ストレージ統合を使って Snowflake on AWS から BigQuery にデータを転送してみた
データ事業本部のはんざわです。
企業が事業部単位でデータ基盤を運用している場合、部門ごとに異なるサービスを利用しているケースは少なくありません。あるチームでは BigQuery を使い、別のチームでは Snowflake、さらに別のチームでは Amazon Redshift を使っている、というような状況です。
このような環境では、「他部署のデータ基盤にあるテーブルを自分たちの環境でも参照したい」といった要望が発生することがあります。
実際に、先日も Snowflake 上のテーブルを BigQuery 側で利用したいというケースがありました。
ちょうどそのタイミングで、Google Cloud BigQuery のアップデートにより、BigQuery Data Transfer Service に Snowflake コネクタが追加され、プレビュー版として使えるようになっていました。
「早速これを試してみよう!」と思ったのですが、残念ながら増分転送には対応しておらず、転送のたびに全件がコピーされる仕様でした。
おそらく、Snowflake から BigQuery への完全移行を想定した機能だと思われます。
そこで今回は、Snowflakeの ストレージ統合 の仕組みを利用して、Snowflake から BigQuery へのデータ転送を試してみたいと思います。
ストレージ統合とは?
ストレージ統合(Storage Integration)とは、Snowflake が外部クラウドストレージ(例:Google Cloud Storage[以下、GCS]、Amazon S3、Azure Blob)に安全にアクセスするための認証設定です。
この仕組みにより、認証情報を直接管理することなく、外部ストレージからファイルを読み込んだり、書き出したりすることができます。
