
y = train_df["Survived"]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=1)
# 3. ExperimentTracking のインスタンス化
# ここで指定したいデータベースを選ぶ
session.use_database("SNOWFLAKE_ML")
# ここで指定したいスキーマを選ぶ
session.use_schema("EXPERIMENTS")
exp = ExperimentTracking(session=session)
# experimentの指定
exp.set_experiment("TITANIC_TEST")
# 4. モデル署名 (Signature) の作成
sig = infer_signature(X_train, y_train)
# 5. コールバックの設定
# 第1引数に `exp` (ExperimentTrackingインスタンス) を渡します
callback = SnowflakeLightgbmCallback(
exp,
model_name="titanic_lgbm_auto_v2",
model_signature=sig
)
# 6. モデル定義
model = LGBMClassifier(
n_estimators=100,
learning_rate=0.05,
random_state=42,
verbose=-1
)
# 7. 学習と自動記録の実行 exp.start_run() を使ってコンテキストを開始します
print("Starting training with ExperimentTracking...")
with exp.start_run("callback_run_v2"):
model.fit(
X_train, y_train,
eval_set=[(X_val, y_val)],
eval_metric="binary_logloss",
callbacks=[callback] # ここで自動記録
)
print("Training finished. Check Experiments UI.")
Experimentsで確認すると、下記のようにパラメータを保存してくれています。
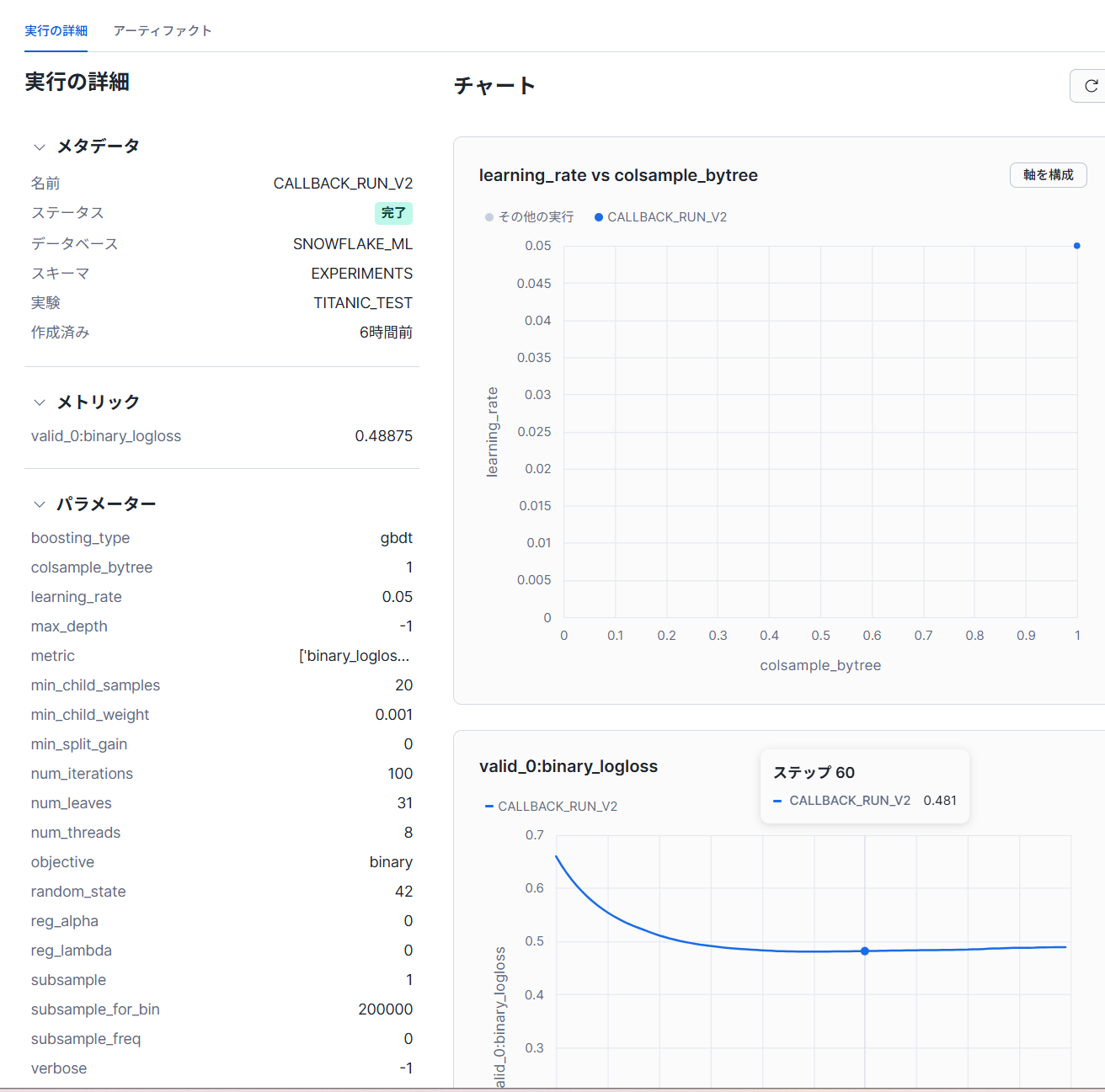
特徴量を増やしもう一度作成
import pandas as pd
from lightgbm import LGBMClassifier
