[新機能]Row timestampsが一般提供となったのでdbtのincremental modelと合わせて試してみた
かわばたです。
2026年2月18日にRow timestampsが一般提供となりました。
「このレコードはいつ更新されたのか?」「前回の処理以降に変更されたデータだけを効率的に取得したい」というニーズに応えるような機能と思いますので試していきます。
【公式ドキュメント】
Row timestamps
対象読者
- Row timestampsについて確認したい方
検証環境
- SnowflakeトライアルアカウントEnterprise版
概要
行のタイムスタンプは、テーブル内の各行が最後に更新された日時を正確に時系列で記録します。同じトランザクションで変更された行は同じタイムスタンプを共有し、異なるトランザクションで変更された行はコミットされた日時順に並べられます。
上記のとおり、Row timestampsは、テーブルの各行が 最後に挿入または更新された時刻 を自動的に追跡する機能です。
テーブルにROW_TIMESTAMP = TRUEを設定することで、Snowflakeが各行のコミット完了時刻を自動的に記録します。この時刻はMETADATA$ROW_LAST_COMMIT_TIMEという疑似列を通じて参照でき、行の挿入・更新時に自動更新されます。ユーザーがこの値を直接変更することはできません。
ユースケース※ドキュメントから引用
-
パイプラインの可観測性: ストリーミング取り込み、CDC、ETL ワークロードのエンドツーエンドのレイテンシとデータの鮮度を、クライアント側のタイムスタンプよりも高い精度で測定します。
-
信頼性の高い増分処理:確定的なコミット時間を使用して、イベント タイムスタンプがスキップする可能性のある遅延レコードまたはバックフィルされたレコードをキャプチャします。
-
決定的な監査証跡:規制コンプライアンスまたは SCD2 スタイルのマイルストーンのために、イベントの時系列順序を確立します。
事前準備
使用するデータ
今回はdbtのサンプルデータjaffle-shopを活用しています。
実際に試してみた
Row timestampsの設定
タイムスタンプの形式を下記のように設定しました。
-- タイムスタンプ表示形式の設定
ALTER SESSION SET TIMESTAMP_TZ_OUTPUT_FORMAT = 'YYYY-MM-DDTHH:MI:SS.FF3 TZH';
ALTER SESSION SET TIMEZONE = 'UTC';
個別テーブルにRow timestampsを設定していきます。
-- テスト用テーブルの作成(ROW_TIMESTAMP = TRUE)
CREATE OR REPLACE TABLE KAWABATA_MART_DB.DBT_TKAWABATA.ROW_TIMESTAMP_TEST (
id INT,
value STRING
) ROW_TIMESTAMP = TRUE;
-- データ挿入
INSERT INTO KAWABATA_MART_DB.DBT_TKAWABATA.ROW_TIMESTAMP_TEST VALUES (1, 'first');
INSERT INTO KAWABATA_MART_DB.DBT_TKAWABATA.ROW_TIMESTAMP_TEST VALUES (2, 'second');
-- METADATA$ROW_LAST_COMMIT_TIME を確認
SELECT
id,
value,
METADATA$ROW_LAST_COMMIT_TIME AS row_timestamp
FROM KAWABATA_MART_DB.DBT_TKAWABATA.ROW_TIMESTAMP_TEST
ORDER BY row_timestamp;
データをインサートした時間にRow timestampsが定義されていることが分かりました。