なお、Snowflake がどのクラウドプロバイダ(AWS, Google Cloud, Azure)上にホストされていても、ストレージ統合を使えば他クラウドのストレージにアクセスできます。
実際にストレージ統合を使ってみる
上記の公式ドキュメントを参考に、ストレージ統合(Storage Integration)を使って Snowflake から GCS へデータをアンロードし、最終的に BigQuery に取り込みます。
全体の大まかな手順は以下の通りです。
- Google Cloud 上に GCS バケットを作成
- Snowflake でストレージ統合を作成
- Google Cloud でカスタムロールを作成し、必要な権限を設定
- ストレージ統合に紐づくサービスアカウントに GCS バケットへのアクセス権限を付与
- ストレージ統合でを使って Snowflake のテーブルを GCS に書き出す
- 書き出したファイルを BigQuery に取り込む
1. Google Cloud で GCS バケットを作成
まずは GCS バケットを作成します。
今回の検証では、以下の構成でバケットを作成しました。
- バケット名:
cm-hanzawa-yuya-from-snowflake - リージョン:
- 単一リージョン
asia-northeast1 (東京)
- 削除(復元可能)ポリシー:無効化
- その他の設定:デフォルトのまま
2. Snowflake でストレージ統合を作成
次に、Snowflake 側で GCS にアクセスするためのストレージ統合を作成します。
ストレージ統合を作成すると、Snowflake で GCS にアクセスするためのサービスアカウントが自動的に生成されます。
このサービスアカウントに GCS バケットへのアクセス権限を付与することで、Snowflake から GCS へのアクセスが可能になります。
以下のクエリを Snowflake 上で実行して、ストレージ統合を作成します。