from snowflake.snowpark import Session
from snowflake.ml.experiment import ExperimentTracking #★ここが重要
from snowflake.ml.experiment.callback.lightgbm import SnowflakeLightgbmCallback
from snowflake.ml.model.model_signature import infer_signature
from sklearn.model_selection import train_test_split
# --- パターン2: 特徴量(Age, Fare)を追加して再実験 ---
# 1. データの作り直し (AgeとFareを追加)
features_v2 = ["Pclass", "Sex", "SibSp", "Parch", "Age", "Fare"]
X_v2 = pd.get_dummies(train_df[features_v2]) # カテゴリ変数の処理
y_v2 = train_df["Survived"]
# データの分割 (乱数シードは同じにして公平に比較)
X_train_v2, X_val_v2, y_train_v2, y_val_v2 = train_test_split(X_v2, y_v2, test_size=0.2, random_state=1)
# ExperimentTracking のインスタンス化
session.use_database("SNOWFLAKE_ML")
# ここで指定したいスキーマを選ぶ
session.use_schema("EXPERIMENTS")
exp = ExperimentTracking(session=session)
exp.set_experiment("TITANIC_TEST")
# 2. 新しいデータに合わせてSignatureを更新
sig_v2 = infer_signature(X_train_v2, y_train_v2)
# 3. コールバックも新しく作り直す (Signatureが変わるため)
callback_v2 = SnowflakeLightgbmCallback(
exp,
model_name="titanic_lgbm_more_features",
model_signature=sig_v2
)