スキーマレベルでRow timestampsの設定
下記クエリでスキーマレベルのデフォルトの設定を確認することができます。(現状は設定なし)
SHOW PARAMETERS LIKE 'ROW_TIMESTAMP_DEFAULT' IN SCHEMA KAWABATA_MART_DB.DBT_TKAWABATA;

下記クエリでスキーマにデフォルト設定することで、新規テーブルに自動適用することができます。
ALTER SCHEMA KAWABATA_MART_DB.DBT_TKAWABATA SET ROW_TIMESTAMP_DEFAULT = TRUE;
既存のテーブルをコピーして新しいテーブルを作成し新しい行をinsertします。
-- 既存テーブルのコピーを作成してテスト
CREATE OR REPLACE TABLE KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_ROW_TS_TEST AS
SELECT * FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS LIMIT 100;
-- 新しい行を挿入
INSERT INTO KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_ROW_TS_TEST
SELECT * FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS LIMIT 5;
-- 追加した5行にタイムスタンプが付与
SELECT
ORDER_ID,
ORDER_DATE,
METADATA$ROW_LAST_COMMIT_TIME AS row_timestamp
FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_ROW_TS_TEST
ORDER BY row_timestamp NULLS FIRST;
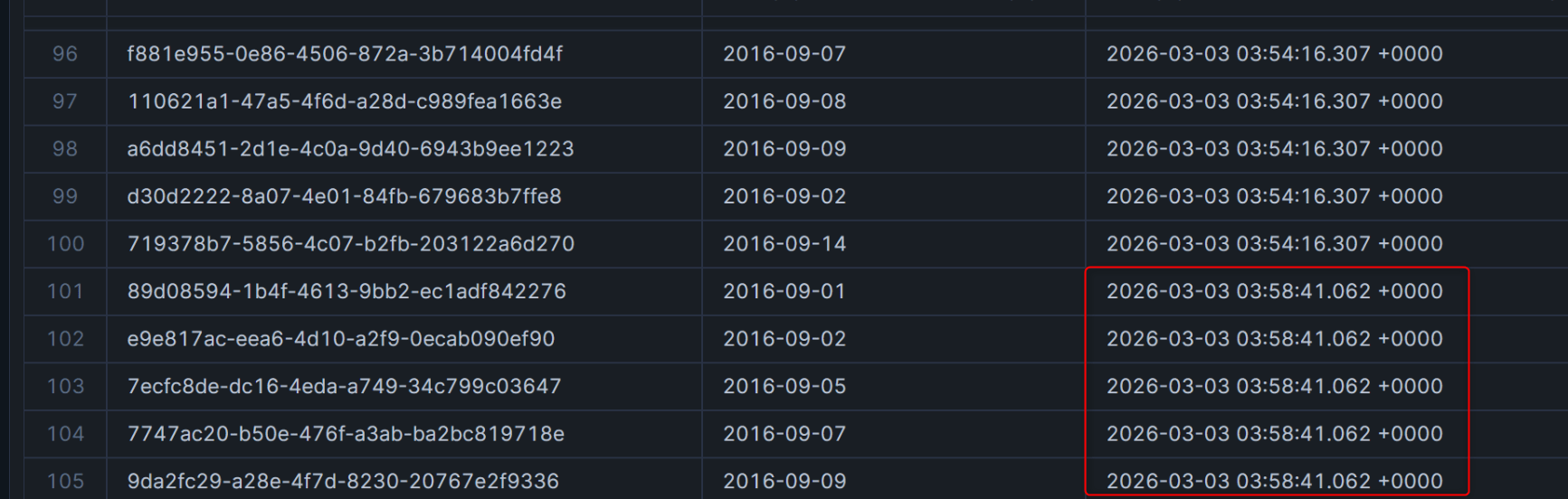
下記のとおり、追加した5行のみ異なるスタンプとなりました。
新規テーブルに自動適用のため、テーブルが作成された段階でタイムスタンプが記録されています。
dbtのincremental modelを試してみた
dbtのincremental modelはテーブル全体を毎回再構築せずに新規・変更行のみを処理してコストと処理時間を削減することを目的としています。
初回実行時にはモデルの全データを変換してテーブルを構築しますが、2回目以降の実行では前回実行以降に新しく追加または変更されたデータのみを処理し、既存のテーブルに追加・更新するのが基本的な動作です。
その際に、ロジックとして下記のように1回目の構築時と2回目の実行時のタイムスタンプを比較し、差分を更新する形です。
{% if is_incremental() %}
WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }})
{% endif %}
【参考ブログ】
dbt Projects on Snowflakeで確認してみた
先ほど作成したORDERS_ROW_TS_TESTテーブルを使用していきます。
ymlファイル
version: 2
sources:
- name: raw
database: KAWABATA_MART_DB
schema: DBT_TKAWABATA
tables:
- name: ORDERS_ROW_TS_TEST
description: "ROW_TIMESTAMP enabled orders table for incremental processing"
incremental modelファイル(orders_incremental.sql)
-- インクリメンタルモデル: Row Timestampを活用した増分処理