注意点として、ACCOUNTADMIN ロールを持つユーザー または CREATE INTEGRATION 権限を持つロール で実行する必要があります。
ここでは、gcs_int という名前でストレージ統合を作成しています。
STORAGE_PROVIDER に GCS を指定し、STORAGE_ALLOWED_LOCATIONS に手順 1 で作成した GCS バケットの URI を設定しています。
USE ROLE ACCOUNTADMIN;
CREATE STORAGE INTEGRATION gcs_int
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = GCS
ENABLED = TRUE
STORAGE_ALLOWED_LOCATIONS = ('gcs://cm-hanzawa-yuya-from-snowflake/');
3. Google Cloud でカスタムロールを作成し、必要な権限を設定
次に、Google Cloud 側でカスタムロールを作成します。
このロールは、後ほどストレージ統合に紐づくサービスアカウントに付与します。
まず、Google Cloud のコンソール画面から IAMと管理 -> ロール を選択します。
次のような画面が表示されたら、ロールを作成 を選択します。

ここから、カスタムロールの作成に進みます。
実行したいアクションによって必要な権限が異なるため、以下の表を参考に、目的に応じた権限を追加してください。
| アクション | 必要な権限 |
|---|---|
| データのロードのみ | ・storage.buckets.get・ storage.objects.get・ storage.objects.list |
| バージョンオプションありのデータのロード、ステージ上でREMOVEコマンドを実行 | ・storage.buckets.get・ storage.objects.delete・ storage.objects.get・ storage.objects.list |