# 4. モデル定義 (パラメータは標準に戻して比較)
model_features = LGBMClassifier(
n_estimators=100,
learning_rate=0.05,
random_state=42,
verbose=-1
)
# 5. 実験の実行
run_name_features = "LGBM_More_Features"
print(f"Starting run: {run_name_features}...")
with exp.start_run(run_name=run_name_features):
model_features.fit(
X_train_v2, y_train_v2,
eval_set=[(X_val_v2, y_val_v2)],
eval_metric="binary_logloss",
callbacks=[callback_v2]
)
print("Feature-rich run finished.")
Experimentsで確認すると、下記のようにパラメータを保存されました。
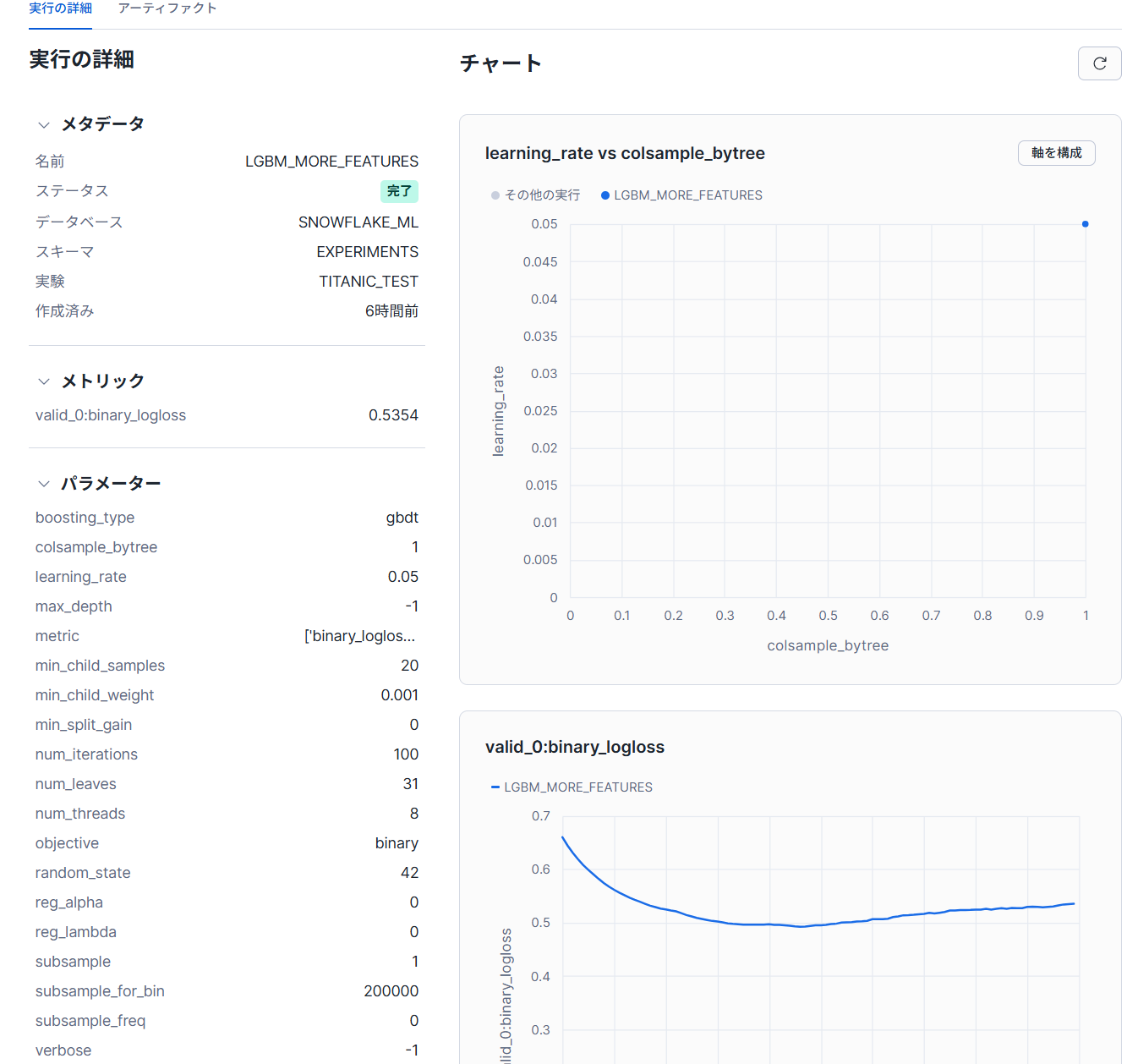
モデル同士の比較
Experimentsの画面で任意のモデルにチェックを入れてから、比較をすることができます。
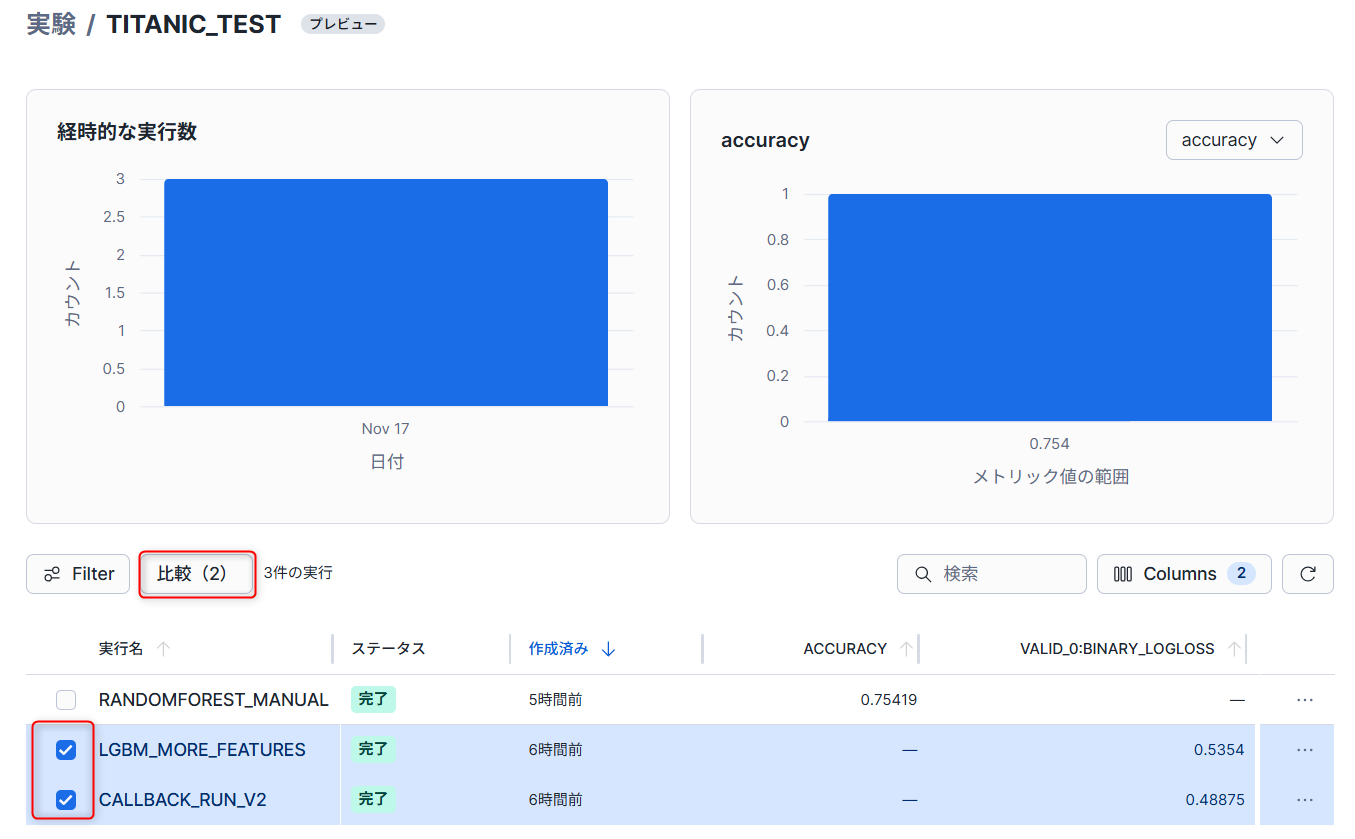
下記のような形で特定の指標を比較することが可能です。
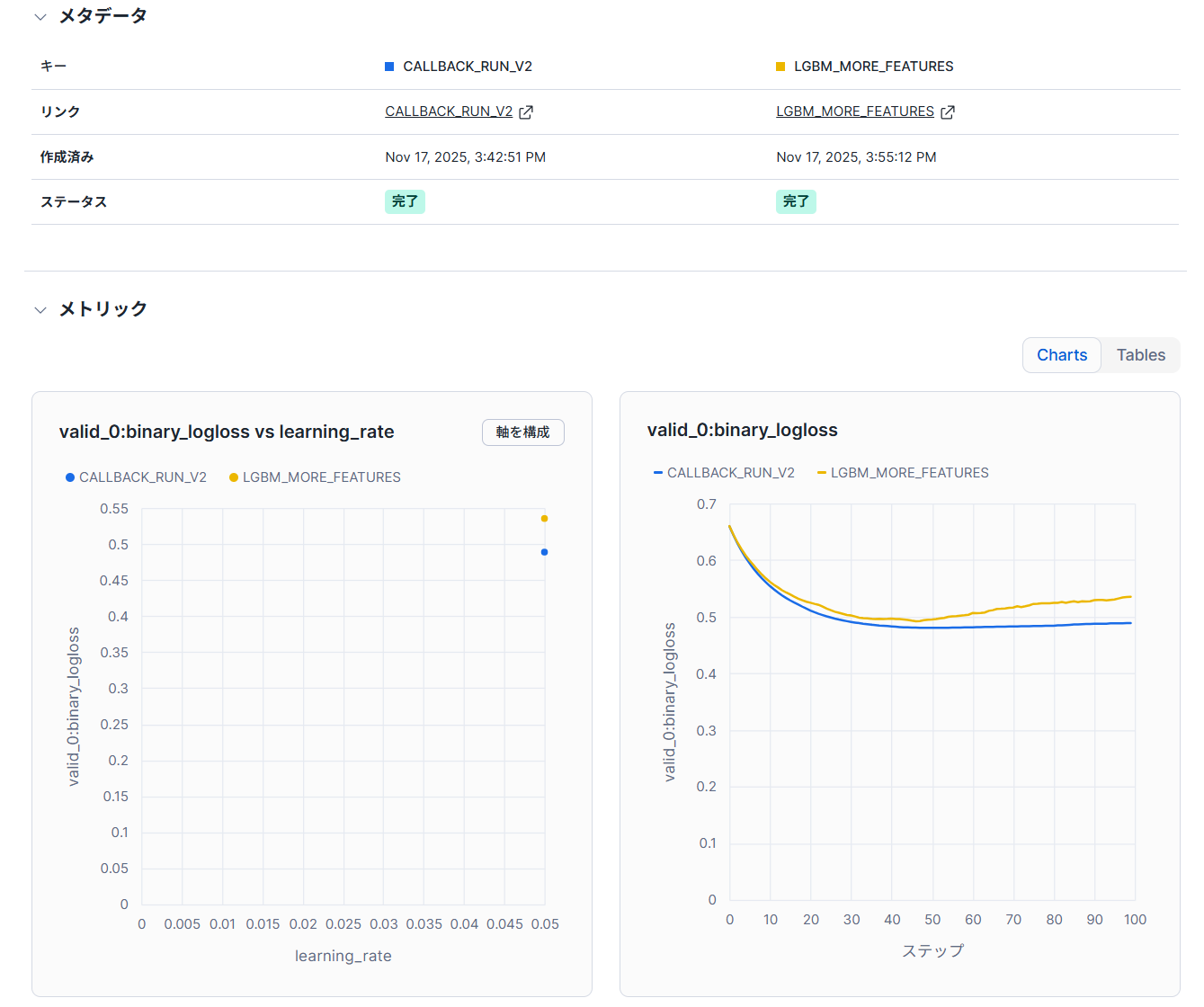
トレーニング情報と成果物を手動で記録する方法
今回はランダムフォレストの手法でモデルを作成しています。
下記のようにモデルを作成しました。
import pandas as pd
from snowflake.ml.experiment import ExperimentTracking
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# データ準備
features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_df[features])
y = train_df["Survived"]
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=1)
# 1. ExperimentTrackingの準備
session = get_active_session()