-- 初回実行時はフルロード、2回目以降は新規・更新行のみを処理
{#
materialized='incremental': インクリメンタルモデルとして実行
unique_key='ORDER_ID': MERGEのキー(重複時は更新)
incremental_strategy='merge': MERGE文で既存行を更新、新規行を挿入
#}
{{
config(
materialized='incremental',
unique_key='ORDER_ID',
incremental_strategy='merge'
)
}}
SELECT
ORDER_ID,
LOCATION_ID,
CUSTOMER_ID,
SUBTOTAL,
TAX_PAID,
ORDER_TOTAL,
ORDER_DATE,
ORDER_COST,
COUNT_ORDER_ITEMS,
IS_FOOD_ORDER,
IS_DRINK_ORDER,
-- Snowflake Row Timestamp: 行がコミットされた時刻を自動取得
METADATA$ROW_LAST_COMMIT_TIME AS ROW_TIMESTAMP
FROM {{ source('raw', 'ORDERS_ROW_TS_TEST') }}
-- 2回目以降の実行時のみ適用されるフィルタ条件
{% if is_incremental() %}
WHERE METADATA$ROW_LAST_COMMIT_TIME > (
-- ターゲットテーブルの最新タイムスタンプより新しい行のみ取得
SELECT COALESCE(MAX(ROW_TIMESTAMP), '1900-01-01'::TIMESTAMP_LTZ)
FROM {{ this }}
)
{% endif %}
1回目の実行
dbt run --select orders_incremental
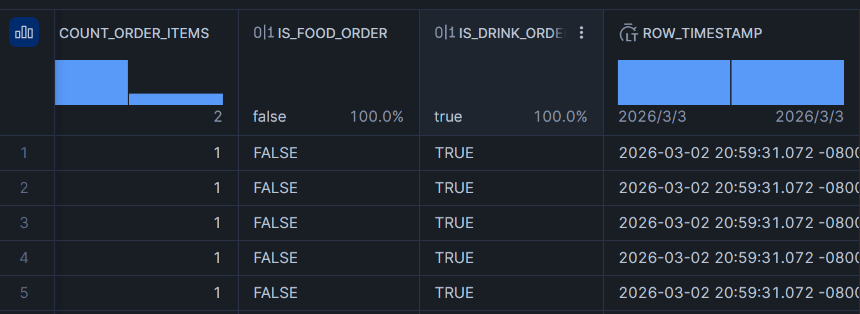
2回目の実行の前にsourcesデータに新しいレコードを追加します。
-- レコードの追加
INSERT INTO KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_ROW_TS_TEST
SELECT * FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS
WHERE ORDER_ID NOT IN (SELECT ORDER_ID FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_ROW_TS_TEST)
LIMIT 10
2回目の実行
dbt run --select orders_incremental
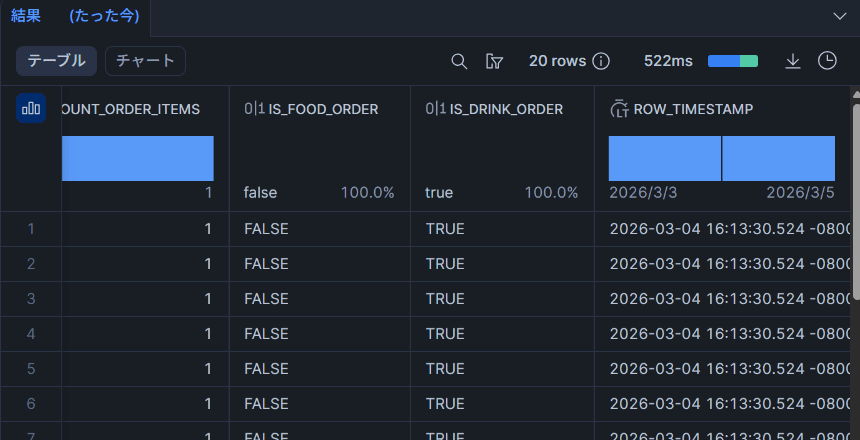
追加されていました。
Row timestampsの分布確認を確認して、差分だけ更新されているか確認します。
SELECT
DATE_TRUNC('minute', ROW_TIMESTAMP) AS commit_minute,
COUNT(*) AS row_count
FROM KAWABATA_MART_DB.DBT_TKAWABATA.ORDERS_INCREMENTAL
WHERE ROW_TIMESTAMP IS NOT NULL
GROUP BY 1
ORDER BY 1;
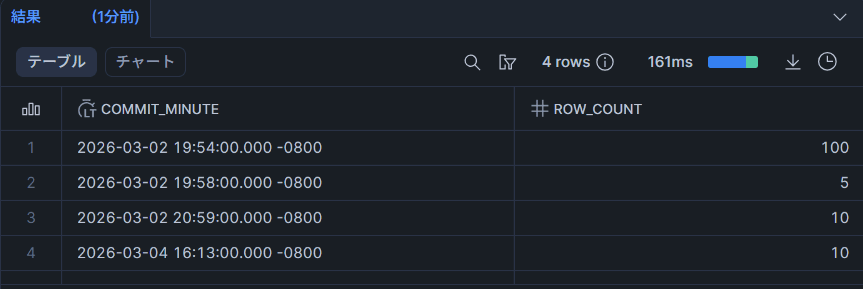
問題なく差分更新できていました。
最後に
こちらの機能かなり使えそうだなと感じました。dbtでいうとincremental modelもそうですが、Snapshotにも活用できます。また、デバックにも特定の時間帯のレコードのみを対象にアプローチできるので調査もしやすいのではと考えています。
この記事が何かの参考になれば幸いです!