| データのロードとアンロード | ・storage.buckets.get・ storage.objects.create・ storage.objects.delete・ storage.objects.get・ storage.objects.list |
| データのアンロードのみ | ・storage.buckets.get・ storage.objects.create・ storage.objects.delete・ storage.objects.list |
今回は、Snowflake から GCS にデータを書き込む(アンロードする)ケースのため、表の一番下の「データのアンロードのみ」に該当する権限を追加しています。
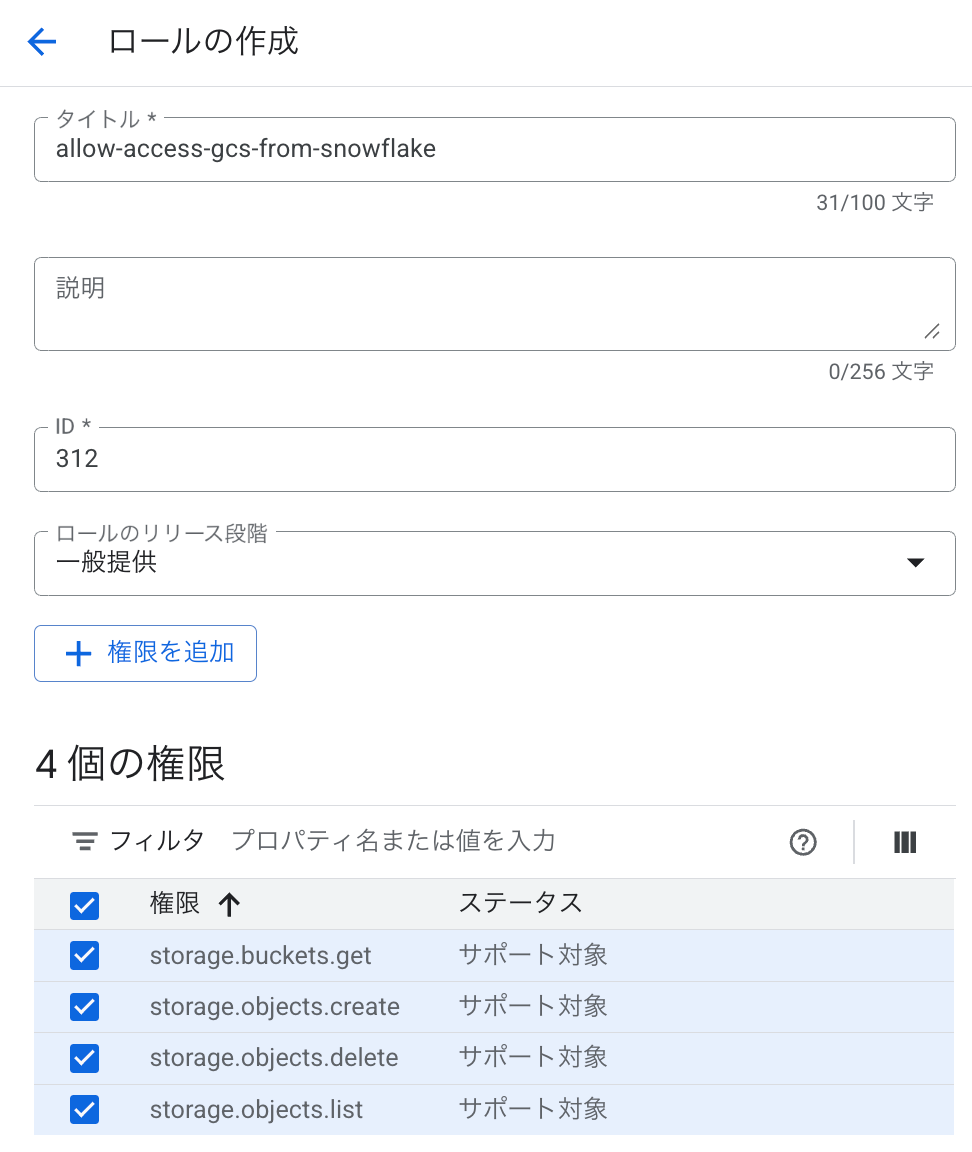
4. ストレージ統合に紐づくサービスアカウントに GCS バケットへのアクセス権限を付与
ストレージ統合に紐づくサービスアカウントに GCS バケットのアクセス権限を付与するには、まずそのサービスアカウントの名前を確認する必要があります。
以下のクエリを実行すると、STORAGE_GCP_SERVICE_ACCOUNT の項目でサービスアカウントの名前を確認できます。
DESC INTEGRATION gcs_int;
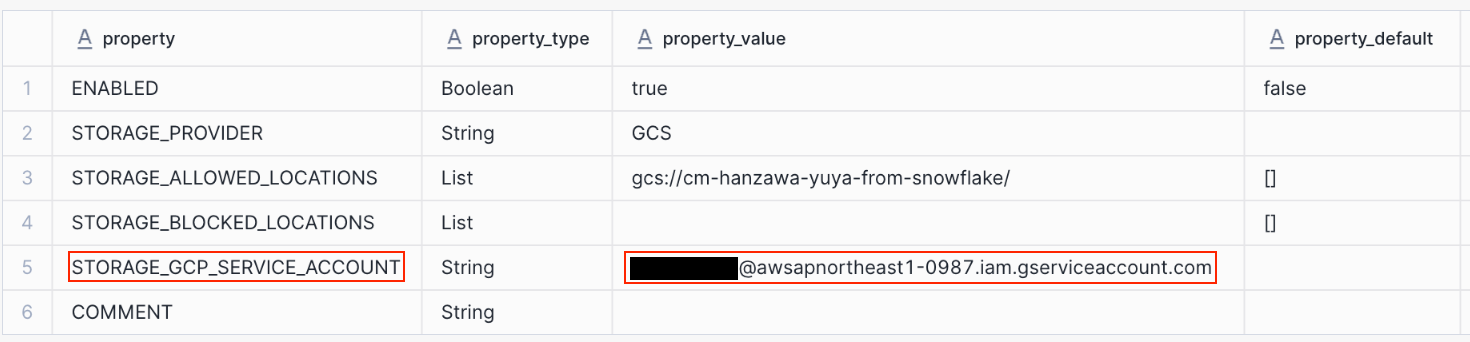
STORAGE_GCP_SERVICE_ACCOUNT の値を控えたら、Google Cloud の設定に戻ります。
Google Cloud のコンソールから Cloud Storage -> バケット に移動します。
バケットの一覧が表示されるので、ステップ 1 で作成したバケットを選択します。次に、画面上部の 権限 タブに移動し、アクセスを許可 をクリックします。
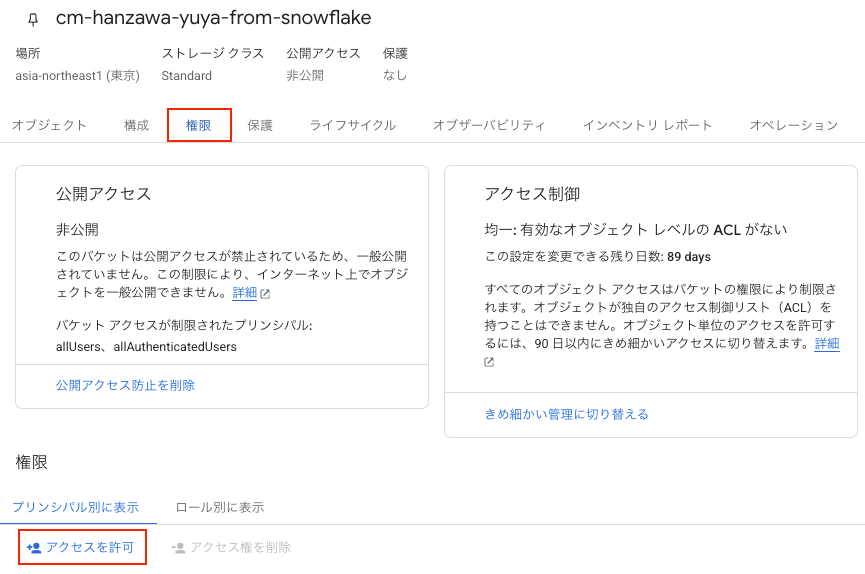