# ExperimentTracking のインスタンス化
session.use_database("SNOWFLAKE_ML")
# ここで指定したいスキーマを選ぶ
session.use_schema("EXPERIMENTS")
exp = ExperimentTracking(session=session)
exp.set_experiment("TITANIC_TEST")
run_name_2 = "RandomForest_Manual"
# 2. 実験の開始
with exp.start_run(run_name=run_name_2):
print(f"Starting run: {run_name_2}")
# --- モデルの設定 ---
n_estimators = 100
model = RandomForestClassifier(n_estimators=n_estimators, random_state=42)
# --- 学習 ---
model.fit(X_train, y_train)
# --- 予測と評価 ---
preds = model.predict(X_val)
acc = accuracy_score(y_val, preds)
# パラメータの記録 (exp.log_param)
exp.log_param("model_type", "RandomForest")
exp.log_param("n_estimators", n_estimators)
# メトリクスの記録 (exp.log_metric)
exp.log_metric("accuracy", acc)
# タグの記録
exp.log_params({"description": "Challenger model using exp methods"})
Experimentsで確認すると、下記のようにパラメータを保存されました。
手動で設定したもののみパラメータとして保存されています。

snowflake.ml.experimentについて
上記のように手動で記録する際も自動で記録する際も、snowflake.ml.experimentライブラリを使用して設定しています。
簡単に下記にまとめましたが、詳細はドキュメントを確認ください。
| メソッド名 | 引数 | 説明 |
|---|---|---|
| session | database_name,schema_name | Snowflake に接続するためのSnowparkセッション。 |