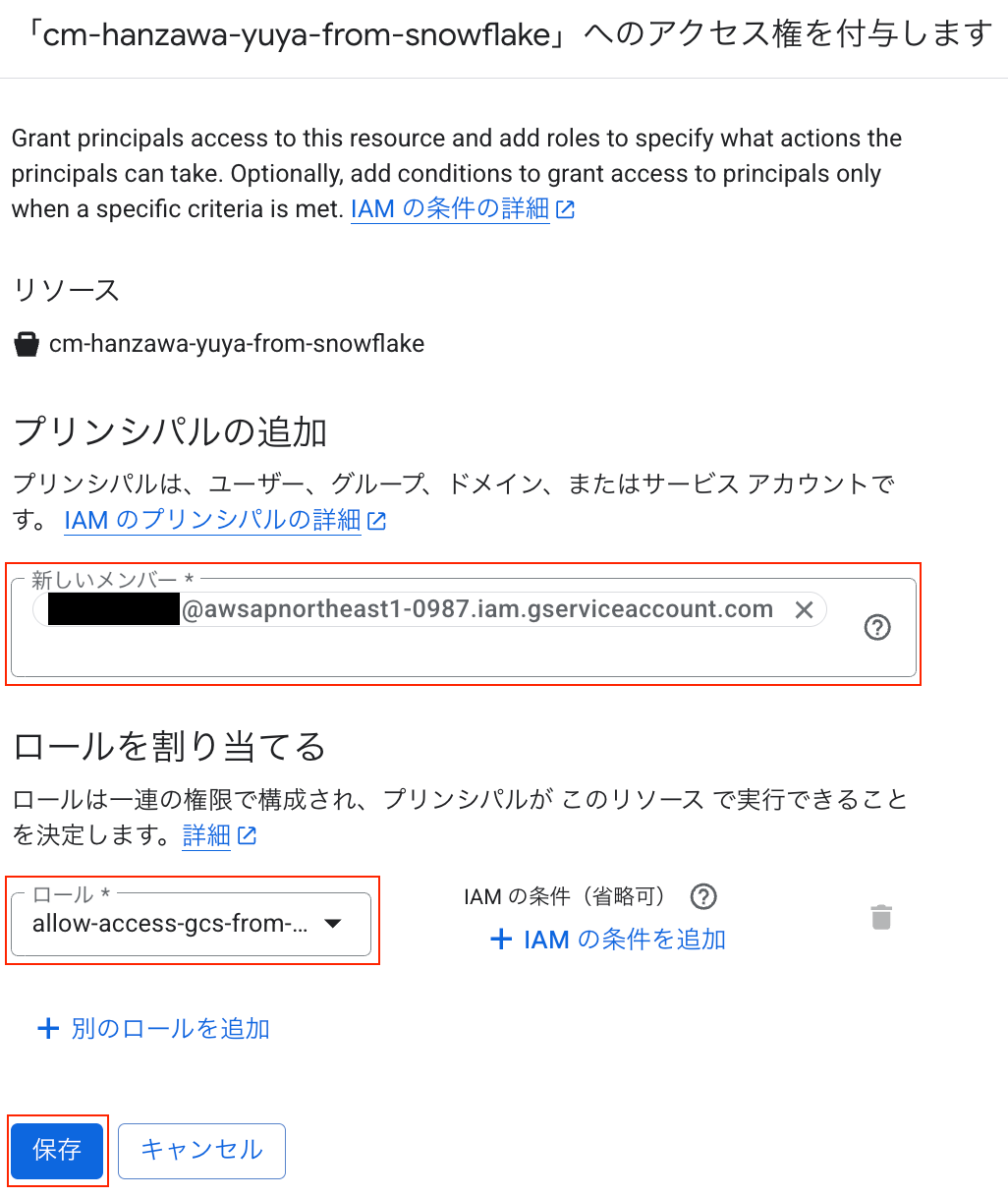
プリンシパルの追加 の項目で先ほど控えたサービスアカウントを入力します。
続いて、ロールを割り当てる の項目で手順 3 で作成したカスタムロールを選択し、最後に 保存 を押したら設定完了です。
5. ストレージ統合を使って Snowflake のテーブルを GCS に書き出す
ここでは、Snowflake のテーブルをストレージ統合を通じて GCS にファイルとして書き出します。
書き出しには COPY INTO コマンドを使用します。
まず、外部ステージを管理するためのデータベースを作成します。
CREATE DATABASE external_stage;
次に、GCS の外部ステージを作成します。
URL には手順 1 で作成した GCS バケットを、STORAGE_INTEGRATION には手順 2 で作成したストレージ統合(gcs_int)を指定します。
CREATE STAGE gcs_stage
URL = 'gcs://cm-hanzawa-yuya-from-snowflake/'
STORAGE_INTEGRATION = gcs_int
FILE_FORMAT = (TYPE = PARQUET);
外部ステージの作成が完了したら、以下のクエリで GCS にファイルを出力します。
USE DATABASE external_stage;
COPY INTO @gcs_stage/test/
FROM SNOWFLAKE_SAMPLE_DATA.TPCDS_SF100TCL.CUSTOMER_DEMOGRAPHICS;
クエリの実行後、GCS バケットを確認すると、以下のキャプチャのようにファイルが出力されていることが確認できました。

6. 書き出したファイルを BigQuery に取り込む
最後のステップとして、Snowflake から GCS に書き出したファイルを BigQuery で参照できるようにします。