| set_experiment | experiment_name | コンテキストにexperimentを設定します。存在しない場合は新規作成されます。 |
| start_run | run_name(省略可) | 新しいRunを開始します。既存の実行名を指定すると再開します。 |
| end_run | run_name(省略可) | 現在の実行、または指定された実行を終了します。 |
| delete_experiment | experiment_name | 指定されたexperimentを削除します。 |
| delete_run | run_name | 指定されたRunを削除します。 |
| log_metric | key,value,step | 現在の実行に単一のメトリックを記録します。 |
| log_param | key,value | 現在の実行に単一のパラメータを記録します。 |
| log_params | params | 現在の実行に複数のパラメータ (辞書形式) を記録します。 |
| log_artifact | local_path,artifact_path | ローカルファイルまたはディレクトリをアーティファクトとして記録します。 |
| list_artifacts | run_name,artifact_path | 指定された実行に関連するアーティファクトを一覧表示します。 |
| download_artifacts | run_name,artifact_path,target_path | アーティファクトをローカルディレクトリにダウンロードします。 |
| log_model | model,model_name,version_name,metrics,conda_dependencies | モデル、バージョン、メタデータを記録します。Snowpark MLやsklearnなど多数のモデルに対応しています。 |
【公式ドキュメント】
最後に
この機能でSnowflakeのML周りがより、Snowflakeだけで完結することに近づいたのではないかと感じています。
モデルのトレーニング履歴をExcelや手書きで管理する手間をなくし、Snowflake上で体系的にバージョン管理・性能比較を行い、最適なモデルを効率的に選定することができるのではないかと考えています。
MLflowとの比較も行っていきたいです。
この記事が何かの参考になれば幸いです!