ここでは BigLake テーブルを使って、GCS 上の Parquet ファイルを読み込みます。
BigLake テーブルの作成方法についてはここでは割愛します。詳細は以下のブログを参考にしてください。
以下のクエリで、GCS 上の Parquet ファイルを参照する BigLake テーブルを作成します。
CREATE OR REPLACE EXTERNAL TABLE snowflake.customer_demographics
WITH CONNECTION `asia-northeast1.biglake-connection`
OPTIONS (
format = 'PARQUET',
uris = ['gs://cm-hanzawa-yuya-from-snowflake/*']
);
テーブル作成後、以下のクエリでデータを確認します。
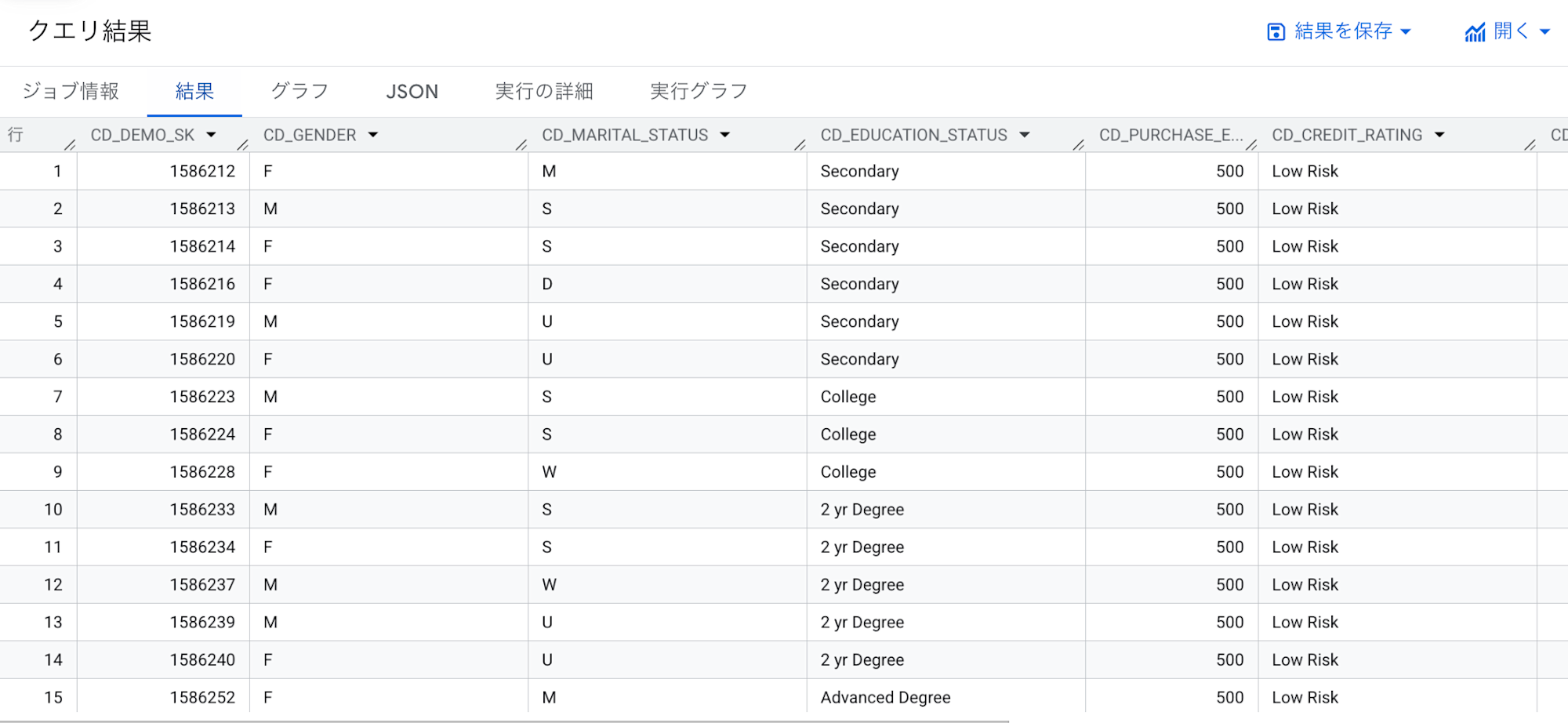
SELECT * FROM snowflake.customer_demographics
以下のように、GCS に書き出したデータが BigQuery 上の BigLake テーブルとして正しく読み込まれていることが確認できました。
まとめ
今回のブログでは、ストレージ統合(Storage Integration)を使って、AWS 上の Snowflake から GCS にファイルを書き出し、それを BigQuery の BigLake テーブルとして読み込む手順を紹介しました。
冒頭で紹介した BigQuery Data Transfer Service の Snowflake コネクタでは、増分転送に対応していませんでしたが、ストレージ統合を利用すれば、クエリの条件次第で柔軟にデータを抽出できるため、増分更新のような運用も可能です。
ストレージ統合は、Snowflake がどのクラウドにホストされていても、他クラウドのストレージと安全に連携できる点も大きな特徴です。
ぜひ参考にしてみてください!









